逻辑回归
==逻辑回归(Logistic Regression)是机器学习中最基础且广泛应用的分类算法之一。==虽然名字中带有"回归",但它主要用于解决分类问题,通过概率判别模型建模来输出样本属于某一类的概率。
一. 分类问题(Classification)基础
分类问题旨在将输入数据映射到离散的类别集合中。
1. 核心定义
-
数据表示: 给定数据集 (x(i),y(i))(x^{(i)},y^{(i)})(x(i),y(i)) 。
-
定义域与值域: x(i)x^{(i)}x(i) 表示样本空间中的一个样本描述 ;y(i)y^{(i)}y(i) 的值域是一个固定的离散类别集 y(i)∈{c1,c2,⋅⋅⋅,cm}y^{(i)}\in\{c_{1},c_{2},\cdot\cdot\cdot,c_{m}\}y(i)∈{c1,c2,⋅⋅⋅,cm} 。
-
问题分类: 主要分为二分类问题和多分类问题 。
2. 判别模型分类
-
确定性判别模型: 形式为 y(i)=fθ(x(i))y^{(i)}=f_{\theta}(x^{(i)})y(i)=fθ(x(i)),该模型对于分类任务通常不可微分 。
-
概率判别模型: 形式为 pθ(y(i)∣x(i))p_{\theta}(y^{(i)}|x^{(i)})pθ(y(i)∣x(i)),该模型对于分类任务是可微分的 。在二分类中,正负类的概率和为1,即 pθ(y(i)=1∣x(i))+pθ(y(i)=0∣x(i))=1p_{\theta}(y^{(i)}=1|x^{(i)})+p_{\theta}(y^{(i)}=0|x^{(i)})=1pθ(y(i)=1∣x(i))+pθ(y(i)=0∣x(i))=1 。
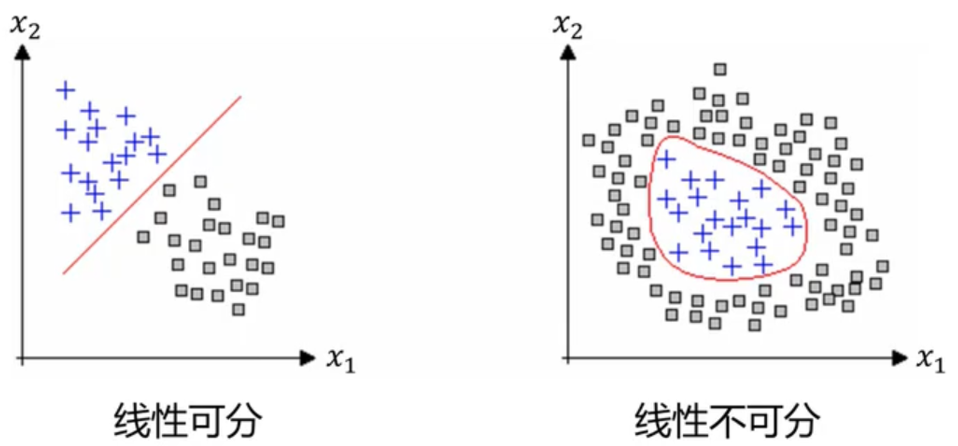
3. 线性可分性
线性可分性是指是否存在一个超平面能够完美划分不同类别的数据。
-
对于二维特征,存在直线 ax1+bx2+c=0ax_{1}+bx_{2}+c=0ax1+bx2+c=0 。
-
使得对于所有的正例满足 ax1+bx2+c>0ax_{1}+bx_{2}+c>0ax1+bx2+c>0,对于所有的负例满足 ax1+bx2+c<0ax_{1}+bx_{2}+c<0ax1+bx2+c<0 。
二. 信息论基础与评价指标
为了评价概率预测分布的好坏,逻辑回归引入了信息论中的交叉熵作为损失函数。
1. 熵 (Entropy)
作用:衡量概率分布的不确定性;分布的不确定性越高,熵就越大。
-
离散值公式: H(p)=−Σxp(x)logp(x)H(p)=-\Sigma_{x}p(x)\log p(x)H(p)=−Σxp(x)logp(x)
-
连续值公式: H(p)=−∫xp(x)logp(x)dxH(p)=-\int_{x}p(x)\log p(x)dxH(p)=−∫xp(x)logp(x)dx
2. 交叉熵 (Cross-Entropy)
作用:给定真实分布 ppp 和预测分布 qqq,衡量两者的差异。
-
离散分布: H(p,q)=−Σxp(x)logq(x)H(p,q)=-\Sigma_{x}p(x)\log q(x)H(p,q)=−Σxp(x)logq(x)
-
连续分布: H(p,q)=−∫xp(x)logq(x)dxH(p,q)=-\int_{x}p(x)\log q(x)dxH(p,q)=−∫xp(x)logq(x)dx
-
分类目标函数: J(y,x,pθ)=−∑I(y=ck)logpθ(y=ck∣x)J(y,x,p_{\theta})=-\sum I(y=c_{k}) \log p_{\theta}(y=c_{k}|x)J(y,x,pθ)=−∑I(y=ck)logpθ(y=ck∣x)
(1). 逻辑回归的模型假设与对数几率 (Log-odds)
在推导损失函数之前,需要先明确模型是如何将输入特征转化为概率的。
作用:建立线性回归输出与二分类概率之间的数学联系。
- 线性输出: z=wTxz = \boldsymbol{w}^T \boldsymbol{x}z=wTx,值域为 (−∞,+∞)(-\infty, +\infty)(−∞,+∞)。
- Sigmoid 映射: σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}σ(z)=1+e−z1,将线性输出挤压到 (0,1)(0, 1)(0,1) 区间,代表预测为正类的概率 ppp。
- 物理意义(对数几率): 如果我们将正类概率 ppp 与负类概率 (1−p)(1-p)(1−p) 做比值,称为几率 (Odds) 。对其取自然对数,即可反推出线性模型的真正含义:
ln(p1−p)=z=wTx\ln\left(\frac{p}{1-p}\right) = z = \boldsymbol{w}^T \boldsymbol{x}ln(1−pp)=z=wTx
结论: 逻辑回归实际上是在用线性模型 wTx\boldsymbol{w}^T \boldsymbol{x}wTx 去拟合真实标记概率的对数几率。有了这个概率 ppp(即 σ\sigmaσ 的输出),我们才能进入下一步:使用极大似然估计推导交叉熵损失函数。
(2).交叉熵损失(BCE)
二分类交叉熵损失函数,也叫做对数损失。这个损失函数被广泛地使用在任何输出结果是二分类的神经网络中,还可被拓展到多分类中。大多数时候,除非特殊声明为二分类,否则提到交叉熵损失,我们会默认算法的分类目标是多分类。
二分类交叉熵损失函数是由极大似然估计推导出来的,对于有m个样本的数据集而言,在全部样本上的平均损失写作:
L(w)=−∑i=1m(yi∗ln(σi)+(1−yi)∗ln(1−σi))L(w) = - \sum_{i=1}^{m} (y_i * \ln(\sigma_i) + (1 - y_i) * \ln(1 - \sigma_i))L(w)=−i=1∑m(yi∗ln(σi)+(1−yi)∗ln(1−σi))
在单个样本的损失写作:
L(w)i=−(yi∗ln(σi)+(1−yi)∗ln(1−σi))L(w)_i = -(y_i * \ln(\sigma_i) + (1 - y_i) * \ln(1 - \sigma_i))L(w)i=−(yi∗ln(σi)+(1−yi)∗ln(1−σi))
参数:
- www表示求解出来的一组权重(在等号的右侧,www在σ\sigmaσ里)
- mmm是样本的个数
- yiy_iyi是样本iii上真实的标签
- σi\sigma_iσi是样本iii上,基于参数www计算出来的sigmoid函数的返回值
- xix_ixi是样本iii各个特征的取值。
我们的目标,就是求解出使L(w)L(w)L(w)最小的www取值。注意,在神经网络中,特征张量X是自变量,权重是www。但在损失函数中,权重www是损失函数的自变量,特征xxx和真实标签yyy都是已知的数据,相当于是常数。不同的函数中,自变量和参数各有不同,因此大家需要在数学计算中,尤其是求导的时候避免混淆。
(3). 极大似然估计求解二分类交叉熵损失
极大似然估计(Maximum Likelihood Estimate, MLE)的感性认识
如果一个事件的发生概率很大,那这个事件应该很容易发生。相应的,如果依赖于权重www的任意事件的发生就是我们的目标,那我们只要寻找令其发生概率最大化的权重www就可以了。寻找相应的权重www,使得目标事件的发生概率最大,就是极大似然估计的基本方法。
其步骤如下:
1、构筑似然函数P(w)P(w)P(w),用于评估目标事件发生的概率,该函数被设计成目标事件发生时,概率最大
2、对整体似然函数取对数,构成对数似然函数lnP(w)\ln P(w)lnP(w)
3、在对数似然函数上对权重www求导,并使导数为0,对权重进行求解
**在二分类的例子中,我们的"任意事件"就是每个样本的分类都正确,对数似然函数的负数就是我们的损失函数。**接下来,我们来看看逻辑回归的对数似然函数是怎样构筑的。
构筑对数似然函数
二分类神经网络的标签是0,1,此标签服从伯努利分布(即0-1分布),因此可得:
样本iii在由特征向量xi\boldsymbol{x}_ixi和权重向量w\boldsymbol{w}w组成的预测函数中,样本标签被预测为1的概率为:
P1=P(y^i=1∣xi,w)=σP_1 = P(\hat{y}_i = 1 | \boldsymbol{x}_i, \boldsymbol{w}) = \sigmaP1=P(y^i=1∣xi,w)=σ
对二分类而言,σ\sigmaσ就是sigmoid函数的结果。
样本iii在由特征向量xi\boldsymbol{x}_ixi和权重向量w\boldsymbol{w}w组成的预测函数中,样本标签被预测为0的概率为:
P0=P(y^i=0∣xi,w)=1−σP_0 = P(\hat{y}_i = 0 | \boldsymbol{x}_i, \boldsymbol{w}) = 1 - \sigmaP0=P(y^i=0∣xi,w)=1−σ
当P1P_1P1的值为1的时候,代表样本iii的标签被预测为1,当P0P_0P0的值为1的时候,代表样本iii的标签预测为0。P1P_1P1与P0P_0P0相加是一定等于1的。
