1 内存模型
1.1 操作系统内存模型
在探讨Golang的存储模型之前,我们可以首先回顾一下操作系统中的多次存储模型设计。可以参看我的这篇文章的第二章节:原子操作CAS与锁实现-CSDN博客。有提到高于存储的体系结构
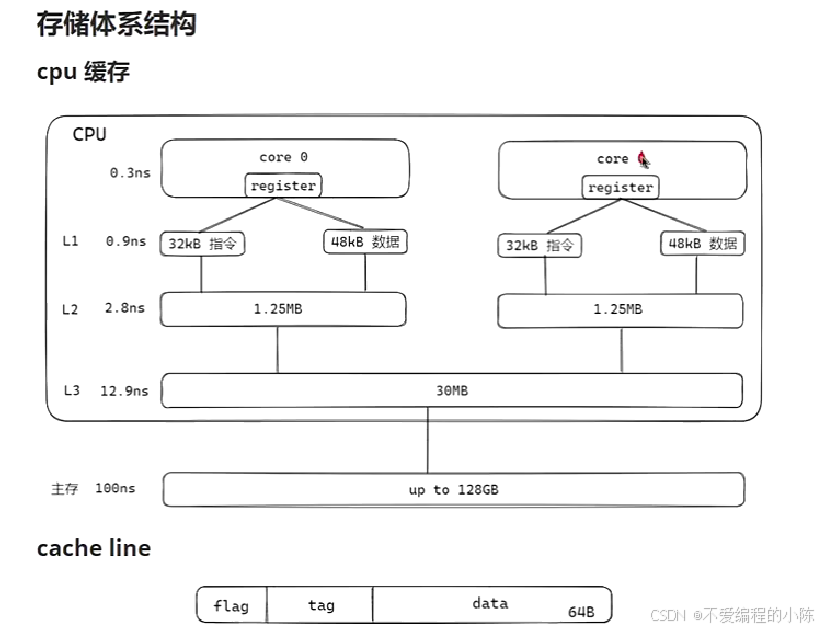
我们可以看出,从上至下依次是CPU -> 寄存器 -> 缓存 -> 内存 -> 磁盘;从上至下的访问速度越来越慢;我们可以从中获取的关键信息:
- 多级模型
- 动态切换
1.2 虚拟内存与物理内存
虚拟内存是操作系统提供的一种抽象,它让每个进程都认为自己独享整个内存空间。实际物理内存由操作系统统一管理,通过页表建立映射关系。
┌─────────────────┐ ┌─────────────────┐
│ 进程1虚拟内存 │ │ 进程2虚拟内存 │
│ 0x0000 ~ 0xFFFF │ │ 0x0000 ~ 0xFFFF │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
┌─────────────────────────────────────────┐
│ 页表映射 │
├─────────────────────────────────────────┤
│ 物理内存 (实际硬件) │
└─────────────────────────────────────────┘
操作系统的内存管理分配有很多内容,这里我们不展开叙述。后续如果有时间作者会另写一篇关于操作系统内存管理的学习博客。读者也可以参看其他的博客。
虚拟内存关键特性:
- 按需分页:仅在实际访问时才分配物理页
- 页面置换:当物理内存不足时,将不常用的页换出到磁盘
- 写时复制:多个进程共享同一物理页,直到有进程尝试写入
总之其主要作用就是让用户与底层硬件中添加一个代理层,优化用户体验。
1.3 分页管理
分页是虚拟内存管理的核心技术,将虚拟内存和物理内存划分为固定大小的页(通常4KB)。
什么是请求分页管理方式:
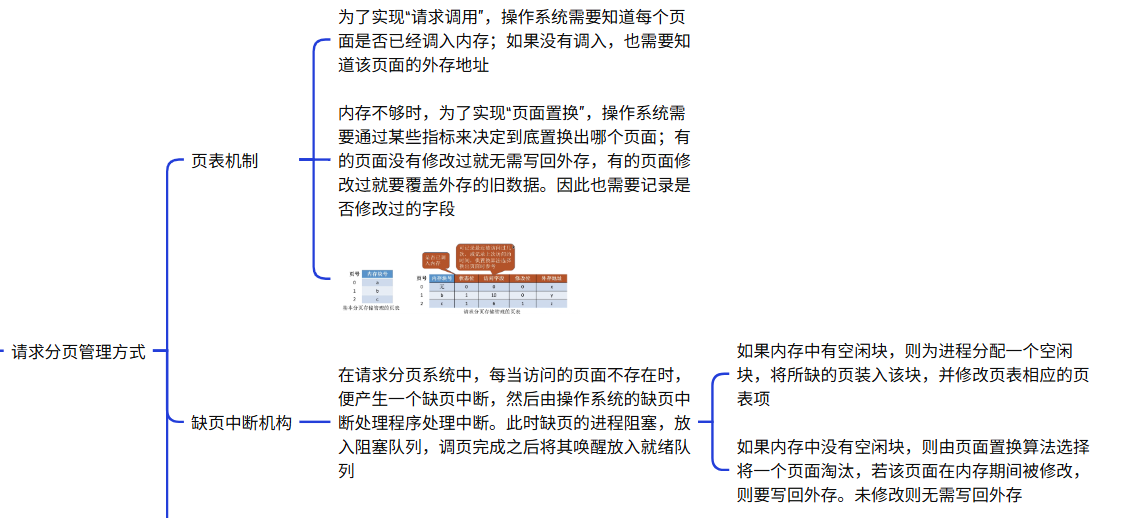
