Sirchmunk 让搜索随查询自进化
RAG 项目标准流程流程:切块 → 向量化 → 存进向量库 → 搜索 → 答案拼接。检索速度确实快,但每次查询都从零开始,知识没法累积。文档更新了?重跑 ETL。换了向量模型?全量重索引。更烦的是,返回的碎片是原始文本的低秩近似 --- 信息已经在嵌入那一步丢掉了。
RAG 做得好的,和它做不到的
RAG 在大规模文档检索上做得不错:快、可扩展、对海量文档集友好。但它的设计范围就是检索,不是知识维护。三个场景性瓶颈让它在我最需要的地方卡住了:
信息有损 --- 384 维向量是原始文本的低秩近似。把 20 页报告压成 100 个嵌入,检索效率高,但文档的叙事脉络、交叉引用、定义体系全丢了。两个主题相关但内容矛盾的碎片可能同时被召回,LLM 毫无察觉地把它们缝合在一起。
索引过期 --- 数据变了,向量库就得批量重跑 ETL。在代码仓库这种每天几十次 commit 的场景里,索引永远滞后于真实数据。你搜的是昨天已经删掉的那段代码。
基础设施重 --- VectorDB + 分块引擎 + ETL 管线 + 嵌入服务,多层组件。搭起来就够折腾,维护更头疼。

这些瓶颈不是 RAG 的设计缺陷 --- 它本来就是检索工具,不是知识维护工具。但企业搜索和 AI Agent 场景需要的恰恰是后者:知识随使用增值,不是每次从零开始。
Sirchmunk 的诞生逻辑
2026 年初,LLM 应用正从玩具走向生产。RAG 成了标配,但刚性架构在数据频繁变化的真实场景处处碰壁。ModelScope(阿里开源社区)团队看到了一个关键洞察:大量 Agent 和企业搜索场景需要的不是"建一座向量索引大厦",而是"直接在原始数据上开窗户"。
这个洞察的推导路径很清晰 --- 如果信息损失源于向量化压缩,那就跳过压缩,直接操作原始文本;如果索引过期源于批量 ETL,那就不要索引,文件放进去即刻可搜;如果基础设施重源于多层组件,那就去掉所有中间层。三个"如果...那就..."串联起来,就是 Sirchmunk 的核心设计:embedding-free、indexless、零基础设施。
ripgrep-all 检索原始文件,蒙特卡洛采样定位关键段落,LLM 只在最必要时介入。搜索产出的知识集群还会自进化 --- 每次查询都让系统更聪明。
项目长什么样
