LLamafactory Qlora微调
Qlora微调
- 模型选择: DeepSeek-R1-Distill-Qwen-1.5B
- 数据选择: finance_sharegpt.jsonl
- 显存要求:
核心参数
- 量化方法:bnb
- 量化等级:8
- 对话模板:deepseekr1
- epoch=30 (数据量越大,此值应该越低)
下面是对每个核心参数的简要介绍及其设置原因:
-
量化方法 (bnb):
- 介绍 :bnb 指的是
bitsandbytes库实现的量化方法,它是一种高效的 4-bit/8-bit 量化技术,能在保持模型性能的同时大幅减少显存占用。 - 为什么这么设置 :选择
bnb是因为它是目前最成熟、最稳定的量化方案之一,与 Hugging Face 生态和 LLaMA-Factory 兼容性最好,能确保微调过程顺利。
- 介绍 :bnb 指的是
-
量化等级 (8):
- 介绍:量化等级决定了模型权重被压缩的精度,例如 8-bit、4-bit。这里设置为 8-bit 量化。
- 为什么这么设置:8-bit 量化在显存节省和模型精度之间取得了很好的平衡。相比 4-bit,8-bit 量化对模型性能的影响更小,更适合对生成质量要求较高的任务(如金融对话),同时仍能显著降低显存需求。
-
对话模板 (deepseekr1):
- 介绍 :对话模板定义了模型输入输出的格式,包括系统提示、用户问题、助手回答的拼接方式。
deepseekr1是专为 DeepSeek-R1 系列模型设计的模板。 - 为什么这么设置 :因为我们微调的基础模型是 DeepSeek-R1-Distill-Qwen-1.5B ,使用其原生的对话模板 (
deepseekr1) 可以确保输入格式与模型预训练和指令微调阶段保持一致,从而获得最佳的微调效果。
- 介绍 :对话模板定义了模型输入输出的格式,包括系统提示、用户问题、助手回答的拼接方式。
-
训练轮数 (epoch=50):
- 介绍:epoch 表示整个训练数据集被模型完整学习一遍的次数。
- 为什么这么设置 :设置
epoch=50是针对当前 finance_sharegpt.jsonl 数据集规模(相对较小)的一个经验值。较多的训练轮数可以让模型在特定领域(金融)数据上充分学习。正如备注所示,如果数据量很大,此值应该调低,以防止模型过拟合(即过度记忆训练数据而丧失泛化能力)。
获取 LLamafactory 项目