总而言之:请求分页管理是一种虚拟内存技术。程序被划分为固定大小的"页",只有当前运行需要的页才会被调入物理内存。当程序访问不在内存中的页时,会触发"缺页中断",操作系统负责将所需页从磁盘调入,并可能根据算法(如LRU)将内存中不常用的页换出。这种方式实现了内存的高效利用,允许运行比物理内存更大的程序。
1.4 Golang内存模型
Go的内存模型建立在操作系统虚拟内存之上,但有自己的管理策略。Go运行时从操作系统申请大块内存,然后自己进行精细管理。
// Go内存布局
┌─────────────────────────────────────────┐
│ 栈区 (Stack) │ ← 每个goroutine有独立的栈
│ Goroutine 1 Stack (2KB~1GB) │
│ Goroutine 2 Stack │
│ ... │
├─────────────────────────────────────────┤
│ 堆区 (Heap) │ ← GC管理,所有goroutine共享
│ ┌─────────────────┐ │
│ │ tiny对象 (<16B)│ │
│ │ small对象(16B~32KB)│ │
│ │ large对象(>32KB)│ │
│ └─────────────────┘ │
├─────────────────────────────────────────┤
│ 全局数据区 (Data/BSS) │ ← 程序启动时分配
│ - 全局变量 │
│ - 常量 │
│ - 代码 │
└─────────────────────────────────────────┘- 以空间换时间,一次缓存,多次复用
由于每次向操作系统申请内存的操作很重,那么不妨一次多申请一些,以备后用.
Golang 中的堆 mheap 正是基于该思想,产生的数据结构. 我们可以从两个视角来解决 Golang 运行时的堆:
I 对操作系统而言,这是用户进程中缓存的内存
II 对于 Go 进程内部,堆是所有对象的内存起源
- 多级缓存,实现无/细锁化
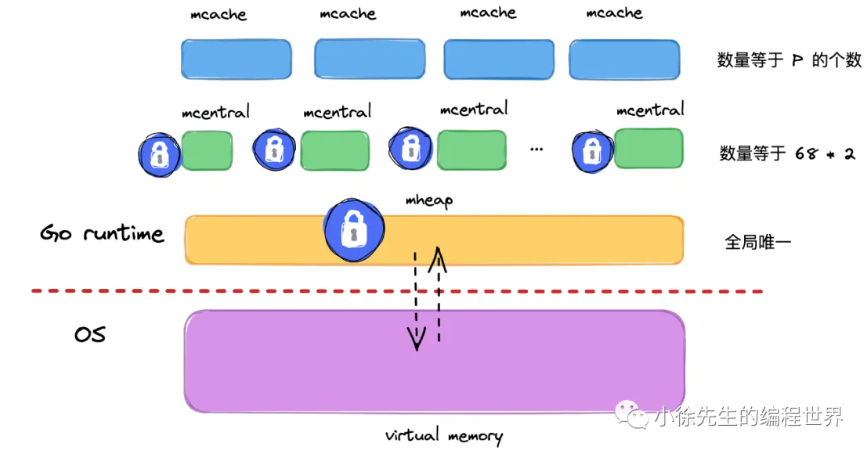
堆是 Go 运行时中最大的临界共享资源,这意味着每次存取都要加锁,在性能层面是一件很可怕的事情.
