一、docker网络
1.1 虚拟化与容器技术本质
1.1.1 虚拟化技术核心价值
资源利用率提升:通过软件模拟硬件功能,实现系统资源的精细化分配与管理。
资源隔离保障:分配后的资源(如虚拟机)之间相互隔离,互不影响,适用于高压力环境及大规模集群部署。
1.1.2 容器技术本质与优势
轻量级进程管理 :容器本质是共享宿主机内核的进程管理工具,具有轻量、快速启动及高一致性的特点。
应用场景定位:主要用于应用服务的管理与微服务架构,而非作为主机级别的操作系统呈现。
1.2 Docker 网络通信原理
1. 2.1 网络地址转换(NAT)机制
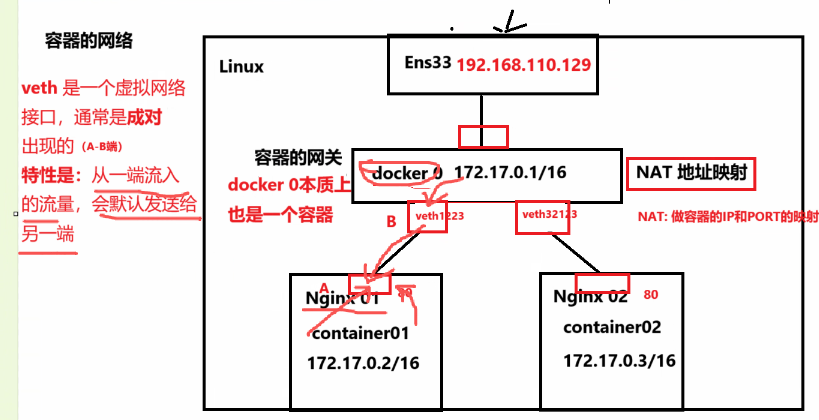
网关与地址映射 :Docker 默认创建 `docker0` 网桥(IP: 172.17.0.1)作为容器网关,负责将容器内部 IP(如 172.17.0.2)通过 NAT 映射为宿主机 IP。
端口映射策略:容器内部端口(如 80)通过 `-P` 参数随机映射为宿主机的高位端口(如 49153),实现外部访问。
1.2.2 虚拟网络设备(Veth Pair)
Veth Pair 成对出现:每创建一个容器,Docker 会在宿主机和容器内各创建一个 `veth` 虚拟网卡,两者成对出现(A/B 端)。
流量转发原理:利用**`veth` 设备**"一端流入、另一端流出"的特性,`docker0` 网桥将流量发送至 `veth` 一端,另一端容器即可接收,实现网络互通。
1.3 容器间通信与服务发现
1.3.1 容器生命周期与 IP 漂移
IP 地址漂移风险:由于容器本质是进程,易因资源竞争或异常导致重启,重启后分配的 IP 地址可能发生变化,无法通过固定 IP 进行访问。
1.3.2 内置 DNS 解析机制
基于容器名的解析:Docker 内置 DNS 服务,支持通过容器名称(如 `nginx01`)进行服务发现。即使容器 IP 变更,DNS 也会自动更新解析记录,确保容器间通过名称稳定通信。
1.4 Docker 四种网络模式详解
1.4.1 Bridge(网桥模式)
默认模式:容器通过 `docker0` 网桥连接,拥有独立的网络命名空间,通过 NAT 与外部通信,适合单机内容器互联。
1.4.2 Host(主机模式)
共享网络栈:容器直接使用宿主机的网络命名空间,没有独立的 IP 和端口映射,性能较高但端口需避免冲突。
1.4.3 None(无网络模式)
拒绝网络连接:容器拥有独立的网络命名空间但不配置任何网络,处于完全隔离状态,适用于安全要求极高的场景。
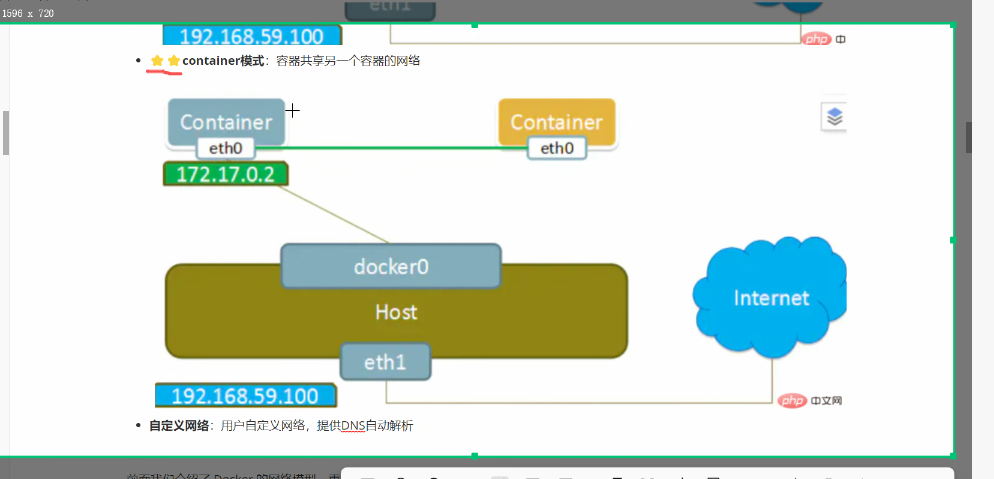
1.4.4 Container(容器模式)
网络共享:新创建的容器共享另一个已存在容器的网络栈,两者使用相同的 IP 和端口,但进程空间隔离。此模式是 K8s 的核心模式,适用于紧密协作的服务(如 Nginx 与 Java 应用)。
1.5 自定义网络与容器互联实战
1.5.1 自定义网络创建与管理
网络创建与查看:通过 `docker network create` 创建自定义网络(默认 Bridge 驱动),使用 `docker network inspect` 查看网络详情(子网、网关)。
容器加入网络:在运行容器时通过 `--network` 参数指定自定义网络,实现容器间的直接通信。
