
计算机是现代生活与编程学习的基础,而操作系统更是连接硬件与软件的核心桥梁。想要真正明白程序如何运行、系统如何工作,就需要从底层原理开始了解。本文将带大家循序渐进认识操作系统相关知识,理清计算机运行逻辑,读懂进程、系统调用等基础概念,帮助我们更清晰地理解计算机工作本质。

1. 冯・诺依曼体系结构:计算机的骨架
冯・诺依曼体系是现代计算机的底层逻辑,它定义了计算机的五大核心部件和数据流动规则,也是我们理解操作系统的基础。
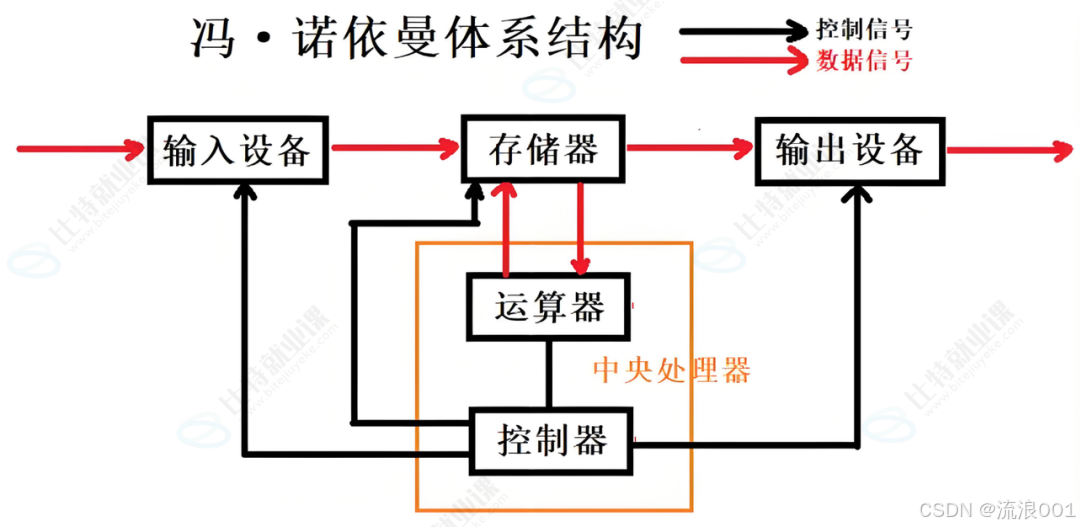
核心组成
•输入设备 :键盘、鼠标、网卡、摄像头等,负责将数据传入计算机
•输出设备 :显示器、声卡、打印机等,负责将数据从计算机传出
•存储器(内存 ):数据的临时中转站,CPU 只能直接与内存交互
•运算器 :负责算术和逻辑运算,是 CPU 的计算核心
•控制器:指挥协调各部件工作,控制指令的执行流程
关键规则
•程序必须先加载到内存:软件运行的前提是程序从磁盘加载到内存,这是体系结构的硬性规定。
•CPU 只和内存打交道 :运算器和控制器仅能直接访问内存,外设与内存之间的数据交互由操作系统协调完成。
•数据流动的本质是 "拷贝":数据从一个设备到另一个设备,本质上是在不同存储介质间的复制过程。
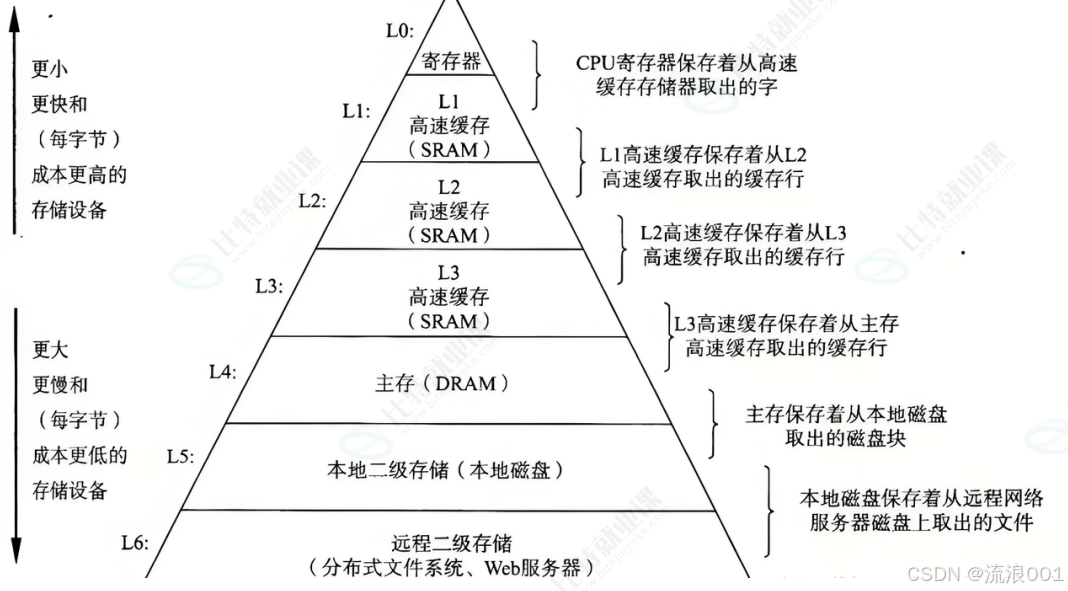
性能视角的理解
计算机的性能瓶颈,本质上由设备的 "带宽" 决定:
寄存器 > 高速缓存 > 内存 (存储器)> 磁盘 / 外设,速度从上到下递减,成本也随之降低。操作系统的核心工作之一,就是通过调度 和缓存,尽量让数据在高速设备中停留,减少低速 IO 的等待。
2. 操作系统:软硬件之间的 "大管家"