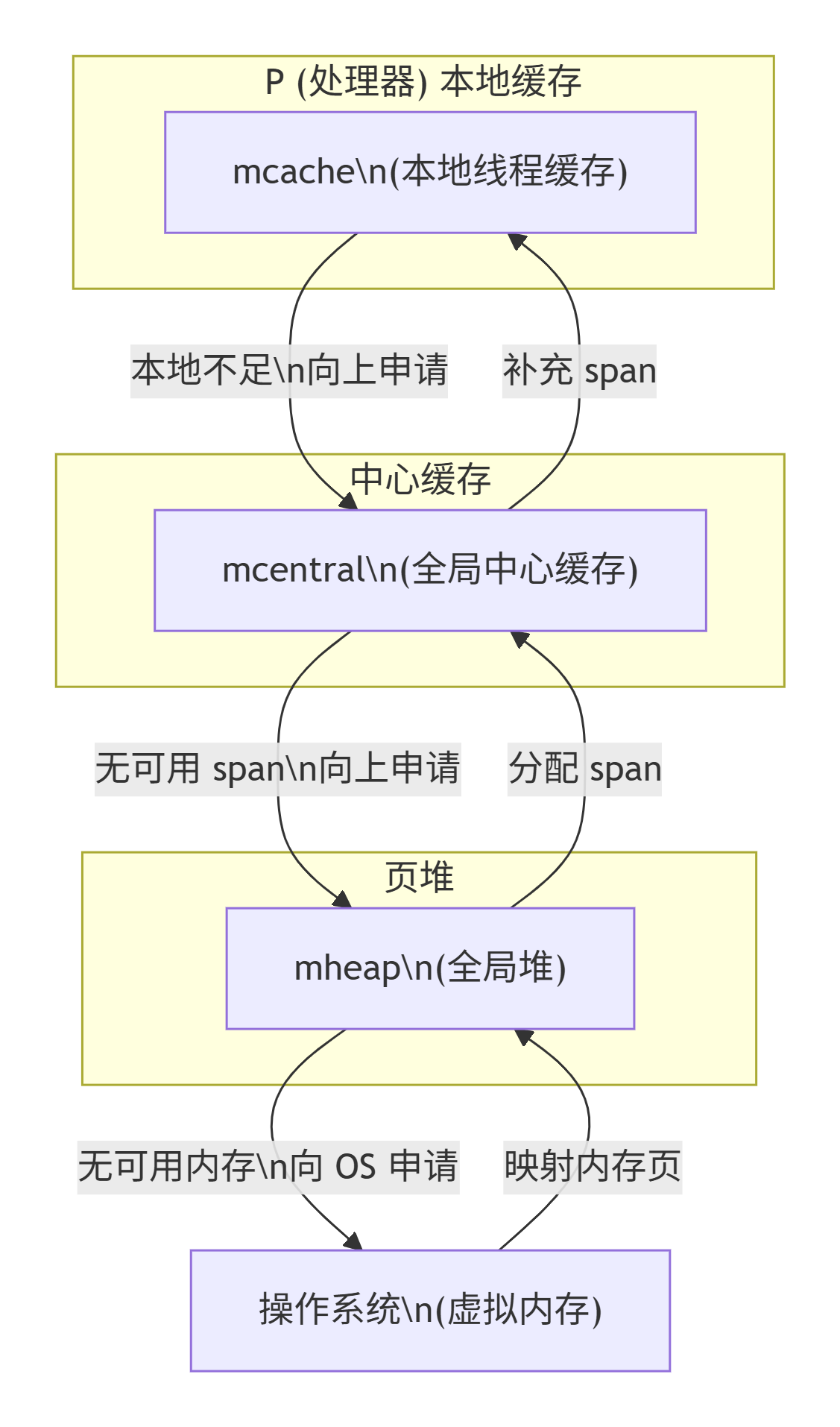
在解决这个问题,Golang 在堆 mheap 之上,依次细化粒度,建立了 mcentral、mcache 的模型,下面对三者作个梳理:
- mheap:全局的内存起源,访问要加全局锁
- mcentral:每种对象大小规格(全局共划分为 68 种)对应的缓存,锁的粒度也仅限于同一种规格以内
- mcache:每个 P(正是 GMP 中的 P)持有一份的内存缓存,访问时无锁
全局总览:
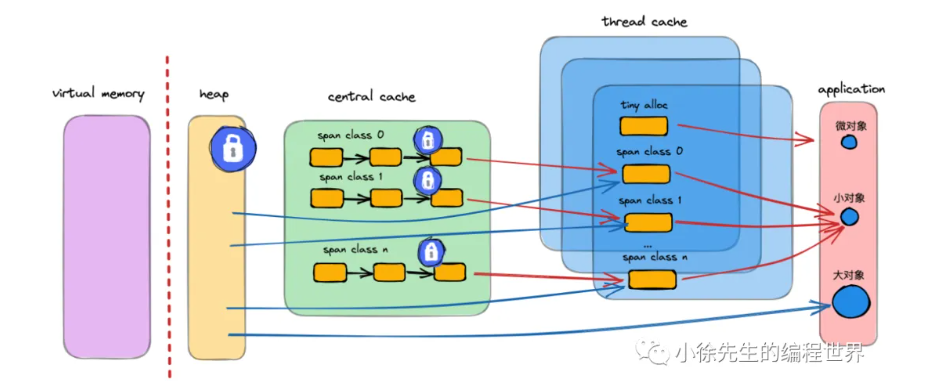
上图是 Thread-Caching Malloc 的整体架构图,Golang 正是借鉴了该内存模型. 我们先看眼架构,有个整体概念,后续小节中,我们会不断对细节进行补充
2 Go内存模型详解
2.1 堆内存管理机制
Go的堆内存管理采用了三级缓存架构 ,从TCMalloc中汲取了设计灵感,旨在实现高并发、低延迟的内存分配。
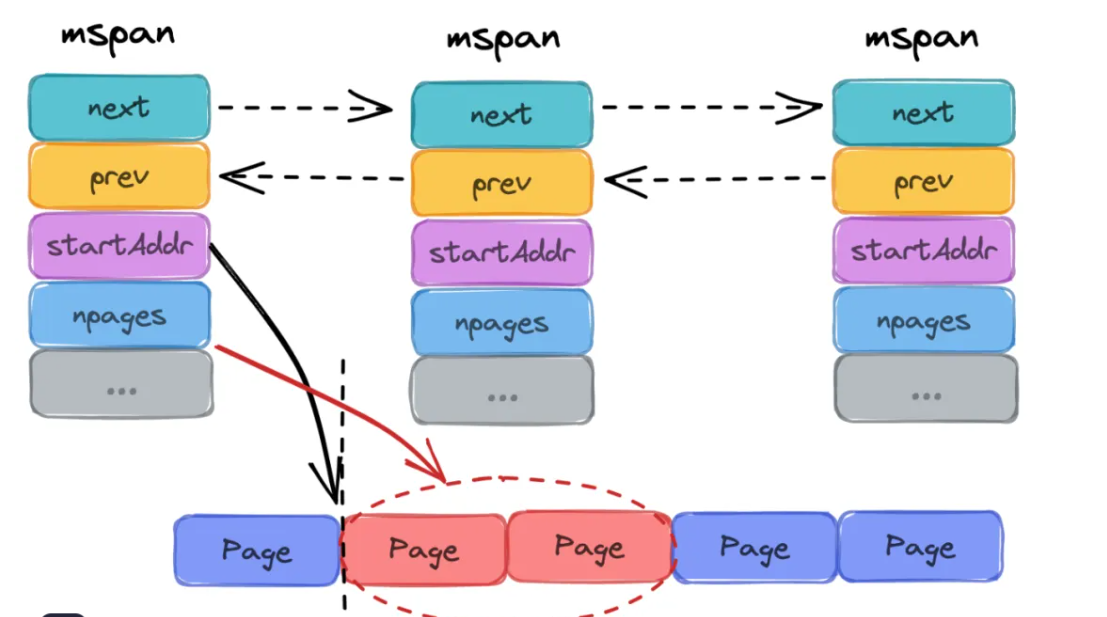
2.1.1 内存单元mspan
mspan是内存管理的基本单元,代表一段连续的内存页。
Go
// runtime/mspan.go
type mspan struct {
next *mspan // 链表中的下一个span
prev *mspan // 链表中的前一个span
startAddr uintptr // 起始地址
npages uintptr // 包含的页数(每页8KB)
spanclass spanClass // 大小等级
nelems uintptr // 对象总数
allocCount uintptr // 已分配对象数
freeindex uintptr // 下一个空闲对象索引
allocBits *gcBits // 分配位图
gcmarkBits *gcBits // GC标记位图
// 状态
state mSpanState // mSpanDead, mSpanInUse等
sweepgen uint32 // 清扫代
}mspan的特质:
- mspan是golang内存管理的最小单元
- mspan大小是page的整数倍(Go中的page大小为8KB),且内部的页是连续的(至少在虚拟内存的视角中是这样的)
- 每个span根据空间大小以及面向分配的对象大小会被划分为不同的等级
- 同等级的mspan会从属于一个mcentral,最终会被组织成为链表,因此带有前后指针(prev、next)
- 由于同等级的mspan内聚于同一个mcentral,所以会基于同一把互斥锁管理
- mspan会基于bitMap辅助快速找到空闲内存块(块大小为对应等级下的object大小),此时需要使用到Ctz64算法
2.1.2 内存单元等级spanClass
Go将对象按大小分为68个固定级别 ,实现零碎片分配。
Go
// 大小分级规则
tiny对象: 0~16字节(特殊处理,合并分配)
small对象: 16字节~32KB(67个固定级别)
large对象: >32KB(特殊处理)
