各位读者大家好,进公司一年了,很久没写文章了,最近ai提效搞的很火,相信大家公司也一定有很多ai提效的经验,这里哈士奇也简单做了一个ai提效的工具,给大家分享一下思路,大家如果有其他经验也欢迎和哈士奇分享。
每次迭代封版,前端开发都要手写一份"这版改了什么、影响哪些功能、测试该回归哪些点"的清单交给测试。这件事重复、耗时,还容易漏。
我们把它交给了 AI------开发 push 一次代码到迭代分支,CI 流水线自动跑完,产出一份这样的报告:
业务功能影响:订单列表页的分组树右键菜单,"批量导出"的显示条件放宽了,被授予"订单导出"权限的用户现在也能看到。
测试用例:用只有"订单导出"权限、没有树操作权限的账号 → 右键分组树节点 → 能看到"批量导出"项 → P0
风险提醒:前端放宽了入口,但后端导出接口的鉴权未同步检查,可能出现"前端能点、后端拒绝"或"前端遮挡、接口可绕过"的不一致。
带 P0/P1/P2 优先级、操作和预期都具体可执行、还能一键复制进 Excel / TestRail。测试拿到就能直接排回归,不用再追着开发问"这版到底动了啥"。
这篇文章讲的,就是我们怎么把一条 CI 流水线 + 一个 AI 工作流 调教成稳定产出这种报告的系统。中间有三个真正花心思的点:怎么让 AI 输出测试真能照着做的影响范围、在"CI 变量不属于自己"的中转流水线里怎么算准增量 diff、大 diff 撞上 prompt 上限时怎么分层裁剪。最后附上几个排查了好几轮才定位的真实坑。
一、问题:人工梳理影响范围,又慢又漏
每次迭代封版前,前端开发要对着自己这版的改动,整理一份"影响了哪些页面、哪些功能、测试该回归哪些点"的清单交给测试。靠人写,有三个绕不开的问题:
- 慢:每次封版都得手写一遍,改动一多就是小半天。
- 漏:人凭记忆梳理,公共组件的连带影响、跨页面的关联改动,经常想不全。
- 不可执行:开发写的常是"调整了订单状态逻辑"这种粗结论,测试拿到还得自己翻译成"打开哪个页面、点哪里、看什么变化",等于只做了一半。
我们想用 AI 接管这一步:直接吃 git diff,自动产出影响范围报告。技术上,"调用大模型分析一段 diff"今天谁都会写,真正难的是让产出达到能直接用的质量------这恰好对应人工梳理的三个痛点:
- 覆盖要全:几十个文件的改动,不能分析着分析着就漏了后面一半(对应第三节,大 diff 怎么不丢文件)。
- 范围要准:得算清楚"这次到底新增了哪些改动",多算少算都会让测试白跑或漏测(对应第二节,增量 diff 怎么算准)。
- 结果要可执行 :每条都得是测试能照着点、能在界面上验证的具体操作和预期,而不是开发视角的粗结论或一句"建议全面测试"(对应下一节,怎么约束 AI 的输出)。
这三件事做好了,AI 才能真正替代人工那一步,而不是产出一份"看着像那么回事、测试却用不上"的报告。
二、整体架构
整个系统跑在一条中转 CI 流水线上(为什么是"中转",第三节会展开)。流程不复杂:
核心是三个 Node 脚本,各管一件事:
| 脚本 | 职责 |
|---|---|
glossary-bootstrap.js |
扫路由表,生成"代码路径 → 业务名称"的术语字典 |
generate-report.js |
收集 git 变更 → 组装 prompt → 调 AI 工作流 → 出 report.md |
md-to-html.js |
把 markdown 报告转成带样式的单文件 HTML |
值得一提的是分工:"每次都一样的内容"(报告格式、硬规则、输出约束)放在 AI 工作流平台的 system prompt 里维护,Node 脚本只负责组装"每次都不一样的动态内容"(diff、commit 列表、术语字典)。这样改报告格式不用动代码重新部署,改 prompt 就行。
三、三个核心技术点
对应第一节的三个痛点,系统真正花心思的地方也是三个:怎么让 AI 的输出测试真能照着做、中转流水线下怎么算准 diff 范围、大 diff 怎么塞进有限的 prompt。下面逐个拆。
1. 怎么让输出"测试能直接照着做"
