文章目录
-
- 背景
- 先说结论
- 一、文本模型:Agnes-2.0-Flash
- 二、轻量文本模型:Agnes-1.5-Flash
-
- 定位
- 完整参数表
- 多模态消息格式(文本+图像)
- [API 信息](#API 信息)
- 模型限制
- [与 2.0-Flash 的关键区别](#与 2.0-Flash 的关键区别)
- 使用建议
- [三、图像模型:Agnes Image 2.1 Flash](#三、图像模型:Agnes Image 2.1 Flash)
- [四、图像模型:Agnes Image 2.0-Flash](#四、图像模型:Agnes Image 2.0-Flash)
- [五、视频模型:Agnes Video V2.0](#五、视频模型:Agnes Video V2.0)
- 六、全模型参数速查对照
-
- 公共参数
- [各模型 Endpoint 汇总](#各模型 Endpoint 汇总)
- 各模型价格汇总(现价均为免费)
- 七、快速上手代码示例
-
- [Python 文本调用](#Python 文本调用)
- [Python 图像调用](#Python 图像调用)
- [Python 视频调用(异步)](#Python 视频调用(异步))
- 八、总结
背景
周一的时候看到了一篇公众号推文,

所以就趁着这个机会去试了下。
官网参考:agnes-ai


使用方式很简单,注册一个账号,然后获取api key,其余和前面介绍的LLM使用方式一致。
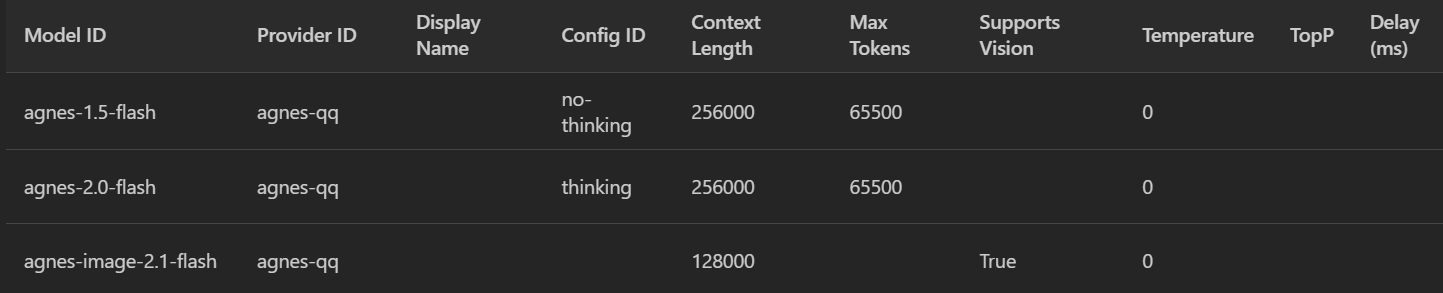
model方面的话,暂时就下面这么5个
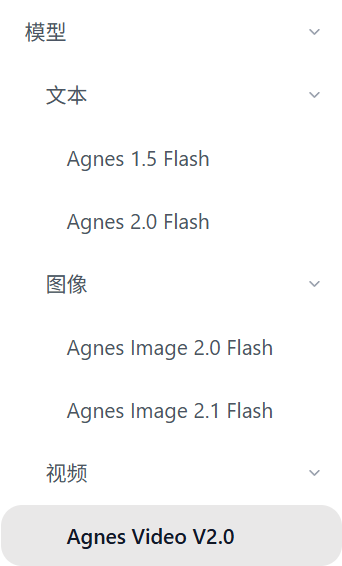
我也一并按照前面介绍过的方式,在claude code以及copilot oai中接入了(可以参考我前面的博客)。
我试了一下几个任务,还是挺不错的,至少生成速度很快
目前作为我的备用方案,调整如下:
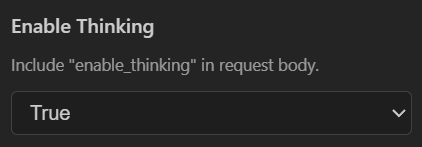
- 2.0 flash:开thinking(在oai的advanced settings中设置),目前用于coding、agent任务,主力
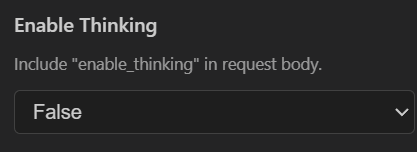
- 1.5 flash:没有thinking,但是多模态,作为简单的文本问答+图片简单解析,即问即答
- 其余的model我暂时没有深度需求
配置方式下图是copilot中调用,还是参考我之前的博客:Vscode LLM备用方案
先说结论
Agnes AI 将旗下全部核心模型 API 无限期免费开放 。不是试水某个模型,而是文本、图像、视频三个模态一次性打包。本文按模型逐一拆解,重点讲清楚每个参数什么意思、怎么设、什么场景用什么值。
一、文本模型:Agnes-2.0-Flash
定位
面向智能体工作流、工具调用、编程、推理的生产级语言模型。Claw-Eval 基准测试 General Leaderboard 排名第 9,Pass^3 分数 60.9%。
完整参数表
基础请求参数
| 参数 | 类型 | 必填 | 说明 | 推荐值 |
|---|---|---|---|---|
model |
string | ✅ | 模型名称,固定为 agnes-2.0-flash |
agnes-2.0-flash |
messages |
array | ✅ | 对话消息数组,每个元素含 role 和 content |
--- |
temperature |
number | ❌ | 控制输出随机性。0=完全确定,1=最大随机 | 确定性任务 0.1-0.3,创意任务 0.7-0.9 |
top_p |
number | ❌ | 核采样阈值。0.1=只考虑高概率token,1.0=不限制 | 默认 1.0,需要稳定输出可设 0.9 |
max_tokens |
number | ❌ | 响应最多生成的 token 数 | 根据任务设定,一般 1024-4096 |
stream |
boolean | ❌ | 是否启用流式输出。true=逐块返回,false=一次性返回 | 实时交互场景用 true |
tools |
array | ❌ | 工具定义数组,用于 function calling | 见下方工具定义格式 |
tool_choice |
string/object | ❌ | 控制模型是否/如何使用工具。auto=自动选择,none=不调用,{"type":"function","function":{"name":"xxx"}}=强制调用某个工具 |
auto 为默认 |
messages 消息格式
json
{
"role": "system" | "user" | "assistant",
"content": "消息内容"
