📚 课程:《黑马程序员 · 大模型 RAG 与 Agent 智能体实战》
📝 学习章节:第01章 前置准备(第01~07集)
🎯 适合人群:AI 初学者、Python 开发者、准备学习 RAG 与 Agent 的同学
一、课程导学:学完能做什么?
随着 ChatGPT、DeepSeek、通义千问等大模型的爆发,AI 应用开发已经成为热门方向。
本课程的目标并不是训练大模型,而是教大家如何利用现有大模型开发实际项目。
学完后可以掌握:
✅ 调用通义千问、DeepSeek 等大模型 API
✅ 开发企业知识库问答系统(RAG)
✅ 开发能够自主规划任务的 Agent 智能体
✅ 掌握 LangChain、OpenAI SDK 等主流开发框架
本课程主要技术栈如下:
Python
OpenAI SDK
LangChain
阿里云百炼
Ollama
RAG
Agent二、接入通义千问大模型
目前最常见的两种使用大模型方式:
| 方式 | 平台 | 特点 |
|---|---|---|
| 云端模型 | 阿里云百炼 | 官方托管、效果最好、新用户有免费额度 |
| 本地模型 | Ollama | 私有化部署、不依赖网络 |
对于新手来说,推荐优先使用云端模型。
原因:
-
配置简单
-
无需高性能显卡
-
模型能力最完整
-
官方持续更新
2.1 开通阿里云百炼
具体流程:
第一步:注册并实名认证
进入阿里云百炼平台:
https://bailian.console.aliyun.com完成:
注册账号
↓
登录
↓
实名认证实名认证通常通过支付宝扫码完成。
第二步:获取 API Key
进入:
API参考
↓
获取API Key
↓
创建API Key生成类似:
sk-xxxxxxxxxxxxxxxxxxxx的密钥。
API Key 的作用
可以把 API Key 理解为:
账号 + 密码拥有它的人就能调用你的模型额度。
因此:
❌ 不要发给别人
❌ 不要提交到 GitHub
❌ 不要直接写进代码
三、使用 OpenAI SDK 调用通义千问
很多同学会有一个误区:
通义千问为什么使用 OpenAI 库调用?
原因是:
阿里云百炼兼容 OpenAI API 标准。
因此可以直接使用 OpenAI 官方 SDK。
3.1 安装依赖
pip install openai3.2 最简单的调用示例
python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "system",
"content": "你是一个乐于助人的助手"
},
{
"role": "user",
"content": "你是谁"
}
],
stream=True
)
for chunk in completion:
print(chunk.choices[0].delta.content, end="", flush=True)
print()四、理解大模型对话格式
在 OpenAI API 中,对话由多个消息组成。
格式如下:
python
messages = [
{"role": "system", "content": "..."},
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."}
]4.1 System(系统角色)
用于设定 AI 的身份和规则。
例如:
python
{
"role":"system",
"content":"你是一个只会说中文的助手"
}作用:
定义身份
定义规则
约束回答风格整个对话过程中持续生效。
4.2 User(用户角色)
用户提出的问题。
例如:
python
{
"role":"user",
"content":"介绍一下人工智能"
}4.3 Assistant(助手角色)
AI 之前给出的回答。
用于实现多轮对话。
例如:
python
{
"role":"assistant",
"content":"人工智能是..."
