重生之我在 Vibe Coding 时代当程序员:第十一课,变量提升真相
上一篇 重生之我在 Vibe Coding 时代当程序员:第十课,var、let、const:ES6变量声明的革命重生 掘金 我刚把
var、let、const的区别捋了一遍:ES6 为什么要补上块级作用域,为什么现在写代码尽量不用var。这次我顺着一些线上网课、技术资料和自己的复盘继续往下挖:如果我在变量声明之前就使用它,JS 到底会发生什么?为什么有时候是
undefined,有时候能正常调用函数,有时候又直接报错?
这篇笔记的主题是 JavaScript 执行原理里的变量提升(Hoisting)。
按照我们之前学习其他编程语言的通识,代码应该是"一行一行往下执行"。但资料里的例子会直接打破这个直觉:代码确实在执行阶段按顺序执行,可是在真正执行之前,JS 引擎还会先做一轮准备。也就是笔记里反复出现的几个词:
- 编译阶段
- 执行阶段
- 执行上下文
- 变量环境
- 词法环境
- 调用栈
- 作用域链
这张图先把整条主线压成一个最小模型:一段 JavaScript 代码不是直接冲进执行结果,而是先经过编译阶段,再进入执行阶段。后面所有关于 undefined、函数声明、TDZ 的问题,本质上都在解释"编译阶段到底准备了什么"。

这次复盘真正要解决的问题不是或者说不仅仅是"变量提升是什么意思",而是明白"变量提升会有什么效果"具体点就是:当我看到一段声明前使用变量或函数的代码时,我怎么判断它到底输出什么。
从 showName 和 myName 开始
我一开始整理的是这个例子:
js
//函数的声明被提升
showName();
console.log(myName);
console.log(add);
var myName = '极客时间';
//传统函数声明
function showName() {
console.log('My name is ' + myName);
}
//函数是一等对象
//该函数声明类似变量的声明
//匿名函数 函数表达式 JS独有的声明方式
//用函数表达式来声明函数,就是普通变量,所以通过变量提升,可以在声明前调用(不传入参数)
var add = function(aa, bb) {
return aa + bb;
}这里表面上看很违反直觉:
js
showName();
console.log(myName);
console.log(add);这三行都写在声明之前。按照"代码一行行执行"的朴素理解,它们应该全部报错。可是实际不是这样。
showName() 可以在函数声明之前调用,因为函数声明会在执行前被处理好。console.log(myName) 不会报"变量不存在",而是输出 undefined,因为 var myName 的声明提前被放进了当前作用域,但赋值 '极客时间' 还没有执行。console.log(add) 也是 undefined,因为 add 是用 var 声明的变量,真正的函数对象要等执行到赋值语句时才会放进去。