}- system:设定角色和行为准则,放在消息数组最前面
- user:用户输入
- assistant:模型回复,用于多轮对话上下文
tools 工具定义格式
json
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取某地点的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和国家"
}
},
"required": ["location"]
}
}
}Thinking 模式参数
针对编程、调试、推理、Agent 工作流,开启深度思考可显著提升质量。
OpenAI 兼容格式:
json
{
"model": "agnes-2.0-flash",
"messages": [...],
"chat_template_kwargs": {
"enable_thinking": true
}
}Anthropic 兼容格式:
json
{
"model": "agnes-2.0-flash",
"messages": [...],
"thinking": {
"type": "enabled",
"budget_tokens": 2048
}
}| 参数 | 说明 | 建议 |
|---|---|---|
enable_thinking |
是否开启深度思考 | 编程/推理任务设为 true |
type |
固定为 "enabled" |
--- |
budget_tokens |
最大思考 token 预算 | 简单任务 2048,复杂调试/多步骤 Agent 任务可提高到 4096-8192 |
API 信息
plain
Endpoint: https://apihub.agnes-ai.com/v1/chat/completions
Method: POST
Content-Type: application/json
Auth: Authorization: Bearer YOUR_API_KEY模型限制
| 项目 | 数值 |
|---|---|
| Context Window | 256K |
| Max Output | 65.5K |
响应格式详解
json
{
"id": "chatcmpl_xxx", // 本次请求唯一 ID,用于追踪
"object": "chat.completion", // 对象类型
"created": 1774432125, // 请求时间戳(Unix 秒)
"model": "agnes-2.0-flash", // 使用的模型
"choices": [ // 生成结果列表
{
"index": 0, // 结果索引(多候选时有用)
"message": {
"role": "assistant", // 角色固定为 assistant
"content": "模型生成的内容"
},
"finish_reason": "stop" // 停止原因:stop=正常结束,length=max_tokens 触发,tool_calls=触发了工具调用
}
],
"usage": {
"prompt_tokens": 35, // 输入 token 数
"completion_tokens": 58, // 输出 token 数
"total_tokens": 93 // 总计
}
}使用建议
- Prompt 结构 :
[角色] + [任务] + [上下文] + [要求] + [输出格式] - temperature:代码生成/调试用 0.1-0.3,文案创作用 0.7-0.9
- stream:需要实时反馈的场景(如聊天机器人)设为 true
- Thinking:编程任务务必开启,budget_tokens 从 2048 起步
二、轻量文本模型:Agnes-1.5-Flash
定位
低延迟、高并发、低成本场景的轻量模型。支持文本+图像多模态输入。
完整参数表
| 参数 | 类型 | 必填 | 说明 | 推荐值 |
|---|---|---|---|---|
model |
string | ✅ | 固定为 agnes-1.5-flash |
--- |
messages |
array | ✅ | 对话消息数组 | --- |
temperature |
number | ❌ | 采样温度,控制随机性 | 0.5-0.8 |
top_p |
number | ❌ | 核采样概率 | 默认 1.0 |
max_tokens |
integer | ❌ | 最大生成 token 数 | 根据任务设定 |
frequency_penalty |
number | ❌ | 频率惩罚,减少重复内容。范围通常 -2.0~2.0,正值降低重复 | 0.0-0.5 |
presence_penalty |
number | ❌ | 存在惩罚,鼓励引入新话题。范围通常 -2.0~2.0 | 0.0-0.5 |
