在数字能源与新型电力系统建设背景下,电力现货市场价格预测(Price Forecasting)和储能充放电策略优化成为了当下最火热的交叉赛道之一。本文通过矩池云 energy forecasting 镜像几分钟内快速搭建环境,彻底跑通 AI 电价预测与储能策略的 Baseline,并手把手教你如何通过特征工程与稳健策略进行进阶优化。
PART.01为什么选择矩池云 energy forecasting 镜像?
在处理时序预测和气象网格数据(如 .nc 文件)时,复杂的依赖库(如 netCDF4、xgboost、lightgbm、scikit-learn 等)往往让新手在搭建环境时抓狂。
矩池云预装的 energy forecasting 镜像 已经完美集成了能源电力预测所需的所有科学计算、机器学习算法以及时序分析工具,真正实现了开箱即用 。无需再为 pip install 报错浪费时间,让我们能把核心精力聚焦在算法本身。
PART.02 核心实战:四步跑通baseline
1、启动实例:登录矩池云市场,租赁4090算力卡,选择"energy forecasting"镜像;
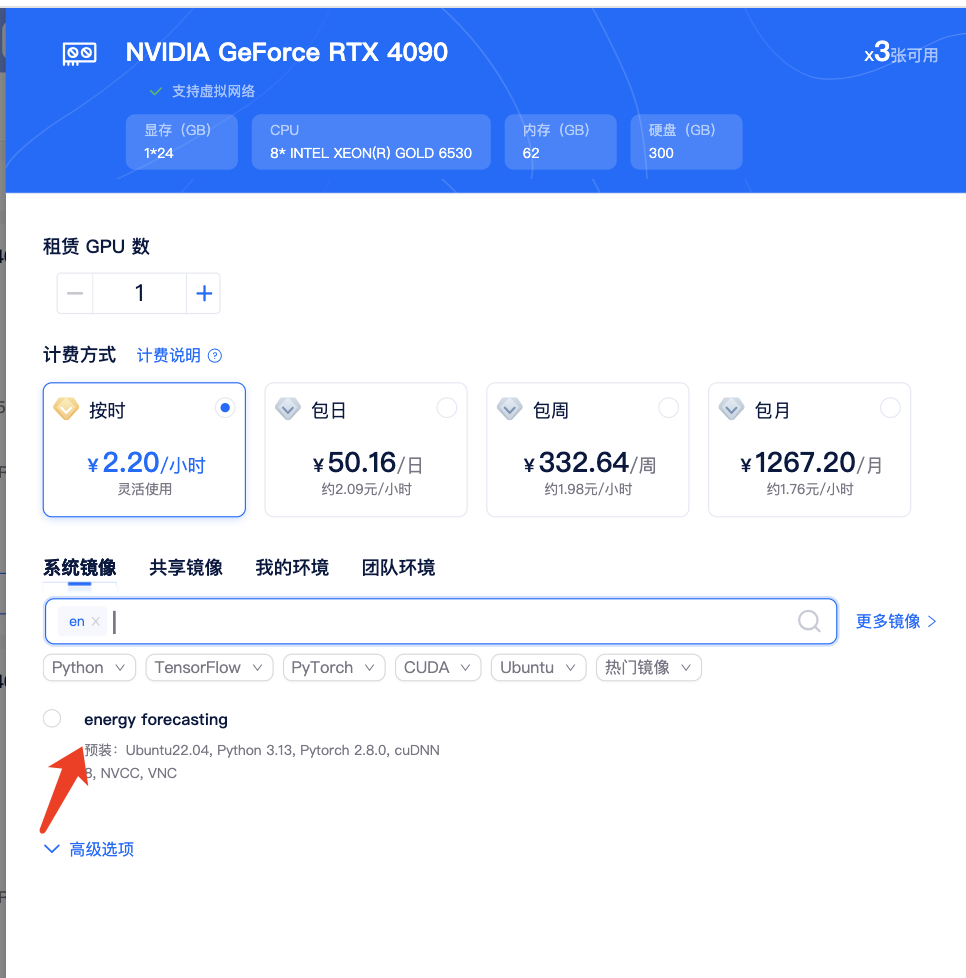
2、运行 Baseline 模型:在终端中复制并运行运行命令
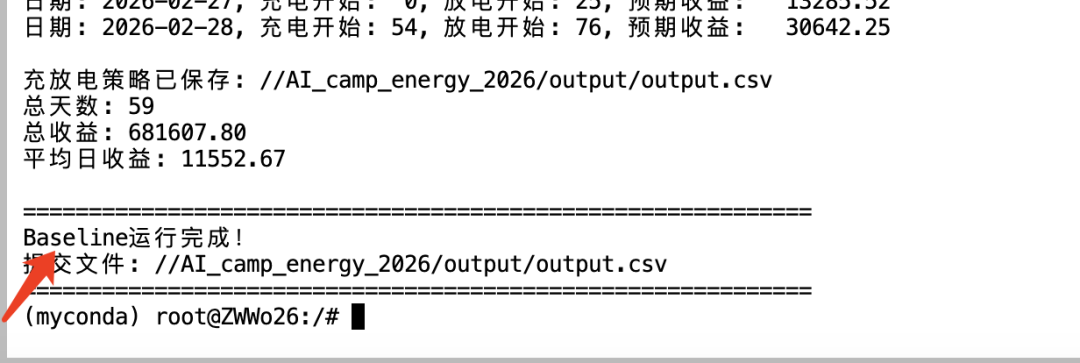
python ./AI_camp_energy_2026/sklearn_baseline.py当看到" Baseline 运行完成! "字样时 ,代表已经成功跑通了全流程 !
