今日分享之前遇到的一个内存泄漏问题,从监控告警到定位根因,一步步还原排查过程,希望能给大家一些启发。
本文与 记一次线上OOM排查:Java heap space 元凶竟是全表查询 一脉相承,都是线上真实 OOM 案例的深度复盘。上篇讲的是 SQL 全表查询导致的堆内存溢出,这篇则聚焦于 Orika 动态字节码生成导致的堆外内存泄漏------同为 OOM,病因各有不同,排查思路一以贯之。
监控是系统的眼睛。当收到线上机器的内存告警时,我们第一时间拉取了基础设施的内存负载趋势图。
1.1 内存走势的周期性规律
通过近期的 内存负载走势图 ,我们可以清晰地观察到两台生产机(172.30.4.60 和 172.30.4.61)的运行状态:
- 短周期观察(2-3天) :内存呈现极其规整的"锯齿状"或"波浪状"上升趋势。即便在业务低峰期,物理内存的基线也在缓慢抬升。每次到达
85% - 90%的临界值后,便伴随着一次断崖式的下跌(系统重启或进程被杀后的自愈)。 - 长周期观察(30天趋势图谱) :拉长到近30天的整体内存图谱可以发现,这种单调递增的趋势不可逆转。虽然频繁的 Minor GC / Full GC 能够回收部分堆内年轻代和老年代对象,但整体内存占用依然像滚雪球一样,直奔
100%满载而去。 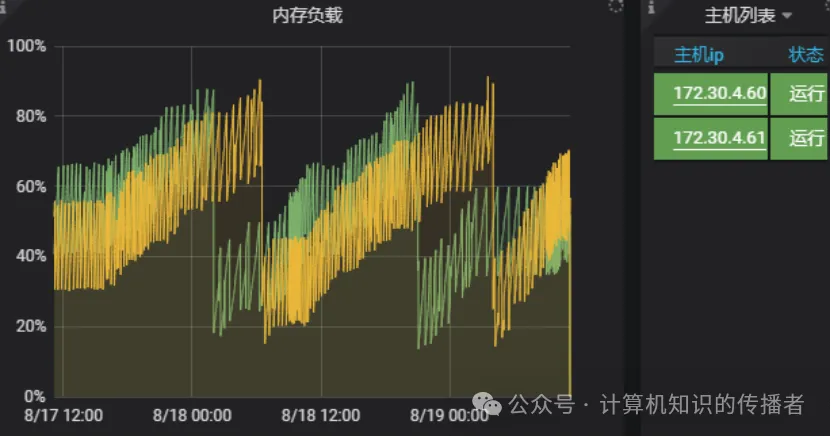
1.2 操作系统层面的 Top 排查
登录到故障机器,执行 top 命令进行底层进程扫描,抓取到了最直接的证据:
- 系统的总内存(
KiB Mem)使用率居高不下,可用内存(free)仅剩下了可怜的100M左右,交换分区(Swap)也被疯狂蚕食。 - 观察进程列表,PID 为
27184的java进程,其 RES(常驻内存) 达到了惊人的 ,而对应的进程 %MEM(内存占用率) 更是高达 !