1.5.2 网络隔离与 DNS 解析机制
网络隔离验证:不同自定义网络(网段)下的容器默认无法直接通信,实现了项目间的网络隔离(如若依项目与商城项目)。
DNS 解析机制:Docker 内置 DNS 服务,支持容器间通过容器名(hostname)直接解析 IP,无需手动配置 hosts。
1.6 容器生命周期与运维命令
1.6.1 容器进程与生命周期
主进程守护原则:容器生命周期取决于其主进程(PID 1)。若主进程退出(如 Nginx 崩溃或任务结束),容器将自动停止。
保持容器运行:演示了通过 `sleep 3600` 命令维持容器运行状态,以模拟后台服务持续运行。
1.6.2 高效运维命令
批量清理容器:利用 `docker rm -f $(docker ps -aq)` 命令特性,强制删除所有容器(包括运行中的),实现快速清理环境。
端口映射与查看:对比了 `-P`(随机端口)与 `-p`(指定端口)的区别,并使用 `docker port` 查看端口映射详情。
1.7 常用诊断与日志命令
1.7.1 日志与进程查看
日志追踪:使用 `docker logs ` 查看容器标准输出,结合 `-f` 参数实时追踪日志,或使用 `-n` 查看指定行数。
进程信息:通过 **`docker top`**命令查看容器内部运行的进程树,辅助排查服务状态。
1.7.2 故障排查技巧
网络连通性测试:进入容器内部使用 `ping` 命令测试容器间网络连通性。
日志分析技巧:推荐使用 `grep -A/B/C` 命令结合 `docker logs` 进行日志上下文分析。
二、Docker 挂载
2.1 挂载介绍
2.1.1 持久化核心价值
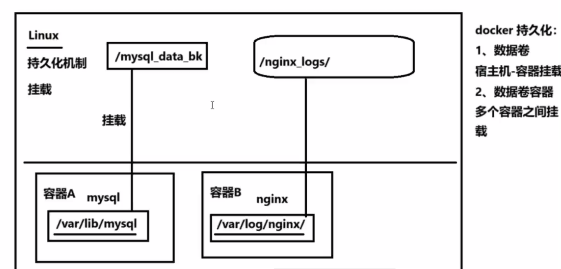
数据安全与备份:通过挂载机制将容器内数据(如 MySQL 数据、Nginx 日志)保存至宿主机或共享存储,确保容器销毁后数据不丢失。
运维便利性:将配置文件挂载至宿主机,可直接在宿主机编辑配置,无需进入容器内部,便于日志采集(如 Filebeat)和配置管理。
2.1.2 Bind Mount(本地挂载)
挂载特性 :使用 `-v /宿主机目录:/容器目录` 命令,本质是宿主机目录(设备文件)覆盖容器目录(挂载点)。
数据覆盖风险:若宿主机目录为空,挂载后会导致容器内原有文件被覆盖(如 Nginx 的 HTML 文件消失),因此需提前在宿主机准备文件。
数据流向:数据存储在宿主机指定目录,容器删除后数据保留。
2.1.3 Volume(数据卷挂载)
挂载特性:使用 `docker volume create ` 创建卷后,通过 `-v 卷名:/容器目录` 挂载。Docker 自动管理卷的生命周期,存储在 `/var/lib/docker/volumes` 下。
数据同步机制:不同于 Bind Mount 的单纯覆盖,Volume 挂载时若容器目录已有文件,会先将文件同步至宿主机卷中,实现双向数据同步。
数据流向:数据存储在 Docker 托管的卷中,即使容器删除,数据卷及数据依然存在。

2.2Docker 数据管理与挂载机制
2.2.1 数据卷(Volume)挂载
创建与挂载流程:首先通过 `docker volume create` 创建存储卷,该卷默认存储在 `/var/lib/docker/volumes` 目录下;随后在运行容器时使用 `-v` 参数将卷挂载至容器内部目录。
