目录
[2.5、使用 Systemd 管理ES服务(开机自启)](#2.5、使用 Systemd 管理ES服务(开机自启))
3.2、修改application.properties配置
4.3、增加TraceId过滤器(Http请求线程打入TraceId)
4.5、新增TraceResponseAdvice,返回对象Resp中设置traceId
[六、扩展: 雪花算法中workerId怎么取](#六、扩展: 雪花算法中workerId怎么取)
在我们实际的项目开发过程中,服务日志从收集、索引及查询也是非常重要的一环,本篇给大家介绍下一款非常优秀的日志收集、处理框架plumeLog
一、plumeLog是什么
参考官网:README
1、plume是无代码入侵的分布式日志系统,基于log4j、log4j2、logback搜集日志,设置链路ID,2、方便查询关联日志
3、基于elasticsearch作为查询引擎
4、高吞吐,查询效率高
5、全程不占应用程序本地磁盘空间,免维护;对于项目透明,不影响项目本身运行
6、无需修改老项目,引入直接使用,支持dubbo,支持springcloud
二、ES搭建
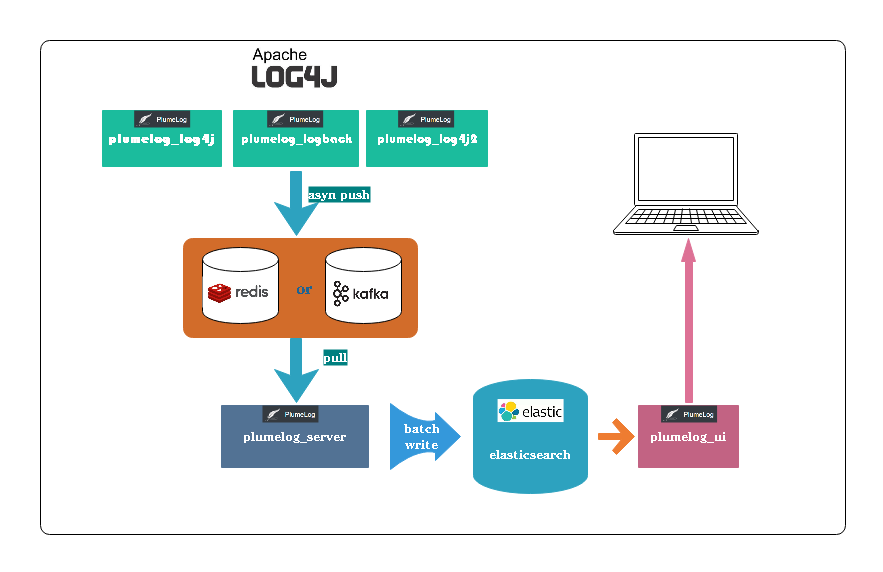
从plumeLog的架构图上我们得知,日志的底层存储是依赖ES的,我们先最底层开始搭建起,先搭建ES,笔者采用的是elasticsearch7.x的版本。
2.1、下载ES安装包安装
下载安装包(若已上传至服务器可跳过)
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.1-linux-x86_64.tar.gz
解压文件
tar -zxvf elasticsearch-7.10.1-linux-x86_64.tar.gz
移动到 /usr/local/ 目录并重命名
mv elasticsearch-7.10.1 /usr/local/elasticsearch
创建数据目录、日志目录
mkdir -p /data/es/data
mkdir -p /data/es/log
#创建es用户
groupadd elastic
useradd -g elastic elastic
将es目录所属主用户赋予给elastic用户
chown -R elastic:elastic /usr/local/elasticsearch
chown -R elastic:elastic /data/es
2.2、修改elasticsearch.yml配置
bash
cluster.name: my-application # 集群名称
node.name: node-1 # 节点名称
path.data: /var/data/elasticsearch # 数据存放路径
path.logs: /var/log/elasticsearch # 日志存放路径
network.host: 0.0.0.0 # 允许所有IP访问,生产环境建议设置具体IP
http.port: 9200 # 端口号
discovery.seed_hosts: ["127.0.0.1"] # 集群自动发现节点
discovery.type: single-node #单节点加上这项
#cluster.initial_master_nodes: ["node-1"] 如果是多节点则加上这项,指定默认初始化的主节点如果有内存限制,可以修改 JVM 配置文件 /usr/local/elasticsearch/config/jvm.options,一般建议设为物理内存的一半,且不超过 32GB
bash
# 修改 JVM 堆内存大小,根据你服务器内存情况调整(单位:m 或 g)
-Xms1g
-Xmx1g2.3、修改系统相关配置
1、修改文件描述符和用户进程限制,编辑 /etc/security/limits.conf 文件,在末尾添加:
bash
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 40962、修改虚拟内存区域最大数量,编辑 /etc/sysctl.conf 文件,在末尾添加:
bash
vm.max_map_count=262144完成后执行 sysctl -p 使配置立即生效
2.4、启动ES服务
切换到 elastic 用户,启动服务
bash
su elastic
cd /usr/local/elasticsearch/bin
./elasticsearch -d2.5、使用 Systemd 管理ES服务(开机自启)
创建服务文件 /etc/systemd/system/elasticsearch.service,这样可以用 systemctl 来管理,并支持开机自启
bash
[Unit]
Description=Elasticsearch
[Service]
User=elastic
ExecStart=/usr/local/elasticsearch/bin/elasticsearch
Restart=always
LimitNOFILE=65535
LimitNPROC=4096
[Install]
WantedBy=multi-user.target保存后执行以下命令,使之生效:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
在服务器本地执行以下命令测试:
bash
{
"name" : "node-1",
"cluster_name" : "my-application",
"cluster_uuid" : "_na_",
"version" : {
"number" : "7.10.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "1c34507e66d7db1211f66f3513706fdf548736aa",
"build_date" : "2020-12-05T01:00:33.671820Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}至此ES搭建完成 !