回到我们的 JVM 启动参数配置中:
-Xmx2g -Xms2g -XX:MetaspaceSize=512M -XX:MaxMetaspaceSize=512M -XX:+UseConcMarkSweepGC最大堆内存(Xmx)明明只限制了 2G,元空间(MaxMetaspaceSize)限制了 512M。堆内存加上元空间的最大理论总和应当控制在 2.5G 左右,为什么物理常驻内存(RES)却直接飙到了 2.79G 甚至逼近操作系统极限?这基本排除了单纯的"堆内长生命周期对象堆积",极有可能是堆外内存溢出 或非标准类加载器持有的元空间/堆内大对象泄露。
二、 诊断升级:Arthas 引路与 MAT 快照"捉妖"
由于服务在启动参数中配置了 -XX:+HeapDumpOnOutOfMemoryError,在最近一次系统濒临崩溃时,我们成功拿到了核心内存快照文件:dump.hprof。接下来,我们请出 Eclipse Memory Analyzer (MAT) 对这个接近 2G 的快照文件进行深度剖析。
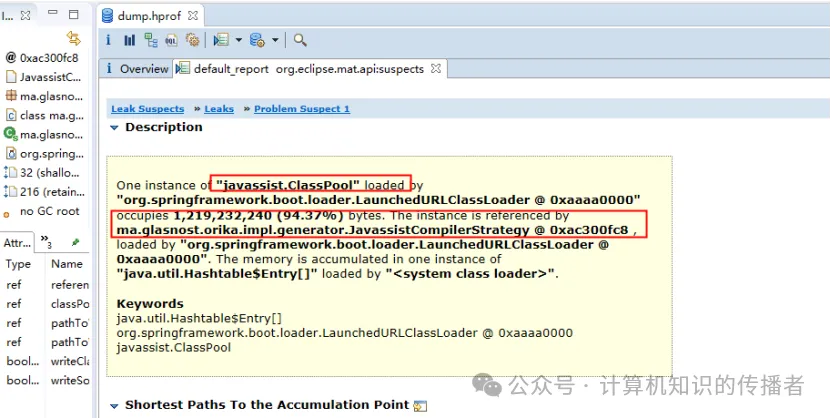
导入 MAT 后,打开 Leak Suspects(内存泄漏猜想) 报告,大对象的真面目在第一张图(Problem Suspect 1)里便暴露得无影无踪:
One instance of "javassist.ClassPool" loaded by "org.springframework.boot.loader.LaunchedURLClassLoader @ 0xaaaa0000"
occupies 1,219,232,240 (94.37%) bytes.
The instance is referenced by ma.glasnost.orika.impl.generator.JavassistCompilerStrategy @ 0xac300fc8 ,
loaded by "org.springframework.boot.loader.LaunchedURLClassLoader @ 0xaaaa0000".2.1 触目惊心的分析数据
- 大对象定位 :一个单例的
javassist.ClassPool对象,直接吃掉了 1.21 GB(占比高达 94.37%) 的物理内存! - 引用链追踪 :这个庞大的
ClassPool实例被 Orika 框架的核心编译策略类ma.glasnost.orika.impl.generator.JavassistCompilerStrategy所绝对持有。 - 内存堆积形式 :所有的内存最终堆积在了一个标准的
java.util.Hashtable$Entry[]数组结构中。
这与我们前期的锯齿状内存波形图达成了完美的吻合!这就是典型的动态动态生成类未释放导致的内存泄漏。
三、 刨根问底:探寻 Orika 与 Javassist 结合的底层陷阱
为什么引入 Orika 这个原本旨在提升系统性能的基础组件,会变成吞噬内存的黑洞?这需要从它的底层编译机制和我们工程中的不当编码说起。
3.1 核心组件的工作原理
Orika 在搭建之初被引入,是为了高效解决对象映射问题。为了摆脱反射带来的性能损耗,Orika 默认采用了 ma.glasnost.orika.impl.generator.JavassistCompilerStrategy 作为其编译策略。
其底层依赖于 Javassist 库。在 Javassist 的世界里,ClassPool 是一个至关重要的概念:
- •
ClassPool是一个存放CtClass(编译时类对象)的容器。 - • 一旦某个
CtClass对象被构建出来,它就会被默认记录并固化在ClassPool中。 - • 致命特性 :Javassist 编译器在编译源文件或生成映射类时,必须频繁访问
ClassPool。如果动态生成的类源源不断,ClassPool就会无限膨胀。除非开发者手动干预将其释放,否则这些动态生成的类信息将伴随宿主 ClassLoader 的生命周期永远留存在堆内存中,永远无法被 GC 回收!
