paper: https://arxiv.org/abs/2401.16122
code: https://github.com/KTH-RPL/DeFlow
摘要
场景流估计通过预测场景中点的运动来确定场景的3D运动场,尤其在辅助自动驾驶任务方面具有重要意义。许多以大规模点云为输入的网络采用体素化方法生成伪图像,以实现实时运行。然而,体素化过程往往导致点级特征丢失,从而给场景流任务中的特征恢复带来挑战。
本文提出DeFlow方法,利用门控循环单元(GRU)精炼模块,实现从体素化特征到点级特征的转换。为进一步增强场景流估计性能,我们设计了一种新型损失函数,以处理静态点与动态点之间的数据不平衡问题。
在Argoverse 2场景流任务上的评估结果表明,DeFlow在大规模点云数据上达到了最先进水平,表明我们的网络相较于其他方法具有更优的性能与效率。代码已开源,地址为:https://github.com/KTH-RPL/deflow。
1. Introduction
在实时条件下处理并估算大型全量点云数据集的场景流,FastFlow3D 9 成为一种切实可行的解决方案。实现实时要求的关键策略之一是体素化(voxelization)。体素化是一种流行的点云处理技术,尤其常用于检测任务 15、16、17。然而,检测任务与场景流任务之间存在显著差异:后者需要逐点级的结果 。基于体素化的方法往往忽视了解码器设计在场景流任务中的重要性,导致其无法区分同一物元(voxel)内各点之间的特征差异。这是因为给定物元内的所有点都从卷积网络继承相同的特征。
为应对上述挑战,我们提出了 DeFlow,该方法通过门控循环单元(GRU)细化模块重建同一物元内各点的不同特征,从而显著提升了最终结果。我们在 Argoverse 2 场景流任务上评估了所提方法,在仅使用 10 万帧标注数据集进行训练的情况下,于在线排行榜上取得了最先进的(state-of-the-art)结果。一个示例如图 1 所示。我们的方法已开源,代码地址为 https://github.com/KTH-RPL/deflow。总之,我们的主要贡献包括:
- 引入一种全新的实时网络架构,在解码器设计中将 GRU 与迭代细化相结合,有效实现了从物元特征到点特征的转换。
- 提出一种新的损失函数,专门针对静态与动态点数据分布不平衡的问题进行优化。
- 在大规模点云数据集 Argoverse 2 的在线排行榜上取得最先进的性能。
II. RELATED WORK
Vedula 等人 18 引入了场景流估计,旨在捕获场景的三维点运动场。这一概念源于二维光流估计,后者是一个经典课题,用于预测二维图像中的视运动模式。
现有的方法大致可分为基于优化 和基于学习两类。基于优化类别中一个突出的例子是 NSFP 12。该方法利用多层感知机(MLP)细化光流,并以 Chamfer 距离作为度量指标。此类方法通常不被归类为基于学习的方法,因为它们不会保存学到的权重以用于推断其他帧,而是采用 MLP 对每一帧进行优化。NSFP 显著的推理时间使其在实时应用中显得不切实际。
近年来出现的基于学习的三维方法 5, 4, 19, 20 可追溯至二维方法 21, 22, 23。光流领域的一项重要工作 RAFT 21 便是很好的代表。它通过循环单元迭代更新光流场,为像素对构建多尺度四维相关性体。在此基础上,PV-RAFT 5 和 DPV-RAFT 24 将其框架适配于三维点云数据。然而,由于内存溢出,这些方法在面对大规模点云时变得计算挑战性很大。该问题通常出现在距离矩阵 5, 24 或相关性矩阵 4 的构建过程中,这些矩阵随着点数增加呈指数级增长。