假设样本iii的真实标签yiy_iyi为1,并且P1P_1P1也为1的话,那就说明我们将iii的标签预测为1的概率很大,与真实值一致,那模型的预测就是准确的,拟合程度很高,信息损失很少。相反,如果真实标签yiy_iyi为1,我们的P1P_1P1却很接近0,这就说明我们将iii的标签预测为1的概率很小,即与真实值一致的概率很小,那模型的预测就是失败的,拟合程度很低,信息损失很多。当yiy_iyi为0时,也是同样的道理。所以,当yiy_iyi为1的时候,我们希望P1P_1P1非常接近1,当yiy_iyi为0的时候,我们希望P0P_0P0非常接近1,这样,模型的效果就很好,信息损失就很少。
真实标签 yi 被预测为1的概率 P1 被预测为0的概率 P0 样本被预测为? 与真实值一致吗? 拟合状况 信息损失 1 0 1 0 否 坏 大 1 1 0 1 是 好 小 0 0 1 0 是 好 小 0 1 0 1 否 坏 大 将两种取值的概率整合,我们可以定义如下等式:
P(y^i∣xi,w)=P1yi∗P01−yiP(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w}) = P_1^{y_i} * P_0^{1 - y_i}P(y^i∣xi,w)=P1yi∗P01−yi
这个等式代表同时代表了P1P_1P1和P0P_0P0,在数学上,它被叫做逻辑回归的假设函数。
- 当样本iii的真实标签yiy_iyi为1的时候,1−yi1 - y_i1−yi就等于0,P0P_0P0的0次方就是1,所以P(y^i∣xi,w)P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P(y^i∣xi,w)就等于P1P_1P1,这个时候,如果P1P_1P1为1,模型的效果就很好,损失就很小。
- 同理,当yiy_iyi为0的时候,P(y^i∣xi,w)P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P(y^i∣xi,w)就等于P0P_0P0,此时如果P0P_0P0非常接近1,模型的效果就很好,损失就很小。
所以,为了达成让模型拟合好,损失小的目的,我们每时每刻都希望P(y^i∣xi,w)P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P(y^i∣xi,w)的值等于1。而P(y^i∣xi,w)P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P(y^i∣xi,w)的本质是样本由特征向量xi\boldsymbol{x}_ixi和权重w\boldsymbol{w}w组成的预测函数中,预测出所有可能的y^i\hat{y}_iy^i的概率,因此1是它的最大值。也就是说,每时每刻,我们都在追求P(y^i∣xi,w)P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P(y^i∣xi,w)的最大值。而寻找相应的参数www,使得每次得到的预测概率最大,正是极大似然估计的基本方法,不过P(y^i∣xi,w)P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P(y^i∣xi,w)是对单个样本而言的,因此我们需要将其拓展到多个样本上。
P(y^i∣xi,w)P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P(y^i∣xi,w)是对单个样本而言的函数,对一个训练集的m个样本来说,我们可以定义如下等式来表达所有样本在特征张量X和权重向量w\boldsymbol{w}w组成的预测函数中,预测出所有可能的y^\hat{y}y^的概率P为:
P=∏i=1mP(y^i∣xi,w)P = \prod_{i=1}^{m} P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P=i=1∏mP(y^i∣xi,w)
=∏i=1m(P1yi∗P01−yi)= \prod_{i=1}^{m} (P_1^{y_i} * P_0^{1 - y_i})=i=1∏m(P1yi∗P01−yi)
=∏i=1m(σiyi∗(1−σi)1−yi)= \prod_{i=1}^{m} (\sigma_i^{y_i} * (1 - \sigma_i)^{1 - y_i})=i=1∏m(σiyi∗(1−σi)1−yi)
这个函数就是逻辑回归的似然函数。
构成对数似然函数
对该概率P取以e为底的对数,再由 log(A∗B)=logA+logB\log(A*B) = \log A + \log Blog(A∗B)=logA+logB 和 logAB=BlogA\log A^B = B \log AlogAB=BlogA 可得到逻辑回归的对数似然函数:
lnP=ln∏i=1m(σiyi∗(1−σi)1−yi)\ln P = \ln \prod_{i=1}^{m} (\sigma_i^{y_i} * (1 - \sigma_i)^{1 - y_i})lnP=lni=1∏m(σiyi∗(1−σi)1−yi)
=∑i=1mln(σiyi∗(1−σi)1−yi)= \sum_{i=1}^{m} \ln(\sigma_i^{y_i} * (1 - \sigma_i)^{1 - y_i})=i=1∑mln(σiyi∗(1−σi)1−yi)
=∑i=1m(lnσiyi+ln(1−σi)1−yi)= \sum_{i=1}^{m} (\ln \sigma_i^{y_i} + \ln(1 - \sigma_i)^{1 - y_i})=i=1∑m(lnσiyi+ln(1−σi)1−yi)
=∑i=1m(yi∗ln(σi)+(1−yi)∗ln(1−σi))= \sum_{i=1}^{m} (y_i * \ln(\sigma_i) + (1 - y_i) * \ln(1 - \sigma_i))=i=1∑m(yi∗ln(σi)+(1−yi)∗ln(1−σi))
这就是我们的二分类交叉熵函数。为了数学上的便利以及更好地定义"损失"的含义,我们希望将极大值问题转换为极小值问题,因此我们对lnP\ln PlnP取负,并且让权重www作为函数的自变量,就得到了我们的损失函数L(w)L(w)L(w):
L(w)=−∑i=1m(yi∗ln(σi)+(1−yi)∗ln(1−σi))L(w) = - \sum_{i=1}^{m} (y_i * \ln(\sigma_i) + (1 - y_i) * \ln(1 - \sigma_i))L(w)=−i=1∑m(yi∗ln(σi)+(1−yi)∗ln(1−σi))
现在,我们已经将模型拟合中的"最小化损失"问题,转换成了对函数求解极值的问题。这就是一个,基于逻辑回归的返回值σi\sigma_iσi的概率性质以及极大似然估计得出的损失函数。在这个函数上,我们只要追求最小值,就能让模型在训练数据上的拟合效果最好,损失最低。
求导
(4). 由二分类推广到多分类
二分类交叉熵损失可以被推广到多分类上,但在实际处理时,二分类与多分类却有一些关键的区别。依然使用极大似然估计的推导流程,首先我们来确定单一样本概率最大化后的似然函数。
对于多分类的状况而言,标签不再服从伯努利分布(0-1分布),因此我们可以定义,样本iii在由特征向量xi\boldsymbol{x}_ixi和权重向量w\boldsymbol{w}w组成的预测函数中,样本标签被预测为类别k的概率为:
Pk=P(y^i=k∣xi,w)=σP_k = P(\hat{y}_i = k | \boldsymbol{x}_i, \boldsymbol{w}) = \sigmaPk=P(y^i=k∣xi,w)=σ
对于多分类算法而言,σ\sigmaσ就是softmax函数返回的对应类别的值。
假设一种最简单的情况:我们现在有三分类1, 2, 3,则样本i被预测为三个类别的概率分别为:
P1=P(y^i=1∣xi,w)=σ1P_1 = P(\hat{y}_i = 1 | \boldsymbol{x}_i, \boldsymbol{w}) = \sigma_1P1=P(y^i=1∣xi,w)=σ1
P2=P(y^i=2∣xi,w)=σ2P_2 = P(\hat{y}_i = 2 | \boldsymbol{x}_i, \boldsymbol{w}) = \sigma_2P2=P(y^i=2∣xi,w)=σ2
P3=P(y^i=3∣xi,w)=σ3P_3 = P(\hat{y}_i = 3 | \boldsymbol{x}_i, \boldsymbol{w}) = \sigma_3P3=P(y^i=3∣xi,w)=σ3
假设样本的真实标签为1,我们就希望P1P_1P1最大,同理,如果样本的真实标签为其他值,我们就希望其他值所对应的概率最大。在二分类中,我们将yyy和(1−y)(1-y)(1−y)作为概率PPP的指数,以此来融合真实标签为0和为1的两种状况。但在多分类中,我们的真实标签可能是任意整数,无法使用yyy和(1−y)(1-y)(1−y)这样的结构来构建似然函数。所以我们认为,如果多分类的标签也可以使用0和1来表示就好了,这样我们就可以继续使用真实标签作为指数的方式。
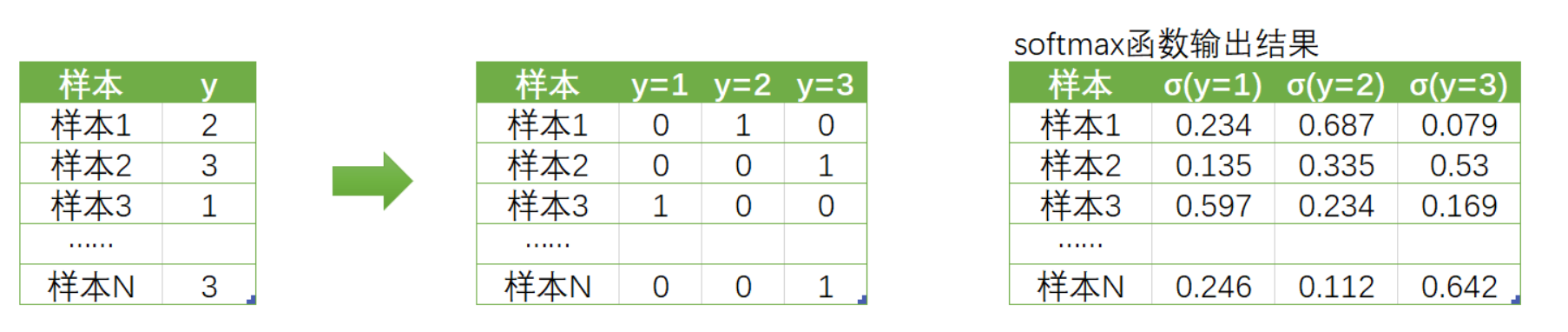
因此,我们对多分类的标签做出了如下变化:
原本的真实标签y是含有1, 2, 3三个分类的列向量,现在我们把它变成了标签矩阵,每个样本对应一个向量。(这就是独热编码one-hot也叫做亚变量)。在矩阵中,每一行依旧对应样本,但却由三分类衍生出了三个新的列,分别代表:真实标签是否等于1、等于2以及等于3。在矩阵中,我们使用"1"标出样本的真实标签的位置,使用0表示样本的真实标签不是这个标签。不难注意到,这个标签矩阵的结构其实是和softmax函数输出的概率矩阵的结构一致,并且一一对应的。
回顾下二分类的似然函数:
P(y^i∣xi,w)=P1yi∗P01−yiP(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w}) = P_1^{y_i} * P_0^{1 - y_i}P(y^i∣xi,w)=P1yi∗P01−yi
当我们把标签整合为标签矩阵后,我们就可以将单个样本在总共K个分类情况整合为以下的似然函数:
P(y^i∣xi,w)=P1yi(k=1)∗P2yi(k=2)∗P3yi(k=3)∗⋯∗PKyi(k=K)P(\hat{y}i | \boldsymbol{x}i, \boldsymbol{w}) = P_1^{y{i(k=1)}} * P_2^{y{i(k=2)}} * P_3^{y_{i(k=3)}} * \dots * P_K^{y_{i(k=K)}}P(y^i∣xi,w)=P1yi(k=1)∗P2yi(k=2)∗P3yi(k=3)∗⋯∗PKyi(k=K)
其中P就是样本标签被预测为某个具体值的概率,而右上角的指数就是标签矩阵中对应的值,即这个样本的真实标签是否为当前标签的判断(是就是1,否就是0)。
注意
许多教材和公式中,都会把多分类似然函数概率的指数直接写作yiy_iyi,若你能够理解此处的指数其实是0和1( 0 - 不是真实标签,1 - 是真实标签),而不是真正的标签yiy_iyi,那直接把指数写作yiy_iyi也是没问题的。为避免混淆,在我们的总结中,还是写作yi(k=真实标签序号)y_{i(k=\text{真实标签序号})}yi(k=真实标签序号)。
更具体的,小k代表y的真实取值,K代表总共有K个分类(此处不是非常严谨,按道理说若K代表总共有K个类别,则不应该再使用K代表某个具体类别,但在这里,由于我们使用的类别编号与类别本身相同,所以为了公式的简化,使用了这样不严谨的表示方式)。虽然是连乘,但对于一个样本,除了自己所在的真实类别指数yiy_iyi会是1之外,其他类别的指数都为0,所以被分类为其他类别的概率在这个式子里就都为0。所以我们可以将式子简写为:
P(y^i∣xi,w)=Pjyi(k=j), j为样本i所对应的真实标签的编号P(\hat{y}_i | \boldsymbol{x}i, \boldsymbol{w}) = P_j^{y{i(k=j)}}, \text{ j为样本}i\text{所对应的真实标签的编号}P(y^i∣xi,w)=Pjyi(k=j), j为样本i所对应的真实标签的编号
对一个训练集的m个样本来说,我们可以定义如下等式来表达所有样本在特征张量X\boldsymbol{X}X和权重向量w\boldsymbol{w}w组成的预测函数中,预测出所有可能的y^\hat{y}y^的概率P为:
P=∏i=1mP(y^i∣xi,w)P = \prod_{i=1}^{m} P(\hat{y}_i | \boldsymbol{x}_i, \boldsymbol{w})P=i=1∏mP(y^i∣xi,w)
=∏i=1mPjyi(k=j)= \prod_{i=1}^{m} P_j^{y_{i(k=j)}}=i=1∏mPjyi(k=j)
=∏i=1mσjyi(k=j)= \prod_{i=1}^{m} \sigma_j^{y_{i(k=j)}}=i=1∏mσjyi(k=j)
这就是多分类状况下的似然函数。与二分类一致,似然函数解出来后,我们需要对似然函数求对数:
lnP=ln∏i=1mσjyi(k=j)\ln P = \ln \prod_{i=1}^{m} \sigma_j^{y_{i(k=j)}}lnP=lni=1∏mσjyi(k=j)
=∑i=1mln(σjyi(k=j))= \sum_{i=1}^{m} \ln(\sigma_j^{y_{i(k=j)}})=i=1∑mln(σjyi(k=j))
=∑i=1myi(k=j)lnσi= \sum_{i=1}^{m} y_{i(k=j)} \ln \sigma_i=i=1∑myi(k=j)lnσi
其中σ\sigmaσ就是softmax函数返回的对应类别的值。再对整个公式取负,就得到了多分类状况下的损失函数:
L(w)=−∑i=1myi(k=j)lnσiL(w) = - \sum_{i=1}^{m} y_{i(k=j)} \ln \sigma_iL(w)=−i=1∑myi(k=j)lnσi
这个函数就是我们之前提到过的交叉熵函数。不难看出,二分类的交叉熵函数其实是多分类的一种特殊情况。
L(w)=−∑i=1myi(k=j)⏟NLLLosslnσi⏟LogSoftmaxL(w) = \underbrace{- \sum_{i=1}^{m} y_{i(k=j)}}{\text{NLLLoss}} \underbrace{\ln \sigma_i}{\text{LogSoftmax}}L(w)=NLLLoss −i=1∑myi(k=j)LogSoftmax lnσi
交叉熵函数十分特殊,虽然我们求解过程中,取对数的操作是在确定了似然函数后才进行的,但从计算结果来看,对数操作其实只对softmax函数的结果σ\sigmaσ起效。因此在实际操作中,我们把ln(softmax(z))\ln(softmax(z))ln(softmax(z))这样的函数单独定义了一个功能做logsoftmax,PyTorch中可以直接通过nn.logsoftmax类调用这个功能。同时,我们把对数之外的,乘以标签、加和、取负等等过程打包起来,称之为负对数似然函数(Negative Log Likelihood function),在PyTorch中可以使用nn.NLLLoss来进行调用。也就是说,在计算损失函数时,我们不再需要使用单独的softmax函数了。
总结:
在多分类(KKK 个类别)中,我们通常使用 Softmax 函数将网络输出转化为所有类别的概率分布。多分类交叉熵(Cross Entropy)公式如下:
CE=−∑i=1Kyiln(y^i)CE = -\sum_{i=1}^{K} y_i \ln(\hat{y}_i)CE=−i=1∑Kyiln(y^i)
其中 yiy_iyi 为真实标签的 One-hot 编码(即:只有正确的类别位置上为 1,其余所有错误类别的位置上均为 0)。
由于除了正确类别之外的 yiy_iyi 都是 0,累加项中那些项直接被消除了,因此,在单个样本上该公式可以被极大地简化为:
CE=−ln(y^correct)CE = -\ln(\hat{y}_{correct})CE=−ln(y^correct)
核心物理意义:多分类交叉熵只关心模型对"正确类别"预测的概率。只要分配给正确类别的概率 y^correct\hat{y}_{correct}y^correct 越接近 1,−ln(1)-\ln(1)−ln(1) 就越接近 0,损失就越小;反之,如果分配给正确类别的概率极低,−ln(0)-\ln(0)−ln(0) 会趋近无穷大,产生巨大的惩罚。
3. KL散度 (KL Divergence)
作用:衡量两个分布之间的距离。
-
特性: 恒大于0,且具有不对称性 。
-
核心公式: DKL(p∣∣q)=H(p,q)−H(p)D_{KL}(p||q)=H(p,q)-H(p)DKL(p∣∣q)=H(p,q)−H(p) 。
参数:
- H(p)H(p)H(p) (信息熵) :表示真实分布 ppp 固有的不确定性。在信息论中,它代表完美无缺地编码真实分布 ppp 所需的最少信息量。
- H(p,q)H(p,q)H(p,q) (交叉熵) :表示如果我们用预测分布(或次优分布)qqq 去近似编码真实分布 ppp 的数据时,所需要的平均信息量。
含义总结 :因为 qqq 不是真正的 ppp,所以用 qqq 去编码一定会浪费一些资源。这个"额外浪费的信息量"就是 KL散度。它衡量了分布 qqq 在拟合分布 ppp 时,到底"损失"了多少信息。
-
离散值 : DKL(p∥q)=∑xp(x)logp(x)q(x)D_{KL}(p \parallel q) = \sum_x p(x)\log \frac{p(x)}{q(x)}DKL(p∥q)=∑xp(x)logq(x)p(x)
-
连续值 : DKL(p∥q)=∫xp(x)logp(x)q(x)dxD_{KL}(p \parallel q) = \int_x p(x)\log \frac{p(x)}{q(x)} dxDKL(p∥q)=∫xp(x)logq(x)p(x)dx
三. 逻辑回归与 Sigmoid 函数
1. Sigmoid 函数
Sigmoid 函数是逻辑回归的核心,它能够将线性回归的连续输出映射到 (0,1)(0, 1)(0,1) 的概率区间内。
-
函数公式: σ(z)=11+e−z\sigma(z)=\frac{1}{1+e^{-z}}σ(z)=1+e−z1
-
