Raft:分布式系统的定海神针
分布式集群的致命痛点 ------ 脑裂问题
什么是分布式脑裂
在一个多节点组成的分布式集群中,当节点之间发生网络分区 时,原本统一的集群可能被撕裂成两个甚至多个"独立小集群"。每个小集群都认为自己是"正统",各自接收客户端请求、各自修改数据、各自对外提供服务------这就是脑裂(Split-Brain)。
想象一个三节点集群 A、B、C,网络故障后 A 和 B、C 断开连接:
- A 认为自己还在正常运行,继续处理写请求
- B 和 C 组成另一个集群,也在处理写请求
- 同一份数据出现了两个互相冲突的版本

痛点举例
脑裂不是理论假设,而是生产环境中真实存在的风险:
- Nacos 注册中心:多个 Nacos 节点如果元数据不一致,微服务注册与发现将产生混乱,服务调用链路断裂
- RocketMQ 集群:Broker 主从切换时若出现双主,消息可能被重复消费或丢失
- Kafka 控制器选举:Controller 负责管理分区分配,若出现双 Controller,分区元数据将产生冲突
这些场景的共同本质:分布式系统中,多个节点必须对"谁是主、数据是什么"达成唯一共识。
方案
有没有一种通用的、可靠的算法来保证分布式集群的一致性?有------Raft 共识算法 。它是目前分布式一致性领域最主流的标准解法,以"易于理解"著称,被广泛应用于工业界各大中间件。

二、Raft 核心架构:三角色分工,秩序的根基
三大节点角色
Raft 将集群中的每个节点定义为以下三种角色之一:
| 角色 | 职责 |
|---|---|
| Leader(领导者) | 集群唯一的"指挥官",处理所有客户端读写请求,统一调度日志复制 |
| Follower(跟随者) | 被动角色,只负责同步 Leader 下发的日志,接收心跳,不主动决策 |
| Candidate(候选人) | Leader 失联后,Follower 发起选举时的临时身份 |
常态运行逻辑
集群正常运行时,只有一个 Leader,其余节点全部是 Follower。所有客户端请求都由 Leader 统一处理,Follower 没有任何自主决策权。

核心规则很简单:Leader 说了算,其他人听令执行。 这种"单主模式"是 Raft 维持集群秩序的根本。
三、Raft 两大核心机制(上):心跳维持 · 稳定常态
心跳包的作用:状态压制
Raft 集群在正常运行期间,Leader 会周期性地向所有 Follower 发送心跳包(Heartbeat) 。心跳包的作用不仅是"我还活着"的信号,更是一个状态压制机制:
- 每个 Follower 内部都有一个选举超时倒计时器
- 每收到一次 Leader 心跳,倒计时器就重置归零
- 只要 Leader 持续发送心跳,Follower 的倒计时就永远不会到期

运行效果
只要网络正常、Leader 存活,心跳包就能持续压制所有 Follower 的选举冲动。集群在稳定运行期间不会触发任何选举,保证了性能和稳定性。