// spanClass编码(8位)
// 高7位:大小等级(0-66表示small,67表示large)
// 最低位:是否包含指针(0=不包含,1=包含)
// 计算对象所属的spanClass
func sizeclass(size uintptr) spanClass {
if size <= smallSizeMax { // 32KB
// 使用预计算的尺寸表
if size <= 1024-8 {
return spanClass(size_to_class8[divRoundUp(size, smallSizeDiv)])
}
return spanClass(size_to_class128[divRoundUp(size-smallSizeMax/2, largeSizeDiv)])
}
// 大对象
return 0
}| class | bytes/obj | bytes/span | objects | tail waste | max waste |
|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% |
| 2 | 16 | 8192 | 512 | 0 | 43.75% |
| 3 | 24 | 8192 | 341 | 8 | 29.24% |
| 4 | 32 | 8192 | 256 | 0 | 21.88% |
| ... | |||||
| 66 | 28672 | 57344 | 2 | 0 | 4.91% |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% |
设计优势:
- 零碎片:每个span只分配固定大小的对象
- 快速分配:通过freeindex直接找到空闲槽位
- GC优化:指针对象和非指针对象分开,减少扫描开销
2.1.3 线程缓存mcache
每个P(处理器)都有独立的本地缓存,实现无锁分配。
Go
// runtime/mcache.go
type mcache struct {
// 每个spanClass对应一个mspan
alloc [numSpanClasses]*mspan
// tiny分配器(<16B的特殊优化)
tiny uintptr // 当前tiny块起始地址
tinyoffset uintptr // 下一个空闲偏移
tinyAllocs uintptr // tiny分配次数统计
// 栈缓存
stackcache [_NumStackOrders]stackfreelist
// 本地alloc统计
local_scan uintptr
local_tinyallocs uintptr
}- mcache是每个P独有的缓存,因此交互无锁
- mcache将每种spanClass等级的mspan各缓存了一个,总数为2(nocan维度)*68(大小维度) = 136
- mcache中还有一个为对象分配器tiny allocator,用于处理小于16B对象内存分配
2.1.4 中心缓存mcentral
当mcache的mspan用尽时,从mcentral获取,需要加锁。
