VLM2Vec, MM-Embed等模型均为判别式:直接提取输入最后一个 token 的隐层状态作为嵌入,不生成新 token,无法利用 MLLM 的推理能力。UME-R1 提出生成式多模态嵌入,让模型先推理、再总结、最后生成嵌入,同时保留判别式嵌入能力。
方法
数据构建
构建冷启动 SFT 监督数据与RL 强化学习数据两套数据集,覆盖图像、视频、视觉文档三模态。
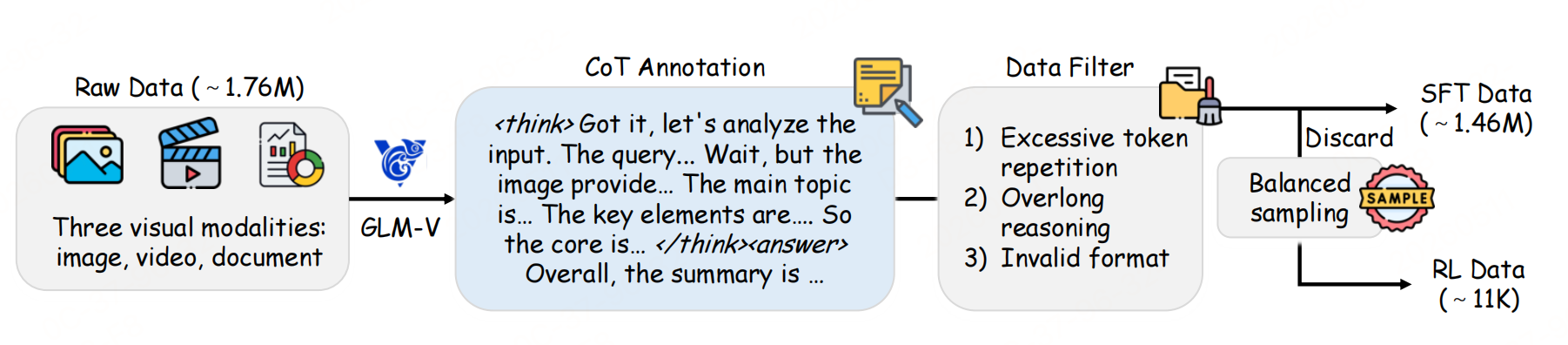
用GLM-4.1V-Thinking推理模型,为每条样本的 query 和 target 生成思维连和摘要。prompt如下:

剔除三类无效样本,最终得到146 万条高质量 SFT 数据:
- 大量连续 token 重复
- 推理文本超长(>8192token)
