目录
- 一、前言
- 二、环境部署
-
- [1、安装 PaddlePaddle 深度学习框架](#1、安装 PaddlePaddle 深度学习框架)
-
- [1.1 安装前提与版本选择](#1.1 安装前提与版本选择)
- [1.2 使用 pip 安装(推荐)](#1.2 使用 pip 安装(推荐))
- [1.3 安装验证](#1.3 安装验证)
- [2、安装 easyocr 核心库](#2、安装 easyocr 核心库)
-
- [2.1 EasyOCR 简介](#2.1 EasyOCR 简介)
- [2.2 使用 pip 安装 EasyOCR](#2.2 使用 pip 安装 EasyOCR)
- [2.3 安装验证与模型下载测试](#2.3 安装验证与模型下载测试)
- [3、安装图像处理库 OpenCV](#3、安装图像处理库 OpenCV)
-
- [3.1 使用 pip 安装 OpenCV-Python](#3.1 使用 pip 安装 OpenCV-Python)
- [3.2 安装验证](#3.2 安装验证)
- 4、创建并运行脚本
-
- [4.1 创建脚本](#4.1 创建脚本)
- [4.2 运行脚本](#4.2 运行脚本)
- [4.3 说明与注意事项](#4.3 说明与注意事项)
一、前言
在书法学习、古籍数字化项目中,我们常常会收集大量的单字书法图片。这些图片可能来自碑帖扫描、名家手迹或创作练习,文件名往往是杂乱无章的编号(如 IMG_001.jpg、扫描图1.png),给后续的整理、检索和使用带来了极大的不便。手动为每张图片命名不仅耗时耗力,而且容易出错。
本文介绍的**"书法单字图片批量重命名工具"** ,完美解决了上面的问题。它利用 EasyOCR 光学字符识别技术,自动识别图片中的汉字,并将文件重命名为识别出的文字。
本文将带你如何从零开始部署环境,运行这款强大的工具。
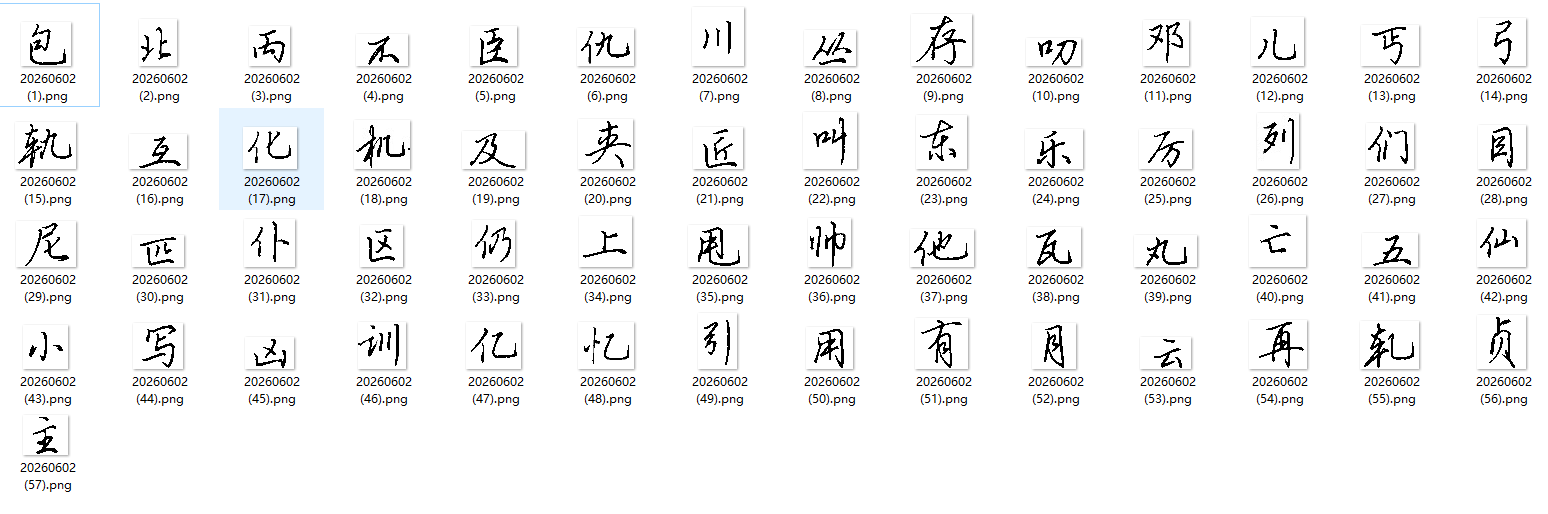
二、环境部署
1、安装 PaddlePaddle 深度学习框架
PaddlePaddle(飞桨)是百度开源的深度学习平台,EasyOCR 依赖其底层计算引擎进行高效的文本检测与识别。因此,安装 PaddlePaddle 是运行本工具的首要步骤。
1.1 安装前提与版本选择
在安装前,请确保您的系统已安装 Python 3.6 及以上版本。您可以通过以下命令检查:
bash
python --version或
bash
python3 --versionPaddlePaddle 提供了 CPU 版本 和 GPU 版本 。对于大多数 OCR 识别任务,CPU 版本已足够使用,且安装更简单。如果您拥有 NVIDIA GPU 并已配置好 CUDA 和 cuDNN,可以选择 GPU 版本以获得更快的处理速度。本教程以 CPU 版本 为例进行安装。
1.2 使用 pip 安装(推荐)
打开终端(Windows 用户可使用 CMD 或 PowerShell,macOS/Linux 用户使用 Terminal),执行以下命令:
bash
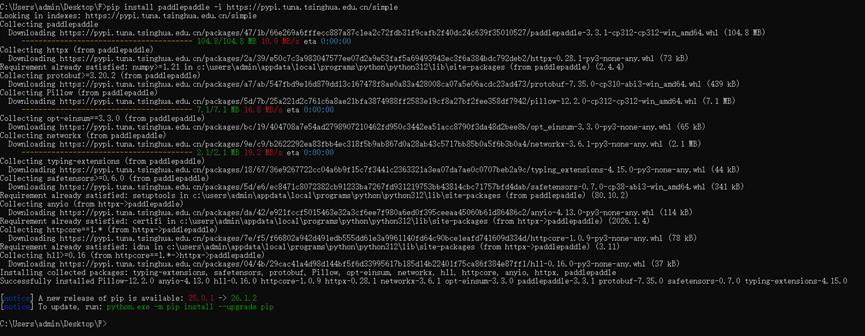
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple命令详解:
pip install paddlepaddle: 这是安装 PaddlePaddle CPU 版本的核心命令。-i https://pypi.tuna.tsinghua.edu.cn/simple: 指定使用 清华大学镜像源 进行下载。
