MiniMax 正式发布了 M3。官方给它的定位是:Coding / Agent、1M 上下文、原生多模态。
正式发布前几天,我看有人发消息说可以进 M3 内测群,然后我就进去了,我以为是内测一段时间再发布,但没想到今天就发布了,那这个内测群,除了提供 7 天免费试用之外,别的好像也没啥用处了。
我身边有个小伙伴一直在做模型测评,这次他史无前例的夸赞了一下 M3 ,这个榜单就一个让我注意的点,那就是 M3 竟然比 opus4.6 分数还高。。。。。。
MiniMax M3 Free 排第 4,88 分,A+。前面是 GPT 5.5 xhigh、Claude 4.7 Opus Max 和 Gemini 3.1 Pro。单看分数,它确实已经贴近 Opus 4.7 那一档了。
但是同一行还有一个很扎眼的备注:慢,7m51s。
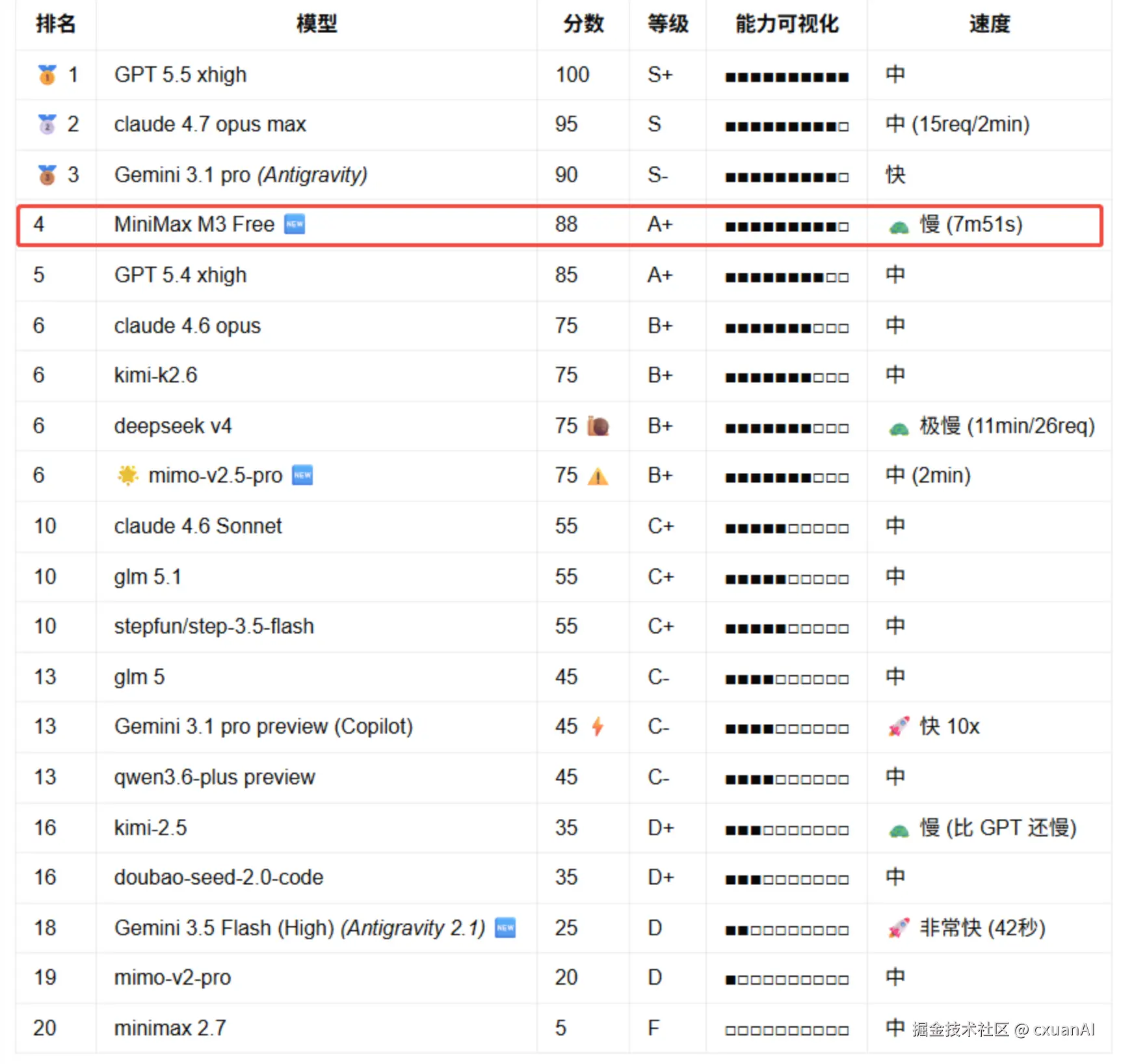
图源:身边小伙伴的测评图。
所以这篇不想写成"国产模型吊打 Opus"的爽文。那种写法就是跑分没输过,体验没赢过。