- 不遵循【< think>...< /think>< answer>...< /answer >】格式
UME-R1模型架构
模型设计目标 :一个模型同时输出判别式嵌入 + 生成式嵌入。

其中 < image> 和 < video> 分别表示输入图像和视频的占位符。如图 a 所示:
- 判别式嵌入:提示中 <disc_emb> token 对应的最后一层隐状态。
- 生成式嵌入:模型生成的 <gen_emb> token 对应的最后一层隐状态
双嵌入生成逻辑:
- 判别式嵌入 :直接提取输入占位符的隐状态,无生成步骤,速度快。
- 生成式嵌入 :先自主生成推理过程+摘要 ,再结合原始输入生成最终表示,精度更高。
模型训练
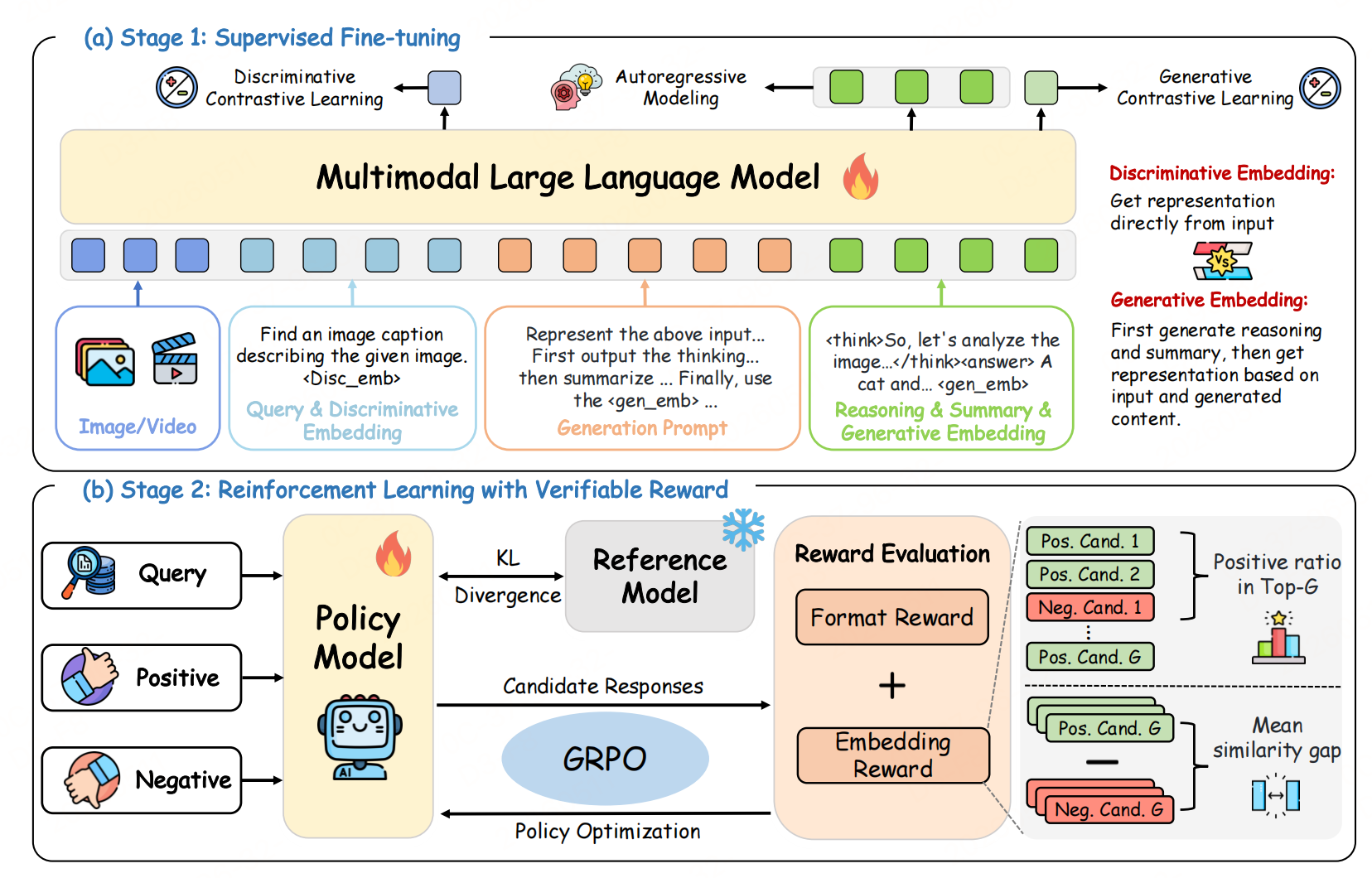