这里我需要修正原注释里一句容易误导的话:函数表达式不是"可以在声明前调用"。更准确地说是:
text
var add 会被提升为 undefined。
在赋值前读取 add,得到 undefined。
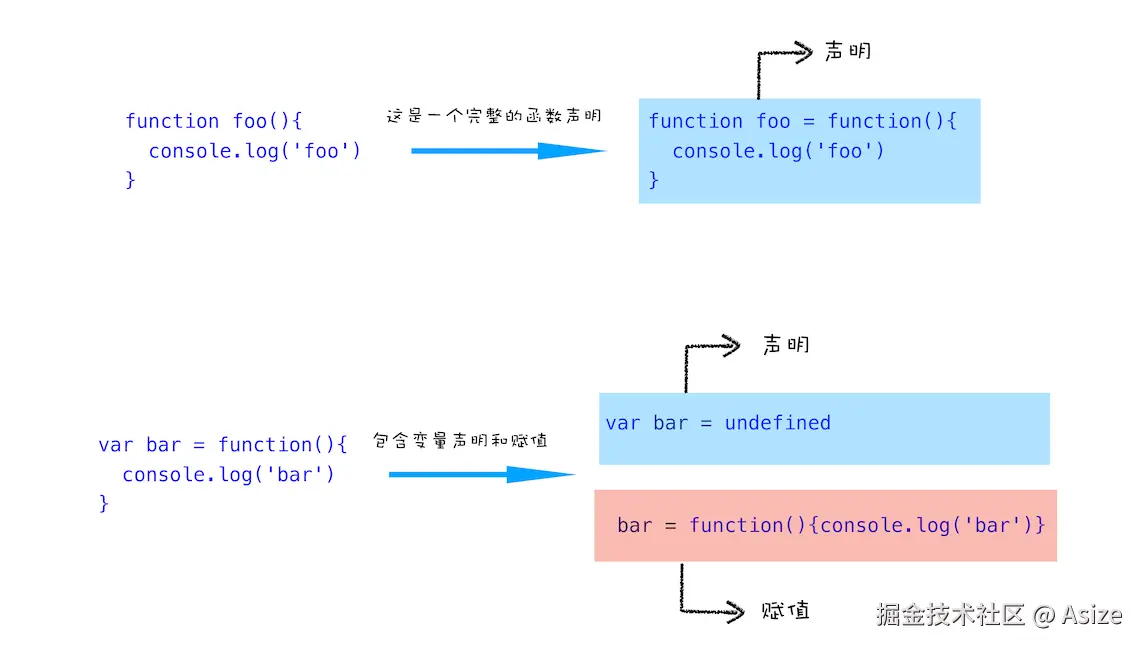
在赋值前调用 add(),会因为把 undefined 当函数调用而报 TypeError。所以这篇笔记第一条主线就是:函数声明和函数表达式不是一回事。 这张图适合用来校准一个最容易混的点:上面是完整函数声明,声明阶段就能拿到函数对象;下面是函数表达式,var bar 先只是声明并初始化为 undefined,真正的函数对象要等赋值语句执行时才进入 bar。
如果没有变量提升会怎样
我在资料里整理了一个"传统假设":假如 JS 不支持变量提升,代码就完全按照书写顺序执行,那么 1.js 里的 myName 和 showName() 都会报错。
但真实的 JS 不是这样。
这部分资料可以总结成:
- 在执行过程中,如果使用了未声明的变量,会报错。
- 在一个变量声明之前使用它,不一定会报错,但该变量的值为
undefined,而不是声明时的值。 - 在一个函数声明之前使用它,不会出错,因为函数声明会被提升,而且函数可以正常执行。
这说明 JS 代码不是只有执行阶段。它在执行前还有一个准备阶段。通常会把这个准备过程称为"编译阶段",也就是 JS 引擎先为后面的执行准备好执行上下文。
这里的关键不是说 JS 真的把代码文本移动到了文件最前面。更准确的理解是:变量声明、函数声明会在执行前被 JS 引擎处理,放进对应的执行上下文里。代码的位置没有物理移动,只是运行环境已经提前知道了某些名字的存在。
1.html:函数内部也会创建自己的执行上下文
我整理的 1.html 是这个样子:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
//编译阶段 准备好作用域 global{} 对象
showName();
console.log(myName);
function showName() {
//编译阶段二 为showName 执行而准备
var myName = '极客时间';
console.log('My name is');
}
</script>
</body>
</html>这段代码里有两个层次。
第一层是全局脚本。执行前,JS 会先准备全局执行上下文。全局里有一个函数声明 showName,所以第一行 showName() 可以执行。
第二层是函数调用。当 showName() 被调用时,JS 又会为这个函数调用准备一个新的函数执行上下文。函数内部的:
js
var myName = '极客时间';属于 showName 函数自己的作用域,不是全局作用域。
所以外面的:
js