Sirchmunk 是一个 CLI 工具 / Web 服务 / Python 库 / Agent 技能,路径 sirchmunk/。核心依赖:openai(LLM 调用)、duckdb(知识集群存储)、kreuzberg(100+ 格式文本提取)、rapidfuzz(模糊匹配)、sentence-transformers(384 维嵌入,仅集群复用时用)、ripgrep-all(文件检索)。pip install sirchmunk 即开即用,零基础设施搭建。
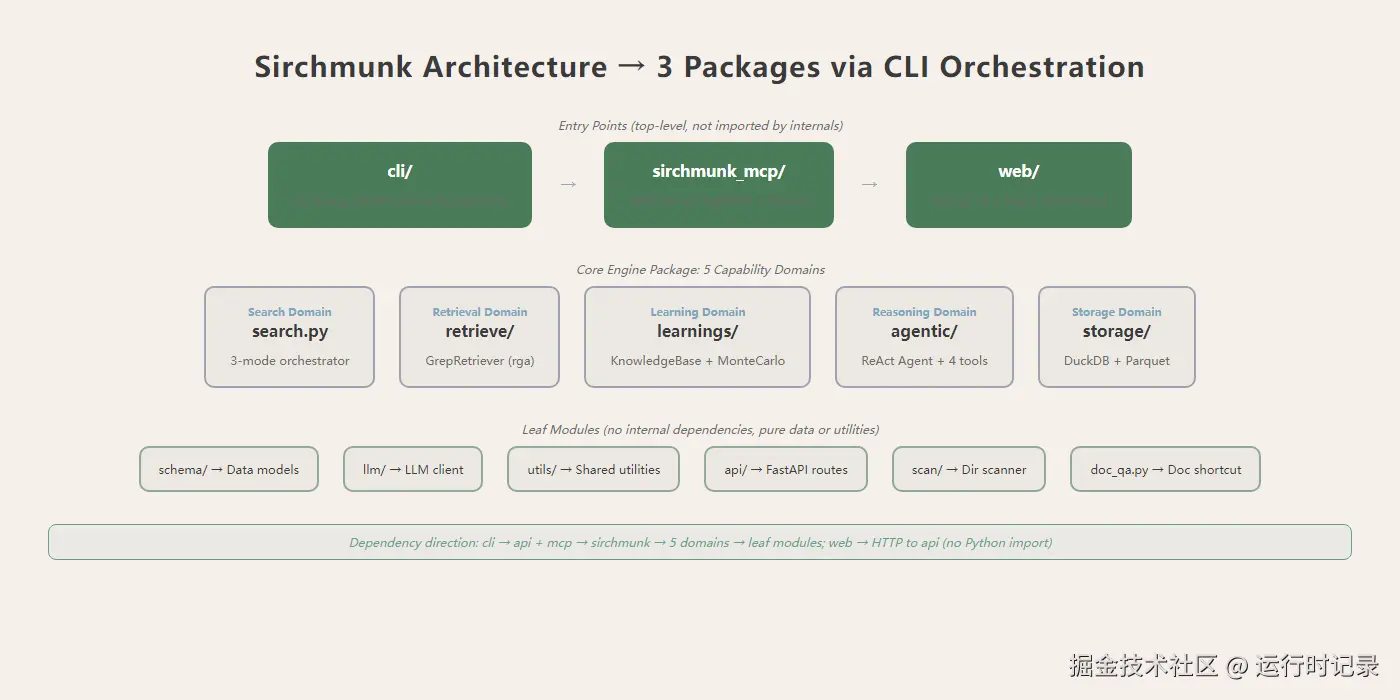 目录结构按功能域组织 --- 检索域(
目录结构按功能域组织 --- 检索域(retrieve/)、学习域(learnings/)、推理域(agentic/)、存储域(storage/)、API 域(api/),每个子模块封装一个独立能力。顶层两个独立 Python 包(核心包 sirchmunk + MCP 包 sirchmunk_mcp)和一个 Next.js 前端 web/,三者通过 CLI 编排而非代码引用耦合。核心引擎包中 search.py 是最重的模块 --- 三模式搜索策略分发、六阶段 DEEP 管线编排、知识集群复用逻辑全在这里。
它能做什么
Sirchmunk 有四个核心能力:
三模式搜索 --- FAST 模式 2 次 LLM 调用 2-5 秒出答案;DEEP 模式蒙特卡洛采样 + ReAct 推理 10-30 秒深度分析;FILENAME_ONLY 纯文件名匹配零 LLM 调用。入口在 search.py:639(AgenticSearch.search),Strategy 模式按 mode 参数分发。
知识集群自进化 --- 搜索不是一次性消费。每次 DEEP 搜索产出 KnowledgeCluster(含证据单元、查询历史、语义关联边),存入 DuckDB。下次相似查询直接命中缓存(384 维 embedding 余弦相似度 >= 0.85),0 LLM 开销。命中时追加查询、提升热度、重算嵌入 --- 知识真的在随使用增值。
WebSocket Chat RAG --- 4 种聊天模式(纯聊 / RAG搜索 / Web搜索 / RAG+Web),流式输出,完整会话管理。入口 chat.py:808,核心是 Mode 2 RAG 搜索。
