引言
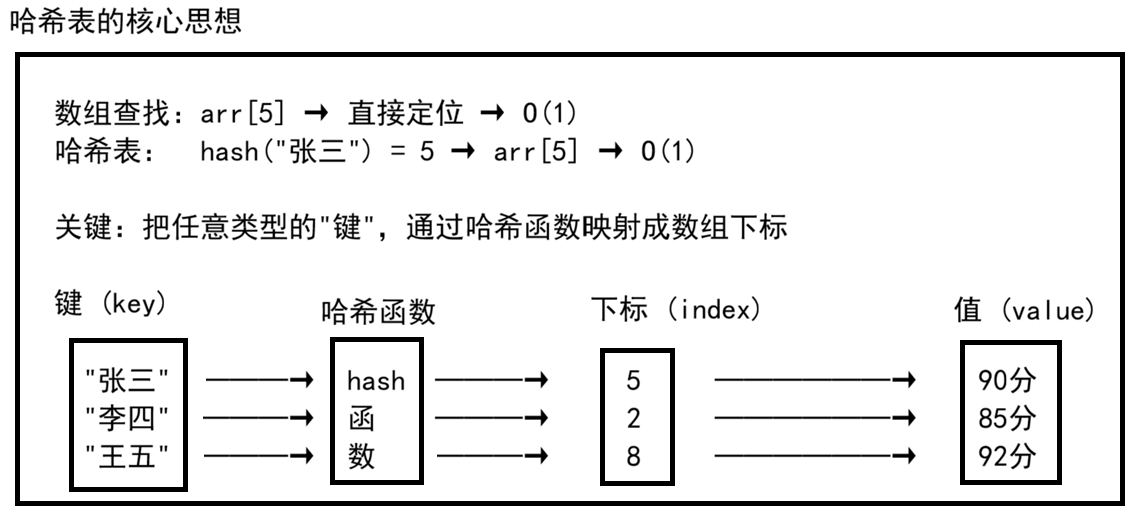
在前面的数据结构系列中,我们学习了各种树结构------BST、AVL、红黑树、B 树、B+ 树。它们通过"比较"来查找,最优能做到 O(log n)。今天要讲的哈希表 ,走的是完全不同的路线:通过映射函数 把键直接映射到存储位置,理想情况下查找只需 O(1)。
哈希表是计算机科学中最实用的数据结构之一。你用的 unordered_map、Redis 的键值存储、数据库的哈希索引、布隆过滤器......底层全都是哈希表的变体。
第一部分:哈希表的基本概念
一、核心三要素
| 要素 | 说明 | 示例 |
|---|---|---|
| 键 (Key) | 待存储数据的标识 | "张三"、1001、user_id |
| 哈希函数 | 把键映射成数组下标的函数 | hash("张三") = 5 |
| 桶数组 | 实际存储数据的数组 | arr[5] = 90 |
理想情况:不同的键映射到不同的下标,查找就是 O(1) 的数组访问。
现实问题 :键的空间远大于数组大小,冲突不可避免------两个不同的键可能映射到同一个下标。
二、哈希表的核心问题

第二部分:哈希函数
一、好的哈希函数的特征
-
计算快:O(1) 时间内完成
-
分布均匀:尽量避免不同的键映射到同一位置
-
确定性:同一个键总是得到同一个哈希值
二、常见哈希函数
1. 除留余数法(最常用)
cpp
// 取模运算,m 通常选质数
int hash(int key, int m) {
return key % m;
}为什么 m 选质数? 如果 m = 10(非质数),键以 0 结尾的全都映射到 0,分布不均匀。m 选质数能减少这种规律性冲突。
2. 乘法哈希
cpp
// 乘以一个常数 A(0 < A < 1),取小数部分 × m
// 常用 A = (√5 - 1) / 2 ≈ 0.6180339887
int hash(int key, int m) {
double A = 0.6180339887;
double frac = key * A - (int)(key * A); // 取小数部分
return (int)(m * frac);
}3. 字符串哈希(BKDR Hash)
cpp
// seed 常用 31、131、1313、13131 等
unsigned int BKDRHash(const char* str) {
unsigned int seed = 131;
unsigned int hash = 0;
while (*str) {
hash = hash * seed + (*str++);
}
return hash;
}为什么用 31? 31 是质数,hash * 31 可以被编译器优化为 (hash << 5) - hash,计算极快。
第三部分:解决冲突
一、拉链法(Chaining)------ 最常用
思路:每个桶存放一个链表(或其他容器),冲突的元素挂在同一链表中。
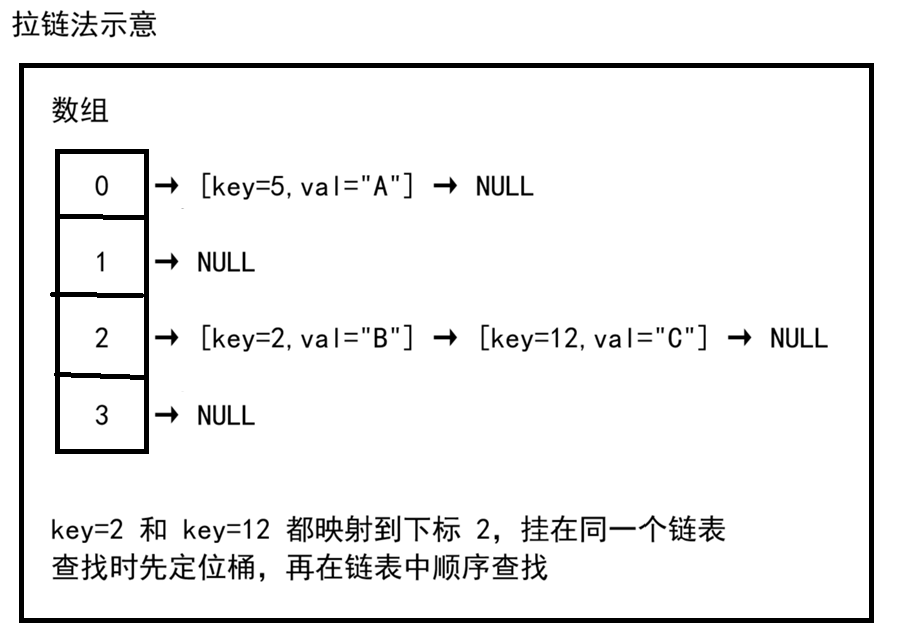
特点:
-
实现简单,删除方便
-
负载因子可以 > 1(桶数可以小于元素数)
-
最坏情况退化为链表 O(n)
二、开放定址法(Open Addressing)
思路:冲突时,在数组中找下一个空位置。
线性探测
cpp
// 冲突后依次检查 i+1, i+2, i+3...
int probe(int hash, int i, int m) {
return (hash + i) % m;
}二次探测
cpp
// 冲突后检查 i+1², i+2², i+3²...
int probe(int hash, int i, int m) {
return (hash + i * i) % m;
}双哈希
cpp
// 冲突后用第二个哈希函数计算步长
int probe(int hash1, int hash2, int i, int m) {
return (hash1 + i * hash2) % m;