console.log(myName);并不能读到函数里面的 myName。这也把作用域链的概念带出来了:变量不是写在代码里就到处都能访问,它属于某个作用域。
2.html:函数声明和函数表达式
2.html 把两种函数写法放在一起对比:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
// var myName = undefined;
// myName = '极客时间'
var myName = '极客时间';
//完整的函数声明,没有涉及赋值操作
function foo() {
console.log('foo');
}
//函数表达式,涉及赋值操作
//只有在赋值操作时,才会将函数声明提升到作用域顶部
var bar = function() {
console.log('bar');
}
</script>
</body>
</html>这里我把它拆成两类:
第一类是完整函数声明:
js
function foo() {
console.log('foo');
}它没有"先声明变量、后赋值函数对象"的过程。函数声明在准备阶段会直接让 foo 这个名字绑定到完整的函数对象。所以在函数声明前调用 foo() 是可以的。
第二类是函数表达式:
js
var bar = function() {
console.log('bar');
}这其实分成两件事:
text
1. 声明变量 bar
2. 把一个函数对象赋值给 bar在执行前,var bar 会被处理成 undefined。但右边这个函数对象要等执行到赋值语句时才会放进 bar。所以在赋值之前:
js
console.log(bar); // undefined
bar(); // TypeError这就是我之前最容易混的地方:读取函数变量 和 调用函数变量 不是一回事。
手动模拟变量提升
3.js 是我手动模拟提升之后的样子:
js
var myName = undefined;
// 再次强调 var声明的变量的提升 既有声明也有赋值操作,但是赋值会在执行阶段执行
// 而 非函数表达式函数,提升只有声明这一步,因为声明就会将函数(包括函数体)提升到作用域顶部,没有赋值这一步,也不需要等到执行阶段
function showName() {
console.log('showName 被执行了');
}
showName();
console.log(myName);
myName = '极客时间';这段代码很好,因为它把"看不见的准备阶段"显性化了。 这张图把"提升"这个抽象词拆成了两块:上半部分是执行前被准备好的声明,下半部分才是按顺序执行的代码。看这张图时,我主要看颜色分层:var myname = undefined 和 function showName() 属于准备好的部分,myname = '极客时间' 这种赋值语句仍然留在执行阶段。
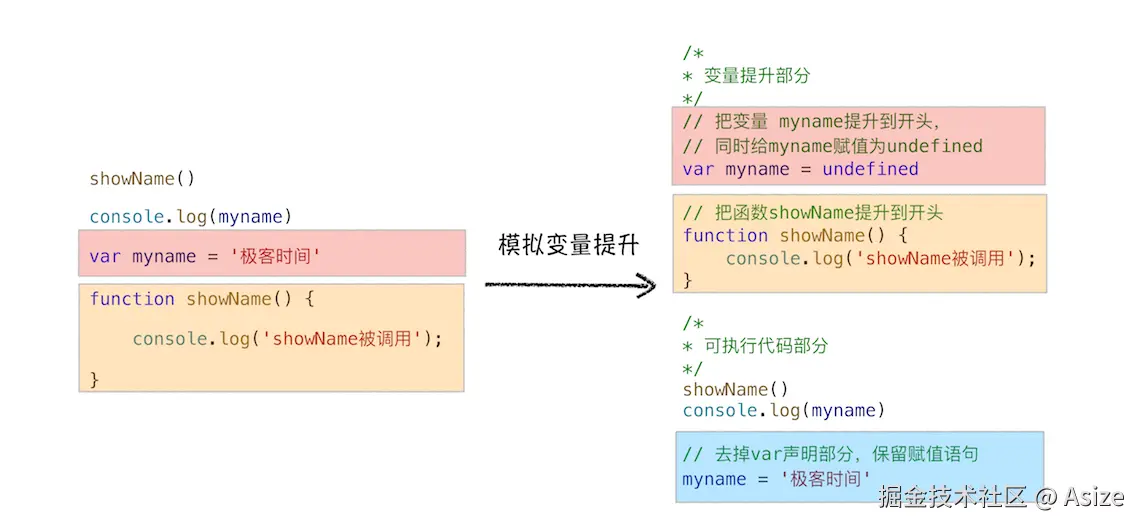 原始写法可能是:
原始写法可能是:
js
