概述
AI是近两年最热门的话题,火热的大语言模型、Agent应用让人们重新拾起对通用人工智能的期待。
计算机视觉 作为AI最核心的分支之一,正在飞速向前发展。不断涌现的新方法和新模型为我们提供丰富的技术手段,帮助我们实现更复杂的算法功能 、创造更多的业务价值。
丰富的新方法也带来了挑战。哪些方法能真正帮助我们解决技术落地难点,如何将它们合理的运用于实际业务场景,发挥出强大的算法能力,是我们必须思考和学习的问题,而了解方法的特性、优势和局限是合理运用的前提。
本篇文章为大家总结了近两年计算机视觉领域的三项重要突破,并简要分享了一些将它们运用于业务场景的经验,希望能为大家各自的项目提供灵感。也欢迎大家评论区留言一同探讨其它重要的方法与应用。三项突破是:
通用视觉底座 ------自监督视觉基础模型(Self-Supervised Visual Foundation Model) 3D重建新范式 ------前馈3D重建与视角生成(Feed-Forward 3D Reconstruction and View Synthesis) 统一理解与生成------统一和原生多模态模型(Unified and Native Multimodal Model)
自监督视觉基础模型
自监督学习
自监督学习 (Self-Supervised Learning, SSL )是一类无监督学习(Unsupervised learning)范式,它无需人工数据标注,从原始数据自身信息和结构获取监督信号,是训练超大参数量模型的关键手段。简单来说,SSL让模型学习从原始数据的可观测局部,预测不可观测的其余部分信息。
SSL的应用可以追溯到上世纪90年代,2019年Yann LeCun正式提出了这一概念,而真正让人们意识到它强大潜力的是自回归大语言模型(Autoregressive Large Language Model, LLM)的爆发。SSL使互联网上海量无标注文本序列可以直接作为LLM的训练数据,催生了LLM从已观测序列预测后续文本的能力,可以说没有SSL就没有LLM的爆发。
将SSL的成功复刻到视觉模型,利用网络中海量无标注的图像数据训练视觉基础模型 (Vision Foundation Model, VFM),是近些年计算机视觉领域最具应用潜力、最有挑战、最令人兴奋的研究方向。
视觉自监督
视觉领域对自监督的探索有两个主流方向,分别是生成式 (Generative Algorithm Based)自监督和对比学习(Contrastive Learning Based)自监督。
生成式自监督
生成式自监督的核心思想与训练LLM采用的自监督方法一致,训练中对图像分块,随机遮挡部分块,模型根据未被遮挡的图像块上下文,预测被遮挡的部分,从而学习、理解数据的内在结构和特征,如下图所示:

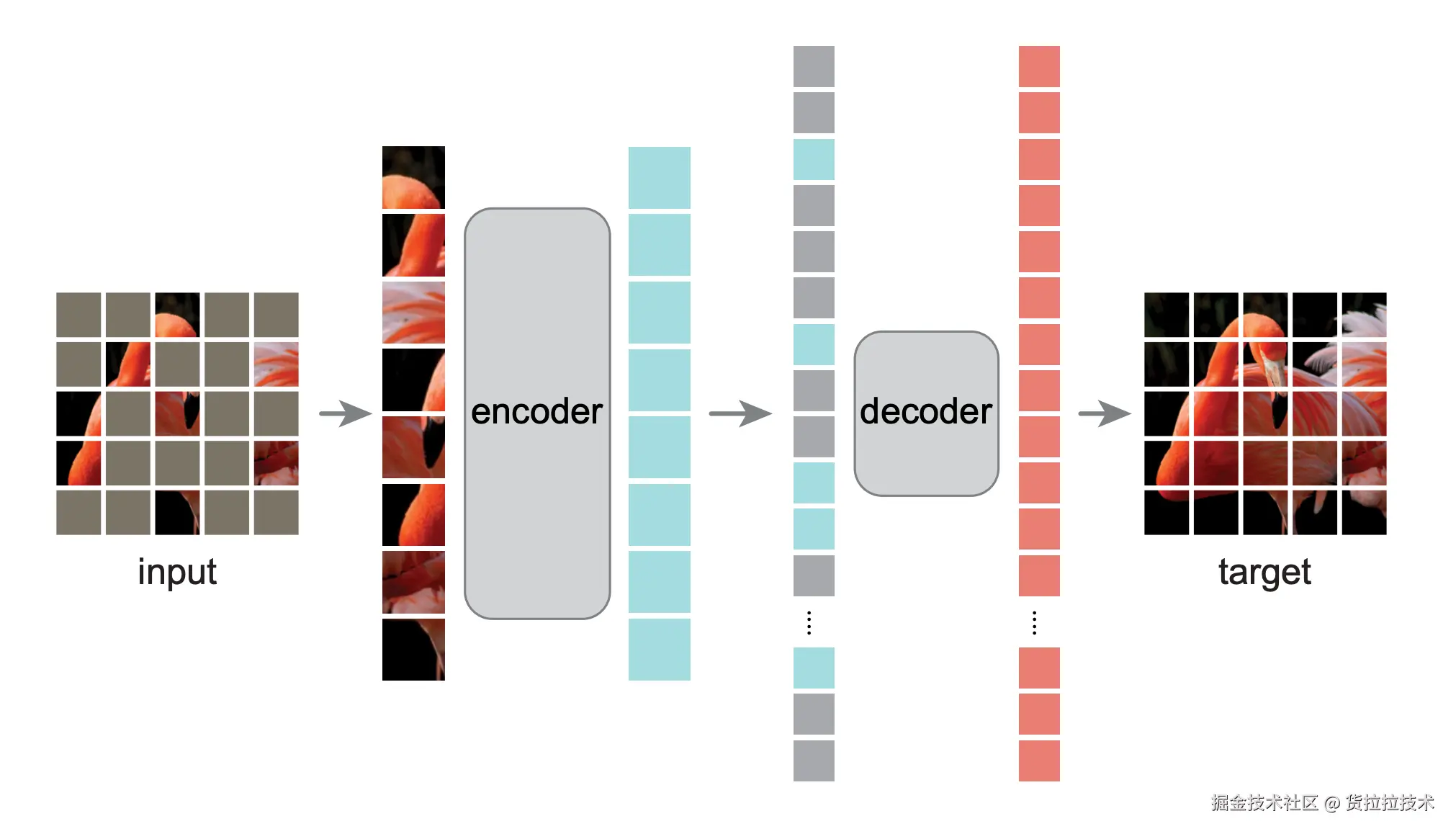
生成式自监督最具代表性的工作是掩码自编码器 (Masked Auto-encoder, MAE),发表于CVPR2022的《Masked Autoencoders Are Scalable Vision Learners》。MAE先用编码器编码可见图像块获得潜在表征,再用解码器从潜在表征和掩码标记重建像素值,模型结构简图如下:
对比学习自监督
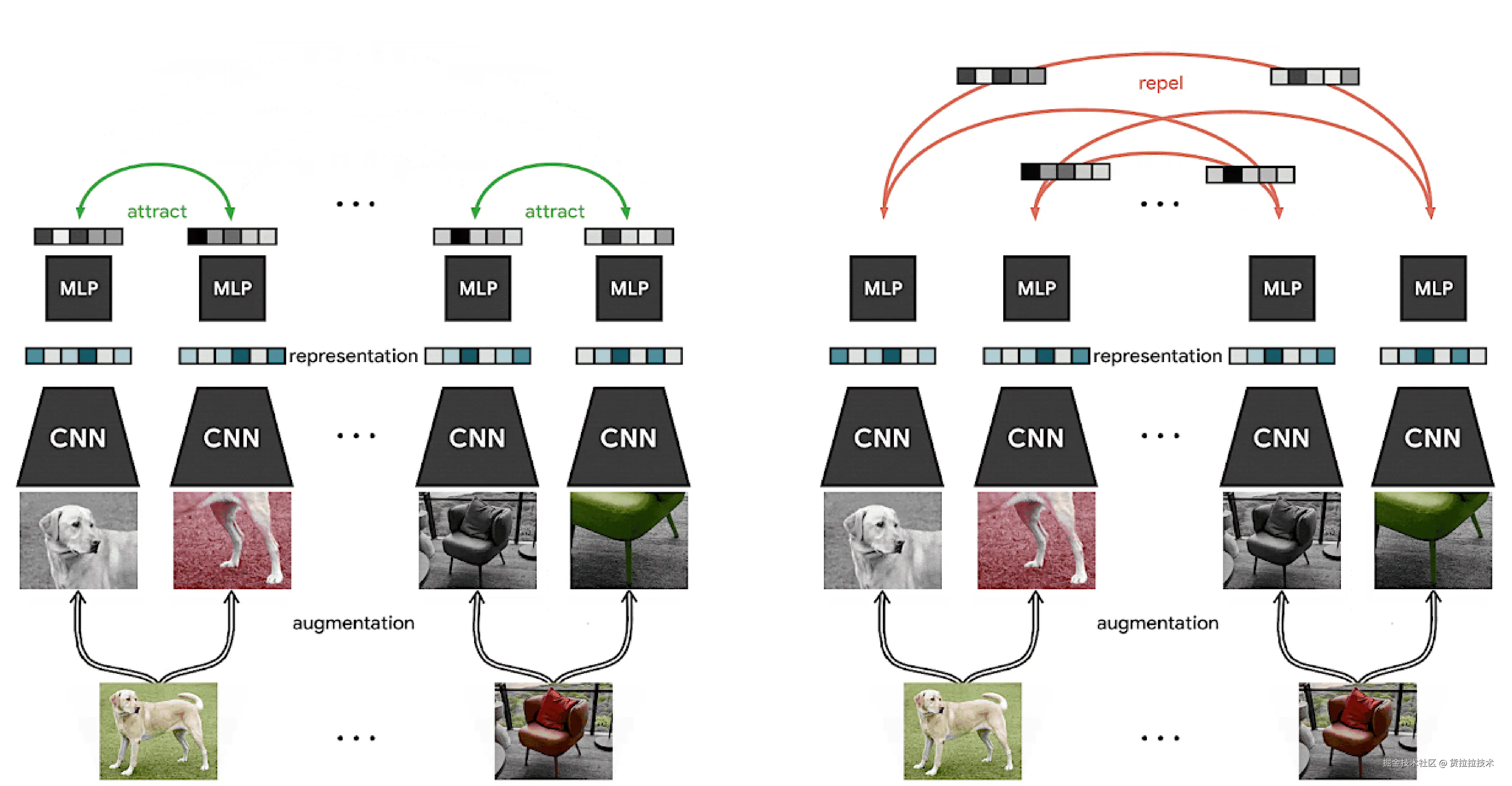