四、Raft 两大核心机制(中):日志复制 · 保证数据一致
这是 Raft 实现强一致性的核心机制,采用两阶段写入流程。
阶段 1:日志分发(未提交)
- 客户端向 Leader 发送写请求(例如
set x = 1) - Leader 将这条操作记录为一条未提交的日志,写入本地日志文件
- Leader 通过
AppendEntriesRPC,将这条日志并行广播给所有 Follower - Follower 收到日志后写入本地日志文件,返回 ACK 确认
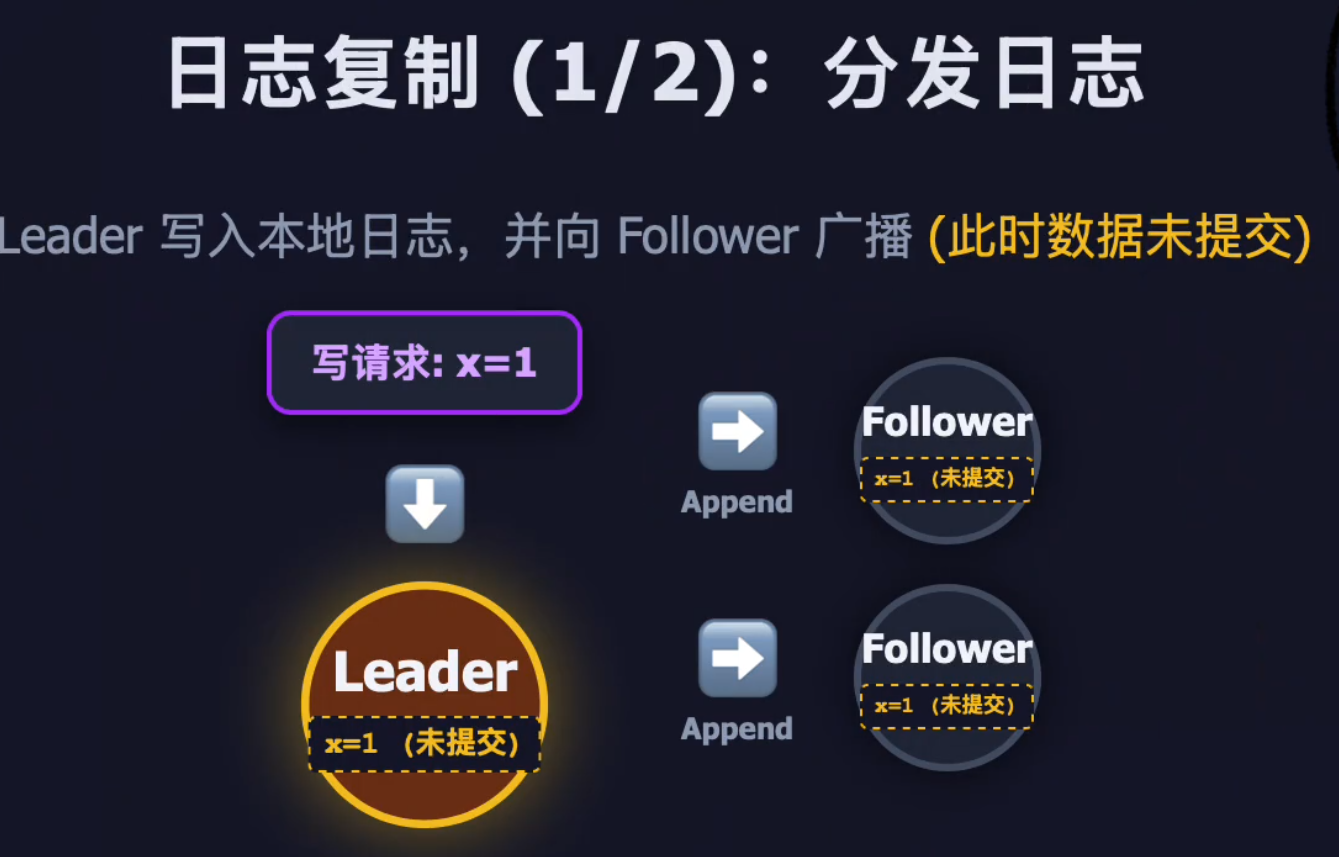
注意:此时数据尚未生效,只是"写入日志",还没有"提交执行"。
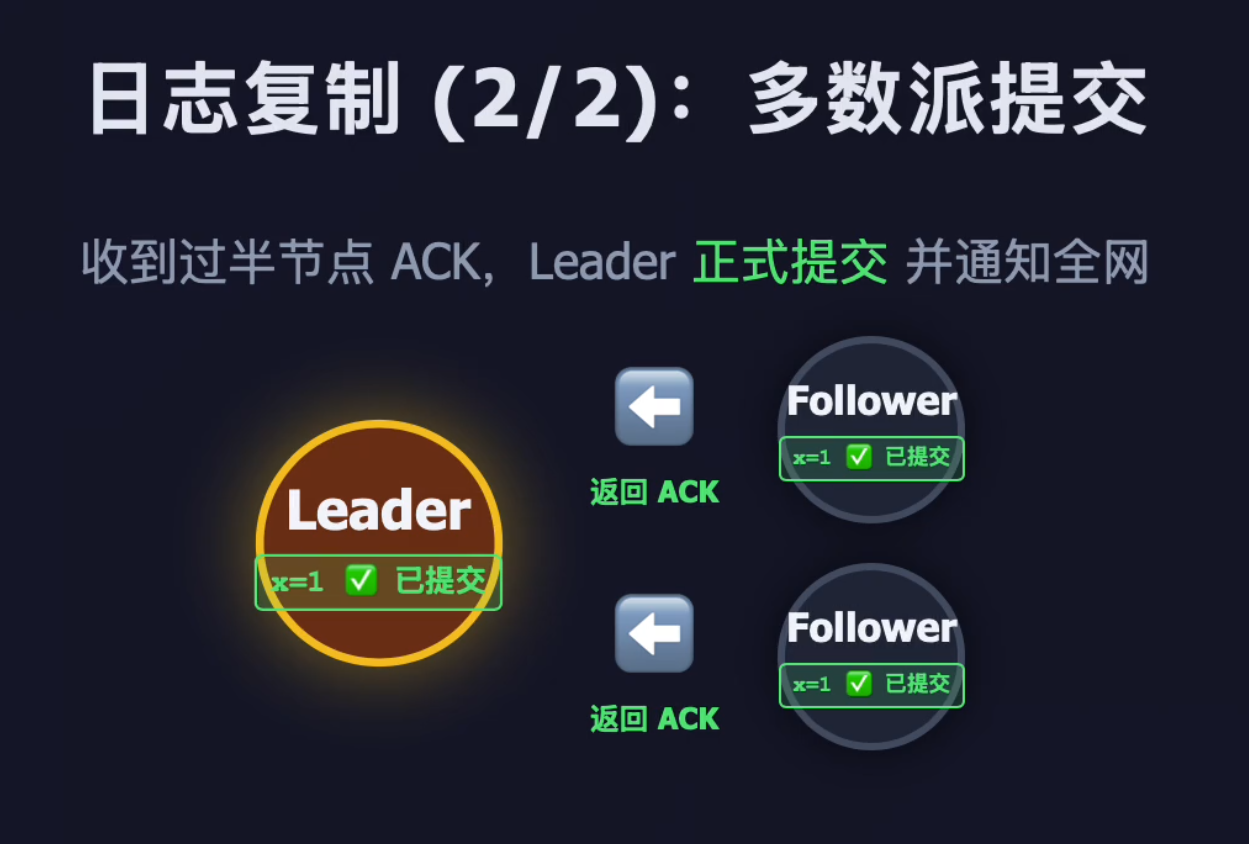
阶段 2:多数派提交(正式生效)
- Leader 统计 ACK 响应数量
- 当超过半数节点 (包括 Leader 自己)成功接收日志后,Leader 将该条日志标记为 Committed(已提交)
- Leader 将提交状态应用到本地状态机(真正执行
set x = 1) - Leader 在下一次心跳或日志同步中,将提交状态同步给所有 Follower
- Follower 也执行对应操作,最终全集群数据一致
- Leader 返回客户端"写入成功"
核心约束
Raft 有一条铁律:只有过半数节点落盘的数据,才算集群的有效数据。
这条规则保证了即使 Leader 突然宕机,新 Leader 上任后也一定拥有最新已提交的数据------因为任何过半数的节点集合,必然包含至少一个拥有最新数据的节点。
五、Raft 两大核心机制(下):故障自动恢复 · Leader 选举
5.1 故障触发:Leader 宕机,心跳中断
当 Leader 宕机或网络中断时,Follower 不再收到心跳包。各 Follower 内部的选举超时倒计时开始持续增长,直到某个 Follower 率先超时。

5.2 角色切换:Follower 升级 Candidate 发起选举
超时的 Follower 进行以下操作:
- 自增任期号(Term):例如从 Term 1 变为 Term 2,标记进入新一轮选举
- 角色切换为 Candidate
- 先给自己投一票
- 向所有其他节点发送
RequestVoteRPC,请求它们投票支持自己

5.3 黄袍加身,晋升新 Leader
- 如果某个 Candidate 收到集群半数以上节点的投票 ,则正式当选为新 Leader
- 新 Leader 上任后,立刻向全集群发送心跳包,重置所有 Follower 的倒计时
- 其他 Follower 收到心跳后,承认新 Leader,恢复正常的跟随状态

选举完成后,集群重新恢复"一主多从"的正常秩序,整个过程无需人工干预,全自动完成。
六、Raft 设计巧思:随机选举超时,解决选举死锁
