文章目录
- [1. 游戏 AI 和学术 AI](#1. 游戏 AI 和学术 AI)
-
- [1.1 游戏 AI 的分类](#1.1 游戏 AI 的分类)
-
- [1.1.1 AI THAT PLAYS](#1.1.1 AI THAT PLAYS)
- [1.1.2 AI THAT CREATES](#1.1.2 AI THAT CREATES)
- [1.1.3 AI THAT MODELS](#1.1.3 AI THAT MODELS)
-
-
- [1.1.1.1 游戏游玩型 AI / 会玩游戏的 AI(Gameplaying AI)](#1.1.1.1 游戏游玩型 AI / 会玩游戏的 AI(Gameplaying AI))
-
- [2. 游戏 AI 简要发展历史](#2. 游戏 AI 简要发展历史)
-
- [2.1 Pac-Man(吃豆人)](#2.1 Pac-Man(吃豆人))
- [2.2 GoldenEye 007(007:黄金眼)](#2.2 GoldenEye 007(007:黄金眼))
- [2.3 F.E.A.R.(极度恐慌)](#2.3 F.E.A.R.(极度恐慌))
- [2.4 Halo 2(光环2)](#2.4 Halo 2(光环2))
- [2.5 Left 4 Dead(求生之路)](#2.5 Left 4 Dead(求生之路))
- [2.6 深度学习](#2.6 深度学习)
- [2.7 工业化时代(The Industrial Revolution)](#2.7 工业化时代(The Industrial Revolution))
- [2.8 总结时间线](#2.8 总结时间线)
- [3. 游戏 AI 模型](#3. 游戏 AI 模型)
-
- [3.1 Movement](#3.1 Movement)
- [3.2 Decision Making](#3.2 Decision Making)
- [3.3 Strategy & Tactics](#3.3 Strategy & Tactics)
- [3.4 Infrastructure](#3.4 Infrastructure)
-
- [3.4.1 Perception / World Interfacing(感知和世界接口)](#3.4.1 Perception / World Interfacing(感知和世界接口))
- [3.4.2 Execution Management(执行管理)](#3.4.2 Execution Management(执行管理))
- [3.4.3 Content Creation & Tools(内容制作和工具)](#3.4.3 Content Creation & Tools(内容制作和工具))
- [3.4.4 Debugging & Visualization(调试和可视化)](#3.4.4 Debugging & Visualization(调试和可视化))
- [4. 这些模块的具体算法](#4. 这些模块的具体算法)
-
- [4.1 Movement](#4.1 Movement)
-
- [4.1.1 基础范式](#4.1.1 基础范式)
- [4.1.2 伪代码](#4.1.2 伪代码)
- [4.1.3 Unity 中的碰撞系统](#4.1.3 Unity 中的碰撞系统)
-
- [4.1.3.1 Collider(碰撞体)](#4.1.3.1 Collider(碰撞体))
- [4.1.3.2 Rigidbody](#4.1.3.2 Rigidbody)
- [4.1.3.3 碰撞回调](#4.1.3.3 碰撞回调)
-
- [4.1.3.3.1 OnCollisionEnter(实体物理碰撞)](#4.1.3.3.1 OnCollisionEnter(实体物理碰撞))
- [4.1.3.3.2 OnTriggerEnter(进入感知区域)](#4.1.3.3.2 OnTriggerEnter(进入感知区域))
- [4.1.4 Pathfinding(寻路)](#4.1.4 Pathfinding(寻路))
-
- [4.1.4.1 Pathfinding Graph(寻路图)](#4.1.4.1 Pathfinding Graph(寻路图))
- [4.1.4.2 A* Algorithm](#4.1.4.2 A* Algorithm)
- [4.1.4.3 NavMesh(导航网格)](#4.1.4.3 NavMesh(导航网格))
-
- [4.1.4.3.1 Pathfinding Aid](#4.1.4.3.1 Pathfinding Aid)
- [4.1.4.3.2 Baked Geometry](#4.1.4.3.2 Baked Geometry)
- [4.1.4.3.3 Agent Awareness](#4.1.4.3.3 Agent Awareness)
- [4.1.4.3.4 Virtual World Interaction](#4.1.4.3.4 Virtual World Interaction)
- [4.1.4.3.5 Unity 中的 NavMesh](#4.1.4.3.5 Unity 中的 NavMesh)
- [4.1.4.4 A* 和 NavMesh 的关系](#4.1.4.4 A* 和 NavMesh 的关系)
- [4.2 Decision Making](#4.2 Decision Making)
-
- [4.2.1 Finite State Machine(FSM,有限状态机)](#4.2.1 Finite State Machine(FSM,有限状态机))
-
- [4.2.1.1 实现方式](#4.2.1.1 实现方式)
- [4.2.1.2 Hierarchical Finite State Machine(HFSM,分层有限状态机)](#4.2.1.2 Hierarchical Finite State Machine(HFSM,分层有限状态机))
- [4.2.2 Behavior Tree(BT,行为树)](#4.2.2 Behavior Tree(BT,行为树))
-
- [4.2.2.1 实现方式](#4.2.2.1 实现方式)
-
- [4.2.2.1.1 Tick](#4.2.2.1.1 Tick)
- [4.2.2.1.2 每个节点会返回三种状态](#4.2.2.1.2 每个节点会返回三种状态)
- [4.2.2.1.3 Composite Nodes(组合节点)](#4.2.2.1.3 Composite Nodes(组合节点))
- [4.2.2.2 FSM 与 BT 的对比](#4.2.2.2 FSM 与 BT 的对比)
- [4.2.2.3 一个用于学习行为树的游戏示例。](#4.2.2.3 一个用于学习行为树的游戏示例。)
1. 游戏 AI 和学术 AI
游戏 AI 和学术 AI 的目标不一样。
游戏 AI 不一定真的很聪明,它的重点是让玩家感觉它聪明、合理、有反应。
学术 AI,比如计算机视觉、深度学习,通常追求最优解和高准确率。
例如图像识别 AI 的目标是尽可能准确地识别图片里的物体;自动驾驶 AI 要尽可能安全、准确地判断路况。
游戏 AI 追求的是"看起来聪明",更重视玩家体验、行为可预测性和运行性能。
游戏里的 AI 不需要每次都做数学上的最优决策。它更需要做到:让玩家觉得好玩、行为要有一定规律,玩家能理解和应对、计算开销不能太高,不能影响游戏帧率。
比如敌人可以聪明地找掩体、包抄玩家,但不能强到让玩家完全没有反应机会。
好的游戏 AI 要"输得漂亮"。也就是说,敌人 AI 要让玩家感到有挑战,但最后仍然给玩家赢的机会。
如果一个 NPC 能从地图另一边每次精准爆头玩家,从数学角度看它很强、很准确,但从游戏设计角度看很糟糕。因为玩家会觉得不公平、很挫败、不好玩。
1.1 游戏 AI 的分类
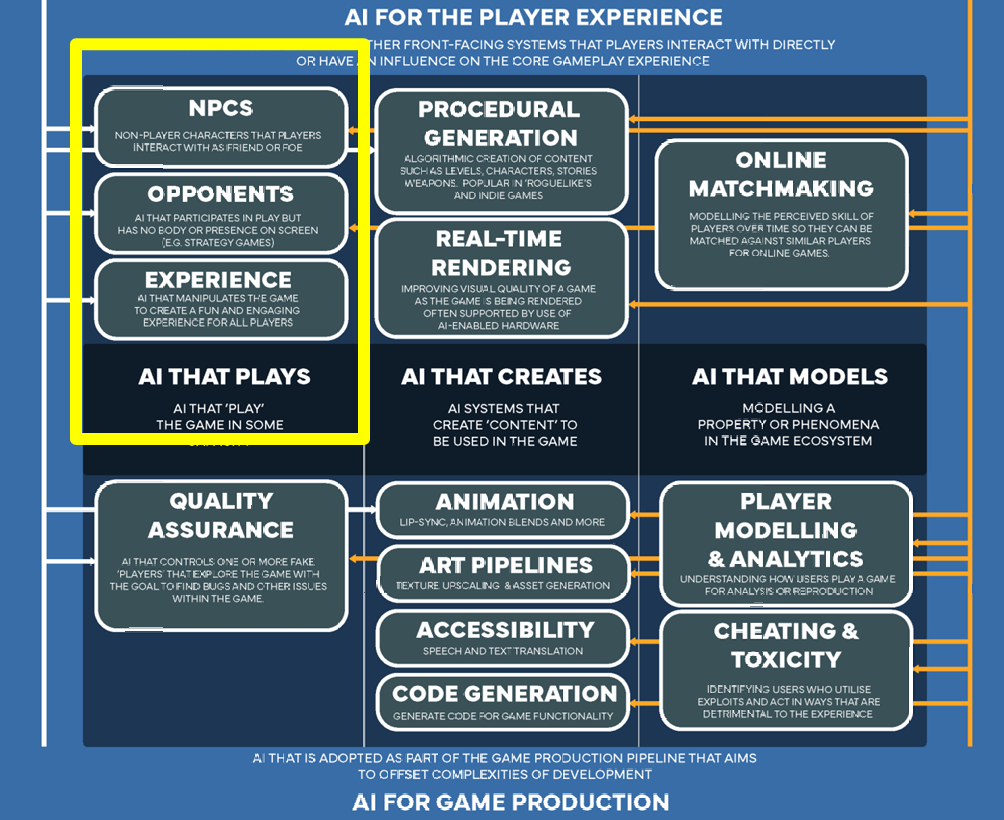
- AI that plays
参与游戏过程的 AI,也就是会"玩游戏"的 AI。 - AI that creates
负责生成游戏内容的 AI。 - AI that models
负责分析、建模、预测玩家或游戏生态的 AI。
1.1.1 AI THAT PLAYS
参与游戏运行、和玩家发生互动的 AI。
它包括三类:
- NPCs
玩家可以互动的非玩家角色,可以是朋友,也可以是敌人。
例如:
| 游戏角色 | 例子 |
|---|---|
| 队友 NPC | 自动跟随、协助战斗 |
| 商人 NPC | 和玩家对话、交易 |
| 任务 NPC | 发布任务、推动剧情 |
| 敌对 NPC | 巡逻、警戒、攻击玩家 |