repetition_penalty |
number | ❌ | 重复控制系数 | 1.0-1.2 |
stop |
string/array | ❌ | 自定义停止序列。遇到这些字符串就停止生成 | --- |
seed |
integer | ❌ | 随机种子,保证结果可复现 | 固定值可复现 |
多模态消息格式(文本+图像)
json
{
"role": "user",
"content": [
{
"type": "text",
"text": "描述这张图片"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.jpg"
}
}
]
}type: "text":纯文本内容type: "image_url":图像 URL,模型会理解图像内容并与文本联合响应
API 信息
plain
Endpoint: https://apihub.agnes-ai.com/v1/chat/completions
Method: POST
Auth: Bearer Token模型限制
| 项目 | 数值 |
|---|---|
| Context Window | 256K |
| Max Output | 65.5K |
与 2.0-Flash 的关键区别
| 维度 | 1.5-Flash | 2.0-Flash |
|---|---|---|
| 侧重 | 速度、成本 | 推理、Agent、编程 |
| 多模态输入 | ✅ 文本+图像 | ❌ 纯文本 |
| Thinking 模式 | ❌ | ✅ |
| 工具调用 | ❌ | ✅ |
| frequency/presence_penalty | ✅ 支持 | ❌ 不支持 |
| 价格 | 0.07/ 0.15 per 1M tokens | 0.1/ 0.2 per 1M tokens |
使用建议
- 图像理解 :用
content数组同时传入文本和图像 URL,模型会联合理解 - 高并发场景:1.5-Flash 的量化技术降低了计算资源需求,适合批量处理
- 需要复现结果 :设置固定
seed值
三、图像模型:Agnes Image 2.1 Flash
定位
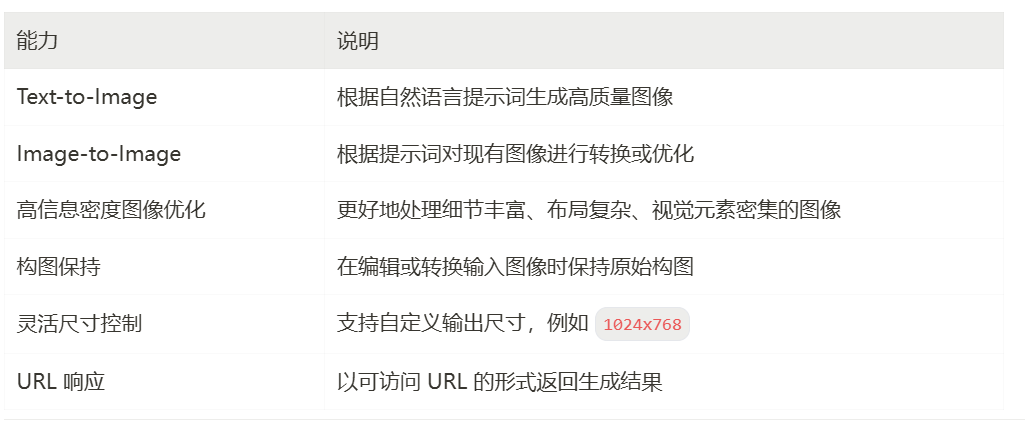
升级版图像生成模型,文生图 + 图生图 ,重点优化了高信息密度图像的生成质量。
完整参数表
文生图请求参数
| 参数 | 类型 | 必填 | 说明 | 推荐值 |
|---|---|---|---|---|
model |
string | ✅ | 固定为 agnes-image-2.1-flash |
--- |
prompt |
string | ✅ | 图像生成的文本指令,描述想要的内容 | 越详细越好 |
size |
string | ❌ | 输出图像尺寸 | 1024x768 等 |
extra_body |
object | ❌ | 高级工作流的额外参数 | 见下方 |
extra_body 参数(图生图)
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
extra_body.image |
array | 图生图时✅ | 输入图像 URL 数组,图生图任务的源图像 |
extra_body.response_format |
string | ❌ | 响应格式,url=返回图像 URL |
API 信息
plain
Endpoint: https://apihub.agnes-ai.com/v1/images/generations
Method: POST
Auth: Bearer Token
Price: $0/image(免费)Prompt 结构详解
plain
[主体] + [场景/环境] + [风格] + [光照] + [构图] + [质量要求]| 组成部分 | 说明 | 示例 |
|---|---|---|
| 主体 | 画面的核心对象 | A luminous floating city |
| 场景/环境 | 主体所处的环境 | above a misty canyon at sunrise |
| 风格 | 艺术风格 | cinematic realism |
| 光照 | 光线效果 | soft golden light |
| 构图 | 画面布局 | wide-angle composition |
| 质量要求 | 细节程度 | high visual density |
图生图 Prompt 结构
plain
[需要改变什么] + [需要保持什么不变]示例:Transform the scene into a rain-soaked cyberpunk night with neon reflections while preserving the original composition and main subject layout.
