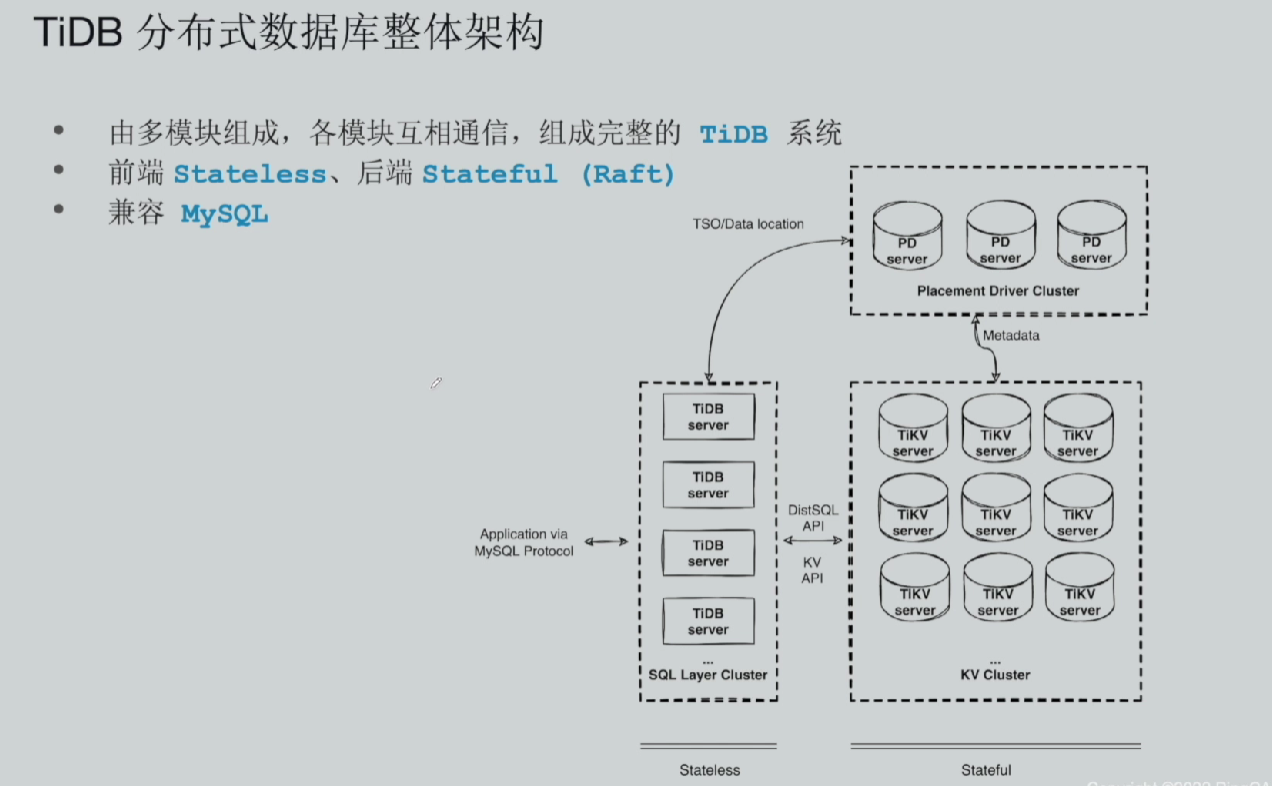
TiDB 是一款兼容 MySQL 协议的分布式关系型数据库,整体架构由 PD 集群、KV 集群、TiDB Server(无状态节点) 三大核心模块组成。三者分工明确、协同工作,依托 Raft 共识算法实现高可用、强一致性与弹性扩缩容,下面从组件功能、实操演示、底层算法、架构优势等维度全面拆解。
一、PD(Placement Driver)集群:集群全局管控核心
PD 是 TiDB 的 "大脑",主要负责存储、管理数据库运行所需的系统级元数据,统筹整个集群的调度、路由与全局管控。在架构交互上,PD 会与上层 SQL 层集群交互时间戳、数据位置信息,同时和下层 KV 集群同步元数据,核心能力分为三部分:
1. TSO(Timestamp Oracle)时间戳授时器
TSO 是实现分布式强一致性事务的核心组件,可直译为时间戳授时器 。TiDB 支持强一致性分布式事务,必须精准判定所有操作的先后顺序。即便数据库无任何数据变更,PD 也会持续生成单调递增的时间戳。当服务端发起事务、执行数据修改时,都需要向 PD 申请最新 TSO。
依靠全局统一的时间戳,分布式集群会形成有序时间流,以此支撑多版本并发控制(MVCC)等事务核心能力。补充说明:此处的 Oracle 仅代表 "权威授时节点",和商用 Oracle 数据库无任何关联。
2. Data Location 数据位置路由
TiDB 服务端执行 SQL 查询时,并不清楚数据的实际存储节点,该路由工作由 PD 全权负责。TiDB 会将数据表的数据行(Row)拆分存储在一个个 Region(数据分片) 中,PD 全局维护映射关系:某条数据归属哪个 Region、该 Region 部署在哪台存储节点。简单来说,PD 就是整个集群的数据路由中心,Region 相关细节后文会详细介绍。
3. Metadata 集群元数据管理