1.3 安装验证
安装完成后,需要验证 PaddlePaddle 是否成功安装并能正常导入。
-
打开 Python 交互环境:
bashpython -
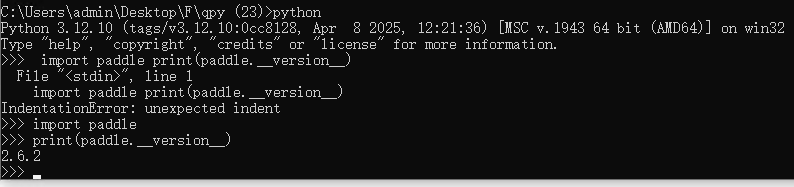
在 Python 环境中,输入以下代码并回车:
pythonimport paddle print(paddle.__version__) -
如果安装成功,终端将输出 PaddlePaddle 的版本号(例如
2.6.2)。这证明 PaddlePaddle 已就绪。
2、安装 easyocr 核心库
EasyOCR 是本工具的核心,它是一个基于深度学习的开源 OCR(光学字符识别)库,支持 80 多种语言,对中文(简体/繁体)识别效果优秀,且使用非常简便。
2.1 EasyOCR 简介
EasyOCR 封装了文本检测(CRAFT)和文本识别(CRNN)两个深度学习模型,并提供了预训练模型。对于书法单字识别场景,它具有以下优势:
- 开箱即用:无需训练模型,安装后即可识别中文。
- 精度较高:对印刷体、手写体(包括部分书法字体)都有不错的识别能力。
- 多语言支持:除了中文,还可识别英文、日文、韩文等。
- 轻量级:相比一些商业 OCR 方案,EasyOCR 的模型大小适中,首次运行时会自动下载。
2.2 使用 pip 安装 EasyOCR
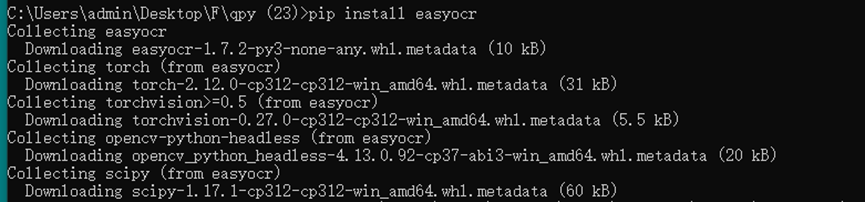
在终端中执行以下命令进行安装:
bash
pip install easyocr命令详解与注意事项:
-
基础命令 :
pip install easyocr会安装 EasyOCR 及其所有依赖。 -
镜像加速 :如果下载速度慢,可以像安装 PaddlePaddle 一样使用国内镜像源:
bashpip install easyocr -i https://pypi.tuna.tsinghua.edu.cn/simple -
版本指定 :如果需要安装特定版本,例如 1.7.2,可以使用:
bashpip install easyocr==1.7.2建议使用最新稳定版以获得最佳功能和性能。
2.3 安装验证与模型下载测试
安装完成后,强烈建议进行一个简单的验证,以确保库能正常导入,并触发首次模型下载(避免在正式运行时等待)。
-
验证库安装:打开 Python 交互环境,导入 EasyOCR。
bashpythonpythonimport easyocr print(easyocr.__version__)成功输出版本号(如
1.7.2)即表示库已正确安装。
注意 :首次初始化
Reader时,会自动从 GitHub Release 下载模型文件(约 50-80 MB)。下载完成后,模型会缓存在用户目录下(如~/.EasyOCR/model/),后续运行无需再次下载。
完成 EasyOCR 的安装与验证后,我们的 OCR 核心引擎就准备好了。接下来安装图像处理库 OpenCV,以便脚本能更好地读取和处理各种格式的图片。
3、安装图像处理库 OpenCV
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。在本工具中,它虽然不是 OCR 识别的核心,但扮演着至关重要的"预处理助手"角色,负责读取、解码和转换各种格式的图片,为 EasyOCR 提供标准化的图像输入。
