一、TiDB 对比传统单机数据库:分布式架构优劣势深度对比

(一)共性:TiDB 同样完整兼容 ACID 与事务一致性
TiDB 虽是分布式数据库,但完整落地 ACID 事务特性,支持 RC、RR 主流事务隔离级别,和传统集中式数据库一样可以保障事务原子性、一致性、隔离性、持久性,业务无需牺牲事务能力换取分布式能力。 依托 PD 全局 TSO 时间戳 + TiKV Raft 多副本 + MVCC 多版本整套机制落地分布式事务,在分布式集群环境下依旧保证数据事务可靠,打破 "分布式数据库很难做标准 ACID 事务" 的固有认知。
(二)核心优势:组件解耦,TiKV/PD/TiDB Server 独立弹性扩缩容
传统集中式数据库所有计算、存储、元数据管控耦合在单机实例中,算力和存储绑定服务器硬件规格; TiDB 采用分层解耦架构:SQL 计算层 TiDB Server、元数据调度层 PD、持久化存储层 TiKV 三者完全解耦,三类组件独立扩容、独立缩容,互不牵制。
- TiKV 存储节点扩缩容 扩容:业务数据量、存储容量、读写吞吐量上涨时,横向新增 TiKV 服务器节点即可,无需更换高配大规格物理机;新增节点接入集群后,PD 自动调度 Region 分片,Raft 自动做数据均衡迁移,数据均匀打散至新节点。 缩容:集群 TiKV 节点资源冗余时,下线多余 TiKV 节点即可,PD 调度 Region 从待下线节点迁移至剩余存活节点,Raft Group 自动重选 Leader、全集群数据重新 Balance,缩容全程业务无感知。
- PD、TiDB Server 同理按需单独增减节点:查询并发暴涨就扩容 TiDB 计算节点;元数据调度压力提升就扩容 PD 节点,资源精细化调配。
(三)高可用进阶:原生 Raft 副本机制,支持同城 / 跨地域机房容灾
- 本地机房高可用 TiKV 默认 Raft 三副本架构,单个 Raft Group 容忍单副本节点宕机,剩余过半副本正常提供读写,单台 TiKV 故障自动重新选举 Leader,上层业务无感,原生自带多副本高可用,不用依赖第三方备份、主从切换脚本实现高可用。 传统库主流靠主从架构,主库故障需人工 / 半自动化切换从库,切换过程大概率短暂断写,容灾运维成本更高。