三、plumeLog-server搭建
plumeLog-server的搭建相对笔记简单,需要注意的是连接ES的地址要确保正确,我们采用最常见的redis队列模式,当然你也可以采用kafka作消息中间件。plumeLog-server笔者使用的是最新的3.5.3的版本。
3.1、下载安装包安装
下载地址:Plumelog
unzip plume-log-server-3.5.zip
mv plume-log-server-3.5 /usr/local #移动目录
3.2、修改application.properties配置
bash
plumelog.model=redis
plumelog.queue.redis.redisHost=localhost:6379
plumelog.queue.redis.redisPassWord=123456
plumelog.queue.redis.redisDb=11
#管理端redis地址 ,集群用逗号隔开,不配置将和队列公用
plumelog.redis.redisHost=127.0.0.1:6379
plumelog.redis.redisPassWord=123456
plumelog.redis.redisDb=11
elasticsearch相关配置,Hosts支持携带协议,如:http、https
plumelog.es.esHosts=localhost:9200
plumelog.es.shards=3
plumelog.es.replicas=1
plumelog.es.refresh.interval=30s
#日志索引建立方式day表示按天、hour表示按照小时
plumelog.es.indexType.model=day
plumelog.es.maxShards=100000
#ES设置密码,启用下面配置
plumelog.es.userName=elastic
plumelog.es.passWord=elastic3.3、启动服务
bash
cd /usr/local/plume-log-server-3.5
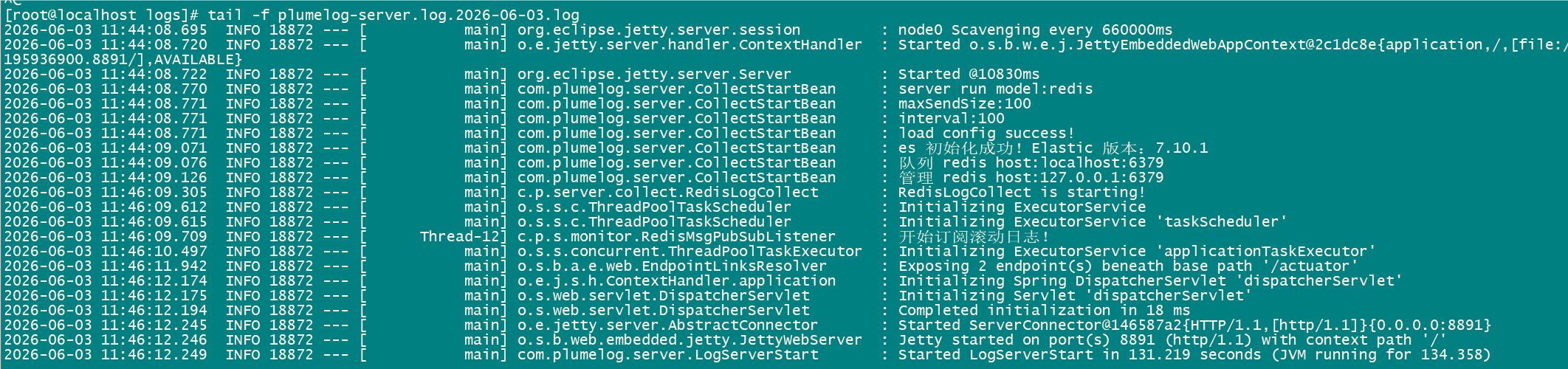
./startup.sh查看plumeLog服务日志:
四、springboot服务集成plumelog
4.1、项目引入pom.xml依赖
XML
<!-- 引入plumeLog -->
<dependency>
<groupId>com.plumelog</groupId>
<artifactId>plumelog-logback</artifactId>
<version>3.5.3</version>
</dependency>
<dependency>
<groupId>com.plumelog</groupId>
<artifactId>plumelog-trace</artifactId>
<version>3.5.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>4.2、项目logback-spring.xml配置
XML
<appender name="plumeLog" class="com.plumelog.logback.appender.RedisAppender">
<appName>tmccloud-merchant</appName>
<redisHost>192.168.31.111:6379</redisHost>
<redisAuth>123456</redisAuth>
<redisDb>11</redisDb>
<env>dev</env>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="ASYNC"/>
<appender-ref ref="errorLog" />
<!-- 加入plumeLog-->
<appender-ref ref="plumeLog"/>
</root>
4.3、增加TraceId过滤器(Http请求线程打入TraceId)
PlumeLogFilterConfig.java
java
import jakarta.servlet.Filter;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class PlumeLogFilterConfig {
@Bean
public FilterRegistrationBean filterRegistrationBean1() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(myTraceIdFilter());
filterRegistrationBean.addUrlPatterns("/*");
filterRegistrationBean.setOrder(Integer.MIN_VALUE);
return filterRegistrationBean;
}
@Bean
public Filter myTraceIdFilter() {
return new MyTraceIdFilter();
}
}MyTraceIdFilter.java
java
import cn.hutool.core.util.IdUtil;
import com.plumelog.core.TraceId;
import com.tingcream.tmccloud.base.worker.WorkerIdUtil;
import jakarta.servlet.*;
import jakarta.servlet.http.HttpServletRequest;
import java.io.IOException;
public class MyTraceIdFilter implements Filter {
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
try {
HttpServletRequest request = (HttpServletRequest)servletRequest;
String traceId = request.getParameter("traceId");
if (traceId != null && !"".equals(traceId)) {
TraceId.logTraceID.set(traceId);
} else {
//TraceId.set();
// 给当前线程打入traceId
long workerId = WorkerIdUtil.getWorkerIdByIp();
String id = IdUtil.getSnowflake(workerId, 0).nextIdStr();
TraceId.logTraceID.set(id);
}
} finally {
filterChain.doFilter(servletRequest, servletResponse);
}
}
public void destroy() {
}
}4.4、全局异常处理器改造
