Raft 协议把分布式一致性拆成三个相对独立的子问题:
- Leader 选举 ------ 集群选出一个 Leader,所有写操作由 Leader 处理
- 日志复制 ------ Leader 把操作复制到所有节点,达到一致后提交
- 安全性 ------ 保证已提交的日志不会被覆盖(选举限制 + 提交规则)
节点的三种状态和定时器
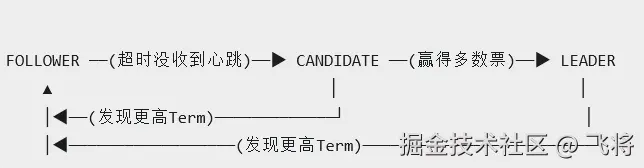
arduino
// 三种状态
private volatile NodeState state = NodeState.FOLLOWER;
// volatile 状态(所有节点都有)
private volatile long commitIndex = 0; // 已提交到哪了
private volatile long lastApplied = 0; // 已应用到状态机到哪了
private volatile String currentLeader; // 当前 Leader 是谁
// Leader 专属(跟踪每个 Follower 的复制进度)
private final Map<String, Long> nextIndex; // 下一条该发给它的日志索引
private final Map<String, Long> matchIndex; // 已确认复制成功的最高索引关键点:nextIndex 和 matchIndex 只在 Leader 上维护。Leader 根据 matchIndex 判断哪些日志已经复制到多数节点上,从而推进 commitIndex。
Leader 选举的完整流程
选举定时器 ------ 随机化的精髓
Raft 用随机选举超时来避免多个 Candidate 同时发起选举(脑裂):
ini
// RaftNode.java --- resetElectionTimer()
long timeout = electionTimeoutMinMs
+ random.nextLong(electionTimeoutMaxMs - electionTimeoutMinMs);
electionTask = scheduler.schedule(this::startElection, timeout, TimeUnit.MILLISECONDS);假设 3 个节点同时启动,如果没有随机化,它们可能在同一时刻超时、同时成为 Candidate、同时发出投票请求,谁也得不了多数票,永远选不出 Leader。随机化让其中一个节点先超时,先发起选举,先拿到多数票。
发起选举 ------ 自增 Term + 投自己一票
ini
private synchronized void startElection() {
currentTerm++; // 任期 +1
votedFor = nodeId; // 投自己
persistState(); // ⚠️ 持久化!保证重启后不违背投票承诺
state = NodeState.CANDIDATE;
long lastLogIdx = getLastLogIndex();
long lastLogTerm = getLastLogTerm();
int votesGranted = 1; // 自己的票
int needed = (clusterMembers.size() / 2) + 1; // 需要多数
// 并发向所有其它节点发 RequestVote RPC
for (String peer : clusterMembers) {
if (peer.equals(nodeId)) continue;
transport.requestVote(peer,
new RequestVoteRequest(currentTerm, nodeId, lastLogIdx, lastLogTerm))
.thenAccept(resp -> {
// 回调里检查...
});
}
}这里有两个关键细节:
-
每次选举必须自增 Term
Term 是 Raft 里的"逻辑时钟",全局单调递增。任何一个节点发现自己的 Term 比对方小,就立即转为 Follower。这保证了集群在任意时刻只有一个最高 Term。
-
带上 lastLogIndex 和 lastLogTerm
假设节点 A 的日志是
[1,1,2,2,3](已提交到索引 5),节点 B 的日志是[1,1,2,2](只到索引 4,且最后一条还没提交)。如果 B 当选 Leader,可能会覆盖 A 上已经提交的日志 ------ 违反安全性。所以 Candidate 必须拥有比投票者更新的日志,比较规则是先比 Term 再比 Index。
投票方怎么决定是否投票
scss
public synchronized RequestVoteResponse handleRequestVote(RequestVoteRequest req) {
// 规则 1: 对方的 Term 大于我 → 我认输,转为 Follower
if (req.getTerm() > currentTerm) {
stepDown(req.getTerm());
}
// 规则 2: 对方 Term 比我小 → 拒绝
if (req.getTerm() < currentTerm) {
grant = false;
}
// 规则 3: 对方 Term 等于我,且我还没投过票(或就是投给它的)
else if (votedFor == null || votedFor.equals(req.getCandidateId())) {
// 规则 4: Candidate 日志至少和我一样新
// 先比较 lastLogTerm,相等时再比较 lastLogIndex
if (req.getLastLogTerm() > myLastTerm
