Tillang Puzzles

一个开源仓库https://github.com/tile-ai/tilelang-puzzles/tree/main
给出用tilelang实现经典算子的例子,附带讲解。分为10个puzzle,每个问题都有待补全文件,和参考实现,以及文字讲解。
采用循序渐进的思路,难度逐渐递增,01-05熟悉语法,06-09实现经典算子,10为挑战复杂实战算子
08 Matirx
矩阵乘法是整个算子优化的核心,大部分经典算子都可以规约到矩阵乘法,比如前一节的注意力里有QKTQK^TQKT,前向传播有参数*输入,反向传播的求偏导也是矩阵乘法,卷积通过im2col转化后也能变成矩阵乘法。
GEMV
先来个基础的,矩阵乘向量,可以看成矩阵乘法的特殊情况,N=1
定义
py
for i in range(M):
ACC = 0 # float32 累加器
for k in range(K):
ACC += A[i, k] * B[k]
C[i] = ACC # 转换回 float16实际上也可以看成规约求和的特殊情况,看成带权规约,普通规约权重都是1,这里的权重是Bk
py
# Reduce Sum (Puzzle 05)
for i in range(N):
C[i] = sum(A[i, :])
# GEMV (Puzzle 08)
for i in range(M):
C[i] = sum(A[i, :] * B[:]) # 加权求和baseline
c
def ref_gemv(A: torch.Tensor, B: torch.Tensor):
assert A.shape == (M, K)
assert B.shape == (K,)
assert A.dtype == B.dtype == torch.float16
return torch.matmul(input=A, other=B) # 返回 [M,]C_local = T.alloc_fragment((BLOCK_M,), accum_dtype),累加类型使用fp32,不同于输入类型fp16,因为fp16不管是精度还是值域都太小了,矩阵乘法有乘法,有累加,数值很大,用32才能保证不溢出+精度过关AB_local[i, j] = A_local[i, j].astype(accum_dtype) * B_local[j].astype(accum_dtype)按前面说的,看成带权规约,先计算乘上权重后的结果。由于输入是fp16,还想保证精度,计算时先显式转成fp32,类似于cpp里的ans += 1ll * x * y- 然后规约
T.reduce_sum(AB_local, C_local, dim=1, clear=False)
py
@tilelang.jit
def tl_gemv(A, B, BLOCK_M: int, BLOCK_K: int):
M, K = T.const("M, K")
dtype = T.float16
accum_dtype = T.float32
A: T.Tensor((M, K), dtype)
B: T.Tensor((K,), dtype)
C = T.empty((M,), dtype)
# TODO: Implement this function
with T.Kernel(T.ceildiv(M, BLOCK_M), threads=128) as bx:
A_local = T.alloc_fragment((BLOCK_M, BLOCK_K), dtype)
B_local = T.alloc_fragment((BLOCK_K,), dtype)
C_local = T.alloc_fragment((BLOCK_M,), accum_dtype)
AB_local = T.alloc_fragment((BLOCK_M, BLOCK_K), accum_dtype)
T.clear(C_local)
for bk in T.Serial(T.ceildiv(K, BLOCK_K)):
T.copy(A[bx * BLOCK_M, bk * BLOCK_K], A_local)
T.copy(B[bk * BLOCK_K], B_local)
for i, j in T.Parallel(BLOCK_M, BLOCK_K):
AB_local[i, j] = A_local[i, j].astype(accum_dtype) * B_local[j].astype(accum_dtype)
T.reduce_sum(AB_local, C_local, dim=1, clear=False)
T.copy(C_local, C[bx * BLOCK_M])
return C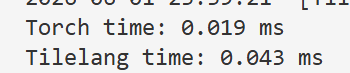
性能很差,这算是不叫暴力的做法
朴素GEMM
T.gemm(A_local, B_local, C_local)和前面唯一的区别,把手动乘上权重,再逐行规约,改成调用gemm接口计算一个块的结果了,只需传入两个输入矩阵,一个接收矩阵。
py
@tilelang.jit
def tl_matmul_naive(A, B, BLOCK_M: int, BLOCK_N: int, BLOCK_K: int):
M, N, K = T.const("M, N, K")
dtype = T.float16
accum_dtype = T.float32
A: T.Tensor((M, K), dtype)
B: T.Tensor((K, N), dtype)
C = T.empty((M, N), dtype)