这是全文最有价值的部分。模型默认会站在开发视角写------"LoginHeader 的 props.type 多了个枚举值",这话对测试毫无用处。要让产出可执行,我们在 prompt 里写死了三层约束:把代码标识翻译成业务说法、给每条用例配具体的操作和预期、翻不出业务价值的改动直接不写。
第一层:把代码标识翻译成业务说法
报告的读者是测试,组件名、文件路径、API、CSS 类名这些对他们全是噪音。所以 prompt 里有一张硬规则表,把代码世界的标识分成七类,每类都给了"换成什么":
| 类型 | 禁写示例 | 换成 |
|---|---|---|
| 组件类名 | a-tag / LoginHeader |
"状态标签" / "登录头部" |
| 文件路径 | pages/Login |
"登录" |
| API 路径 | /api/Login/login-create |
"创建登录"或直接省略 |
| 函数/变量 | colorMap / renderStatus |
描述效果,不写名字 |
| CSS 类名 | .a-tag-red |
"红色标签样式" |
| 依赖库名 | vuedraggable |
"拖拽"(读者不关心怎么实现) |
| 钩子/生命周期 | onMounted / onBeforeUnmount |
描述时机("进入页面时"/"关闭页面时") |
配一组正反对照,让模型知道边界在哪:
不合格:"
pages/Login的LoginActionBar加了拖拽"合格:"登录页底部的操作栏现在可以拖动位置"
光有禁写规则不够,模型还得知道正确的业务名从哪来。我们定了一条优先级链:
- 术语字典命中 → 直接用字典里的业务名(字典怎么来,见下一节)
- 字典未命中 → 看 diff 上下文(同目录文件命名、注释、commit message)推断
- 仍推断不出 → 输出时加"(推测,请开发校正)"
- 实在太底层、找不到对应业务名 → 说明它根本不该出现在给测试看的报告里,整段删掉,而不是硬翻一个出来
第 4 条很关键。很多人做这种总结会让模型"尽量翻译",结果逼出一堆生造的业务名误导测试。我们的态度是:翻不出来就别写,宁缺毋滥。
翻译流程的优先级
光有禁写规则不够,模型还得知道正确的业务名从哪来。我们定了一条优先级链:
- 术语字典命中 → 直接用字典里的业务名(字典怎么来,见下一节)
- 字典未命中 → 看 diff 上下文(同目录文件命名、注释、commit message)推断
- 仍推断不出 → 输出时加"(推测,请开发校正)"
- 实在太底层、找不到对应业务名 → 说明它根本不该出现在给测试看的报告里,整段删掉,而不是硬翻一个出来
第 4 条很关键。很多人做这种总结会让模型"尽量翻译",结果逼出一堆生造的业务名误导测试。我们的态度是:翻不出来就别写,宁缺毋滥。
术语字典从哪来:AST 扫路由表
字典是这套系统里最"工程化"的一环。glossary-bootstrap.js 在流水线早期跑一次,用 @babel/parser 解析路由文件,把路由表里的 component → meta.title 映射抽出来,生成"组件路径 → 业务名"的字典。
关键有两点。
第一,按 children 层级拼出完整业务路径。 路由是嵌套的,单看一级菜单不够,得拼成"主页 / 登录页 / 登录者列表"这种带层级的名字,测试一看就知道在哪个页面:
js
// 递归遍历路由数组,提取 { 组件路径 → 中文业务名(含层级) }
function walkRoutes(arrayNode, parentTitle, routerDir, srcDir, i18nTable, out) {
if (!arrayNode || arrayNode.type !== "ArrayExpression") return;
for (const el of arrayNode.elements) {
if (!el || el.type !== "ObjectExpression") continue;
const metaNode = getProp(el, "meta");
const title = resolveTitle(metaNode, i18nTable); // 中文或 null