基于对比学习的自监督方法历史更悠久,核心思想是从原始图像构建数据对,再做对比学习 。代表性的工作是 SimCLR,发表于ICML2020的《A Simple Framework for Contrastive Learning of Visual Representations》。SimCLR应用裁剪、颜色抖动、高斯模糊等随机增强,从每张原始图像构建两个视图,将同一图像构建的视图作为正对,将不同图像构建的视图作为负对,进行对比学习,其架构简图如下:
基础模型DINO
DINO (Self-distillation with No Labels)是Meta自21年开始发布的自监督学习范式和预训练基础模型系列,2021~2026年间相继发布了3个版本,DINOv3是时下最强大的通用视觉基础模型和视觉特征提取器。
DINOv1、v2
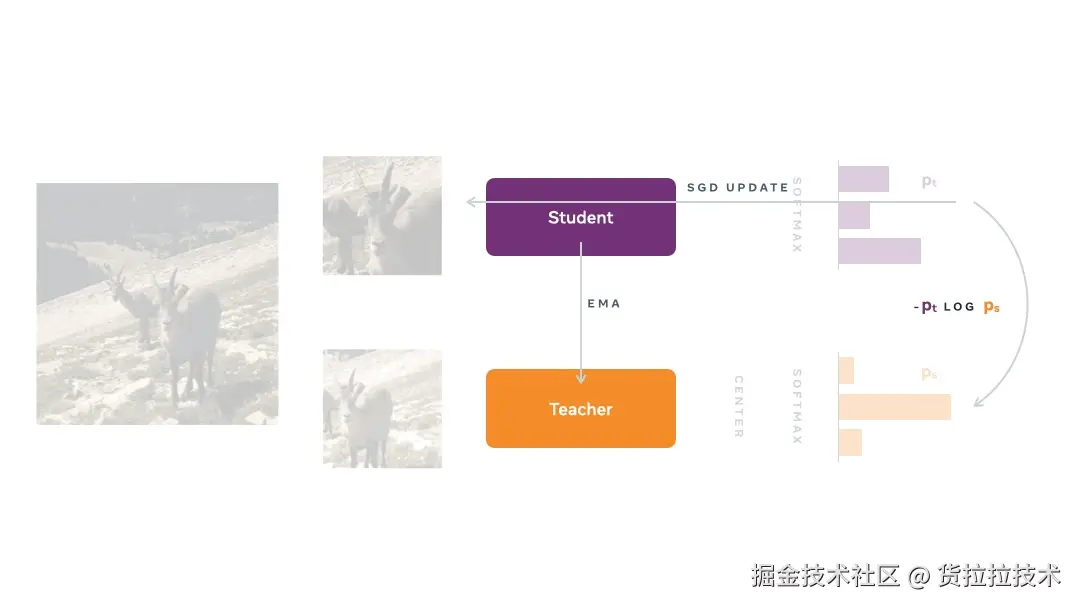
2021年,DINOv1 以《Emerging Properties in Self-Supervised Vision Transformers》为题发表于ICCV2021,将蒸馏思想引入了对比自监督学习,提出了自蒸馏概念,训练中DINO更新教师网络、学生网络两个模型:
- 一张图像经过两种不同的随机裁剪和数据增强,得到一个局部视图和一个全局视图
- 学生网络从局部视图预测概率分布,通过梯度下降更新权重,约束其输出的概率分布尽可能接近教师网络
- 教师网络从全局视图预测概率分布,通过学生网络的指数移动平均(EMA)更新权重
迭代过程如图所示:
v1模型虽然确定了DINO系列通用视觉模型的定位,但只使用0.13B图像训练,最大模型参数量只有86M,性能较专用模型有较大差距。
2023、24年,DINOv2 和DINOv2-Register 相继以《DINOv2: Learning Robust Visual Features without Supervision》、《Vision Transformers Need Registers》为题发布,进一步提升模型性能,模型仅需小样本微调即可用于各类下游任务。v2模型的训练数据规模小幅增加到0.14B,最大模型参数量大幅增加到1.1B,其基础模型特性推动了大量以其为核心组件的前沿探索,如后文将介绍的前馈3D重建。
DINOv3
2025年末DINOv3 发布,解决了视觉长期训练的劣化问题,实现了在超大规模数据上训练超大模型。v3模型无需微调即在多项视觉任务中超过有监督方法,作为特征提取器能获得细致、稳定、通用的图像特征,将通用视觉基础模型推向新的高度。v3模型的图像训练数据规模达到了1.7B,是v2模型的12倍,模型参数量达到了6.7B,是v2模型的6倍。
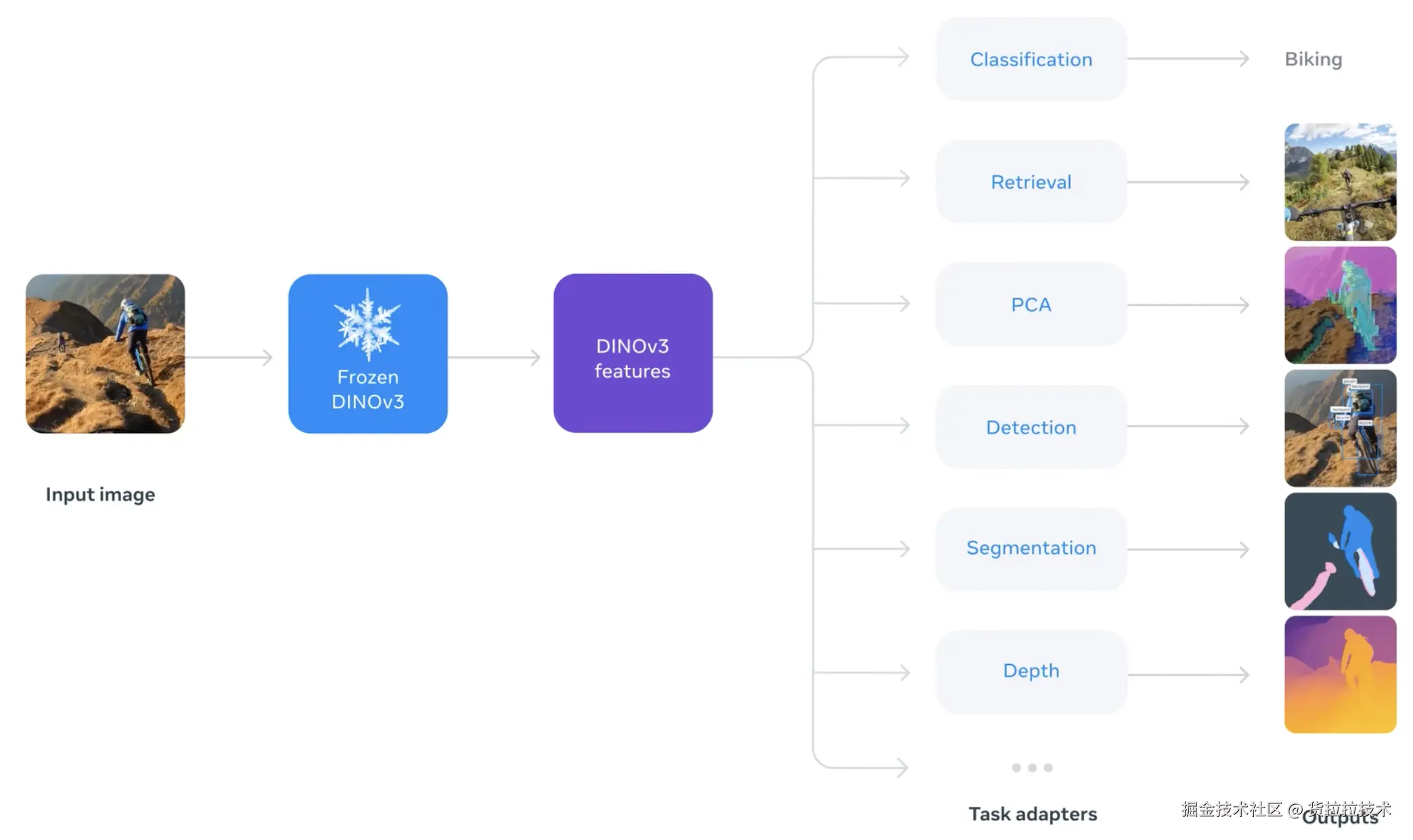
DINOv3展现了强大的通用性 ,并且能提取高质量的像素级特征,通过连接轻量的任务模块,即可在分类、检测等稀疏任务和分割、深度估计等密集任务上超过专用模型,下面两幅图直观展示了它的通用性和像素级特征:

自监督视觉基础模型尽管具备极佳的泛化能力,但在实时性、机器成本方面较专用轻量深度模型仍有劣势,在实际业务场景中,我们使用基础模型解决两类难点问题:
- 结合专门设计的模型组件实现复杂的非传统算法功能,如多图细节一致性比对、贴纸轻微褶皱和偏移检测