高信息密度图像技巧
2.1-Flash 针对复杂场景做了专项优化。Prompt 中需要清晰描述:
- 主体:画面核心对象
- 背景:远景元素
- 环境:氛围、天气、时间
- 重要细节:关键视觉元素
- 次要细节:丰富画面层次
- 风格与光照:整体调性
- 构图限制:视角、比例
使用建议
- 文生图:用详细 prompt,包含所有 6 个组成部分
- 图生图:明确说明"改什么"和"保什么"
- 高密度场景:逐层描述视觉元素,不要遗漏重要细节
四、图像模型:Agnes Image 2.0-Flash
定位
高性能图像编辑与生成模型,支持图生图 + 多图合成。Artificial Analysis Image Editing Leaderboard ELO 1,184(Top 20)。
完整参数表
| 参数 | 类型 | 必填 | 说明 | 推荐值 |
|---|---|---|---|---|
model |
string | ✅ | 固定为 agnes-image-2.0-flash |
--- |
prompt |
string | ✅ | 图像编辑/生成的文本提示词 | --- |
size |
string | ❌ | 输出图像尺寸 | 1024x768、1024x1024、768x1024 |
seed |
number | ❌ | 随机种子,保证结果可复现 | 固定值可复现 |
tags |
array | ❌ | 任务类型标记 | ["img2img"] 表示图生图 |
extra_body.image |
array | 图生图时✅ | 输入图像 URL 数组 | --- |
extra_body.response_format |
string | ❌ | 输出格式 | url |
关键参数说明
tags: ["img2img"]:图生图任务必须添加此标记,否则模型会当作文生图处理extra_body.image:可传单张或多张图像 URL。多图时会将多张图合成为一张新图像seed:设置固定值可复现相同结果,适合需要迭代优化的场景
API 信息
plain
Endpoint: https://apihub.agnes-ai.com/v1/images/generations
Method: POST
Auth: Bearer Token
Price: $0/image(免费)响应格式
json
{
"created": 1774432125,
"data": [
{
"url": "https://..."
}
],
"usage": {
"generated_images": 1
}
}与 2.1-Flash 的选择建议
| 需求 | 选哪个 |
|---|---|
| 从零生成复杂场景 | 2.1-Flash(高信息密度优化) |
| 编辑现有图像 | 2.0-Flash(图生图专精) |
| 多图合成 | 2.0-Flash(支持多参考图) |
| 需要 seed 复现 | 2.0-Flash(支持 seed 参数) |
五、视频模型:Agnes Video V2.0
定位
下一代电影级视频生成模型,支持文生视频、图生视频、多图视频、关键帧动画四种工作流。
完整参数表
创建视频任务参数
| 参数 | 类型 | 必填 | 说明 | 推荐值 |
|---|---|---|---|---|
model |
string | ✅ | 固定为 agnes-video-v2.0 |
--- |
prompt |
string | ✅ | 视频内容的文本描述 | --- |
image |
string/array | ❌ | 输入图片 URL 或 URL 数组 | 图生视频时必填 |
mode |
string | ❌ | 生成模式 | ti2vid(文生视频)或 keyframes(关键帧) |
height |
integer | ❌ | 视频高度 | 768 |
width |
integer | ❌ | 视频宽度 | 1152 |
num_frames |
integer | ❌ | 视频总帧数 | 见下方约束 |
num_inference_steps |
integer | ❌ | 推理步数 | 默认值即可 |
seed |
integer | ❌ | 随机种子,保证可复现 | 固定值可复现 |
frame_rate |
number | ❌ | 视频 FPS | 1-60,推荐 24 |
negative_prompt |
string | ❌ | 负向提示词,描述要避免的内容 | --- |
extra_body.image |
array | 多图/关键帧时✅ | 多图或关键帧的输入图片 URL | --- |
extra_body.mode |
string | 关键帧时✅ | 额外模式设置 | "keyframes" |
num_frames 约束(重要!)