风险问题
如果所有 Follower 使用固定的、相同的超时时间 (例如都是 300ms),那么当 Leader 宕机时,所有 Follower 会同时超时,同时升级为 Candidate,同时发起选举。
结果就是:每个 Candidate 只拿到自己那一票,选票平分 ,谁都无法过半,选举陷入无限循环死锁。
解决方案
Raft 给每个节点配置一个独立的随机超时时间,通常在 150ms ~ 300ms 之间随机取值。
例如三节点集群:
- 节点 A:超时 150ms
- 节点 B:超时 210ms
- 节点 C:超时 280ms

设计优势
- 节点 A 最先超时(150ms),率先成为 Candidate 并发起选举
- 当 A 的选举请求到达 B 和 C 时,它们还没有超时,仍然是 Follower
- B 和 C 收到请求后投票给 A,A 顺利当选
从根源上避免了平局,这就是 Raft 选举机制的精妙之处------用一个简单的随机化策略,解决了一个看似复杂的分布式死锁问题。
七、从 Raft 到多 Agent 架构:分布式共识思想的延伸
理解了 Raft 的核心机制后,你会发现它的思想远不止用于数据库和中间件------在 AI 多 Agent 系统中,分布式共识的设计哲学同样深刻影响着架构决策。
以我正在开发的星环(StarRing)多 Agent 深度研究系统为例,来看看 Raft 的三大核心思想是如何映射到多 Agent 架构中的。
7.1 Leader 选举 → Agent 角色分工
Raft 的精髓在于"单 Leader 统一调度"。星环系统的设计如出一辙:
| Raft 角色 | 星环 Agent 角色 | 职责映射 |
|---|---|---|
| Leader | Planner(规划者) | 接收用户任务,拆解研究计划,统一调度其他 Agent |
| Follower | Researcher / Analyst / Writer | 被动接收 Planner 分配的子任务,执行后返回结果 |
| Candidate | Reviewer(审稿人) | 在 Researcher 输出质量不达标时,触发反思循环(Reflection),"挑战"现有结论并推动重新研究 |
如果没有 Planner 作为统一的调度中心,多个 Agent 各自为政、并发执行,就会出现类似 Raft 脑裂的问题:同一份研究报告被不同 Agent 按不同方向撰写,最终产出互相矛盾。 单 Leader 模式让星环的 Agent 协作始终保持有序。
7.2 日志复制 → LangGraph 状态图与检查点
Raft 的日志复制机制本质上是在解决一个问题:如何保证多个节点看到一致的数据状态?
在星环系统中,这个问题同样存在。多个 Agent 需要共享研究进度、中间结论、检索结果。星环通过 LangGraph 状态图(StateGraph) 来实现类似"日志复制"的效果:
- 状态图中每个节点的输出都会写入全局共享状态(State),类似 Raft 的日志条目
- LangGraph 的 Checkpointer(检查点机制) 会在每一步执行后自动持久化状态,类似 Raft 的日志落盘
- 任何 Agent 执行失败,系统可以从最近的检查点恢复,而无需从头开始------这和 Raft 新 Leader 从已提交日志恢复是同一个思路
一句话总结:Raft 用日志保证节点间数据一致,星环用 StateGraph 保证 Agent 间状态一致。
7.3 心跳机制 → Agent 健康监控与超时重试
Raft 的心跳机制告诉我们:在分布式环境中,"沉默"就意味着故障。星环系统在设计 Agent 调用链路时,也借鉴了这一思想:
- 每个 Agent 调用都设置超时机制(基于 FastAPI 异步任务),避免某个 Agent 卡死导致整个研究流程阻塞
- Planner 在分发任务后会等待各 Agent 的响应,如果某个 Agent 超时未返回,Planner 可以选择重试或降级策略
- 这与 Raft 中 Follower 等待心跳超时后触发选举的逻辑如出一辙:当预期的响应没有到来,必须主动采取措施恢复系统
7.4 多数派提交 → 多源交叉验证
Raft 最核心的可靠性保障是"过半数节点确认才提交"。星环在研究质量把控上也采用了类似策略:
- RAG 双通道检索:同一问题同时通过联网搜索(Tavily)和本地知识库(Chroma)检索,两个来源交叉验证
- Reviewer 反思循环:Researcher 的输出必须经过 Reviewer 审查,如果 Reviewer 认为论证不充分,会触发反思,要求补充证据
- 只有当检索结果 + 分析结论 + 审稿意见三者达成一致时,Writer 才会生成最终输出
这本质上是 Raft 多数派思想的 AI 化表达:单一来源的结论不可信,多源交叉验证后的共识才是可靠的。
小结
Raft 不仅是一个算法,更是一种在不可靠环境中建立秩序的工程思维。 这种思维在任何分布式系统中都适用------无论底层是数据库节点,还是 AI Agent。
八、主流中间件落地
Raft 不仅是理论算法,它早已成为各大中间件的底层一致性基石:
| 中间件 | Raft 应用场景 |
|---|---|
| Nacos 2.x | 基于 Raft 实现集群元数据的强一致性同步,保证服务注册信息在所有节点一致 |
| RocketMQ 5.x | NameServer/Controller 集群采用 Raft 保证配置和路由信息的一致性 |
| Kafka KRaft | 移除对外部 ZooKeeper 的依赖,原生内置 Raft 做 Controller 选举和元数据管理 |
| etcd / Consul | 以 Raft 为核心的分布式 KV 存储,广泛用于 Kubernetes 等云原生基础设施 |
九、为什么 Raft 是分布式的定海神针