- Opponents
参与游戏对抗的 AI,但它在屏幕上不一定有具体身体或角色形象。
典型例子是策略游戏里的电脑玩家。
例如:
| 游戏类型 | Opponent AI 的表现 |
|---|---|
| 象棋游戏 | 电脑对手计算下一步 |
| RTS 即时战略 | 电脑控制基地、造兵、进攻 |
| 回合制策略 | 电脑势力扩张、外交、作战 |
| 卡牌游戏 | 电脑根据手牌选择出牌策略 |
- Experience
调整游戏过程,让玩家获得更有趣、更投入体验的 AI。
比如:
| 功能 | 例子 |
|---|---|
| 动态难度调整 | 玩家太强时提高敌人强度,玩家频繁失败时降低难度 |
| 资源分配 | 控制补给、金币、血包出现频率 |
| 关卡节奏控制 | 让战斗、探索、休息交替出现 |
| 剧情触发 | 根据玩家行为调整事件发生顺序 |
1.1.2 AI THAT CREATES
创造游戏内容的 AI。
这里包括:
- Procedural Generation(程序化生成)
例如自动生成地图、关卡、地下城、角色、任务、故事等。
像 Roguelike 游戏常用这种方法,每一局地图都不一样。 - Real Time Rendering(实时渲染相关 AI)
例如用 AI 提升画质、超分辨率、补帧、降噪,让画面更清晰流畅。 - Animation(动画相关 AI)
例如角色动作衔接、走路跑步切换、口型同步。 - Art Pipelines(美术流程 AI)
例如纹理放大、资产生成、风格转换、材质处理。 - Accessibility(无障碍功能 AI)
例如语音转文字、文字翻译、辅助阅读。 - Code Generation(代码生成 AI)
例如生成游戏功能代码、辅助写脚本、自动补全代码。
1.1.3 AI THAT MODELS
创造游戏内容的 AI。
这里包括:
- 建模和分析类 AI。
它主要分析玩家、匹配系统和游戏生态。 - Online Matchmaking
在线匹配。
根据玩家水平、胜率、段位、延迟、行为习惯,把水平相近的玩家匹配到一起。 - Player Modelling & Analytics
玩家建模与数据分析。
分析玩家怎么玩游戏,比如停留时间、失败位置、付费行为、关卡通过率。 - Cheating & Toxicity
作弊和不良行为检测。
例如检测外挂、脚本、辱骂、恶意挂机、破坏游戏环境的行为。
1.1.1.1 游戏游玩型 AI / 会玩游戏的 AI(Gameplaying AI)
它不是只指敌人 NPC,也可以指电脑玩家、测试机器人、匹配和平衡系统、陪玩机器人等。
可以按照目的分类:
- 为了赢而玩(Playing to Win)
它的目标是优化成功率(success)、准确率(accuracy)、效率(efficiency)。
比如 AlphaGo 下围棋、Deep Blue 下国际象棋、AI 在策略游戏里打败人类。
这类 AI 更接近传统学术 AI,重点是赢、算得准、表现强。 - 为了体验而玩(Playing for Experience)
它的目标是优化可信度(believability)、玩家参与感(player engagement)、趣味性(fun)。
比如 AlphaGo 下围棋、Deep Blue 下国际象棋、AI 在策略游戏里打败人类。
比如游戏里的队友 NPC 不需要每次都做最优操作,它要让玩家觉得自然、有配合感、有情绪价值。
下图可能展示一个更好的分类方式。

我们将其可以分为两个维度,其中一个是目的维度,另一个是其呈现的形式。
然后这两个维度中的情况组合就会是一种AI。
我们呱呱介绍的就是按照目的划分,但其实介绍的比较粗糙,现在按照上面图的划分可以更详细。
- Player + Win
像玩家一样玩游戏,并且目标是赢。
用途:把游戏作为 AI 测试平台、用 AI 挑战玩家、强化学习基准测试、通用游戏 AI。
例子:TD-Gammon(西洋棋 AI)、Chinook(跳棋 AI)、Deep Blue(国际象棋 AI)、Waston(问答系统)、AlphaGo(围棋 AI)、AlphaStar(星际争霸 AI)。 - Non-Player + Win
AI 不直接作为玩家出现,但它的目标仍然和"获胜、平衡、控制局面"有关。
用途:游戏平衡、扮演人类玩家不愿意承担的角色。
例子:Rubber Banding in Racing Games(赛车游戏里常见的动态平衡机制,比如玩家落后时,系统可能让玩家更容易追上;玩家领先太多时,后面的 AI 车辆可能突然变快。) - Player + Experience
AI 像玩家一样参与游戏,但目标是改善体验、测试游戏或模拟玩家。
比如一个测试 AI 自动跑地图,检查玩家会不会卡住、关卡会不会太难、某个路线是否可行。
它不一定追求赢,而是帮助开发者评估游戏体验。
用途:内容评估、多人游戏队友机器人、幽灵玩家与玩家画像、游戏测试、演示模式。
例子:Game Turing Tests(游戏图灵测试,判断 AI 是否像真人玩家)、Drivatar in Forza Series(《极限竞速》里的 Drivatar AI 车手)。 - Non-Player + Experience
不以玩家身份出现,主要用于营造可信、自然、有趣的游戏体验。
这类就是我们最常说的游戏 NPC AI。它的重点是让玩家觉得角色"像活的",而不是单纯追求最强。
用途:可信的、类人的智能体;敌对 NPC;合作型 NPC。
例子:The Last of Us 中的 Ellie、Half-Life 2 中的 Alyx、Halo Series 中的 Elites。
2. 游戏 AI 简要发展历史
2.1 Pac-Man(吃豆人)

《吃豆人》由南梦宫在 1980 年推出,是街机时代的重要作品。
《吃豆人》里的四只幽灵不会完全按照同一种方式追赶玩家。
而且《吃豆人》通过非常简单的规则,让不同敌人呈现出不同"性格",从而让玩家感觉它们具有智能。
这里用的策略可以用有限状态机模型去解释。
AI 在不同状态下采用不同的行为规则,并且可以根据条件切换状态。
以《吃豆人》为例,幽灵可能处于这些状态:
| 状态 | 行为 |
|---|---|
| Chase | 追赶玩家 |
| Scatter | 暂时分散,移动到特定区域 |
| Frightened | 玩家吃到强化豆后,幽灵逃跑 |
| Eaten | 被玩家吃掉后返回基地 |
幽灵不会始终采取同一种行动。游戏会根据时间、玩家状态和幽灵当前状态切换行为。
四只幽灵的性格也完全不一样:
Blinky(红色幽灵)直接追赶玩家。它的目标通常接近玩家当前位置,因此会持续向玩家逼近。
Pinky(粉色幽灵)尝试埋伏玩家。它不会只盯着玩家当前所在位置,而会参考玩家前方的位置进行移动。因此,玩家可能感觉它在预判路线。
Inky(青色幽灵)尝试从侧面包抄,并参考红色幽灵 Blinky 的位置。它的目标计算方式更复杂,会综合玩家位置、玩家方向和 Blinky 的位置。
因此,它的行为更难预测。
Clyde(橙色幽灵)在追赶和离开之间切换。
当它距离玩家较远时,可能接近玩家。当它距离玩家较近时,可能转向自己的固定区域。
这会让它看起来有些犹豫,也更像拥有独特性格。
因此简单规则加上不同性格,可以产生复杂的整体表现。
2.2 GoldenEye 007(007:黄金眼)

1997 年 Nintendo 64 平台的《GoldenEye 007》代表了战术型敌人 AI 的兴起(The Rise of Tactics)。
它的重要创新是Sensory Simulation (Perception,感官模拟,或感知系统)。
它的意思是敌人需要通过特定信息发现玩家,例如视线、声音和环境线索。
在一些简单游戏中,敌人可能始终知道玩家坐标。即使玩家躲在墙后面,敌人仍然会直接朝玩家移动。
《GoldenEye 007》中的守卫需要先获得某些线索,才会做出反应。
守卫会对声音、视线范围以及尸体做出反应。
例如玩家躲在墙后面时,敌人的视线被遮挡,通常无法立即发现玩家。
这样的敌人更容易让玩家觉得公平。
玩家可以理解敌人为什么发现自己,也可以利用规则制定策略,例如:
- 减少制造声音。
- 利用墙壁和障碍物隐藏自己。
- 避免让敌人看到倒下的守卫。
- 观察敌人的巡逻路线,寻找通过时机。
这种感知设计推动了潜行玩法的发展,让 AI 的行为显得公平且可以预测。
2.3 F.E.A.R.(极度恐慌)

2005 年 的 F.E.A.R. 推出了Goal Oriented Action Planning (GOAP,目标导向行动规划)
它的核心思路是先确定目标,再根据当前情况选择实现目标的一系列行动。
固定脚本容易破坏沉浸感。