PD 统一管理集群各类管理型元数据。典型场景:在 TiDB 中新建数据表时,表的全局唯一编号由 PD 统一分配。除此之外,数据库对象标识、集群配置等管理类信息,均由 PD 维护。
综上,PD 集群承载 TiDB 所有系统级能力与管控数据;而用户创建的表、索引等业务数据,则全部存储在 KV 集群中。
二、KV 集群:分布式数据存储引擎
KV 集群本质是一套分布式键值(Key-Value)数据库,属于标准 NoSQL 组件,原生提供 KV 读写接口,也是 TiDB 真正落地业务数据的存储层。
上层 SQL 层会将用户输入的 SQL 语句转译为底层 KV 操作,再调用 KV 集群接口完成数据存取。KV 集群本身无法解析 SQL 语法,仅识别键值对格式数据,所有读写操作都基于 Key-Value 实现。
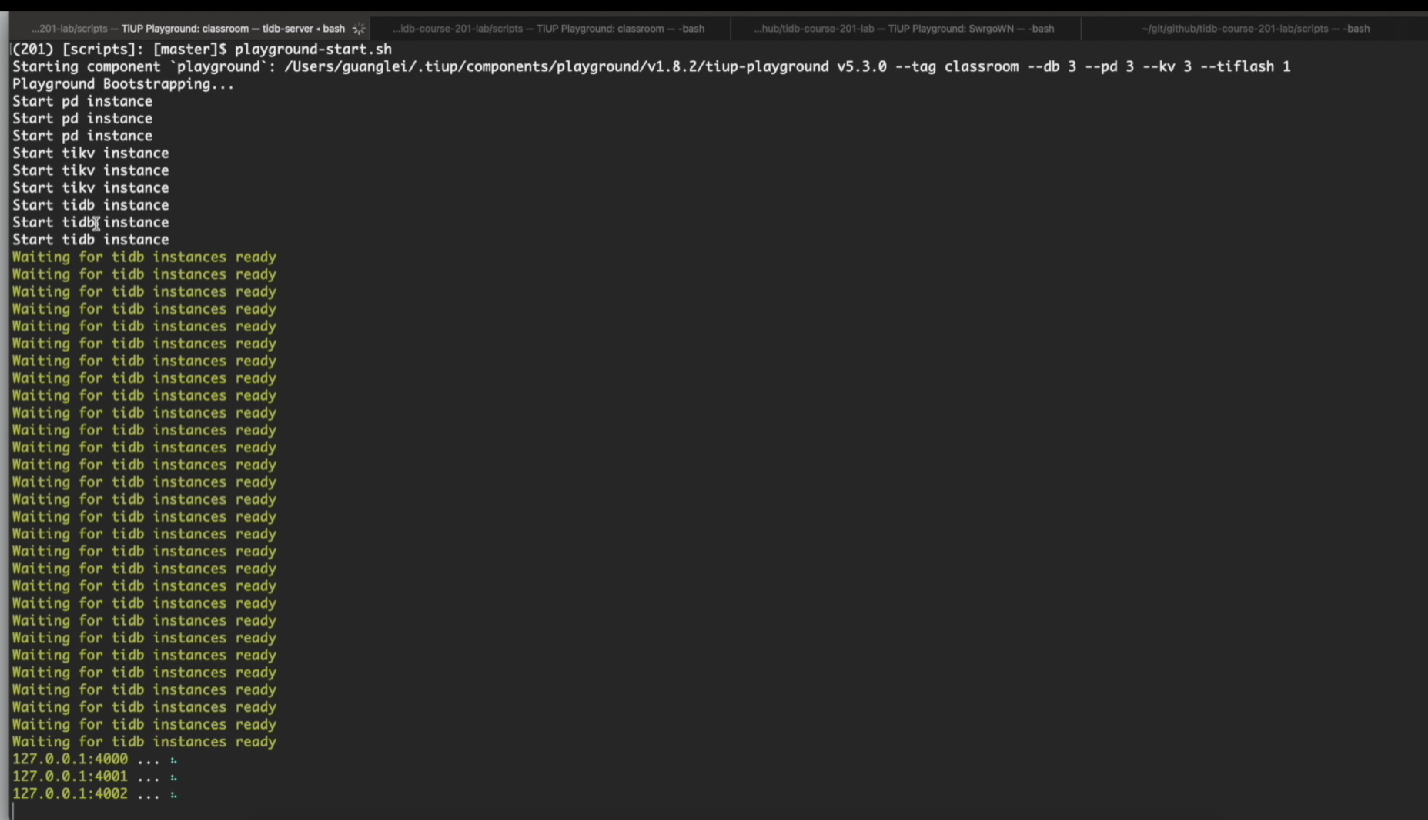
本地环境实操演示
为直观理解 KV 集群的交互逻辑,我们在单机搭建测试环境进行演示:
- 集群部署说明 :本次演示将 PD、KV 部署在同一台机器,方便调试;生产环境严禁混部 ,需将两类组件拆分部署至不同服务器,保障资源隔离与高可用。目前集群所有服务已正常启动。
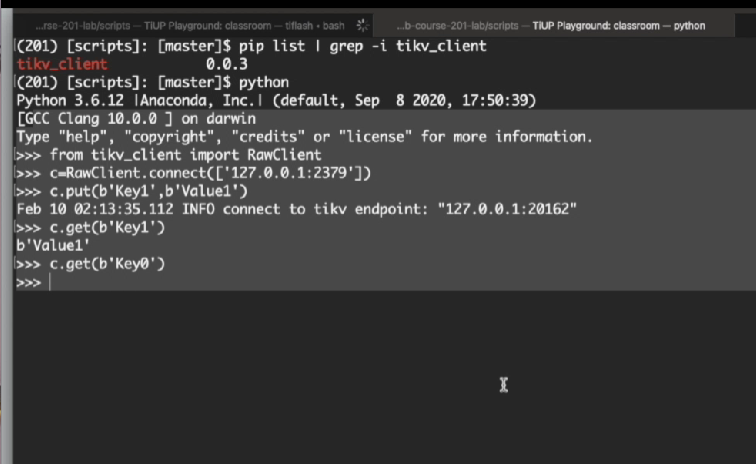
- 客户端使用提醒 :测试使用的 Python 版 KV 客户端模块仅适用于演示场景,功能与稳定性不达标,禁止在生产环境使用。
- 集群连接:调用连接函数时,传入任意一个 PD 节点的访问地址(Endpoint)即可建立连接,多 PD 节点能力对等。
- 数据读写 :KV 集群仅接收字节流(bytes)格式数据。写入时构造 Key-Value 键值对,读取时通过指定 Key 即可查询对应 Value,全程仅基于键值对交互,不识别 SQL。
有状态集群与 Raft 容错算法
PD 集群与 KV 集群都属于 Stateful(有状态)集群 ,节点会在本地磁盘持久化数据。很多人会产生疑问:如果节点宕机、甚至彻底损坏,数据是否会丢失?答案是否定的,核心保障就是 Raft 共识算法。