所以我更关心的问题是:M3 到底在哪些体验上接近 Opus 4.7,又在哪些体验上还不能脑补成 Opus 4.7?
这次发布的重点,不是又多了一个模型
这和过去很多国产模型发布不太一样。
以前大家喜欢比单点能力:数学多少分、代码多少分、长文本多少 token。但 M3 这次讲的是组合能力。它不是只想回答一道题,而是想进到一个长程工作流里,连续读代码、看日志、调工具、改方案、再继续跑。

图源:我自己绘制,数据来自 MiniMax 官方博客和模型页。
官方博客里有几个关键数字:
SWE-Bench Pro 59.0%,Terminal-Bench 2.1 为 66.0%,SWE-fficiency 34.8%,KernelBench Hard 28.8%,MCP Atlas 74.2%。
这些数字单独看,不一定有体感。真正有体感的是官方那句话:在 SWE-Bench Pro 上,M3 超过 GPT-5.5 和 Gemini 3.1 Pro,接近 Opus 4.7;在 SVG-Bench 上,M3 超过 Opus 4.7。
注意,是 接近,不是全面等同。
接近 Opus,接近在哪里
我倾向于把这个"接近"限定在一个范围里:Coding / Agent 的长程任务体验。
因为从官方材料看,M3 这次最想证明的不是"我会写一个函数",而是"我能在一个复杂任务里持续推进"。这正是 Opus 这类模型过去最拉开差距的地方。
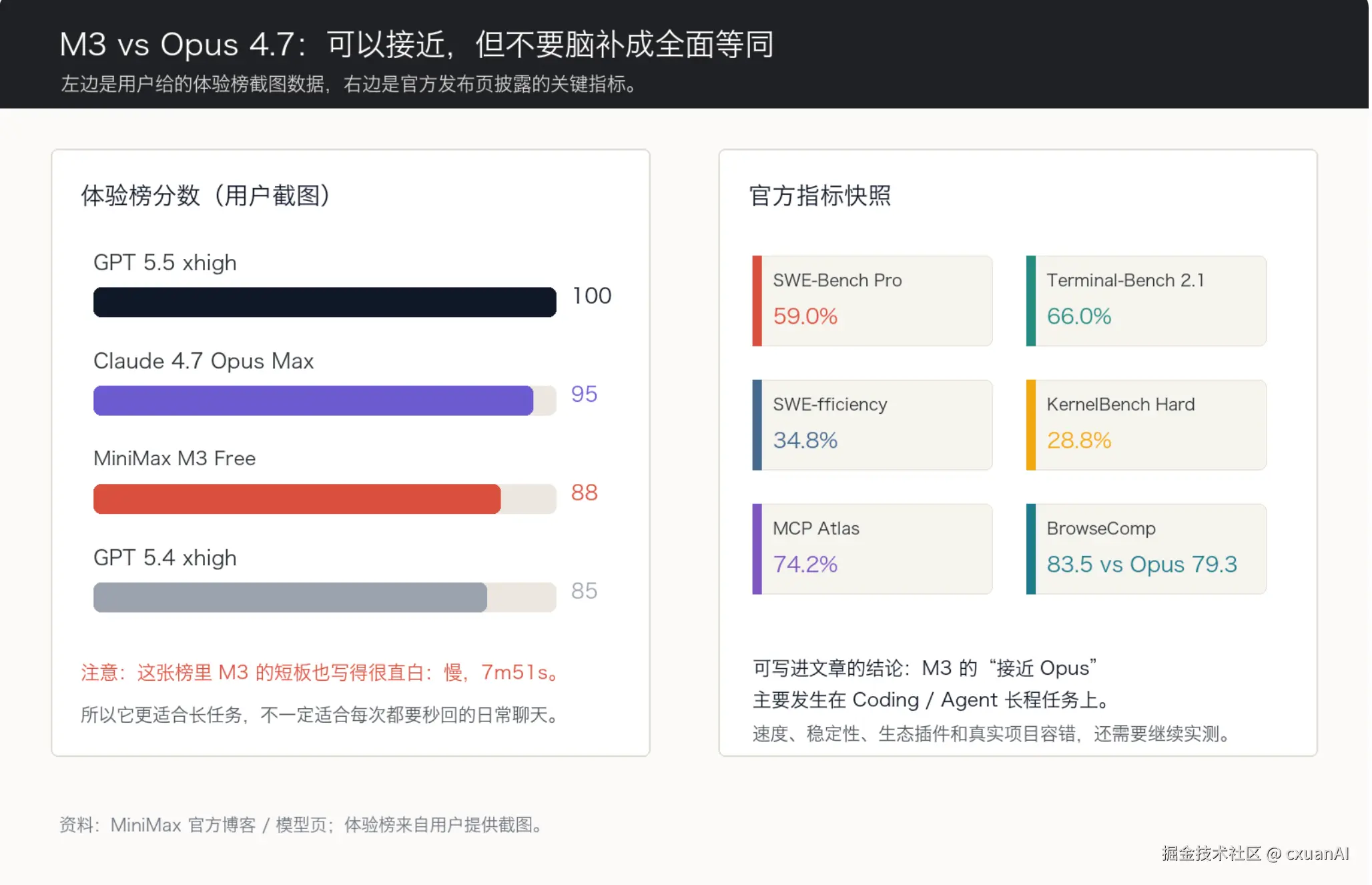
图源:我自己自制;体验榜来自用户截图,官方指标来自 MiniMax 发布页。
模型页还给了一个很有意思的点:BrowseComp 上 M3 得分 83.5,Opus 4.7 是 79.3。也就是说,至少在官方口径下,M3 在自主浏览、信息检索这类 Agent 能力上已经能和 Opus 4.7 正面比较。
但是体验榜里的慢,也不能忽略。
如果你的场景是日常聊天、快速问答、随手补一段代码,7 分多钟就是硬伤。你不能因为一个模型能跑 24 小时,就假装它每次响应都很丝滑。
所以我的第一判断是:M3 更像一个可以挂后台跑任务的工程型模型,而不是一个每句话都要秒回的聊天模型。
1M 上下文不是为了炫技
官方这次反复讲 MSA,也就是 MiniMax Sparse Attention。
