量化算法的本质
量化算法的本质在于快速实现Y=XW计算,其中X,W往往都是FP16数据类型,在大模型推理过程中,输入X往往被称之为activation,而权重W被称之为weight,对于一个M,K,N的矩阵乘法(即X的形状为M,K,W形状为K,N,Y形状为M,N)的矩阵来说,最简单的实现方式就是调用cublas仓库,这里需要重点注意的是X和W的排列方式,尤其是W的排列方式,比如说下面这段代码
cpp
cublasGemmEx(
handle,
CUBLAS_OP_T,
CUBLAS_OP_N,
N,
M,
K,
&alpha,//alpha = 1.0f
W, CUDA_R_16F, ldb,//ldb = K
X, CUDA_R_16F, lda,//lda = K
&beta,//beta = 0.0f
Y, CUDA_R_32F, ldo,//ldo = N
CUBLAS_COMPUTE_32F,
CUBLAS_GEMM_DEFAULT);处理的就是Y=XW的计算过程,但是其中X是行主元数据(即X形状是M,K,步长stride是K,1),而W是列主元数据(即W形状是K,N,步长stride是1,K,这个可以通过W = torch.randn(N,K).t()这种方式得到)。
上面的这个矩阵乘法大家耳熟能详,但是这个矩阵乘法在大模型推理训练过程中会带来一些问题,比如说最直接的就是显存占用情况,假设我们只考虑Y=XW这个计算,如果W是一个数据量为8B(80亿参数)的矩阵,如果W的每个元素都是FP16,那么W需要占用显存(GB)= 参数量×数据比特数/(8×1024×1024×1024)=14.9,也就是说,仅仅考虑存储这个权重W就需要占用14.9GB显存,如果我们能够换一种思路,比如说把权重的数据类型换成INT8,此时显存马上可以降低一半变成7.45GB,如果进一步把权重数据类型变成INT4,那么显存继续降低变成3.73GB,也就是说,对于一个稍微普通的带显卡的笔记本,就可以实现这个推理过程了。
在输入X,也就是activation数据类型为F16的情况下,W数据类型为INT8,此时的量化称之为W8A16量化,如果W数据类型为INT4,此时量化称之为W4A16量化。
比如说W8A8量化,指的就是输入X数据类型为INT8,权重矩阵数据类型也是INT8。
矩阵的量化算法
这里我们先介绍一下矩阵的量化算法,即:一个形状为K,N,数据类型为FP16的权重矩阵W,是如何变成另一个形状为K,N,数据类型为INT4或者INT8的量化矩阵w_packed。下面我们以INT8来举例子说明:
per_tensor_quant_int8
这种量化最简单,先计算出全局的abs最大值global_max = max(abs(W.flatten())),此时引入一个scale = global_max /127,有了scale以后,下面使用这段伪代码
python
for i in range(K):
for j in range(N):
val = W[i,j] / scale
val = max(-127, min(127, val))
w_packed[i,j] = val.to(torch.int8)通过上面这种方式得到的结果,我们称之为对称量化,这种对称量化方式涉及到的参数有w_packed, scale和W,其中scale是一个长度为1的数据类型为F32的tensor,与之对应的还有一个非对称量化,非对称量化会多一个zero参数,但是实际大模型量化过程中用的最多的就是对称量化。
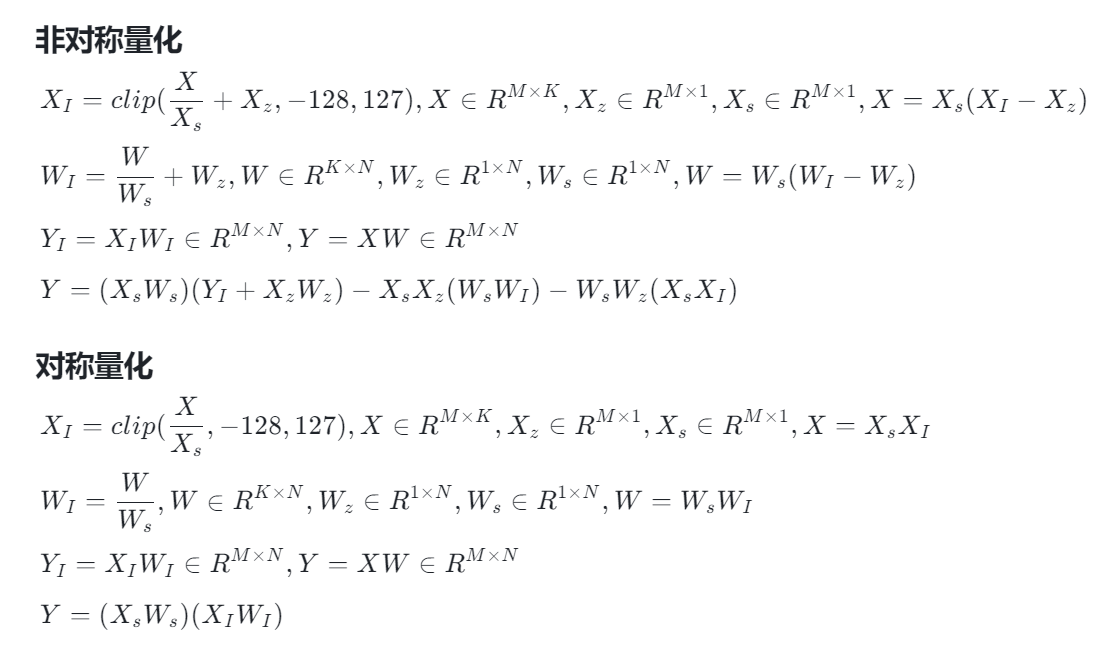
per_channel_quant_int8
有了上面关于per_tensor_quant_int8量化的介绍,此时理解per_channel_quant_int8量化就简单多了,对称的per_channel_quant_int8量化和上面的区别在于scale的形状变成了K,1,也就是说,原来需要计算整个矩阵abs(W)的全局最大值,现在需要针对每一行abs(Wi,:计算最大值,python代码实现可以参考
python
def per_channel_quant_int8_torch(x, symmetric):
if symmetric:
x = x.float()
absmax = x.abs().max(dim=-1).values
absmax = absmax.clamp_min(1e-10).unsqueeze(-1)
scale_x = absmax / 127
x_q = x.mul(127 / absmax)
x_q = torch.round(x_q).to(torch.int8)
return x_q, scale_x, None