|| (req.getLastLogTerm() == myLastTerm
&& req.getLastLogIndex() >= myLastIdx)) {
votedFor = req.getCandidateId();
persistState(); // ⚠️ 投票要持久化
grant = true;
resetElectionTimer(); // 重置自己的选举定时器
}
}
}投票的四条规则:
- 对方的 Term 大于我 → 我认输,转为 Follower
- 对方 Term 比我小 → 拒绝
- 对方 Term 等于我,且我还没投过票(或就是投给它的)
- 如果要投票给对方,必须确保对方日志至少和我一样新 ------ 对方的 lastLogTerm 大于我,或 lastLogTerm 相同但 lastLogIndex ≥ 我
votedFor 被持久化到磁盘上。如果节点在投完票后宕机重启,它还能记住自己已经投过票了,不会在同一个 Term 里投两次 ------ 这防止了同一个 Term 有两个 Leader。
计票 & 成为 Leader
ini
private void becomeLeader() {
state = NodeState.LEADER;
currentLeader = nodeId;
// 初始化每个 Follower 的 nextIndex = 自己最后一条日志 +1
long lastIdx = getLastLogIndex();
for (String peer : clusterMembers) {
nextIndex.put(peer, lastIdx + 1);
matchIndex.put(peer, 0L);
}
// 立刻发送心跳(空 AppendEntries)
heartbeatTask = scheduler.scheduleAtFixedRate(
this::sendHeartbeat, 0, heartbeatIntervalMs, TimeUnit.MILLISECONDS);
// 取消选举定时器 ------ Leader 不需要
if (electionTask != null) electionTask.cancel(false);
}Leader 当选后马上广播心跳,目的是尽快让所有 Follower 知道新 Leader 的存在,也阻止其他节点发起新的选举(因为收到心跳就重置选举定时器)。
日志复制 ------ 一致性的核心
AppendEntries RPC 的字段含义
makefile
AppendEntriesRequest:
term → Leader 的任期
leaderId → 告诉 Follower 谁是 Leader
prevLogIndex → "我要追加的日志的前一条"的索引
prevLogTerm → "我要追加的日志的前一条"的任期
entries → 要追加的日志条目列表
leaderCommit → Leader 的 commitIndex(告诉 Follower 你也能提交了)prevLogIndex 和 prevLogTerm 是这个 RPC 最核心的设计 ------ 它们实现了日志一致性检查。
Leader 端:发送日志
scss
private void sendAppendEntries(String peer) {
// 从 nextIndex 反算该从哪里开始发
long prevIdx = nextIndex.getOrDefault(peer, getLastLogIndex() + 1L) - 1;
// 收集从 prevIdx+1 开始的所有日志
List<LogEntry> entries = new ArrayList<>();
for (LogEntry e : logEntries) {
if (e.getIndex() > adjustedLastIncluded && e.getIndex() >= startBatch) {
entries.add(e);
}
}
long prevTerm = getLogTermAtIndex(prevIdx);
AppendEntriesRequest req = new AppendEntriesRequest(
currentTerm, nodeId, prevIdx, prevTerm, entries, commitIndex);
transport.appendEntries(peer, req).thenAccept(resp -> {
if (resp.isSuccess()) {
// 成功 ------ 推进 nextIndex 和 matchIndex
matchIndex.put(peer, prevIdx + entries.size());
nextIndex.put(peer, newMatch + 1);
advanceCommitIndex(); // ⚠️ 检查是否能提交了
} else {
// 失败 ------ nextIndex 倒退一位,重试
nextIndex.put(peer, Math.max(1, nextIndex.get(peer) - 1));
}
});
}回溯机制是最精彩的设计之一:当 Follower 拒绝 AppendEntries(因为 prevLogIndex 位置上的日志不一致),Leader 就把 nextIndex 减 1 后重试。这是一个二分查找的退化版(线性回溯),简单但有效。最坏情况下要回溯整条日志,但实际中几乎不会发生,因为正常情况下 Leader 和 Follower 的日志高度一致。
Follower 端:接收 & 一致性检查
scss
public synchronized AppendEntriesResponse handleAppendEntries(AppendEntriesRequest req) {