}4.4 工作流程
python
System
↓
User
↓
Assistant
↓
User
↓
Assistant本质上就是不断向模型提交完整历史消息。
五、流式输出(Streaming)
调用模型时有一个重要参数:
stream=True流式输出
stream=True效果:
边生成边返回类似:
你
好
,
我
是
...用户体验更好。
非流式输出
python
stream=False效果:
等待全部生成完成
↓
一次性返回当回答较长时等待时间明显增加。
两者对比
| 参数 | 特点 |
|---|---|
| stream=True | 实时返回 |
| stream=False | 完整返回 |
实际项目中大部分都会使用流式输出。
六、环境变量管理 API Key
很多初学者会这样写:
api_key="sk-xxxxxxxxxxxx"虽然简单,但非常危险。
如果代码上传 GitHub:
API Key 泄露
↓
额度被盗刷
↓
账户损失正确做法:环境变量
Linux / Mac
编辑:
~/.bashrc或者:
~/.zshrc添加:
python
export OPENAI_API_KEY=你的key
export DASHSCOPE_API_KEY=你的key执行:
source ~/.bashrc使配置立即生效。
Windows
打开:
系统属性
↓
高级系统设置
↓
环境变量
↓
新建添加:
OPENAI_API_KEY
DASHSCOPE_API_KEY即可。
Python 中读取