MCP 集成 --- FastMCP SDK 注册 4 个工具(search/scan_dir/get_cluster/list_clusters),支持 stdio 和 HTTP 传输。Claude Desktop 或 Cursor IDE 直接调用。入口 server.py:26(create_server),委托给核心 AgenticSearch.search。
它怎么做到的
DEEP 搜索:六阶段管线 + 蒙特卡洛采样
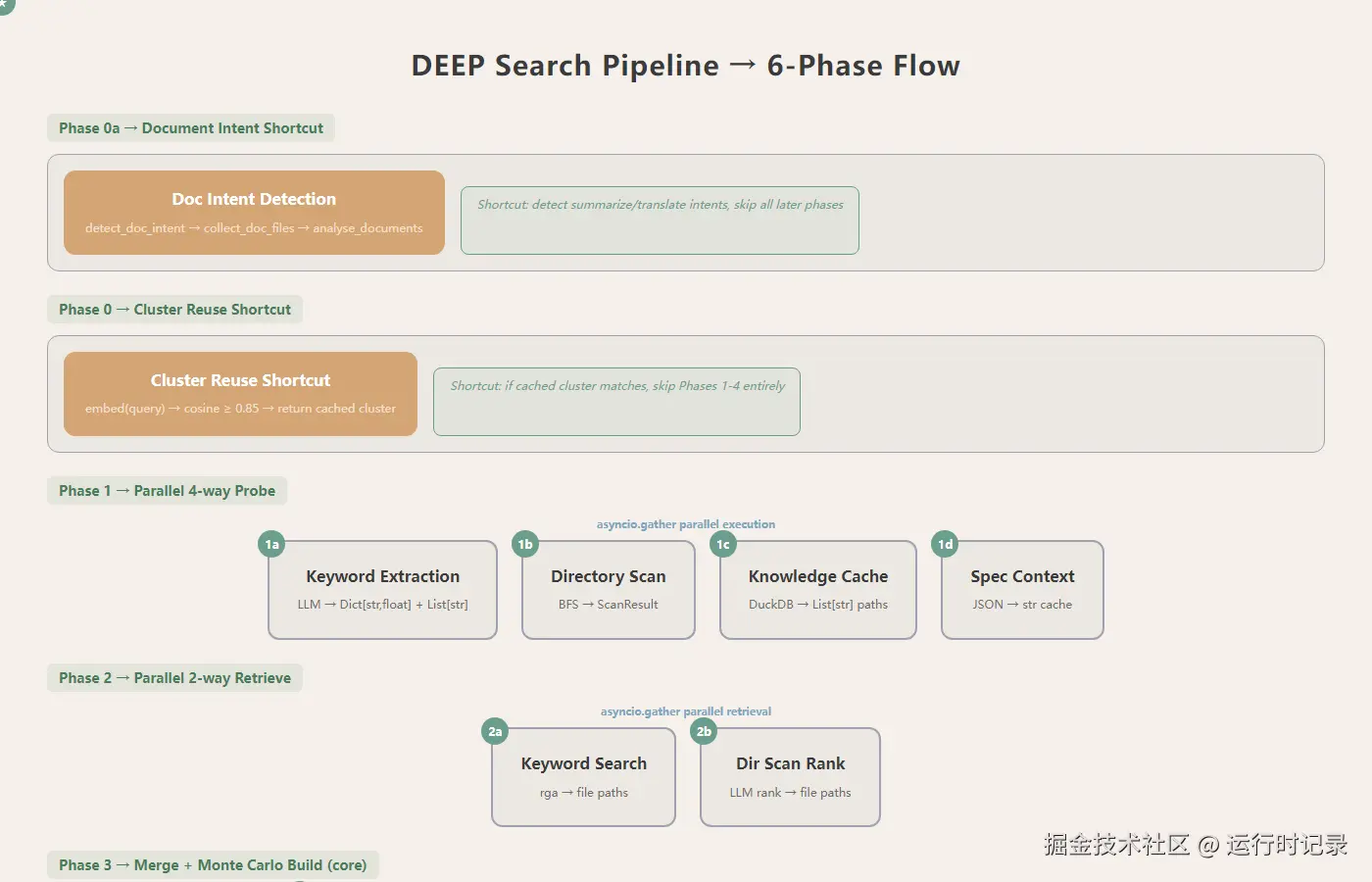 DEEP 搜索是最完整的管线,入口
DEEP 搜索是最完整的管线,入口 search.py:787。调用链:
scss
_search_deep(search.py:787)
Phase 0a: _try_direct_doc_analysis → detect_doc_intent(doc_qa.py:62) → analyse_documents
Phase 0: _try_reuse_cluster(search.py:196) → embed → search_similar_clusters
Phase 1: _probe_keywords + _probe_dir_scan + _probe_knowledge_cache + _load_spec_context (并行4路)
Phase 2: _retrieve_by_keywords + _rank_dir_scan_candidates (并行2路)
Phase 3: _merge_file_paths → _build_cluster → KnowledgeBase.build(knowledge_base.py:175)
→ MonteCarloEvidenceSampling.get_roi(evidence_processor.py:364)
Phase 4: _summarise_cluster 或 _react_refinement(react_agent.py:145) (ReAct循环)
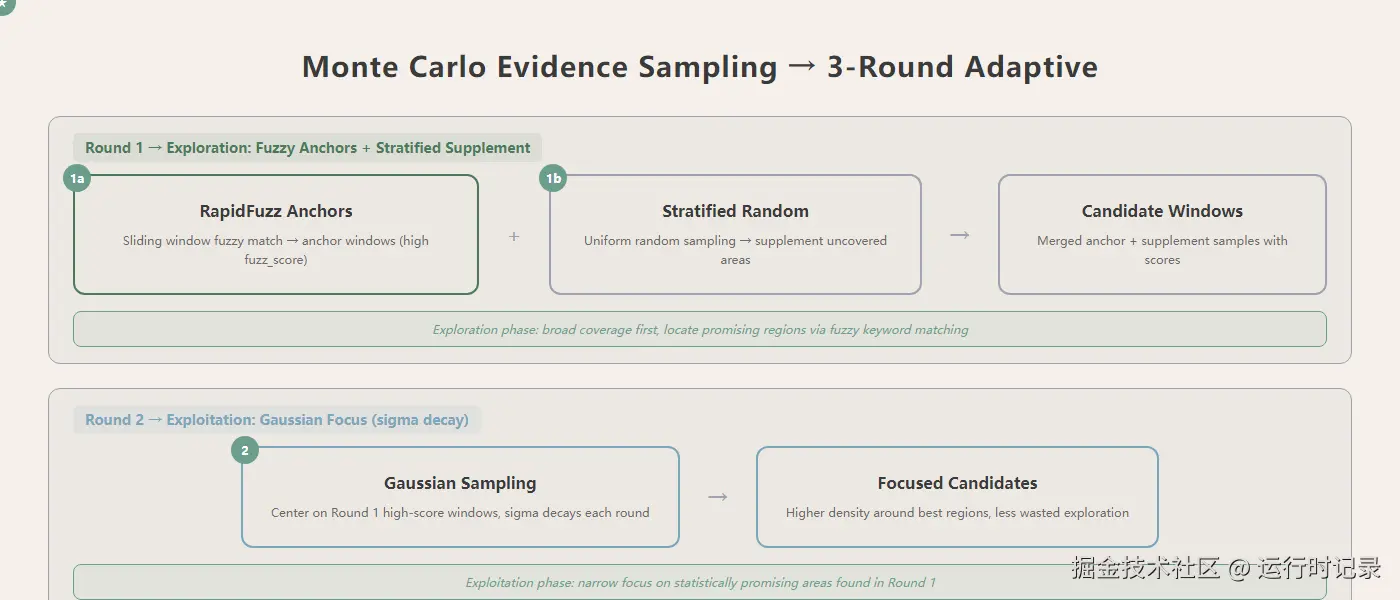
