监督学习入门:线性回归与分类
在深度学习和大模型出现之前,机器学习就已经在解决大量真实世界的问题了。这一篇的目标是让你真正理解监督学习的工作原理,而不仅仅是会调用API。
1.1 一、什么是监督学习:带答案的练习题
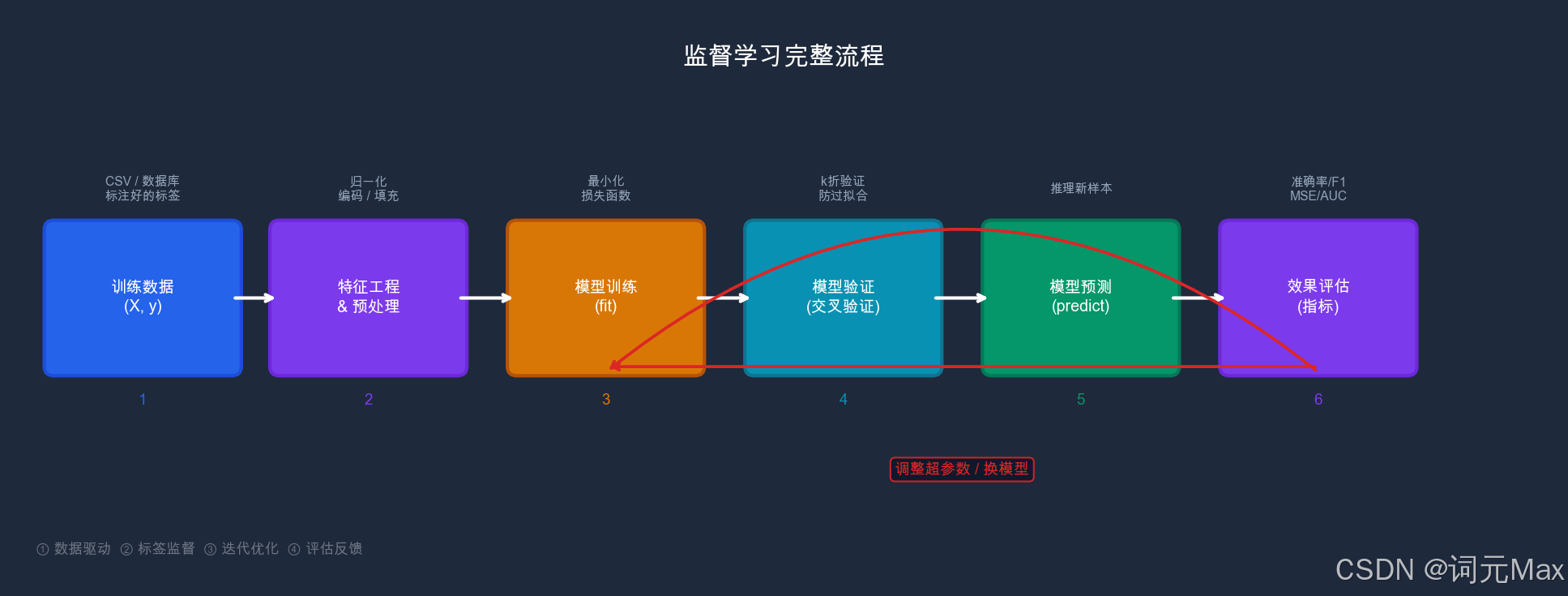
监督学习完整流程------从训练数据到预测输出的五个核心步骤
1.1.1 先从直觉出发
想象你在教一个孩子学认字。你的做法是:拿出一张张卡片,每张上面印着一个字,你告诉孩子"这个字念什么,是什么意思"。孩子看了几百张卡片之后,遇到新的字就能猜出大概是什么意思。
这就是监督学习的核心逻辑:给机器看大量"有答案的例子",让它自己找规律,然后用学到的规律来回答新问题。
**监督(Supervised)**的含义就在这里------训练数据每条都带有"答案"(标签),相当于有"老师"在监督和纠正。
带答案的训练数据:
(房子面积=80平方米) → 答案:房价=200万
(房子面积=120平方米) → 答案:房价=280万
(房子面积=60平方米) → 答案:房价=160万
...