3. 查看本地评估指标
运行完成后,终端会输出两个关键的本地评估指标 :
本地的 RMSE 降低 + 平均日收益上涨,真实效果也最好。每次改完代码,先看终端这两个数字再决定是否下载结果。
- 验证集 RMSE:评估模型预测电价的平均误差,数值越小越好(越接近0代表预测越准)
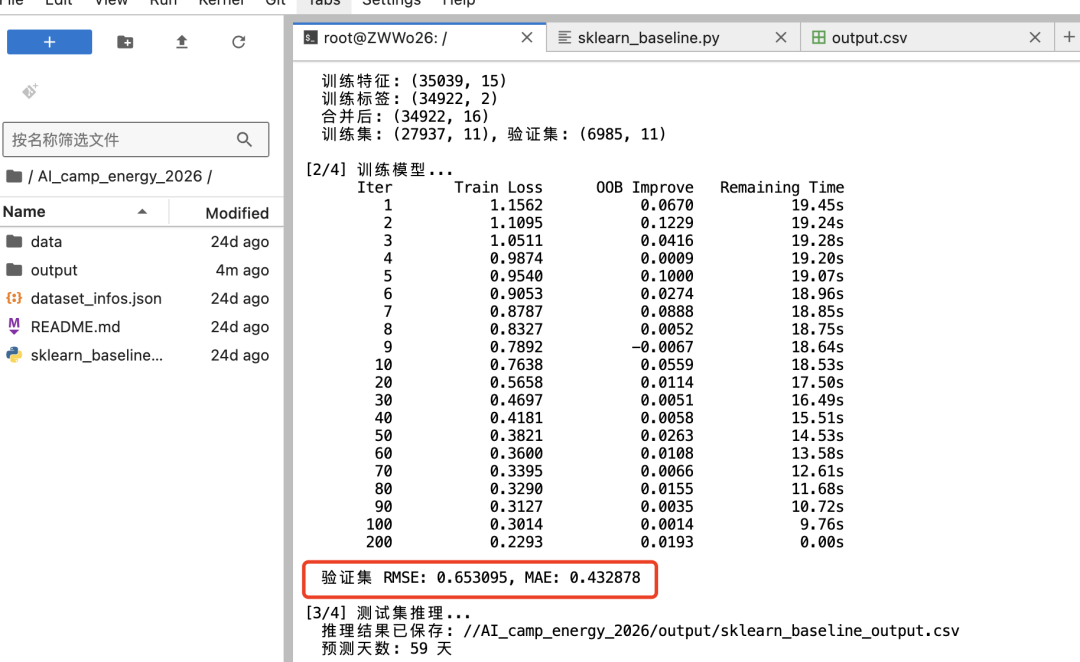
- 平均日收益:基于当前预测电价,执行基础储能充放电策略所获得的日均收益,数值越大越好 。
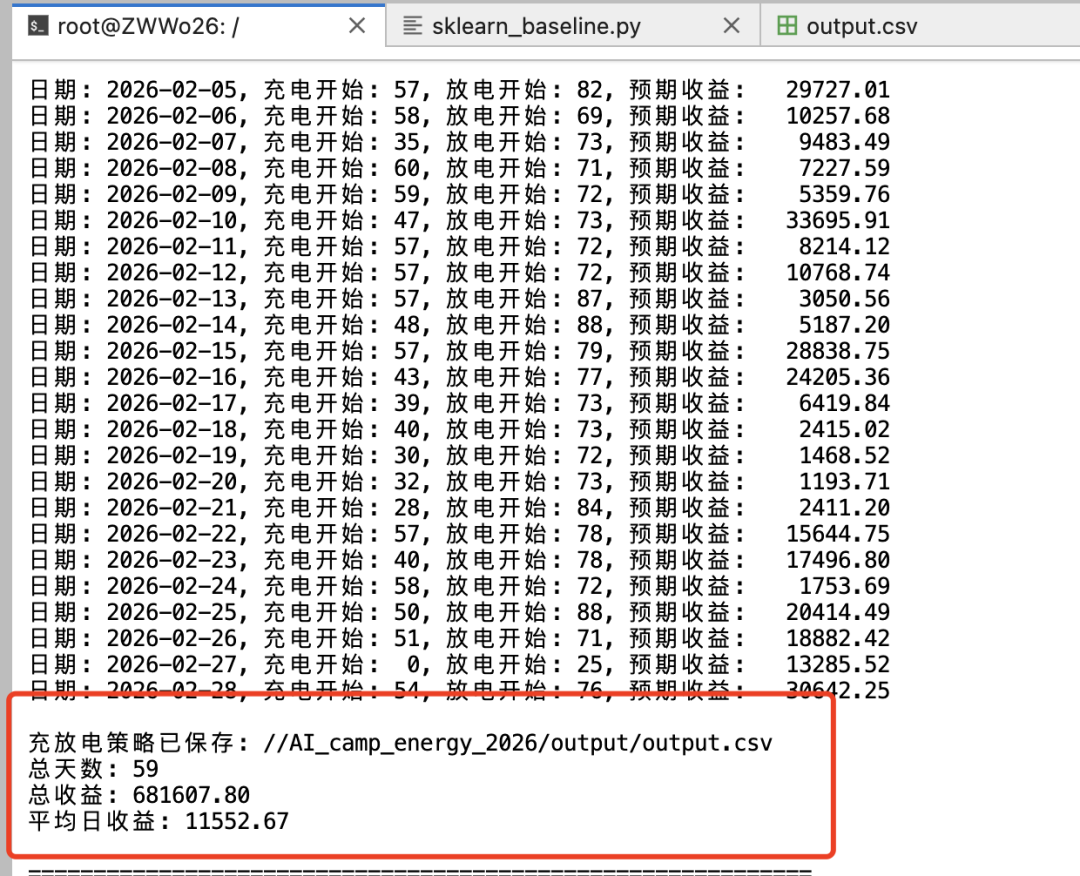
4. 导出结果文件
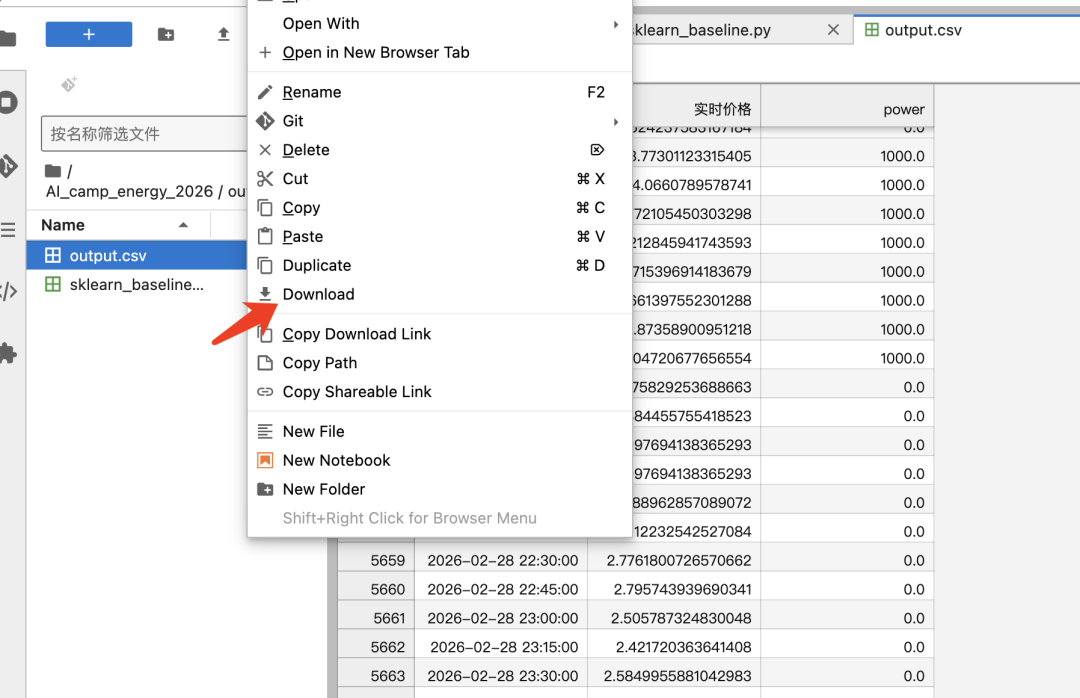
运行生成的充放电策略结果会自动保存在 AI_camp_energy_2026/output/output.csv。在 JupyterLab 左侧文件浏览器中找到该文件,右键点击并选择【Download】,即可下载到本地 。
PART.03 进阶调优方案
虽然 Baseline 能让你快速跑通,但在结构上还非常简单,存在明显的优化空间 :
1、特征过于单一:模型仅使用了 7 个基础的边界条件预测值特征,完全忽略了气象数据(.nc 文件)这一座金矿,同时也缺少时序特征 。
2、算法对时序不感知:默认采用基础的 GradientBoostingRegressor (GBDT) ,它本身是不感知时间顺序的,必须要靠特征工程显式喂给它 。