- 处理依赖先验的不适定(ill-posed)问题,如单目深度估计、显著性目标检测、无参考数字篡改检测
前馈3D重建
多视角立体与新视角生成
视觉三维重建(Image-based 3D Reconstruction)是计算机视觉最重要的任务之一,它的目标是从2D图像恢复3D物体或场景结构。其不依赖主动传感器的特性,使其广泛应用于纯视觉自动驾驶、数字重建等场景,也是物流行业实现货物体积测量、自动化分拣等应用的核心技术手段。
对"3D重建"的探索历史悠久,并且近期技术迭代迅速,导致"3D重建"在不同历史时期和语境下有着不同含义,当下提及它通常可能指代两类不同的重建任务:
1. 多视角立体 (Multi-View Stereo, MVS)及子环节如:
- 运动恢复结构 (Structure from Motion, SfM)
- 立体匹配(Stereo Matching)
- 深度估计(Depth Estimation)
2. 新视角生成(Novel View Synthesis)
多视角立体重建
MVS从多视角2D图像恢复物体或场景的真实几何结构,如下图是用经典工具COLMAP重建的建筑物:

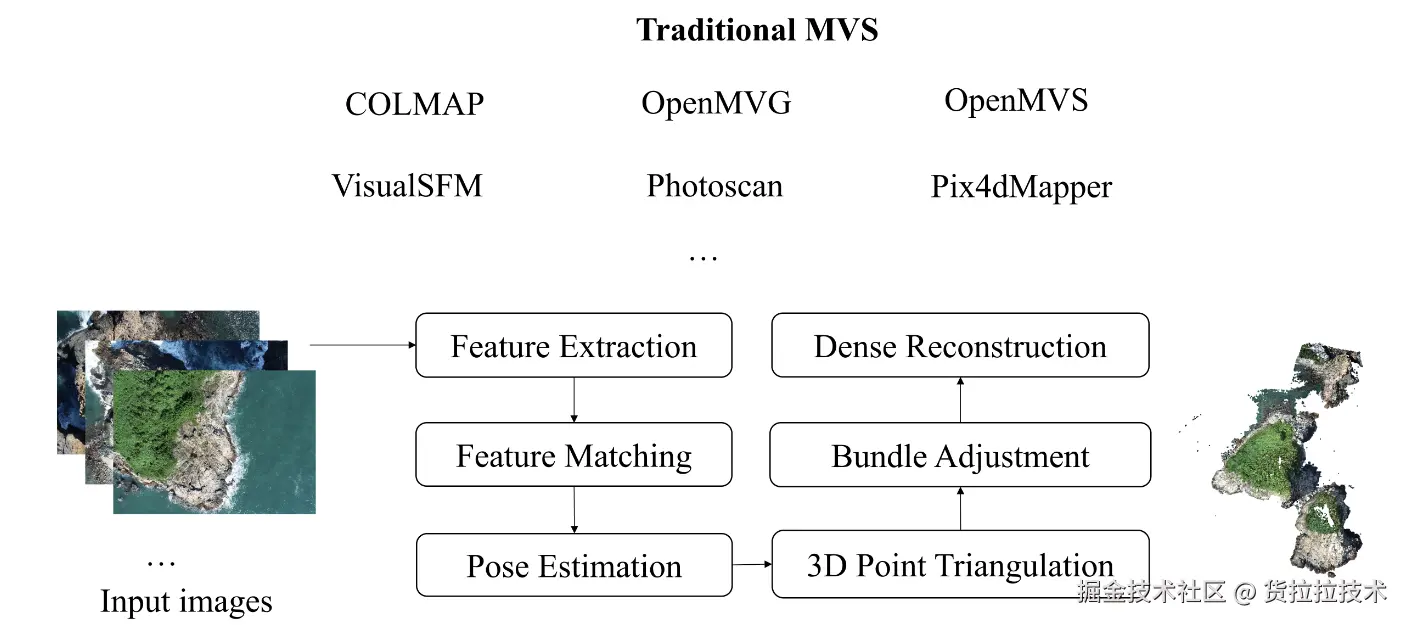
经典MVS方法和工具包括COLMAP、OpenMVS等,通常经过多视角图像特征提取、匹配、相机位姿估计、三角化、BA、密集重建等步骤恢复3D结构信息,经典工具与流程如下图所示:
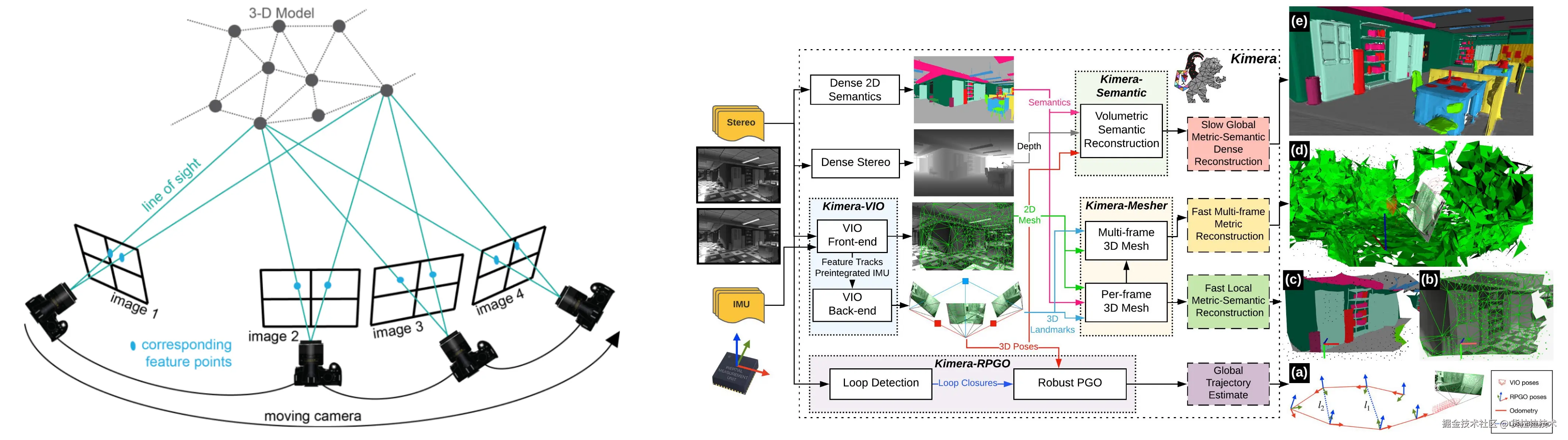
SfM可以看作MVS的简化,相较MVS舍弃了密集重建,只恢复物体大致结构,更关注预测相机位姿与实时性,如下图左侧所示。同步定位与建图(Simultaneous Localization and Mapping, SLAM)是SfM最经典的应用,是工业机器人、无人机领域的核心技术,下图右侧是MIT Spark实验室的实时SLAM框架Kimera的流程简图:
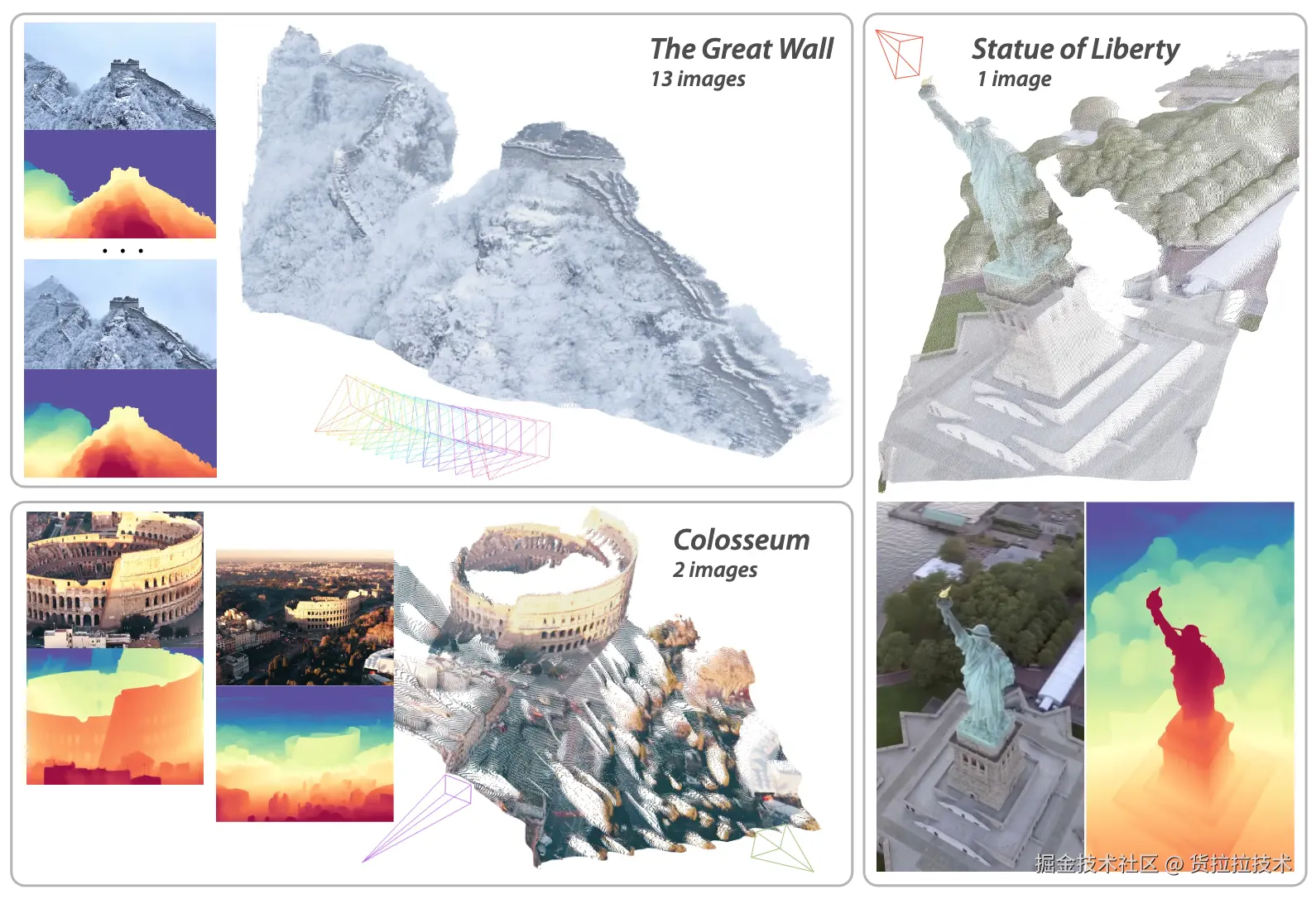
深度估计是恢复物体或场景精细几何结构的关键技术,它的目标是预测2D图像中每个像素对应的深度值。常用方法包括双目立体匹配、单目深度估计等,近期最佳工作是来自ICLR2026的DepthAnything3模型,其获取的深度图如下:
新视角生成
新视角生成是2020年开始兴起的视觉任务,是计算机视觉、图形学近年来最火热的研究方向之一,也是世界模型、空间智能、数字人直播等热门应用的底层技术手段。
新视角生成的目标是从多视角2D图像迭代隐式神经表示或显式高斯表示,再利用它们渲染出极逼真的新视角图像。如下图是CVPR2026中两项新工作的例图,它们利用这项技术构建动态逼真肖像:

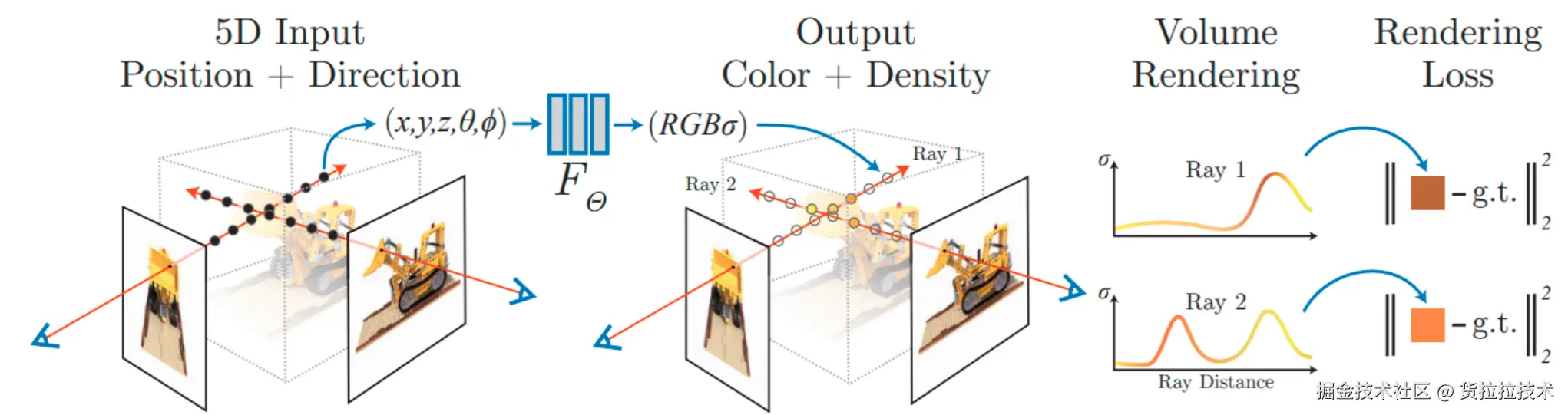
神经辐射场 (Neural Radiance Field, NeRF )是新视角生成的开篇之作,发布于ECCV2020的《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》。NeRF将场景或物体表示为一个MLP ,利用该场景的多视角图像训练优化,使其能够从输入的任意空间坐标和视角方向生成体密度和颜色,进而通过体渲染生成新视角图像。NeRF需要为每个场景训练独立的MLP,通过MLP推理和体渲染生成新视角,其原理简图如下:
3D高斯溅射 (3D Gaussian Splatting, 3DGS )是显式表示方法的事实标准,发布于SIGGRAPH2023的《3D Gaussian Splatting for Real-Time Radiance Field Rendering》。3DGS将场景表示为大量可优化的各项异性的高斯粒子 ,每个高斯粒子包含位置、旋转、缩放、不透明度等属性,使用可微光栅化渲染,大幅加快了场景迭代和渲染速度。3DGS是当下新视角生成最主流的方法,下图左侧是3DGS的原理简图,右侧是与NeRF的直观对比:

传统MVS与新视角生成都是基于迭代的方法,必须为每个场景迭代各自的显式或隐式表示,才能获得该场景的结构信息或逼真新视角图像,步骤复杂、迭代耗时长,制约了它们更广泛的应用。
基于学习的前馈3D重建
在物流领域,多视角立体一类的几何重建方法因其能够重建货物真实结构信息,尤为重要,而每个场景过长的迭代时间、复杂的重建步骤严重限制了这些技术落地于实际业务。
对于2D视觉任务,从单图检测、分割,到多图对比、匹配,多数任务都有基于学习的简洁且高效的端到端方案,只需要通过单个深度模型即可实现,并且随着上一章节介绍的基础模型的发展,更是实现了单个模型解决多个视觉任务的突破。
摆脱复杂、耗时的迭代,通过学习一个端到端的深度模型 ,实现从单次模型前馈推理重建所有3D信息,是近年来3D视觉最重要的突破方向。早期探索通过结合传统迭代方法和深度模型提升整体重建性能,24年开始如DUSt3R的一些端到端方案开始出现,一些代表性方法如下图:

CVPR2025上,牛津大学和Meta合作的《VGGT: Visual Geometry Grounded Transformer》斩获最佳论文荣誉,开启了前馈3D重建的篇章。
VGGT
VGGT 是一个结构简洁的前馈Transformer,通过在海量有标注数据上训练,实现了通过单次模型前向推理从任意张多视角图像预测场景所有3D信息。下图左侧是VGGT的直观介绍,输入多视角图像,模型一次性预测相机参数、场景点图和深度图,右侧展示了VGGT高质量的重建精度 和极快的重建速度:

VGGT模型结构包括2D特征提取、交替注意力、结果预测三部分,如下图所示。2D特征提取 阶段,VGGT应用DINO从各视角图像提取表征序列,并为每个序列额外增加用于预测相机参数的相机Token;交替注意力 阶段,交替在全局表征序列、单视角表征序列上做自注意力操作,获得场景表征序列和相机表征序列;结果预测阶段,MLP从相机表征预测稀疏的相机参数,DPT模块从场景表征预测深度图、点图等密集输出。
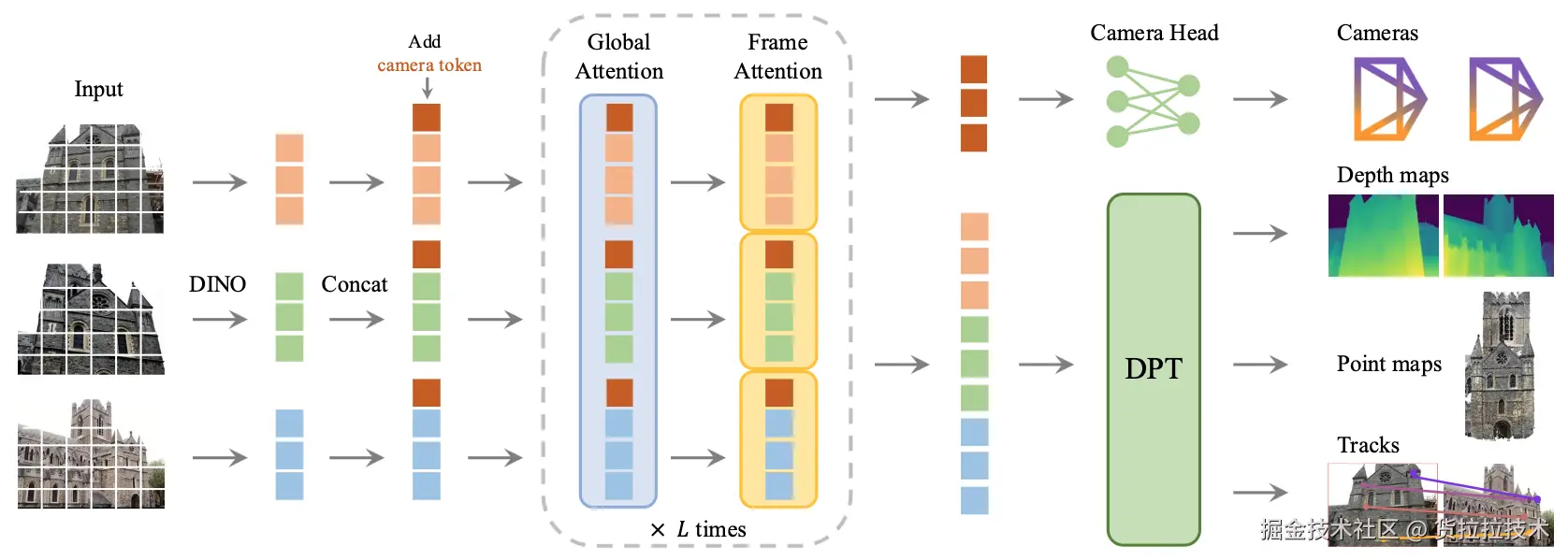
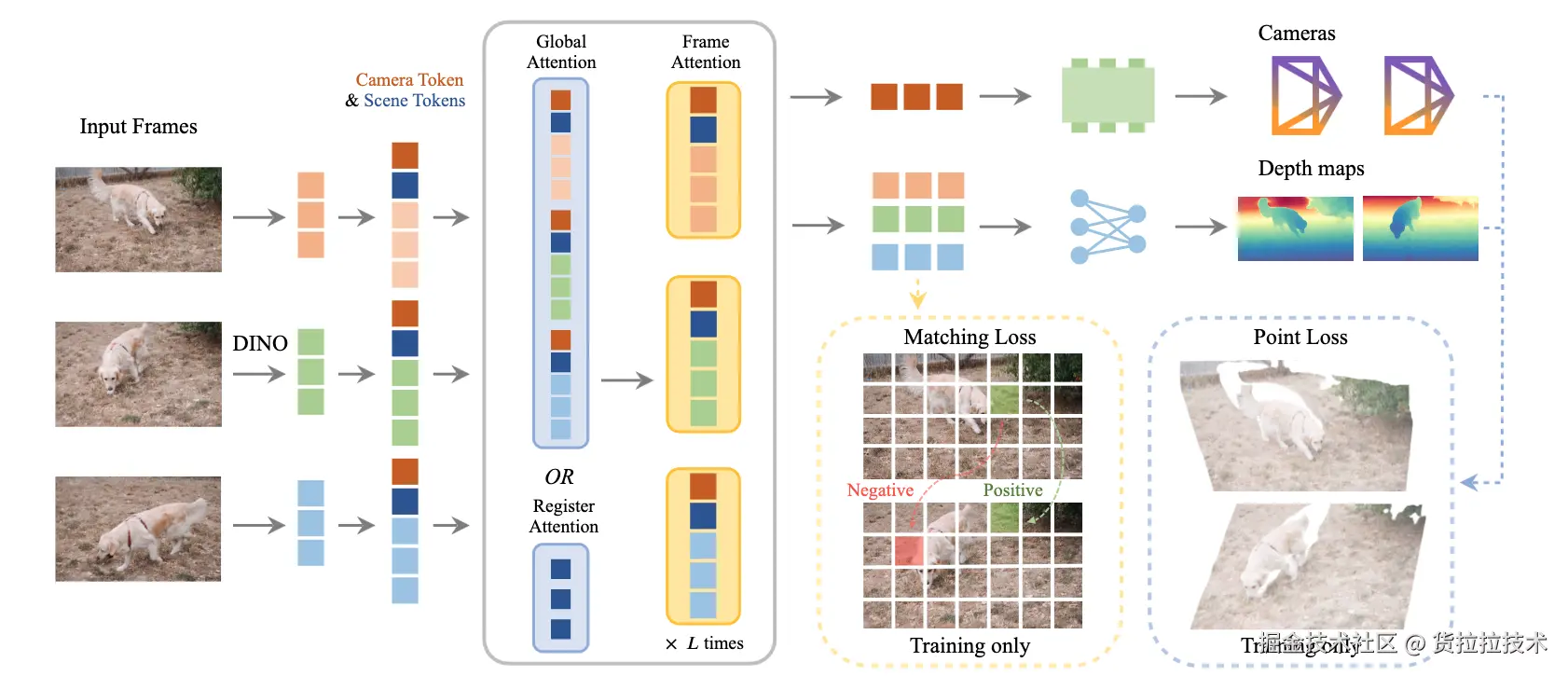
CVPR2026上,牛津大学和Meta发布了改进版VGGT-Ω,通过结构优化和大幅度增加训练数据,进一步提升了VGGT性能,VGGT-Ω模型简图如下图所示:
MapAnything
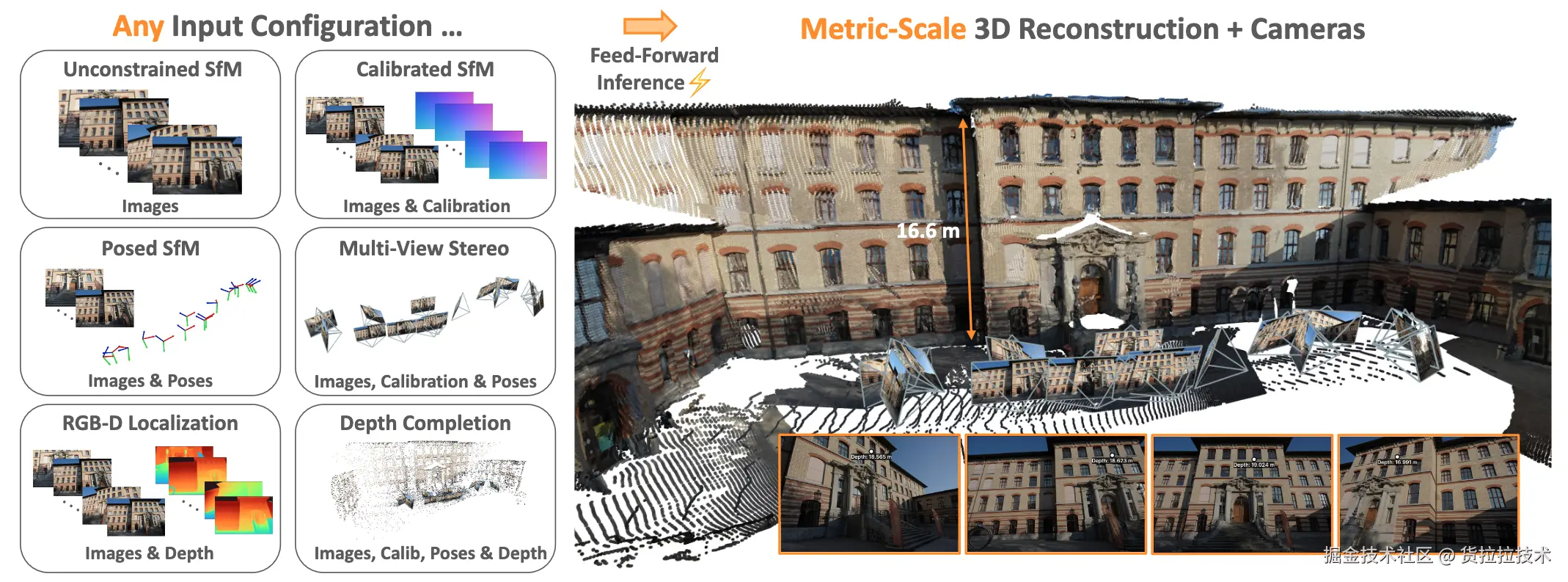
MapAnything是Meta和卡耐基梅隆大学合作以《MapAnything: Universal Feed-Forward Metric 3D Reconstruction》为题发布的全功能前馈3D重建模型。