导数性质: σ′(z)=σ(z)⋅(1−σ(z))\sigma^{\prime}(z)=\sigma(z)\cdot(1-\sigma(z))σ′(z)=σ(z)⋅(1−σ(z))
2. 模型输出与对数几率
-
概率预测: 模型预测样本为正类的概率为 pθ(y(i)=1∣x(i))=σ(ΘTx(i))=11+e−ΘTx(i)p_{\theta}(y^{(i)}=1|x^{(i)}) = \sigma(\Theta^{T}x^{(i)}) = \frac{1}{1+e^{-\Theta^{T}x^{(i)}}}pθ(y(i)=1∣x(i))=σ(ΘTx(i))=1+e−ΘTx(i)1 。
-
对数几率 (Log-odds): 逻辑回归实际上是在用线性回归逼近"对数几率",公式推导为 ln(y1−y)=z=ΘTx\ln(\frac{y}{1-y}) = z = \Theta^{T}xln(1−yy)=z=ΘTx 。
四. 损失函数与模型训练
1. 统一损失函数
作用:基于交叉熵,将正例和负例的损失函数整合为一个统一的公式。
-
当真实标签 y=1y=1y=1 时,损失为 −1⋅logpθ(y=1∣x)=−logσ(ΘTx)-1\cdot \log p_{\theta}(y=1|x)=-\log \sigma(\Theta^{T}x)−1⋅logpθ(y=1∣x)=−logσ(ΘTx) 。
-
当真实标签 y=0y=0y=0 时,损失为 −1⋅logpθ(y=0∣x)=−log(1−σ(ΘTx))-1\cdot \log p_{\theta}(y=0|x)=-\log(1-\sigma(\Theta^{T}x))−1⋅logpθ(y=0∣x)=−log(1−σ(ΘTx)) 。
-
单样本统一公式: J(Θ)=−y⋅logσ(ΘTx)−(1−y)⋅log(1−σ(ΘTx))J(\Theta)=-y\cdot \log \sigma(\Theta^{T}x)-(1-y)\cdot \log(1-\sigma(\Theta^{T}x))J(Θ)=−y⋅logσ(ΘTx)−(1−y)⋅log(1−σ(ΘTx)) 。
2. 总体损失与梯度下降
-
mmm 个样本的平均损失: J(Θ)=−1m∑i=1my(i)⋅logσ(ΘTx(i))+(1−y(i))⋅log(1−σ(ΘTx(i)))J(\Theta)=-\frac{1}{m}\sum_{i=1}^{m}y^{(i)}\cdot \log \sigma(\Theta^{T}x^{(i)})+(1-y^{(i)})\cdot \log(1-\sigma(\Theta^{T}x^{(i)}))J(Θ)=−m1∑i=1my(i)⋅logσ(ΘTx(i))+(1−y(i))⋅log(1−σ(ΘTx(i))) 。
-
优化方法: 由于该损失函数很难通过解析法直接求解,通常采用梯度下降法进行迭代优化 。
-
梯度推导结果: 经过链式法则求导,参数更新的梯度公式为 ∂J∂θj=1m∑i=1m(hθ(x(i))−y(i))xj(i)\frac{\partial J}{\partial\theta_{j}} = \frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}∂θj∂J=m1∑i=1m(hθ(x(i))−y(i))xj(i) 。
五. 决策边界与正则化
1. 决策边界
作用:划分正负类的分界线或分界面。
判定规则:
-
ΘTx≥0\Theta^{T}x\ge0ΘTx≥0 时,预测为正类 。
-
ΘTx<0\Theta^{T}x<0ΘTx<0 时,预测为负类 。
-
ΘTx=0\Theta^{T}x=0ΘTx=0 即为决策边界 。
ΘTx\Theta^{T}xΘTx对应一个平面
- 非线性决策边界: 如果数据线性不可分,可以通过构建非线性回归模型(引入多项式特征),如 pθ(x)=σ(θ0x1+θ2x1x2+θ3x12+⋅⋅⋅)p_{\theta}(x)=\sigma(\theta_{0}x_{1}+\theta_{2}x_{1}x_{2}+\theta_{3}x_{1}^{2}+\cdot\cdot\cdot)pθ(x)=σ(θ0x1+θ2x1x2+θ3x12+⋅⋅⋅) 来拟合复杂的决策边界 。
2. 正则化
作用:防止模型过拟合(Over-fitting),提高泛化能力。
-
原理: 谁的数值大,就狠狠地惩罚谁,逼迫所有参数的数值尽可能变小。因为数值极大的参数总是附着在高次项上的,所有正则化可以减少高次项参数的值,使得拟合出的决策曲线更加平滑 。
-