plain
num_frames 必须满足两个条件:
1. num_frames ≤ 441
2. num_frames = 8n + 1(n 为正整数)
合法值:81, 121, 161, 201, 241, 281, 321, 361, 401, 441
非法值:100, 150, 200, 300 等视频时长计算
plain
seconds = num_frames / frame_rate| 目标时长 | num_frames | frame_rate | 实际时长 |
|---|---|---|---|
| 约 3 秒 | 81 | 24 | 3.375s |
| 约 5 秒 | 121 | 24 | 5.042s |
| 约 6 秒 | 161 | 24 | 6.708s |
| 约 10 秒 | 241 | 24 | 10.042s |
| 约 18 秒 | 441 | 24 | 18.375s |
调整策略:
- 想要更长的视频 → 降低
frame_rate(如 12fps) - 想要更流畅的画面 → 提高
frame_rate(如 30fps),但时长会变短
异步任务工作流
视频生成是异步的,分两步:
Step 1:创建任务
plain
POST https://apihub.agnes-ai.com/v1/videos返回:
json
{
"id": "task_xxx",
"task_id": "task_xxx",
"object": "video",
"model": "agnes-video-v2.0",
"status": "queued", // 任务状态
"progress": 0, // 进度 0-100
"created_at": 1780457477, // 创建时间戳
"seconds": "10.0", // 预计时长
"size": "1280x768" // 分辨率
}Step 2:轮询结果
plain
GET https://apihub.agnes-ai.com/v1/videos/{task_id}返回(完成时):
json
{
"id": "task_xxx",
"model": "agnes-video-v2.0",
"object": "video",
"status": "completed", // 任务状态
"progress": 100,
"seconds": "10.0",
"size": "1280x768",
"error": null,
"remixed_from_video_id": "https://storage.../video_xxxxxx.mp4" // 视频 URL
}任务状态说明
| 状态 | 说明 | 下一步 |
|---|---|---|
queued |
排队等待中 | 继续轮询 |
in_progress |
正在生成中 | 继续轮询 |
completed |
生成完成 | 从 remixed_from_video_id 获取视频 |
failed |
生成失败 | 检查 error 字段,调整参数重试 |
错误码
| 错误码 | 说明 | 处理 |
|---|---|---|
| 400 | 请求参数无效 | 检查参数格式和约束 |
| 401 | 未授权 | 检查 API Key |
| 404 | 任务不存在 | 检查 task_id |
| 500 | 服务器错误 | 稍后重试 |
| 503 | 服务繁忙 | 稍后重试 |
Prompt 结构详解
文生视频 :[主体] + [动作] + [场景] + [镜头运动] + [光照] + [风格]
图生视频:描述哪些内容需要运动,同时保持关键主体稳定
多图视频:描述输入图片之间的关系和过渡方式
关键帧动画:清晰描述帧与帧之间的过渡关系
参数推荐配置
| 场景 | width | height | num_frames | frame_rate |
|---|---|---|---|---|
| 标准视频 | 1152 | 768 | 121 | 24 |
| 短视频(社交) | 1152 | 768 | 81 或 121 | 24 |
| 更流畅运动 | 1152 | 768 | 121 | 30 |
| 可复现结果 | --- | --- | --- | 设置固定 seed |
| 关键帧过渡 | --- | --- | --- | extra_body.mode: "keyframes" |
API 信息
plain
创建任务: POST https://apihub.agnes-ai.com/v1/videos
查询结果: GET https://apihub.agnes-ai.com/v1/videos/{task_id}
Auth: Bearer Token
Price: $0/second(免费)六、全模型参数速查对照
公共参数
| 参数 | 2.0-Flash | 1.5-Flash | Image 2.1 | Image 2.0 | Video V2.0 |
|---|---|---|---|---|---|
model |
✅ | ✅ | ✅ | ✅ | ✅ |
messages |
✅ | ✅ | ❌ | ❌ | ❌ |
prompt |
❌ | ❌ | ✅ | ✅ | ✅ |
temperature |
✅ | ✅ | ❌ | ❌ | ❌ |
top_p |
✅ | ✅ | ❌ | ❌ | ❌ |
max_tokens |
✅ | ✅ | ❌ | ❌ | ❌ |
seed |
❌ | ✅ | ❌ | ✅ | ✅ |
stream |
✅ | ❌ | ❌ | ❌ | ❌ |
size |
❌ | ❌ | ✅ | ✅ | ❌ |
image |