Raft 是主流分布式共识算法,作用是保证多副本数据的完整性与一致性,核心遵循多数派原则。
1. Raft 在 PD 集群中的应用
生产环境 PD 一般部署 3 个节点,数据默认保存 3 份副本,并分散至所有 PD 节点。
- 角色划分:同一时刻集群内仅有一个 Leader 主节点,其余为 Follower 从节点;
- 写入规则:数据成功写入超过半数节点(3 节点集群至少写入 2 个),即判定写入完成;
- 故障自愈:单个从节点宕机不影响服务;若 Leader 节点故障,剩余存活节点会自动重新选举新 Leader,集群无感知切换。
2. Raft 在 KV 集群中的应用
KV 集群同样使用 Raft 算法,但共识单元不同 :PD 以整节点为单位达成共识,KV 则以 Region(数据分片) 为最小共识单元。
- 分片规则:TiDB 默认单个 Region 大小为 96MB,每个 Region 配置 3 份副本,分散在不同 KV 节点上;
- 角色机制:单个 Region 内部同样区分 Leader 与 Follower,遵循 Raft 多数派原则;
- 灵活配置:KV 集群可包含大量节点,但单个 Region 仅占用 3 台节点存放副本,副本数量支持自定义调整。
分片数量估算
以 100TB 业务数据为例,按照默认 96MB/Region 计算分片总量:单位换算:\(100\ \text{TB} = 100 \times 1024 \times 1024 = 104857600\ \text{MB}\)Region 总数:\(104857600 \div 96 \approx 1092267\)
由此可得:100TB 数据按照默认规则拆分,约产生 109 万个 Region 分片。海量轻量化分片,也是 TiDB 实现数据均衡调度、分布式存储的基础。
三、TiDB Server:无状态 SQL 接入层
TiDB Server 属于 Stateless(无状态)节点 ,也是用户访问数据库的入口。该节点不存储任何系统数据与业务数据,核心职责是对外提供兼容 MySQL 的访问接口。