- 跨地域异地容灾落地 依托节点灵活部署特性,可将 PD、TiKV 副本分散部署在不同城市、不同云可用区、不同 IDC 机房,依托优质骨干网络实现跨地域多副本:常规同城多活副本部署同城不同机房;异地灾备配置部分副本异步跨地域部署,实现区域级故障容灾。 落地实例:头部大型云厂商客户落地跨地域部署最佳实践,曾遭遇云厂商单可用区整体区域性故障,因 TiKV、PD 节点打散在多个地域机房,集群核心数据不受影响,核心业务全程不停服、无下线,是传统集中式数据库很难低成本实现的架构能力。 补充新理念:超大体量业务场景下,TiDB 依靠全域多副本实时冗余,天然实现 "全时在线热备份",大型客户直接取消定时全量备份作业,省去海量数据定时备份、故障后耗时冗长的数据还原成本,是分布式架构带来的运维革新。
(四)横向水平扩展:区别于传统库纵向升级的扩容逻辑
TiDB 采用横向加节点(Scale Out):存储空间不足、读写吞吐上涨,直接往集群新增普通 X86 服务器,依靠 Region 分片打散数据,集群整体容量与性能线性提升,硬件选型灵活、采购落地简单。 传统集中式库依赖纵向升配(Scale Up):性能瓶颈只能升级服务器 CPU、内存、硬盘,不断更换更高规格小型机 / 高配物理机,硬件成本指数级上涨,且单台服务器硬件存在物理性能天花板,数据体量到达单机上限后无法继续扩容。 传统数据库即便借助中间件做分库分表实现伪分布式扩容,也需要业务层改 SQL、改分表逻辑、维护分片规则,跨分片事务、跨分片聚合查询缺陷突出,和 TiDB 原生分布式透明分片不在同一层级。
(五)设计取舍:性能短板与适用场景边界
TiDB 为海量数据、高并发吞吐设计,架构天然存在跨组件网络交互开销:一条主键单行增删改查,需要 TiDB Server→PD 查路由→多 TiKV 节点 Raft 副本同步,链路涉及多层网络通信;而传统单机数据库所有数据在本地磁盘,无跨机网络损耗,小数据量、高频单行简单 SQL 场景,传统单机库响应延迟更优。
选型总结 业务数据体量小、SQL 以单行简单 CRUD 为主:优先传统单机关系型数据库,发挥低延迟优势; 数据 PB 级、大表海量数据、高频大批量写入、报表大范围聚合查询、需要跨地域多活容灾:TiDB 分布式架构优势完全释放,完美解决传统库容量与性能天花板痛点。
