分布式一致性协议入门:Raft、Paxos与ZAB的核心思想
作者 :Weisian
发布时间:2026年4月

直击痛点:
"分布式系统为什么必须保证数据一致?Paxos为什么被称为'难理解、难实现'?Raft凭什么成为工业界首选?ZAB和Raft到底有什么区别?90%的开发者知道分布式,但只有1%真正懂一致性协议------这是分布式架构、中间件源码、高薪面试的必过门槛。"
在分布式系统中,一致性协议是解决多副本数据一致性的基石:
- 数据副本:为了防止单点故障,每个数据都有多个副本;
- 一致性问题:多个副本之间如何保证数据一致?
- 故障恢复:节点宕机后,如何保证系统继续可用?
- Leader选举:谁来决定哪个节点是主节点?
本文核心价值 :
✅ Paxos :从Basic Paxos到Multi Paxos,讲透"多数派"核心思想;
✅ Raft :Leader选举、日志复制、安全性保障,完整流程拆解;
✅ ZAB :ZooKeeper的原子广播协议,崩溃恢复+消息广播双模式;
✅ 对比分析 :三种协议的适用场景、优缺点、工程实现;
✅ 面试金句:Raft选举过程、网络分区处理、ZAB与Raft区别。
📌 核心一句话 :
Paxos 是理论基石,定义了分布式共识的天花板;Raft 是工程杰作,将复杂问题模块化,易于理解和实现;ZAB是领域专家,专为ZooKeeper的顺序一致性需求而生。三者殊途同归,目标都是在不可靠的网络中,让一群节点就某个事实达成一致。
分布式一致性协议的本质是在不可靠的环境中建立可靠的共识:Paxos通过严谨的数学证明奠定了理论基础,但实现复杂;Raft通过清晰的角色划分(Leader/Follower/Candidate)和任期(Term)机制,将问题分解为选举、复制、安全三个子问题,成为工程首选;ZAB则针对ZooKeeper的原子广播和严格顺序性需求,设计了独特的崩溃恢复与消息广播双模式。理解它们,就是理解分布式系统的"信任"是如何建立的。
📌 面试金句先记牢:
- Paxos:包含Proposer(提议者)、Acceptor(接受者)、Learner(学习者)三种角色,通过Prepare(准备)和Accept(接受)两阶段达成共识;Multi-Paxos引入Leader简化流程。
- Raft:包含Leader(领导者)、Follower(跟随者)、Candidate(候选人)三种角色;通过随机超时触发选举,保证只有一个Leader;日志复制遵循"过半提交"原则;安全性规则确保新Leader拥有最新日志。
- ZAB :包含Leader、Follower、Observer三种角色;运行于崩溃恢复 (选主+数据同步)和消息广播(类2PC)两种模式;使用ZXID(64位全局事务ID)保证顺序。
- 核心区别:Paxos允许多个Proposer并发提案,冲突解决复杂;Raft和ZAB都采用单一Leader模型,流程更清晰。
- 网络分区:Raft/ZAB会牺牲可用性(AP)保证一致性(CP),少数派无法选举出新Leader,整个集群暂停服务。
- 工程选择:理论研究看Paxos,工业实践选Raft(etcd, TiDB, Consul),协调服务用ZAB(ZooKeeper)。
一、为什么需要一致性协议?
1.1 真实场景:多节点数据乱了怎么办?
假设你有3台机器存用户余额:
- 客户端请求:扣减100元;
- 节点A写入成功,节点B、C还没同步;
- 此时节点A宕机;
- 新请求读取节点B/节点C,读到旧数据;
- 业务直接出错:钱扣了,但余额没变。
这就是分布式最核心的问题:多副本数据不一致。

再比如:
- 3个节点,突然全部没主;
- 必须快速选一个新Leader,否则服务不可用;
- 不能同时选出两个主(脑裂);
- 新主必须拥有最新最全的数据。

1.2 一致性协议要解决的3件事
所有一致性协议,目标完全一致:
- 数据一致:所有存活节点最终数据完全一样;
- 自动选主:主节点宕机,快速选出新主,不丢数据;
- 故障容忍 :只要过半节点存活,系统就能正常工作。

二、Paxos协议:分布式一致性的理论基础(理论鼻祖,最难但最严谨)
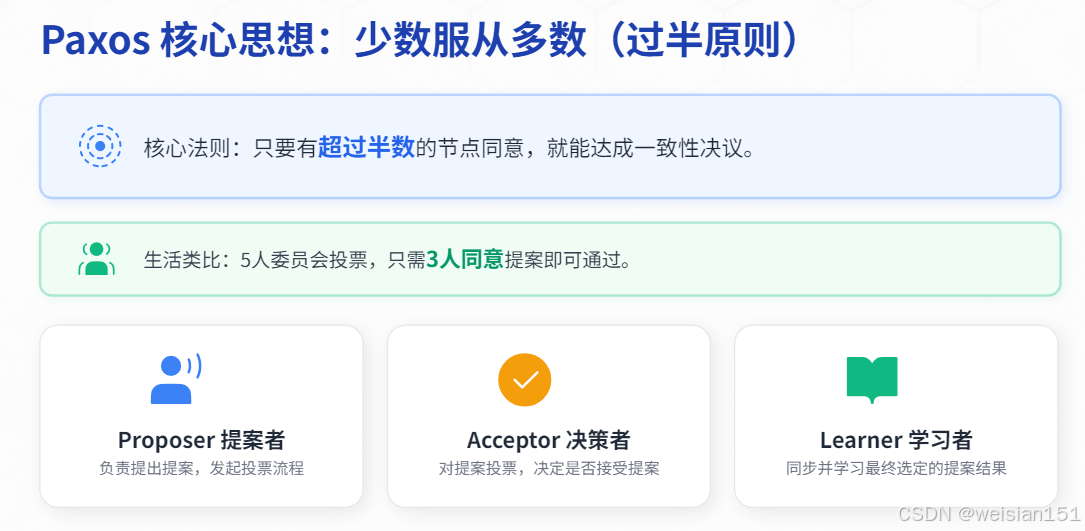
2.1 核心思想:少数服从多数(过半原则)
Paxos的核心思想非常简单:只要有超过半数的节点同意,就能达成一致。
生活类比:一个5人委员会,只要有3人同意,提案就能通过。
关键概念:
- Proposer(提案者):提出提案的节点;
- Acceptor(决策者):对提案进行投票的节点,可以接收或拒绝提案。
- Learner(学习者):学习最终被选定的提案。
2.2 Basic Paxos:两阶段提交
Basic Paxos通过两阶段提交保证只有一个值被确定:

阶段1:Prepare(准备阶段)
1. Proposer生成一个全局唯一的提案编号N(通常用时间戳+节点ID);
2. Proposer向所有Acceptor发送Prepare(N)请求;
3. Acceptor收到Prepare(N)后:
- 如果N > 已响应的最大编号,则承诺不再接受编号<N的提案,并返回已接受的提案;
- 否则,拒绝该请求。阶段2:Accept(确认阶段)
1. Proposer收到多数派Acceptor的响应后:
- 如果所有响应都没有已接受的提案,则自由选择提案值V;
- 如果某个响应包含了已接受的提案,则选择编号最大的提案值V;
2. Proposer向所有Acceptor发送Accept(N, V)请求;
3. Acceptor收到Accept(N, V)后:
- 如果没有承诺过不接受N,则接受提案并存储;
- 否则,拒绝。生活类比 :
班长选班服(Proposer),先问所有人"我要提方案了,别听比我早的方案了"(Prepare),过半同意后,再正式公布班服样式(Accept),过半同意就定下来。
代码示例(简化版):
java
/**
* Basic Paxos 核心逻辑
*/
public class BasicPaxos {
// Acceptor状态
static class Acceptor {
private int highestPromisedId = -1; // 承诺的最高提案编号
private int acceptedId = -1; // 已接受的提案编号
private String acceptedValue = null; // 已接受的提案值
// 处理Prepare请求
public PrepareResponse onPrepare(int proposalId) {
if (proposalId > highestPromisedId) {
highestPromisedId = proposalId;
return new PrepareResponse(true, acceptedId, acceptedValue);
}
return new PrepareResponse(false, -1, null);
}
// 处理Accept请求
public boolean onAccept(int proposalId, String value) {