3、策略过度"死板":充放电策略(默认挑最便宜的连续 8 个时段充电、最贵的连续 8 个时段放电)完全相信了模型的预测结果 。一旦模型预测出现偏差,策略就会跟着翻车 。
方向 1:特征重要性筛选(去噪声)
GBDT 模型自带 feature_importances_ 属性 。我们可以在 sklearn_baseline.py 的 if __name__ == '__main__': 模块代码末尾加入以下几行,来看看到底哪些特征在起作用 :
Python
# 打印特征重要性排序 print("\n特征重要性排序(从高到低):")
bash
print("\n特征重要性排序(从高到低):")
importance = model.feature_importances_
for feat, imp in sorted(zip(all_features, importance), key=lambda x: -x[1]):
print(f" {feat}: {imp:.4f}")注意点 :如果运行后发现有些特征(如 month)的贡献度接近 0 ,可以直接从 all_features 中将其剔除,去除特征噪声,RMSE 通常会进一步下降 。
不会改代码**?** 把这段问 AI:
"我有一段 sklearn_baseline.py代码,想在末尾加几行打印特征重要性。请告诉我具体加在哪一行、缩进怎么处理、加完之后怎么看输出。"
想深入还可以看:
- 排列重要性 (permutation importance):把某个特征的数值故意打乱,看 RMSE 上升多少。上升越多越重要------比feature_importances_更可靠
- 特征相关性热图 :看特征之间是否高度相关(比如"风光总加预测值"和"风电预测值"可能讲的是一回事),两个特征讲同一件事会让模型学得糊涂(共线性问题)
方向 2:引入历史电价的"滞后特征 (Lag Features)"
电价有很强的时序自相关性 ------今天下午 2 点的电价,跟昨天下午 2 点 的电价大概率接近;跟上周同一时刻也有规律。
如果模型知道"昨天这时候电价是 2.5",就能更好地预测"今天这时候电价"。这种用历史值做特征的做法叫滞后特征 (lag features)。
🔰最简单的做法 : 加一个 "1 天前的电价 " 特征
具体怎么算?
1 天 = 24 小时 × 4 = 96 个时段
所以"1 天前同一时刻的电价" = 当前时刻往前数 96 个点的电价
在 Baseline 代码里,新加一列price_lag_96,然后把它加到all_features里就行。
💬 怎么改代码 ? 直接问 AI:
"我在做时间序列预测,想给训练数据加一个'1 天前同一时刻的电价'(price_lag_96)作为新特征。
数据每 15 分钟一个点,所以 1 天 = 96 个点。请基于 sklearn_baseline.py给我具体的修改方案------告诉我:
在哪一段加代码
加什么代码
测试集没有真实电价,这种情况下滞后特征该怎么处理?"
