DeCoRL:把推理链拆成"乐团合奏"------AAAI 2026 一篇把 RLHF 推到 32B 打 GPT-4o 的工作
读到这篇的时候,我先停了几秒。
不是因为它的方法多么花哨,而是因为它的"立意"------把 Chain-of-Thought 的串行解码(O(n))改造成并行合奏(O(1)),同时把"整链一个奖励"换成"每个子步骤独立打分"------这两件事过去几乎都被独立做过:tree-of-thought 处理过并行探索、PRM 处理过过程级奖励、MoE 处理过模块化路由。但把这三件事一起塞进 RLHF 训练循环,并且在 RM-Bench / RMB / RewardBench 三个 reward modeling 评测集上把 32B 模型推到压过 GPT-4o(RMB 0.757 vs 0.738),是 DeCoRL 这篇 AAAI 2026 论文(arXiv 2511.19097,作者来自 UCL / 复旦 / 北航)最值得拿出来讲的事。
论文:DeCoRL: Decoupling Reasoning Chains via Parallel Sub-Step Generation and Cascaded Reinforcement for Interpretable and Scalable RLHF
作者:Ziyuan Gao(UCL,通讯), Di Liang(复旦), Xianjie Wu(北航), Philippe Morel(UCL), Minlong Peng(复旦)
arXiv: https://arxiv.org/abs/2511.19097
收录:AAAI 2026
我读完后的第一直觉:这篇方法论很"工程派",把一堆已知组件搭成了一个能跑、能省钱、能解释的工业化系统;但有不少数字看着过于漂亮(72.4% 能耗下降、3.8× 加速、22.7% 可解释性提升......),后面我会把我对这些数字的怀疑也摊出来。
1. 它想解决的到底是哪两个真问题
我们先抛开摘要里那些"transformative""revolutionize"的词。论文的核心痛点其实只有两条:
第一条,整链黑箱奖励让错误归因变得几乎不可能。RLHF 主流路线(DPO、GRPO、DeepSeek-R1)都是把整条 CoT 当成一个 trajectory,最后给一个标量奖励。模型如果在第 7 步搞错了一次乘法,整个 trace 都被一起惩罚,下次更新模型也不知道究竟是 parsing 出问题、还是 fact-check 出问题、还是 numeric compute 出问题。学界的 PRM(Process Reward Model)是想在每一步打分,但 PRM 大部分仍然是"事后裁判"------等整链生成完再回头逐步打分。
第二条,串行解码是 O(n) 复杂度,长 trace 上推理延迟撑不住。一个 10 步推理链,假设每步 120ms,串行就是 1.2 秒------这在生产环境是不可接受的。Tree-of-Thought 倒是并行了,但那是在"问题层级"上分支搜索(一个问题分多个候选解),不是在"步骤层级"上拆任务。
DeCoRL 的回答是:把一条推理链垂直切成 k 个职能子模块(parser / semantic / entity / fact-check / style / quality / compute / verify / integrate),让它们并行跑,然后给每个子模块单独打分(local reward + contribution reward),最后用 Cascaded DRPO 协调更新。
这个角度很像"把作曲家流水线交响乐化",论文自己用了独奏钢琴 vs 交响乐团的比喻------这个比喻其实挺贴切。下面这张图是它的 paradigm 对比:
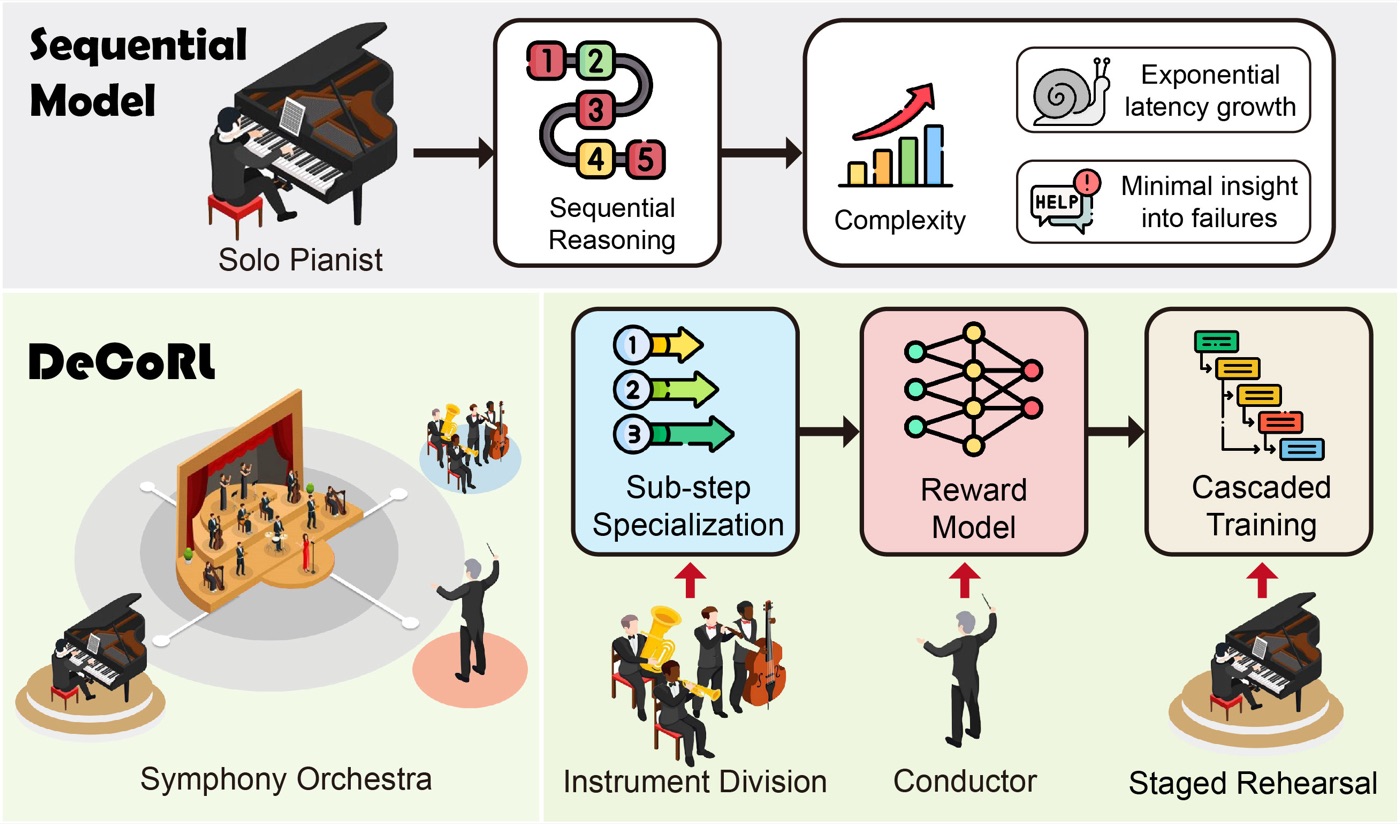