MapAnything采用离散场景表示 ,将场景分解为多视角深度图、局部射线图、相机位姿和尺度因子,从而实现更灵活的输入、输出组合 ,使其不仅能接收图像,也能接收额外传感器信息和相机参数来提升性能;MapAnything还能直接预测真实尺度因子,实现从图像预测物体和场景的真实物理尺寸,下图直观展示了它的功能:
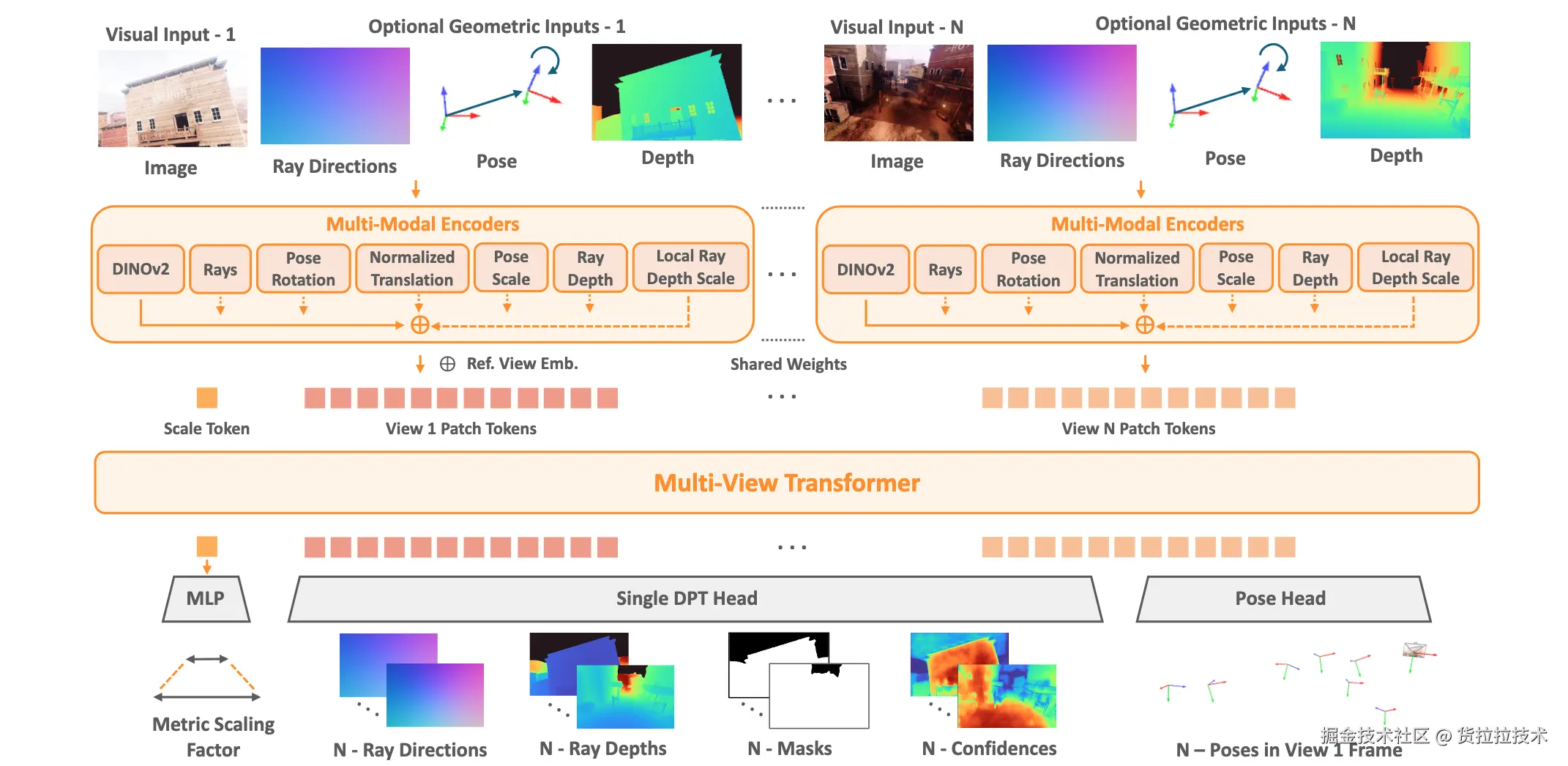
和VGGT一样,MapAnything主体通过简洁Transformer实现,同样使用DINO提取2D特征,其结构如下图所示:
统一多模态模型
多模态与两类VLM
从视觉多传感器融合(Multi-sensor Fusion)到视觉-文本跨模态对齐(Image-Text Alignment),再到图-文-语音全模态模型(Omni Multimodal Model),多模态涉及领域多、研究历史悠久,是通向通用人工智能最重要的技术路线之一。
本章节我们重点关注最重要的视觉、文本两个模态,简要梳理一下时下热门的视觉语言模型 (Vision Language Model, VLM)
根据模型结构和用途的差异,可以将现代VLM划分成两大类型:
- 多模态大语言模型 (Multimodal Large Language Model, MLLM)
- 视觉主干VLM
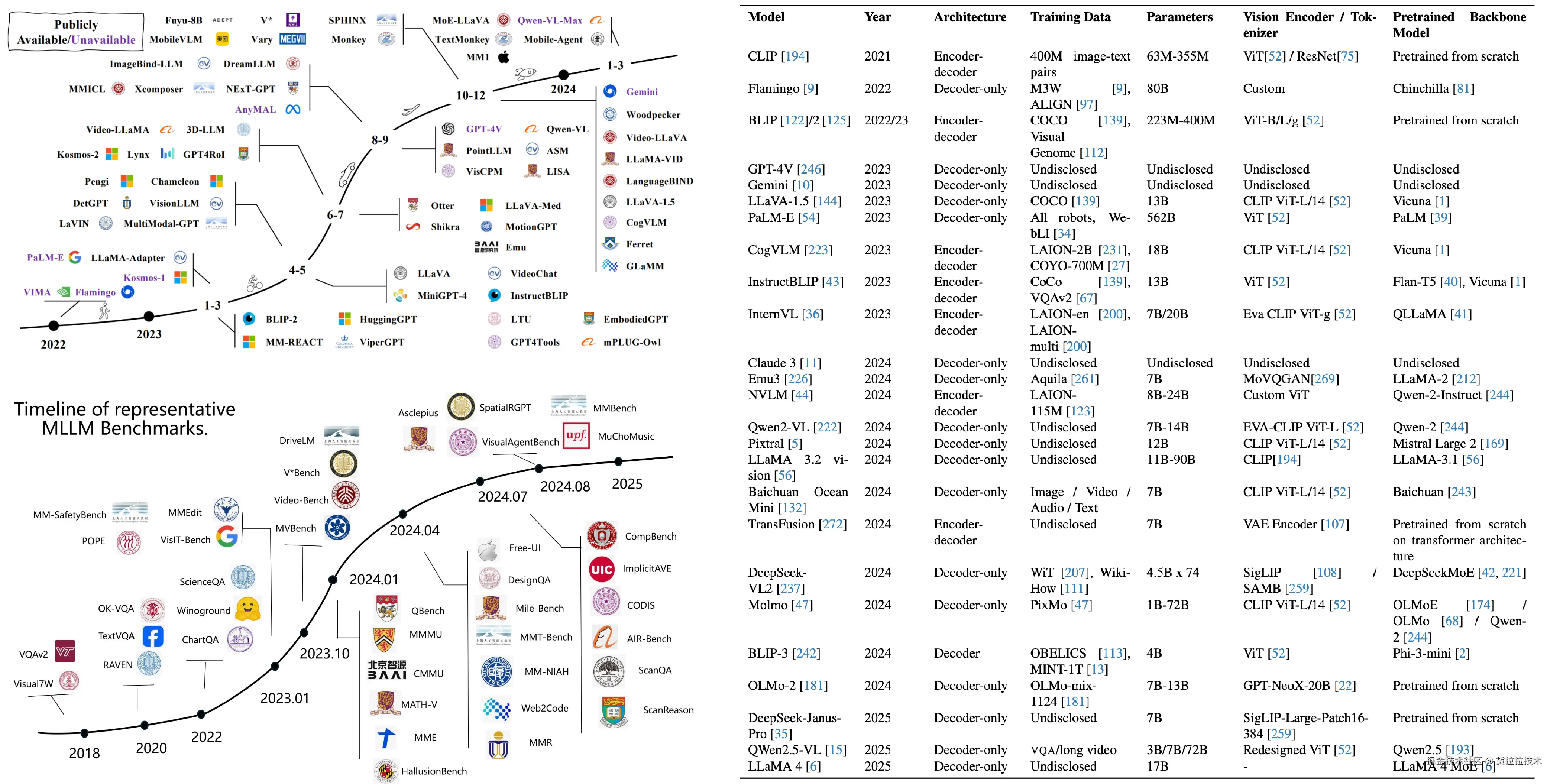
MLLM将视觉输入作为一类"感知",主体由作为"大脑"的LLM驱动,代表模型如Qwen-VL系列、LLaVA系列。MLLM寄予人们对通用人工智能的期待,商业、开源模型不断刷新榜单,下图左上直观展示了一些代表性模型,右侧列举了模型的架构与参数,左下是针对MLLM的基准:
视觉主干VLM将视觉模型作为主体,文本作为高层级语义概念引导模型行为。视觉主干VLM专门服务于视觉任务,在各大计算机视觉会议中广受关注。代表模型如SAM3,通过文本指明需要分割的目标,如下图所示:

从MLLM到NMM、UMM
MLLM表现出的开箱即用 与人机问答交互能力 吸引了大量关注,具备极大的商业潜力,是国内外各大厂商重点投入的方向。早期代表性模型如LLaVA, Qwen-VL等,依赖预训练好的LLM和视觉ViT,通过MLP、Q-Formerd、注意力等方式将ViT输出的视觉表征向文本表征对齐,再用视觉-文本数据整体微调,使语言模型获得视觉理解能力,模型架构简图如下:
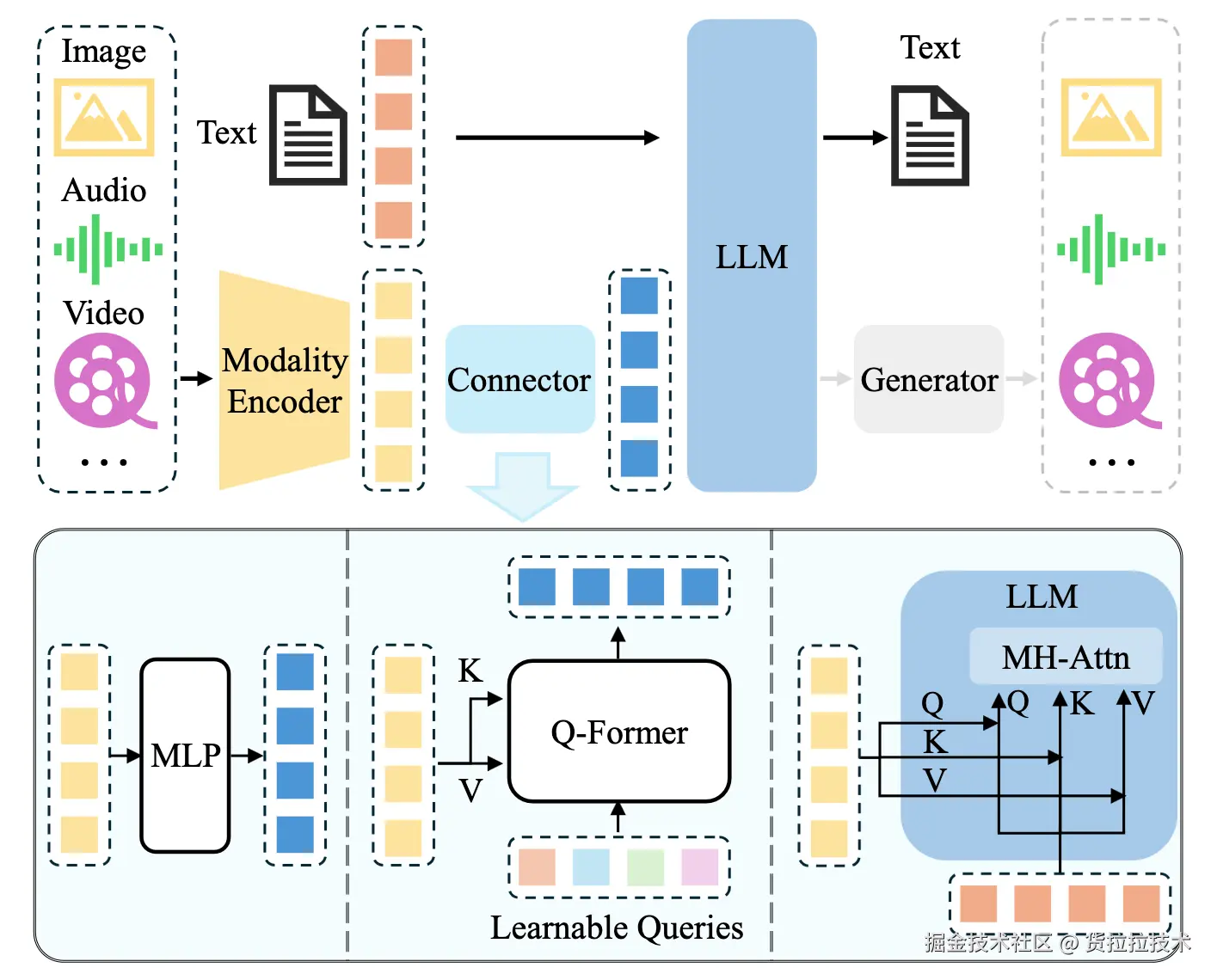
这个时期模型有两个主要问题。首先是视觉模态仅作为一个附件,视觉组件参数比重低,模型整体表现出的图像理解能力不稳定。其次模型只具有文本生成能力,不具有视觉内容生成能力,只能输出文本。
为了解决这两个问题,近两年从MLLM衍生出两类新模型架构:
- 原生多模态模型 (Native Multimodal Model, NMM)
- 统一多模态模型 (Unified Multimodal Model, UMM)
NMM 舍弃预训练模型,使用视觉、文本数据从头训练,使两个模态在输入端"原生的"同样重要,最具代表性的模型如Qwen3.5,不再区分文本模型和VL模型。
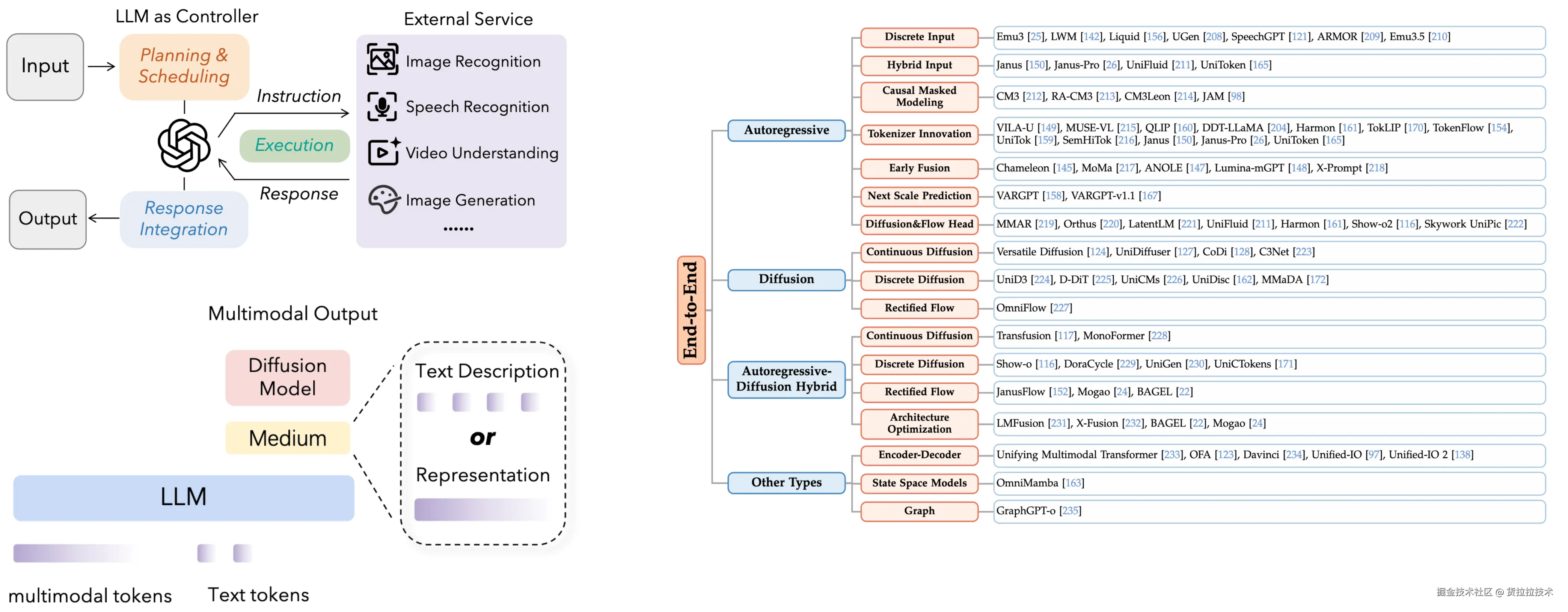