幸运的是,在其他点云相关任务(如检测 15, 16, 17 和分割 25, 26)中,存在一些针对处理大规模点云的编码器设计。Lang 等人 17 提出的 PointPillar 因其卓越的性能与高效率相结合而脱颖而出。该方法将点转换为体素,为卷积网络创建伪图像,其灵感来源于二维方法:光流估计的开山之作 CNN------FlowNet 27 采用了 U-Net 自编码器架构。在场景流任务中,FastFlow3D 9 是一个能够在大规模点云数据(8 万至 17.7 万个点)上实时运行的网络,它也使用 PointPillar 作为其编码器。然而,FastFlow3D 的解码器在区分同一体素内各点之间的特征方面表现不佳,这一局限性归因于 PointPillar 中的体素化过程。采用 PointPillar 方法可以提高效率
可将光流中开发的解码器设计适配至场景流任务。在光流任务中,先前使用的网络(如 PWC-Net 28)采用上下文网络以扩大输出的感受野,并通过空洞卷积 29 对光流进行细化。此外,IRR 30 提出了迭代残差细化方法,在无需扩大网络规模的情况下实现了更高的精度。Feihu 等人 31 利用门控循环单元(GRU)进行细化,通过多次迭代来估计光流。沿袭光流领域工作的思路,我们在方法中采用 GRU,以强调 3D 点场景流任务中体素特征向点特征转换的过程。
III. PROBLEM STATEMENT
本研究致力于解决自动驾驶中实时场景流估计的挑战。给定分别在时刻 t 和 t+1 捕获的两个连续输入点云 Pt 和 Pt+1,以及作为变换矩阵的自车运动 Tt,t+1,目标是为 Pt 中的每个点 p 预测运动向量(即流)ˆFt,t+1(p)=(x,y,z)TˆFt,t+1(p) = (x, y, z)^TˆFt,t+1(p)=(x,y,z)T。 已知我们传感器数据采集的频率为 10 Hz,因此将流解释为速度变得直截了当。总体目标是最小化终点误差(EPE),该误差表示预测流与真实流之间的差异,如下式所示:
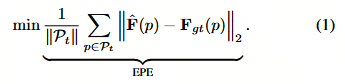
门控循环单元
门控循环单元(GRU, Gated Recurrent Unit)的核心公式主要包含重置门(Reset Gate) 、**更新门(Update Gate)和候选隐藏状态(Candidate Hidden State)**的计算。
设 ht−1h_{t-1}ht−1 为上一步的隐藏状态,xtx_txt 为当前时刻的输入,WWW 和 UUU 分别为输入权重矩阵和隐藏状态权重矩阵,bbb 为偏置向量,σ\sigmaσ 为 Sigmoid 激活函数。
以下是标准 GRU 的数学公式:
-
重置门 (Reset Gate) rtr_trt
决定上一时刻的隐藏状态在多大程度上对当前候选隐藏状态有用。
rt=σ(Wr⋅xt+Ur⋅ht−1+br) r_t = \sigma(W_r \cdot x_t + U_r \cdot h_{t-1} + b_r) rt=σ(Wr⋅xt+Ur⋅ht−1+br)
-
更新门 (Update Gate) ztz_tzt
决定当前隐藏状态中有多少保留自上一时刻,有多少需要更新。
zt=σ(Wz⋅xt+Uz⋅ht−1+bz) z_t = \sigma(W_z \cdot x_t + U_z \cdot h_{t-1} + b_z) zt=σ(Wz⋅xt+Uz⋅ht−1+bz)
-
