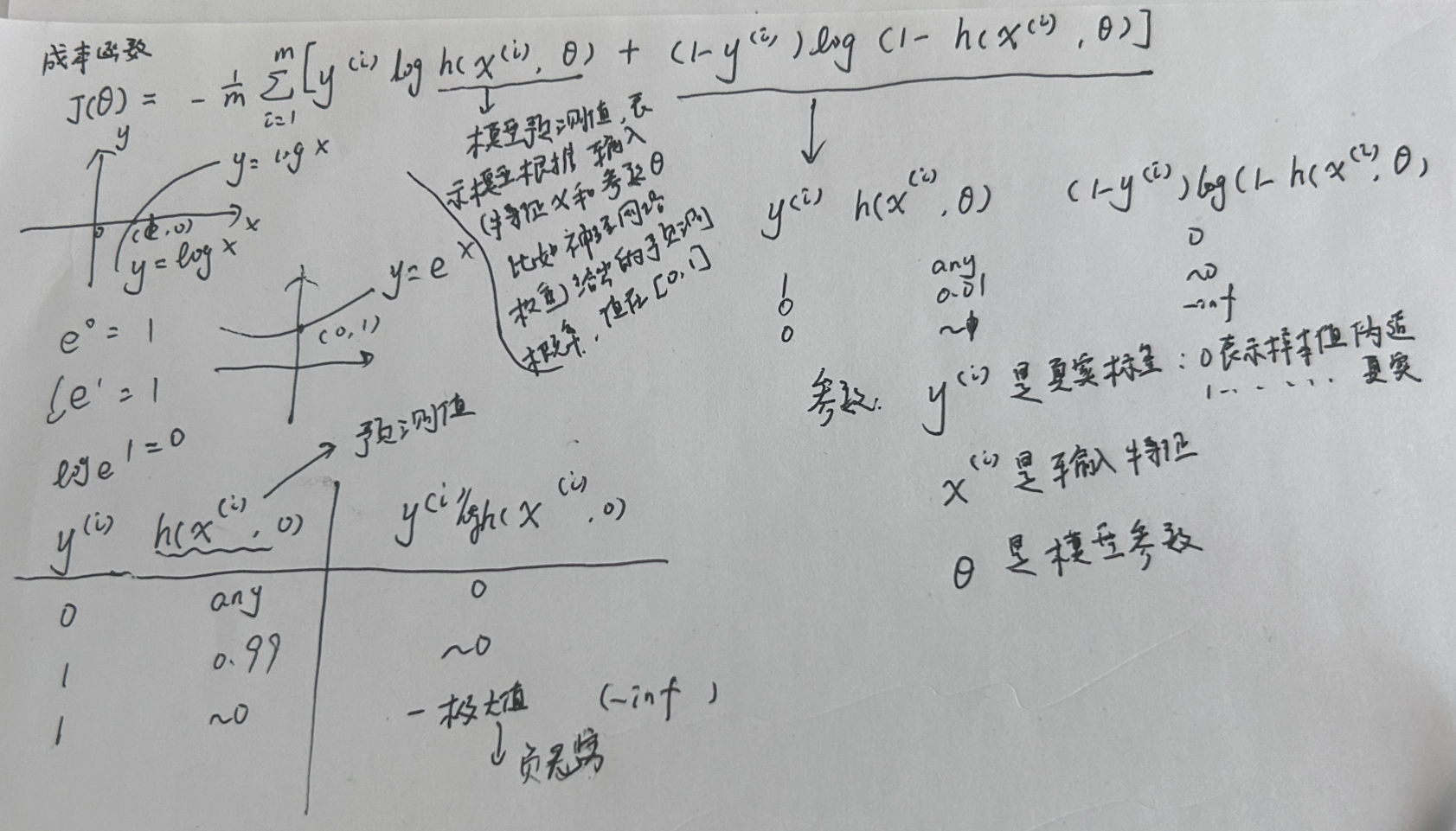
一、完整公式
J(θ)=−1m∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i))) J(\theta) = -\frac{1}{m} \sum_{i=1}^m \Big y\^{(i)} \\log h_\\theta(x\^{(i)}) + (1-y\^{(i)}) \\log\\big(1-h_\\theta(x\^{(i)})\\big) \\Big J(θ)=−m1i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))
这是二分类逻辑回归的标准损失函数(对数交叉熵损失),用来衡量模型预测结果和真实结果的差距。
二、逐个符号解释
-
J(θ)J(\theta)J(θ)
整体损失值/代价函数。数值越大,代表模型预测越不准;训练目标就是最小化 J(θ)J(\theta)J(θ)。
-
mmm
训练集里样本总数量 。除以 mmm 是为了取平均损失,消除样本总数的影响。
-
∑i=1m\displaystyle\sum_{i=1}^mi=1∑m
对每一个样本 的损失求和,iii 代表第 iii 个样本。
-
y(i)y^{(i)}y(i)
第 iii 个样本的真实标签,二分类只有两个取值:
- y=1y=1y=1:属于正样本
- y=0y=0y=0:属于负样本
-
hθ(x(i))h_\theta(x^{(i)})hθ(x(i))
模型对第 iii 个样本的预测概率 ,取值范围 (0,1)(0,1)(0,1),表示该样本是正类的概率。
-
负号 −-−
因为对数函数 log(x)\log(x)log(x) 在 x∈(0,1)x\in(0,1)x∈(0,1) 时结果为负数,加负号把损失转为正数,方便优化。
三、分场景理解(核心逻辑)
把公式拆成两部分,对应两种真实标签:
场景1:真实标签 y=1y=1y=1(正样本)
此时 1−y=01-y=01−y=0,后半项直接消失,公式简化为:
单样本损失=−log(hθ(x)) \text{单样本损失} = -\log\big(h_\theta(x)\big) 单样本损失=−log(hθ(x))
- 模型预测 hhh 越接近 111(预测正确):损失趋近于 0
- 模型预测 hhh 越接近 000(预测错误):损失急剧变大,严厉惩罚错误
场景2:真实标签 y=0y=0y=0(负样本)
此时 y=0y=0y=0,前半项直接消失,公式简化为:
单样本损失=−log(1−hθ(x)) \text{单样本损失} = -\log\big(1-h_\theta(x)\big) 单样本损失=−log(1−hθ(x))
- 模型预测 hhh 越接近 000(预测正确):损失趋近于 0
- 模型预测 hhh 越接近 111(预测错误):损失急剧变大
四、整体作用总结
- 对二分类任务量身设计,专门评价逻辑回归模型好坏;
- 预测越偏离真实标签,损失值越高,倒逼模型不断修正参数;
- 相比平方损失,交叉熵在分类任务中梯度更稳定、收敛更快,是机器学习分类模型最常用的损失函数。