操作系统(OS) 是一组管理软硬件资源的程序集合,它是硬件的管理者,也是上层软件的服务提供者。
核心组成
•狭义的操作系统 :内核,负责进程管理、内存管理、文件管理、驱动管理四大核心功能
•广义的操作系统:内核 + 外壳程序(如 shell) + 系统调用 + 系统库 + 第三方工具
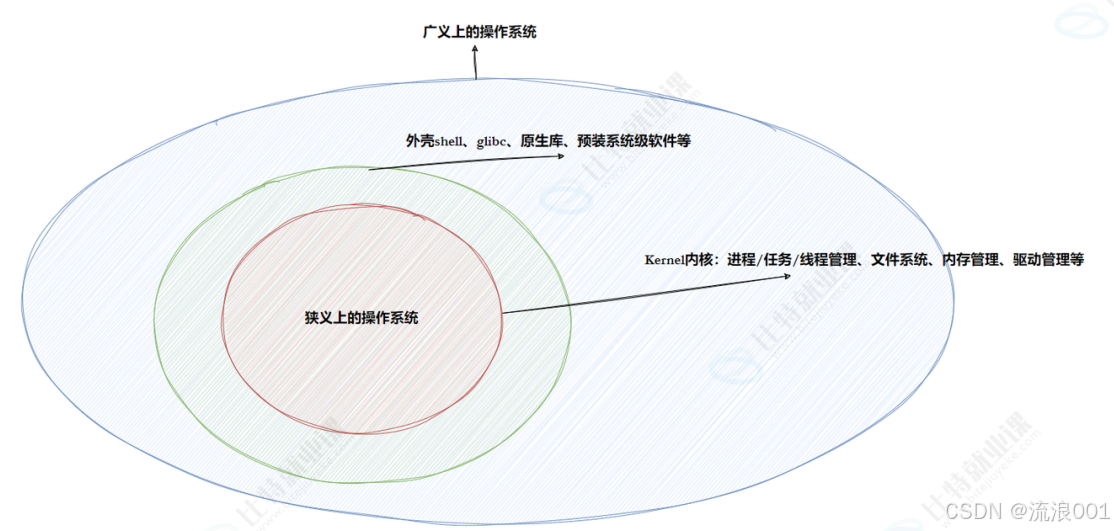
例如我们现在使用的安卓系统,它就是用Linux内核加外壳(shell)包装得到的
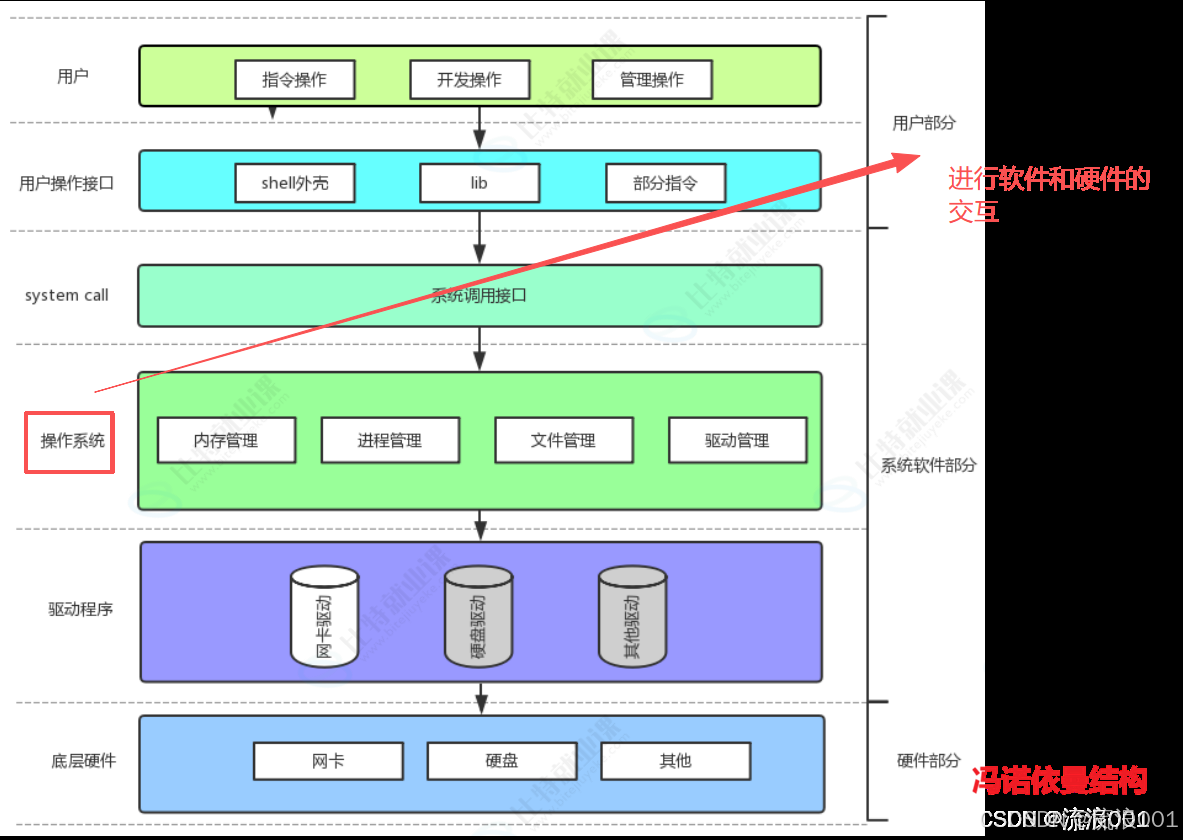
设计 OS 的核心目的
•对下管理硬件:统一管理 CPU、内存、磁盘、外设等资源,解决多程序竞争资源的冲
突问题
•对上提供服务 :为用户和应用程序提供稳定、安全、易用的接口,屏蔽硬件底层的复杂细节
•提高资源利用率:通过合理调度,让 CPU 和 IO 设备尽可能并行工作,减少资源闲置
1.简单故事介绍:
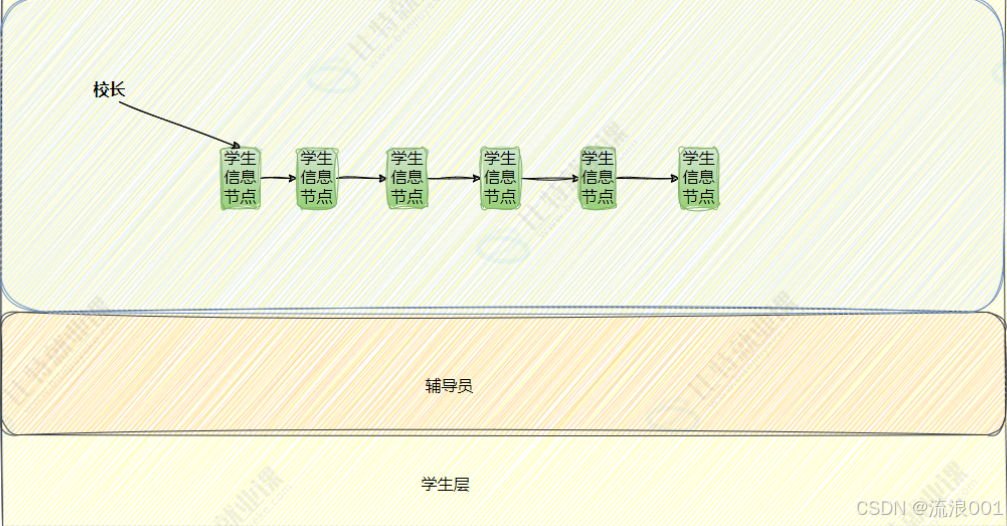
我们可以用一个校园故事,把校长 、辅导员 、学生和操作系统的管理逻辑完整串起来:
清晨的校园里,校长(操作系统内核) 坐在办公楼里,制定着全校的资源规则与调度秩序,手里握着分配教室、图书馆、网络和水电的最终决定权,保证学校的一切资源都不会被滥用。辅导员(系统服务 / 中间层) 则守在教学楼,接收学生们的各种申请。学生(应用进程) 们带着自己的目标来上课、自习、开班会 ------ 他们需要教室(CPU 时间) 、座位(内存) 、黑板(显示设备) 和网络接口(外设),但谁也不能直接闯入校长办公室,只能先向辅导员提交申请。