学习后,给新数据:
(房子面积=100平方米) → 模型预测:约240万相比之下,传统编程的思路是:程序员写规则,计算机执行规则。比如要识别垃圾邮件,你可能会写:"如果邮件包含'免费领取'且发件人不在通讯录里,标记为垃圾邮件"。但这种规则很快就会失效------垃圾邮件发送者会不断变换措辞。
监督学习让计算机自己找规律:给它看数千条已标注的例子,计算机能发现比人工规则更全面、更鲁棒的特征。
1.1.2 什么时候用回归,什么时候用分类
监督学习分两大类,判断标准很简单:
看你要预测的东西是连续的数值,还是离散的类别。
| 问题类型 | 要预测的是什么 | 用什么算法 | 例子 |
|---|---|---|---|
| 回归(Regression) | 连续数值 | 线性回归、随机森林回归 | 房价(200万、280万)、温度(25℃)、销量(500件) |
| 分类(Classification) | 离散类别 | 逻辑回归、决策树 | 垃圾邮件(是/否)、猫狗鸟(三类)、情感(正/负/中性) |
判断口诀:预测出来的东西,能在数轴上找到位置吗?能的话用回归,不能的话用分类。
1.2 二、线性回归:最简单的回归模型
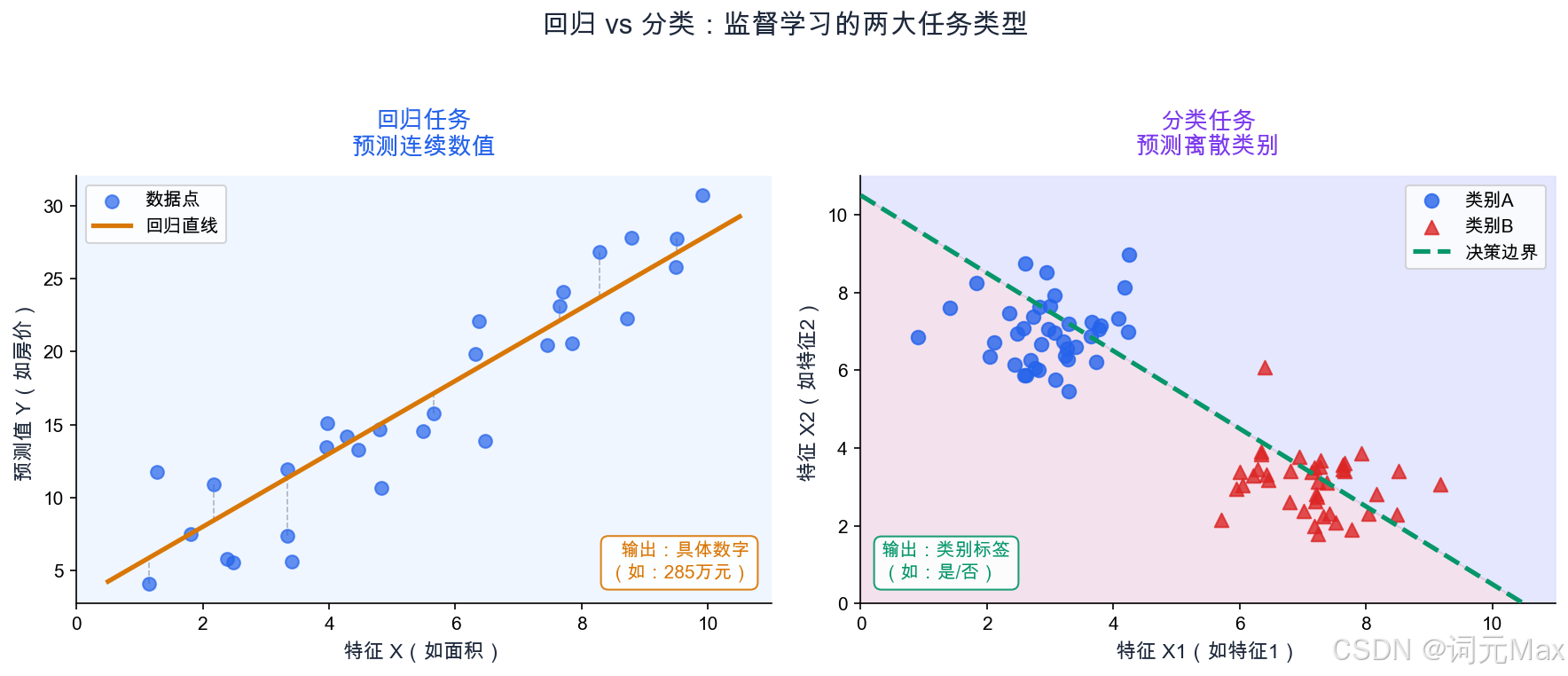
回归 vs 分类------监督学习的两大任务类型对比
1.2.1 为什么从线性回归开始
线性回归不只是一个"简单的入门算法",它是理解整个机器学习的钥匙。神经网络中的每一个神经元,本质上就是在做线性回归(再加一个激活函数)。
从线性回归出发,你能看清楚机器学习最核心的三个要素:模型、损失函数、优化。
1.2.2 "用直线拟合数据"的直觉
设想你手里有一批房价数据:每套房子的面积(平方米)和对应的售价(万元)。你把这些数据点画在坐标纸上,发现一个规律:面积越大,价格越高,而且基本成正比。
线性回归做的事情,就是找一条直线,让它尽量"穿过"这些数据点------不是穿过每一个点(做不到,因为数据有噪声),而是让直线和所有数据点的总体距离最小。
为什么用"平方误差"而不是直接用误差之和?
如果直接用误差之和,正误差和负误差会相互抵消,结果没有意义。平方之后:
- 所有误差变成正数
- 大误差被惩罚得更重(误差为2时,平方误差是4;误差为1时只有1)------让模型更努力地避免离群点的巨大误差
线性回归与神经网络的关系
线性回归是神经网络最简单的特例:没有隐藏层,没有激活函数,只有输入直接连到输出。一个有100个输入特征的线性回归,等价于一个只有输入层和输出层的神经网络(输出层没有激活函数)。
理解这个联系,你就能理解神经网络为什么能学习复杂关系:通过堆叠多个线性变换加非线性激活函数,逐层学习越来越抽象的特征表示。
1.2.3 线性回归代码实战
这段代码在做什么:生成模拟的"面积-房价"数据,用线性回归拟合,然后评估模型好坏并可视化结果。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 生成示例数据:面积 → 房价
np.random.seed(42)
# reshape(-1, 1) 解释:
# np.random.uniform() 生成的是一维数组 (200,)
# sklearn 要求输入是二维数组 (200, 1),即200行、每行1个特征
# -1 是"自动计算行数"的意思
area = np.random.uniform(50, 200, 200).reshape(-1, 1)
price = 2.5 * area + np.random.normal(0, 20, (200, 1)) + 50