else:
w = x.float()
w_min = w.min(dim=-1, keepdim=True)[0]
w_max = w.max(dim=-1, keepdim=True)[0]
w_scale = (w_max - w_min) / 255.0
w_scale = torch.clamp(w_scale, min=1e-8)
w_zero = -w_min / w_scale - 128.0
w_q = torch.round(w / w_scale + w_zero)
w_q = torch.clamp(w_q, -128, 127)
w_packed = w_q.to(torch.int8)
return w_packed, w_scale, w_zero与之类似的还有per_channel_quant_fp8,per_tensor_quant_fp8,本质上没有区别,只不过最后量化结果数据类型不一致而已,至于per_channel_quant_int8和per_tensor_quant_int8的CUDA代码实现也非常简单,可以参考添加链接描述和添加链接描述
真正的难点在于矩阵乘法。
量化模型的矩阵乘法
在量化大模型推理过程中,一般会提前提供已经量化好的权重以及对应的scale,也就是说,现在需要实现的计算过程拥有下面几个参数:
X:形状为M,K,往往是行主元,即步长stride=K,1,数据类型为FP16或者FP32
W:形状为K,N,如果是行主元,那么步长stride=N,1,如果是列主元,步长stride=1,K,数据类型可能为INT4或者是INT8
scale:当形状为M,1对应的是per_channel_quant,当形状为1,的时候,对应的是per_tensor_quant,数据类型为FP32
zero:这是optional参数,数据类型和形状往往和scale保持一致(但是awq_marlin_gemm,gptq_marlin_gemm这些量化模型可能会很不一样),如果zeros存在,那么对应的就是非对称量化,如果zeros不存在,对应的就是对称量化。
bias:这是一个optional参数,数据类型为FP32,形状往往为N,1
W8A8矩阵乘法
我们以W8A8对称量化算法来举例说明量化矩阵乘法,计算过程涉及的参数就变成了:
X:形状为M,K,往往是行主元,即步长stride=K,1,数据类型为INT8
W:形状为K,N,这里我们考虑列主元,步长stride=1,K,数据类型为INT8
x_scale:形状为M,1,数据类型为FP32
w_scale:形状为N,1,数据类型为FP32
bias:这是一个optional参数,数据类型为FP32,形状为N,1
需要实现的计算大概就是
Y = (x_scale * X)@ (w_scale * W) + bias,
在具体的实现过程中,有两种方案,
方案1:先调用cublas计算y_packed = x_packed@w_packed,由于此时x_packed, w_packed数据类型都是INT8的,使用cublas计算速度会特别快,这个时候相当于说,我们需要在CUDA层面额外引入一份显存来存储这个临时数据y_packed,cublas的计算流程可以参考下面这段代码
cpp
const int32_t alpha_I = 1;
const int32_t beta_I = 0;
cublasGemmEx(
handle,
CUBLAS_OP_T,
CUBLAS_OP_N,
N,
M,
K,
&alpha_I,
b, CUDA_R_8I, ldb,//ldb = K
a, CUDA_R_8I, lda,//lda = K
&beta_I,
y_packed, CUDA_R_32I, ldo,//ldo=N
CUBLAS_COMPUTE_32I,
CUBLAS_GEMM_DEFAULT);特别注意,上面的这段代码里面要求x_packed是行主元的形状为M,K的指针,而w_packed是列主元的,形状为K,N的指针,其中x_packed可以通过torch.randn(M,K)直接生成,而w_packed可以通过torch.randn(N,K).t()直接生成。有了y_packed以后,剩下的就是做后处理,根据x_scale和w_scale以及y_packed把结果还原出来,这部分比较简单。
可以看出,这个方案1其实需要实现两个kernel,第一个kernel调用cublas,第二个kernel进行后处理,这个方案非常直接简单,但是在性能上不占优势,CUDA代码里面,我们希望一个算子往往只占用一个kernel,这种做法肯定会比直接使用torch.matmul计算FP16的X@W要慢。