采用两阶段训练,先通过SFT赋予模型双嵌入+推理能力,再用RLVR优化生成式嵌入质量。
Stage 1:冷启动监督微调
目标:让模型同时学会3件事
- 生成判别式嵌入;
- 生成带推理+摘要的生成式嵌入;
- 掌握基础的分步推理能力。
总损失:
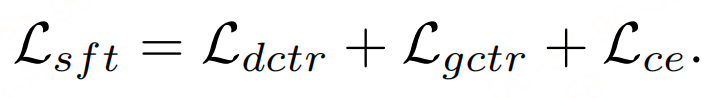
- 判别式对比损失:传统损失,优化判别式嵌入的检索性能。
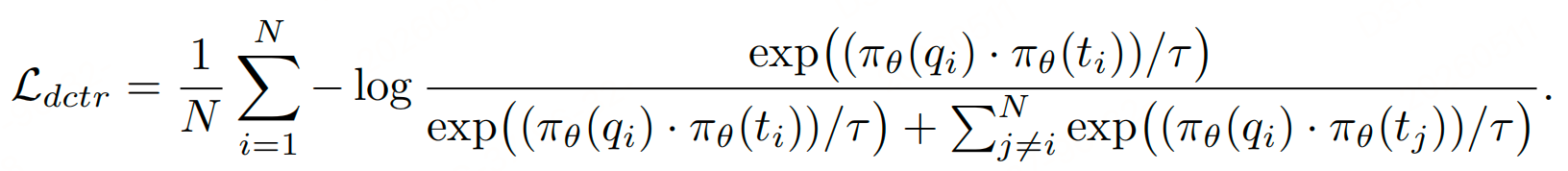
-
生成式对比损失:对推理+摘要后的生成式嵌入 做对比学习,利用CoT语义提升精度:
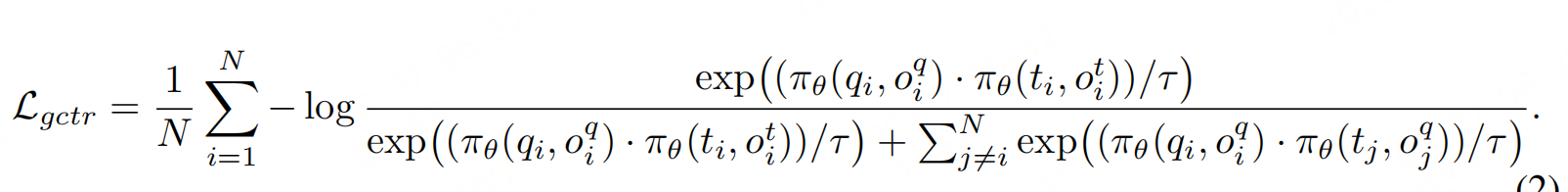
- o_i\^q :查询 q_i 的推理+摘要;