用户提交的 SQL 语句全部由 TiDB Server 接收,完成语法解析、生成执行计划,并将 SQL 逻辑转译为底层可执行指令,下发给 KV 存储层完成数据读写。
四、TiDB 整体架构优势与扩缩容能力
整套 TiDB 由「有状态 PD+KV 集群」+「无状态 TiDB Server」组成,架构不依赖共享存储,全部使用本地磁盘(Local Storage),所有组件均支持横向线性扩缩容,可根据业务压力灵活调整资源,特性类似微服务架构。
1. 各组件扩缩容规则
- PD 集群 :负载过高时新增节点即可。受 Raft 多数派协议约束,节点总数建议设置为奇数,保证选举与数据一致性正常运行。
- KV 集群:当存储容量不足、读写算力吃紧时,新增 KV 节点即可分担压力,数据会自动完成分片迁移与均衡;Region 副本数同样建议配置为奇数。
- TiDB Server:作为计算接入层,若 SQL 请求量大、响应变慢,直接增加节点;业务低峰、资源闲置时,可下线节点释放资源。
2. 架构设计核心特点
TiDB 整套架构的设计理念处处体现负载均衡思想。我们可以将它理解为一台强化型负载均衡器:在实现分布式数据存储、强一致性事务处理的基础上,原生兼容 MySQL 协议,兼顾分布式数据库的高性能、高可用与传统关系型数据库的使用习惯,这也是 TiDB 最核心的设计亮点。
总结
- PD 集群:全局管控中心,负责授时、路由、元数据管理;
- KV 集群:底层存储引擎,基于键值对存储业务数据,依托 Region 分片 + Raft 算法实现高可用;
- TiDB Server:SQL 接入网关,无状态设计,负责语句解析与请求转发。
三大组件各司其职、配合默契,结合本地存储、线性扩缩容、Raft 强一致性等特性,让 TiDB 成为适配海量数据、高并发场景的主流分布式数据库。
官网资料学习整理,原视频地址如下:
TIDB架构与特点-01TIDB整体架构