// 当前层级标题:本级无中文则沿用父级
let curTitle = parentTitle;
if (title) {
curTitle = parentTitle ? parentTitle + " / " + title : title;
}
// 收录本路由(组件路径存在 且 本级有中文标题)
const compNode = getProp(el, "component");
const importPath = compNode ? extractComponentPath(compNode) : null;
if (importPath && title) {
const resolved = resolveComponentPath(importPath, routerDir, srcDir);
if (resolved) out[resolved] = curTitle;
}
// 递归 children
const childrenNode = getProp(el, "children");
if (childrenNode && childrenNode.type === "ArrayExpression") {
walkRoutes(childrenNode, curTitle, routerDir, srcDir, i18nTable, out);
}
}
}第二,meta.title 经常不是中文字面量,而是 i18n key。 比如 meta: { title: $t('login.detail') },AST 拿到的是 $t('login.detail') 这个 key,不还原就成了字典里的乱码。所以我们需要加载 app 的 zh-CN 语言包,命中 key 时回查中文:
js
// 从字符串字面量 / $t() 调用节点解析出中文,拿不到返回 null
function resolveStringNode(node, i18nTable) {
if (!node) return null;
if (node.type === "StringLiteral") {
return CJK_RE.test(node.value) ? node.value : null; // 仅中文直采
}
// $t('ns.key') / t('ns.key') → 回查 i18n 表
if (
node.type === "CallExpression" &&
node.callee &&
(node.callee.name === "t" || node.callee.name === "$t") &&
node.arguments[0]?.type === "StringLiteral"
) {
const zh = i18nTable[node.arguments[0].value];
return zh && CJK_RE.test(zh) ? zh : null;
}
return null;
}自动提取是兜底,覆盖路由能覆盖到的页面。路由里没有的业务组件(比如某个公共弹窗),靠手写字典补充。手写字典优先级更高,同 key 覆盖自动提取的结果。手写字典就是一个普通 JSON:
json
{
"apps/xxx/src/pages/index.vue": "首页",
"apps/xxx/src/pages/LoginList/index.vue": "登录列表",
"apps/xxx/src/pages/LoginList/LoginDetail.vue": "登录列表 / 登录详情",
}最终这份字典作为 # 术语字典 段落拼进 prompt,模型按上面的优先级链使用。
第二层:每条用例都要"能照着点"
翻译解决了"看得懂",但测试要的是"照着做"。所以 prompt 对测试用例的格式和内容都下了硬约束:
- 操作必须具体可执行:写"打开任一待支付订单的详情页",而不是"测试订单状态"。
- 预期必须具体可观察:写"顶部标签显示为橙色",而不是"显示正常"。
- 必带优先级,且分层明确:P0 = 正向主流程,P1 = 关联路径 / 公共改动的主要场景,P2 = 边界 / 负向场景,每个优先级至少一条。