- o_i\^t :目标 t_i 的推理+摘要。
-
自回归语言损失:对推理、摘要token做下一个token预测**,强制模型学会生成规范CoT:
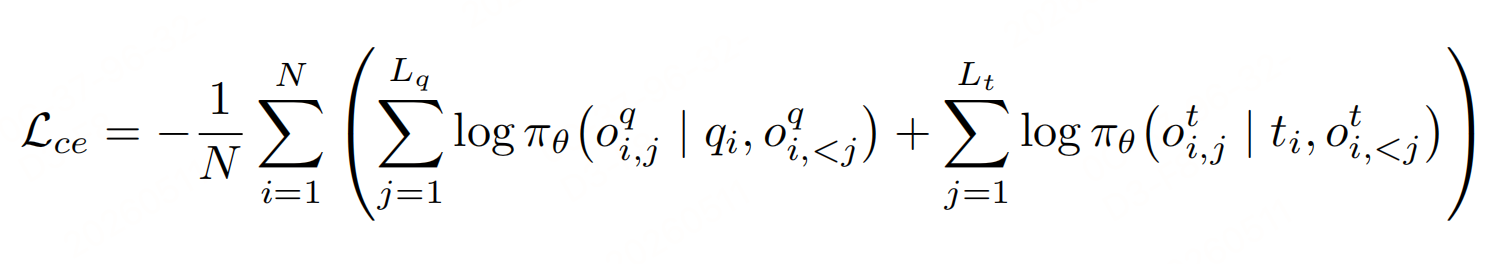
- L_q/L_t :查询/目标的推理长度。
Stage 2:可验证奖励强化学习(RLVR)
使用GRPO进一步优化推理轨迹对embedding的性能【仅用小数据集即可优化,不破坏判别式嵌入性能】。
奖励函数设计:
(1)格式奖励(Format Reward)
强制模型严格遵循模板:< think>推理< /think> < answer>摘要< /answer> < gen_emb>。符合得1分,偏差得0分,保障输出的结构化与可解释性。
(2)嵌入奖励(Embedding Reward)