Phase 5: _save_cluster_with_embedding → DuckDB + Parquet + 384维embedding核心算法是 MonteCarloEvidenceSampling.get_roi(evidence_processor.py:364)--- 三轮自适应重要性采样:
第一轮 --- 模糊锚点 + 分层补充。RapidFuzz 滑动窗口找与查询关键词模糊匹配的段落(锚点),再用均匀随机采样补充锚点没覆盖的区域。探索为主。
第二轮 --- 高斯聚焦。sigma 随轮次衰减,以第一轮高分窗口为中心做高斯采样。聚焦为主 --- 但聚焦位置来自探索阶段的统计结果,不是猜测。
第三轮 --- LLM 评分筛选。采样窗口送进 LLM 做 ROI 评分,top_k 窗口送入最终 ROI 摘要生成。
这不是穷举阅读整个文件,而是用统计方法在有限 token 预算内找到最值得读的部分。分块策略跟文档内容无关 --- 不预设"每块 500 字"这种刚性切分,而是让采样算法根据查询自适应决定看哪里。
FAST 搜索:贪心早终止
FAST 搜索只做 2 次 LLM 调用,入口 search.py:1037:
scss
_search_fast(search.py:1037)
Step 0: _try_reuse_cluster (缓存命中则短路返回,0 LLM调用)
Step 1: llm.achat(FAST_QUERY_ANALYSIS) → primary/fallback/file_hints关键词
Step 2: _fast_find_best_file(search.py:1180) → rga关键词搜索 → 逐级降级(primary→regex→filename) → 贪心选top1
Step 3: _fast_sample_evidence → _read_context_windows(search.py:1307) → grep命中行号±30行区间合并+max_chars=15000截断
Step 4: llm.achat(ROI_RESULT_SUMMARY, stream=True) → answer关键设计是两级关键词级联:先用 LLM 提取复合关键词搜索,没命中就逐级降级到原子关键词、正则、文件名。只要能定位到一个最相关的文件,就用上下文窗口采样提取证据。快但精确度够用 --- 这是"速度为默认偏好"哲学的直接体现。
知识集群进化:搜索结果不是一次性消费