UMM 统一理解与生成任务,模型不只能理解多模态输入,也能生成多模态输出,例如生成图像、视频。按照具体的实现方式可以分成外部专家建模、模块联合建模、端到端建模三个类型,下图左上、左下分别是外部专家建模、模块联合建模的架构简图,右侧列举了各类端到端模型:
视觉主干VLM
视觉主干VLM通常专门解决特定一类视觉任务,近期最具代表性的是Meta于25年底发布的第3代SAM(Segment Anything Model)。
SAM3
SAM系列模型通过多样化的参考、提示来实现"万物分割"和可提示概念分割 (Promptable Concept Segmentation, PCS)。SAM、SAM2两代模型只关注视觉参考,实现了通过点位、边框指定要分割的内容,SAM3在此基础上引入了对文本提示的支持,是当下综合表现最佳的视觉分割模型。
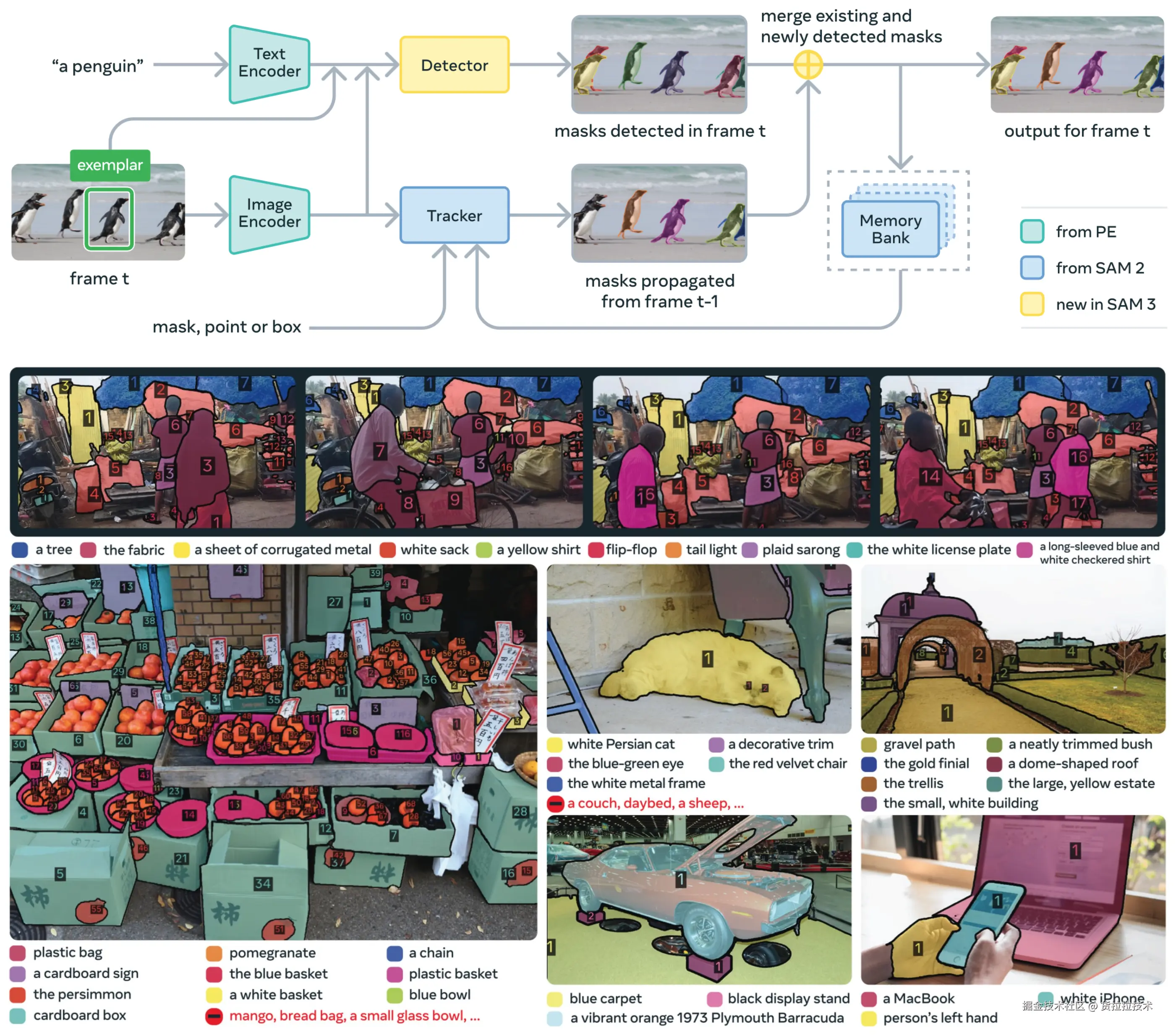
SAM3 的功能非常贴合实际使用场景,支持图像、视频输入,可以单独或混合使用文本提示 、点位 、边框 、参考样图,既可以根据文字描述精准分割对应的物体实例,也可以根据参考样图分割文本难以描述的概念,还能结合点、框提升分割精确性,如下图所示:

SAM3采用了简单模型配合大参数量、海量数据的策略,模型参数量达到8.5M,训练数据集包括4M不重复短语与52M掩码,以及38M合成短语与1.4B合成掩码。SAM3可识别超过4M个细分概念,面对物体遮挡、目标密集等复杂场景依旧能稳定完成目标定位、分割与跟踪。下图上方是SAM的结构简图,下方直观展示了其对细分概念 的区分能力和分割细粒度:
在实际业务场景中,MLLM和视觉主干VLM都发挥了重要作用:
- MLLM能够快速实现多个算法功能 ,非常适合工单量偏小但规则多、常调整的图像审核场景,通过文本描述实现对多条审核规则的自动化处理能力,提升审核时效和规范
- 视觉主干VLM在IoT特殊图像域、样本缺失等场景,为我们提供了具备基础识别能力的起点模型 ,大幅度提高算法实现速度和业务指标,同时在多个通用算法流程里作为重要子环节
总结与感悟
本篇公众号为大家总结了近期计算机视觉领域里能够帮助我们业务落地的3个代表性技术突破:
- 自监督视觉基础模型
- 前馈3D重建
- 统一多模态模型
在具体业务场景中,它们帮助我们解决了多个难题:
- 自监督视觉基础模型提供了通用、细粒度视觉特征,通过结合专用算法模块,实现了多图细节特征比对、贴纸轻微褶皱偏移检测等非传统视觉任务
- 前馈3D重建为感知货物体积、尺寸等应用提供了技术基础;基础模型提取2D特征结合注意力捕获3D信息的思想应用于多视角图像比对等任务
- 统一多模态模型帮助我们快速实现针对重复、繁琐的图像审核的自动化算法;视觉主干VLM帮助我们提升特殊域、少数据场景的算法能力
最后与大家分享一些感想,AI社区有句流传很久的俗语 ------ "不要迷信论文结果",它一方面是大家对灌水论文的调侃,另一方面是表达想要将论文中的好方法应用于实际业务实现稳定的效果,经常还需要解决重重困难。在AI爆发的时代,这句话尤其重要,我们不只需要好的模型与方法,更需要能灵活运用它们,将它们落地于实际业务,将技术变现成价值的能力。只有不断学习、深入思考、多实践,才能提升这项能力,运用好我们手上空前丰富的算法工具。希望大家都能在AI时代不断前进,实现自己的价值。
作者介绍
技术中心-智能平台部-算法组:
李佳翰,资深算法工程师
引用
