文章目录
- 前言
- [一、 哨兵集群的核心架构与三大常态监控](#一、 哨兵集群的核心架构与三大常态监控)
- [二、 主观下线(SDOWN)与客观下线(ODOWN)](#二、 主观下线(SDOWN)与客观下线(ODOWN))
-
- [1. 主观下线(Subjectively Down, SDOWN)](#1. 主观下线(Subjectively Down, SDOWN))
- [2. 客观下线(Objectively Down, ODOWN)](#2. 客观下线(Objectively Down, ODOWN))
- [三、 领头哨兵(Leader)选举](#三、 领头哨兵(Leader)选举)
- [四、 如何挑选新 Master?](#四、 如何挑选新 Master?)
-
- 第一轮:健康度普查(过滤不健康的节点)
- 第二轮:优先级对比(`replica-priority`)
- [第三轮:数据完整度比拼(复制偏移量 `Offset`)](#第三轮:数据完整度比拼(复制偏移量
Offset)) - [第四轮:终极绝杀(进程 RunID)](#第四轮:终极绝杀(进程 RunID))
- [五、 状态传播与通知](#五、 状态传播与通知)
- 总结
前言
在前面的文章中,我们深入探讨了 Redis 的主从复制架构,它完美解决了数据的多副本冗余和读写分离问题。然而,主从复制存在一个致命的痛点:一旦主节点(Master)宕机,集群将直接丧失写能力,必须人工介入将某个从节点(Replica)手动提拔为主节点。
为了实现真正意义上的 7x24小时高可用(HA) ,Redis 引入了哨兵模式(Sentinel)。
哨兵模式的核心任务就是化身为集群的"监控卫士",在主节点发生故障时,自动完成主观下线、客观下线、哨兵Leader选举、新主选拔及状态传播 的全套自动化故障转移流程。本文将带你逐一拆解这背后的底层运转逻辑。
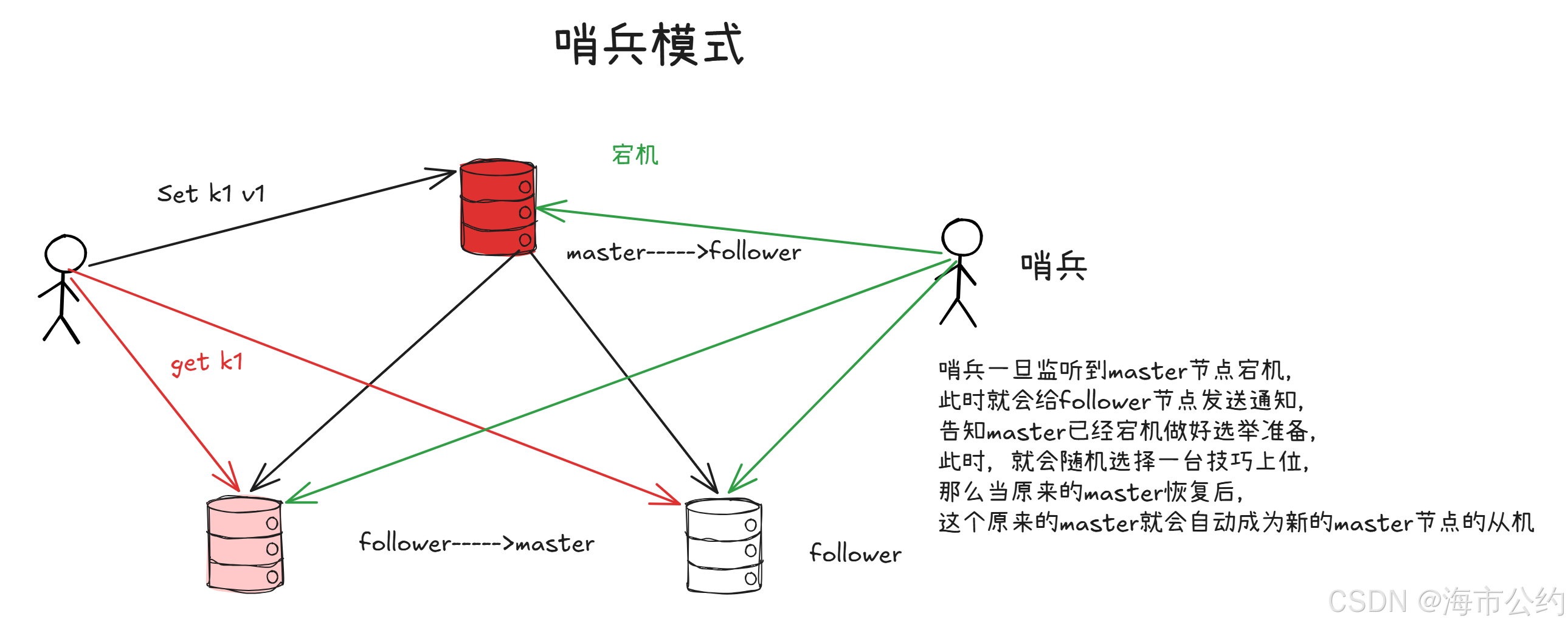