简单说,它想解决的是长上下文成本爆炸的问题。官方称,M3 API 最高支持 1M tokens,上下文保底 512K。在 100 万上下文长度下,M3 每 token 计算量只有上一代模型的 1/20,prefill 加速超过 9 倍,decoding 加速超过 15 倍。
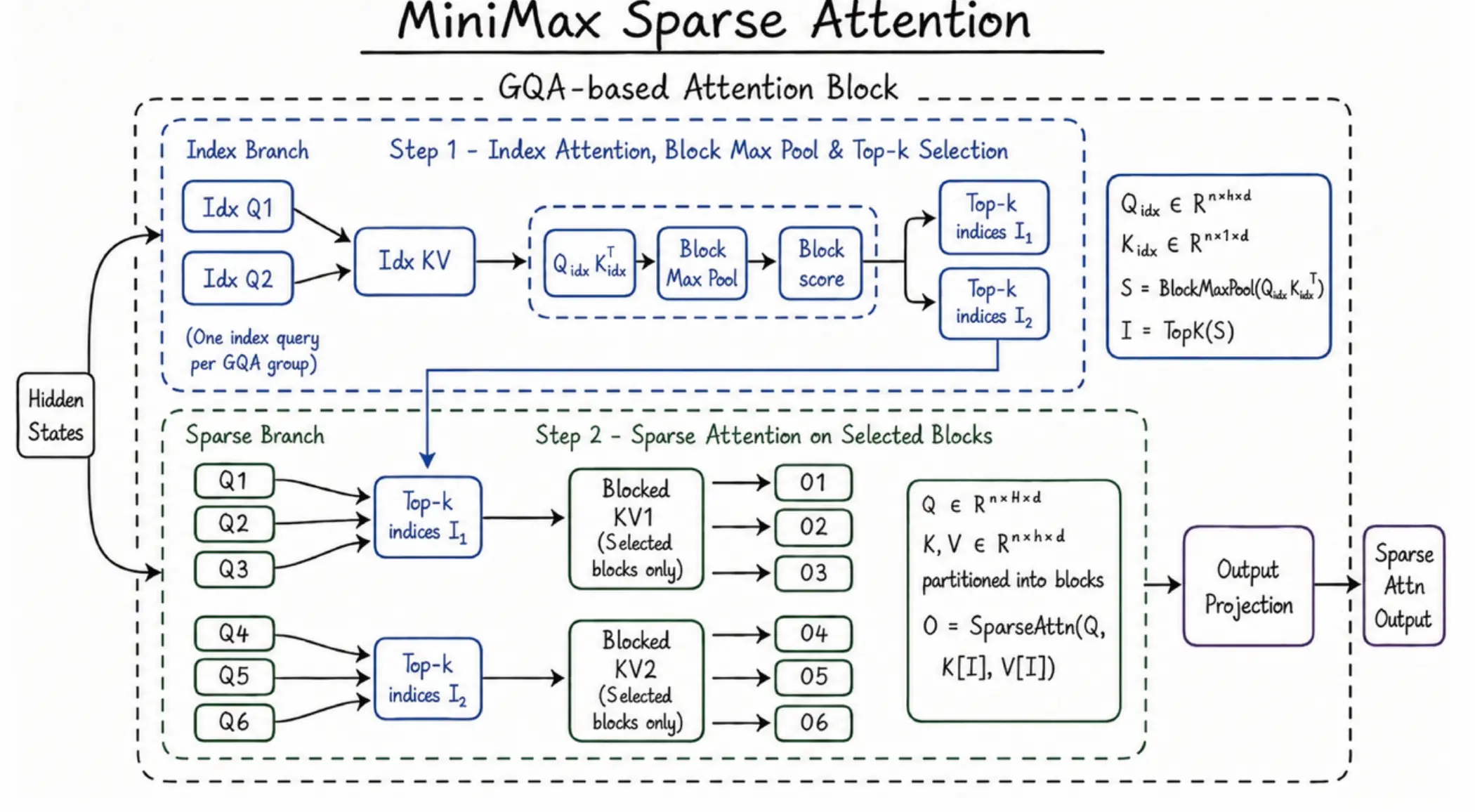
图源:MiniMax 官方博客。
这听起来很技术,但到了 Coding Agent 场景里却很现实。
一个真实开发任务里,上下文不是一篇 PDF。它是仓库结构、历史改动、用户中途改需求、测试日志、失败原因、工具调用记录、代码审查意见,还有 Agent 自己前面做过的判断。
模型一旦漂移之后,就会开始重复劳动。
你让它修 bug,它前面已经排除过 A 方案,过了几十轮又把 A 方案拿出来试一遍。你让它改 UI,它前面已经知道不要用某个组件,后面又手痒加回去。这种体验比单纯写错代码更让人头皮抓马。
所以 M3 的 1M context 真正要解决的是 Agent 在长任务里能不能记得自己为什么走到这里。