3.1 使用 pip 安装 OpenCV-Python
在终端中执行以下命令:
bash
pip install opencv-python命令详解与选项:
-
opencv-python: 这是 OpenCV 的"主包",包含了 OpenCV 的主要模块(core, imgproc, highgui 等),满足绝大多数基础图像处理需求。 -
镜像加速:可以使用国内镜像源加速下载:
bashpip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple -
版本指定:如需安装特定版本(例如 4.8.1),可以使用:
bashpip install opencv-python==4.8.1
3.2 安装验证
安装完成后,建议进行简单的验证,确保 OpenCV 能正常导入和使用。
-
验证库安装 :打开 Python 交互环境。
bashpython -
在 Python 环境中,输入以下代码:
pythonimport cv2 print(cv2.__version__) -
如果安装成功,终端将输出 OpenCV 的版本号(例如
4.13.0)。这证明 OpenCV 已就绪。

至此,运行"书法单字图片批量重命名工具"所需的三个核心依赖(PaddlePaddle, EasyOCR, OpenCV)已全部安装并验证完毕。接下来,我们将进入最关键的步骤------创建工具脚本。
4、创建并运行脚本
环境部署完成后,我们需要创建核心的 Python 脚本文件。这个脚本将整合 EasyOCR 的识别能力与文件操作,实现自动化批量重命名。
4.1 创建脚本
将下列代码保存成python源文件:如rename_chars.py。
c
# -*- coding: gbk -*-
# -*- coding: utf-8 -*-
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
书法单字图片批量重命名工具 - EasyOCR 版本
自动识别图片中的汉字,并将文件重命名为识别出的文字
"""
import os
import re
import sys
def batch_rename_with_easyocr(folder_path):
"""使用 EasyOCR 批量重命名图片文件"""
# 检查 easyocr 是否安装
try:
import easyocr
except ImportError:
print("? EasyOCR 未安装,请运行: pip install easyocr")
return
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print(f"? 文件夹不存在: {folder_path}")
return
# 获取所有图片文件
extensions = ('.png', '.jpg', '.jpeg', '.bmp', '.tiff', '.gif')
image_files = [f for f in os.listdir(folder_path)
if f.lower().endswith(extensions)]
if not image_files:
print(f"? 在 {folder_path} 中没有找到图片文件")
return
print(f"?? 找到 {len(image_files)} 张图片")
print("?? 正在初始化 OCR 引擎(首次运行会下载模型,请稍候)...")