Go
// runtime/mcentral.go
type mcentral struct {
spanclass spanClass
partial [2]spanSet // 包含空闲对象的span列表
full [2]spanSet // 无空闲对象的span列表
// partial[0]: 清扫过的span
// partial[1]: 未清扫的span
}- mcache申请span -> 从partial0获取
- 如果partial0为空 -> 从partial1获取
- 如果partial1为空 -> 从mheap申请新的额span
- span用尽 -> 移动到full列表
- span完全空闲,归还给mheap
2.1.5 全局堆缓存mheap
管理整个堆内存,从操作系统申请大块内存
Go
// runtime/mheap.go
type mheap struct {
// 页分配器
pages pageAlloc
// 所有mcentral
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize]byte
}
// 大对象分配
largealloc uint64
nlargealloc uint64
// arena元数据
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
// 清扫状态
sweepgen uint32
sweepDrained uint32
}arena布局:
- 每个arena: 64MB
- 每个heapArena: 管理一个arena的元数据
- arenaL1Bits = 6, arenaL2Bits = 20 (Linux)
- 支持最大内存: 2^(6+20+20) = 2^46 = 64TB
3 内存逃逸
go语言编译器会自动决定把一个变量放在栈还是放在堆,编译器会做逃逸分析(escape analysis) ,当发现变量的作用域没有跑出函数范围,就可以在栈上,反之则必须分配在堆 。
go语言声称这样可以释放程序员关于内存的使用限制,更多的让程序员关注于程序功能逻辑本身。
3.1 什么是逃逸分析
逃逸分析是Go编译器在编译阶段执行的静态分析,用于确定变量的生命周期和分配位置。
逃逸分析的目标:
- 确定变量是否超出函数作用域
- 决定在栈还是堆上分配
- 优化内存分配,减少GC压力
3.2 什么时候会内存逃逸
场景1:返回局部变量指针
Go
func escapeToHeap() *int {
x := 42 // 逃逸到堆
return &x // 返回指针,生命周期超出函数
}
func noEscape() int {
x := 42 // 栈上分配
return x // 返回值,不逃逸
}场景2:闭包引用外部变量
Go
func closureEscape() func() int {
y := 100 // 逃逸到堆
return func() int {
return y // 闭包引用外部变量
}
}场景3:
Go