将Resp中设置TraceId, 方便搜索报错日志信息。
java
import com.plumelog.core.TraceId;
import com.tingcream.tmccloud.base.core.Resp;
import com.tingcream.tmccloud.base.exception.BusinessException;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.validation.ConstraintViolation;
import jakarta.validation.ConstraintViolationException;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.validation.BindException;
import org.springframework.validation.ObjectError;
import org.springframework.web.HttpRequestMethodNotSupportedException;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.servlet.resource.NoResourceFoundException;
import java.util.List;
/**
* 全局异常处理器
*/
@ControllerAdvice
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
/**
* JSR303 异常
* @param e
* @param request
* @return
*/
@ExceptionHandler({BindException.class})
public Resp<?> handleBindException(BindException e, HttpServletRequest request) {
log.error(e.getMessage());//记录完整错误信息
List<ObjectError> errors = e.getBindingResult().getAllErrors();
ObjectError err= errors.get(0);
String msg = err.getDefaultMessage();
Resp res= Resp.error(msg);
res.setTraceId(TraceId.logTraceID.get());
return res ;
}
/**
* JSR303 异常
* @param e
* @param request
* @return
*/
@ExceptionHandler({MethodArgumentNotValidException.class})
public Resp<?> handleMethodArgumentNotValidException(MethodArgumentNotValidException e, HttpServletRequest request) {
log.error(e.getMessage());//记录完整错误信息
List<ObjectError> errors = e.getBindingResult().getAllErrors();
ObjectError err= errors.get(0);
String msg = err.getDefaultMessage();
Resp res= Resp.error(msg);
res.setTraceId(TraceId.logTraceID.get());
return res ;
}
/**
* JSR303 异常
* @param e
* @param request
* @return
*/
@ExceptionHandler({ConstraintViolationException.class})
public Resp<?> handleConstraintViolationExceptionException(ConstraintViolationException e, HttpServletRequest request) {
log.error(e.getMessage());
ConstraintViolation c = (ConstraintViolation)e.getConstraintViolations().toArray()[0];
String msg =c.getMessage();
Resp res= Resp.error(msg);
res.setTraceId( TraceId.logTraceID.get());
return res ;
}
/**
* BusinessException 自定义业务异常处理
* @param e
* @param request
* @return
*/
@ExceptionHandler({BusinessException.class})
public Resp<?> handleBusinessException(BusinessException e, HttpServletRequest request) {
//返回自定义的状态code和msg
log.error(e.getMsg());
Resp res= new Resp<>(e.getCode(), e.getMsg(), e.getData());
res.setTraceId( TraceId.logTraceID.get());
return res ;
}
/**
* Exception 异常
* @param e
* @param request
* @return
*/
@ExceptionHandler({Exception.class})
public Resp<?> handleException(Exception e, HttpServletRequest request) {
log.error(e.getMessage(),e);
Resp res;
if(e instanceof HttpRequestMethodNotSupportedException){
res= Resp.error("客户端http请求方式有误,请检查!");
}else{
res= Resp.error("抱歉,系统异常!");
}
res.setTraceId( TraceId.logTraceID.get());
return res ;
}
@ExceptionHandler(NoResourceFoundException.class)
@ResponseStatus(HttpStatus.NOT_FOUND)
public ResponseEntity<?> handleNoResourceFound(NoResourceFoundException e) {
// 如果是 favicon.ico 请求,直接返回空,不记录日志