官方博客里有三个任务,我觉得比大多数 benchmark 更值得看。
第一个是论文复现。MiniMax 把一篇 ICLR 2025 Outstanding Paper Award 论文《Learning Dynamics of LLM Finetuning》丢给 M3,让它独立复现。官方说 M3 连续跑了接近 12 小时,产出 18 次 commit 和 23 张实验图,跑通了核心实验。
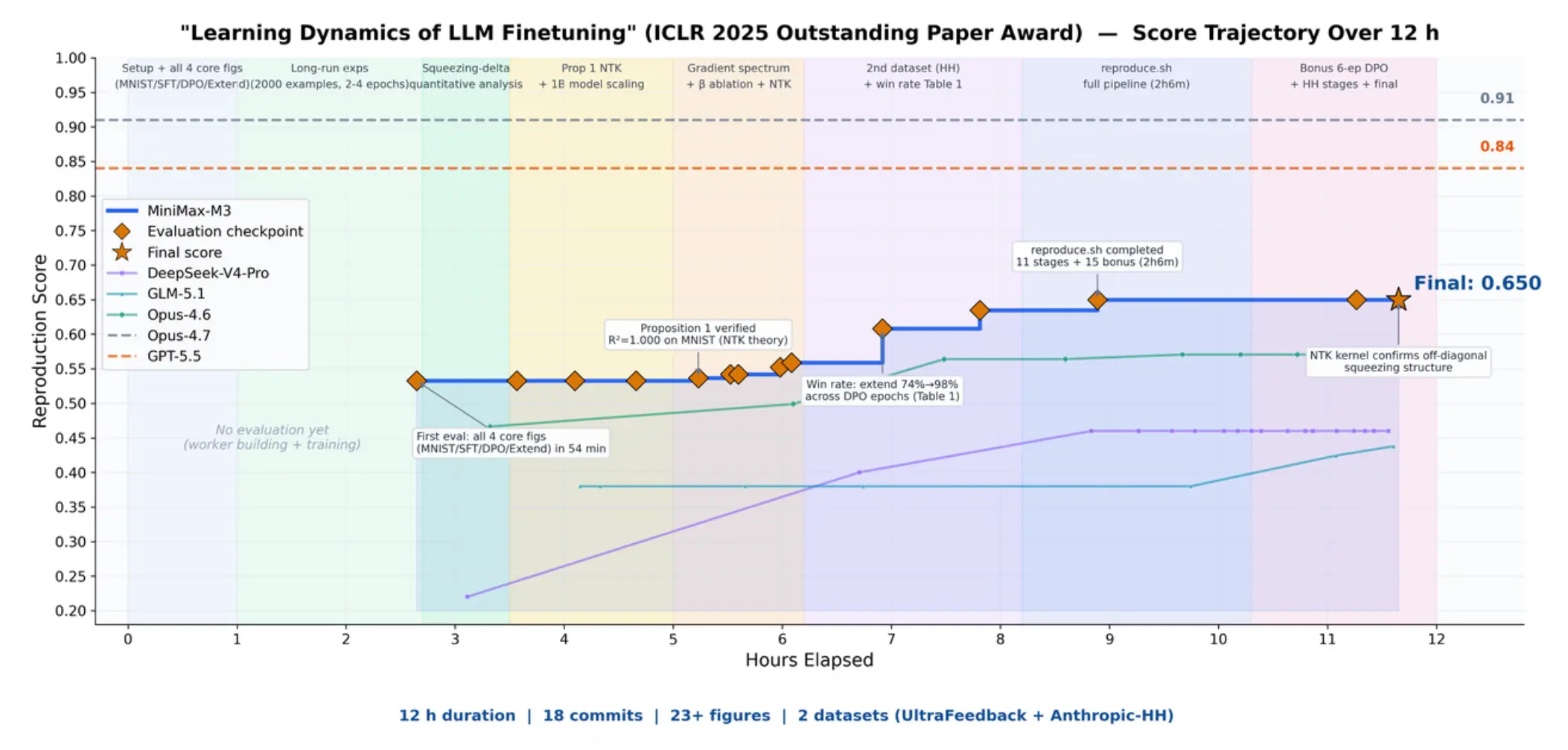
图源:MiniMax 官方博客。
第二个是 CUDA 算子优化。
这个任务更硬一点。起点是一份任务描述、一个 benchmark 脚本、一个不能直接运行的 Triton 骨架,没有高性能参考实现。M3 在约 24 小时里完成 147 次 benchmark 提交、1,959 次工具调用,把 Hopper FP8 GEMM 的硬件峰值利用率从 7.6% 推到 71.3%,相当于 9.4 倍加速。
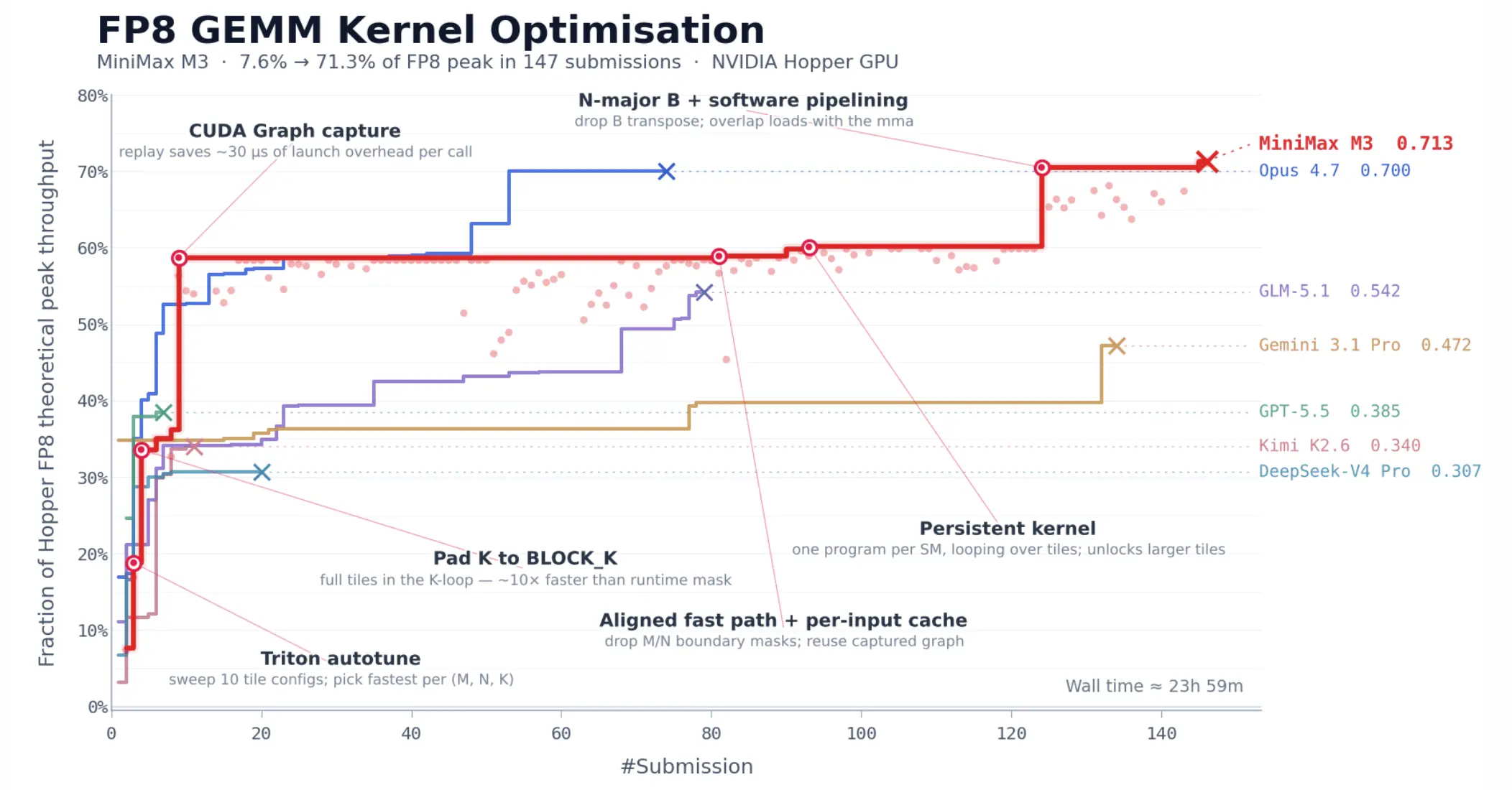