# 初始化 EasyOCR(简体中文,使用 CPU)
reader = easyocr.Reader(['ch_sim'], gpu=False, verbose=False)
print("? OCR 引擎初始化完成,开始处理...\n")
print("=" * 60)
success_count = 0
fail_count = 0
skip_count = 0
for idx, filename in enumerate(image_files, 1):
file_path = os.path.join(folder_path, filename)
print(f"[{idx}/{len(image_files)}] ?? {filename}")
try:
# OCR 识别
result = reader.readtext(file_path, detail=0, paragraph=False)
if result and result[0]:
# 获取第一个识别的文字块
detected = result[0].strip()
# 清理非汉字字符(保留中文、英文、数字)
clean_name = re.sub(r'[^\u4e00-\u9fff\w]', '', detected)
if clean_name and len(clean_name) >= 1:
# 限制文件名长度
if len(clean_name) > 20:
clean_name = clean_name[:20]
new_path = os.path.join(folder_path, f"{clean_name}.png")
# 处理重名
counter = 1
original_new_path = new_path
while os.path.exists(new_path) and new_path != file_path:
name = os.path.splitext(original_new_path)[0]
new_path = os.path.join(folder_path, f"{name}_{counter}.png")
counter += 1
# 重命名文件
if new_path != file_path:
os.rename(file_path, new_path)
print(f" ? 识别为: 「{detected}」 → {os.path.basename(new_path)}")
success_count += 1
else:
print(f" ?? 识别为: 「{detected}」 → 文件名已匹配")
skip_count += 1
else:
print(f" ?? 识别结果无效: '{detected}' → 跳过")
fail_count += 1
else:
print(f" ?? 未识别到文字 → 跳过")
fail_count += 1
except Exception as e:
print(f" ? 处理出错: {str(e)[:100]}")
fail_count += 1
continue
print("=" * 60)
print(f"\n?? 处理完成!")