- 数量跟改动规模挂钩 :几百行的改动 12
30 条,上千行 3050 条,再大就更多------避免大改动只配三五条用例敷衍。 - 影响点和用例一一对应:业务影响章节里列出的每一条,都必须有对应的测试用例,不允许"提了影响却没有用例"。
这几条约束的作用,是把模型从"我来总结一下这次改了啥"逼到"我来告诉你测试该怎么点、点完该看到什么"。
第三层:翻不出业务价值的改动,直接不写
最后一类改动需要主动丢弃:只动了配置文件、构建脚本、CI 文件、依赖版本------测试在界面上根本观察不到任何变化。
prompt 里明确写了这条规则:这类改动整段不写进报告,不要为了凑数写"前端构建配置有改动,建议冒烟测试"。工程化改动的回归靠 CI 自己跑通就够了,写进给测试看的报告纯粹是噪音。
翻译、可执行、不凑数------三层叠起来,AI 才从"会总结 diff"变成"产出测试真能用的影响范围"。
模型提示词(仅供参考)
markdown
你是一个资深测试工程师。用户会传入一份代码改动(git diff + commit 列表 + 可选术语字典),
你需要分析其测试范围,并按下面格式输出"代码影响范围报告"。
# 报告结构(严格按此格式输出,不要任何额外说明、不要 <think> 推理块、不要"以下是报告"前缀)
## 业务功能影响
- 用 bullet 列出每个业务影响点,每条一个
- 多处同构改动合并叙述(写"这类改动同时影响 X、Y、Z",而非重复三条)
## 测试用例
| # | 用例标题 | 操作 | 预期 | 优先级 |
|---|---|---|---|---|
## 建议回归测试点
[与测试用例互补的策略级提示,2-4 条]
## 风险提醒
[每个风险点 + 具体建议]
# 硬规则
1. 测试用例优先级:
- P0 = 正向主流程
- P1 = 关联路径 / 公共改动的主要场景
- P2 = 边界 / 负向场景
- 每个优先级至少 1 条
2. 数量自适应:
- > 小于500 行 → 12~30 条(按照0~500行的比例增加数量)
- > 1000 行~3000行 → 30~50 条(按照1000~3000行的比例增加数量)
- > 3000 行以上 → 50以上(用例越多越好)
3. 操作描述具体可执行:写"打开任一待支付订单的详情页"而非"测试订单状态"
4. 预期具体可观察:写"顶部标签显示为橙色"而非"显示正常"
5. 推测性结论末尾加"(推测)"
6. 不出现任何 diff 或代码片段
7. 保证测试用例尽量全面
8.同一模块内不同功能点(如"订单的操作记录"和"退款的操作记录")算独立影响点,
不得合并。只有"完全相同的改动复制到多处"才允许合并叙述。
9.测试用例必须覆盖"业务功能影响"章节里列出的每一条影响点。不允许存在"有影响但没有对应测试用例"的情况。
10.commit 列表中的每个 commit message 都代表一个独立改动意图。
# 输出淘洗(最重要,违反任何一条都判定为不合格)
测试同学读不懂代码。报告里不准出现以下任何代码世界的标识------必须翻译成业务说法:
| 类型 | 禁写示例 | 换成 |
|---|---|---|
| 组件类名 | a-tag / LoginHeader | "状态标签" / "登录头部" |
| 文件路径 | apps/xxx/src/pages/Login | "登录" |
| API 路径 | /api/Login/login-create | "创建登录"或直接省略 |
| 函数/变量/常量 | colorMap / renderStatus | 描述效果,不写名字 |
| CSS 类名 | .a-tag-red | "红色标签样式" |
| 依赖库名 | vuedraggable / sortablejs | "拖拽"(读者不关心怎么实现) |
| 钩子/生命周期 | onMounted / onBeforeUnmount | 描述时机("进入页面时"/"关闭页面时") |
## 翻译流程
1. 用户输入里如果带了"# 术语字典"章节,**优先按字典翻译**