二、共享存储集群深度剖析:伪分布式架构对比 TiDB 原生分布式
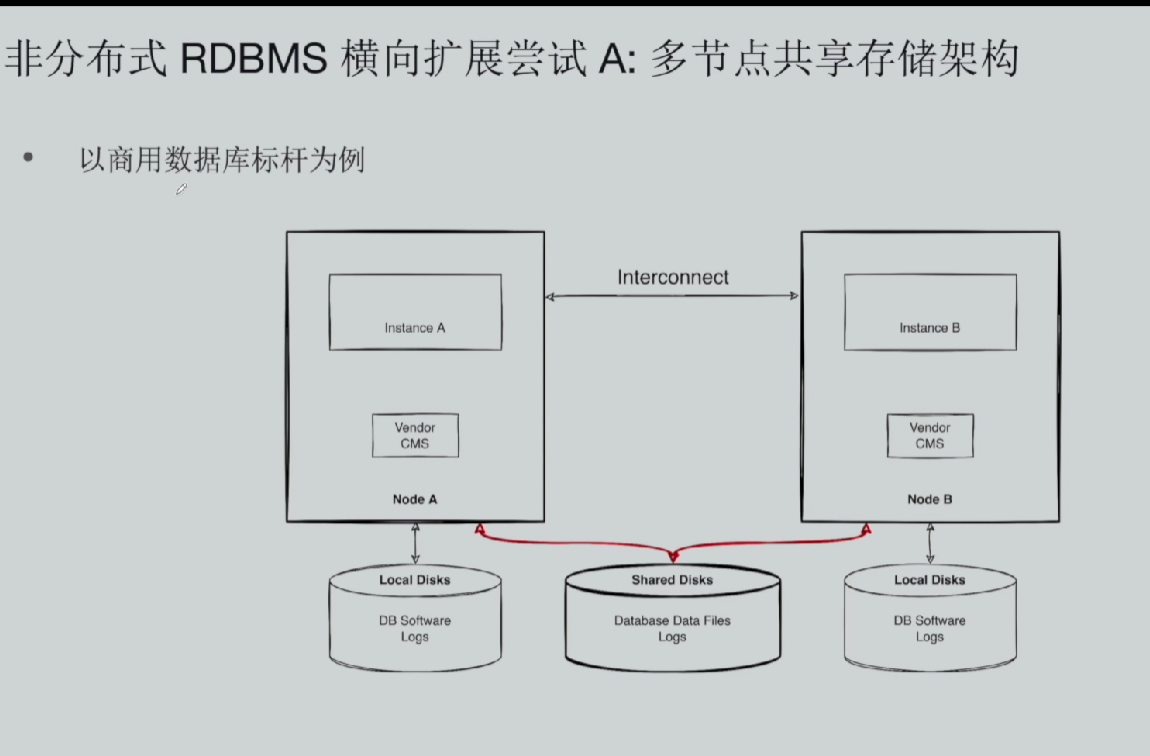
(一)共享存储集群表层表现:看似横向扩容
这类商用集群部署形态:节点 A 资源容量不足时,新增节点 B,数据库实例可同时运行在 A、B 两台服务器,节点对等,客户端 Session 既能访问节点 A,也能接入节点 B;后续业务扩容还能持续新增节点,从服务器硬件层面看实现了机器横向扩容,外在表现和分布式集群高度相像。 但仅停留在计算节点横向叠加,底层存储、内核执行逻辑依旧是单库架构,无法从数据、锁、缓存、存储粒度完成分布式改造。沿用传统数据库多年内核设计:行锁管理、缓冲区 Cache、数据页管理全是单实例逻辑,整套集群本质是多台服务器共用一套底层存储,把多个物理节点虚拟成单个数据库内核运行,行业俗称 "多节点、单内核" 架构。 节点之间依靠昂贵高速互联链路(Interconnect)同步内存缓存数据、锁信息,配套整套高端共享块存储设备,不管新增多少台服务器,底层数据文件统一存放在共享存储中,所有节点读写落地同一份存储介质。
(二)共享存储集群三大先天短板
-
硬件投入成本极高,投入产出比(ROI)偏低 节点间高速互联专线造价高昂,节点越多,互联组网成本线性上涨;核心数据依托高端集中式共享块存储,高端存储机柜、磁盘阵列、双控冗余设备采购与维保费用远高于普通 X86 本地磁盘。整套架构为了实现 "多节点虚拟单库" 付出巨额硬件开销,资源投入性价比远低于 TiDB 基于普通服务器 + 本地磁盘的分布式方案。
-
天然存在集中式单点故障与硬件瓶颈 共享存储是硬性单点故障源(SPOF):所有业务数据统一存放在共享存储,哪怕前端计算节点扩容至几十台,一旦共享存储阵列、存储控制器、存储链路故障,全集群数据库整体瘫痪,前端再多对等节点也无法挽救业务。 经典案例:Netflix 早年故障,奈飞 2010 年在线业务采用该商用共享存储集群架构,一次共享存储固件升级失误直接造成整套存储宕机,前端大量计算节点全部闲置,核心业务连续停机 48 小时;集群本地磁盘仅存放日志、临时文件,核心业务不落地本地盘,无法用来故障兜底。 