Tillang Puzzles

一个开源仓库https://github.com/tile-ai/tilelang-puzzles/tree/main
给出用tilelang实现经典算子的例子,附带讲解。分为10个puzzle,每个问题都有待补全文件,和参考实现,以及文字讲解。
采用循序渐进的思路,难度逐渐递增,01-05熟悉语法,06-09实现经典算子,10为挑战复杂实战算子
05 reduce-sum
定义
py
for i in range(N):
B[i] = 0
for j in range(M):
B[i] += A[i, j]baseline
c
def ref_reduce_sum(A: torch.Tensor):
return torch.sum(A, dim=1) # 沿维度1(列)求和朴素规约
for by in T.serial(M // BLOCK_M):对M维度串行遍历块,因为M维度要都规约到一个变量里,也就是多个块要写同一个位置,如果不加锁,会出现错误结果,如果加锁,又会产生竞争,等待,退化到近似串行,不如直接串行for i in T.parallel(BLOCK_N):N维度,每一行都规约到自己的位置,并行没有冲突。row_sum =T.alloc_var(dtype)核函数内声明单个变量,默认使用寄存器内存row_sum = T.float32(0)赋初值,核函数内不能直接用0.0这种,都要套一个Tilelang的接口。for j in T.serial(BLOCK_M):块内同样的,都要累加到同一个变量,会产生冲突,所以串行。
py
def tl_reduce_sum(A, BLOCK_N: int, BLOCK_M: int):
N, M = T.const("N, M")
dtype = T.float32
A: T.Tensor((N, M), dtype)
B = T.empty((N,), dtype)
# TODO: Implement this function
with T.Kernel(N // BLOCK_N, threads=256) as bx:
n_idx = bx * BLOCK_N
A_local = T.alloc_fragment((BLOCK_N, BLOCK_M), dtype)
B_local = T.alloc_fragment((BLOCK_N,), dtype)
T.clear(B_local)
for by in T.serial(M // BLOCK_M):
m_idx = by * BLOCK_M
T.copy(A[n_idx, m_idx], A_local)
# T.reduce_sum(A_local, B_local, dim=1, clear=False)
for i in T.parallel(BLOCK_N):
row_sum =T.alloc_var(dtype)
row_sum = T.float32(0)
for j in T.serial(BLOCK_M):
row_sum = row_sum + A_local[i, j]
B_local[i] = B_local[i] + row_sum
T.copy(B_local, B[n_idx])
return B利用规约接口
T.reduce_sum(A_local, B_local, dim=1, clear=False)这些手动规约可以用一个接口来实现。参数分别为输入张量,输出张量,规约维度,是否清零输出张量。这里我们对A规约,输出到B,对A的M维度,也就是第1个维度(从0开始计算)。不能清零张量,因为一行分多个块,多次需要累加到一起,才能得到每一行的规约求和
py
with T.Kernel(N // BLOCK_N, threads=256) as bx:
n_idx = bx * BLOCK_N
A_local = T.alloc_fragment((BLOCK_N, BLOCK_M), dtype)
B_local = T.alloc_fragment((BLOCK_N,), dtype)
T.clear(B_local)
for by in T.serial(M // BLOCK_M):
m_idx = by * BLOCK_M
T.copy(A[n_idx, m_idx], A_local)
T.reduce_sum(A_local, B_local, dim=1, clear=False)
# for i in T.parallel(BLOCK_N):
# row_sum =T.alloc_var(dtype)
# row_sum = T.float32(0)
# for j in T.serial(BLOCK_M):
# row_sum = row_sum + A_local[i, j]
# B_local[i] = B_local[i] + row_sum
T.copy(B_local, B[n_idx])
return B性能分析
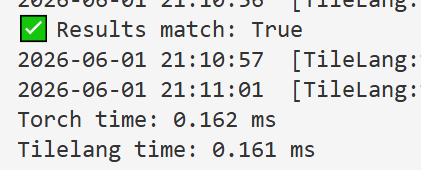
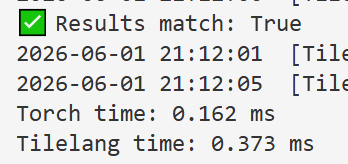
以下两个tilelang kernel分别是reduce接口和手动规约,手动规约慢一倍,因为手动规约,对于每一行M个元素来说其实是完全串行的,只对N维度并行了。
但一维规约其实是有快速算法的,采用二进制位+分治的思想,可以看这篇文章https://blog.csdn.net/Maxwell_Newton/article/details/155850412?spm=1011.2415.3001.5331
这里的reduce接口应该就使用了类似的实现。但这样的快速实现要手动操作线程,warp,不符合tilelang的设计哲学,所以封装起来,不暴露给开发者。