按照要求安装好依赖
准备数据集
- 将
finance_sharegpt.jsonl放到data里, 格式如下
jsonl
{"conversations": [{"from": "human", "value": "什么是H股"}, {"from": "gpt", "value": "H股是注册地在中国内地、上市地在香港交易所的公司股票。它以港币交易,受香港市场规则约束。"}]}
{"conversations": [{"from": "human", "value": "什么是蓝筹股"}, {"from": "gpt", "value": "蓝筹股通常指规模大、经营稳定、行业地位较高的上市公司股票。它们波动相对较低,但并不代表没有投资风险。"}]}- dataset_info.json 注册数据集
json
"finance_sharegpt": {
"file_name": "finance_sharegpt.jsonl",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"tags": {
"role_tag": "role",
"user_tag": "user",
"assistant_tag": "gpt"
}
}
}启动LLamafactory
sh
# 安装好依赖后启动
llamafactory-cli webui参数设置及训练
- 自行注册 swanlab 获取key
- 除了核心参数还需设置一下参数, 参考截图,点开始训练

测试
训练完成后可以调到chat 选项卡里进行聊天测试
最终测试应加载检查点后加载模型,如图
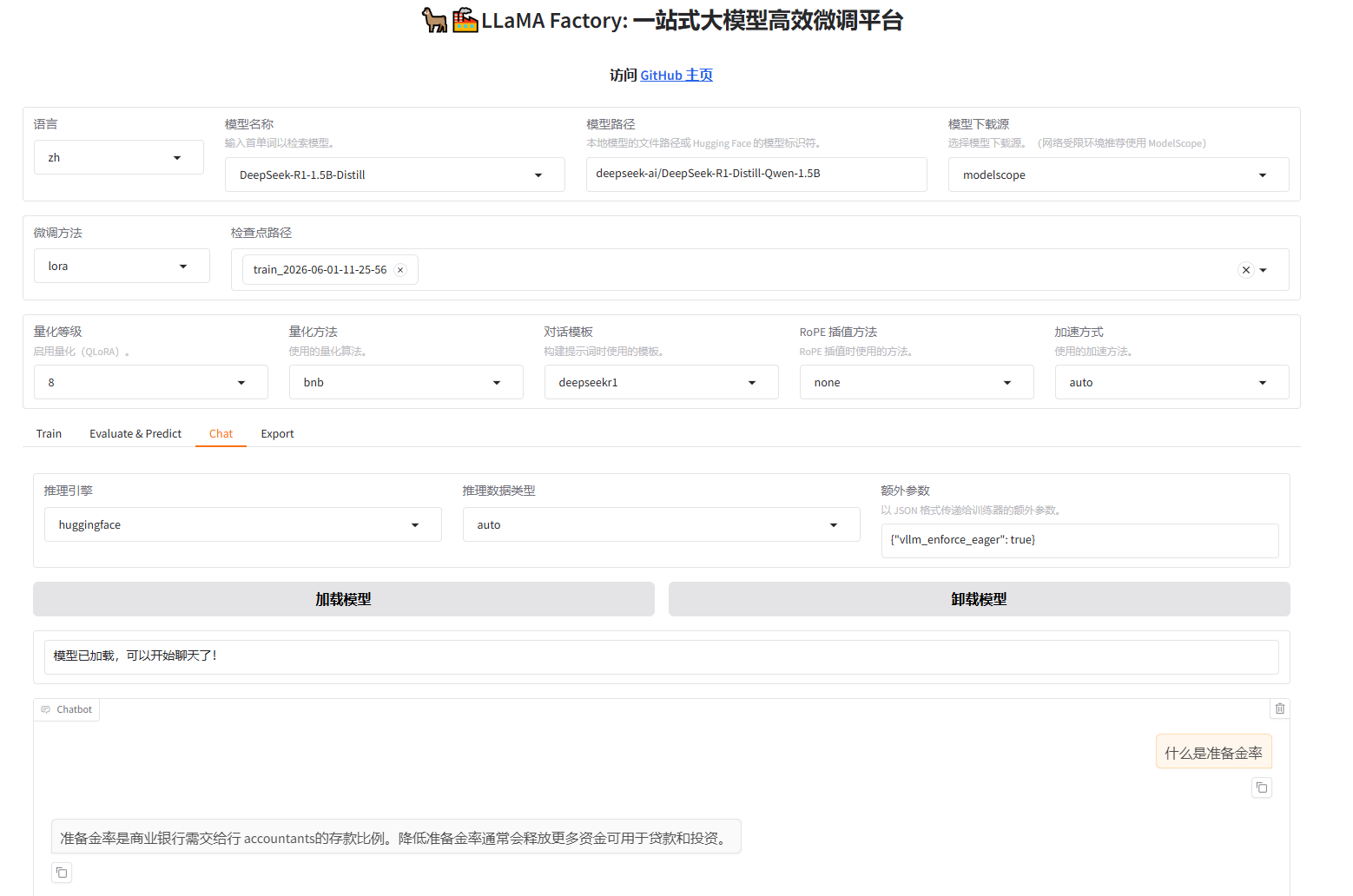
- 以下是对比数据截图

可以感觉已经收到了训练数据的影响
训练结果图表解读
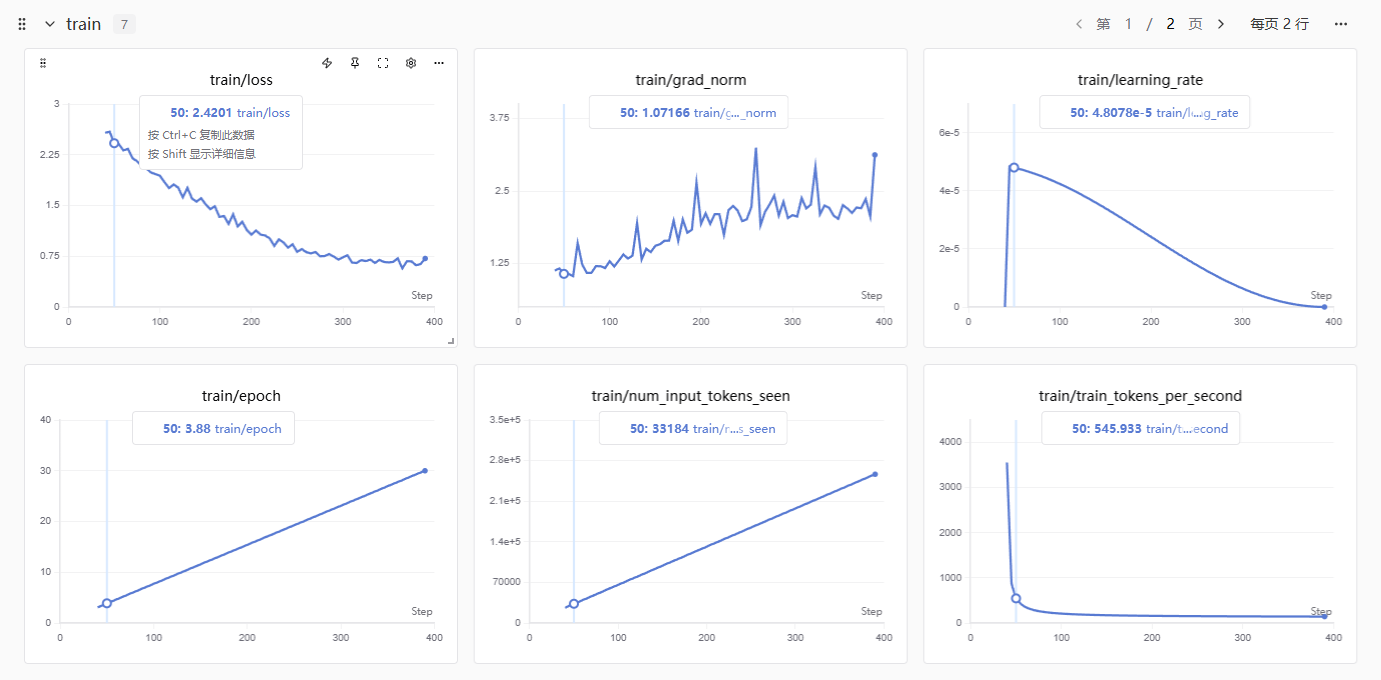
以下是训练过程中生成的监控图表及其详细解读:
1. train/loss(损失函数曲线)------ 核心收敛表现
图表表现:曲线从 Step 50 时的 2.42 一路顺滑下降,最终在 Step 300-400 之间稳定在 0.7 左右,形成完美的"L型"底座。
深度含义:
- 平滑的下降弧度表明学习率和优化器参数设置科学
- 模型已充分学习训练数据
- 最终平直的线段证明在此时结束训练非常精准,既没有过早中断(未学完),也没有过度训练导致过拟合