共享存储极易成为性能瓶颈:TiDB 的性能热点大多源于业务侧数据热点,可通过 PD 调度 Region 迁移、拆分分片打散热点;但共享存储集群往往还未出现业务数据热点,集中式存储 IO、控制器就先达到性能上限,想要缓解只能采购更高规格存储,成本持续攀升。
-
并非真正分布式,扩容治标不治本 该架构只是在计算层堆砌节点,存储层没有分片、没有数据副本打散,没有 Region、Raft 这类分布式数据分片与多副本机制。扩容只能提升并发连接、SQL 计算能力,无法突破底层共享存储的容量上限与 IO 瓶颈。从数据库内核本质来看,属于集中式数据库套上集群外壳,看似横向扩展,内核仍是单点集中式逻辑。
(三)对照 TiDB 原生分布式核心区别
存储形态不同:TiDB 的 TiKV 数据全量落地各节点本地磁盘,无集中共享存储,数据按 Region 分片打散在全集群不同服务器; 故障域拆分不同:TiDB 依靠 Raft 多副本跨机器冗余,单台 TiKV、单机房故障依靠副本自动切换,不存在全局统一存储单点; 扩容逻辑不同:TiDB 新增节点后 PD 自动迁移 Region,数据均匀重分布,存储、算力同步扩容;共享存储集群加节点仅扩充计算资源,存储容量与 IO 上限仍被集中存储锁死; 硬件成本不同:TiDB 通用 X86 服务器 + 普通 SATA/NVMe 磁盘即可部署,无需昂贵高速互联与高端集中存储,大规模部署成本优势显著。
小结 共享存储集群是集中式数据库的集群化改良方案,优化了前端计算并发能力,但没有颠覆底层集中存储架构,受单点存储束缚;而 TiDB 从数据分片、副本管理、存储落地全链路原生分布式设计,从根源规避集中式架构的单点与扩容瓶颈,这也是海量互联网、政企大客户选择 TiDB 承载超大业务的关键原因。
三、手动分库分表痛点解析 & TiDB 自动化分片方案 + 集群部署指南
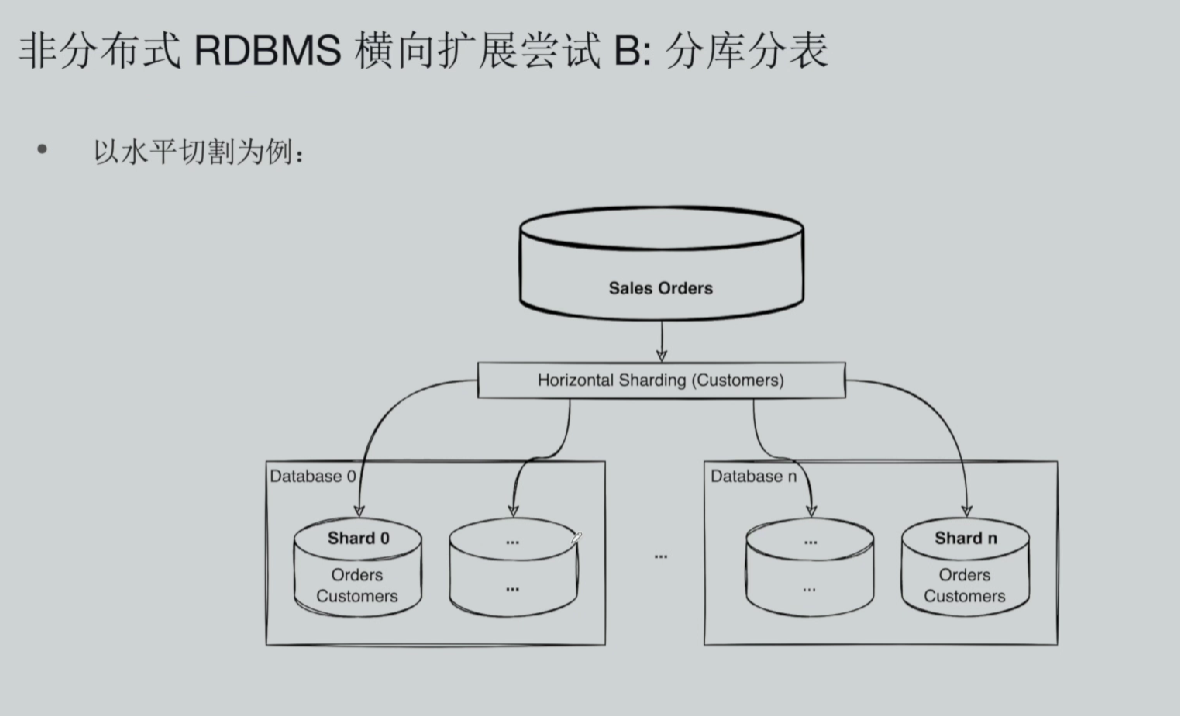
(一)手动水平分库分表的落地思路