候选隐藏状态 (Candidate Hidden State) h~t\tilde{h}_th~t
计算新的候选记忆单元,这里使用了重置门 rtr_trt 来过滤掉不相关的历史信息。
h~t=tanh(Wh⋅xt+Uh⋅(rt⊙ht−1)+bh) \tilde{h}t = \tanh(W_h \cdot x_t + U_h \cdot (r_t \odot h{t-1}) + b_h) h~t=tanh(Wh⋅xt+Uh⋅(rt⊙ht−1)+bh)
注:⊙\odot⊙ 表示逐元素乘积(Hadamard product)。
-
最终隐藏状态 (Hidden State) hth_tht
根据更新门 ztz_tzt 线性插值上一时刻的状态和当前候选状态。
ht=(1−zt)⊙ht−1+zt⊙h~t h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t ht=(1−zt)⊙ht−1+zt⊙h~t
总结:
- rtr_trt 控制"遗忘"过去的程度(重置门越大,越忽略过去的状态)。
- ztz_tzt 控制"记忆"过去的程度(更新门越大,越保留过去的状态;更新门越小,越倾向于使用新计算的候选状态)。
- h~t\tilde{h}_th~t 是当前的新信息提议。
- hth_tht 是最终输出到下一步的状态。
研究背景(DeFlow)中,GRU 被用于解码器部分,通过迭代细化,从体素化特征中提取更精细的点级特征,从而解决同一物元内特征混淆的问题。
IV. APPROACH
我们的方法建立在 Fast-Flow3D 9 的整体流水线基础之上,该方法专为大规模点云数据而设计。简而言之,该方法首先对点进行体素化(voxelization),并将其格式化为具有指定分辨率的鸟瞰图(bird-eye-view)网格特征。通过卷积层,网络能够高效地学习这些体素内的特征。
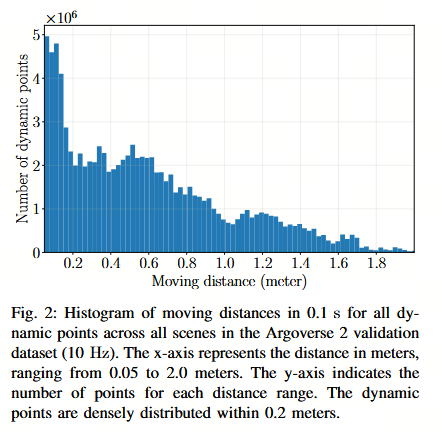
基于我们对 Argoverse 2 数据集的分析(如图 2 所示),我们观察到动态点在 0.05 米至 0.2 米的运动范围内密集分布。因此,分辨率的选择至关重要,如第五-B 节所示。然而,更高的分辨率也会导致计算需求的增加,使其难以在计算资源有限的设备上实际应用。如果选择较粗糙的分辨率,解码器的设计便变得至关重要,因为它需要区分同一体素内的点特征,从而获得与更高分辨率相当的结果。
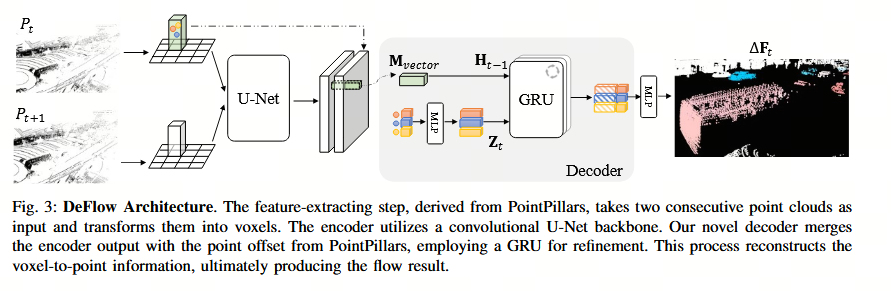
在接下来的章节中,我们将按照图 3 所示概述我们的框架,并突出重点关注的领域及改进之处。
A. 输入与输出
利用大多数自动驾驶数据集 32, 11 提供的高精度(HD)地图,或部署如 33 所示的地面分割技术,我们可以轻松地从 PtP_tPt 和 Pt+1P_{t+1}Pt+1 中排除地面点。
从 PtP_tPt 到 Pt+1P_{t+1}Pt+1 的流动向量 F^\hat{F}F^ 分解为以下两部分:
F^=Fego+ΔF^,(2) \hat{F} = F_{ego} + \Delta \hat{F}, \quad (2) F^=Fego+ΔF^,(2)
其中,FegoF_{ego}Fego 是由自车运动产生的流动,可以直接从变换矩阵 Tt,t+1T_{t,t+1}Tt,t+1 中获得;而 ΔF^\Delta \hat{F}ΔF^ 则是我们网络的输出。
B. 编码器与骨干网络