一、 哨兵集群的核心架构与三大常态监控
在生产环境中,为了防止哨兵自身单点故障以及"误报"主节点宕机,哨兵通常也是以集群(Cluster)的形式部署的。
每个哨兵实例本质上都是一个特殊的 Redis 节点,它们不存储业务数据,而是通过内部的定时任务机制常态化地监控整个集群:
- 每 10 秒一次(信息搜集) :哨兵向 Master 发送
INFO命令。通过 Master 返回的信息,哨兵可以动态获取当前所有 Slave 节点的最新拓扑结构,从而实现自动发现新加入的从节点。 - 每 2 秒一次(内部通信) :哨兵通过 Master 和 Slave 节点的
__sentinel__:hello发布/订阅(Pub/Sub)频道交换信息。利用这一机制,哨兵之间可以互相感知对方的存在,并分享各自对 Master 的状态评估。 - 每 1 秒一次(心跳保活) :这是最核心的监控。哨兵向 Master、Slave 以及其他哨兵发送
PING命令。如果某个节点在down-after-milliseconds配置的时间内没有有效回复,哨兵就会认为该节点出了问题。
二、 主观下线(SDOWN)与客观下线(ODOWN)
当主节点真的出现网络拥堵或者宕机时,哨兵集群是如何一步步给它"判死刑"的?这里有两个层层递进的概念:
1. 主观下线(Subjectively Down, SDOWN)
当哨兵 A 向 Master 发送 PING 命令,如果在配置的时间窗口内连续收不到有效响应,哨兵 A 就会在本地判定:"在我看来,这个 Master 已经挂了"。这就是主观下线。
⚠️ 注意:此时可能仅仅是哨兵 A 自身的网络丢包或抖动,Master 本身是健康的。因此,单凭主观下线绝对不能触发故障转移。
2. 客观下线(Objectively Down, ODOWN)
为了消除单点误判,当哨兵 A 判定 Master 主观下线后,会立即向其他哨兵发送 SENTINEL is-master-down-by-addr 命令,询问其他兄弟:"你们觉得 Master 挂了吗?"