# TODO: Implement this function
with T.Kernel(T.ceildiv(M, BLOCK_M), T.ceildiv(N, BLOCK_N), threads=128) as (bx, by):
A_local = T.alloc_fragment((BLOCK_M, BLOCK_K), dtype)
B_local = T.alloc_fragment((BLOCK_K, BLOCK_N), dtype)
C_local = T.alloc_fragment((BLOCK_M, BLOCK_N), accum_dtype)
T.clear(C_local)
for bk in T.Serial(T.ceildiv(K, BLOCK_K)):
T.copy(A[bx * BLOCK_M, bk * BLOCK_K], A_local)
T.copy(B[bk * BLOCK_K, by * BLOCK_N], B_local)
T.gemm(A_local, B_local, C_local)
T.copy(C_local, C[bx * BLOCK_M, by * BLOCK_N])
return C
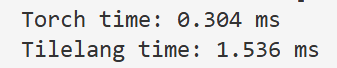
性能还是很差,而且看起来5x比前面的GEMV的3x左右还要差?难道gemm还不如手动规约高效?显然不是,因为GEMM两个输入都是矩阵,计算规模更大了,那么效率差距会被放大。实际GEMM肯定效率是比手动规约高的。
GEMM内部一般会直接调用MMA接口,使用Tensor Core计算。Tensor Core是矩阵计算专用单元,只能级算特定大小的矩阵乘法,不灵活,但是计算吞吐量大;前面的reduce和拷贝这些操作,都是CUDA Core执行的,可以执行通用计算,但是效率低。所以调用Tensor Core的GEMM接口一般性能肯定比CUDA Core的reduce高。
这里我们和torch还有差距,说明还有优化没用上。
优化版GEMM
B_local = T.alloc_shared((BLOCK_K, BLOCK_N), dtype)这里把张量从寄存器换到了共享内存上,明明寄存器更快,这是为什么?因为寄存器资源是很有限的,基本装下一个(BLOCK_M, BLOCK_K)大的张量就快满了,两个就不够了,而溢出部分的数据,会被直接存到全局内存,全局内存的延迟是最高的,整体效率被这个环节完全拖慢了,什么优化都没用了。所以,只有最频繁用到的累加数组,我们考虑安排在寄存器上,两个输入分块安排在共享内存,共享内存一般很大,容纳多个块都没问题。同时,访问速度也还可以接受。for bk in T.Pipelined(T.ceildiv(K, BLOCK_K), num_stages=3):又是tilelang的一个强大接口,这里可以在并行循环里,增加一个参数num_stage,指定流水线级数。就可以把这个循环流水线化!理论上合适的流水阶段划分,可以实现等同于级数的加速比!- 这里虽然轻飘飘的一行,实际内部优化思想非常重要,注意到流水线建立前,每一轮的循环执行的是,先拷贝,再计算。但是我们前面提到过,现代GPU的内存带宽远小于计算吞吐量,也就是说大部分时间,计算核心都处于阻塞,等待内存搬运,这正是适合流水线优化的地方,可以把搬运和计算解耦,流水线一个阶段负责搬运,一个阶段负责计算,这样搬运的时候也可以计算,大大提升效率,整体瓶颈只取决于最慢的部分,也就是搬运,计算延迟几乎被完全隐藏了。
py
@tilelang.jit
def tl_matmul_opt(A, B, BLOCK_M: int, BLOCK_N: int, BLOCK_K: int):
M, N, K = T.const("M, N, K")
dtype = T.float16
accum_dtype = T.float32
A: T.Tensor((M, K), dtype)
B: T.Tensor((K, N), dtype)
C = T.empty((M, N), dtype)
# TODO: Implement this function
with T.Kernel(T.ceildiv(M, BLOCK_M), T.ceildiv(N, BLOCK_N), threads=128) as (bx, by):
A_local = T.alloc_shared((BLOCK_M, BLOCK_K), dtype)
B_local = T.alloc_shared((BLOCK_K, BLOCK_N), dtype)
C_local = T.alloc_fragment((BLOCK_M, BLOCK_N), accum_dtype)
T.clear(C_local)
for bk in T.Pipelined(T.ceildiv(K, BLOCK_K), num_stages=3):
T.copy(A[bx * BLOCK_M, bk * BLOCK_K], A_local)
T.copy(B[bk * BLOCK_K, by * BLOCK_N], B_local)
T.gemm(A_local, B_local, C_local)
T.copy(C_local, C[bx * BLOCK_M, by * BLOCK_N])
return C优化都用上后和torch实现差的不多了。

另外来验证一下,所有张量都申请在寄存器上会不会导致性能退化。可以看到几乎退化到朴素GEMM版本了,这是合理的,因为朴素版本就是直接访问全局内存,这里内存溢出后,张量也是存在全局内存上的,访问延迟自然和直接存在全局内存上相近。