showName();
console.log(myName);
var myName = '极客时间';
function showName() {
console.log('showName 被执行了');
}但从执行上下文的角度看,可以理解成执行前先准备好:
js
var myName = undefined;
function showName() {
console.log('showName 被执行了');
}然后执行阶段再按顺序跑:
js
showName();
console.log(myName);
myName = '极客时间';这个拆分也正好对应 4.js 和 5.js。
4.js:变量提升部分
我把变量提升部分单独拆成了 4.js:
js
// 变量提升部分的代码
var myName = undefined;
function showName() {
console.log('showName 被执行了');
}这部分代表执行前已经准备好的东西。
var myName 已经存在,但值是 undefined。showName 已经存在,而且是完整的函数对象。
这能解释为什么:
js
console.log(myName);不是"找不到变量",而是读到了 undefined。
也能解释为什么:
js
showName();可以在函数声明前执行。
5.js:执行阶段代码
5.js 则是执行阶段:
js
// 执行阶段代码
showName();
console.log(myName);
myName = '极客时间';到执行阶段,代码才真正按顺序执行。
所以 showName() 先执行,console.log(myName) 读到的是之前准备好的 undefined,最后才执行赋值:
js
myName = '极客时间';这也解释了为什么变量提升会影响可读性:我眼睛看到赋值在后面,但程序执行时这个名字已经提前存在了。对于学习者来说,这很容易造成"代码书写顺序"和"运行时状态"不一致的感觉。
变量环境和词法环境
技术资料里还会进入一个更底层的区分:
text
VariableEnvironment:
myname -> undefined,
showName ->function : {console.log(myname)}这里的 VariableEnvironment 可以先理解成:用来保存 var 声明和函数声明等内容的环境。
再看 6.js:
js
// var 提升:声明和初始化一起完成,放入变量环境,值为 undefined,可直接访问
// let 提升:声明提升但初始化不提升,放入词法环境,处于暂时性死区(TDZ),声明前访问报错
// 代码执行时候,分支
// 在变量环境中的可以在声明前执行
// 在词法环境中的不可以声明前执行
// 变量提升的本质 是在编译阶段就完成了变量(包括函数)的内存地址的分配
// 代码执行阶段是按照顺序执行
console.log(myName);//词法环境