// 步骤 1: Term 检查(跟投票逻辑一样)
if (req.getTerm() > currentTerm) stepDown(req.getTerm());
if (req.getTerm() < currentTerm)
return new AppendEntriesResponse(currentTerm, false, 0);
// 步骤 2: 收到合法的 Leader 心跳 → 重置选举定时器
currentLeader = req.getLeaderId();
state = NodeState.FOLLOWER;
resetElectionTimer();
// 步骤 3: ⚠️ 一致性检查 ------ 核心
long localPrevTerm = getLogTermAtIndex(req.getPrevLogIndex());
if (localPrevTerm != req.getPrevLogTerm()) {
return new AppendEntriesResponse(currentTerm, false, 0);
// ↑ 拒绝!告诉 Leader 我们这里不一致
}
// 步骤 4: 追加新条目,冲突的就截断
for (LogEntry entry : req.getEntries()) {
// 如果这条索引上已有不同 Term 的日志,删除它及之后所有
if (existing != null && existing.getTerm() != entry.getTerm()) {
while (logEntries.size() > pos) logEntries.remove(...);
}
logEntries.add(entry);
}
// 步骤 5: 推进 commitIndex
if (req.getLeaderCommit() > commitIndex) {
commitIndex = Math.min(req.getLeaderCommit(), getLastLogIndex());
applyCommitted();
}
}一致性检查 prevLogTerm != localPrevTerm 是 Raft 保证安全性的核心。用一个例子来解释:
ini
Leader 日志: [1] [1] [2] [2] [3] [3]
↑ index=2, term=1
假设 prevLogIndex=2,prevLogTerm=1
Follower 在 index=2 处的日志 Term 必须是 1,否则说明双方日志在此分叉
比如 Follower 日志: [1] [1] [2] [4] ← index=2 处 term=1(匹配),分歧在后面
[1] [1] [3] [3] ← index=2 处 term=1(匹配),分歧在后面
[1] [2] [2] [2] ← index=2 处 term=2 ≠ 1,直接拒绝!如果 Follower 拒绝,Leader 会回溯 nextIndex,下次从更早的索引开始发,直到找到双方一致的 point,再从那里开始覆盖。
提交:只有 Leader 当前 Term 的日志才能推进 commitIndex
ini
private void advanceCommitIndex() {
// 收集所有节点的 matchIndex,取中位数(多数)
List<Long> matches = new ArrayList<>();
matches.add(getLastLogIndex()); // Leader 自身
matches.addAll(matchIndex.values());
matches.sort(Collections.reverseOrder());
int majority = (clusterMembers.size() / 2) + 1;
long newCommit = matches.get(Math.min(majority - 1, matches.size() - 1));
if (newCommit > commitIndex) {
long t = getLogTermAtIndex(newCommit);
if (t == currentTerm) { // ⚠️ 只能提交自己任期的日志
commitIndex = newCommit;
applyCommitted();
}
}
}为什么只能提交自己任期的日志?
这是 Raft 安全性最关键的设计。考虑以下场景:
| 时间 | 事件 |
|---|---|
| Term 1 | S1 是 Leader,复制日志 [index=2, term=1] 到 S1 和 S2 后就宕机,这条日志没达到多数,没提交 |
| Term 2 | S5 当选(日志更新),它复制了一条自己的日志 [index=2, term=2] 到 S3/S4/S5,成功提交 |
| Term 3 | S1 重新当选(日志 [index=2, term=1] 还在它本地),如果 S1 把 term=1 的旧日志提交了 → 它会覆盖 S5 在 Term 2 已经提交了的 [index=2, term=2] |
这意味着 一条已提交的日志被删除了,违反了 Raft 的安全性保证。
所以论文规定:Leader 只能通过提交自己任期的日志来"连带"提交之前任期的日志。这被称为"Commitment by current term"规则。
具体做法:S1 当选后,不在 index=2 处直接提交旧的 term=1 日志。它必须在 index=3 处创建一条 term=3 的新日志,将这条 term=3 的日志复制到大多数节点。当 term=3 的日志被提交时,index=2 的 term=1 日志自动连带被提交。
为什么这样安全?因为一旦 term=3 的日志存在于大多数节点上,根据 Leader 完备性:任何未来的 Leader 必须拥有这条 term=3 的日志(否则它无法获得大多数投票),而任何拥有 term=3 日志的节点,根据日志匹配特性,必然拥有前面 index=2, term=1 的日志。