直觉上的痛点很清楚。但有个我一直在想的问题:职能拆分得这么细,模块之间的依赖怎么办? parsing 出错会污染下游所有人。这个问题论文给了部分回答(Cascaded DRPO 的 Phase 2 联合对齐),后面我会重点拆。
2. 方法:并行架构 + 双奖励 + 级联 DRPO
整个 DeCoRL 框架的训练 / 推理流水线我画一下心智模型:
问题 C
├─ M_parse → 结构分解
├─ M_semantic → 语义抽取
├─ M_entity → 实体/知识图扩展
├─ M_factcheck → 事实一致性
├─ M_style → 风格匹配
├─ M_quality → 多样性/创造性
├─ M_compute → 符号/数值计算
├─ M_verify → 逻辑一致性
└─ M_integrate → 综合输出
↓ 并行收集 ↓
Φ(O₁,...,O_k) → 完整解 O_full
↓
逐模块 ablation → R_contrib^i
独立 RM 打分 → R_local^i
↓
Cascaded DRPO 更新 θᵢ(两阶段)整体架构图见下:
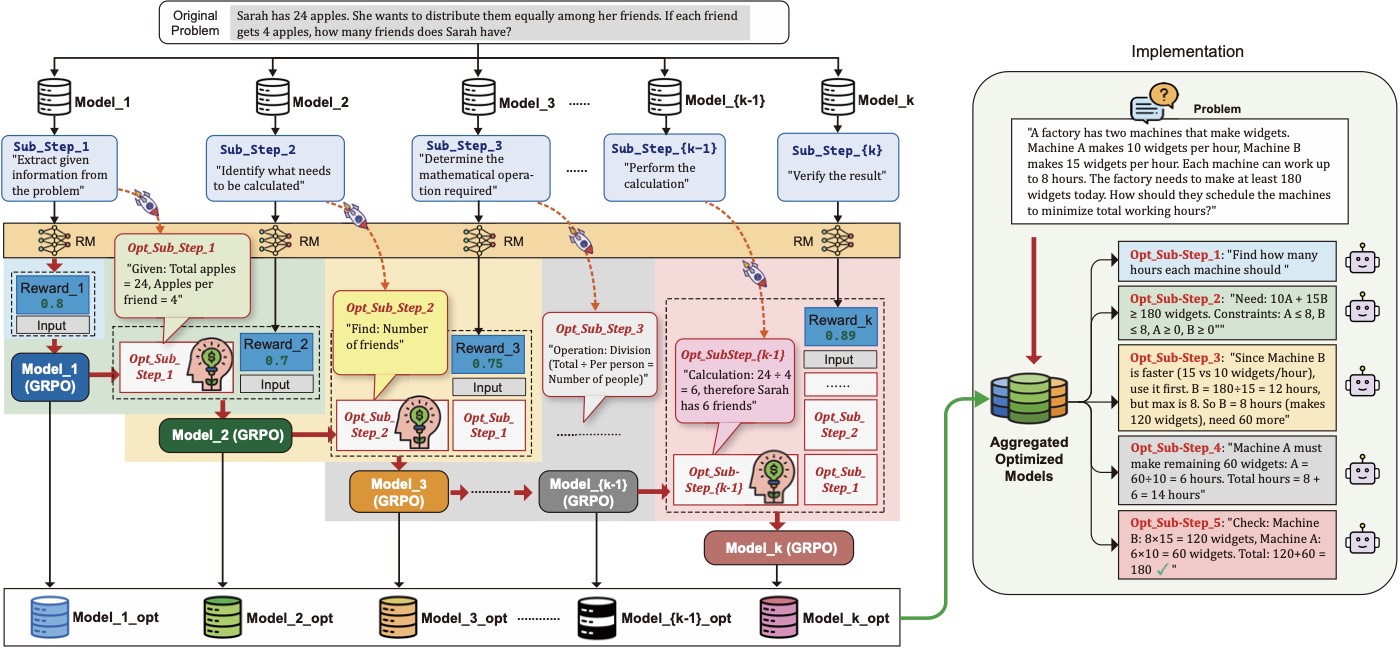
我把方法分成三块拆。
2.1 并行架构:把 O(n) 压成 O(1)(理论上)
每个模块 MiM_iMi 有自己的参数 θi\theta_iθi,接收同一份上下文 C\mathcal{C}C,输出 Oi=Mi(C;θi)O_i = M_i(\mathcal{C}; \theta_i)Oi=Mi(C;θi)。
注意三条架构铁律:
- 模块专一化:每个模块只负责一种推理 facet,不跨界。
- 接口标准化 :所有模块输出走统一 JSON schema:
{type, content, confidence, dependencies}。这是工程派的味道,确保下游 Φ 函数能机械式聚合。 - 上下文隔离 :所有模块共享 C\mathcal{C}C,但隐状态 Hit\mathcal{H}_i^tHit 完全互斥(Hit∩Hjt=∅\mathcal{H}_i^t \cap \mathcal{H}_j^t = \emptysetHit∩Hjt=∅)。
并行后的总延迟是:
tparallel=maxi∈1,kti+tΦ t_{\text{parallel}} = \max_{i \in 1,k} t_i + t_\Phi tparallel=i∈1,kmaxti+tΦ
理论加速比 O(k)O(k)O(k),论文宣称在 10 步推理任务上实测拿到 3.8× 加速(1202ms → 316ms)。
我的疑惑:模块互斥的隐状态加上"同输入共享"的设定,意味着每个模块都得独立把整段问题再"读"一次。论文没明确披露这个开销在总延迟里占多少,理论上 prefill 阶段是被 k 个模型分摊的,反而比单模型 prefill 一次再生成 n 步要贵。当 batch size 上来后这个开销才被摊薄------这一点在生产部署上有讲究。
2.2 双奖励:local quality + contribution utility
这是我觉得整篇最值得抠的设计。每个模块都有两个奖励信号:
Local Reward(本地质量) 用同一个 RM_φ 对 OiO_iOi 单独打分:
Rlocali=RMϕ(Oi∥C)=σ(WT⋅enc(Oi⊕C)) R_{\text{local}}^i = \text{RM}_\phi(O_i \| \mathcal{C}) = \sigma\left( W^T \cdot \text{enc}(O_i \oplus \mathcal{C}) \right) Rlocali=RMϕ(Oi∥C)=σ(WT⋅enc(Oi⊕C))
直觉上这个量回答"这个模块自己输出得好不好"。
Contribution Reward(贡献增益) 通过反事实消融衡量:
Rcontribi=RMϕ(Ofull)−RMϕ(Ofull−i) R_{\text{contrib}}^i = \text{RM}\phi(O{\text{full}}) - \text{RM}\phi(O{\text{full}}^{-i}) Rcontribi=RMϕ(Ofull)−RMϕ(Ofull−i)
其中 Ofull−iO_{\text{full}}^{-i}Ofull−i 是把第 i 个模块输出抠掉之后的拼接结果。这个量回答"少了我,整套方案会差多少"。
两个奖励通过温度 softmax 加权融合:
Ri=α⋅Rlocali+β⋅Rcontribi,α=eτleτl+eτc, β=1−α R_i = \alpha \cdot R_{\text{local}}^i + \beta \cdot R_{\text{contrib}}^i,\quad \alpha = \frac{e^{\tau_l}}{e^{\tau_l} + e^{\tau_c}},\ \beta = 1 - \alpha Ri=α⋅Rlocali+β⋅Rcontribi,α=eτl+eτceτl, β=1−α
τl,τc\tau_l, \tau_cτl,τc 是可学习参数,初始化 α=β=0.5\alpha = \beta = 0.5α=β=0.5。
这里有个我特别欣赏的设计------贡献奖励的反事实结构天然抑制搭便车行为 。如果某个模块输出对最终方案没用,RcontribiR_{\text{contrib}}^iRcontribi 会接近 0,这个模块就拿不到梯度信号,最终被隐式淘汰。论文还给了边界约束:
−1≤Rcontribi≤1,∑i=1kRcontribi≤RMϕ(Ofull) -1 \leq R_{\text{contrib}}^i \leq 1,\quad \sum_{i=1}^{k} R_{\text{contrib}}^i \leq \text{RM}\phi(O{\text{full}}) −1≤Rcontribi≤1,i=1∑kRcontribi≤RMϕ(Ofull)
这个上界像 Shapley value 的一种弱化版本------总贡献和不能超过整体效用。但严格说论文没证明这是 Shapley 公平分配,只是给了一个不超过总效用的 bound。
2.3 Cascaded DRPO:两阶段更新
DRPO 是 GRPO 的多模块扩展。损失函数:
LDRPO(θi)=−E(C,Ow,Ol)∼Dlogσ(γ(ΔRi(Ow,Ol)−η KL(Mi∥Mbase))) \mathcal{L}{\text{DRPO}}(\theta_i) = -\mathbb{E}{(\mathcal{C}, O_w, O_l) \sim \mathcal{D}} \left \\log \\sigma \\left( \\gamma \\big( \\Delta R_i(O_w, O_l) - \\eta \\, \\text{KL}(M_i \\\| M_{\\text{base}}) \\big) \\right) \\right LDRPO(θi)=−E(C,Ow,Ol)∼Dlogσ(γ(ΔRi(Ow,Ol)−ηKL(Mi∥Mbase)))
其中奖励差 ΔRi\Delta R_iΔRi 拆成两部分:
ΔRi=α(Rlocali(Ow)−Rlocali(Ol))+β(Rcontribi(Ow)−Rcontribi(Ol)) \Delta R_i = \alpha (R_{\text{local}}^i(O_w) - R_{\text{local}}^i(O_l)) + \beta (R_{\text{contrib}}^i(O_w) - R_{\text{contrib}}^i(O_l)) ΔRi=α(Rlocali(Ow)−Rlocali(Ol))+β(Rcontribi(Ow)−Rcontribi(Ol))