对于点云光栅化,我们采用了 PointPillars 16, 17 中的动态体素化技术,以提高框架的效率。我们计算每个点到柱子中心(pillar center)的偏移量,以及点到其聚类坐标的聚类偏移量。体素化之后,通过线性变换聚合柱子内的所有点。
在将 PtP_tPt 和 Pt+1P_{t+1}Pt+1 编码为网格后,我们使用 2D 卷积 U-Net 骨干网络。两个网格均通过此共享权重的骨干网络进行处理。
C. 解码器
在 FastFlow3D 中,获取逐点流动(point-wise flow)的过程由"去柱化"(unpillar)操作协助完成。该操作对于每个点,检索相关联的流动嵌入网格单元,附加点特征,并使用多层感知机(MLP)推导流动向量。然而,正如之前所强调的那样,这种方法并不适合用于体素到点特征的重建。
如图 3 所示,在解码器操作之前,我们将 PtP_tPt 的柱子特征与 U-Net 特征的输出进行拼接, resulting in a format of Mvector∈RN×CM_{vector} \in R^{N \times C}Mvector∈RN×C。这里,NNN 表示 PtP_tPt 中的点数,CCC 表示拼接后的特征通道数。
我们观察到,简单地将同一体素中所有点共有的 CCC 个通道与专门用于点偏移的 3 个通道进行拼接,会导致不平衡。对于同一体素中的点,大部分通道是相同的。
解决这种不平衡的直观方案是将点偏移特征扩展以匹配维度 CCC。然而,这种修改反而使原始性能恶化,证明有必要进行专门的网络设计。
受到利用门控循环单元(GRU)31 的 2D 光流技术的启发,我们在图 3 的解码器中提出了一种用于 3D 场景流的替代方法。在此方法中,我们将 MvectorM_{vector}Mvector 指定为第一个隐藏状态,记为 H0H_0H0。通过线性层,我们扩展点偏移并将其设置为输入,表示为 xxx。这些组件之间的关系由以下公式捕捉:
Ht=Zt⊙Ht−1+(1−Zt)⊙H~t,(3) H_t = Z_t \odot H_{t-1} + (1 - Z_t) \odot \tilde{H}_t, \quad (3) Ht=Zt⊙Ht−1+(1−Zt)⊙H~t,(3)
其中,ZtZ_tZt 充当更新门。它接收 xxx 作为输入,随后通过一维卷积层进行处理,并使用 Sigmoid 激活函数。项 Ht−1H_{t-1}Ht−1 代表之前的隐藏状态。对于初始实例,H0H_0H0 被设置为 MvectorM_{vector}Mvector。H~t\tilde{H}_tH~t 代表候选隐藏状态,由重置门和模型权重确定。
为了在保持参数规模较小的前提下维持模型性能,我们在门控循环单元(GRU)层中采用了多次迭代策略。完成这些迭代后,将最新的隐藏状态 HtH_tHt 与点偏移特征进行拼接。该拼接后的特征随后通过多层感知机(MLP),最终生成如 Fig. 3 所示的增量流场 ΔF^\Delta \hat{F}ΔF^。我们在第 V-B 节中提供了详尽的消融实验,详细说明了我们解码器设计的细节及其性能表现。
D. 损失函数
自动驾驶场景中的场景流估计任务具有固有的挑战性,这主要归因于环境的动态特性。在激光雷达点云中,大量反射建筑物或道路等静态结构的点保持静止。这导致数据集中的标签存在不平衡问题,即背景静态点的数量远多于其他类型的点。为解决这一问题,损失函数引入了一种缩放函数 σ(p)\sigma(p)σ(p),以根据每个点的运动特性平衡其贡献:
L=1∥Pt∥∑p∈Ptσ(p)∥ΔF^(p)−ΔFgt(p)∥2,(4) L = \frac{1}{\|P_t\|} \sum_{p \in P_t} \sigma(p) \|\Delta \hat{F}(p) - \Delta F_{gt}(p)\|^2, \quad (4) L=∥Pt∥1p∈Pt∑σ(p)∥ΔF^(p)−ΔFgt(p)∥2,(4)
其中 ∥Pt∥\|P_t\|∥Pt∥ 表示 PtP_tPt 中的点数量。
FastFlow3D 9 在其实验中引入了一种基于前景和背景点区分度的缩放方法。两者的区别在于该点是否包含在任何跟踪对象的边界框内:
σ(p)t={1if p∈Foreground0.1if p∈Background(5) \sigma(p)_t = \begin{cases} 1 & \text{if } p \in \text{Foreground} \\ 0.1 & \text{if } p \in \text{Background} \end{cases} \quad (5) σ(p)t={10.1if p∈Foregroundif p∈Background(5)
随着自监督学习的兴起,由于缺乏区分前景和背景的标签,ZeroFlow 14 提出了一种替代的缩放函数。该函数基于点运动的速度(流场大小)进行缩放:
σ(p)s={0.1if s(p)<0.4 m/s1.0if s(p)>1.0 m/s1.8s(p)−0.8o.w.(6) \sigma(p)_s = \begin{cases} 0.1 & \text{if } s(p) < 0.4 \text{ m/s} \\ 1.0 & \text{if } s(p) > 1.0 \text{ m/s} \\ 1.8s(p) - 0.8 & \text{o.w.} \end{cases} \quad (6) σ(p)s=⎩ ⎨ ⎧0.11.01.8s(p)−0.8if s(p)<0.4 m/sif s(p)>1.0 m/so.w.(6)
在 ZeroFlow 的启示基础上,我们提出了一种更精细的缩放方法,该方法考虑了动态点与静态点数量的分布情况。该方法根据运动速度将 PtP_tPt 划分为三个类别 {Pt/1,Pt/2,Pt/3}\{P_{t/1}, P_{t/2}, P_{t/3}\}{Pt/1,Pt/2,Pt/3},如公式 (6) 所定义。总损失为这三个类别的损失之和:
Ltotal=∑i=131∥Pt/i∥∑p∈Pt/i∥ΔF^(p)−ΔFgt(p)∥2.(7) L_{total} = \sum_{i=1}^{3} \frac{1}{\|P_{t/i}\|} \sum_{p \in P_{t/i}} \|\Delta \hat{F}(p) - \Delta F_{gt}(p)\|^2. \quad (7) Ltotal=i=1∑3∥Pt/i∥1p∈Pt/i∑∥ΔF^(p)−ΔFgt(p)∥2.(7)
这种综合损失函数确保模型能够平衡不同类型的点运动,从而在多样化的场景中提供稳健的场景流估计。
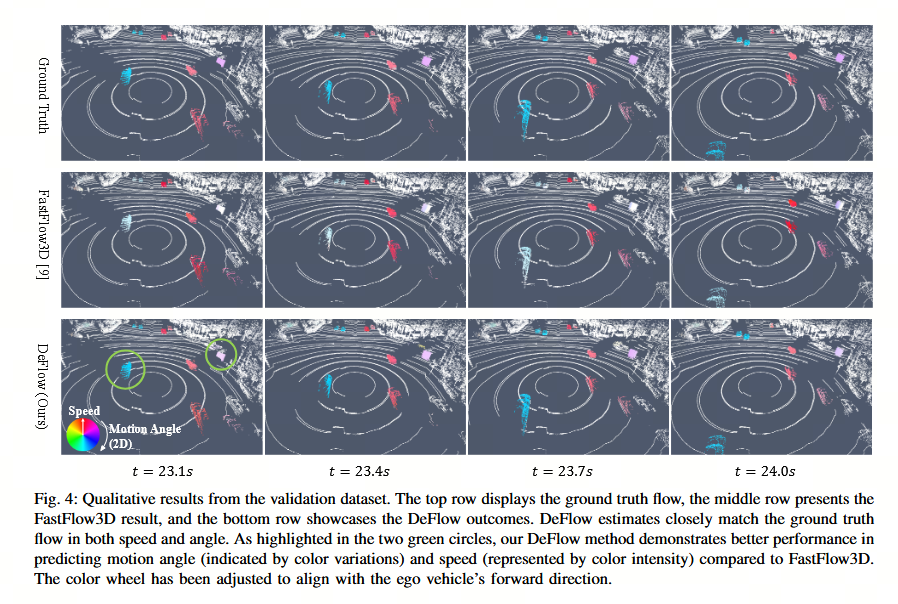
六、结论
本文提出了DeFlow,这是一种用于大规模点云自动驾驶的高效且高性能的方法。我们的主要贡献包括:引入DeFlow网络,在点级别上增强了点-体素-点网络特征的提取与重建;同时,提出了一种新的损失函数,以应对点之间数据分布不平衡带来的挑战。实验结果充分验证了我们方法的有效性。 未来的工作可围绕DeFlow的自监督探索,以及与相机、雷达等多模态传感器的融合展开。由于场景流估计主要关注动态物体的流动,若我们能首先对静态和动态部分进行分割36,则可大幅降低基于神经优化的方法的计算负担。