假设敌人的行动提前写死,那么玩家第二次遇到相同场景时,可能很快发现敌人的行动完全一致。敌人会显得机械。
解决办法是动态规划。让 AI 会根据当时的环境和目标选择行动。
例如,敌人的目标是包抄玩家。那么AI 可能根据地图结构、掩体位置、队友位置和玩家所在位置选择不同路径。
假设一名敌人需要把玩家逼出掩体,它可能从多个动作中选择组合:
| 动作 | 作用 |
|---|---|
| Move to cover | 移动到掩体后面 |
| Suppress player | 持续射击,压制玩家 |
| Flank player | 绕到侧面攻击 |
| Throw grenade | 投掷手榴弹 |
| Retreat | 撤退到更安全的位置 |
| Search area | 搜索玩家可能藏身的位置 |
不同敌人可以承担不同任务:
| 敌人 | 行动 |
|---|---|
| 敌人 A | 在正面持续开火 |
| 敌人 B | 从侧面移动 |
| 敌人 C | 投掷手榴弹逼迫玩家离开掩体 |
这便是动态小队战术(Dynamic squad tactics)。
开发者不需要把每一个行动步骤都提前写死。
2.4 Halo 2(光环2)

2004 年的 《Halo 2》是 2000 年代中期现代 NPC 行为设计的代表案例之一。
当角色行为越来越复杂时,有限状态机很容易变得难以管理,形成所谓的"意大利面条式代码"。
一个简单敌人可能只有几种状态:
| 状态 | 行为 |
|---|---|
| Patrol | 巡逻 |
| Chase | 追赶玩家 |
| Attack | 攻击玩家 |
| Flee | 逃跑 |
此时 FSM 很容易理解。
但如果角色还要判断血量、弹药、掩体、距离、队友位置、玩家视野和手榴弹威胁,状态之间的连接会迅速增多。
例如:
| 当前情况 | 可能采取的动作 |
|---|---|
| 看到玩家且距离较远 | 接近玩家 |
| 看到玩家且附近有掩体 | 寻找掩体 |
| 血量较低 | 撤退 |
| 队友正在压制玩家 | 尝试包抄 |
| 玩家投掷手榴弹 | 躲避 |
| 丢失玩家视野 | 搜索区域 |
每一个状态都可能与多个状态相互切换,逻辑会越来越混乱。代码像缠在一起的意大利面一样,逻辑交叉复杂,很难修改和调试。
为了解决这样的问题,《Halo 2》使用的是行为树(BT,Behavior Tree)。
行为树会把 NPC 的复杂行为拆分成多个小任务,再按照树状结构组织起来。
行为树由模块化、可重复使用的任务组成。
例如,一个敌人的简化行为树可以写成:
选择一个可执行行为
├── 如果受到手榴弹威胁
│ └── 躲避
├── 如果血量过低
│ └── 撤退
├── 如果看到玩家
│ ├── 寻找掩体
│ ├── 瞄准
│ └── 射击
└── 如果没有发现玩家
└── 巡逻AI 会从上往下检查条件,并执行当前最适合的行为。
行为树还会要求按照顺序完成一组步骤。
例如:
攻击玩家
├── 移动到掩体
├── 瞄准玩家
└── 开火行为树的优势在于:每种行为都可以拆成独立模块。
例如:
| 行为模块 | 可用于哪些角色 |
|---|---|
| 寻找掩体 | 多种士兵类敌人 |
| 躲避手榴弹 | 多种地面单位 |
| 搜索玩家 | 守卫、士兵、精英敌人 |
| 追赶目标 | 近战敌人、怪物 |
| 撤退 | 血量较低的角色 |
设计师可以重复使用这些模块,也可以调整优先级。
例如:
| 敌人类型 | 行为特点 |
|---|---|
| 基础敌人 | 更容易逃跑,行为简单 |
| 精英敌人 | 会寻找掩体、躲避手榴弹、主动包抄 |
| 重装敌人 | 移动较慢,但会正面压制玩家 |
行为树让设计师可以创建复杂且反应灵敏的 NPC(能够根据当前情况迅速改变行为的 AI),不需要每次都重新编写底层 C++ 代码。
例如:
| 情况变化 | NPC 反应 |
|---|---|
| 玩家投掷手榴弹 | 立即躲避 |
| 玩家躲到掩体后面 | 搜索或包抄 |
| 队友被击败 | 改变位置或撤退 |
| 玩家突然靠近 | 切换为近距离攻击 |
2.5 Left 4 Dead(求生之路)

2008 年的《求生之路》中的 AI 导演系统,代表了 2000 年代至 2010 年代程序化设计的发展。
AI 的作用已经超出控制某一个角色,它还会像"游戏主持人(Game Master)"一样控制整体节奏。
也就是说,AI 的职责从控制单个敌人,扩展到调节整局游戏的节奏和玩家体验。
系统根据规则和实时情况动态生成内容。
因此,玩家每次游玩同一个关卡时,遭遇的敌人数量、出现位置、道具分布和音乐节奏都可能不同。
AI 导演会实时判断玩家当前的压力和紧张程度。
这里的"压力"通常不是直接读取玩家的心理状态,而是根据游戏中的数据进行估计,例如:
| 数据 | 可能反映的情况 |
|---|---|
| 玩家剩余生命值 | 队伍是否处于危险状态 |
| 队员是否倒地 | 当前战斗压力是否过高 |
| 弹药和医疗包数量 | 玩家是否需要补给 |
| 玩家推进速度 | 玩家是否过于轻松或频繁受阻 |
| 敌人数量 | 当前场面是否过于拥挤 |
| 一段时间内的受伤情况 | 玩家是否需要喘息时间 |
因此,AI Director 会判断玩家此时适合继续承受压力,还是需要一个短暂的恢复阶段。
系统会动态生成敌人、物品和音乐,以维持戏剧化的紧张感。
| 玩家状态 | AI Director 可能采取的措施 |
|---|---|
| 玩家推进过于顺利 | 增加敌人,安排特殊感染者 |
| 玩家连续陷入苦战 | 减少敌人密度,提供缓冲时间 |
| 玩家缺少补给 | 在后续区域放置医疗包或弹药 |
| 即将出现高压战斗 | 改变音乐,营造危险临近的感觉 |
| 玩家长时间没有遭遇敌人 | 安排新的敌群,避免节奏过于平淡 |
如果敌人从头到尾一直很多,玩家容易疲劳。
如果敌人长期很少,玩家容易觉得无聊。
AI Director 的任务是控制强弱变化,让整个过程更有节奏。
从这里开始,游戏 AI 可以管理整体玩家体验,也可以控制 NPC 行为。也就是说游戏 AI 的应用范围扩大了。
2.6 深度学习
2010 年代以后,深度学习开始显著影响游戏 AI 研究。
AI 不再只依靠开发者预先写好的规则,还可以通过训练学习复杂策略。
2016 年,DeepMind 开发的 AlphaGo 在围棋比赛中击败职业棋手李世石。
围棋的可能局面数量极其庞大,无法通过穷举所有走法解决。
AlphaGo 使用的是深度神经网络与蒙特卡洛树搜索相结合。

到 2019 年前后,AI 已经能够在《Dota 2》和《星际争霸 II》这类复杂实时游戏中达到很强的竞技水平,并在特定比赛或实验条件下击败职业玩家。
围棋是轮流下棋,玩家可以在规定时间内思考。
《Dota 2》和《星际争霸 II》里的局面持续变化,AI 需要不断做出决定。
这里因为战争迷雾系统所以 AI 无法随时看到地图上的所有内容。这就是 Imperfect Information(不完全信息)。
AI 不能只关注眼前的一次战斗,还需要考虑后续发展。
2.7 工业化时代(The Industrial Revolution)
进入 2020 年代以后,生成式 AI 和大语言模型开始进入游戏行业。游戏 AI 的重点逐渐从"控制角色行为"扩展到"生成游戏内容"。
早期 Game AI 主要解决这些问题:
| 早期问题 | 示例 |
|---|---|
| NPC 如何追赶玩家 | 《吃豆人》幽灵 |
| NPC 如何感知玩家 | 视线、声音、警戒系统 |
| NPC 如何选择行动 | 行为树、GOAP |
| 系统如何调节节奏 | 《求生之路》的 AI Director |
进入 2020 年代后,AI 还可以参与创造内容:
| 新方向 | 示例 |
|---|---|
| 自动生成对话 | NPC 根据玩家提问实时回答 |
| 自动生成任务 | 根据玩家行为创建新任务 |
| 自动生成场景 | 创建地图、建筑、地形 |
| 辅助美术制作 | 生成概念图和纹理 |
| 辅助游戏开发 | 生成代码和测试脚本 |
大语言模型可以让 NPC 进行数量非常多、没有预先完全写死的对话。
传统 NPC 对话通常由开发者提前写好,如果玩家问了脚本之外的问题,NPC 通常无法回答。
引入大语言模型后,NPC 可以根据世界观、角色身份和当前任务生成回答。
图像生成工具可以辅助制作纹理和概念图。
AI 可以在游戏运行过程中动态生成关卡、任务,甚至生成部分游戏规则。
AIGC 驱动的系统可以在玩家游玩时,根据玩家行为动态生成部分内容。
这种思路可以提高游戏内容的丰富程度,但开发难度也会增加。
一个较完善的世界模型可以帮助 AI 生成更合理的剧情和任务。
例如,玩家已经击败某个角色后,系统就不应该再生成"去拜访这个角色"的任务。
