前言
在前文我们系统掌握了Java线程、锁、AQS、ThreadLocal等底层并发基础后,本章将聚焦Java并发工具核心落地载体------并发容器与并行框架。
日常开发中,我们极少手动加锁控制集合并发安全,JDK为我们封装了一套线程安全的并发容器,底层内置完善的锁机制、CAS操作、并发控制逻辑,开发者只需直接调用API即可,无需手动处理加锁、扩容、线程竞争等复杂逻辑,大幅降低并发开发成本。
本章重点讲解:ConcurrentHashMap底层原理、哈希散列核心逻辑、阻塞队列体系、有界无界队列差异、线程池任务调度机制、Fork/Join并行计算框架等
一、前置基础:HashMap与HashTable
1.1 HashMap底层结构
HashMap是线程不安全的哈希容器,核心结构为数组+链表/红黑树,1.7和1.8两个版本的底层优化差异是面试基础必考点:
JDK1.7 结构:数组+单向链表
采用头插法插入链表节点,无红黑树结构,哈希冲突过多时会导致链表无限拉长,查询效率退化为O(n)。同时也是并发死循环问题的根源版本。
JDK1.8 结构:数组+单向链表+红黑树
优化两大核心点:一是采用尾插法替代头插法,彻底解决扩容死循环问题;二是新增红黑树优化,当链表长度大于8、数组容量大于64时,链表转换为红黑树,将查询效率优化为O(logn),大幅解决哈希冲突导致的性能退化问题。
1.2 HashMap 多线程致命问题
HashMap未做任何并发控制,多线程环境下存在两大致命故障,绝对不能用于并发场景:
-
数据覆盖丢失:多线程同时执行put操作,若哈希索引一致,后执行的线程会直接覆盖前一个线程写入的数据,导致数据永久丢失。
-
扩容死循环、服务宕机:JDK1.7头插法机制下,多线程同时触发扩容,会导致链表节点互相引用、形成环形链表。后续遍历、查询数据时会进入无限循环,CPU 100%占用,直接引发服务宕机。
核心总结:HashMap 查询、写入高效,但完全线程不安全,仅限单线程场景使用。
1.3 HashTable 线程安全容器
HashTable是JDK早期提供的线程安全哈希容器,为解决HashMap并发问题而生,但存在严重性能缺陷。
其核心实现逻辑:对整个哈希表全局加synchronized锁。
无论读写、无论操作哪个索引位置的数据,都会锁住整个容器,所有线程串行执行,完全丧失并发能力。高并发场景下吞吐量极低、性能极差,目前已彻底废弃,仅作为面试对比知识点。
二、哈希散列核心原理
2.1 散列(哈希)核心定义
散列(Hash)是一种经典数据映射算法:将任意长度、无规律的输入数据,通过固定哈希算法,转换为固定长度的哈希值。
核心特性:
-
算法固定:相同输入永远得到相同哈希值;
-
均匀分组:无规律数据被均匀打散分配到不同索引位置;