2. 字典未命中 → 看 diff 上下文(同目录文件命名、注释、commit message)推断业务名
3. 仍无法推断 → 输出时加"(推测,请开发校正)"
4. 如果一个代码标识"实在找不到对应业务名",说明它太底层,**根本不该出现在给测试看的报告里** ------ 整段删掉,而不是保留
## 违规对照
不合格:"LoginHeader.vue 中的 colorMap 改了,a-tag 组件的颜色会变化"
合格:"登录页头部的标签颜色变了"
不合格:"apps/xxx/src/pages/Login 的 LoginActionBar 加了拖拽"
合格:"登录页底部的操作栏现在可以拖动位置"
不合格:"/api/Login/login-create 新增了字段校验"
合格:"创建登录时会多一层字段校验"
## 兜底策略:纯工程化改动整段删除
如果某个改动只是"动了某个配置文件 / 构建脚本 / CI 文件 / 依赖更新",
且测试无法在界面上观察到任何变化,则**这条改动整段不写进报告**。
不要为了凑数写"前端构建配置有改动,建议冒烟测试"这种条目------
工程化改动的回归靠 CI 自己跑通就够了,写进给测试看的报告纯粹是噪音。
只保留测试**能在 UI 上感知**的改动。
# 推测标注规则
以下场景,对应条目末尾加"(推测)":
- 基于文件名/路径推断业务用途,但没看到注释或路由定义证实
- 基于 commit message 推测影响范围,但没看到具体代码逻辑
- 推理"可能影响 X" 但 diff 里没直接证据
推测不标注 = 误导测试,比不写还糟。
# 禁止事项
- 禁止建议测试"所有相关页面"、"整个模块"这种笼统范围
- 禁止在风险提醒里堆砌通用建议("建议全面测试")
- 禁止把 commit message 内容直接复制到业务功能影响章节(那是开发视角,不是测试视角)
- 禁止在报告里出现 code diff
- 禁止任何前缀("好的,收到"、"以下是报告"、"作为资深测试工程师")------ 直接给 markdown2. 中转流水线下,diff 范围怎么算准
先解释"中转流水线"是什么:出于 runner 权限隔离,我们的报告生成不直接在项目仓库的 CI 里跑,而是由一个独立的"中转项目"流水线触发,它克隆目标仓库后再分析。
这个架构带来一个反直觉的大坑。
核心矛盾:CI 变量不属于自己
中转流水线里那些熟悉的 CI 变量------CI_COMMIT_SHA、CI_COMMIT_BEFORE_SHA、GITLAB_USER_NAME------全是中转项目自己的值,跟我们要分析的目标仓库毫无关系:
CI_COMMIT_BEFORE_SHA是中转项目的旧 SHA,拿它做目标仓库的 diff 范围毫无意义GITLAB_USER_NAME是触发中转流水线的人,不一定是代码提交者CI_MERGE_REQUEST_IID在 push 流水线里为空
解法是:凡是跟目标仓库相关的信息,全部从克隆下来的本地 git 取,一个 CI 变量都不信:
js
// 分支名从本地 git 取
const branch = execSync("git rev-parse --abbrev-ref HEAD").trim();
// HEAD SHA 从本地 git 取
const headSha = execSync("git rev-parse HEAD").trim();
// 作者从本地 git log 取,而不是 GITLAB_USER_NAME
const author = execSync("git log -1 --format=%an HEAD").trim();增量 diff:用 Events API 查上次 push 的起点
我们不想每次都做 origin/main..HEAD 的全量 diff------太大,而且测试只关心"这次 push 新增的改动"。要算增量,得知道"上次 push 到这个分支时的起点 SHA"。
由于 CI_COMMIT_BEFORE_SHA 不可用,我们改查 GitLab 的 Events API,从目标仓库自己的 push 事件里找。这里踩过一个坑:直接在 URL 里加 action=pushed 过滤,某些 GitLab 版本对 token 可见的事件类型有限制,返回空数组。