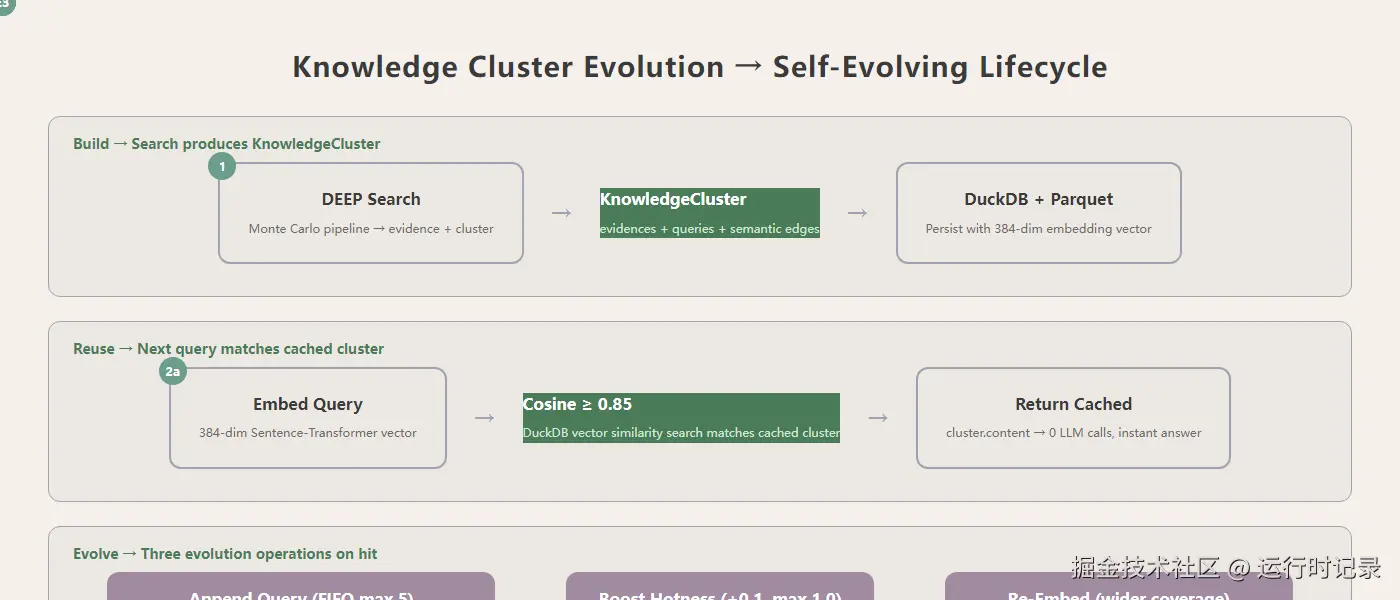 这是 Sirchmunk 最让我兴奋的设计。每次 DEEP 搜索产出的 KnowledgeCluster 不是用完就丢 --- 它被存入 DuckDB,附上 384 维 embedding。下次相似查询进来(
这是 Sirchmunk 最让我兴奋的设计。每次 DEEP 搜索产出的 KnowledgeCluster 不是用完就丢 --- 它被存入 DuckDB,附上 384 维 embedding。下次相似查询进来(search.py:196,_try_reuse_cluster),先算 embedding 余弦相似度,>= 0.85 就直接返回缓存内容,0 LLM 调用。命中时还做了三件进化操作:追加查询到 FIFO 历史(max 5)、提升热度(+0.1 上限 1.0)、重算嵌入(合并新查询的语义,扩大覆盖范围)。集群越用越聪明,语义覆盖越用越广。
数据怎么流动
三条核心管线的数据流:
FAST 管线:str(query) → embedding 匹配 → 命中即返回 / 未命中:LLM 关键词 → rga 搜索 → 贪心选文件 → 上下文窗口采样 → LLM 答案合成。2 次 LLM 调用,2-5 秒。
DEEP 管线:str(query) → 文档意图短路 → 集群复用 → 并行 4 路探测 → 并行 2 路检索 → 合并 + 蒙特卡洛构建集群 → 答案生成/ReAct精炼 → 持久化。5+ LLM 调用,10-30 秒。
FILENAME_ONLY 管线 :str(query) → 纯文件名模式匹配 → rga rg --files。0 LLM 调用,毫秒级。
持久化方式务实得让人舒服:DuckDB 内存表做实时 CRUD,守护线程定期原子写入 Parquet 文件。进程内速度优先于分布式扩展 --- 单进程架构,不追求跨节点协调。
评价:做得好的,还不够的
Sirchmunk 做得好的:
- 零基础设施。
pip install sirchmunk即开即用,文件放进去即刻可搜。ripgrep-all 支持 PDF/DOCX/PPTX 等 100+ 格式,不需要预索引。 - 三模式策略。FAST 2 秒出答案,DEEP 蒙特卡洛深度分析,FILENAME_ONLY 毫秒级文件定位。用户选择优先于一刀切。