-
可逆溯源:可通过哈希值反向定位原始数据存储位置。
所有哈希容器(HashMap、ConcurrentHashMap)的索引定位、数据分组,全部依赖散列算法实现。
2.2 散列算法优劣判断标准:哈希倾斜
优质的哈希算法核心目标:数据均匀分布,避免扎堆。
若大量数据哈希后集中在少数索引位置,会形成哈希倾斜:链表无限拉长、红黑树频繁转换、查询性能大幅下降。ConcurrentHashMap的算法优化、分段锁设计,本质都是为了规避哈希倾斜、提升并发性能。
三、ConcurrentHashMap 并发哈希容器
3.1 核心定位与设计思想
ConcurrentHashMap是JDK官方推荐的高并发线程安全哈希容器,完美平衡了HashMap的不安全与HashTable的低性能,是并发场景存储键值对数据的首选。
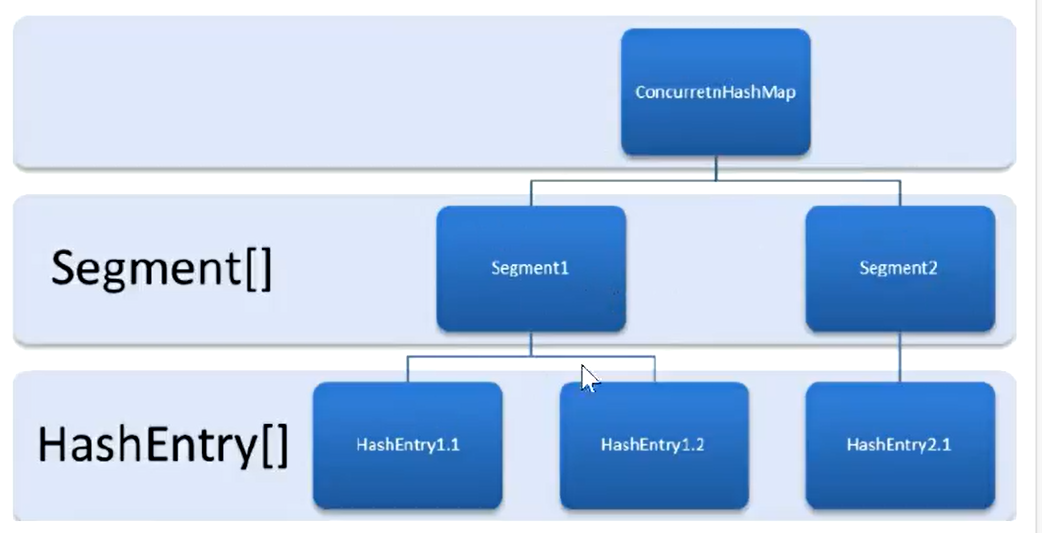
核心设计理念:分段锁思想
摒弃HashTable全局锁的低效设计,将一个大哈希表拆分为若干个独立的小哈希表(桶),每个桶单独加锁、独立竞争,不同桶的线程互不影响,真正实现并行读写、互不阻塞,并发吞吐量大幅提升。
3.2 三大核心方法底层逻辑(get/put/size)
ConcurrentHashMap底层内置锁机制与CAS并发控制,使用者无需手动加锁,天然线程安全。
1. get 查询操作(无锁、高效)
查询全程无加锁、基于volatile可见性+CAS实现,极致高效。多线程并发查询完全无阻塞,仅在节点初始化、扩容时做轻量并发控制,适配超高并发查询场景。
2. put 写入操作(分段锁+CAS)
写入采用CAS无锁尝试 + synchronized桶锁机制:优先通过CAS尝试无锁写入,失败后仅锁定当前数据所在的桶,不影响其他桶的读写操作。既保证线程安全,又最大化保留并发性能。
3. size 统计操作(精准计数)
并非简单遍历计数,底层维护累加计数器,结合分段统计、容错修正机制,精准统计容器实时数据量,兼顾并发更新准确性与统计性能。
3.3 核心优势总结
-
相较于HashMap:天然线程安全,无数据覆盖、无扩容死循环问题;
-
相较于HashTable:分段锁细化并发粒度,支持多线程并行操作,性能碾压全局锁;
-
读写并发友好,读无锁、写细粒度锁,适配读多写少、高并发业务场景。
四、并发队列体系
4.1 ConcurrentLinkedQueue 无锁并发队列
ConcurrentLinkedQueue是JDK提供的无锁、高并发、非阻塞队列,底层全程基于CAS实现并发控制,无锁竞争开销,性能极高。
核心场景:高并发无阻塞消息流转、异步任务缓冲,适合纯消费、纯生产的高速并发场景。
4.2 七大阻塞队列