}| 方法 | 插入 | 查找 | 删除 | 问题 |
|---|---|---|---|---|
| 线性探测 | O(1) 均摊 | O(1) 均摊 | 需标记删除 | 一次聚集(连续占用) |
| 二次探测 | O(1) 均摊 | O(1) 均摊 | 需标记删除 | 二次聚集 |
| 双哈希 | O(1) 均摊 | O(1) 均摊 | 需标记删除 | 实现稍复杂 |
| 拉链法 | O(1) 均摊 | O(1) 均摊 | 直接删 | 需要额外指针空间 |
第四部分:负载因子与扩容
一、负载因子

| 冲突解决方法 | 推荐 α 上限 |
|---|---|
| 拉链法 | 0.75 ~ 1.0 |
| 线性探测 | 0.5 ~ 0.7 |
| 二次探测 | 0.5 |
二、扩容时机
当 α 超过阈值时,创建更大的数组 ,将所有元素重新哈希(Rehash)到新数组。
扩容的代价是 O(n),但均摊下来每次插入仍是 O(1)。
cpp
// 扩容伪代码
if (count / capacity > LOAD_FACTOR) {
new_capacity = capacity * 2; // 扩容为原来 2 倍
new_table = 创建新数组(new_capacity);
for (旧表中的每个元素) {
重新哈希插入到 new_table;
}
释放旧表;
使用新表;
}第五部分:完整代码实现(拉链法)
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define INIT_CAPACITY 8
#define LOAD_FACTOR 0.75
// 键值对节点
typedef struct HashNode {
int key;
int value;
struct HashNode* next;
} HashNode;
// 哈希表
typedef struct {
HashNode** buckets;
int capacity;
int size;
} HashMap;
// 哈希函数
int hash(int key, int capacity) {
return key % capacity;
}
// 创建哈希表
HashMap* createHashMap() {
HashMap* map = (HashMap*)malloc(sizeof(HashMap));
map->capacity = INIT_CAPACITY;
map->size = 0;
map->buckets = (HashNode**)calloc(INIT_CAPACITY, sizeof(HashNode*));
return map;
}
// 插入或更新
void put(HashMap* map, int key, int value) {
int idx = hash(key, map->capacity);
// 查找是否已存在
HashNode* cur = map->buckets[idx];
while (cur) {
if (cur->key == key) {
cur->value = value; // 更新
return;
}
cur = cur->next;
}
// 不存在,头插法插入新节点
HashNode* node = (HashNode*)malloc(sizeof(HashNode));
node->key = key;
node->value = value;
node->next = map->buckets[idx];
map->buckets[idx] = node;
map->size++;
}
// 查找,返回 value,未找到返回 -1
int get(HashMap* map, int key) {
int idx = hash(key, map->capacity);
HashNode* cur = map->buckets[idx];
while (cur) {
if (cur->key == key) return cur->value;
cur = cur->next;