let myName = '极客时间';这段代码的结果是 ReferenceError。
这里要修正一个我以前很容易写错的说法:不能简单说 let 不提升。更准确是:
text
let 声明也会被放入当前词法环境。
但是在执行到 let 声明语句之前,它没有完成初始化。
这个阶段叫暂时性死区(TDZ)。
在 TDZ 中访问变量,会报 ReferenceError。所以 var 和 let 的关键差异不是"有没有提升",而是:
text
var:声明和初始化一起完成,初始值是 undefined。
let:声明被记录在词法环境里,但初始化要等执行到声明语句。因此:
js
console.log(myName);
let myName = '极客时间';不会像 var 那样输出 undefined,而是直接报错。
执行上下文:编译阶段准备什么
我把这里整理成一句话:
输入一段代码,经过编译之后会生成两部分内容:执行上下文和可执行代码。 如果只看文字,"执行上下文"很容易变成一个空泛名词。这张图的作用是把它具体化:输入代码先被编译,编译后形成执行上下文和可执行代码;执行上下文里又可以继续拆成变量环境和词法环境。这样我才能理解为什么
var和let在声明前表现不同。
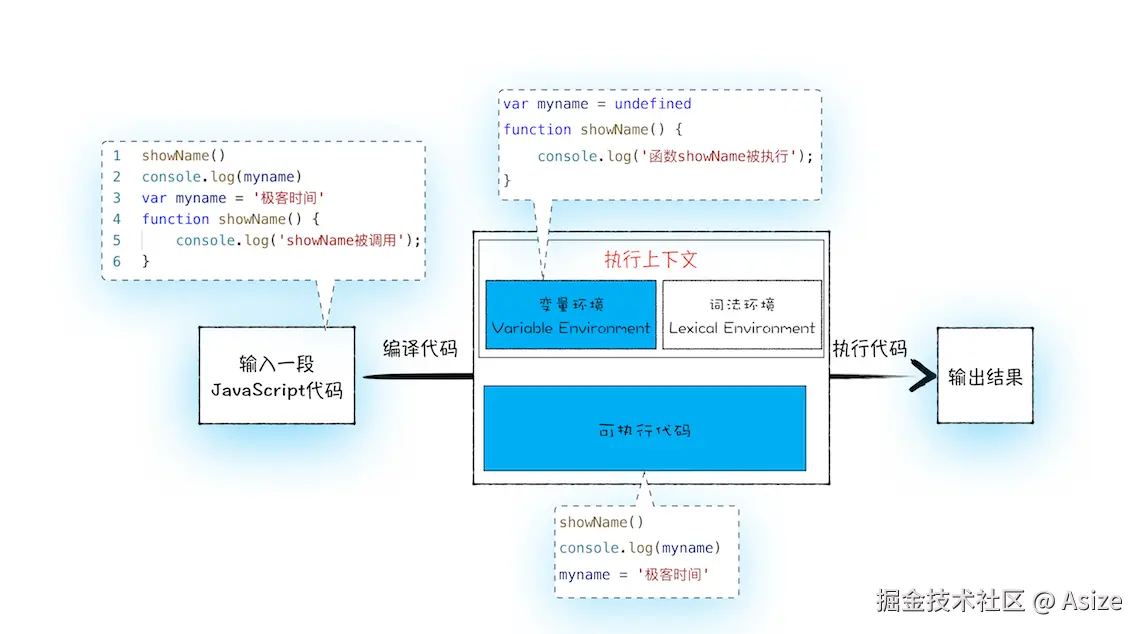 这个说法对我来说很关键。
这个说法对我来说很关键。
JS 执行一段代码时,不是拿到代码就直接从第一行跑到最后一行。它会先创建当前代码的执行上下文。执行上下文可以理解成这段代码运行时需要的环境,里面会有变量环境、词法环境等信息。
调用一个函数时,也会进入这个函数自己的上下文。也就是说:
text
全局代码执行 -> 全局执行上下文
函数被调用 -> 函数执行上下文
函数里再调用函数 -> 新的函数执行上下文这些上下文的进入和退出,后面就会和调用栈联系起来。
这一篇的重点还不是把调用栈画得多完整,而是先知道:每次函数调用都不是在原地随便执行一下,而是会创建新的运行环境。
作用域链:变量到底从哪里找
我原来的资料里有一个标题是"作用域链",虽然正文还没有展开太多,但它和变量提升其实是绑在一起的。
变量查找不是全局乱找,而是按作用域链查找。基本规则是:
text
先在当前作用域找。
当前作用域找不到,再去外层作用域找。
一直找到全局作用域。
全局还找不到,就报错。所以 1.html 里的这个代码:
js
function showName() {
var myName = '极客时间';
console.log('My name is');
}函数内部的 myName 是函数局部变量。外面的:
js
console.log(myName);不会进入函数里面找变量。只有函数被调用时,函数自己的执行上下文才会被创建,里面的局部变量才属于那个函数调用。
这也提醒我:看变量输出结果时,不能只看名字一样不一样,还要看它属于哪个作用域。