加入 L2 正则化的损失函数: J(Θ)=−1m∑i=1my(i)⋅logσ(ΘTx(i))+(1−y(i))⋅log(1−σ(ΘTx(i)))+λ2mθTΘJ(\Theta) = -\\frac{1}{m}\\sum_{i=1}\^{m}y\^{(i)}\\cdot \\log \\sigma(\\Theta\^{T}x\^{(i)})+(1-y\^{(i)})\\cdot \\log(1-\\sigma(\\Theta\^{T}x\^{(i)}))+\frac{\lambda}{2m}\theta^{T}\ThetaJ(Θ)=−m1∑i=1my(i)⋅logσ(ΘTx(i))+(1−y(i))⋅log(1−σ(ΘTx(i)))+2mλθTΘ 。
参数:
-
J(Θ)J(\Theta)J(Θ) :代价函数 / 目标函数 (Cost Function)。
-
mmm :训练样本总数 。公式前面的 1m\frac{1}{m}m1 是为了求所有样本误差的平均值,使得代价函数的值不会因为样本数量的增加而无限放大。
-
iii :样本索引 。带有上标 (i)(i)(i) 的变量代表这是训练集中的第 iii 个数据样本。
-
y(i)y^{(i)}y(i) :第 iii 个样本的真实标签 。在二分类问题中,取值只能是 000 (负类)或 111 (正类)。
-
x(i)x^{(i)}x(i) :第 iii 个样本的**特征向量。代表输入数据的各个特征维度,通常还会包含一个恒为 111 的截距项特征 x0(i)x_0^{(i)}x0(i)。
-
Θ\ThetaΘ :模型的参数向量/权重向量 。包含了 θ0,θ1,...,θn\theta_0, \theta_1, \dots, \theta_nθ0,θ1,...,θn,是模型需要学习的核心变量。ΘTx(i)\Theta^{T}x^{(i)}ΘTx(i) 即为特征与权重的线性组合。
-
σ()\sigma()σ() :Sigmoid 函数 。形式为 σ(z)=11+e−z\sigma(z) = \frac{1}{1+e^{-z}}σ(z)=1+e−z1,用于将线性输出 ΘTx(i)\Theta^{T}x^{(i)}ΘTx(i) 映射到 (0,1)(0, 1)(0,1) 区间内,赋予其概率的物理意义。
-
σ(ΘTx(i))\sigma(\Theta^{T}x^{(i)})σ(ΘTx(i)) :模型对第 iii 个样本属于正类(y=1y=1y=1)的预测概率 。通常也可以简写为 y^(i)\hat{y}^{(i)}y^(i)。
-
λ\lambdaλ :正则化系数 (Regularization Parameter) 。这是一个超参数,用于控制模型正则化(惩罚过大参数)的力度。λ\lambdaλ 越大,防过拟合力度越强(但也容易导致欠拟合);λ\lambdaλ 为 000 时,则完全没有正则化。
-
θTΘ\theta^{T}\ThetaθTΘ :L2 正则化项(惩罚项) 。本质上等于模型权重的平方和(即 ∑j=1nθj2\sum_{j=1}^{n}\theta_j^2∑j=1nθj2)。公式除以 2m2m2m 是为了求导时能抵消掉平方产生的系数 222,方便计算。
重要注意: 在标准的逻辑回归正则化中,偏置项(截距)θ0\theta_0θ0 是不参与惩罚的 。因此公式这里特意用小写 θ\thetaθ 与大写 Θ\ThetaΘ 做了区分(或默认为去除 θ0\theta_0θ0 后的参数向量内积),实际计算的应是 ∑j=1nθj2\sum_{j=1}^{n}\theta_j^2∑j=1nθj2 而不是从 j=0j=0j=0 开始。
-
六. 多分类问题 (Multi-class Classification)
逻辑回归可以通过扩展来解决诸如图像识别(如识别猫、狗、小鸡)或天气预测等多分类任务。
1. 多个二分类模型组合 (One-vs-All)
-
思路: 基于基础逻辑回归,对每一个类别训练一个二分类模型(判断"是该类"与"不是该类") 。
-
预测: 将样本输入所有训练好的模型中,选择预测概率值最大的那个类作为最终输出 。
2. Softmax 直接输出多分类分布
-
思路: 将网络的输出层替换为 Softmax 层,直接输出样本属于各个类别的概率分布 。
-
Softmax 公式:
Softmax(zk)=ezk∑i=1KeziSoftmax(z_k) = \frac{e^{z_k}}{\sum_{i=1}^K e^{z_i}}Softmax(zk)=∑i=1Keziezk
(其中 KKK 是总类别数,zkz_kzk 是第 kkk 个类别的线性得分)
-
性质: 确保所有类别的输出概率在 (0,1)(0, 1)(0,1) 之间,且概率总和严格等于 1,即 Σiyi=1\Sigma_{i}y_{i}=1Σiyi=1 。