- 每一个收到询问的哨兵会根据自己当前的心跳结果进行投票。
- 当赞成 Master 挂掉的哨兵数量达到了配置文件中设定的**法定人数(Quorum 值,通常设为 哨兵总数/2 + 1)*时,Master 就会被标记为*客观下线。
- 一旦达成客观下线共识,整个集群就会正式拉响警报,开启故障转移。
三、 领头哨兵(Leader)选举
Master 判定客观下线后,接下来必须由一个具体的哨兵去执行"把 Slave 提拔为 Master"的物理操作。如果所有哨兵同时去指挥,必然导致乱套。因此,必须先在哨兵集群中选出一个 Leader(领头羊)。
Redis 采用了类似于 Raft 协议 的领头羊选举算法:
- 率先发现 Master 客观下线的哨兵(假设是哨兵 A)会立刻向其他哨兵发起申请,要求成为 Leader(为自己拉票)。
- 每个哨兵在这一轮选举中只有一张选票,原则是"先到先得",谁先申请就投给谁。
- 胜出条件 :一个哨兵想要成功当选 Leader,必须同时满足两个硬性指标:
- 获得的票数必须
≥ Quorum。 - 获得的票数必须 大于哨兵总数的一半(Majority 机制,即
> 哨兵总数/2)。
- 获得的票数必须
- 成功胜出的哨兵 Leader,将独自全权负责接下来的高可用故障转移。
四、 如何挑选新 Master?
现在,哨兵 Leader 站在了所有的 Slave 面前。它的任务是:挑出最完美、数据最完整的一个 Slave,将其任命为新的 Master。
为了确保新 Master 的稳定和数据一致性,Leader 会在本地进行一场严格的"四轮淘汰赛":
第一轮:健康度普查(过滤不健康的节点)
首先,淘汰掉所有已经断线的、或者频繁断线的从节点。如果某个 Slave 与原 Master 断开连接的时间超过了 down-after-milliseconds * 10,直接取消参赛资格(因为它的数据太旧了)。
第二轮:优先级对比(replica-priority)
Redis 允许我们在配置文件中为不同的从节点配置静态优先级 replica-priority(默认是 100)。
- 哨兵会优先选择这个值最小的 Slave(值越小优先级越高)。
- 注:如果某节点的优先级配成了 0,代表它永远不参与 Master 的选举。
第三轮:数据完整度比拼(复制偏移量 Offset)
如果大家的优先级一样大,那就比谁的数据更全。
- 哨兵会去查看所有 Slave 的
slave_repl_offset(复制偏移量)。 - Offset 最大的那个 Slave 胜出。因为 Offset 最大意味着它从旧 Master 那里同步过来的写命令最完整,提拔它能最大限度地避免数据丢失。
第四轮:终极绝杀(进程 RunID)
如果在极罕见的情况下,连数据进度也完全一样,那就只能进行物理上的无情绝杀:
- 哨兵会对比每个 Slave 的
RunID(Redis 启动时随机生成的 40 位十六进制字符串)。 - 选择 RunID 字典序最小的那个 Slave。
五、 状态传播与通知
挑出了天选之子(假设是 Slave-1)后,哨兵 Leader 开始下达行政命令,正式改变集群的物理拓扑结构:
- 封官加爵 :Leader 向 Slave-1 发送
SLAVEOF NO ONE命令,命令其断开与旧 Master 的主从关系,正式翻身做主人,升级为全新的 Master。 - 诸侯归顺 :Leader 向其余所有的 Slave 节点发送
SLAVEOF <新Master_IP> <新Master_Port>命令,让它们立刻转头去向新的 Master 顶礼膜拜、建立新的主从复制连接。 - 安抚旧部 :那原先挂掉的旧 Master 怎么办?哨兵并没有忘记它。哨兵会将其保存在自己的监控名单中,一旦发现这个旧 Master 恢复健康重新上线,哨兵会立刻强制给它发送
SLAVEOF命令,将其拍扁成一个普通的 Slave,去复制新 Master 的数据。 - 通知客户端 :在整个故障转移期间,哨兵会通过消息通知(如支持 Sentinel 的客户端连接池),将最新的 Master 节点地址同步给客户端应用,整个过程对业务代码来说几乎是完全透明的。
总结
Redis 哨兵模式的核心美学在于"自动化的一致性决策"。它通过:
- 1秒一次的心跳 发现问题;
- Quorum 法定人数 确认问题(客观下线);
- Majority 过半机制 选举 Leader;
- 优先级 ➡️ Offset ➡️ RunID 的严密路径筛选出最完美的新 Master。