最终改成全量取回事件 + 代码里精确匹配 ------靠 push_data 的字段命中,而不是靠 action 字符串:
js
for (const ev of events) {
const pd = ev && ev.push_data;
if (!pd) continue;
// 匹配:这条 push 事件的目标 SHA == 当前 HEAD,且 ref == 当前分支
if (pd.commit_to !== currentSha) continue;
if (pd.ref !== branchName) continue;
const before = pd.commit_from;
if (!before || /^0+$/.test(before)) return null; // 全 0 是首次 push
return before;
}三层验证链:查到 SHA 不等于能用
查到 before SHA 只是第一步。浅克隆(--depth=50)+ 可能的 force push,让这个 SHA 随时可能"不可达"或"已脱链"。所以拿到它之后还要过三道关,任何一道挂了就回退到全量 diff:
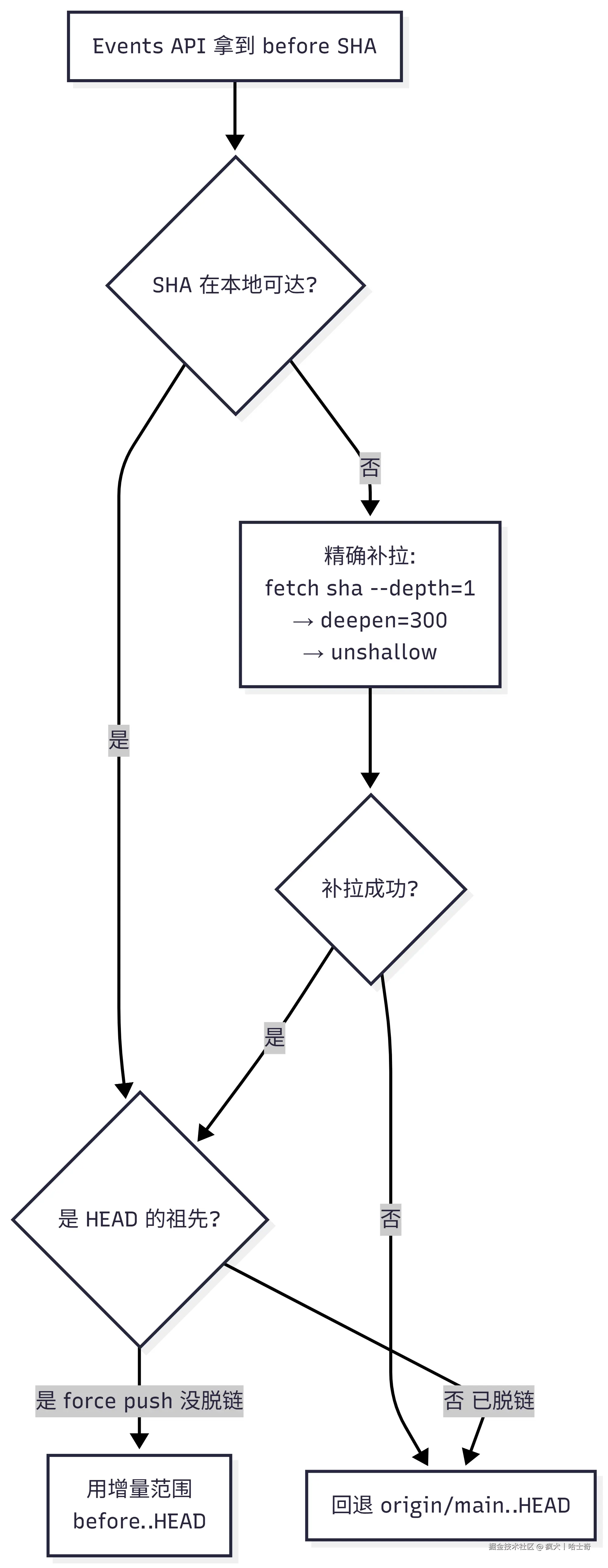
- 可达性 :
git cat-file -e <sha>验证对象存在。注意别用git rev-parse <sha>^{commit}------花括号在 Windows shell 下会被破坏,判定恒失败。 - 补拉 :不可达时优先
git fetch origin <sha> --depth=1精确补这一个对象,比--deepen可靠(deepen 只延伸当前 tip 的历史,base 若已脱离 tip 历史就补不到)。 - 祖先校验 :
git merge-base --is-ancestor <sha> HEAD。force push / rebase 后旧 SHA 会脱链,不是 HEAD 祖先,这时用它做 diff 起点结果是错的,必须回退。
这套验证链看着繁琐,但它保证了一件事:宁可退化成全量 diff,也绝不产出一个范围算错的报告。
3. 大 diff 撞上 prompt 上限怎么办
AI 工作流平台的长文本输入变量有上限(我们这里约 100KB)。大型迭代几十个文件、几十 KB 的 diff,加上术语字典和上下文,很容易超限。
最早的做法是简单粗暴:diff 截断到 50KB。问题立刻暴露------排在后面的几十个文件直接消失了,模型完全不知道它们存在,报告自然漏掉。
新方案是三层分层裁剪,核心思路是"保证每个文件至少在清单里露脸",再按业务优先级把有限的预算花在刀刃上。
同时由于我们每一次提交不太可能大于这么多行,所以基本上是不太存在超出的情况。
先给每个文件按业务重要性分类:
js
function classifyFile(filepath) {
// 业务组件最重要
if (/\.(vue|tsx|jsx)$/.test(filepath)) return "core";
// 业务逻辑次之(排除测试/配置/声明文件)
if (/\.(ts|js)$/.test(filepath)) {
if (/\.(test|spec|config|d)\./.test(filepath)) return "low";
return "high";
}
// 样式
if (/\.(scss|less|css)$/.test(filepath)) return "medium";
// 配置、lock、构建产物
if (/\.(json|ya?ml|lock|md)$/.test(filepath) ||
filepath.includes("dist/")) return "low";
return "medium";
}然后按优先级分配 65KB 预算,三层处理:
- 全景清单 :所有改动文件每个一行(优先级 + 改动行数 + 路径),约占 3-5KB。再大的改动,每个文件都在清单里。
- 关键文件完整 diff :