有关 AIGC 目前的挑战是幻觉(Hallucination)、可控性(controllability)和延迟(latency)。
幻觉(Hallucination)指的是 AI 生成了与游戏世界不一致的内容。
例如:
| 幻觉问题 | 例子 |
|---|---|
| 剧情矛盾 | NPC 提到一个不存在的国家 |
| 状态矛盾 | NPC 要求玩家寻找已经被摧毁的建筑 |
| 人物矛盾 | 已经死亡的角色突然发布任务 |
| 规则矛盾 | AI 生成无法完成的任务 |
可控性(controllability)指的是生成式 AI 的输出需要符合游戏设计师设定的规则。
例如:
| 控制要求 | 原因 |
|---|---|
| 符合世界观 | 避免剧情混乱 |
| 符合角色性格 | 保持 NPC 可信度 |
| 控制难度 | 避免任务过难或过于简单 |
| 避免不适当内容 | 保证游戏内容安全 |
| 保持剧情连贯 | 避免前后矛盾 |
延迟(latency)指的是玩家和 NPC 对话时,AI 需要在较短时间内生成回答。
如果玩家每说一句话都要等待较长时间,体验会受到明显影响。
| 延迟情况 | 玩家感受 |
|---|---|
| 几乎立即回答 | 对话自然 |
| 等待数秒 | 可以接受,但会感觉停顿 |
| 等待十几秒 | 容易破坏沉浸感 |
| 网络不稳定 | 对话体验明显下降 |
2.8 总结时间线
不同年代解决的问题不一样。
| 时期 | 核心问题 |
|---|---|
| 1970 年代到 1980 年代 | AI 应该按照什么规则行动 |
| 1990 年代 | AI 如何发现玩家 |
| 2000 年代 | AI 如何规划和组织复杂行为 |
| 2010 年代 | AI 如何通过训练学习策略 |
| 2020 年代 | AI 如何生成内容并参与游戏生产 |
游戏 AI 的发展方向逐渐从简单规则控制,扩展到感知、规划、学习和内容生成。游戏 AI 的最终目标始终围绕玩家体验展开。
我们这里可以总结游戏 AI 设计上的几条黄金原则(Golden Rule):
- Perception is King:感知非常重要。AI 的表现取决于它能获得什么信息。
例如,一个射击游戏中的敌人是否知道玩家的位置,会显著影响玩家体验。 - Predictability vs. Intelligence:某些情况下,可以预测的 AI 更适合作为游戏对手。
这里的重点是,敌人的行为需要具有一定规律。 - The "Hack" is OK:商业游戏中的 AI 可以使用巧妙的简化方法,营造出复杂智能的感觉。例如《吃豆人》
- Tools, not just Code:现代游戏 AI 开发依赖可视化工具,也依赖底层代码。
例如行为树编辑器可以让设计师直接调整 NPC 的逻辑
3. 游戏 AI 模型
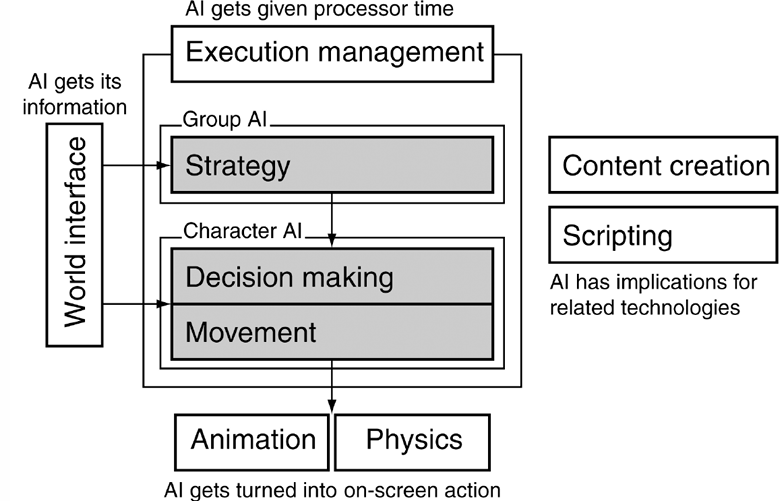
我i们这里介绍一个经典的三层模型去解释游戏 AI。
它把游戏角色的智能行为分成三个层次,从底层到高层依次为:
| 层次 | 核心问题 | 典型功能 |
|---|---|---|
| Movement | 怎么移动 | 转向、寻路、避障、物理移动 |
| Decision Making | 当前做什么 | 巡逻、攻击、撤退、寻找掩体 |
| Strategy | 整体目标是什么 | 小队配合、战术安排、长期目标 |
举一个射击游戏中的例子:
敌人小队想要从侧面包抄玩家。
| 层次 | 具体任务 |
|---|---|
| Strategy | 决定安排一名敌人从侧面绕后 |
| Decision Making | 让该敌人执行"移动到侧翼位置"的行为 |
| Movement | 计算路线,绕开障碍物,最终走到目标点 |
这里实现 Decision Making 的有三种常见方法:State Machines(状态机)、Behavior Trees(行为树)、Goal Oriented Planning(目标导向规划)。
整个支撑 AI 系统允许的底层模块是基础设施(基础设施)。
包括:
| 基础模块 | 作用 |
|---|---|
| Perception | 感知玩家、声音、环境变化 |
| Scheduling | 分配 AI 的计算时间 |
| World interfacing | 读取游戏世界状态 |
| Tools | 为设计师提供编辑和调试工具 |
因此上图概括一下就是:游戏 AI 先从游戏世界读取信息,再经过策略、决策和运动三个层次处理,最后通过动画和物理系统转化成玩家能够看到的角色行为。执行管理负责分配计算资源,内容创建和脚本系统则与 AI 开发密切相关。
3.1 Movement
Movement 把决策转化为运动。
其不负责决定决策是什么,决策来源于 Decision Making层。
例如,AI 已经决定:
前往掩体。
Movement 层接下来需要处理:
掩体在哪里、应该走哪条路线、如何绕开桌子、如何避免撞到队友、角色应该朝哪个方向转身、接近掩体时是否需要减速。
具体的运动包括:
| 英文 | 中文 | 含义 |
|---|---|---|
| Align | 对齐 | 让角色调整朝向 |
| Pursue | 追逐 | 预测移动目标的位置并追赶 |
| Evade | 躲避 | 远离威胁或预测威胁位置 |
| Collision avoidance | 碰撞规避 | 避免撞到墙、桌子或其他角色 |
这里会涉及比如寻路算法,常见算法包括 A*、Navigation mesh(导航网格,用来表示角色可行走区域)。
3.2 Decision Making
Decision Making 选择下一步做什么。
决策层负责决定角色当前要执行什么行为。
它会根据角色自身状态和外部环境作出判断。
例如:
| 当前情况 | AI 可能选择的行为 |
|---|---|
| 没有发现玩家 | 巡逻 |
| 看到玩家 | 进入战斗 |
| 玩家距离很远 | 追赶 |
| 玩家距离较近 | 射击 |
| 生命值较低 | 撤退 |
| 附近有手榴弹 | 躲避 |
| 暂时失去玩家位置 | 搜索附近区域 |
常用的三种技术:
- FSM:有限状态机
有限状态机结构简单,行为容易预测。 - Behavior Trees:行为树
行为树具有模块化和可扩展性。 - Utility based AI:效用型 AI
效用型 AI 会给不同选项打分,然后选择分数较高的行为。
决策会同时受到外部世界状态和角色内部目标的影响。
外部世界状态,例如:
| 信息 | 影响 |
|---|---|
| 玩家是否出现 | 是否进入战斗 |
| 附近是否有掩体 | 是否寻找掩体 |
| 是否出现手榴弹 | 是否躲避 |
| 队友是否倒下 | 是否改变战术 |
角色内部状态和目标,例如:
| 信息 | 影响 |
|---|---|
| 当前生命值 | 是否撤退 |
| 弹药数量 | 是否换弹 |
| 角色身份 | 冲锋、支援或防守 |
| 当前任务 | 巡逻、守门或追击 |
所以前面的例子提到一个守卫看到玩家后,会从巡逻状态切换为战斗状态。
3.3 Strategy & Tactics
Strategy & Tactics 是超越单个角色的协调。
战略与战术层关注多个角色之间的协作,以及持续时间更长的行动计划。
这里讨论的范围已经超出了单个 NPC。
因此这几项的对比如如下面例子所示:
| 层次 | 示例 |
|---|---|
| Strategy | 小队需要控制某个区域,阻止玩家继续推进 |
| Tactics | 一部分敌人正面压制玩家,另一部分敌人侧面包抄 |
| Decision Making | 某个士兵判断自己应该移动到哪个掩体 |
| Movement | 该士兵绕开桌子,沿着路线到达掩体 |
策略层负责协调多个角色,也可以制定持续时间较长的计划。
因此策略层通常需要空间推理和团队层面的信息。
例如:小队指挥模块安排一组士兵进行压制射击,另一组士兵进行侧翼包抄。每个士兵仍然会根据自己的处境独立判断具体行动。
完整流程可以写成:
Strategy:
制定小队战术
安排 A 组正面压制
安排 B 组侧翼包抄
Decision Making:
每名士兵判断应该寻找哪个掩体
判断是否需要换弹
判断是否需要躲避手榴弹
Movement:
沿着路径移动
绕开障碍物
到达目标位置3.4 Infrastructure
Infrastructure 是支撑 AI 运行的基础设施
基础设施是连接各个模块的黏合剂,让 AI 能够在真实游戏中正常工作。
3.4.1 Perception / World Interfacing(感知和世界接口)
AI 如何知道自己看到了什么,听到了什么?