if (proposalId >= highestPromisedId) {
highestPromisedId = proposalId;
acceptedId = proposalId;
acceptedValue = value;
return true;
}
return false;
}
}
// Proposer逻辑
static class Proposer {
private int proposalId;
private List<Acceptor> acceptors;
public String propose(String value) {
// 阶段1:Prepare
int prepareCount = 0;
int highestAcceptedId = -1;
String highestAcceptedValue = null;
for (Acceptor acceptor : acceptors) {
PrepareResponse resp = acceptor.onPrepare(proposalId);
if (resp.isOk()) {
prepareCount++;
if (resp.getAcceptedId() > highestAcceptedId) {
highestAcceptedId = resp.getAcceptedId();
highestAcceptedValue = resp.getAcceptedValue();
}
}
}
// 如果多数派未响应,提案失败
if (prepareCount <= acceptors.size() / 2) {
return null;
}
// 阶段2:Accept
String finalValue = highestAcceptedValue != null ? highestAcceptedValue : value;
int acceptCount = 0;
for (Acceptor acceptor : acceptors) {
if (acceptor.onAccept(proposalId, finalValue)) {
acceptCount++;
}
}
return acceptCount > acceptors.size() / 2 ? finalValue : null;
}
}
}2.3 Multi Paxos:简化版Paxos(真正可用)
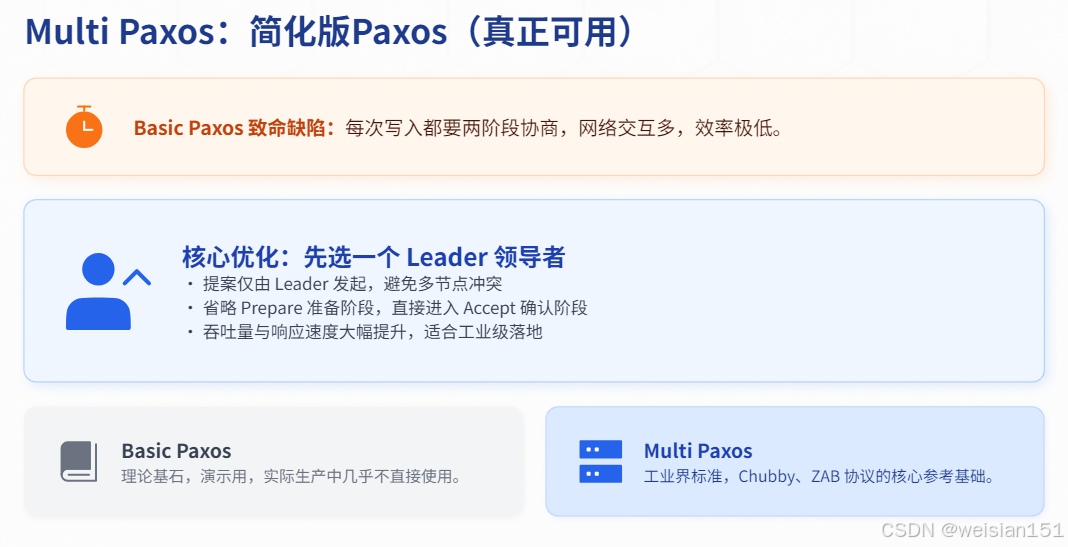
Basic Paxos 有致命缺陷:每次写入都要两阶段,效率极低 。
Multi Paxos 做了一个关键优化:先选一个Leader。
- 只由Leader发起提案;
- 省略Prepare阶段,直接Accept;
- 性能大幅提升。
结论:
- Basic Paxos:理论演示,几乎不用;
- Multi Paxos:工业版Paxos基础(Chubby、ZAB都借鉴它)。
2.4 Paxos 优点与缺点
| 维度 | 说明 |
|---|---|
| 优点 | 理论最严谨、正确性最高、容错强 |
| 缺点 | 极难理解、极难实现、调试困难、原生性能一般 |
| 适用 | 做理论研究、底层协议设计参考 |
三、Raft协议:工业界首选,易懂易实现
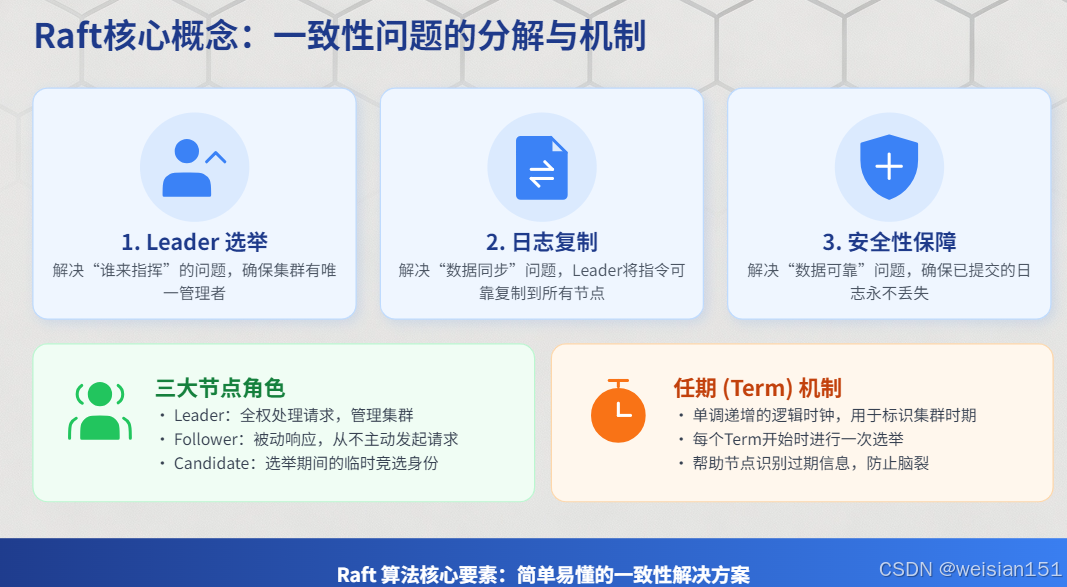
3.1 核心概念
Raft将一致性问题分解为3个独立子问题:
- Leader选举:如何选出Leader?
- 日志复制:如何将日志复制到所有节点?
- 安全性:如何保证已提交的日志不会丢失?