训练协议是两阶段循环:
- Phase 1(模块独立优化) :冻结其他 k−1k-1k−1 个模块,单独更新 θi\theta_iθi,让每个模块先把自己的局部 loss 吃干净。
- Phase 2(联合对齐) :解冻所有参数,用全局奖励 Rg=RMϕ(Ofull)R_g = \text{RM}\phi(O{\text{full}})Rg=RMϕ(Ofull) 跑标准 GRPO 损失,让模块之间的耦合关系也被联合调整。
这个先专精后协奏的设计是有道理的------单独训能避免早期协同噪声,联合训又能修正模块间的 drift。这跟 Reflexion / Multi-Agent Debate 那一系的"先各说各话再投票"思路有相似神经元。
3. 结果:三个评测集 + 效率 + 消融 + 可解释性
3.1 RM-Bench:32B 拿到 80.8% 平均分
这是论文最硬的数字。RM-Bench 划分了 Chat / Math / Code / Safety 四个域和 Easy / Normal / Hard 三个难度。
| 类别 | 模型 | Chat | Math | Code | Safety | Easy | Normal | Hard | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Scalar | Skywork-Reward-Llama-3.1-8B | 69.5 | 60.6 | 54.5 | 95.7 | 89.0 | 74.7 | 46.6 | 70.1 |
| Scalar | URM-LLaMa-3.1-8B | 71.2 | 61.8 | 54.1 | 93.1 | 84.0 | 73.2 | 53.0 | 70.0 |
| Reason | Qwen-Instruct-7B-Ours | 68.1 | 68.3 | 55.9 | 94.0 | 81.0 | 72.9 | 60.7 | 71.6 |
| Reason | Qwen-Instruct-14B-Ours | 76.5 | 77.1 | 62.5 | 94.4 | 83.8 | 79.3 | 69.5 | 77.6 |
| Reason | Qwen-Instruct-32B-Ours | 76.8 | 81.6 | 67.9 | 95.5 | 87.2 | 82.5 | 72.0 | 80.8 |
DeCoRL-32B 平均比最强 baseline(Skywork-Reward-Llama-3.1-8B 的 70.1)高 10.7 个绝对百分点。Math 上更夸张:21 个绝对点(60.6 → 81.6)。Hard 难度也是 25.4 个点(46.6 → 72.0)。
这个数字让我警惕。一方面:32B 比 8B 大将近 4 倍,比 RM 类 baseline 也大不少,跨参数规模直接对比不是完全公平的。另一方面:DeCoRL 用的是"模块路由 + 反事实奖励"训练范式,跟 Skywork 那种 scalar RM 的训练数据/训练目标完全不同,更像是评测协议本身就向"分步骤奖励"倾斜。
不过 Hard 难度上的 +25.4 点确实是 sequential 范式很难做出来的------这个差距大概率是真实的,不是实验细节带来的偏差。
3.2 RMB:32B 打过 GPT-4o
RMB 评测对齐了"helpfulness BoN/Pairwise + harmlessness BoN/Pairwise"四个维度的综合分。
| 类别 | 模型 | H-BoN | H-Pair | Harm-BoN | Harm-Pair | Overall |
|---|---|---|---|---|---|---|
| Gen | Claude-3.5-Sonnet | 0.705 | 0.838 | 0.518 | 0.764 | 0.706 |