1He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learnersC//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 16000-16009.
2Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representationsC//International conference on machine learning. PmLR, 2020: 1597-1607.
3Caron M, Touvron H, Misra I, et al. Emerging properties in self-supervised vision transformersC//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 9650-9660.
4Oquab M, Darcet T, Moutakanni T, et al. Dinov2: Learning robust visual features without supervisionJ. arXiv preprint arXiv:2304.07193, 2023.
5Siméoni O, Vo H V, Seitzer M, et al. Dinov3J. arXiv preprint arXiv:2508.10104, 2025.
6Morelli L, Ioli F, Beber R, et al. COLMAP-SLAM: A framework for visual odometryJ. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2023, 48: 317-324.
7Rosinol A, Abate M, Chang Y, et al. Kimera: an open-source library for real-time metric-semantic localization and mappingC//2020 IEEE international conference on robotics and automation (ICRA). IEEE, 2020: 1689-1696.
8Lin H, Chen S, Liew J, et al. Depth anything 3: Recovering the visual space from any viewsJ. arXiv preprint arXiv:2511.10647, 2025.
9Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesisJ. Communications of the ACM, 2021, 65(1): 99-106.
10Kerbl B, Kopanas G, Leimkühler T, et al. 3d gaussian splatting for real-time radiance field renderingJ. ACM Trans. Graph., 2023, 42(4): 139:1-139:14.