2. train/grad_norm(梯度范数)------ 训练稳定性
图表表现:曲线在 1.0-2.5 之间波动,Step 300 后有小幅反弹(最高约 3.5),但整体控制在合理低位。
深度含义:
- 波动主要由于 Batch Size 较小(2),样本差异导致梯度波动
- 没有出现梯度爆炸(Gradient Explosion)现象
- 训练过程健康稳定
3. train/learning_rate(学习率变化)------ 训练策略
图表表现:
- Step 50 前:急速上升(Warmup 阶段)
- Step 50:达到峰值 4.8e-5(接近设置的 5e-5)
- 随后:以余弦退火(Cosine)方式缓慢降至 0
深度含义:
- 学习率调节器(lr_scheduler)运作符合预期
- 前期快速学习,后期精细调整
- 在不破坏原有知识的前提下对齐金融数据集
4. train/epoch(训练轮数进度)------ 进度监控
图表表现:完美的笔直对角线,从 Step 50 的 3.88 轮到 Step 390+ 的第 30 轮。
深度含义:
- 训练过程平稳连续
- 无数据格式死锁或硬件故障导致的卡顿
- 每轮计算步数恒定
5. train/num_input_tokens_seen(累计输入 Token 数)
图表表现:完美的线性上升曲线,最终约 26 万 Token。
深度含义:
- 200 条数据 × 30 轮 ≈ 6000 次样本处理
- 平均每个样本(含 Prompt 和 Answer)约 40-50 tokens
- 累计处理总量符合预期
6. train/train_tokens_per_second(显卡吞吐量)
图表表现:
- Step 50:545.9 tokens/s(fp32 计算,硬件未跑满)
- 后续步骤:稳定在 100-200 tokens/s 的低水平线
深度含义:
- fp32 计算拖慢了 V100/T4 显卡性能
- 数据集轻量(200 条),十几分钟即可完成训练
- 下次可优化为 fp16 以提升效率
🏁 最终评估
总体评分:90 分(优秀)
优点:
- 模型收敛极佳(Loss 0.7 很理想)
- 训练过程极度稳定(无 NaN,无梯度爆炸)
改进建议:
- 计算精度:下次微调时将 fp32 改为 fp16
- 训练轮数:将 epoch 从 30 降低到 5-10 轮
- 预期效果:不仅训练速度大幅提升,模型泛化表现也会更灵动