数据持久化特性:数据卷挂载不会覆盖容器内挂载目录下的原有数据,且在容器删除后数据依然保留,适用于数据持久化场景。
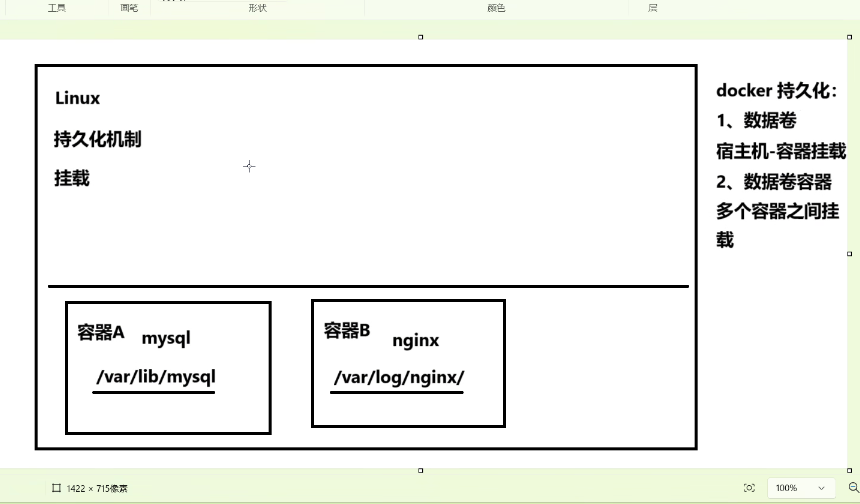
2.2.2 本地目录(Bind Mount)挂载
覆盖风险与准备:直接将宿主机目录挂载至容器,此方式会完全覆盖容器内挂载目录下的数据。因此必须在挂载前于宿主机目录下创建并准备好文件。
应用场景局限:虽然操作直接,但存在数据覆盖风险,需谨慎使用。
2.2.3 数据卷容器(Data Volume Container)
容器间数据共享:通过 `--volumes-from` 参数实现容器间的挂载共享。例如,创建 `web2` 容器暴露挂载点 `/data1` 和 `/data2`,`web3` 容器可直接继承这些挂载点。
性能优势:相比通过网络(网桥)传输数据,数据卷容器避免了网络性能损耗,适用于容器间频繁数据交互的场景(如 Fluentd 采集 Nginx 日志)。
2.4 容器化部署的适用性与限制
三类不适合在 Docker 中运行的服务类型:
2.4.1 高安全性与稳定性要求的服务
核心数据库风险:MySQL 等核心数据库若对安全稳定性要求极高,不适合容器化。容器短生命周期特性可能导致业务中断或数据丢失,尤其在业务繁忙时风险更大。
临时数据例外:若 MySQL 仅存储非核心的客户信息等简单数据,可考虑容器化。
2.4.2 高性能与高吞吐量的服务
性能压制问题:Kafka 等消息队列处理性能要求极高(百万级吞吐量),容器进程管理机制可能压制其性能,通常建议部署在容器外部。
2.4.3 极度消耗资源的服务
资源隔离限制:Oracle 等重量级数据库通常需要大量物理内存(如 128GB),容器虚拟化环境难以满足其极致性能需求,且单进程容器存在单点故障风险。
总结
bash
虚拟化解决什么问题,容器又解决什么问题
redis
哨兵 : 监控 选举(RAFT) hello频道 主客观下线 高可用 (角色确定好,动作的方向确定好,加上关键词)
cluster: 哈希槽 多master分布式集群 主-从同步、高可用 扩展能力强/高性能 健康检查
部署/正常使用/故障异常/优化
进行比较,先确定 核心职能 + 优缺点 + 技术的特性 (我们在哪些地方需求这个技术)
不管多复杂的技术,核心本质都是很简单的
数据存取、高可用、适应不同场景
区别:
哨兵 cluster
高可用 哨兵节点完成 master hash槽
数据存取 master(主从复制) master(分布式)主从同步
优缺点 维护简单,性能瓶颈 扩展能力强,维护复杂
虚拟化解决什么问题,容器又解决什么问题
提高系统资源利用率,
模拟 分配、管理资源 隔离
场景:在大规模集群下使用(安全性比容器好,稳定)
本质:如果是虚拟机的化,完整的操作系统
虚拟化的产品: kvm、EXSI、hyper-v(windows)、XEN、AMD公司产品
容器 本质:进程管理服务、共享系统内核
轻量 简单 移植性好
场景:容器是作为应用服务的管理工具(微服务)
容器的产品:Docker Podman
容器的网络:
1、bridge 容器网桥:多个容器 使用docker0网桥的veth对进行连接(默认)
2、host 主机网络:容器直接使用宿主机的网卡ip:port 进行通讯
3、none 无网络连接
4、⭐container 多个容器使用同一个容器的网络通讯