core/high文件完整保留,但单文件上限 15KB(防止单个超大文件吃光预算)。 - 次要文件摘要 :
medium文件只提取关键行------函数定义、export、组件声明,最多 30 行。low文件只记文件名,不取 diff。
这样即使某个文件的 diff 被裁掉了,它仍在全景清单里,模型能结合 commit 列表推测它的改动意图,并在报告里标"(推测)"。比起"后面文件直接消失",信息完整度高了一个量级。
四、几个排查了好几轮的坑
实现过程踩了十几个坑,这里挑三个最有共性、读者能直接迁移经验的。
坑 1:token "有值"不等于"有效"------一次被表象误导好几轮的排查
这是最值得写的一个。
现象 :流水线原本用 SSH 克隆目标仓库,只有特定人触发能成功,别人触发就 clone 失败。为了让所有人都能跑,把 clone 改成 HTTPS + token(https://oauth2:$TOKEN@...)。结果更糟------所有人触发都报 HTTP Basic: Access denied,全挂了。
排查过程被表象误导了好几轮,逐一排除:
- 误判一:跨项目权限。 以为 token 对目标仓库没权限。查 token 配置(read_api、read_repository、Reporter 角色、有效期到 2032),权限本身没问题。
- 误判二:项目改名。 项目显示名改过,一度以为要把 clone 地址换成新名。实测换了反而报
not found------证明 URL 路径(slug)没变,改的只是显示名,git 地址不受影响。改回去。 - 误判三:runner 变量为空。 换了 runner 机器,怀疑变量没注入。加
echo "length: ${#TOKEN}"自检,输出length: 49------变量有值,排除为空。
关键认知 :length: 49 只能证明"变量有值",证明不了"值有效"。一个已被 revoke 的旧 token,长度同样是 49。当时 token 列表里有好几个同名的、已 revoked 的旧 token,CI 变量里存的恰好是其中一个失效的值。
根因:SSH 时代靠 runner 机器本地的 SSH key 鉴权(所以表现为"看人、看机器");改成 HTTPS + token 后,鉴权完全取决于这个变量的值,而它恰好是个失效 token,于是全员 denied。换成有效 token 后 clone 立即成功。
教训:
- 鉴权失败,先验证 token "是否有效" ,而不是只看"是否有值"。
${#VAR}长度自检只能排除为空,验不出失效。最快的定死方式是本地用同一个 token 跑一次 clone。 - 报错会"分层":上层关卡(token)没过时,看不到下层问题。token 修好后立刻暴露了下一层错误(分支 ref 解析)。修好一层暴露下一层,不要因为报错变了就以为引入了新 bug。
坑 2:网关 keep-alive 导致 HTTP 请求永久挂起
现象:调用 AI 工作流 API 时,偶尔请求永久挂起,不返回也不报错。
根因 :网关在 keep-alive 模式下,chunked transfer 的终止符发不全,导致 Node 的 res.on('end') 永远不触发,整个请求永久卡住。
解法 :强制关闭长连接 + 加一道 close 事件兜底:
js
// 强制 Connection: close + 禁用 keepAlive agent
const finalHeaders = Object.assign({ Connection: "close" }, headers);
const req = mod.request({ /* ... */ agent: false, headers: finalHeaders }, (res) => {
const chunks = [];
let resolved = false;
res.on("data", (c) => chunks.push(c));
res.on("end", () => {
if (resolved) return;
resolved = true;