3.2 致命的代码误区:重复创建 Factory
既然 Orika 本身有缓存机制,为什么会产生海量的、不重样的 CtClass 呢?
通过对代码库的全局审查,我们在业务层或工具类(BeanUtils)中发现了类似下面的致命代码:
参考gzh: 计算机知识的传播者问题根源分析:
DefaultMapperFactory每次被new出来时,都会在底层同步初始化一个新的JavassistCompilerStrategy。- 而每个
JavassistCompilerStrategy内部都会绑定一个全新的、独立的ClassPool。 - 当高并发请求流经此方法时,系统每做一次对象转换,就会动态生成诸如
Orika_SourceVO_TargetDO_Mapper123456$1这样的动态映射类,并死死塞进当前的ClassPool中。 - 虽然随着方法结束,
mapperFactory的局部变量引用断开了,但是由于类加载器(ClassLoader)与生成的类对象之间存在逆向引用 ,或者ClassPool内部的线程上下文、系统类加载器持有了未卸载的动态类,导致这部分庞大的动态字节码对象无法被 JVM 识别为垃圾。
久而久之,ClassPool 中的 Hashtable 疯狂累积,最终引发了我们在 MAT 看到的 的绝望场面。
四、 彻底断根:性能优化与修复方案
解铃还须系铃人。明确了是因为"局部重复创建 MapperFactory 导致字节码容器膨胀"的根源后,修复方案自然水到渠成。核心思想非常简单:全局单例化,最大化复用 Orika 的缓存架构。
4.1 方案一:基于 Spring 管理的全局单例工具类(推荐)
将 MapperFactory 交给 Spring 容器作为单例进行管理,确保整个进程周期内,只存在一个 ClassPool,且相同的对象映射只编译一次:
参考gzh: 计算机知识的传播者在业务代码中直接注入 MapperFacade 即可安全使用:
@Service
public class AccountService {
@Autowired
private MapperFacade mapperFacade;
public AccountVO getAccount(Long id) {
AccountDO accountDO = accountDao.findById(id);
// 纯内存高效率映射,且绝无内存泄漏风险
return mapperFacade.map(accountDO, AccountVO.class);
}
}4.2 方案二:静态单例工具类封装(无 Spring 环境适用)
如果在非 Spring 容器环境下,可以使用标准的静态内部类单例模式进行封装:
import ma.glasnost.orika.MapperFacade;
import ma.glasnost.orika.MapperFactory;
import ma.glasnost.orika.impl.DefaultMapperFactory;
public class OrikaBeanUtils {
private static final MapperFactory FACTORY;
private static final MapperFacade MAPPER;
static {
FACTORY = new DefaultMapperFactory.Builder().build();
MAPPER = FACTORY.getMapperFacade();
}
public static <S, D> D copy(S source, Class<D> destinationClass) {
if (source == null) {
return null;
}
return MAPPER.map(source, destinationClass);
}
}五、 总结与反思
本次生产环境的 OOM 告警,是一节生动的 JVM 底层原理课。我们在引入任何第三方开源组件时,不能仅仅停留在"API 怎么调用"的表面层次,更应当关注其背后的架构设计与生命周期模型。
-
- 警惕高频方法中 框架核心对象的行为 :诸如 Orika 的
MapperFactory、Jackson 的ObjectMapper等,它们本身都是重量级的、线程安全的、且内部带有深层缓存机制的组件,绝不能当做普通的局部临时变量来频繁创建。
- 警惕高频方法中 框架核心对象的行为 :诸如 Orika 的
-
- 规范 Code Review 与压测 :这类涉及字节码生成的类库泄漏,在常规的单体测试中极难被发现(因为调用次数少、内存增量不明显)。必须通过长时间的稳定性压测并配合堆外、元空间监控,才能让这类"锯齿状"隐形杀手无处遁形。
欢迎点赞加关注,一起聊聊 AI。更多线上真实案例复盘。