func sendPointer() {
ch := make(chan *int, 1)
data := 42 // 逃逸到堆
ch <- &data // 指针发送到channel
}场景4:在slice中存储指针
Go
func slicePointer() []*int {
arr := make([]*int, 0, 10)
for i := 0; i < 10; i++ {
v := i // 每次循环都逃逸!
arr = append(arr, &v)
}
return arr
}场景5:接口类型赋值
Go
func interfaceEscape() {
var w io.Writer
buf := bytes.NewBuffer(make([]byte, 1024)) // 可能逃逸
w = buf // 接口赋值可能导致逃逸
w.Write([]byte("hello"))
}场景6:变量过大
Go
func largeAllocation() {
// 大对象可能直接在堆上分配
var large [1024 * 1024]byte // 1MB数组
_ = large
}场景7:调用未知函数
Go
func unknownCall() {
data := make([]byte, 1024)
// 如果someFunction的实现不可见(在另一个包)
// 编译器保守假设data可能逃逸
someFunction(&data)
}4 Golang的垃圾回收机制
4.1 Go GC的演进历程
GoV1.3版本标记删除:

GoV1.5版本三色标记法:


Golang为什么不选择如java类似的分代垃圾回收机制?
分代垃圾回收机制是现代编程语言(如Java)中一种高效的垃圾回收策略。其核心思想是:根据对象存活时间的不同,将内存划分为几代,并针对不同代采用不同的回收算法和频率,从而提升垃圾回收的整体效率。
然而Golang中存在内存逃逸机制,会在编译过程中将生命周期更长的对象转移到堆中,将生命周期短的对象分配在栈上,并以栈为单位对这部分对象进行回收.
综上,内存逃逸机制减弱了分代算法对Golang GC所带来的优势,考虑分代算法需要产生额外的成本(如不同年代的规则映射、状态管理以及额外的写屏障),Golang 选择不采用分代GC算法.
4.2 屏障机制
上面简单的提了一些关于golang语言GC的发展史,在Golang1.8版本之后,GC策略基本稳定,就是并发三色标记法+混合写屏障的机制
Golang GC 中用到的三色标记法属于标记清扫-算法下的一种实现,由荷兰的计算机科学家 Dijkstra 提出,下面阐述要点:
- 对象分为三种颜色标记:黑、灰、白
- 黑对象代表,对象自身存活,且其指向对象都已标记完成
- 灰对象代表,对象自身存活,但其指向对象还未标记完成
- 白对象代表,对象尙未被标记到,可能是垃圾对象
- 标记开始前,将根对象(全局对象、栈上局部变量等)置黑,将其所指向的对象置灰
- 标记规则是,从灰对象出发,将其所指向的对象都置灰. 所有指向对象都置灰后,当前灰对象置黑
- 标记结束后,白色对象就是不可达的垃圾对象,需要进行清扫.