Raft 之所以能成为分布式系统的稳定基石,源于三大核心优势:
- 架构极简 :整个算法拆分为日志复制 和领导人选举两大模块,概念清晰,学习成本远低于 Paxos
- 高可靠 :过半提交 保证数据不丢,自动选主保证服务不断,即使在节点宕机、网络分区的极端场景下,依然保障数据一致性
- 易落地:各大主流中间件全面采用,工程实践成熟,有大量经过生产验证的开源实现
一句话总结 :分布式系统想要不乱、数据不冲突,Raft 就是底层的稳定基石。它用简洁的机制,解决了分布式世界最复杂的问题------如何在不可靠的环境中达成共识。
十、拓展思考题
思考题 1:集群节点数为什么推荐奇数?
答: 奇数节点是为了更高效地形成多数派(Quorum)。
- 3 节点集群:多数派 = 2,最多容忍 1 个节点故障
- 4 节点集群:多数派 = 3,最多容忍 1 个节点故障
- 5 节点集群:多数派 = 3,最多容忍 2 个节点故障
可以看到,4 节点和 3 节点的容错能力一样,但 4 节点需要更多节点确认才能提交,性能反而更差。偶数节点相比少一个的奇数节点,容错能力不变但开销增大,所以推荐奇数(3、5、7)。
思考题 2:新 Leader 上任后,如何同步旧 Leader 未提交的日志?
答: Raft 通过 Leader 日志覆盖机制 解决:
- 新 Leader 上任后,维护一个
nextIndex指针,初始值为自己日志的最后一条位置 + 1 - 当 Follower 与新 Leader 日志不一致时,Leader 会逐步回退
nextIndex,找到双方日志的一致点 - 从一致点开始,Leader 将自己后续的日志全量覆盖 Follower 的冲突日志
- 旧 Leader 未提交的日志,由于未经过半数确认 ,不会被新 Leader 继承------这些日志会被丢弃或覆盖
- 最终所有 Follower 的日志都与新 Leader 完全一致
关键原则:只有已提交(Committed)的日志才一定会被保留,未提交的日志可能被丢弃。
思考题 3:脑裂场景下,Raft 如何避免双主同时对外提供服务?
答: Raft 通过任期号(Term)+ 过半投票两重机制防止双主:
- 任期号机制:每个 Term 内最多只能选出一个 Leader。Candidate 必须拿到当前 Term 过半数的选票才能当选,而每个节点在每个 Term 中只能投一票,所以不可能在同一个 Term 中选出两个 Leader
- 过半投票约束 :即使网络分区导致集群分裂为两部分,只有拥有过半数节点 的分区才能选出 Leader;少数派分区因凑不够选票,无法产生 Leader,只能处于不可用状态
- 脑裂恢复:当网络恢复后,少数派分区发现存在更高 Term 的 Leader,会自动承认并同步数据,集群重新统一
这就是 Raft 的精髓:宁可让少数派分区不可用,也绝不出现双主导致数据冲突。 这也是 CAP 定理中 CP 优先于 A 的典型体现。