场景:
1、bridge 通用场景
2、host 这种网络一般只在公司内网环境使用,不会给公网访问(特性是网络性能最佳,但安全不足)
3、container 在需要频繁交互的容器之间使用 (比如ruoyi的前后端)
#指定nginx01 暴露的端口是81
docker run -itd --name nginx01 -p 81:80 nginx:1.25.3
#从(49153开始)"按顺序" 分配给nginx02 一个端口
docker run -itd --name nginx01 -P nginx:1.25.3
#批量删除容器(非up的)
docker rm `docker ps -aq`
#自定义一个网络(网段默认分配)
docker network create ruoyi-net
#查看网络的基本信息
docker network inspect ruoyi-net
#查看docker 日志 / 容器内的进程信息
docker logs 容器ID/name
docker top 容器ID/name
docker 的四种网络模式(不止4种)
挂载机制: 存储空间共享的机制
命令字:
mount 设备文件 挂载点
把设备文件的存储空间,包含存储空间中的数据文件,一并共享给挂载点使用
Docker 数据卷 持久化
是什么,干嘛的: 本质而言就是宿主机与容器之间的挂载行为
作用:可以方便数据采集(日志、备份数据等等)同时可以方便修改配置文件
#Docker 的数据卷有多种类型
bind 本地挂载
volume 数据卷挂载
1、"数据卷"命令
宿主机--容器的挂载
#本地挂载
docker run -itd --name nginx_bind -v /nginx_html_data/:/usr/share/nginx/html -P nginx:1.25.3
本地挂载后,是宿主机的目录--》作为设备文件挂载给容器内的目录使用
这种方式会覆盖原本容器内挂载目录下的数据,所以,通常我们需要先在宿主机目录下创建并准备好文件,再进行本地挂载
#存储卷
docker volume create nginx_html
先创建存储卷,存储卷会默认创建在 /var/lib/docker/volumes/卷name/_data/
再和容器内的目录进行挂载
docker run -itd --name nginx_bind -v nginx_html:/usr/share/nginx/html -P nginx:1.25.3
挂载后,不会覆盖容器内挂载目录下的数据,并且删除容器后,数据也可以保存下来
2、"数据卷容器"
容器之间相互挂载
创建一个 web2 的数据卷容器,它有两个数据卷: /data1 和 /data2
[root@localhost ~]# docker run --name web2 -v /data1 -v /data2 -it centos:7 /bin/bash
在 web2 容器内部,我们向这两个数据卷中分别写入了文件。
[root@localhost ~]# echo "this is web2" > /data1/abc.txt
[root@localhost ~]# echo "THIS IS WEB2" > /data2/ABC.txt
创建新的容器 web3 ,并使用 --volumes-from 选项将 web2 容器中的数据卷挂载到