节点角色:
- 角色(Role) :
- Leader:集群的管理者,处理所有客户端请求,负责日志复制。
- Follower:被动角色,响应Leader的心跳和日志复制请求。
- Candidate:临时角色,在选举期间参与投票。
- 任期(Term):一个单调递增的逻辑时钟,用于识别过期信息。每个任期开始时进行一次选举,成功则产生一个Leader,失败则进入下一个任期。
3.2 Leader选举(心跳与随机超时)
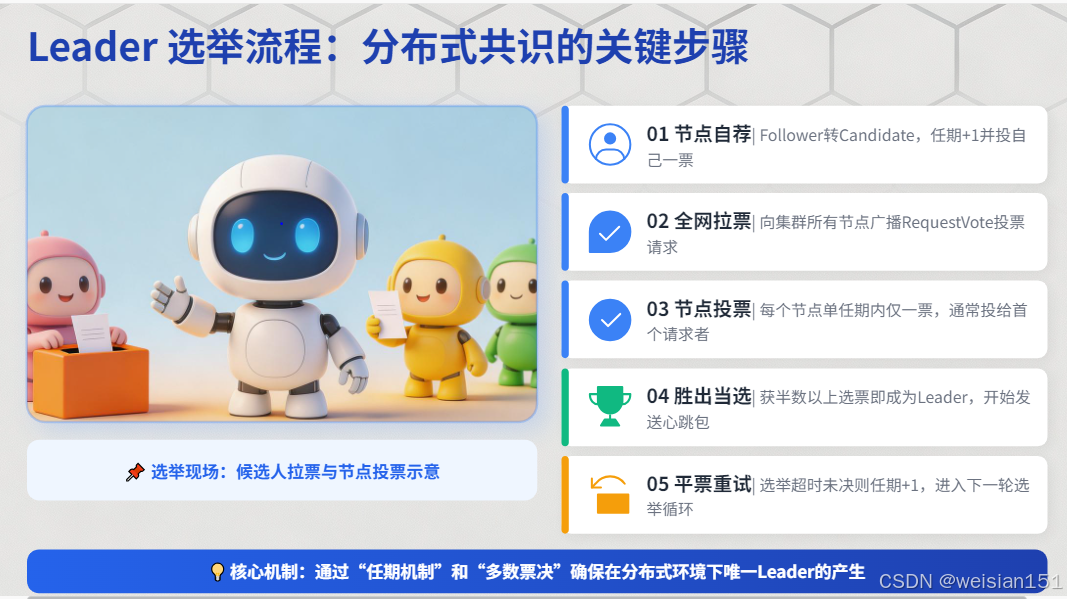
3.2.1 选举触发条件
触发条件 :Follower在一段时间内(选举超时)没有收到来自Leader的心跳。
3.2.2 选举流程
- Follower将自己的状态变为Candidate,任期号+1,并给自己投一票。
- Candidate向所有其他节点发送
RequestVote请求。 - 收到
RequestVote的节点,在一个任期内只能投一票(给第一个满足条件的Candidate)。 - 如果Candidate获得了多数派的选票,它就成为新任Leader,并开始发送心跳。
- 如果选举超时前没有选出Leader(如出现平票),则任期结束,所有节点进入下一个任期重新选举。
关键设计 :随机选举超时。为了避免平票导致的无限重试,每个Follower的选举超时时间是一个随机值(如150-300ms)。这使得在正常情况下,总有一个Follower会率先超时并赢得选举。

3.3 日志复制(保证顺序与一致性)
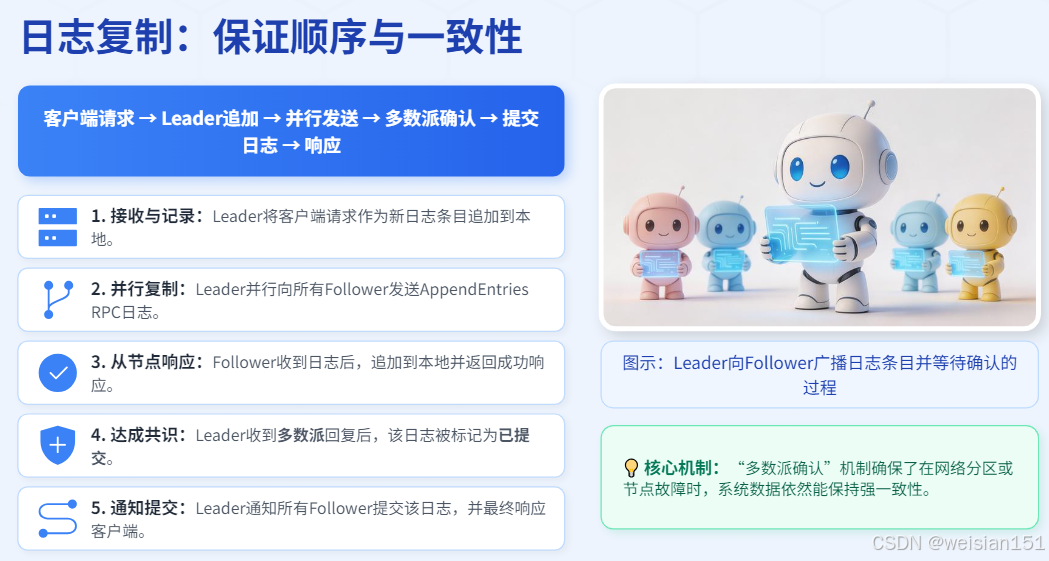
3.3.1 核心流程
客户端请求 → Leader追加日志 → 并行发送AppendEntries RPC → 等待多数派确认 → 提交日志 → 响应客户端- 客户端向Leader发送请求。
- Leader将请求作为新的日志条目追加到自己的日志末尾。
- Leader并行地向所有Follower发送
AppendEntriesRPC,包含新日志条目。 - Follower收到后,会进行一致性检查(日志的索引和任期必须匹配),如果匹配则追加日志,并返回成功。
- Leader收到多数派 Follower的成功回复后,该日志条目被提交(Committed)。
- Leader在下一次
AppendEntries中通知Follower哪些日志已被提交,Follower也将其提交。
3.3.2 日志匹配特性
核心保证:如果两个节点的日志在相同索引位置的条目任期相同,那么这两个节点在该索引之前的所有日志完全相同。
实现机制:
- Leader发送
AppendEntries时携带前一条日志的索引和任期; - Follower检查前一条日志是否匹配;
- 如果不匹配,Follower拒绝并告知冲突信息;
- Leader递减
nextIndex重试,直到找到匹配点。
3.4 安全性保证(防止数据回退)
Raft的安全性规则确保了已提交的日志不会丢失:
- 选举限制:一个Candidate要赢得选举,它的日志必须至少和多数派节点一样新。具体来说,比较日志时,先比较最后一个日志条目的任期号,任期号大的更新;如果任期号相同,则日志长的更新。
- 提交规则:Leader只能提交当前任期的日志。对于之前任期的日志,必须通过提交当前任期的日志来间接提交。
生活类比:班级选班长(Leader Election)。平时班长(Leader)负责传达老师(客户端)的指令(日志复制)。班长每天会点名(心跳)确保大家在线。如果班长突然消失(宕机),同学们(Follower)等一会儿(随机超时)后,会有人自荐(Candidate)并拉票。谁的"履历"(日志)最新、支持者(选票)最多,谁就当新班长。新班长上任后,会先和大家对齐之前的笔记(日志同步),再继续传达新指令。

3.5 网络分区处理
场景:5节点集群(S1,S2,S3,S4,S5),S1是Leader,网络分区将{S1,S2}和{S3,S4,S5}隔开。
处理流程:
1. S1收不到多数派响应,无法提交新日志;
2. {S3,S4,S5}选举出新Leader(S3),任期+1;
3. 客户端请求写入S3成功(多数派{S3,S4,S5});
4. 网络恢复后,S1发现S3的任期更大,自动降级为Follower;
5. S3的日志覆盖S1的未提交日志,保证一致性。
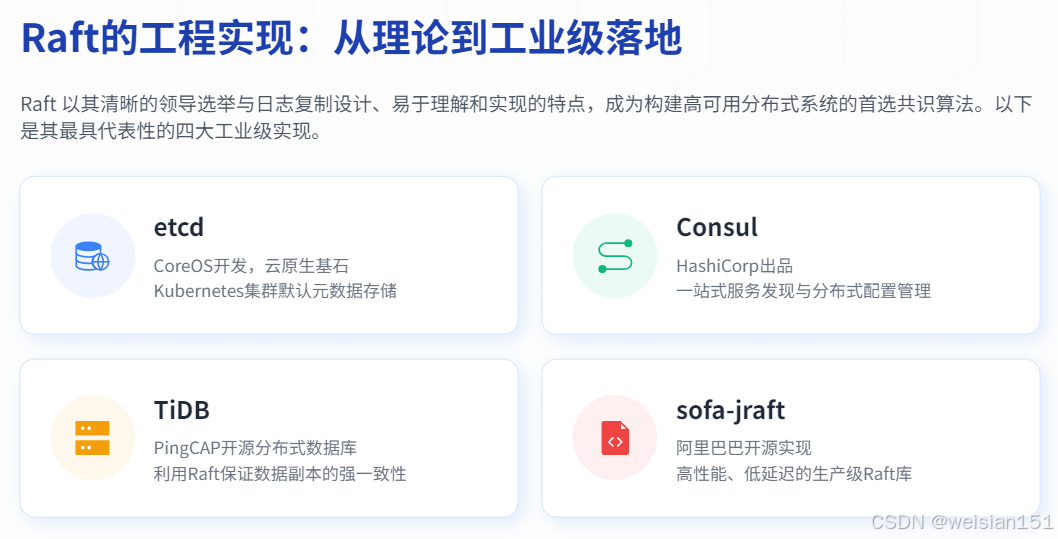
3.6 工程实现
主流实现:
- etcd:CoreOS开发,Kubernetes默认存储;
- Consul:HashiCorp开发,服务发现+配置管理;
- TiDB:分布式数据库,Raft保证数据一致性;
- sofa-jraft:阿里巴巴开源的Raft实现。
四、ZAB协议:ZooKeeper的原子广播
4.1 核心概念
ZAB(ZooKeeper Atomic Broadcast)是ZooKeeper保证数据一致性的核心协议。
两种模式:
- 崩溃恢复(Recovery Mode):Leader选举和数据同步;
- 消息广播(Broadcast Mode):正常运行时的事务处理。
核心特性:
- 顺序一致性:所有事务按全局顺序提交;
- 原子性:事务要么在所有节点提交,要么都不提交;
- 实时性:一旦提交,客户端能立即看到。

4.2 崩溃恢复:Leader选举
ZAB的Leader选举与Raft类似,但细节不同:
当集群启动或Leader宕机时,进入此模式。
- Leader选举 :类似于Raft,但选举依据是ZXID (ZooKeeper Transaction ID)。ZXID是一个64位数字,高32位是epoch (纪元,代表Leader周期),低32位是事务计数器 。ZXID最大的节点(意味着拥有最新的数据)最有可能成为新Leader。