快照 ------ 压缩日志
Raft 日志会随着时间膨胀。快照是解决方案:
ini
public synchronized void takeSnapshot() {
Snapshot snap = stateMachine.takeSnapshot(); // 让状态机自己拍快照
snap.setLastIncludedIndex(lastApplied);
snap.setLastIncludedTerm(getLogTermAtIndex(lastApplied));
// 删除已被快照覆盖的日志条目
logEntries.removeIf(e -> e.getIndex() > adjustedLastIncluded
&& e.getIndex() <= cutoff);
lastIncludedIndex = lastApplied;
lastIncludedTerm = getLogTermAtIndex(lastApplied);
// 持久化到磁盘
MAPPER.writeValue(snapPath.toFile(), snap);
}如果 Leader 需要发给一个落后很多的 Follower,而 Leader 已经把日志压缩了,Leader 会发 InstallSnapshot RPC 把整个快照发给 Follower。Follower 收到后直接替换自己的状态机和日志。
成员变更 ------ 联合共识
在成员变更过程中,如果直接切换到新配置,可能出现"两个 Leader"同时存在(脑裂)的情况。
问题
假设一个 5 节点集群(A,B,C,D,E)要缩容为 3 节点(A,B,C)。
如果直接让各节点从旧配置切到新配置,由于网络延迟,不同节点切换的时间点不同:
- A、B 已经切换到新配置(3 节点,多数 = 2)
- C、D、E 还在旧配置(5 节点,多数 = 3)
此时如果 A、B 与 C、D、E 网络分区:
- A、B 认为自己有 2/3,可以选出 Leader
- C、D、E 认为自己有 3/5,也可以选出 Leader
两个 Leader 同时存在 → 数据不一致。
联合共识的核心思想
联合共识的思路是:变更过程中,不是在不同时刻使用不同配置,而是让"旧配置"和"新配置"同时生效。
具体规则:
在联合共识阶段,一个日志条目要被提交,必须同时获得旧配置的多数同意和新配置的多数同意。
也就是说,这个阶段的"多数"是两个配置都要过半。
成员变更的两阶段流程
第一阶段:进入联合配置(Cold,new)
Leader 向集群发送一个特殊的日志条目,内容是 Cold,new(旧配置 + 新配置的组合)。
各节点收到后,立即生效这个联合配置:
- 选举:必须同时获得旧配置多数和新配置多数的投票,才能成为 Leader
- 提交:必须同时获得旧配置多数和新配置多数的确认,日志才能提交
第二阶段:切换到新配置(Cnew)
当 Cold,new 日志被成功提交后,Leader 再发送 Cnew 日志条目。
各节点收到 Cnew 后,切换到纯新配置,成员变更完成。
为什么联合共识能避免脑裂?
关键在于:Cold,new 阶段,任何决策都需要两个配置同时过半。
假设旧配置是 5 节点(A,B,C,D,E),新配置是 3 节点(A,B,C):
- 旧配置多数 = 3 票
- 新配置多数 = 2 票
在 Cold,new 阶段,要成为 Leader 必须同时拿到:
- 旧配置中至少 3 票
- 新配置中至少 2 票
这意味着任何两个候选者不可能同时成功,因为旧配置的 3 票已经占用了 5 个节点中的大多数,不可能同时分给两个候选者。
即使网络分区,最多只有一个候选者能同时满足两个配置的多数要求。
联合共识 vs. 单节点变更
在 Diego Ongaro 的博士论文中,联合共识是通用解法。但在后续的工程实践中(如 etcd),更常用的是单节点变更(One-node membership change):
- 每次只增或减 1 个节点
- 旧配置多数和新配置多数必然有交集(数学保证)
- 不需要显式的联合共识阶段,实现更简单
但联合共识仍然是理论完备的方案,适用于任意规模的成员变更。
下面是一个单步变更的简单实现:
typescript
public void changeMembership(boolean add, String peerId, String peerAddress) {
Set<String> newConfig = new HashSet<>(clusterMembers);
if (add) newConfig.add(peerId);
else newConfig.remove(peerId);
clusterMembers = newConfig;
persisted.setClusterMembers(newConfig);
persistence.save(persisted);
}只要新旧配置的大多数存在交集,就不会出现脑裂,因为新旧多数派都必然要争取至少一个共同的节点。
总结
Raft 的安全性由三条防线共同保证:
| 防线 | 机制 | 防止什么 |
|---|---|---|
| 投票承诺 | votedFor 持久化,每个 Term 只投一次 |
一个 Term 两个 Leader |
| 日志比较 | 投票时比较 lastLogTerm + lastLogIndex |
落后节点当选 Leader |
| 限时提交 | Leader 只提交自己任期的日志 | 已提交的日志被错误覆盖 |
这三条一起保证了 Raft 的 Leader 完备性(Leader Completeness Property):一旦一条日志被提交,所有未来的 Leader 的日志里必定包含这条日志。这是分布式 KV 不丢数据的根本保证。