这部分负责把游戏世界中的信息提供给 AI。
包含三部分:
- 感官模拟(Sense simulation):模拟 NPC 的视野范围。
- 轮询(Polling):系统按照固定时间间隔检查信息。
- 事件(Events):当某件事发生时,系统立即通知 AI。
3.4.2 Execution Management(执行管理)
执行管理负责分配 AI 的计算时间,并控制不同角色使用多复杂的逻辑。
游戏的 CPU 还需要处理渲染、物理、动画、声音和网络通信。AI 不能无限占用计算资源。
这就如同计算机系统一样。
其包含:
- 时间片分配(Time slicing):系统把计算时间分给不同 NPC。
- 优先级调度(Priority scheduling):系统优先更新更重要的 NPC。
- LOD AI(Level of Detail AI):根据 NPC 与玩家的距离和重要程度,使用不同复杂程度的 AI。
例如:
| NPC 情况 | AI 复杂度 |
|---|---|
| 玩家面前的敌人 | 使用完整感知、行为树和寻路 |
| 隔壁房间的敌人 | 降低决策频率 |
| 地图另一端的敌人 | 使用简化状态更新 |
| 玩家暂时不可能遇到的 NPC | 暂停部分计算 |
3.4.3 Content Creation & Tools(内容制作和工具)
开发者需要借助专门工具创建和管理 AI 内容。
其包含:
- 路径点编辑器(Waypoint editors):开发者可以在地图中放置路径点,让 NPC 沿着这些位置移动。
- 行为树编辑器(Behavior tree editors):设计师可以通过可视化界面调整 NPC 的行为逻辑。
- 导航网格工具(Navmesh tools):它帮助开发者定义 NPC 可以行走的区域。
3.4.4 Debugging & Visualization(调试和可视化)
开发者需要看到 AI 为什么选择某个行为。
如果 NPC 表现异常,开发者要判断问题出现在哪个模块。
可视化工具可以在屏幕上显示:
| 调试信息 | 示例 |
|---|---|
| NPC 当前状态 | Patrol、Combat、Search |
| 当前目标 | 玩家、掩体、路径点 |
| 感知范围 | 视野扇形、声音半径 |
| 寻路路线 | 从当前位置到目标位置的路径 |
| 行为树节点 | 当前正在执行哪个节点 |
| Utility 分数 | 不同行为的评分 |
通过这样的方式帮助开发者判断问题出现在哪个模块。
4. 这些模块的具体算法
我们现在讲一下这些模块如何具体实现包括 Movement 和 Decision Making。
4.1 Movement
在实际运行中,各个模块会相互配合:
NavMesh 表示哪些区域可以行走→A* 搜索从起点到终点的大致路线→Movement 控制角色沿路线移动→转向行为处理避障、调整朝向和速度。
因此其包含Basic Movement(基础运动控制)、Pathfinding Algorithms (A*,路径搜索)、World Representation (NavMesh,用导航网格表示可通行区域)
运动算法起到控制器的作用。
运动算法会读取角色当前状态和游戏环境信息,再输出一个运动请求。
运动算法的输入包括几何信息(Geometric data)和游戏状态(Game state)。
几何数据例如:
| 信息 | 含义 |
|---|---|
| Current position | 角色当前坐标 |
| Orientation | 角色当前朝向 |
| Velocity | 角色当前速度 |
| Acceleration | 角色当前加速度 |
游戏状态例如:
| 信息 | 含义 |
|---|---|
| Target position | 角色需要到达的位置 |
| Level geometry | 地图中的墙壁、桌子、楼梯和房间结构 |
| Other characters | 其他角色的位置 |
| Paths | 已经规划好的路径 |
| Special locations | 掩体、出口、据点等特殊位置 |
运动算法输出一个运动请求。
常见输出有两种形式:
- 目标速度(Target velocity)
- 转向力或加速度(Steering force and acceleration)
下图展示了这个过程。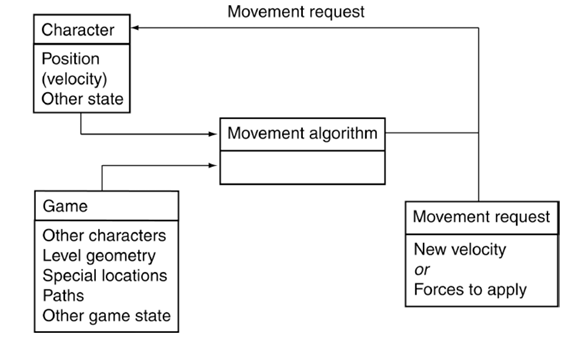
例如:角色准备前往出口→算法读取角色当前位置→算法读取出口位置和地图障碍物→算法输出向前移动并向右转向→角色位置发生变化→下一帧重新计算。
很多游戏虽然使用三维场景,角色移动仍然可以简化成平面上的运动问题。因此是 2D 或者 2.5D 上进行计算。
角色具有三维位置,但朝向变化通常围绕竖直轴进行(full 3D position but orientation restricted to the up-axis)。
4.1.1 基础范式
对于游戏角色运动控制的两种基础范式。它们接收角色状态和目标位置,再计算角色应该如何移动。主要差别在于:角色的速度是否可以瞬间改变,以及系统是否考虑加速度和惯性。
- Kinematic Movement(运动学式移动)
它只处理角色的位置和朝向等几何信息,不考虑质量、惯性和受力过程。
也就是说,其只根据静态数据进行计算。
系统直接输出角色需要采用的速度。
直接开始移动,或者直接停止移动。
因此这样做会显得移动比较机械。
因为系统忽略惯性和质量,速度可以瞬间改变。
因此其一般是早期街机游戏使用的方式,例如《吃豆人》里的幽灵。 - Steering Behaviors(动态转向行为)
它会考虑角色当前速度,再输出加速度或作用力,让角色逐渐调整运动状态。
因此其除了考虑静态数据还会考虑当前速度。
系统输出加速度或力。
因此这样做最终的移动轨迹更加平滑。
因为系统会考虑动量,因此移动表现更加自然。
两者对比在下表中更加清晰。
| 对比项目 | Kinematic Movement | Steering Behaviors |
|---|---|---|
| 中文理解 | 运动学式移动 | 动态转向行为 |
| 主要输入 | 位置、朝向 | 位置、朝向、当前速度 |
| 主要输出 | 目标速度 | 加速度或作用力 |
| 是否考虑惯性 | 通常不考虑 | 考虑 |
| 速度变化 | 可以瞬间变化 | 逐渐变化 |
| 移动效果 | 简洁、直接 | 平滑、自然 |
| 常见用途 | 网格游戏、简单 NPC | 现代角色、车辆、群体行为 |
4.1.2 伪代码
我们现在用最基础的追寻目标行为来看一下两者的具体实现上的区别。
对于Kinematic Movement(运动学式移动),其核心逻辑是:
读取角色当前位置→读取目标位置→计算从角色指向目标的方向→将方向标准化→乘以最大速度→更新角色朝向→输出目标速度。
用公式表示就是: velocity = target.position − character.position ∥ target.position − character.position ∥ × maxSpeed \text{velocity}=\frac{\text{target.position} - \text{character.position}} {\left\|\text{target.position} - \text{character.position}\right\|} \times \text{maxSpeed} velocity=∥target.position−character.position∥target.position−character.position×maxSpeed
相关伪代码如下:
class KinematicSeek:
character: Static
target: Static
maxSpeed: float
function getSteering() -> KinematicSteeringOutput:
result = new KinematicSteeringOutput()
# Get the direction to the target.
result.velocity = target.position - character.position
# The velocity is along this direction, at full speed.
result.velocity.normalize()
result.velocity *= maxSpeed
# Face in the direction we want to move.
character.orientation = newOrientation(
character.orientation,
result.velocity)
result.rotation = 0
return result我们再看Steering Behaviors(动态转向行为),其也是让角色朝目标位置移动。
区别在于控制方式。前者直接输出速度,这里输出加速度,因此角色的速度会逐渐变化。
思路如下:读取角色当前位置→读取目标位置→计算目标方向→将方向向量单位化→乘以最大加速度→输出线性加速度。
公式如下: a = p target − p character ∥ p target − p character ∥ × a max \mathbf{a}=\frac{\mathbf{p}{\text{target}} - \mathbf{p}{\text{character}}} {\left\|\mathbf{p}{\text{target}} - \mathbf{p}{\text{character}}\right\|} \times a_{\max} a=∥ptarget−pcharacter∥ptarget−pcharacter×amax
伪代码如下:
class Seek:
character: Kinematic
target: Kinematic
maxAcceleration: float
function getSteering() -> SteeringOutput:
result = new SteeringOutput()
# Get the direction to the target.
result.linear = target.position - character.position
# Give full acceleration along this direction.
result.linear.normalize()
result.linear *= maxAcceleration
result.angular = 0
return result在此基础上我们还可以给其添加障碍物与墙壁规避机制。
它的核心思路是:角色沿当前运动方向向前发射一条检测射线。如果射线即将撞到墙壁,系统就在碰撞点附近生成一个新的临时目标,让角色朝远离墙壁的方向转向。
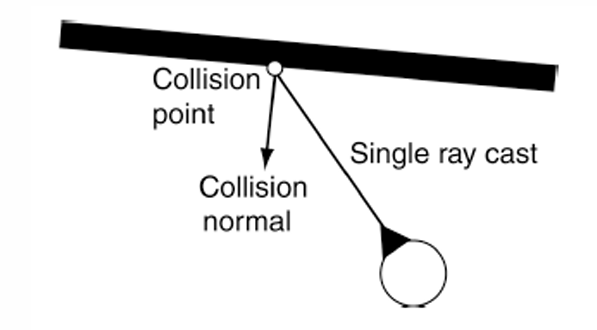
完整过程如下:检测到墙壁→计算碰撞点→读取碰撞法线→沿法线方向设置安全目标→调用 Seek→角色朝安全目标转向。
伪代码如下:
class ObstacleAvoidance extends Seek:
detector: CollisionDetector
# The minimum distance to a wall (i.e., how far to avoid
# collision) should be greater than the radius of the character.
avoidDistance: float
# The distance to look ahead for a collision
# (i.e., the length of the collision ray).
lookahead: float
# ... Other data is derived from the superclass ...
function getSteering():