阻塞队列是Java并发编程的核心工具,也是线程池的底层依赖,核心特性:自带阻塞、唤醒机制,无需手动控制线程等待与唤醒。
核心规则:队列满时生产者阻塞、队列空时消费者阻塞,完美适配生产者消费者模型,规避并发数据错乱、无效CPU消耗问题。
JDK共计7种阻塞队列,适配不同业务场景:ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityBlockingQueue、DelayQueue、LinkedTransferQueue、BlockingDeque。
五、有界队列 VS 无界队列
队列的有界、无界特性,直接决定线程池的线程扩容策略、任务拒绝策略、系统负载上限,是线程池调优的核心知识点。
5.1 无界队列
无固定容量上限,可无限存放任务。任务堆积时不会触发线程扩容,只会持续堆积任务,极端场景下会导致内存溢出OOM。适用于任务量稳定、无突发流量的场景。
5.2 有界队列(工程首选)
设置固定最大容量,结合线程池核心参数实现精细化流量管控,核心运行机制:
-
最小核心线程数:无任务、低流量时,仅保留核心线程运行,无频繁线程创建销毁,CPU消耗极低;
-
队列缓冲阶段:突发任务到来时,优先存入有界队列缓冲,由核心线程逐步消费;
-
最大线程扩容:队列存满、任务积压时,线程池自动扩容至最大线程数,加速消费突发任务,削峰填谷;
-
拒绝兜底:线程数、队列全部打满后,触发拒绝策略,保护系统不被流量打垮。
核心价值:管控并发峰值、避免OOM、减少线程频繁创建销毁、保护系统稳定性。
六、Fork/Join 并行计算框架
6.1 核心设计思想
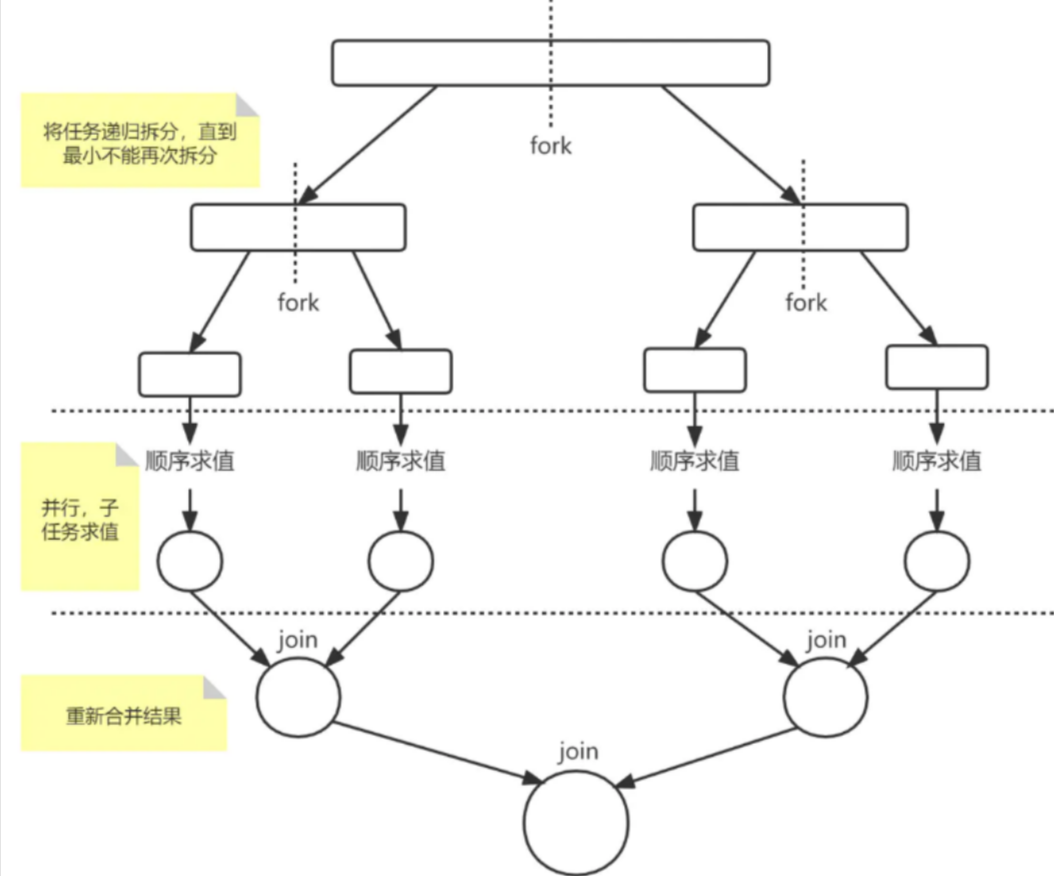
Fork/Join是JDK1.7推出的分治并行框架 ,核心逻辑:大任务拆分、小任务并行执行、最终结果合并。
专门适配大规模批量计算、递归计算、海量数据处理场景,将单一耗时大任务,拆解为无数个可并行执行的子任务,交由多线程并发处理,最后汇总结果,极大提升批量计算效率。
6.2 核心工作流程
-
Fork(拆分):判断任务是否过大,若超出阈值则递归拆分为多个子任务;
-
Compute(计算):拆分后的小任务独立并行执行;
-
Join(合并):等待所有子任务执行完毕,汇总所有子结果,合并为最终结果。

6.3 线程池任务提交两大方式(面试必区分)
Java线程池、ForkJoin框架均支持两种任务提交方式,核心差异清晰:
1. execute()
无返回值提交,仅负责执行任务,无法获取任务执行结果、无法捕获任务异常,适用于纯异步执行、无需结果的业务场景。
2. submit()
有返回值提交,返回Future对象,可通过Future获取任务执行结果、捕获执行异常,支持结果回调、任务监控,适用于需要结果反馈的计算类任务。