# 划分训练集和测试集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(
area, price, test_size=0.2, random_state=42
)
# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差(MSE): {mse:.2f}") # 越小越好,0表示完美
print(f"R²分数: {r2:.4f}") # 越接近1越好,表示模型解释了多少数据变化
print(f"斜率(面积每增加1平方米,价格增加): {model.coef_[0][0]:.4f} 万元")
print(f"截距: {model.intercept_[0]:.4f} 万元")你应该看到类似这样的输出:
均方误差(MSE): 405.83
R²分数: 0.9856
斜率(面积每增加1平方米,价格增加): 2.4937 万元
截距: 51.3842 万元R²接近1(0.9856),说明线性模型很好地捕捉到了面积和房价的关系。斜率约2.49,接近我们设定的真实斜率2.5,说明模型学习正确。
线性回归的数学本质:
y = w₁x₁ + w₂x₂ + ... + wₙxₙ + b训练目标:找到最优的 w(权重)和 b(偏置),使预测误差(均方误差)最小。
1.3 三、逻辑回归:分类任务的基础
1.3.1 为什么不能直接用线性回归做分类
假设你想根据肿瘤大小判断是否为恶性(0=良性,1=恶性)。用线性回归会得到一个连续值------可能是0.3,也可能是1.7,甚至是-0.2。这些数字不能直接解释为"是/否",而且概率只能在0到1之间,线性回归的输出可以超出这个范围。
更深的问题是:分类问题里,你更想要的是一个"概率"------某个样本属于正类的可能性有多大?这就引出了Sigmoid函数的需求。
1.3.2 Sigmoid函数:把任意数值压缩到(0,1)
Sigmoid函数的形状就像一个S:
- 当输入很大时(特征强烈指向正类),输出接近1(高概率是正类)
- 当输入很小时(特征强烈指向负类),输出接近0(低概率是正类)
- 当输入为0时(两边势均力敌),输出正好是0.5
这样,逻辑回归就把"任意实数范围的线性输出"压缩成"0到1之间的概率",完美适合分类任务。
名字叫"回归",但实际上是分类模型------这是个历史遗留的命名问题。
1.3.3 逻辑回归代码实战
这段代码在做什么:加载乳腺癌数据集(569个样本,30个特征,二分类:良性/恶性),标准化后训练逻辑回归模型,并打印详细评估报告。
python
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
# 加载乳腺癌数据集(二分类:良性/恶性)
data = load_breast_cancer()
X, y = data.data, data.target
# 数据标准化:把所有特征缩放到均值为0、方差为1
# 为什么要标准化?逻辑回归对特征尺度敏感
# 如果有的特征是[0,1],有的是[0,1000],大尺度特征会主导学习过程
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
# 训练
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)
# 评估
y_pred = clf.predict(X_test)
print(f"准确率: {accuracy_score(y_test, y_pred):.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=data.target_names))你应该看到类似这样的输出:
准确率: 0.9649
分类报告:
precision recall f1-score support
malignant 0.95 0.95 0.95 40
benign 0.97 0.97 0.97 74
accuracy 0.96 114准确率96.5%,说明逻辑回归在这个医疗数据集上效果非常好。注意两个类别的召回率都在95%以上------对医疗诊断来说,召回率(漏诊率的反面)尤为重要。
1.4 四、支持向量机(SVM):找最宽的分界线
1.4.1 为什么要"最大化间隔"
逻辑回归找到的是一条能正确分开数据的线,但满足条件的线可以有无数条。SVM的洞察是:这些线里,离两侧数据点都最远的那条线,对新数据的泛化能力最强。
直觉:想象桌上散落着红豆和绿豆,你要用一把尺子把它们分开。有无数种放法,但SVM要找那把"离两侧豆子都最远"的放法------这条线两侧的空白区域越宽越好,这就是"最大间隔"。
宽间隔意味着:即使来了稍微有噪声的新数据,也不容易被分错,容错能力更强。
核方法:有时红豆和绿豆混在一起,直线根本分不开。核方法的思路是把平面"折弯"成三维空间,让原来分不开的数据,在高维空间里变得线性可分。
python
from sklearn.svm import SVC
from sklearn.datasets import make_classification
# 生成二分类数据
X, y = make_classification(n_samples=500, n_features=2,
n_redundant=0, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 训练SVM(RBF核,处理非线性问题)
# C:惩罚系数,C越大越不允许分错,容易过拟合;越小容错性更好
# gamma='scale':自动计算的合理默认值
svm = SVC(kernel='rbf', C=1.0, gamma='scale')
svm.fit(X_train, y_train)
print(f"SVM准确率: {svm.score(X_test, y_test):.4f}")SVM的优势:高维数据表现好(文本分类)、对小数据集有效、有理论保证(最大间隔)
SVM的局限:大数据集训练慢、对特征尺度敏感(需要标准化)、参数调优比较麻烦
1.5 五、特征工程:传统ML的核心竞争力
1.5.1 为什么特征工程如此重要
传统机器学习有一个著名的说法:"垃圾进,垃圾出(Garbage in, garbage out)"。
这是传统ML与深度学习的根本区别之一:传统ML需要人工提取特征,深度学习能自动学习特征。
一个用户是否会流失,直接看"注册日期"和"用户ID"是没用的,但"距上次登录天数"和"近一个月消费频率"就是有价值的特征------这种从原始数据构造有意义特征的过程,需要人脑来设计。
好的特征工程可以让简单模型超越复杂模型。
python
import pandas as pd
# 示例:电商用户特征工程
df = pd.DataFrame({
'user_id': [1, 2, 3, 4, 5],
'register_date': ['2023-01-01', '2023-06-15', '2024-01-20',
'2022-12-01', '2024-03-01'],
'last_purchase': ['2024-01-01', '2024-02-01', '2024-03-01',
'2023-12-01', '2024-03-15'],
'total_orders': [50, 3, 12, 100, 1],