业务痛点:单张大表(如 sales_order 订单表、客户表)数据量暴涨,单实例数据库硬件上限扛不住存储与 IO 压力。 落地方式:按业务字段做数据切割,常用拆分维度:客户编号、客户归属地域、订单 ID 哈希等规则;原本一张逻辑大表,被拆分至数十上百套互相独立的物理数据库实例,每个实例只承载一部分分片数据,物理库之间完全隔离、独立部署。 从硬件层面:新增服务器就能新增分片库,看似实现了横向扩容;从底层架构:各分片 DB 之间无互联心跳链路、无共享存储,分片库彼此互相隔离,感知不到其他分片存在。
(二)手动分库分表四大致命痛点
-
分片路由逻辑下沉,业务代码改造代价极高 整套分片规则没有中间件或数据库内核接管,数据落在哪个库、哪张表,全部由应用代码自行维护。开发需要在代码里硬编码分片路由规则,新增分片键、调整拆分逻辑都要改代码、全量发布,业务迭代成本陡增。
-
运维成本(OPS)居高不下,缩容几乎无解 扩容:新增分片节点尚可新建独立库;缩容:下线服务器需要把对应分片数据合并迁移至剩余库,海量数据迁移、数据合并工程量极大,线上落地难度极高。 实战案例:部分企业拆分出近 140 套数据库,其中 1/3 为主写库、2/3 只读从库,运维复杂度指数级上升,运维团队负担沉重。
-
跨分片 SQL 能力退化,弱化关系型数据库能力 需要跨全部分片做聚合、关联、统计、DDL 变更时,数据库原生无法跨库执行,只能逐个连接所有分片库单独执行 SQL,再在应用层内存汇总结果。分片越多,SQL 易用性越差,硬生生把关系型 MySQL/Oracle 改造成了伪 NoSQL,丢失 SQL、事务、关联查询原生优势,陷入 "何苦不用原生 NoSQL" 的尴尬局面。
-
分布式事务天然短板 跨分片数据更新无法使用数据库原生事务,想要保证跨分片一致性需要业务手动做分布式事务补偿、回滚逻辑,极易出现数据不一致、脏数据。
(三)TiDB 原生 Region 自动分片:从内核规避分库分表弊端
TiDB 对应用完全屏蔽底层分片细节,开发者只需要像使用传统 MySQL 一样编写标准 SQL,底层分片、数据搬迁全由 PD+TiKV 自动完成:
- 自动分片:数据按 Key 范围自动切割成 Region,无需开发指定分片字段、不用在应用写路由逻辑;