web3 中。这样, web3 就可以访问 web2 中的数据卷了。
[root@localhost ~]# docker run -it --volumes-from web2 --name web3 centos:7 /bin/bash
在 web3 容器内部,我们可以验证是否能够访问到 web2 中的数据卷内容。
Docker 容器不适合管理哪些应用服务
1、安全、稳定性要求特别高的服务不适合跑在容器中 比如 核心的数据库服务(mysql)
2、通常来说,kafka 一般都是做在容器外面的
3、极度吃资源的服务不适合放在容器中(oracle)
2个方向的内容:
1、网络(4种模式)
2、持久化(数据卷、数据卷容器)
docker logs xxxx部分补充:redis
bash
一、Redis 技术理解
1. 核心技术掌握层级划分
熟练级标准:能够提炼重点并明确细节,涵盖部署、正常使用、异常故障及优化四个方向。
精通级标准:除了熟练级要求外,还需具备在不同场景下进行代码级开发与设计的完整体系能力。
2. 面试表述的"角色-动作"逻辑
主体与客体界定:在描述技术原理时,必须先明确名词角色(如哨兵节点、Master、Slave)。
动作方向确定:清晰描述动作的发起方与接收方(如哨兵监控 Master),并结合关键词(如监控、同步、选举)进行串联。
二、哨兵模式(Sentinel)核心机制解析
1. 核心关键词提炼
核心要素:主要包括哨兵节点、Master、Slave 三个角色,以及监控、Hello 频道同步、主客观下线判断、Raft 选举等动作。
逻辑闭环:通过"监控-同步-判断-选举"的流程,最终实现故障转移与高可用。
2. 运行机制拆解
故障检测机制:哨兵通过监控 Master 状态,利用 Hello 频道进行信息同步,并执行主客观下线判断。
高可用实现:一旦判定 Master 宕机,哨兵集群通过 Raft 协议选举出新的 Master,完成自动切换。
三、Cluster 模式架构与特性
1. 核心架构特征
分布式多 Master 架构:由多个 Master 节点组成分布式集群,数据通过哈希槽(Hash Slot)进行分片存储。
主从同步机制:每个 Master 拥有专属的 Slave 节点,负责数据同步与备份。
2. 核心能力与特性
高扩展性与性能:支持动态添加 Master 节点,哈希槽自动重分配,实现横向扩展与高性能读写。
高可用保障:Master 节点间进行健康检查,故障时由 Slave 自动晋升为 Master 并继承哈希槽位。
三、区别对比
1. 高可用与数据存取机制差异
哨兵模式(Sentinel):依赖哨兵节点监控主从状态,通过主客观下线判定及自动切换实现高可用;数据存取完全基于主从复制集群,由 Master 节点承担读写压力。
Cluster 模式:采用分布式架构,通过多个 Master 节点同时工作并平分哈希槽(Hash Slot)来实现高可用与数据存取,具备天然的横向扩展能力。
2. 扩展性与维护复杂度权衡
扩展性对比:哨兵模式受限于单台 Master 节点的性能瓶颈(内存、CPU),仅能通过昂贵的纵向扩展提升性能;Cluster 模式通过增加 Master 节点即可实现横向扩展,扩展能力更强。
运维复杂度:哨兵模式维护简单,仅需配置主从复制与哨兵监控;Cluster 模式需管理哈希槽位分配与数据迁移,维护相对复杂。