方案2:直接调用cutlass来计算整个过程,这个说起来很简单,但是实现起来非常复杂,这个的原始代码参考添加链接描述
GPTQ MARLIN矩阵乘法
Gptq marlin矩阵乘法计算的也是Y=XW,其中X,W往往都是FP16数据类型,在大模型推理过程中,输入X往往被称之为activation,而权重W被称之为weight,对于一个M,K,N的矩阵乘法(即X的形状为M,K,W形状为K,N,Y形状为M,N)的矩阵来说。这个算法的核心目的包括:
1:把浮点权重(W)量化压缩到 4bit/8bit(体积缩小 4~8 倍);
2:把量化后的权重重排成 MARLIN 专用格式(适配 GPU 硬件执行单元);
3:保证推理速度接近浮点、精度几乎无损。
模块1:将浮点数据类型的W量化得到量化权重w_q, w_s, w_z以及根据(w_q,w_s,w_z)反量化得到的w_ref
首先根据下面的逻辑做数据重排
python
# 代码逻辑
w = w.reshape((-1, group_size, size_n)) # [K/group, group, N]
w = w.permute(1, 0, 2) # [group, K/group, N]
w = w.reshape((group_size, -1)) # [group, K/group * N]然后获取对应group的最大值,最小值以及绝对最大值。
python
max_val = torch.max(w, 0, keepdim=True).values
min_val = torch.min(w, 0, keepdim=True).values
abs_val = torch.max(abs(max_val), abs(min_val)如果需要设置零点,那么就计算对应的w_s和w_z,参考
python
max_q_val = quant_type.max()
min_q_val = quant_type.min()
w_s = (max_val - min_val).clamp(min=1e-5) / quant_type.max()
maybe_w_zp = (
torch.round(torch.abs(min_val / w_s)).clamp(min_q_val, max_q_val).int()
)这里提到的quant_type就是对应的量化类型,如果是int8量化,那么对应的quant_type就是int8,此时对应的上下界max_q_val,min_q_val就是127,-127,用数学公式表达就是
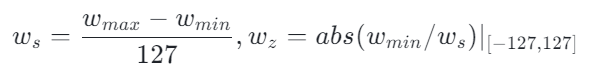
如果不需要设置零点,那么只计算w_s,对应的代码参考
python
w_s = torch.max(
abs(max_val / (max_q_val if max_q_val != 0 else torch.inf)),
abs(min_val / (min_q_val if min_q_val != 0 else torch.inf)),
)用数学公式表达就是
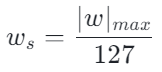
对应的量化权重计算参考
python
w_q = torch.round(w / w_s).int() + (maybe_w_zp if zero_points else 0)
w_q = torch.clamp(w_q, min_q_val, max_q_val)用数学公式表达就是
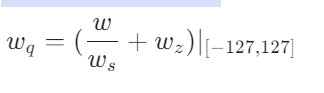
最后根据刚才计算的w_q,w_s,w_z得到一个反量化的w_ref=(w_q - w_z)w_s,值得说明的是,此时这个w_ref和最原始的w大概率不等价。
GPTQ 把权重压成 INT4/INT8,但直接存成 K,N 矩阵,GPU 跑不快。这是因为
1:GPU TensorCore(MMA)一次喜欢读 16×16 小块;
2:而且要连续内存、特定顺序才能用向量加载(LDG.128);
3:原生矩阵是 "行主序",不满足硬件读取模式。
Marlin perm 的本质: 把 INT4/INT8 权重重新切成 16×16 瓦片 → 打乱瓦片内部元素顺序 → 拼成 GPU 最喜欢的内存布局。重点:perm 不是随机乱排,是硬编码的、为了 TensorCore 读得快的固定重排。
这个marlin重排的过程很复杂,本人也不太能看懂。
awq_marlin_gemm和gptq_marlin_gemm的主要区别在于awq_marlin不支持zeros,
awq_marlin的实现源代码来自添加链接描述
gptq_marlin的实现源代码来自添加链接描述