- 知识集群自进化。复用时零 LLM 成本、追加查询扩大语义覆盖、热度累积 --- 知识真的在增值,不是每次从零开始。
- MCP 集成干净。独立包可选安装,4 个工具覆盖核心功能,Claude Desktop 和 Cursor IDE 直接调用。
它做不到的:
-
没有自动化测试。 整个项目零测试文件。AgenticSearch 核心搜索管线、蒙特卡洛采样算法、DuckDB 持久化全是零覆盖。这是最大风险 --- 采样边界 case 出错你不会知道,直到生产环境返回空答案。
-
Web 搜索是 mock 函数。
api/chat.py:443的_perform_web_search返回固定文本,WebScanner 是空壳(scan/web_scanner.py:7)。Mode 3 和 Mode 4 的聊天路径没法用。 -
单进程架构。 DuckDB 内存表做存储,没有分布式协调。适合个人和小团队,大规模并发会卡。
-
蒙特卡洛采样有硬截断。
max_chars=15000上下文窗口截断(search.py:1307),大文件的关键信息可能被切掉。务实之举(控制 token),但限制了深度分析能力。
可配置的能力边界:
核心行为都可以通过环境变量切换:LLM 提供商(LLM_BASE_URL)、模型(LLM_MODEL_NAME)、搜索深度(DEFAULT_MAX_DEPTH=5)、返回文件数(DEFAULT_TOP_K_FILES=3)、集群复用开关(SIRCHMUNK_ENABLE_CLUSTER_REUSE=true)、相似度阈值(CLUSTER_SIM_THRESHOLD=0.85)。不需要改代码,改 .env 就行。
让我兴奋的不是 Sirchmunk 的具体实现细节 --- 而是搜索自进化模型。传统 RAG 每次查询从零开始,Sirchmunk 让知识随使用增值。搜索产出的集群被复用、进化、扩大语义覆盖。零嵌入索引、零分块策略、零基础设施 --- 三个"零"不是偷懒,而是对"到底需要什么"的诚实回答:你需要的不是一座向量索引大厦,而是直接在原始数据上开窗户。
不过话说回来,Sirchmunk 显然还是早期项目。缺测试、mock 功能未实现、单进程架构意味着它还没到生产就绪。但搜索自进化的想法 --- 每次搜索让系统更聪明,知识集群随使用增值 --- 是我见过的 RAG 替代方案里最有前景的方向之一。