print(f" ? 成功重命名: {success_count} 个")
print(f" ?? 跳过/失败: {fail_count} 个")
print(f" ?? 已匹配不变: {skip_count} 个")
print(f" ?? 总计: {len(image_files)} 个文件")
def main():
print("=" * 60)
print("??? 书法单字图片批量重命名工具 (EasyOCR版)")
print("=" * 60)
print()
# 获取文件夹路径
if len(sys.argv) > 1:
folder_path = sys.argv[1]
else:
folder_path = input("请输入图片文件夹路径(直接回车使用当前目录): ").strip()
if not folder_path:
folder_path = "./"
# 确认
print(f"\n?? 目标文件夹: {os.path.abspath(folder_path)}")
confirm = input("\n?? 即将对文件夹内的所有图片进行重命名,是否继续?(y/n): ").strip().lower()
if confirm == 'y':
print("\n开始处理...\n")
batch_rename_with_easyocr(folder_path)
else:
print("已取消操作")
if __name__ == "__main__":
main()将这个脚本文件和你的图片文件放在同一个文件夹下
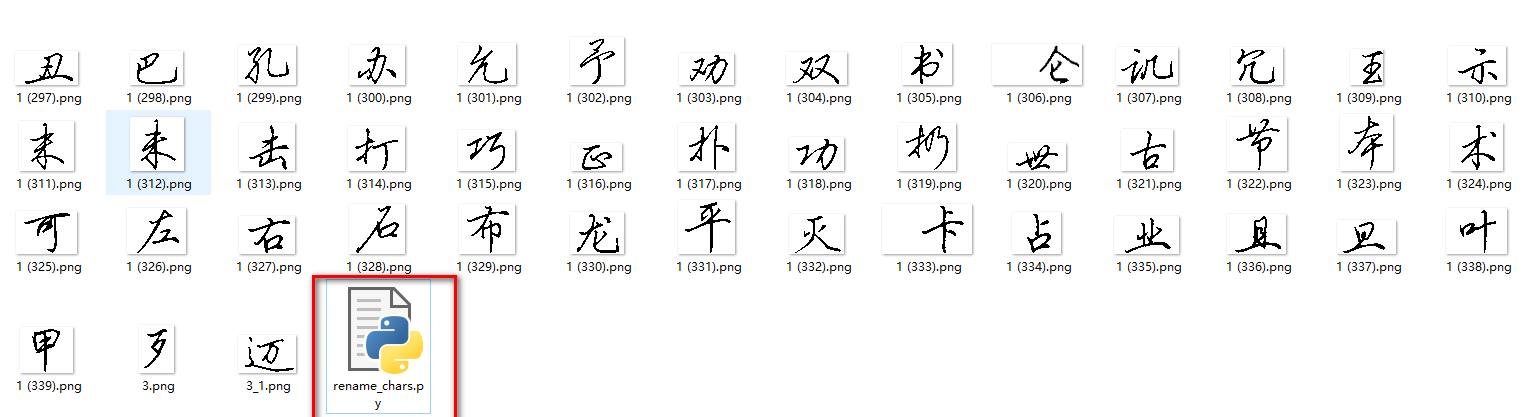
4.2 运行脚本
脚本创建完成后,您可以通过命令行方式运行它。这是最直接、最高效的运行方式,适合批量处理或自动化场景。
基本命令格式:
bash
python rename_chars.py 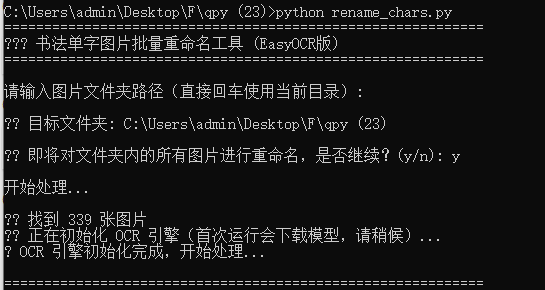
具体操作步骤:
-
打开终端/命令提示符:
- Windows :按
Win + R,输入cmd或powershell,回车。
- Windows :按
-
导航到脚本所在目录 :
使用
cd命令切换到存放rename_chars.py脚本的文件夹。 如果脚本在D:\Projects\OCR_Rename,则输入:bashcd D:\Projects\OCR_Rename或者在你的脚本所在的文件夹地址栏中输入 cmd 后按回车键即可
4.3 说明与注意事项
- 首次运行会自动下载模型文件(约 50-80MB),需要网络。
- 识别准确率不高的情况
- 原因:图片质量差、文字过于潦草、背景复杂。
- 解决 :
- 预处理图片:在运行脚本前,可尝试用图像软件调整对比度、裁剪掉多余背景。
- 调整识别语言 :如果图片中包含繁体字,可尝试修改脚本第 38 行,将
['ch_sim']改为['ch_tra'](繁体)或['ch_sim','ch_tra'](简繁混合)。 - 手动复核:对于重要资料,建议对识别结果进行人工复核。
现在,我们已成功使用"书法单字图片批量重命名工具"完成了自动化命名。所有图片文件现在都有了清晰的中文名称,极大方便了后续的整理、检索和研究。