# 1. Calculate the target to delegate to seek.
# Calculate the collision ray vector.
ray = character.velocity
ray.normalize()
ray *= lookahead
# Find the collision.
collision = detector.getCollision(character.position, ray)
# If have no collision, do nothing.
if not collision:
return null
# 2. Otherwise create a target and delegate to seek.
target = collision.position + collision.normal * avoidDistance
return Seek.getSteering()4.1.3 Unity 中的碰撞系统
两个核心组件:
| 组件 | 作用 | 比喻 |
|---|---|---|
| Collider | 定义物体的碰撞边界 | 物体的"皮肤" |
| Rigidbody 或 Rigidbody2D | 定义物体的质量、速度和物理运动方式 | 物体的"灵魂" |
4.1.3.1 Collider(碰撞体)
Collider(碰撞体)告诉 Unity 物理引擎:
这个物体占据多大的空间,它的边界在哪里。
游戏画面中看到的模型,和物理引擎实际用于碰撞计算的形状可以不同。
例如,一个角色在画面中可能有手臂、腿部和复杂的服装,但碰撞计算通常只使用一个较简单的胶囊形状。
使用基础碰撞体(Primitive Colliders)可以显著降低计算量。
常见类型如下:
| Unity 组件 | 中文 | 适合的对象 |
|---|---|---|
| Box Collider | 盒形碰撞体 | 墙壁、箱子、桌子、门 |
| Sphere Collider | 球形碰撞体 | 球、圆形道具、爆炸检测范围 |
| Capsule Collider | 胶囊碰撞体 | 人形角色、敌人 NPC |
因此对于复合碰撞体(Compound Colliders),可以通过组合多个简单碰撞体,近似描述复杂物体的形状。
例如一辆汽车可以使用多个基础碰撞体:
车身:Box Collider
车头:Box Collider
车尾:Box Collider
车轮附近:多个辅助 Collider
这样可以获得较准确的碰撞效果,同时避免直接使用复杂网格进行计算。
当然对于一些形状不规则的物体,我们可以使用精度更高的方式,但是计算成本也会更高。
Mesh Collider(网格碰撞体)使用模型网格作为碰撞边界,精度较高,但计算成本也更高。
例如:一块形状不规则的岩石。
因此对于会频繁移动的角色和物体,通常优先使用基础碰撞体或复合碰撞体。
原因是 Mesh Collider 的计算量更大。某些情况下,移动物体还需要启用 Convex 选项,使用简化后的凸包参与碰撞。
4.1.3.2 Rigidbody
Rigidbody 负责定义物体如何参与物理运动。
Rigidbody 可以让物体具有以下属性:
| 属性 | 含义 |
|---|---|
| Mass | 质量 |
| Velocity | 速度 |
| Angular velocity | 角速度 |
| Drag | 阻力 |
| Use Gravity | 是否受到重力影响 |
| Constraints | 是否锁定某些位置轴或旋转轴 |
例如,一个箱子只有 Collider 时,它拥有碰撞边界。
给它加上 Rigidbody 后,它还可以被推动、掉落和撞飞。
因此对于碰撞系统设计的黄金规则是两个物体之间要产生完整的物理碰撞检测与碰撞回调,至少有一个物体需要带有 Rigidbody。
4.1.3.3 碰撞回调
首先我们先解释 Callback (回调函数)。
它表示某个事件发生时,系统自动调用对应函数。
因此比如,NPC 撞到墙壁时,Unity 可以自动执行:
csharp
void OnCollisionEnter(Collision collision)
{
Debug.Log("NPC 撞到了物体");
}因此碰撞系统一般有两种回调函数。
4.1.3.3.1 OnCollisionEnter(实体物理碰撞)
当两个物体发生实体接触时,触发物理碰撞回调。这就是硬碰撞(hard collisions)。因为碰撞会产生物理效果,例如阻挡、弹跳、摩擦或停止移动。
要触发 OnCollisionEnter,通常需要满足以下条件:
| 要求 | 含义 |
|---|---|
两个物体都带有 Collider |
双方都有碰撞边界 |
至少一个物体带有 Rigidbody |
至少一方参与动态物理系统 |
双方的 Is Trigger 都没有勾选 |
需要进行实体碰撞 |
| 图层之间允许发生碰撞 | Layer Collision Matrix 没有屏蔽对应图层 |
我们可以用于:检测 NPC 是否被投射物击中,或者是否撞到了原本应该避开的墙壁。
在 NPC 撞墙示例中,两者都有 Box Collider,但是 NPC 有 Rigidbody。
4.1.3.3.2 OnTriggerEnter(进入感知区域)
当一个物体进入触发区域时,执行检测逻辑。这种检测通常不会阻挡物体移动。所以被理解为软检测(soft detection)。它只负责判断物体是否进入某个区域。
因此要实现 OnTriggerEnter 的基本要求如下:
| 要求 | 含义 |
|---|---|
至少一方的 Collider 勾选 Is Trigger |
需要存在触发区域 |
| 双方通常都需要 Collider | 需要有检测边界 |
至少一方通常需要 Rigidbody |
让 Unity 物理系统处理回调 |
| 图层之间允许检测 | 图层配置不能屏蔽交互 |
我们解释一下这里的 Is Trigger 是什么。每个 Collider 组件中都有一个选项:Is Trigger。
勾选后,这个碰撞体会变成触发器。
因此其用途可以是:在 NPC 头部附近设置一个不可见的视野锥体。玩家进入这个区域后,NPC 就能认为玩家在其视野里。
所以 OnCollisionEnter 用于检测具有物理阻挡效果的实体碰撞。OnTriggerEnter 用于检测角色是否进入某个感知或触发区域。游戏 AI 常使用前者处理撞墙和受击,使用后者实现警戒范围、视野范围和任务触发。
4.1.4 Pathfinding(寻路)
角色已经知道自己要去哪里,接下来应该选择哪条路线,才能绕开障碍物并到达目标位置。
当然这条路要合理,且要尽可能的短。
这种问题无法由前面的 Seek 算法解决,因为 Seek 适合于目标与角色之间没有障碍物的情况。例如出现有障碍物的情况,它主要根据当前速度方向处理眼前碰撞。面对复杂地图时,角色仍然可能走入死胡同。
因此寻路算法通常不会直接控制角色每一步怎么走。它会先生成一系列中间位置,叫做路径点/导航点(Waypoints)。
因此寻路位于 Decision Making 和 Movement 之间。它只负责找到实现目标的路线,因此它同时连接两个层次。
完整流程可以写成:Decision Making决定去哪里→Pathfinding计算怎么到达那里→Movement控制角色实际移动→Animation 和 Physics 呈现跑步、转向和碰撞效果。
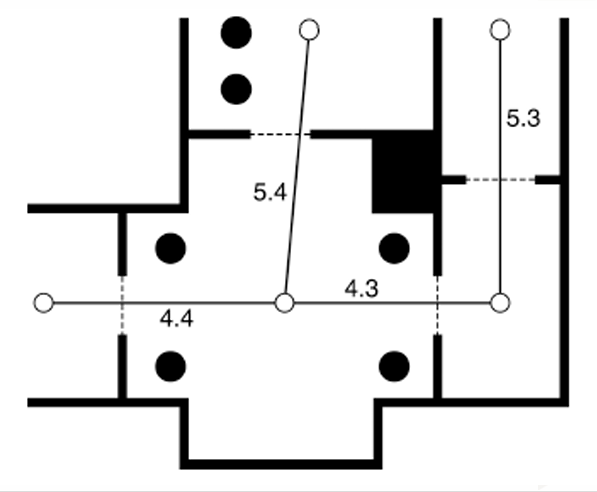
4.1.4.1 Pathfinding Graph(寻路图)
寻路算法通常先把游戏地图抽象成一张图,再在图上寻找总代价较低的路线。
算法不会直接读取墙壁、房间、门洞等完整三维几何细节。地图需要先转换为节点和连接关系。
| 概念 | 英文 | 含义 |
|---|---|---|
| 节点 | Node | 地图中的位置、区域或路径点 |
| 边 | Edge 或 Connection | 两个节点之间是否可以通行 |
| 代价 | Cost | 从一个节点移动到另一个节点需要付出的成本 |
因此寻路算法会先把地图抽象成由节点、边和代价组成的图,然后在图上寻找从起点到终点总代价较低的路线。
4.1.4.2 A* Algorithm
它用于计算角色从起点到终点的一条合适路径。游戏中的 NPC 寻路、地图导航和机器人路径规划都经常使用它。
综合考虑已经走过的成本,以及从当前位置到终点的预计成本。
公式为: f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)