我们可以把这张图的管理逻辑,用操作系统的视角串成一个完整的故事:
校长 就像操作系统内核 ,只需要握着第一个学生信息节点的地址,就能通过这条单向链表,遍历并管理全校所有学生;辅导员 则像内核里的进程调度模块 ,负责维护这条链表的日常更新 ------ 新生入学就创建新节点(结构体) 并链入链表,学生毕业就摘除节点,学生状态变化就更新节点信息;而最底层的学生 ,就像一个个应用进程,只需专注自身任务,所有管理操作都通过辅导员和节点完成,内核无需直接接触每个学生,就能高效完成对全校资源与秩序的管控。
2.总结
计算机硬件:
1.先描述:用struct
2.再组织起来:用链表或其它高效的数据结构
3.系统调用和库函数
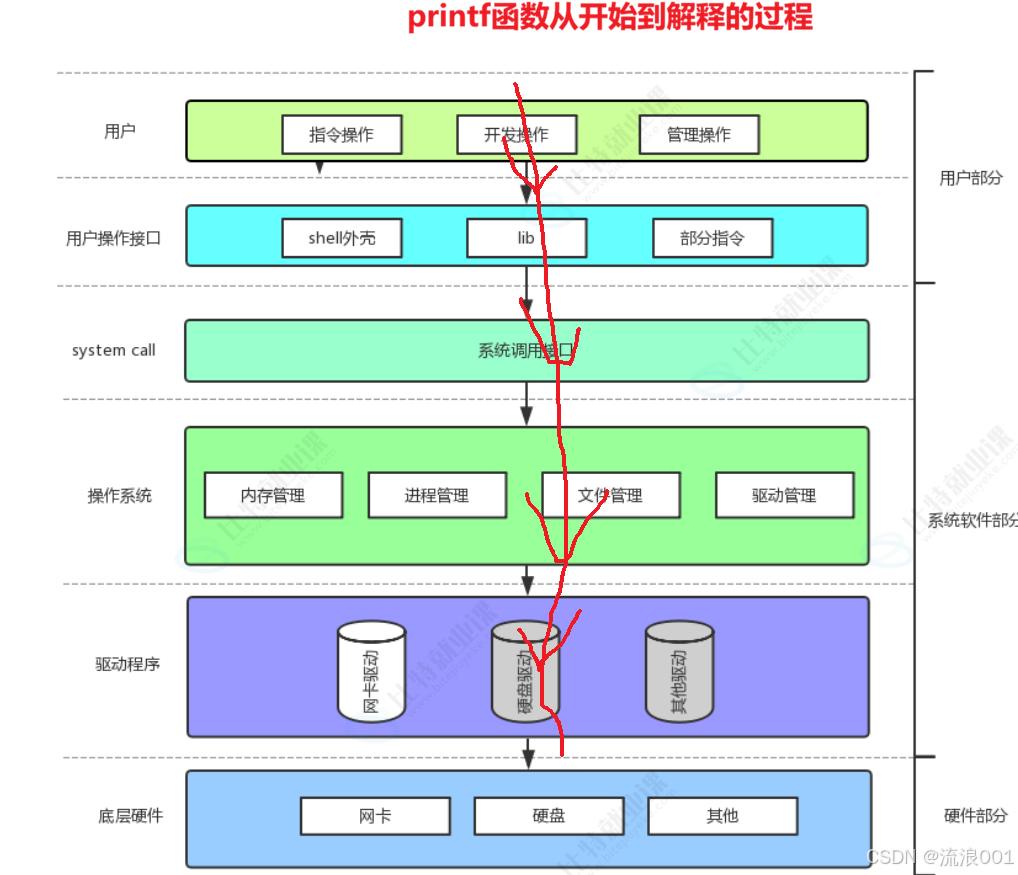
操作系统为了安全,将运行空间分为用户态 和内核态 ,用户程序无法直接操作硬件,必须通过系统调用向内核发起请求。
1.通俗理解:银行柜台模型
- 用户程序就像银行客户,操作系统内核就像银行柜台
- 客户不能直接进入金库操作,必须通过柜台(系统调用)办理业务
- 系统调用是用户态进入内核态的唯一入口,也是操作系统提供给用户的服务接口

2.系统调用与库函数的关系
库函数(如 C 标准库)是对系统调用的封装,为用户提供更易用的接口
例如,printf()最终会调用write()系统调用,将数据输出到标准输出设备
库函数运行在用户态,系统调用会触发用户态到内核态的切换
4. 进程:程序运行的动态实体
程序是存储在磁盘上的静态文件,而进程是程序运行起来后,在内存中的动态实体
1.进程的核心定义
•进程 = 程序代码 + 数据 + 进程控制块(PCB)
•每个进程都有自己独立的地址空间,包括代码段、数据段、堆栈段