- 数据同步:新Leader选出后,会与Follower进行数据同步。Leader会根据Follower的ZXID,决定是让Follower回滚(TRUNC)还是给它补发缺失的日志(DIFF或SNAP),直到所有Follower的日志与Leader一致。

4.3 消息广播:类似2PC
ZAB的消息广播类似于两阶段提交(2PC),但做了优化:
当Leader和Follower完成同步后,进入此模式,处理客户端的写请求。
- 流程 :非常类似两阶段提交(2PC) 。
- Leader收到客户端请求,生成一个Proposal,并为其分配一个新的ZXID。
- Leader将Proposal发送给所有Follower。
- Follower收到Proposal后,将其写入本地磁盘(保证持久化),然后向Leader发送ACK。
- Leader收到过半Follower的ACK后,向所有Follower发送Commit消息。
- Follower收到Commit后,将Proposal应用到内存数据库,并通知客户端操作成功。
关键特性 :严格的FIFO顺序。ZAB保证所有Proposal都按照ZXID的顺序被处理,这正是ZooKeeper提供顺序一致性语义的基础。

关键区别:
- 无Prepare阶段:Leader直接发送Proposal;
- ACK机制:Follower持久化后立即ACK,无需等待提交;
- 异步提交:Leader收到多数派ACK后提交,Follower收到Commit后提交。
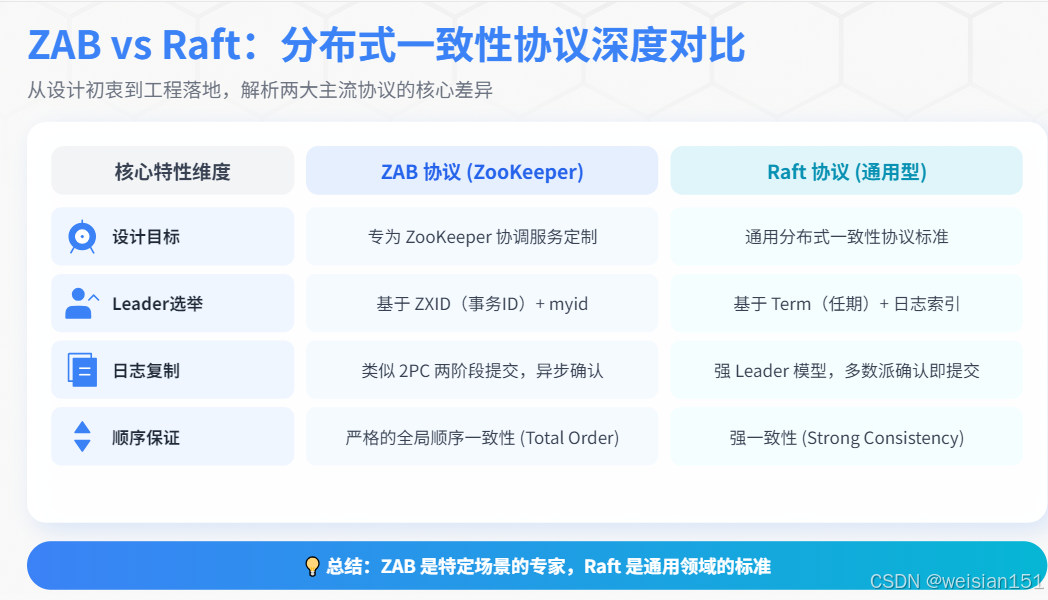
4.4 ZAB vs Raft
| 特性 | ZAB | Raft |
|---|---|---|
| 设计目标 | ZooKeeper协调服务 | 通用一致性协议 |
| Leader选举 | 基于ZXID和myid | 基于Term和日志索引 |
| 日志复制 | 类似2PC,异步提交 | 强Leader,多数派确认 |
| 顺序保证 | 全局顺序一致性 | 强一致性 |
| 实现复杂度 | 中等 | 较低(易于理解) |
| 典型应用 | ZooKeeper | etcd、Consul、TiDB |
五、对比分析:Paxos vs Raft vs ZAB
5.1 核心差异
| 特性 | Paxos | Raft | ZAB |
|---|---|---|---|
| 设计目标 | 理论完备性 | 可理解性、易实现 | 为ZooKeeper定制,强调顺序性 |
| 核心模型 | 多Proposer并发 | 单一Leader | 单一Leader |
| 角色 | Proposer, Acceptor, Learner | Leader, Follower, Candidate | Leader, Follower, Observer |
| 核心流程 | Prepare/Accept两阶段 | Leader选举/日志复制 | 崩溃恢复/消息广播 |
| 日志提交 | 多数派Accept即选定 | 多数派复制后Leader提交 | 类2PC,过半ACK后Commit |