图源:MiniMax 官方博客。
第三个是 PostTrainBench。它要让 M3 在 12 小时里给 4 个只预训练过的 Base 模型做数据合成、训练、评测、迭代。官方给出的结果是 M3 得分 0.37,略低于 Opus 4.7 的 0.42 和 GPT-5.5 的 0.39,但明显领先其他模型。

图源:我自己绘制,数据来自 MiniMax 官方博客。
这里我会加一个保守备注:这些都是官方自测,不是独立第三方复现。
但是它们的方向是对的。因为真正的 Agent 测评,不能只问"最后答案对不对",还要看它能不能在反馈稀疏、路径不清晰、上下文越来越脏的时候继续工作。
这个能力,过去是 Opus 这类模型最贵的地方。
M3 还有一个不能绕开的卖点:价格和可用量。
官方同步调整了 MiniMax Token Plan:Plus 49 元每月 6 亿 token,Max 119 元每月 18 亿 token,Ultra 469 元每月 55 亿 token。官方说按相同价格算,约是 Claude 订阅的 15 倍用量。
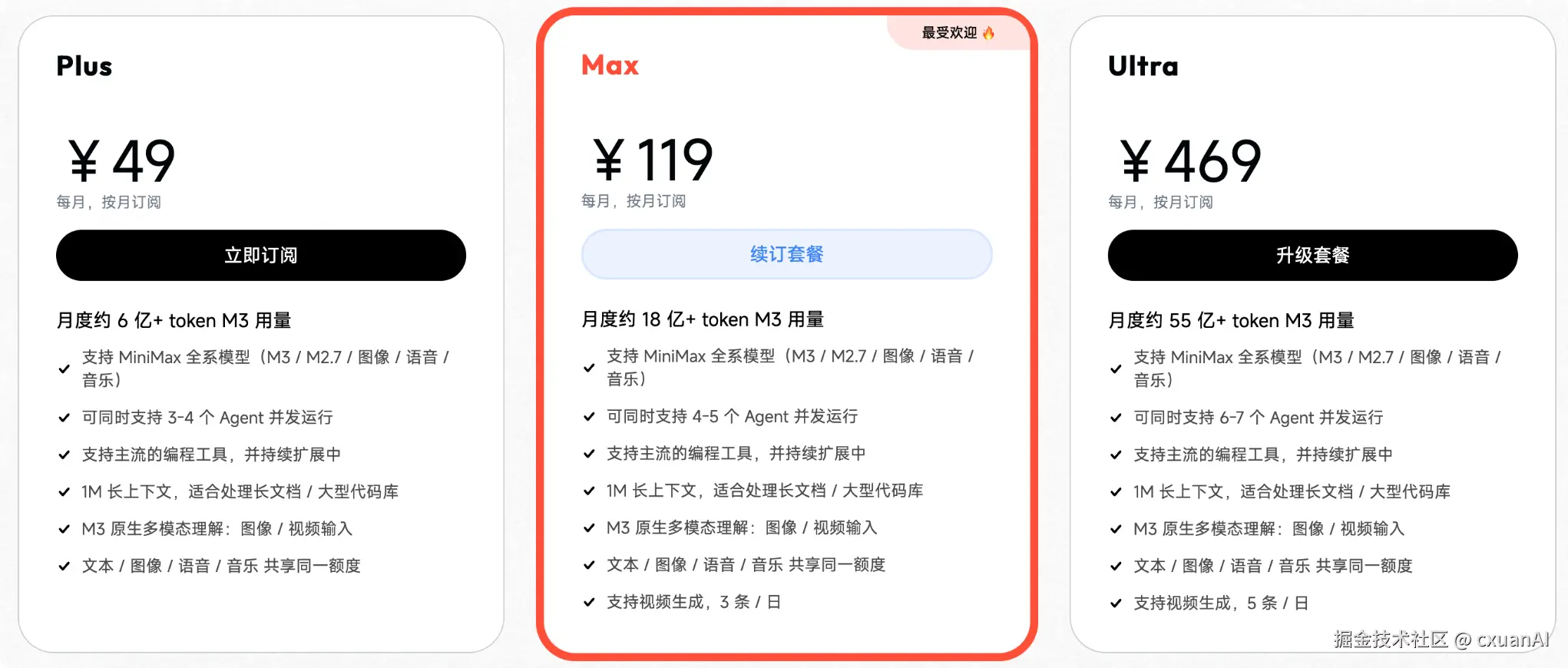