•操作系统通过struct task_struct(Linux 下的 PCB)来描述和管理进程
2.进程控制块(PCB)内容分类
•标示符 : 描述本进程的唯一标示符,用来区别其他进程。
•状态 : 任务状态,退出代码,退出信号等。
•优先级 : 相对于其他进程的优先级。
•程序计数器 : 程序中即将被执行的下一条指令的地址。
•内存指针 : 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
•上下文数据 : 进程执行时处理器的寄存器中的数据。
•I/O 状态信息 : 包括显示的 I/O 请求,分配给进程的 I/O 设备和被进程使用的文件列表。
•记账信息 : 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
•其他信息
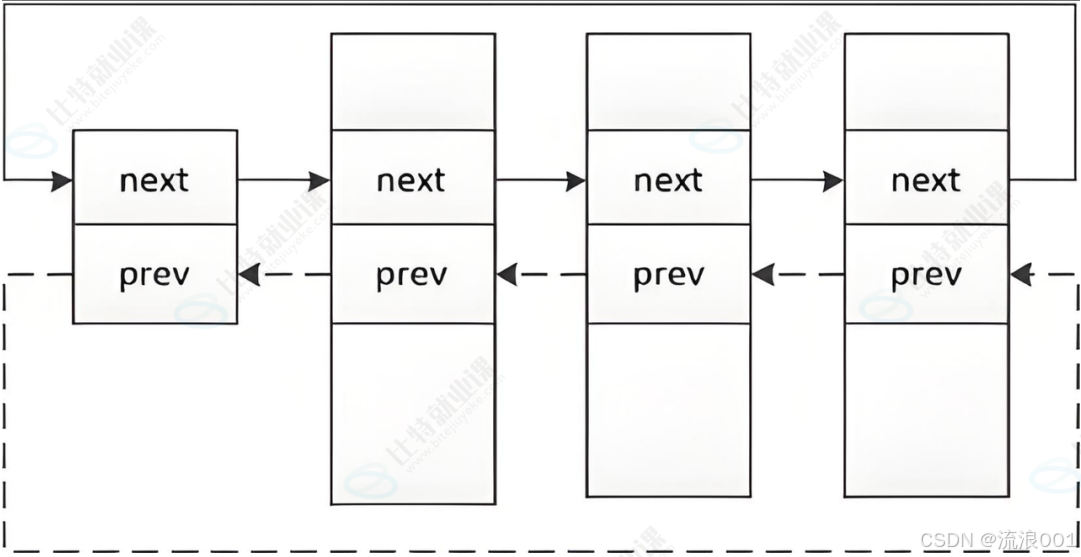
3.组织进程
在Linux内核的源码中可以看到,所有运行在系统里的进程都以task_struct双向链表的形式存在内核里
进程的关键属性
•PID(进程 ID) :操作系统中进程的唯一标识符,类似进程的 "身份证号"
•PPID(父进程 ID) :创建当前进程的进程 ID,类似进程的 "父 ID"
•进程状态 :运行态、就绪态、阻塞态等,描述进程当前的运行情况
•资源信息:进程打开的文件描述符、内存地址、CPU 寄存器状态等
cpp
struct task_struct {
// 1. 进程标识核心字段
pid_t pid; // 进程ID
pid_t tgid; // 线程组ID(主线程PID = 进程ID)