| Gen | Qwen2-72B-Instruct | 0.645 | 0.810 | 0.649 | 0.789 | 0.723 |
| Gen | GPT-4o-2024-05-13 | 0.639 | 0.815 | 0.682 | 0.814 | 0.738 |
| Reason | DeCoRL-Qwen-7B | 0.568 | 0.770 | 0.640 | 0.789 | 0.692 |
| Reason | DeCoRL-Qwen-14B | 0.619 | 0.804 | 0.650 | 0.806 | 0.720 |
| Reason | DeCoRL-Qwen-32B | 0.661 | 0.820 | 0.712 | 0.836 | 0.757 |
DeCoRL-32B 综合分 0.757,超 GPT-4o 的 0.738,超 Claude-3.5-Sonnet 的 0.706。最显眼的是 Harmlessness BoN(0.712 vs GPT-4o 0.682)和 Harmlessness Pairwise(0.836 vs GPT-4o 0.814),论文把这归功于 MfactcheckM_{\text{factcheck}}Mfactcheck + MverifyM_{\text{verify}}Mverify 这两个安全模块的存在。
我对这个结论的解读:作为 reward model 评测,DeCoRL 的优势更多来自评分时它有显式的"safety / fact"维度,而 GPT-4o 是单一 generative judge,靠 prompt 控制评估方向。把 reward modeling 任务拆成多视角投票,本身就是更强的 ensemble。但要把这个结论推广到"DeCoRL 在端到端推理生成任务上也能压 GPT-4o"------论文没这个证据。
3.3 效率:3.8× 加速 / 72.4% 能耗下降
| Metric | Sequential | DeCoRL | Improvement |
|---|---|---|---|
| Latency (10-step) | 1,202ms | 316ms | 3.8× faster |
| Energy consumption | 142 pJ/op | 39 pJ/op | 72.4% reduction |
| Throughput (QPS) | 18.2 | 30.6 | 68% increase |
| 模块扩展延迟 | N/A | +18% | Minimal impact |
| 加新模块的精度 | N/A | +7.3% | Significant gain |
3.8× 加速对应 9 个并行模块(k=9)下的实测加速比,理论 O(k)O(k)O(k) 上限是 9×。差距哪去了?被 prefill / 模块间 schema 校验 / Φ 聚合吃掉了。这其实挺合理。
72.4% 能耗下降这条我半信半疑。pJ/op 是非常底层的能耗指标,一般得在硬件 profiler 上跑出来。论文没说能耗是怎么测的(NVIDIA NVML?SoC 级别采样?还是按 FLOP 推算?),单凭 "142 → 39 pJ/op" 这个数字很难复现。
68% QPS 提升这个指标是合理的------并行化天然吃满 GPU 利用率。
3.4 消融:贡献奖励是核心
| Variant | RM-Bench | RMB | Latency | Interpretability |
|---|---|---|---|---|
| Full DeCoRL | 80.8 | 0.757 | 316ms | 84.0% |
| 去掉 contribution reward | 76.1 (-4.7) | 0.721 (-4.8) | 316ms | 51.9% (-32.1) |