}
return -1;
}
// 删除
void removeKey(HashMap* map, int key) {
int idx = hash(key, map->capacity);
HashNode* cur = map->buckets[idx];
HashNode* prev = NULL;
while (cur) {
if (cur->key == key) {
if (prev == NULL) {
map->buckets[idx] = cur->next; // 删除头节点
} else {
prev->next = cur->next; // 删除中间节点
}
free(cur);
map->size--;
return;
}
prev = cur;
cur = cur->next;
}
}
// 释放
void freeHashMap(HashMap* map) {
for (int i = 0; i < map->capacity; i++) {
HashNode* cur = map->buckets[i];
while (cur) {
HashNode* tmp = cur;
cur = cur->next;
free(tmp);
}
}
free(map->buckets);
free(map);
}
// 测试
int main() {
HashMap* map = createHashMap();
put(map, 1, 100);
put(map, 2, 200);
put(map, 9, 900); // 和 1 冲突(如果 capacity=8,都映射到 1)
printf("key=1 → %d\n", get(map, 1)); // 100
printf("key=2 → %d\n", get(map, 2)); // 200
printf("key=9 → %d\n", get(map, 9)); // 900
printf("key=3 → %d\n", get(map, 3)); // -1(不存在)
removeKey(map, 2);
printf("删除后 key=2 → %d\n", get(map, 2)); // -1
freeHashMap(map);
return 0;
}第六部分:哈希表的实际应用
| 应用 | 说明 |
|---|---|
unordered_map / unordered_set |
C++ STL 哈希容器 |
| Redis 键值存储 | 全局哈希表存储所有 key |
| 数据库哈希索引 | MySQL Memory 引擎的哈希索引 |
| 布隆过滤器 | 判断元素是否可能存在(用多个哈希函数) |
| LRU 缓存 | unordered_map + 双向链表 |
| 负载均衡 | 一致性哈希 |
第七部分:哈希表 vs 平衡树
| 对比项 | 哈希表 | 平衡树(红黑树) |
|---|---|---|
| 查找 | O(1) 平均 | O(log n) |
| 插入 | O(1) 平均 | O(log n) |
| 删除 | O(1) 平均 | O(log n) |
| 有序遍历 | ❌ 无序 | ✅ 有序 |
| 范围查询 | ❌ 不支持 | ✅ 支持 |
| 内存占用 | 较大(桶数组+链表指针) | 较小(只存数据和左右指针) |
| 最坏情况 | O(n) | O(log n) |
| C++ 对应 | unordered_map |
map |
总结
一、核心要点
| 要点 | 内容 |
|---|---|
| 哈希函数 | 把键映射成数组下标,要求计算快、分布均匀 |
| 冲突解决 | 拉链法(链表)和开放定址法(线性探测/二次探测/双哈希) |
| 负载因子 | 元素数/桶数,超过阈值需要扩容并 Rehash |
| 时间复杂度 | 均摊 O(1),最坏 O(n)(全部冲突到同一桶) |
二、一句话记忆
哈希表用哈希函数把键映射成数组下标实现 O(1) 查找,通过拉链法或开放定址法解决冲突,负载因子过大时扩容并重新哈希所有元素。