其中, n n n表示当前正在评估的节点。 f ( n ) f(n) f(n)是经过当前节点到达终点的总预计成本, g ( n ) g(n) g(n)是从起点到当前节点 n n n的实际成本, h ( n ) h(n) h(n)是从当前节点 n n n到终点的预计成本。
这里预计成本是一种启发式算法,只是估计当前节点到终点还有多远。它不要求精确,只需要快速提供一个合理估计。但是启发式估计的质量会影响算法运行效率。
如果 h ( n ) h(n) h(n)不超过真实的剩余成本,A*可以保证找到最短路径,但可能需要搜索更多节点。
这种启发式函数称为可采纳启发式函数。
例如,在有障碍物的地图中,直线距离通常小于或等于真实行走距离.使用直线距离作为 h(n) 时,估计值偏保守,但能够保持最短路径保证。
如果h(n) 高于真实剩余成本,搜索通常会更偏向终点方向,速度可能提高,但结果未必是最短路径。也就是说最终角色仍然可以到达终点,只是多走了一段距离。
因此游戏中通常更重视角色行为是否合理、响应是否及时。轻微牺牲路径最优性有时可以换取更快的计算速度。
4.1.4.3 NavMesh(导航网格)
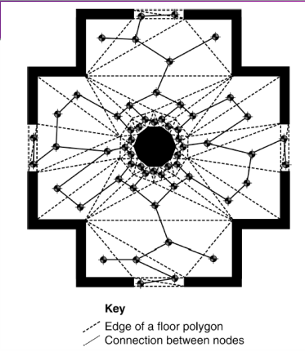
它用于告诉游戏中的 AI 角色地图中哪些区域可以行走,哪些区域需要避开。
NavMesh 是一种用于表示 AI 角色可行走区域的数据结构。
游戏场景通常包含复杂的三维模型,例如地面、楼梯、墙壁、桌椅和岩石。寻路算法没有必要直接处理所有模型细节。
系统会提取角色可以安全行走的区域,并使用多个多边形进行近似表示。
因此 NavMesh 可以理解为专门给 AI 角色使用的简化地图。
4.1.4.3.1 Pathfinding Aid
NavMesh 存储寻路所需的信息,帮助 AI 角色计算从 A 点到 B 点的合适路线。
因此NavMesh 本身主要负责表示可通行空间。
A* 等寻路算法负责在这些区域中搜索路线。
两者的关系可以写成:NavMesh 提供地图结构→ A*搜索合适路线→Movement 系统控制角色沿路线移动。
4.1.4.3.2 Baked Geometry
NavMesh 是 Baked(烘焙生成的),也就是说系统会根据场景中的地面、楼梯、地形和障碍物,提前计算可行走区域。
烘焙提前把复杂地图处理成 AI 能快速使用的导航数据。
这样做可以减少游戏运行时的计算压力。
4.1.4.3.3 Agent Awareness
生成 NavMesh 时通常会考虑角色体型,包括半径和高度。
不同角色的通行能力不同。
常见参数包括:
| 参数 | 含义 |
|---|---|
| Radius | 角色半径,决定能否通过狭窄区域 |
| Height | 角色高度,决定能否进入低矮区域 |
| Step Height | 可跨越台阶的最大高度 |
| Max Slope | 可以行走的最大坡度 |
所以,同一张地图可能需要针对不同角色类型生成不同的导航数据。
4.1.4.3.4 Virtual World Interaction
NavMesh 除了用于 NPC 寻路,还可以用于虚拟现实中的传送移动。
例如在 VR 游戏中,玩家使用控制器选择一个落点。系统需要判断该位置是否安全、是否可以站立。
这样可以避免玩家传送到不可到达的位置。
4.1.4.3.5 Unity 中的 NavMesh
NavMeshAgent 是添加在角色身上的组件,用于让角色在 NavMesh 上移动。
NavMeshObstacle 用于表示会阻挡路径的物体。
例如,一个敌人需要追赶玩家:敌人发现玩家→NavMesh 判断哪些区域可以通行→寻路算法计算绕过墙壁的路线→NavMeshAgent 沿路线移动→发现前方出现移动箱子→局部避障系统调整方向→继续追赶玩家。
4.1.4.4 A* 和 NavMesh 的关系
NavMesh 提供可行走区域,A* 在这些区域组成的图结构上搜索路线。
A* 需要在图结构(有向非负权重图)上工作,也就是需要一个简化后的结构,才能快速计算路线。而 NavMesh 的作用就是把复杂空间转换成适合寻路的表示形式。
在现代游戏引擎中,它们通过几何抽象和图遍历过程协同工作。
NavMesh 会把可行走地面划分成多个凸多边形(convex polygons)。
凸多边形的特点是多边形内部任意两点之间的直线路径都位于多边形内部。
这意味着角色在同一个凸多边形内部移动时,通常不需要担心撞到墙壁。
NavMesh 中的每个多边形可以被视为寻路图中的一个节点。
如果两个多边形共享一条边,角色通常可以从一个区域走到另一个区域。系统会在对应节点之间建立连接。
相邻节点之间的成本,通常可以用两个区域中心点之间的欧几里得距离表示。
通过这样的方式 NavMesh 描述可走区域,A* 负责选择路线。
4.2 Decision Making
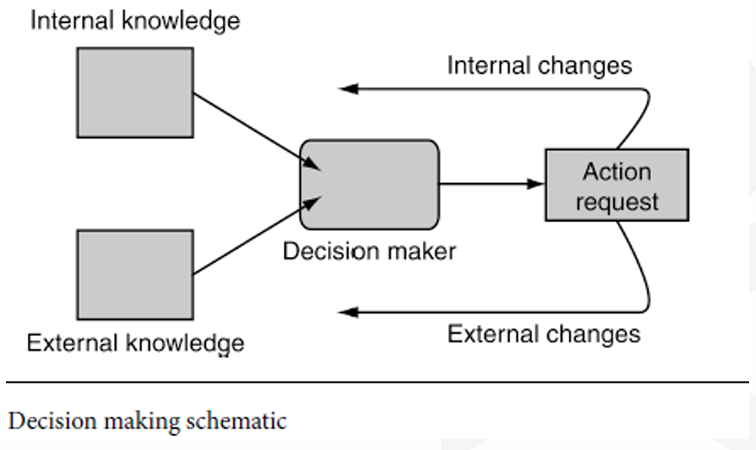
Decision Making 的定义是:角色处理已有信息,并选择合适行动的能力。
输入角色自身的状态以及外部信息。
角色自身的状态,例如:
| 内部信息 | 含义 |
|---|---|
| Health | 当前生命值 |
| Ammo | 当前弹药数量 |
| Goals | 当前目标 |
| Current state | 当前状态,例如巡逻、战斗、逃跑 |
| Cooldown | 技能是否可以使用 |
| Role | 角色职责,例如突击、支援、防守 |
外部信息,例如:
| 外部信息 | 含义 |
|---|---|
| Enemy positions | 敌人或玩家的位置 |
| Layout | 地图结构 |
| Cover locations | 掩体位置 |
| Distance | 与玩家的距离 |
| Line of sight | 是否能够看到玩家 |
| Nearby threats | 附近是否有手榴弹或其他危险 |
| Team information | 队友的位置和状态 |
决策模块会使用某种逻辑方法处理信息。
常见方法包括:
| 方法 | 中文 | 特点 |
|---|---|---|
| FSM | 有限状态机 | 简单清晰,适合基础行为 |
| BT | 行为树 | 模块化,适合复杂 NPC |
| Utility AI | 效用型 AI | 给行动评分,选择分数较高的行为 |
| GOAP | 目标导向行动规划 | 根据目标动态组合行动步骤 |
决策模块最终输出一个行动请求。
例如:
| Action Request | 中文含义 |
|---|---|
| Attack | 攻击 |
| Reload | 换弹 |
| Find Cover | 寻找掩体 |
| Patrol | 巡逻 |
| Search | 搜索 |
| Retreat | 撤退 |
| Flank | 包抄 |
| Throw Grenade | 投掷手榴弹 |
因此 Decision Making 是 Game AI 的行动选择模块。它读取角色内部状态和外部环境信息,通过有限状态机、行为树等逻辑方法生成行动请求,再由寻路、运动、动画和物理系统负责执行。
4.2.1 Finite State Machine(FSM,有限状态机)
FSM 是游戏 AI 中最基础的决策方法之一。它的核心思路是:
角色在任意时刻处于一个明确状态,根据触发条件切换到另一个状态。
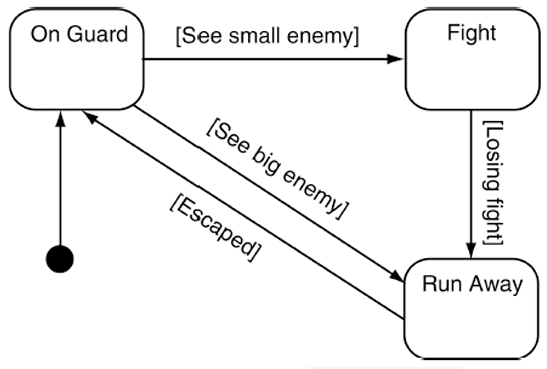
有限状态机由 State(状态)和 Transition(状态转换)组成。
State(状态),每个状态对应一种相对明确的行为模式。
例如:
| 状态 | NPC 的行为 |
|---|---|
| Patrol | 沿固定路线巡逻 |
| On Guard | 保持警戒,观察附近区域 |
| Fight | 攻击敌人 |
| Run Away | 逃离敌人 |
| Search | 搜索失去踪迹的玩家 |
| Reload | 换弹 |
Transition(状态转换),它规定角色在什么条件下从一个状态切换到另一个状态。
例如:Patrol 状态中如果发现玩家就进入 Fight 状态。这里发现玩家就是转换条件。
常见转换条件包括:
| 条件 | 可能引发的转换 |
|---|---|
| 看到玩家 | 从巡逻切换到追赶 |
| 玩家进入攻击距离 | 从追赶切换到攻击 |
| 生命值过低 | 从战斗切换到逃跑 |
| 弹药为零 | 从攻击切换到换弹 |
| 玩家消失一段时间 | 从搜索切换回巡逻 |
| 成功脱离战斗 | 从逃跑切换回警戒 |
Initial State(初始状态),也就是角色进入游戏时最先处于的状态。例如前面的图的例子,角色一开始的状态就是 Guard(警戒状态)。