| 串行执行 | 80.5 (-0.4) | 0.754 (-0.4) | 1,172ms (+271%) | 84.0% |
| Ad-hoc 接口 | 74.3 (-8.0) | 0.698 (-7.8) | 316ms | 63.7% (-20.3) |
| 仅联合优化(去掉 Phase 1) | 77.6 (-4.0) | 0.732 (-3.3) | 316ms | 72.4% (-11.6) |
我把这张消融表反复看了三遍。三个结论:
- 接口标准化的影响(−8.0% RM-Bench)比贡献奖励(−4.7%)还大。这个发现挺反直觉的。论文没大书特书,但我觉得这才是真正的"工程灵魂"------schema 化让聚合函数 Φ 不会因为下游格式漂移而崩,而 ad-hoc 输出会让 Φ 在 5%~10% 的 case 上拼出乱码。
- 串行执行只损失 0.4 个点,说明并行化主要带来效率而非精度。把这两件事正交掉是干净的:accuracy 来自模块化奖励 + 接口标准,efficiency 来自并行 + DRPO。
- Phase 1 模块独立优化贡献 4 个点。这个值得记一下------只跑 Phase 2 联合对齐会让模块间相互抢梯度,先各自练再合奏的设计是有数据支持的。
3.5 可解释性:错误归因从 41% 提到 89%
| 指标 | Sequential | DeCoRL | 变化 |
|---|---|---|---|
| 错误定位准确率 | 61.3% | 84.0% | +22.7 |
| 错误模块识别精度 | 41.2% | 89.3% | +48.1 |
| 平均调试时间(分钟) | 23.4 | 7.3 | −68.8% |
| 奖励归因一致性 (Cohen's κ) | 0.52 | 0.91 | +75.0 |
| 错误归因率 | 38.7% | 10.2% | −73.6% |
| 诊断精度 | 54.1% | 87.6% | +61.9 |
Cohen's κ 从 0.52(中度一致)到 0.91(接近完美一致)这个跨度是实打实的。前提是这套指标的 ground truth 怎么标------论文里没看到详细标注协议(人工标了多少条、标注员多少个、IAA 多少),这是我希望补充材料能补上的关键信息。
4. 我的几条批判性笔记
抓住一些我读完后还在想的事:
第一,"模块拆 9 个"的数字是怎么定的? 论文给了 9 个模块的功能清单(parse / semantic / entity / factcheck / style / quality / compute / verify / integrate),但没回答:为什么不是 6 个?为什么不是 12 个?哪些任务上某些模块基本不被激活?比如 Math 域的 prompt,MstyleM_{\text{style}}Mstyle 和 MentityM_{\text{entity}}Mentity 大概率是没用的。论文没给 module activation 的统计,也没说 contribution reward 在不同域下哪些模块靠近 0。这个数据如果给了,可解释性的故事会更完整。
第二,反事实奖励的计算开销没被认真讨论。 RcontribiR_{\text{contrib}}^iRcontribi 需要把 OfullO_{\text{full}}Ofull 和 Ofull−iO_{\text{full}}^{-i}Ofull−i 都过一遍 RM_φ。9 个模块意味着每个 batch 要做 10 次 RM 推理(1 次完整 + 9 次 ablated)。这在训练阶段是真实开销,论文宣称 3.8× 加速主要是推理时的,训练吞吐量没披露。要复现这套训练,单 epoch 的 RM forward 数量是其他方法的 10 倍。