图源:MiniMax 官方博客。
这就是为什么它哪怕慢,也依然有吸引力。
Opus 级别模型的问题不是只贵一点,而是你不敢让它随便跑。一个长程 Agent 任务动不动就是几十万、几百万 token,价格会直接决定你敢不敢把任务交给它。
M3 如果能把"接近 Opus 的长程能力"压到一个更日常的成本里,那它的意义就不是模型排行榜上多一个 A+,而是让开发者真的开始把 Agent 当做首选。
不过这里也要留一手。官方博客说接下来 10 天内会更新技术报告,并开源对应模型权重;模型页也写了会在 HuggingFace 和 GitHub 上开放,支持私有集群部署和微调。
也就是说,现在可以先体验,但开源权重、技术报告、第三方复测,还要等官方继续补齐。
我的结论
如果"体验接近 Opus 4.7"指的是:它在 Coding / Agent 长程任务里能理解大目标、保留上下文、持续调用工具、在多轮失败后继续推进,那这个说法有依据。
如果"体验接近 Opus 4.7"指的是:它每个场景都和 Opus 一样稳、一样快、一样会兜底,那就吹过了。
M3 这次真正有价值的地方,是把 Frontier 模型过去最昂贵的一部分能力,往开发者日常里推了一步。它不一定替代 Opus,但它可能会改变很多人的用法。
以前你会把 Opus 留给关键任务来做。
现在你可能会把 M3 挂到一个真实仓库里,让它跑一下午,看看它第 145、220、500 次尝试的时候还会不会继续想办法。
这才是 M3 这次最值得测的地方。
如果你已经拿 M3 跑过真实仓库,尤其是跑过 1 小时以上的任务,欢迎把"慢在哪里、稳在哪里、崩在哪里"的样本丢给我。这个模型最该看的不是首轮回答,是长线程后半段。
资料来源:
- MiniMax 官方博客:MiniMax M3:前沿 Coding 能力,1M上下文,原生多模态,一个模型全给你
- MiniMax 模型页:MiniMax M3
- OpenRouter 模型页:MiniMax M3 - API Pricing & Providers
- 用户提供的体验榜截图
MiniMax #M3 #Coding #Agent #Opus
标签只是归档,真正值得看的还是下一轮真实项目样本。