struct task_struct *parent; // 父进程指针
struct list_head children; // 子进程链表头
uid_t uid; // 真实用户ID
gid_t gid; // 真实组ID
// 2. 进程状态与调度
volatile long state; // 进程状态(核心字段)
int prio, static_prio, normal_prio; // 优先级
unsigned int rt_priority; // 实时进程优先级
struct sched_entity se; // 调度实体,关联调度类
// 3. 内存管理核心
struct mm_struct *mm; // 用户态地址空间(普通进程有效)
struct mm_struct *active_mm; // 内核态地址空间(所有进程有效)
// 4. 文件与IO
struct files_struct *files; // 文件描述符表(fd数组)
struct fs_struct *fs; // 文件系统信息(当前目录、根目录)
// 5. 信号处理
struct signal_struct *signal; // 信号相关全局信息
struct sighand_struct *sighand; // 信号处理函数集合
sigset_t blocked; // 阻塞的信号集
// 6. 上下文与栈
void *stack; // 进程内核栈指针
struct thread_struct thread; // CPU寄存器上下文(切换时保存/恢复)
// 7. 时间统计
cputime_t utime, stime; // 用户态耗时、内核态耗时
};
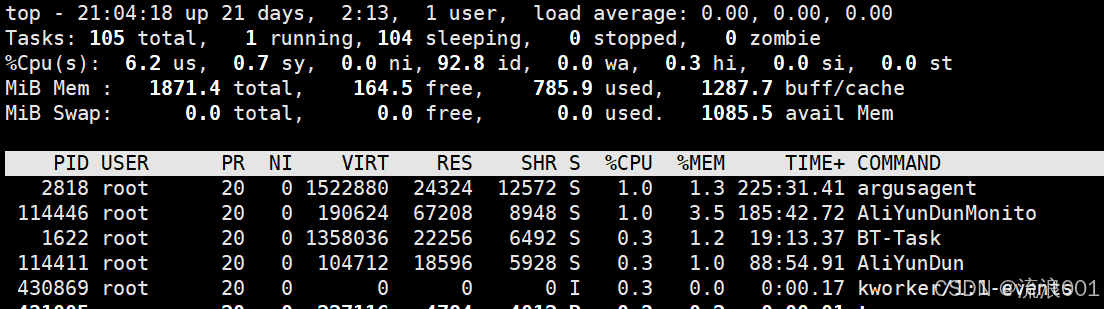
4.查看进程
在Linux中输入下面指令
•ls /proc
•top
•ps
都可查看

5.通过系统调用获取进程标识符
•1.进程ID(PID)
•2.父进程ID(PPID)
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
printf("我的进程:%d\n", getpid());
printf("我的父进程:%d\n", getppid());
return 0;
}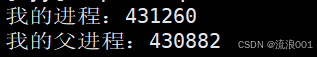
6.通过系统调用创建一个进程
1.创建进程 fork
fork()
fork() 会创建一个新进程,返回值有三种情况:
•返回 小于 0 :创建失败
•返回 0 :代表当前是子进程
•返回 大于 0:代表当前是父进程,返回值是子进程的 PID
代码示例:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
printf("hello proc:%d, ret :%d\n", getpid(), ret);
sleep(1);
return 0;
}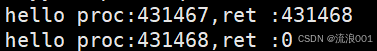
但是为什么会有两个打印输出呢?
fork() 会创建一个和父进程几乎一模一样的子进程,之后两个进程各自独立运行 ,都从 fork() 后面的代码继续往下走。

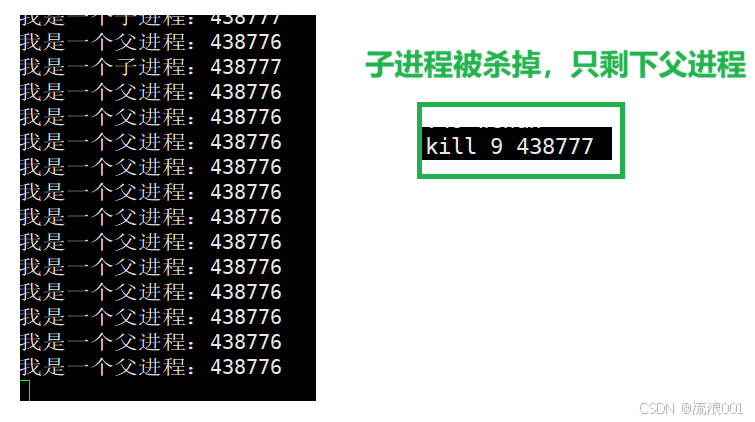
2.杀进程 kill 9 +进程标识符
3.进程的深入理解