11Rosinol A, Violette A, Abate M, et al. Kimera: From SLAM to spatial perception with 3D dynamic scene graphsJ. The International Journal of Robotics Research, 2021, 40(12-14): 1510-1546.
12Wang J, Chen M, Karaev N, et al. Vggt: Visual geometry grounded transformerC//Proceedings of the Computer Vision and Pattern Recognition Conference. 2025: 5294-5306.
13Keetha N, Müller N, Schönberger J, et al. MapAnything: Universal Feed-Forward Metric 3D Reconstruction; map-anything. github. ioC//2026 International Conference on 3D Vision (3DV). IEEE, 2026: 499-509.
14Wang J, Chen M, Zhang S, et al. VGGT- ΩJ. arXiv preprint arXiv:2605.15195, 2026.
15Carion N, Gustafson L, Hu Y T, et al. Sam 3: Segment anything with conceptsJ. arXiv preprint arXiv:2511.16719, 2025.
16Furukawa Y, Hernández C. Multi-view stereo: A tutorialJ. Foundations and Trends in Computer Graphics and Vision, 2015, 9(1-2): 1-148.
17Gui J, Chen T, Zhang J, et al. A survey on self-supervised learning: Algorithms, applications, and future trendsJ. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 9052-9071.
18Zhang J, Li Y, Chen A, et al. Advances in Feed‐Forward 3D Reconstruction and View Synthesis: A SurveyC//Computer Graphics Forum. 2025: e70494.
19Yin S, Fu C, Zhao S, et al. A survey on multimodal large language modelsJ. National Science Review, 2024, 11(12): nwae403.
20Yang Y, Tian H, Shi Y, et al. A Survey of Unified Multimodal Understanding and Generation: Advances and ChallengesJ. Authorea Preprints, 2025.