'total_amount': [5000, 300, 1200, 15000, 80]
})
df['register_date'] = pd.to_datetime(df['register_date'])
df['last_purchase'] = pd.to_datetime(df['last_purchase'])
# 特征工程:从原始字段构造新特征
reference_date = pd.Timestamp('2024-04-01')
df['days_since_register'] = (reference_date - df['register_date']).dt.days # 注册多久了
df['days_since_purchase'] = (reference_date - df['last_purchase']).dt.days # 多久没购买了
df['avg_order_value'] = df['total_amount'] / df['total_orders'] # 客单价
df['purchase_frequency'] = df['total_orders'] / df['days_since_register'] # 购买频率
print(df[['user_id', 'days_since_register', 'days_since_purchase',
'avg_order_value', 'purchase_frequency']])你应该看到一个表格,展示5个用户的特征,包括注册天数、最后购买距今天数、客单价和购买频率。这些特征比原始的"注册日期"和"总金额"对预测用户行为更有价值。
1.6 六、多分类问题
现实中很多问题有多个类别,不是简单的是/否。
python
from sklearn.datasets import load_iris
# 鸢尾花数据集(3类:setosa/versicolor/virginica)
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 逻辑回归处理多分类
# multi_class='multinomial':同时考虑所有类别的概率(Softmax方式)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
clf = LogisticRegression(multi_class='multinomial', max_iter=1000)
clf.fit(X_train, y_train)
print(f"多分类准确率: {clf.score(X_test, y_test):.4f}")
print(classification_report(y_test, clf.predict(X_test),
target_names=iris.target_names))你应该看到准确率约97%,三个类别都有较高的精确率和召回率。
小结
| 算法 | 适用场景 | 优点 | 缺点 | 适合用于 |
|---|---|---|---|---|
| 线性回归 | 连续值预测 | 简单、可解释、训练快 | 只能拟合线性关系 | 房价、销售额预测 |
| 逻辑回归 | 二/多分类 | 输出概率、可解释 | 线性决策边界 | 垃圾邮件过滤、医疗诊断 |
| SVM | 高维、小数据集 | 泛化性好、理论完备 | 大数据慢、调参复杂 | 文本分类、图像识别(小数据) |
这三个算法都有一个共同的局限:线性假设------它们假设数据可以用直线(超平面)分开或拟合。现实数据往往不满足这个假设。下一篇,我们看决策树------一种完全不同的思路,通过非线性的分割来处理更复杂的数据边界。