python
import os
api_key = os.environ.get(
"DASHSCOPE_API_KEY"
)这样代码中不会出现敏感信息。
七、Ollama:本地部署大模型
除了云端模型外,还可以在自己的电脑上运行大模型。
最流行的方案就是:
Ollama7.1 什么是 Ollama?
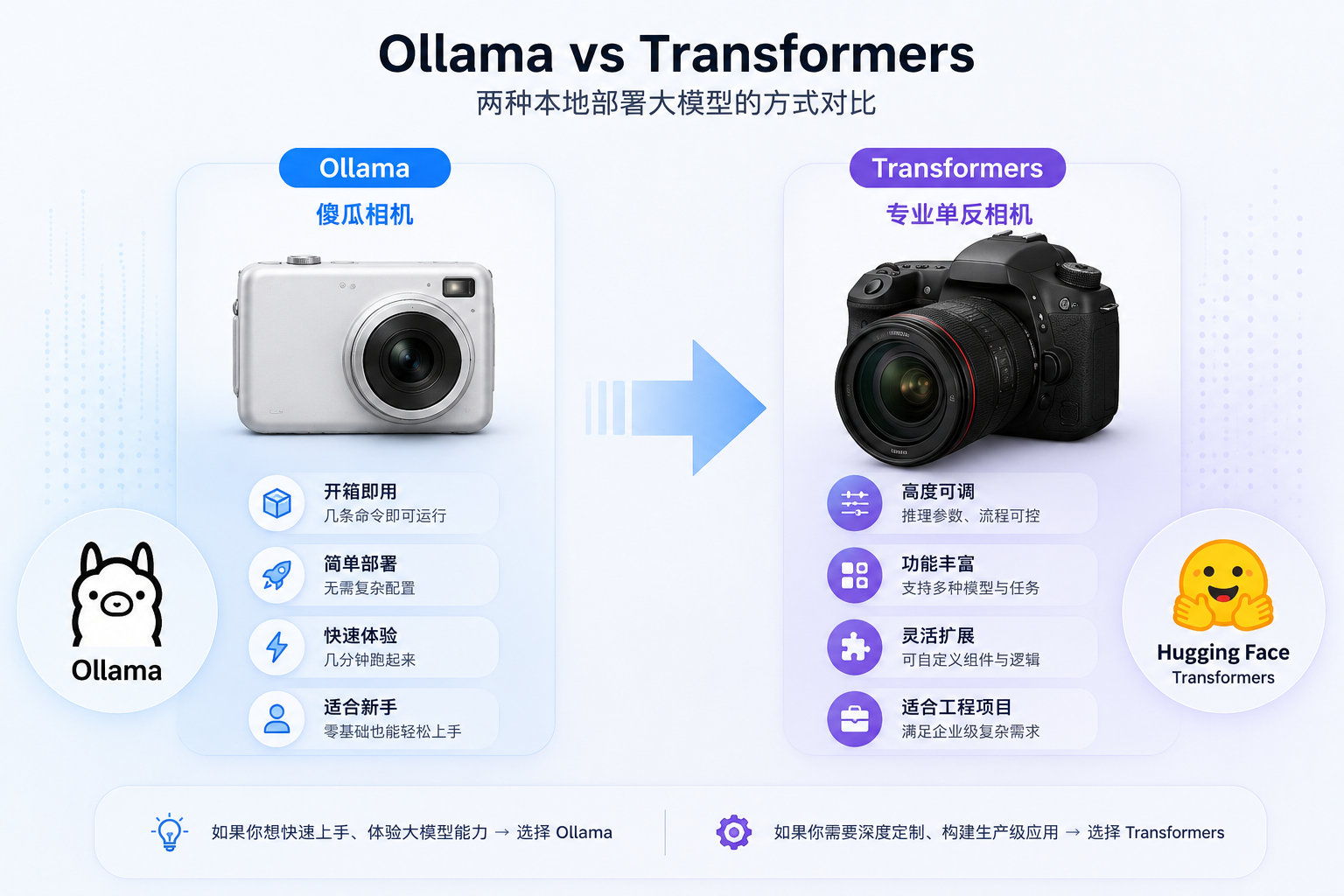
简单理解:
阿里云百炼 = 云端模型平台
Ollama = 本地模型平台区别:
| 项目 | 百炼 | Ollama |
|---|---|---|
| 运行位置 | 云端 | 本地 |
| 是否联网 | 需要 | 不需要 |
| 模型维护 | 官方负责 | 用户负责 |
| 算力来源 | 云服务器 | 自己电脑 |
7.2 常见模型
Ollama 支持大量开源模型:
| 模型 | 特点 |
|---|---|
| Qwen | 中文能力优秀 |
| DeepSeek-R1 | 推理能力强 |
| Llama | Meta 开源模型 |
| Phi-4 | 微软轻量模型 |
参数量含义
例如:
1.5B
7B
14B
32B
70BB = Billion(十亿参数)
一般规律:
参数越大
↓
能力越强
↓
资源消耗越高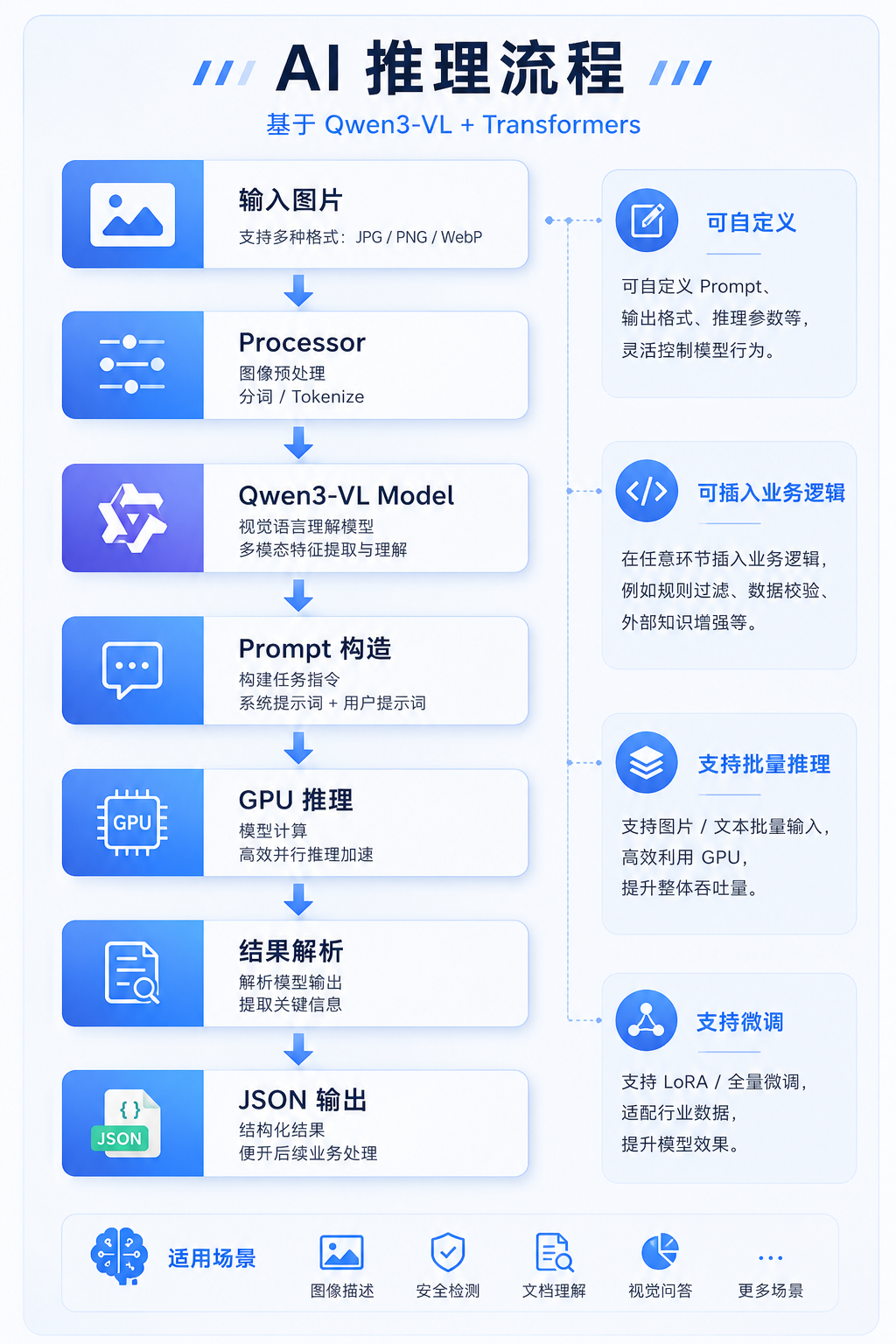
八、安装 Ollama
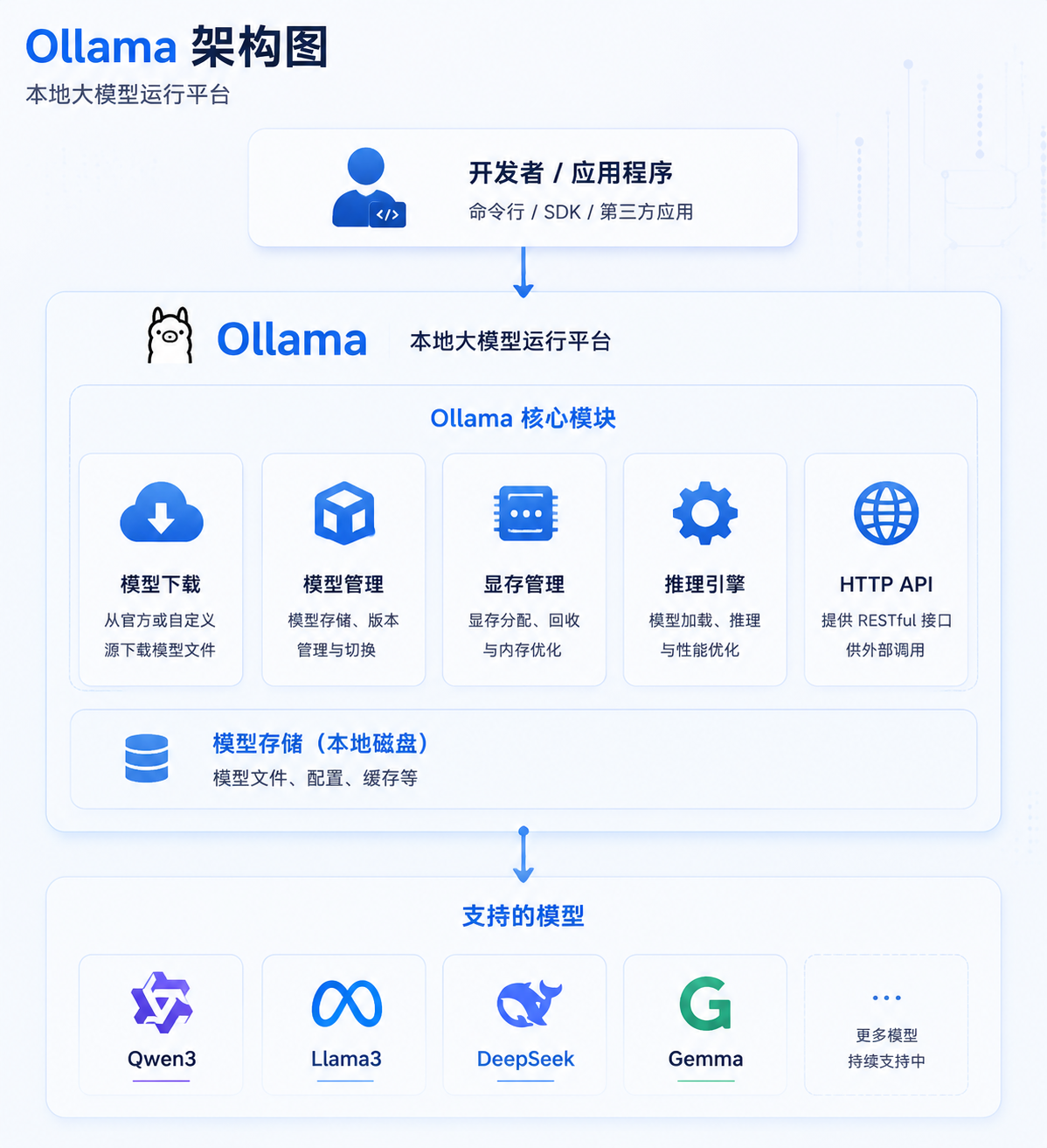
官网:
https://ollama.com下载安装完成后即可使用。
下载并运行模型
例如:
ollama run deepseek-r1:1.5b首次运行会自动下载。
下载完成后即可直接聊天:
>>> 你是谁查看已安装模型
ollama list输出示例:
NAME
deepseek-r1:1.5b
qwen3:8b
llama3:8b九、代码调用本地 Ollama
有趣的是:
调用本地模型与调用云端模型几乎完全一致。
云端版本
python
client = OpenAI(
api_key=os.environ.get("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)本地版本
python
client = OpenAI(
api_key="ollama",
base_url="http://localhost:11434/v1",
)调用代码
python
completion = client.chat.completions.create(
model="deepseek-r1:1.5b",
messages=[
{
"role":"user",
"content":"你好"
}
]
)除了:
api_key
base_url
model其它代码完全一致。
十、本章总结
本章主要完成了大模型开发环境的搭建,并掌握了两种主流调用方式。
整体架构如下:
云端调用流程
Python代码
↓
OpenAI SDK
↓
阿里云百炼API
↓
通义千问模型
↓
返回结果本地调用流程
Python代码
↓
OpenAI SDK
↓
Ollama服务
↓
本地模型
↓
返回结果核心知识点速记
| 知识点 | 关键内容 |
|---|---|
| API Key | 身份凭证,必须妥善保管 |
| Environment Variable | 推荐存储密钥方式 |
| System | 定义角色和规则 |
| User | 用户输入 |
| Assistant | 模型历史回复 |
| Stream | 流式输出 |
| Ollama | 本地运行大模型 |
| Base URL | 决定请求发送到哪里 |
写在最后
这一章属于整个 RAG 与 Agent 学习路线的基础篇。
虽然内容不复杂,但后续所有内容------包括 Prompt Engineering、LangChain、RAG 知识库、Agent 工具调用------都建立在这一章的基础之上。
如果你是第一次接触大模型开发,建议亲手完成以下实践:
-
成功调用一次通义千问 API
-
配置环境变量管理 Key
-
安装并运行 Ollama
-
用同一套代码切换云端和本地模型
完成这些之后,再进入下一章《OpenAI SDK 基础与提示词工程》,学习如何编写高质量 Prompt 和实现多轮对话。
系列文章:
-
第01章:前置准备(本文)
-
第02章:OpenAI库基础与提示词工程(更新中)
-
第03章:LangChain基础(待更新)
-
第04章:RAG知识库实战(待更新)
-
第05章:Agent智能体开发(待更新)