每个状态可以附带三类动作:
- Entry Actions
进入状态时执行一次的动作。
例如,角色进入战斗状态时,拔出武器,锁定目标。 - Exit Actions
离开状态时执行一次的动作。
例如,角色离开战斗状态时,取消目标锁定,收起武器。 - Active Actions
角色停留在当前状态期间持续执行的动作。
在角色保持该状态期间,每一帧或每次逻辑更新都会执行。
例如,角色处于逃跑状态时,不断计算远离敌人的方向、更新逃跑路径、沿路径移动、检查是否已经脱离危险。
4.2.1.1 实现方式
有两种实现方式:
- Hard Coded FSM(硬编码状态机)
状态转换条件和具体行为直接写在程序代码里。
例如,可以使用一个很大的 switch 结构:
这样做执行速度快,结构直接。但是角色行为复杂以后,代码会越来越难维护。
csharp
switch (currentState)
{
case State.Patrol:
Patrol();
if (CanSeePlayer())
{
currentState = State.Chase;
}
break;
case State.Chase:
ChasePlayer();
if (IsPlayerInAttackRange())
{
currentState = State.Attack;
}
break;
case State.Attack:
AttackPlayer();
if (ammo <= 0)
{
currentState = State.Reload;
}
break;
}- Data Driven FSM(数据驱动状态机)
状态机结构写在外部数据文件中,也可以通过可视化工具配置。
例如,可以使用 JSON 描述状态和转换关系:
python
{
"state": "Patrol",
"action": "PatrolRoute",
"transitions": [
{
"condition": "CanSeePlayer",
"targetState": "Chase"
}
]
}也可以用图形化编辑器拖拽节点:
Patrol
↓ CanSeePlayer
Chase
↓ InAttackRange
Attack
↓ AmmoEmpty
Reload程序读取这些数据后,再在运行时构建角色逻辑。
4.2.1.2 Hierarchical Finite State Machine(HFSM,分层有限状态机)
普通 FSM 适合状态较少的情况。状态越来越多以后,转换箭头会大量增加,结构会变得难以维护。HFSM 会把相关状态放进一个更高层的状态中,从而减少重复连接。
如下图所示:
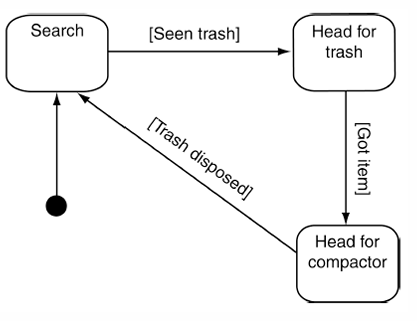
这里描述了一个清洁机器人的基本任务。
机器人有三个状态:
| 状态 | 含义 |
|---|---|
Search |
搜索垃圾 |
Head for trash |
前往垃圾所在位置 |
Head for compactor |
把垃圾运送到压缩机 |
这个状态机非常简单。
但是如果我们想要增加电量不足的状态该怎么办,因为这里会在每个状态中存在。
| 当前状态 | 没电后的行动 |
|---|---|
| 正在搜索垃圾 | 前往充电 |
| 正在前往垃圾 | 前往充电 |
| 正在运送垃圾 | 前往充电 |
因此,中间图需要增加多个充电状态:
| 新状态 | 含义 |
|---|---|
Get power (search) |
搜索过程中没电,前往充电 |
Get power (head for trash) |
前往垃圾途中没电,前往充电 |
Get power (head for compactor) |
运送垃圾途中没电,前往充电 |
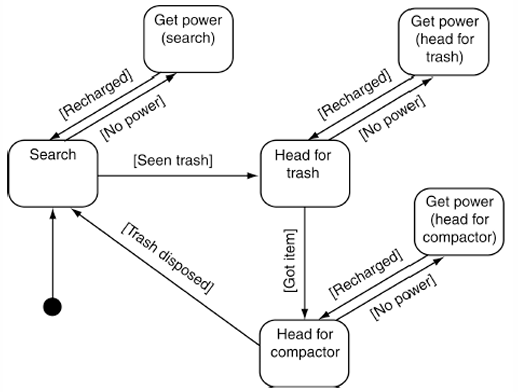
充电完成以后,机器人还要回到原来的状态。
因此这里的逻辑类似且重复,如果再增加,那么状态机就会越来越复杂。
因此 HFSM 的解决方案是把一个状态机嵌套在另一个高层状态中,用层级结构降低复杂度。
这里把原来的三个清洁状态放进一个更大的状态:Clean up(执行清洁任务)。
它是一个 Super state,也就是:高层状态或父状态。
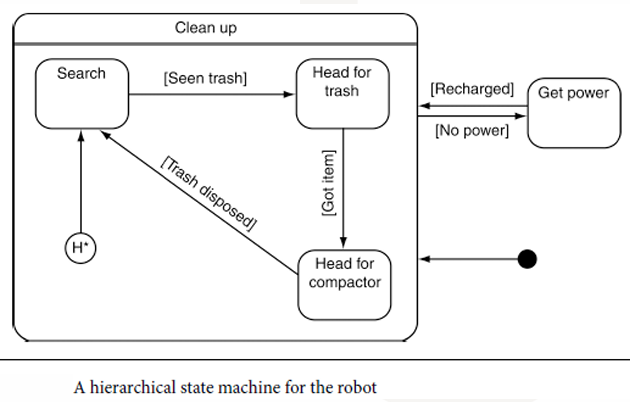
这里的 Super stgate 是一个高层状态内部,它可以包含一个完整的子状态机。
当然这里还需要一个 History State (历史状态节点)。
记住角色离开父状态之前,最后处于哪个子状态。返回父状态时,继续执行之前中断的任务。
假设机器人正在运送垃圾,途中突然没电,充电完成后,机器人会继续回来运送垃圾,而不是从初始状态开始。
4.2.2 Behavior Tree(BT,行为树)
行为树是游戏 AI 中常用的决策结构。它会把角色行为拆分成多个任务,再按照树状层级组织起来。
有限状态机通常关注角色当前处于什么状态,行为树更关注角色当前应该执行什么任务。
例如行为树的思路是:
当前最合适的任务是什么?例如:
选择当前任务
├── 附近有手榴弹
│ └── 躲避
├── 生命值过低
│ └── 寻找掩体
├── 弹药耗尽
│ └── 换弹
├── 看到玩家
│ └── 攻击
└── 没有看到玩家
└── 巡逻行为树是一棵由任务模块组成的树。系统会从根节点开始,周期性地向下检查和执行节点。
行为树具有很强的模块化特点。同一个子树可以重复用于多种角色。
4.2.2.1 实现方式
行为树核心内容有三个部分:
- 行为树如何周期性执行
- 每个节点执行后会返回什么状态
- Sequence 和 Selector 两类组合节点如何控制任务流程
4.2.2.1.1 Tick
Tick 可以理解为行为树的一次更新信号。
行为树通常从根节点开始,按照固定频率向下检查节点,判断当前应该执行什么任务。
4.2.2.1.2 每个节点会返回三种状态
每个行为树节点执行后,通常会返回以下三种状态:
| 状态 | 中文 | 含义 |
|---|---|---|
Success |
成功 | 当前任务已经完成 |
Failure |
失败 | 当前任务无法完成 |
Running |
执行中 | 当前任务还没有结束,需要后续继续执行 |
4.2.2.1.3 Composite Nodes(组合节点)
它们本身通常不执行具体动作,而是控制多个子节点的执行顺序。
-
Sequence(序列节点)
序列节点相当于逻辑与 AND。所有子任务都成功,整个序列才成功。
例如:是否有弹药?→是否看到目标?→开火。
只有前两个条件都满足,AI 才会开火
如果没有弹药,后面的两个都不会继续执行。
-
Selector(选择节点)
选择节点相当于逻辑或 OR。只要找到一个可以执行成功的子节点,整个 Selector 就成功。
例如:优先尝试攻击→攻击无法执行时,尝试逃跑→逃跑也无法执行时,进入待机
4.2.2.2 FSM 与 BT 的对比
FSM 更适合简单、清晰、线性的逻辑;行为树更适合复杂、模块化、需要频繁响应环境变化的角色 AI。
FSM 的优点:当角色行为较少、流程比较固定时,FSM 很容易理解和实现。
例如菜单系统、Boss阶段。
FSM 的缺点:状态越来越多以后,FSM 会变得难以扩展,转换关系也容易过于僵硬。
BT 的优点:行为树更容易扩展,模块化程度更高,也更适合制作复杂且具有快速反应能力的 NPC。
BT 的缺点:行为树初期搭建成本较高。树结构过大以后,调试也可能变得困难。
很多现代大型商业游戏会使用行为树管理角色 AI。
4.2.2.3 一个用于学习行为树的游戏示例。
行为树可以通过不同类型的节点组合,构建出清晰、可复用、可视化的 NPC 行为逻辑。
通过组合节点,可以用可视化、模块化、可复用的方式设计行为。
例如,可以把一个 NPC 的逻辑拆成多个小模块,这些模块可以重新组合,也可以重复用于不同角色。
行为树中的节点类型:Composite、Decorator、Leaf。
- Composite(组合节点)
其中包含的 Sequence 和 Selector 不再过多叙述。Parallel(并行节点)指的是同时执行多个子节点。 - Decorator(修饰节点)
它通常包裹一个子节点,用来改变子节点的执行条件、执行频率或返回结果。
例如 Loop (循环执行)和 Invert(反转结果)。 - Leaf(叶子系欸但)
它位于行为树最底层,通常负责检查条件或执行具体动作。
叶子节点有两类:Condition(条件节点),它用于检查某个条件是否成立。
Action(动作节点),它用于执行具体行为。动作节点可能立即完成,也可能需要持续一段时间。
运行细节在 4.2.2.1 节介绍过了,这里就不再重复了。