LoRA (Low-Rank Adaptation of Large Language Model)
大规模语言模型的低秩适应
低秩: 指矩阵的秩远小于其行数和列数,意味着数据中存在大量冗余信息 。
NLA - 自然语言自编码器(Natural Language Autoencoder(s))
DeepSeek-Flash(即DeepSeek-V4-Flash)的总参数量为2840亿(284B),但在实际推理时,只会激活约130亿(13B)的参数
LLaMA-Factory
Unsloth Pro + LoRA-XT + QLoRA
HuggingFace生态: https://huggingface.co/
阿里巴巴达摩院提出的魔塔社区: https://modelscope.cn
行业有人称其为中国版的HuggingFace
LLaMA-Factory: https://github.com/hiyouga/LLaMA-Factory
Unsloth: https://github.com/unslothai/unsloth
适用 RTX 5080
使用的5080 16G显存 甜点级 大模型
文本生成模型:8B-13B级别(如Llama 3 8B/13B、Qwen2.5 14B)全精度模型
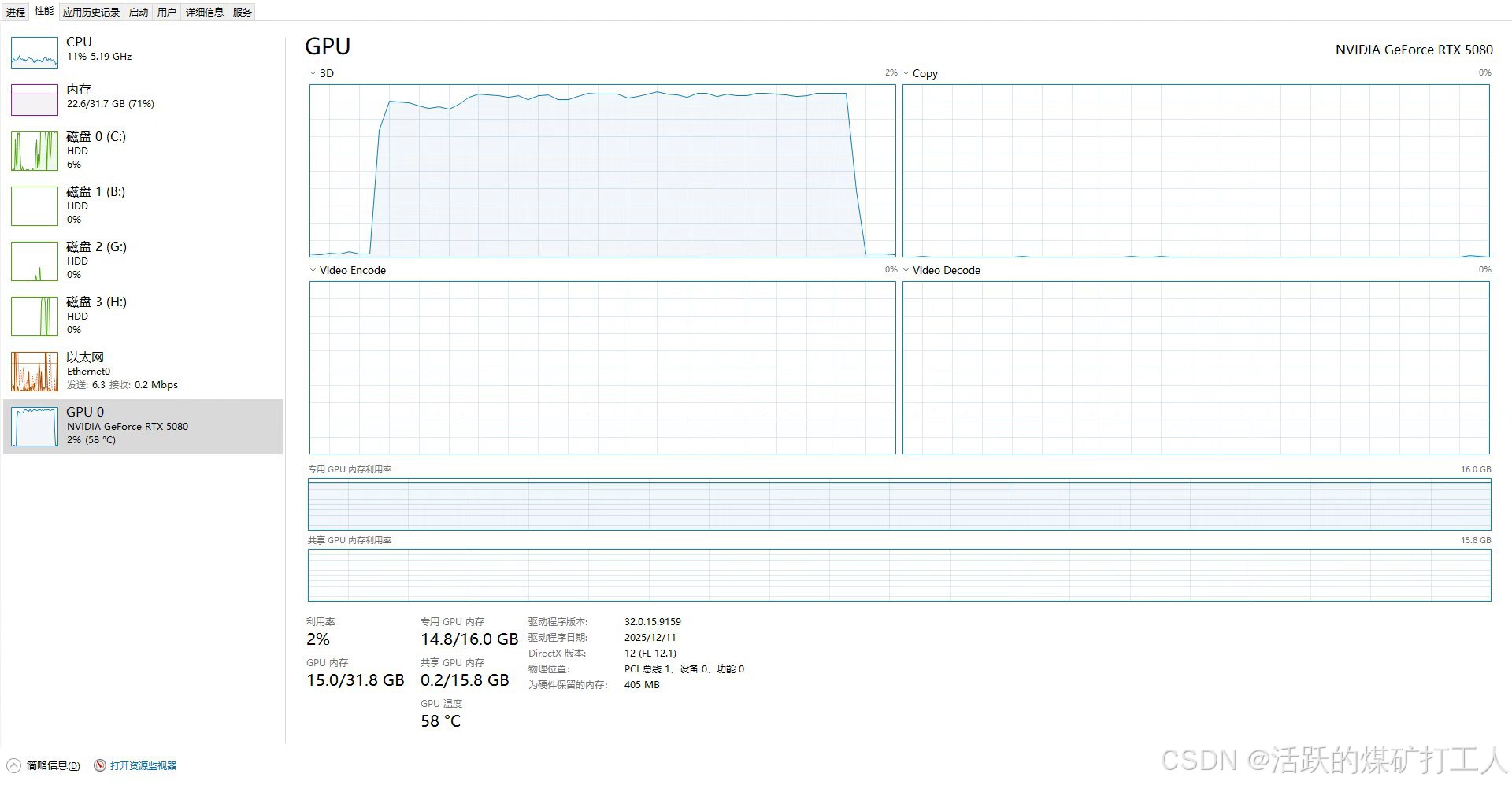
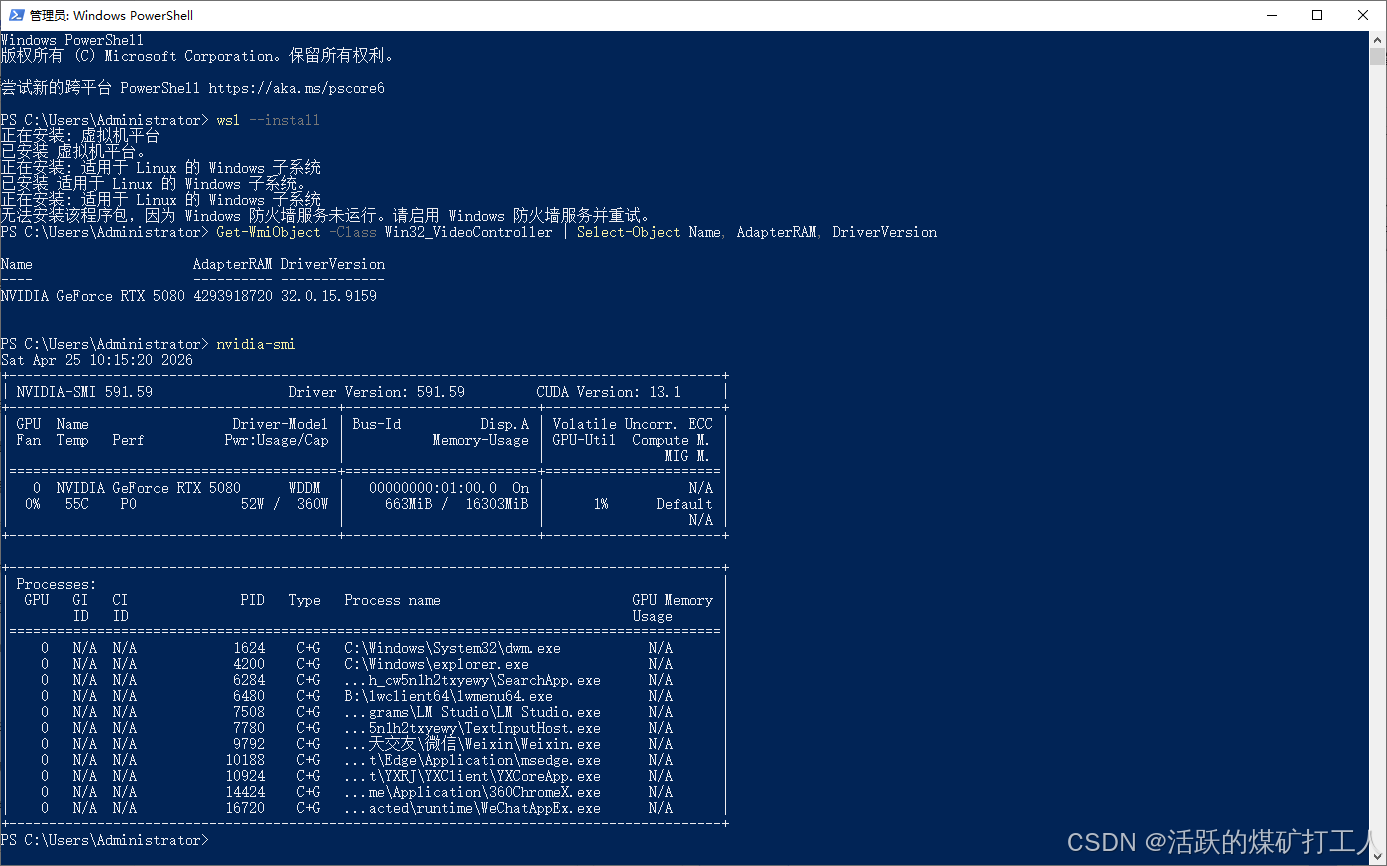
对比ollama提供的cloud 模型速度比,本地速度快出一小截
可能涉及到本地调整的参数与云上不同,以及云传的网络过滤延迟等。