| 选主依据 | 提案编号(Ballot) | 日志的新鲜度(任期+索引) | ZXID(epoch+计数器) |
| 工程实现 | 极其复杂,易出错 | 清晰、模块化,广泛采用 | 与ZooKeeper深度绑定 |
| 典型应用 | Chubby (Google) | etcd, Consul, TiDB, CockroachDB | ZooKeeper |
一句话总结:
- Paxos告诉你"能做什么",是理论的灯塔。
- Raft告诉你"怎么做",是工程的蓝图。
- ZAB告诉你"在ZooKeeper里怎么做",是领域的专家。

5.2 适用场景建议
Paxos:
- ✅ 学术研究、理论理解
- ✅ 需要极致性能的定制化系统
- ❌ 普通业务系统(实现太复杂)
Raft:
- ✅ 分布式数据库(TiDB)
- ✅ 分布式配置中心(etcd)
- ✅ 分布式协调服务(Consul)
- ✅ 通用分布式系统
ZAB:
- ✅ 分布式协调服务(ZooKeeper)
- ✅ 需要强顺序一致性的场景
- ❌ 通用分布式系统(设计专用于ZK)

六、面试高频真题
Q1:什么是分布式一致性协议?解决什么问题?
答案 :
一致性协议用于分布式多节点环境,保证在节点宕机、网络异常情况下:
- 多副本数据最终一致;
- 自动Leader选举;
- 故障转移、脑裂解决;
- 过半节点存活即可服务。
Q2:Raft协议的Leader选举过程是怎样的?
答案:
- 触发:Follower在随机选举超时(如150-300ms)内未收到Leader心跳。
- 自荐 :Follower转为Candidate,任期+1,给自己投票,并向所有节点发
RequestVote。 - 投票:收到请求的节点,在一个任期内只投一票给日志更新(任期更大或任期相同索引更大)的Candidate。
- 胜出:Candidate获得多数派选票后成为Leader,开始发送心跳。
- 平票:若无Candidate胜出,则任期结束,进入下一任期重试。

Q3:Raft如何保证新主一定有最新数据?
答案 :
Raft在选举时严格校验日志:
- 只有日志最新、最完整的节点才能成为Leader;
- 投票节点会拒绝给日志比自己旧的Candidate投票。
Q4:Raft如何处理网络分区?分区恢复后数据会丢失吗?
答案:
场景:5节点集群,Leader在少数派分区(2节点)
1. 少数派Leader(S1)无法收到多数派响应,无法提交新日志;
2. 多数派分区(3节点)选举新Leader(S3),Term+1;
3. 客户端请求写入S3成功(多数派确认);
4. 网络恢复后:
- S1发现S3的Term更大,自动降级为Follower;
- S3的日志覆盖S1的未提交日志(数据一致性保证);
- S1未提交的日志被丢弃(但客户端未收到成功响应,会重试)。
结论:已提交的日志永不丢失,未提交的日志被丢弃。Q5:ZAB和Raft的区别是什么?