融合排序 +相似度差,适配多模态嵌入:

- 排序得分:正样本在Top-G中的占比,对齐下游检索任务;
- 相似度差:正/负样本平均相似度之差,细粒度优化区分度;
- 优势:替代固定阈值奖励,适配不同模态的相似度分布。
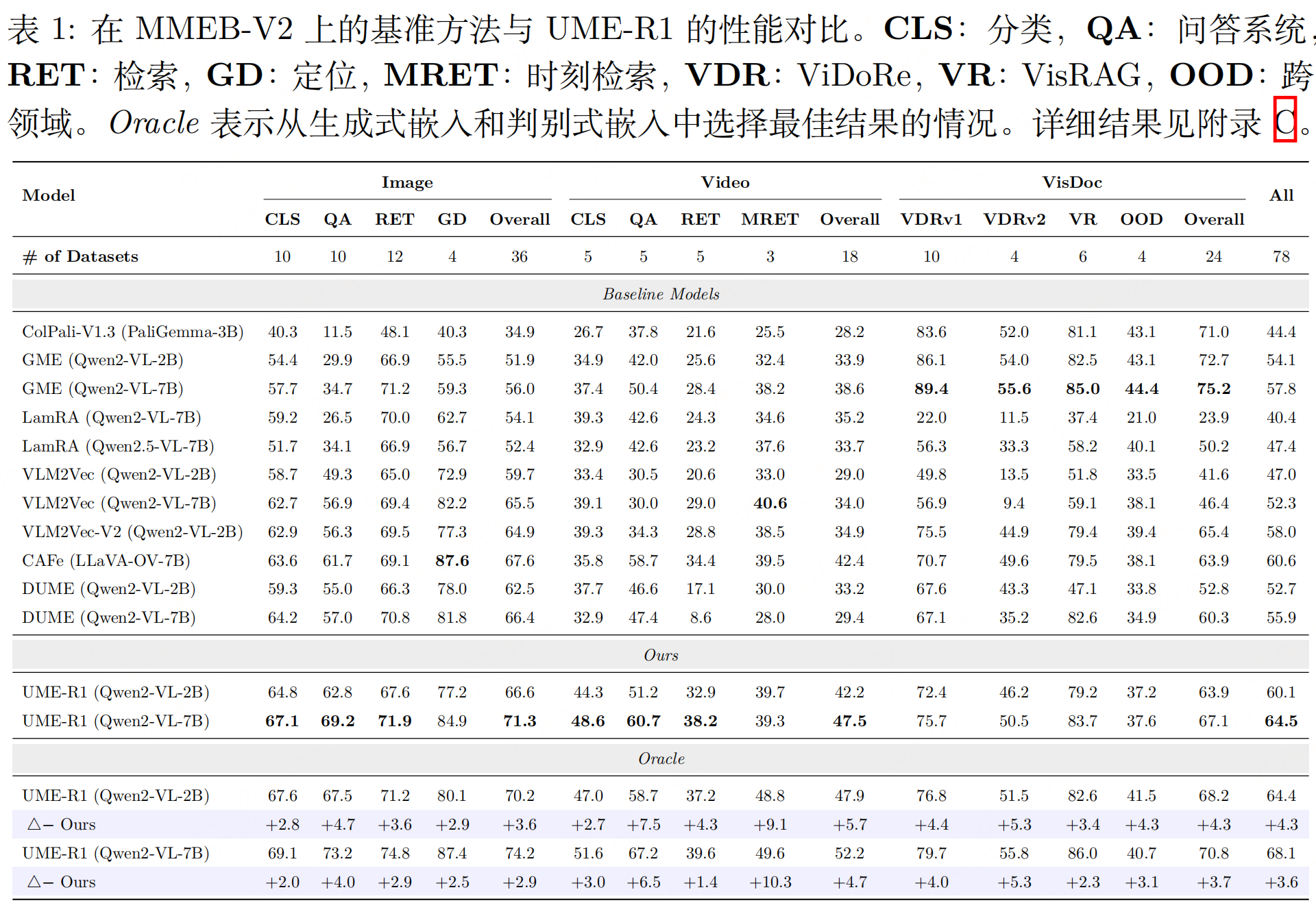
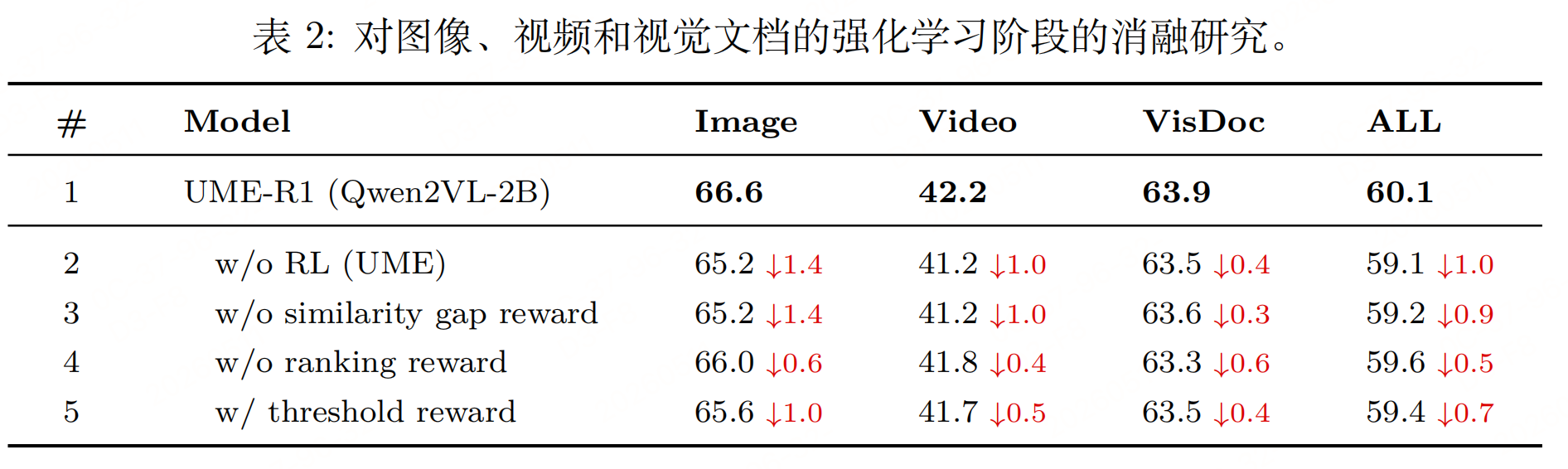
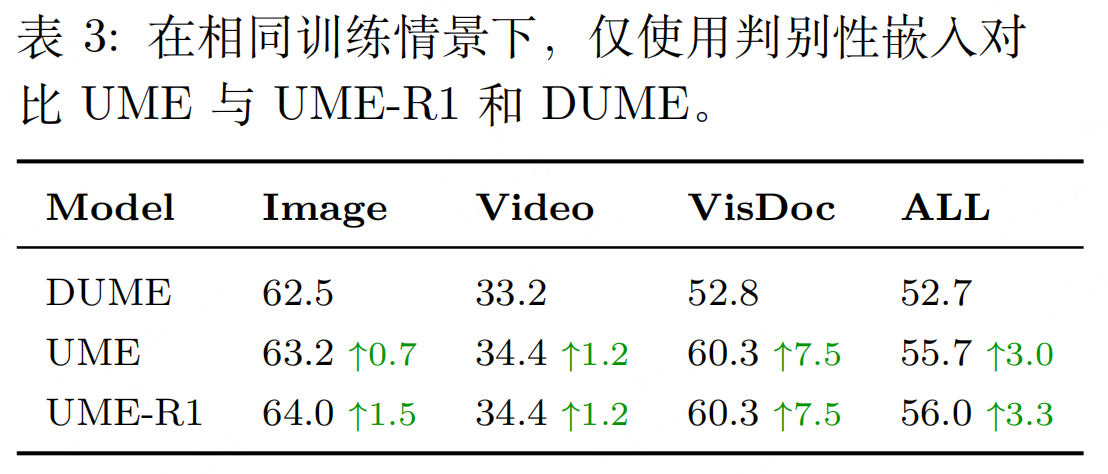
实验
参考文献
UME-R1: EXPLORING REASONING-DRIVEN GENER ATIVE MULTIMODAL EMBEDDINGS,https://arxiv.org/pdf/2511.00405