- 自动化扩缩容均衡 扩容 TiKV 节点:PD 自动调度 Region 从存量节点迁移至新节点,全集群数据自动重平衡; 缩容下线 TiKV 节点:PD 自动把待下线节点上所有 Region 迁移到集群剩余节点,Raft 同步完成均衡,全程业务无感知;
- 完整 SQL 能力保留:跨分片关联查询、聚合、事务由 TiDB 计算层统一处理,上层业务沿用标准 SQL,不会退化成 NoSQL 使用形态;
- 原生分布式事务:依托 TSO+MVCC+Raft,跨 Region 分布式 ACID 事务数据库原生支持,不用业务额外开发补偿逻辑。
四、落地佐证:海量企业客户落地验证
目前大量政企、互联网行业客户在核心 / 非核心业务替换原有分库分表架构落地 TiDB,网上可检索大量客户实战分享、落地白皮书,真实业务场景落地案例充分验证 TiDB 原生分布式分片方案的落地价值。
五、TiDB 三种集群部署方案
讲完架构原理与竞品对比后,进入实操环节,TiDB 集群搭建一共分为本地测试部署、标准生产集群部署、公有云托管部署三类方案,全部配套官方完备文档,可直接参照落地。
-
非生产环境:单机本地测试集群部署 适用场景:个人学习、功能验证、课堂练习,不用于线上业务。 支持操作系统:Linux、MacOS;特点:一键快速拉起轻量化 TiDB 测试集群,部署链路简短、依赖少,几分钟即可完成实例启动;定位:仅用于功能测试、SQL 练习,硬件与架构不满足生产高可用规范。
-
生产级:标准集群本地自建部署 适用场景:企业私有化机房落地正式业务,生产环境标准方案。 系统约束:仅主推 Linux 操作系统;前置要求:部署前需要核对软硬件环境规格,官方提供配套环境预检脚本,可批量自动化校验服务器资源、系统参数、端口、磁盘配置等前置条件;落地流程:按照官方文档分步执行,规范化部署 TiDB Server、PD、TiKV 三类组件,构建符合 Raft 多副本规范的高可用生产集群,步骤严谨、配置项齐全。
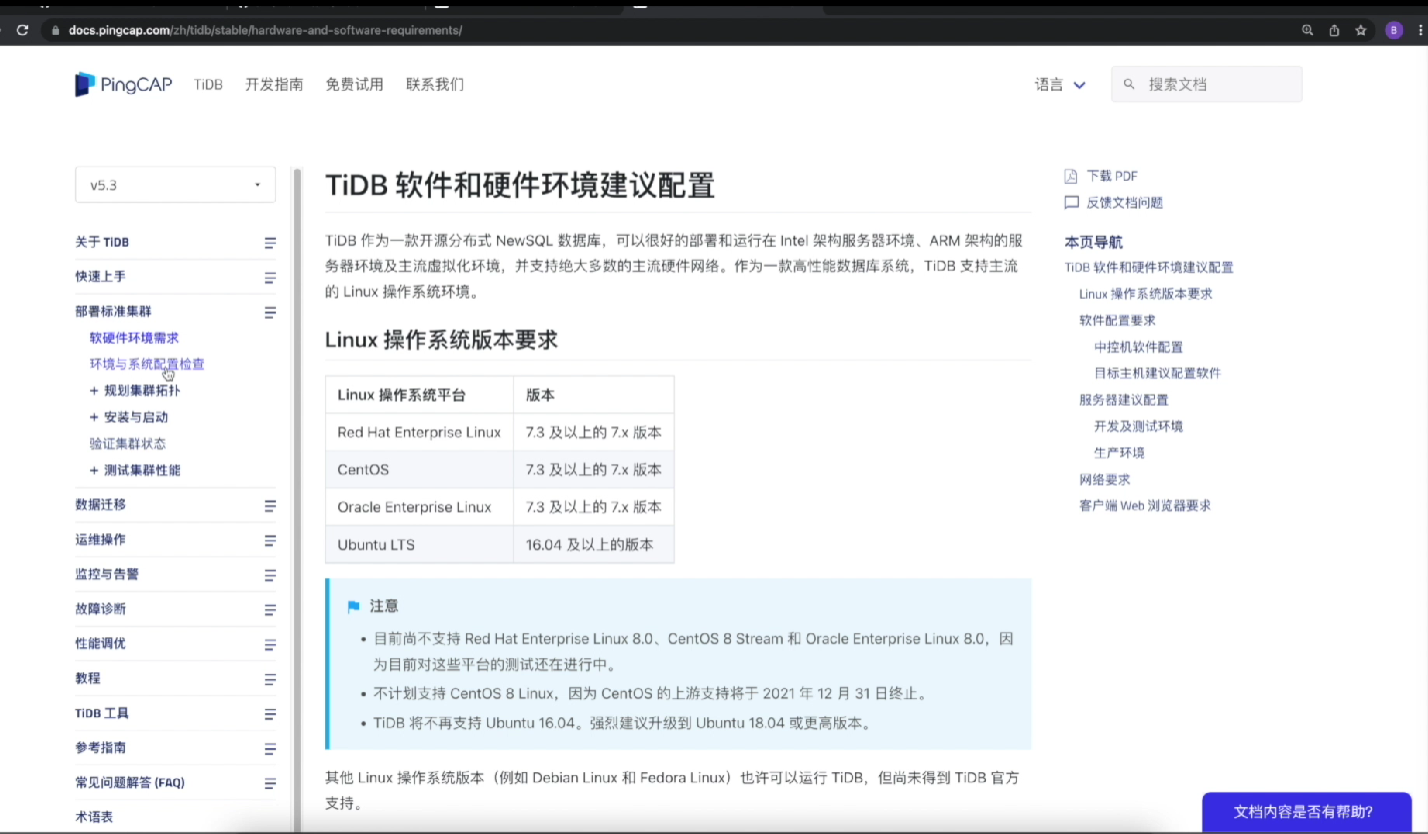
-
云端托管部署 适用场景:云上业务快速上线、免去底层集群运维成本。依托各大公有云 TiDB 托管服务,开箱即用,无需自主采购服务器、手动运维集群,在云控制台即可一键创建、弹性扩缩 TiDB 实例。