答案:
1. 设计目标不同:
- ZAB专为ZooKeeper设计,强调全局顺序一致性;
- Raft是通用一致性协议,强调可理解性。
2. 日志复制机制:
- ZAB:类似2PC,Leader发送Proposal→Follower持久化→ACK→Leader提交→通知Commit;
- Raft:Leader追加日志→并行AppendEntries→多数派确认→提交。
3. Leader选举:
- ZAB:基于ZXID(事务ID)和myid(节点ID);
- Raft:基于Term和日志索引。
4. 实现复杂度:
- ZAB:中等,但有较多ZooKeeper特定设计;
- Raft:较低,易于理解和实现。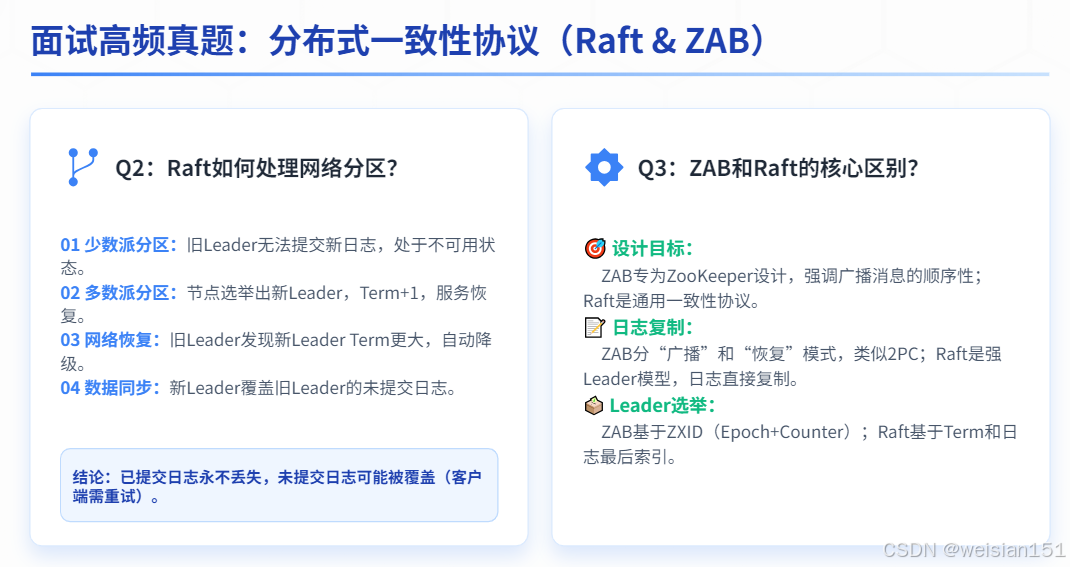
Q6:为什么说Paxos难懂又难实现?
答案:
1. 理论基础深奥:
- 基于复杂的数学归纳证明;
- 需要处理多种边界情况(重复提案、提案编号冲突等)。
2. 实现细节复杂:
- Multi Paxos需要自己实现Leader选举、日志压缩等;
- 缺少具体实现指导,容易出错。
3. 典型问题:
- "活锁":多个Proposer交替提交导致无法达成一致;
- "幽灵复现":旧Leader的提案在新任期被重新提交。
4. 工程实践:
- Google Chubby的作者说:"Paxos和现实世界之间有很大鸿沟";
- 实际生产环境多使用Raft或Raft变种。Q7:什么是脑裂?如何解决?
答案 :
脑裂:网络分区导致集群出现多个Leader 。
解决方法(Raft/ZAB一致):
- 使用任期(Term/Epoch),单调递增;
- 只有任期最大的Leader合法;
- 旧主自动降级为Follower;
- 必须过半确认才能当选主。
Q8:为什么一致性协议都用"过半原则"?
答案:
- 容错性最强:允许少数节点宕机;
- 安全性最高:两个过半集合一定相交,不会出现双主;
- 性能平衡:不用等待所有节点,延迟更低。
总结
1. 核心知识点速记口诀
分布式一致性难,多副本数据要统一,
Paxos多数派达成,两阶段提交严,
Raft分解三问题,选举日志和安计,
Leader选举随机时,日志最新是前提,
多数派确认提交,网络分区能自愈,
ZAB专为ZK设计,崩溃恢复加广播,
三种协议各有长,工程选型要适宜。2. 核心要点回顾
- Paxos:理论基础,多数派达成一致,两阶段提交,实现复杂;
- Raft:易于理解,Leader选举+日志复制+安全性,etcd/TiDB使用;
- ZAB:ZooKeeper专用,崩溃恢复+消息广播,强调顺序一致性;
- Leader选举:随机超时避免冲突,日志最新原则保证安全;
- 日志复制:强Leader,多数派确认,日志匹配特性保证一致性;
- 网络分区:多数派分区自愈,少数派降级,已提交日志不丢。
3. 学习建议
- 入门:先学Raft,理解Leader选举和日志复制;
- 进阶:对比ZAB,理解两种协议的差异;
- 理论:研究Paxos,理解数学原理;
- 实践:阅读etcd/Raft、ZooKeeper源码,加深理解。

写在最后
从Paxos到Raft再到ZAB,分布式一致性协议经历了从理论到工程的演进。Paxos提供了理论基础,Raft让一致性变得易于理解,ZAB为ZooKeeper提供了强大的顺序保证。
很多面试者能说出Raft有Leader选举,却讲不清楚日志匹配特性;有人知道ZAB有崩溃恢复,却不理解为什么需要数据同步。理解"多数派、日志最新、顺序一致"这三大核心思想,才能在分布式系统的面试和实践中游刃有余。
记住:一致性协议的本质是在不可靠的环境中,通过"多数派"机制达成可靠共识。Raft用随机超时避免选举冲突,用日志最新保证数据安全;ZAB用ZXID保证全局顺序;Paxos用两阶段提交保证理论正确性。
如果觉得有帮助,欢迎点赞、收藏、转发!