想深入还可以试:
- 加 1 天前 + 2 天前 + 1 周前多个滞后(price_lag_96 / price_lag_192 / price_lag_672)注意:加越远的滞后,训练数据前面的样本就会因为缺数据被丢掉(比如加 1 周前的滞后,前 7 天的训练样本会废掉),要权衡。
- 加滚动统计量:过去 1 天的电价均值、标准差、最大最小值------给模型提供"最近的电价大致水平"
方向 3:解锁气象金矿数据(NWP 气象特征合并)
气象信号(如风速、辐照度)是新能源出力的最上游决定性信号(风大、太阳好---风光出力多--- 供大于求--- 电价低)。官方提供的气象数据存在于 data/ 目录下的 .nc (NetCDF4 格式) 文件中 。
- 处理要点:
.nc文件的维度通常是(time, channel, lat, lon),需要对空间格点(经纬度lat/lon)求平均 ,将其转化为一维的时间序列。
- 对齐要点:气象数据往往是逐小时的(每天 24 个点),而电价是 15 分钟粒度的(每天 96 个点),需要使用 Pandas 的 resample()或 interpolate()进行插值对齐后再合并到训练集中 。
在 Baseline 代码里,新加一列price_lag_96,然后把它加到all_features里就行。
💬 完全没接触过 .nc 文件 ? 一句话让 AI 帮你搞定 :
"我提供了气象数据文件(.nc 格式,NetCDF4),路径在data/train/下。
请基于 sklearn_baseline.py帮我:
写一段代码读取.nc文件,先告诉我里面到底有哪些变量
提取风速(u100/v100)和辐照度(ghi 之类的),做空间平均
按 15 分钟时间粒度对齐到训练数据
把这些气象特征合并到df_train里
我用的库是 pandas,请提示我先pip install哪些包。"
想深入还可以做:
- 相关性分析:先做"气象变量 × 电价"的相关性热图,看哪些气象变量跟电价关系最强,优先用那些
- 对照组实验 :在 Baseline 基础上逐一加入气象特征,加完一个看一次 RMSE,而不是一次全加
方向 4:策略层加入"阈值兜底",不盲信预测
Baseline 的充放电策略完全相信预测电价------如果模型预测明天 14:00 电价最高,它就毫不犹豫在 14:00 放电。
但预测一定有误差 。如果实际 18:00 才是最高峰,你 14:00 放电只能赚一点点,真正的高峰反而错过了。这种 " 预测错了 → 策略跟着翻车 " 的风险 ,Baseline 完全没考虑。
更聪明的做法:在策略层面加一些"防御性设计",降低对预测精度的依赖。
🔰最简单的做法 : 加一个 " 阈值兜底 "
朴素的逻辑是:
-
如果预测的"最便宜时段"电价还没低到某个值 ,就不充电(因为可能更便宜)
-
如果预测的"最贵时段"电价还没高到某个值 ,就不放电(因为可能更贵)
也就是:预测不够极端的时候 , 宁可不动也不乱动。
💬 怎么改 generate_strategy 函数 ? 让 AI 给你写 :
"在 sklearn_baseline.py里有一个generate_strategy函数,目前的逻辑是:挑预测电价最便宜的连续 8 个时段充电、最贵的连续 8 个时段放电。
我想加一个'阈值兜底'策略------只有当预测的'放电时段平均电价 - 充电时段平均电价'超过某个阈值时,才执行充放电;否则当天不动。
请帮我:
修改generate_strategy函数,加一个min_profit_threshold参数
默认值给一个合理的初始猜测
告诉我怎么调这个阈值"
想深入还可以做:
- 敏感性分析:对预测电价加 ±5%、±10% 的随机噪声,看选出来的最优时刻是否还稳定。如果一扰动就大变,说明策略不稳健
- 稳健优化思路 :在枚举方案时,不只看"按预测值最赚多少",还要考虑"如果预测有 ±10% 误差,这个方案最差能赚多少"------选最坏情况下也不太差的方案,而不是只看最好情况。
矩池云 Energy Forecasting 镜像,把原本需要配置多源气象数据接口、手动对齐时序差分、调试复杂梯度提升树(GBDT)与时序大模型的数周工作量,压缩到了5 分钟轻松上手。
无论你是要发新型电力系统的学术论文、冲刺 AI 能源电力电价预测的顶尖比赛,还是单纯想搞懂储能策略到底怎么搞最赚钱,都绝对值得试一试。
👉在矩池云搜索 "energy forecasting" 镜像,开始你的第一个 AI 能源电价预测与储能调优实战吧!