第三,"22.7% 可解释性提升"这个说法语义模糊。 论文给的具体指标是错误定位准确率从 61.3% 涨到 84.0%(+22.7 个绝对点)。但介绍里写的是 "22.7% improvement in interpretability metrics"------这个表述很容易被读者理解成 22.7% 的相对提升。两者差异不小(绝对 +22.7 vs 相对 +37%)。这种表达模糊是论文写作里很常见的小毛病,但放在评审视角下会被挑出来。
第四,跟 PRM-style 方法的横向对比缺位。 DeCoRL 的核心定位是"过程级 reward + 并行架构"。但论文的对比 baseline 主要是 scalar RM 和 generative judge,没跟主流 PRM 方法(GenPRM、Math-Shepherd、OmegaPRM、ReasonGenRM)正面比较。如果 DeCoRL 真要替代 PRM 范式,应该在 ProcessBench 这类评测上展示自己的优势------但论文里完全没出现 ProcessBench 的数据。
第五,DRPO 对 KL 项的依赖很强但没消融。 损失里那个 η KL(Mi∥Mbase)\eta \, \text{KL}(M_i \| M_{\text{base}})ηKL(Mi∥Mbase) 项是 reward hacking 的最后防线(每个模块都不能跑得离 base policy 太远)。论文没消融 η\etaη 的影响,也没说不同模块用了相同还是不同的 η\etaη。这是 RLHF 类方法里的高敏参数。
第六,"AAAI 2026 接收"这个标签值得认真对待,但也别神化。 论文写得工整、故事完整、效率指标硬,这是 AAAI 这种系统型会议会喜欢的。但学术上的真正贡献度------尤其是相比 DeepSeek-GRM、Critique-RM、ArmoRM 这些更早期的多目标 RM 工作------其实是"工程组合 + 落地验证",不是范式级的突破。
5. 这套思路能给我们的启发
我把它当成一个生产侧 reward modeling 系统的工程模板来看待,不是"通用推理 LLM 的下一代范式"。三条具体启发:
第一,reward 信号的拆分维度比奖励模型本身的容量更重要。同样一个 RM_φ,在 DeCoRL 框架下被复用了 10 次(1 次 full + 9 次 ablated),每次都给一个不同侧面的信号------这本身就是一种"轻量级集成"。
第二,先专精后合奏的两阶段训练协议在多目标对齐里值得复用。无论是 Reflexion / Multi-Agent Debate / 还是这里的 DRPO Phase 1+2,先让模块各自找到稳定点再联合优化,比一上来就联合训要稳。
第三,接口标准化(schema-based)是多模块系统的工程命门。论文把 ad-hoc 接口的精度损失(−8%)量化出来,这是给所有想搞 LLM 模块化协作的人的一颗钉子:JSON schema 别省。
但我也想提醒:DeCoRL 用了 9 个 7B/14B/32B 子模型并行------总参数量其实远高于一个 32B 单体。把"3.8× 加速 + 32B 打 GPT-4o"放在一起说的时候,这个总参数账要单独算清楚。它真正卖的是 latency × 准确率 × 可解释性 这三个维度的 Pareto front,不是参数效率。
读完这篇,我接下来想试的一个东西:把 DeCoRL 的 contribution reward + Cascaded DRPO 思路套在 GenPRM(前一篇我刚解读过,arXiv 2504.00891)的 step-level 训练上------把生成式 PRM 的每一步打分用反事实消融重新校准一下,看看 ProcessBench 上能不能进一步逼近 GPT-4o。这或许是更值得做的事,比把 DeCoRL 整套搬进通用 LLM 训练实在得多。