最后这张图可以当成做题前的提醒:遇到 var myname = '极客时间',不要把它看成一个不可拆的整体。它可以被理解成"声明"和"赋值"两段,声明先让变量变成 undefined,赋值要等执行到那一行才发生。
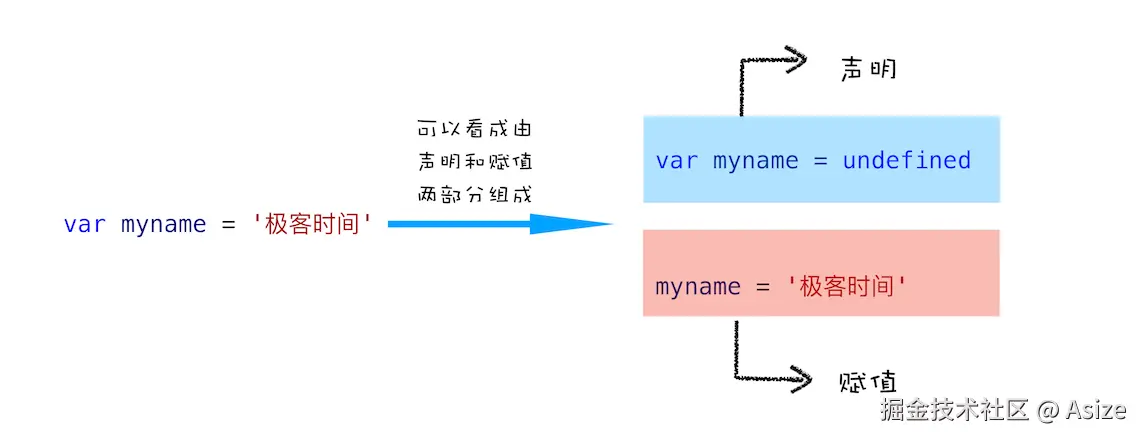
我现在怎么判断 hoisting 题
经过这次复盘,我现在判断变量提升题,会先问三个问题:
第一,这个变量/函数是怎么声明的?
text
var
let
const
function 声明
var 函数表达式第二,当前代码是在读取它,还是调用它?
js
console.log(foo); // 读取
foo(); // 调用第三,当前执行到这里时,它在执行上下文里的状态是什么?
text
var:已经初始化为 undefined
function 声明:已经是函数对象
var 函数表达式:赋值前是 undefined
let / const:声明前处于 TDZ,访问会 ReferenceError这样看,前面的几个例子就能串起来了。
var:
js
console.log(myName);
var myName = '极客时间';输出:
text
undefined函数声明:
js
showName();
function showName() {
console.log('showName 被执行了');
}输出:
text
showName 被执行了函数表达式:
js
add();
var add = function(aa, bb) {
return aa + bb;
}结果:
text
TypeError因为 add 在赋值前只是 undefined,不是函数。
let:
js
console.log(myName);
let myName = '极客时间';结果:
text
ReferenceError因为 myName 在词法环境中已经存在,但还处于暂时性死区。
这篇笔记对 Vibe Coding 的意义
这篇笔记看起来很"基础",甚至有点绕:编译阶段、执行阶段、变量环境、词法环境、TDZ。可是越是在 AI 可以快速生成代码的时代,这种底层判断反而越重要。
AI 很容易写出一段"看起来像 JS"的代码,但如果我不知道变量什么时候是 undefined,什么时候是 ReferenceError,什么时候又是 TypeError,我就只能把错误信息丢回给 AI,让它继续猜。
而这次复盘真正让我拿到的能力是:看到一段声明前使用变量或函数的代码时,我可以自己判断:
text
这个名字有没有被当前作用域记录?
它现在有没有完成初始化?
它现在的值是不是函数对象?
这行代码是在读取它,还是调用它?这比背"变量提升"四个字有用得多。
所以这一篇的结论不是"JS 很怪",而是:JS 的执行不是只看书写顺序,还要看执行前的上下文准备。只要把准备阶段和执行阶段分开,很多看似玄学的输出就能解释清楚。
这也是我在 Vibe Coding 时代继续学基础的原因:AI 可以帮我写代码,但不能替我建立判断代码运行过程的脑内模型。