❌ | ❌ | extra_body | extra_body | ✅ / extra_body |
tools |
✅ | ❌ | ❌ | ❌ | ❌ |
thinking |
✅ | ❌ | ❌ | ❌ | ❌ |
num_frames |
❌ | ❌ | ❌ | ❌ | ✅ |
frame_rate |
❌ | ❌ | ❌ | ❌ | ✅ |
negative_prompt |
❌ | ❌ | ❌ | ❌ | ✅ |
各模型 Endpoint 汇总
| 模型 | Endpoint |
|---|---|
| 文本(2.0/1.5) | POST /v1/chat/completions |
| 图像(2.1/2.0) | POST /v1/images/generations |
| 视频 V2.0 | POST /v1/videos → GET /v1/videos/{task_id} |
各模型价格汇总(现价均为免费)
| 模型 | 输入价格 | 输出价格 | 其他 |
|---|---|---|---|
| 2.0-Flash | 0.1/1M → 0 | 0.2/1M → 0 | --- |
| 1.5-Flash | 0.07/1M → 0 | 0.15/1M → 0 | --- |
| Image 2.1 | --- | --- | 0.003/image → 0 |
| Image 2.0 | --- | --- | 0.003/image → 0 |
| Video V2.0 | --- | --- | 0.005/second → 0 |
七、快速上手代码示例
Python 文本调用
python
import httpx
response = httpx.post(
"https://apihub.agnes-ai.com/v1/chat/completions",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "agnes-2.0-flash",
"messages": [{"role": "user", "content": "Hello"}],
"temperature": 0.7,
"max_tokens": 1024,
"stream": False,
}
)
print(response.json()["choices"][0]["message"]["content"])Python 图像调用
python
response = httpx.post(
"https://apihub.agnes-ai.com/v1/images/generations",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "agnes-image-2.1-flash",
"prompt": "A floating city above a misty canyon at sunrise",
"size": "1024x768",
}
)
print(response.json()["data"][0]["url"])Python 视频调用(异步)
python
# Step 1: 创建任务
create_resp = httpx.post(
"https://apihub.agnes-ai.com/v1/videos",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "agnes-video-v2.0",
"prompt": "A cinematic shot of a cat walking on the beach at sunset",
"height": 768,
"width": 1152,
"num_frames": 121,
"frame_rate": 24,
}
)
task_id = create_resp.json()["task_id"]
# Step 2: 轮询结果
import time
while True:
result = httpx.get(
f"https://apihub.agnes-ai.com/v1/videos/{task_id}",
headers={"Authorization": "Bearer YOUR_API_KEY"}
)
data = result.json()
if data["status"] == "completed":
print(data["remixed_from_video_id"])
break
elif data["status"] == "failed":
print("Failed:", data.get("error"))
break
time.sleep(5) # 每 5 秒轮询一次八、总结
| 模型 | 核心优势 | 关键参数 | 适合谁 |
|---|---|---|---|
| 2.0-Flash | Agent、编程、推理 | tools, thinking, stream | 开发者、AI 工程师 |
| 1.5-Flash | 低延迟、多模态输入 | frequency_penalty, seed | 高并发、图像理解 |
| Image 2.1 | 高信息密度文生图 | prompt, size | 设计师、内容创作者 |
| Image 2.0 | 图像编辑、多图合成 | tags, seed, image | 视觉设计师、电商 |
| Video V2.0 | 电影级视频、运镜控制 | num_frames, frame_rate, mode | 视频创作者、广告 |
一句话:一个 API Key,五种模型,文本→图像→视频全链路打通,全部免费。参数虽多,但按场景选对组合,几分钟就能跑通第一个 Demo。