从golang的GC的发展史看,主要解决的就是逐渐解决STW对GC程序性能的影响,那么如何在并发GC的同时还能够不让GC清理错误呢?如:
- Golang 并发垃圾回收可能存在漏标问题
- Golang 并发垃圾回收可能存在多标问题
这就是下面要探讨的问题
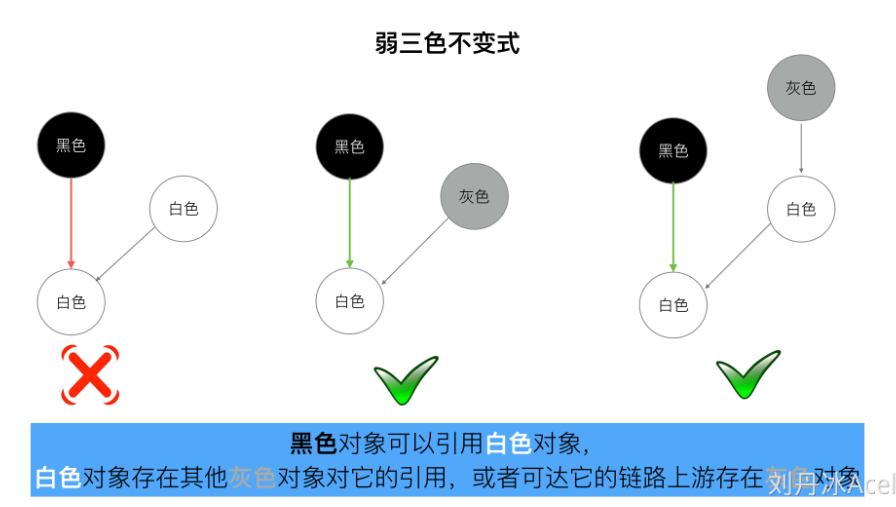
4.2.1 强弱三色不变式
漏标问题的本质就是,一个已经扫描完成的黑对象指向了一个被灰\白对象删除引用的白色对象. 构成这一场景的要素拆分如下:
- 黑色对象指向了白色对象
- 灰、白对象删除了白色对象
- 1、2步中涉及的白色对象是同一个对象
- 1发生在2之前
- 强三色不变式:白色对象不能被黑色对象直接引用(直接破坏(1))

- 弱三色不变式:白色对象可以被黑色对象引用,但要从某个灰对象出发仍然可达该白对象(间接破坏了(1)、(2)的联动)
4.2.2 插入写屏障

插入写屏障(Dijkstra)的目标是实现强三色不变式,保证当一个黑色对象指向一个白色对象前,会先触发屏障将白色对象置为灰色,再建立引用.
特点:
- 保证强三色不变式
- 不需要删除屏障
- 但需要重新扫描栈(栈上不启用屏障)
4.2.3 删除写屏障

删除写屏障(Yuasa barrier)的目标是实现弱三色不变式,保证当一个白色对象即将被上游删除引用前,会触发屏障将其置灰,之后再删除上游指向其的引用.
特点:
- 保证弱三色不变式
- 允许黑色对象指向白色对象
- 不需要重新扫描栈
- 但会产生浮动垃圾
4.2.4 混合写屏障
结合上面插入写屏障和删除写屏障机制,二者选择其一即可解决并发GC漏标的问题,至于错标问题,则采用容忍态度,放到GC的下一轮中延后处理即可
然而真实场景中,需要补充一个新的设定------屏障机制无法作用于栈对象
这是因为栈对象可能涉及频繁的轻量操作,倘若这些高频操作都需要一一触发屏障机制,那么所带来的成本将是无法接受的
在这一背景下,单独看插入写屏障或者删除写屏障,都无法真正的解决漏标问题,除非我们引入额外的STW阶段对栈对象的处理进行兜底
为了消除这个额外的STW成本,golang1.8引入了混合写屏障机制,可以视为糅合插入写屏障+删除写屏障的加强版本:
- GC 开始前,以栈为单位分批扫描,将栈中所有对象置黑
- GC 期间,栈上新创建对象直接置黑
- 堆对象正常启用插入写屏障
- 堆对象正常启用删除写屏障

混合写屏障优势:
- 栈上不需要写屏障:提高性能
- 不需要重新扫描栈:减少STW时间
- 精度更高:减少浮动垃圾
- 实现简单:结合两种屏障的优点