resolve({ statusCode: res.statusCode, body: Buffer.concat(chunks).toString() });
});
// 兜底:连接关闭但 end 未触发时也认为完成
res.on("close", () => {
if (resolved || chunks.length === 0) return;
resolved = true;
resolve({ statusCode: res.statusCode, body: Buffer.concat(chunks).toString() });
});
});
req.setTimeout(180000, () => req.destroy(new Error("HTTP 请求超时")));调用第三方 AI 服务时,Connection: close + close 事件兜底 + 超时销毁,这套组合能挡掉大部分网关层的诡异挂起。
坑 3:Windows runner 上的两个环境兼容问题
中转流水线早期跑在 Windows runner 上,撞了两个跨平台问题:
- 管道 buffer 溢出 :
execSync('git diff ...')直接取输出,diff 一大就截断或报错------Windows cmd 管道 buffer 默认很小。解法是先写临时文件再fs.readFileSync(tmp, 'utf-8')读回(顺便用utf-8强制读取,避免 GBK 把中文文件名解成乱码)。 - 老 Node 不支持新语法 :早期版本依赖某个 SFC 解析库,它用了老 Node 不支持的 class field 语法(
#privateField),直接报语法错误。解法是砍掉这个重依赖,用正则手搓<route>block 的提取------少一个依赖,多一份兼容。
五、报告长什么样
最后一步,md-to-html.js 把 markdown 报告转成单文件 HTML。这里有个值得一提的设计:两段式渲染。
- 服务端(markdown-it):解析 markdown,生成标题锚点、表格、列表等基础结构,注入到内联了完整 CSS 的模板里。
- 客户端(内联 JS,浏览器加载时执行) :对 DOM 做视觉增强------按
h2把扁平结构分组包进卡片、按标题关键词匹配 emoji 图标(业务🎯 / 用例🧪 / 回归🔁 / 风险⚠️)、把单元格里的P0/P1/P2文本渲染成彩色徽章、加"一键复制测试用例"按钮(提取表格为 TSV,可直接贴进 Excel / TestRail)。
截图: 报告 HTML 页面渲染效果------渐变头部卡片 + 优先级彩色徽章 + 章节卡片化
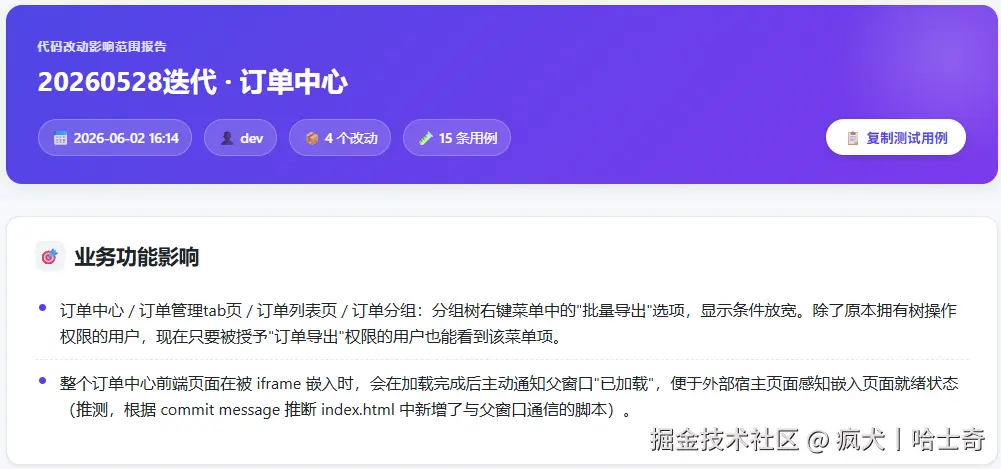
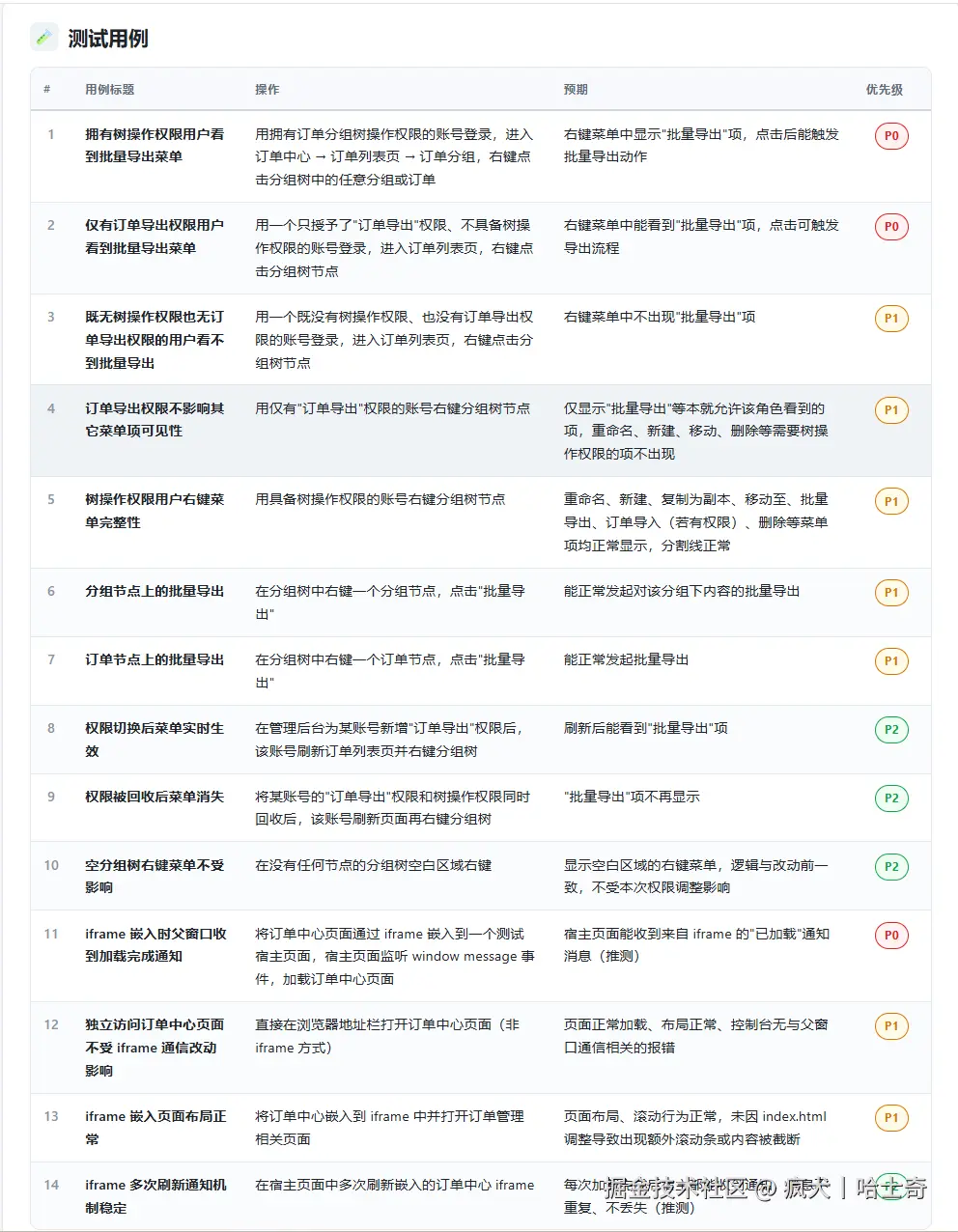

一个值得记下的坑:因为卡片化和徽章渲染依赖客户端 JS,如果下游用纯静态 HTML 解析(不执行 JS),看到的是未分组的扁平结构和纯文本优先级。所以无头浏览器截图 / 转 PDF 时,要确保 JS 已经执行完。
六、经验总结
这套系统跑下来,沉淀几条可复用的经验:
- 给非技术读者看的 AI 报告,要在 prompt 里写死"输出淘洗"硬规则,而不是指望模型自觉。 明确列出禁写的标识类型 + 正反对照,比一句"请说人话"管用得多。
- 业务术语字典优先靠路由表 + i18n 自动生成,AST 能覆盖大部分页面;手写字典只补自动提取不到的,且优先级更高。
- 在中转/受限 CI 环境里,凡是
CI_*变量先确认"属不属于自己"。 不属于自己的,全部从本地 git 重新取。 - 鉴权失败,先验 token 的有效性(本地跑一次 clone),别只看长度。 长度只能排除为空,验不出失效。
- 大 prompt 用分层裁剪,而不是一刀切截断。 全景清单保证每个文件露脸,预算花在高优先级文件上。
- 调第三方 AI 服务,
Connection: close+close事件兜底 + 超时销毁,挡掉网关层的诡异挂起。
核心其实就一句话:让 AI 干活不难,难的是让它的产出真正贴合读者------这中间的每一道翻译、裁剪、兜底,才是这套系统的价值所在。