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
if(ret < 0)
{
perror("fork file!\n");
return 1;
}
else if(ret == 0)
{
printf("我是一个子进程\n");
}
else
{
printf("我是一个父进程\n");
}
return 0;
}
一个变量,两个返回值(因为有两个进程)
4.关键特性:父子进程的执行顺序
fork()之后,父子进程谁先执行,由操作系统的调度器决定,顺序是不确定的- 父子进程共享代码段,但数据段是独立的,修改数据不会互相影响
5.进程的独立性:写时拷贝机制
父子进程之间的数据看似共享,实际上是通过 ** 写时拷贝(Copy-On-Write, COW)** 机制实现了真正的独立性。
写时拷贝的工作原理
•fork()刚创建子进程时,父子进程的页表指向同一块物理内存,数据段是只读共享的
•当父进程或子进程尝试修改数据时,操作系统会为修改方复制一份数据副本
•复制完成后,父子进程各自的页表指向自己的物理内存,互不干扰
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
int val = 100;
pid_t pid = fork();
if (pid == 0) {
// 子进程修改val的值
val = 200;
printf("子进程:val = %d,地址:%p\n", val, &val);
} else {
sleep(1); // 等待子进程先执行
printf("父进程:val = %d,地址:%p\n", val, &val);
}
return 0;
}