if (e.getMessage() != null && e.getMessage().contains("favicon.ico")) {
// 可以返回一个空的 404 响应,或者直接返回 null
return ResponseEntity.notFound().build();
}
// 其他资源找不到的情况,根据需要处理
log.warn("资源未找到: {}", e.getMessage());
return ResponseEntity.notFound().build();
}
}Resp响应类
java
import lombok.Getter;
import lombok.Setter;
@Getter
@Setter
public class Resp<T> {
public static final int SUCCESS=200;
public static final int FAILURE=500;
public static final int ERROR=9999;
/**
* 返回状态码(200 操作成功 500操作失败 9999系统异常...)
*/
private Integer code ;
/**
* 返回消息
*/
private String msg ;
/**
* 日志追踪码Id
*/
private String traceId;
/**
* 返回数据
*/
private T data;
public Resp(Integer code, String msg) {
this.code = code;
this.msg = msg;
}
public Resp(Integer code, String msg,T data) {
this.code = code;
this.msg = msg;
this.data=data;
}
public static <T> Resp<T> success(){
return new Resp(SUCCESS,"操作成功") ;
}
public static <T> Resp<T> successMsg(String msg){
return new Resp(SUCCESS,msg) ;
}
public static <T> Resp<T> success(T data){
return new Resp(SUCCESS,"操作成功",data) ;
}
public static <T> Resp<T> failure(String msg){
return new Resp(FAILURE,msg) ;
}
public static <T> Resp<T> error(String msg){
return new Resp(ERROR,msg) ;
}
}4.5、新增TraceResponseAdvice,返回对象Resp中设置traceId
java
import com.plumelog.core.TraceId;
import com.tingcream.tmccloud.base.core.Resp;
import org.springframework.core.MethodParameter;
import org.springframework.http.MediaType;
import org.springframework.http.converter.HttpMessageConverter;
import org.springframework.http.server.ServerHttpRequest;
import org.springframework.http.server.ServerHttpResponse;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice;
@RestControllerAdvice
public class TraceResponseAdvice implements ResponseBodyAdvice<Object> {
@Override
public boolean supports(MethodParameter returnType, Class<? extends HttpMessageConverter<?>> converterType) {
// 只处理 Resp 类型的返回值
return returnType.getParameterType() == Resp.class;
}
@Override
public Object beforeBodyWrite(Object body,
MethodParameter returnType,
MediaType selectedContentType,
Class<? extends HttpMessageConverter<?>> selectedConverterType,
ServerHttpRequest request,
ServerHttpResponse response) {
if (body instanceof Resp) {
Resp<?> resp = (Resp<?>) body;
// 从 Plumelog 上下文中获取当前请求的 traceId
String traceId = TraceId.logTraceID.get();
resp.setTraceId(traceId);
}
return body;
}
}4.6、其他后台线程设置traceId
如xxl-job的定时任务执行,并非是用户http请求行为,而是后台线程执行,这时我们需要手动打入traceId才行。
java
import cn.hutool.core.util.IdUtil;
import com.plumelog.core.TraceId;
import com.tingcream.tmccloud.base.worker.WorkerIdUtil;
import org.slf4j.MDC;
import java.util.UUID;
/**
* 手动打入traceId 例如xxl-job定时任务中的后台线程
*/
public class TraceHelper {
// MDC 中的 Key,Plumelog 默认会识别
private static final String TRACE_ID_KEY = "traceId";
public static void setTraceId() {
long workerId = WorkerIdUtil.getWorkerIdByIp();
String traceId = IdUtil.getSnowflake(workerId, 0).nextIdStr();
TraceId.logTraceID.set(traceId); // 设置 Plumelog 上下文
MDC.put(TRACE_ID_KEY, traceId); // 设置 MDC,方便普通日志打印
}
public static void clearTraceId() {
TraceId.logTraceID.remove();
MDC.remove(TRACE_ID_KEY);
}
}五、请求接口查看日志
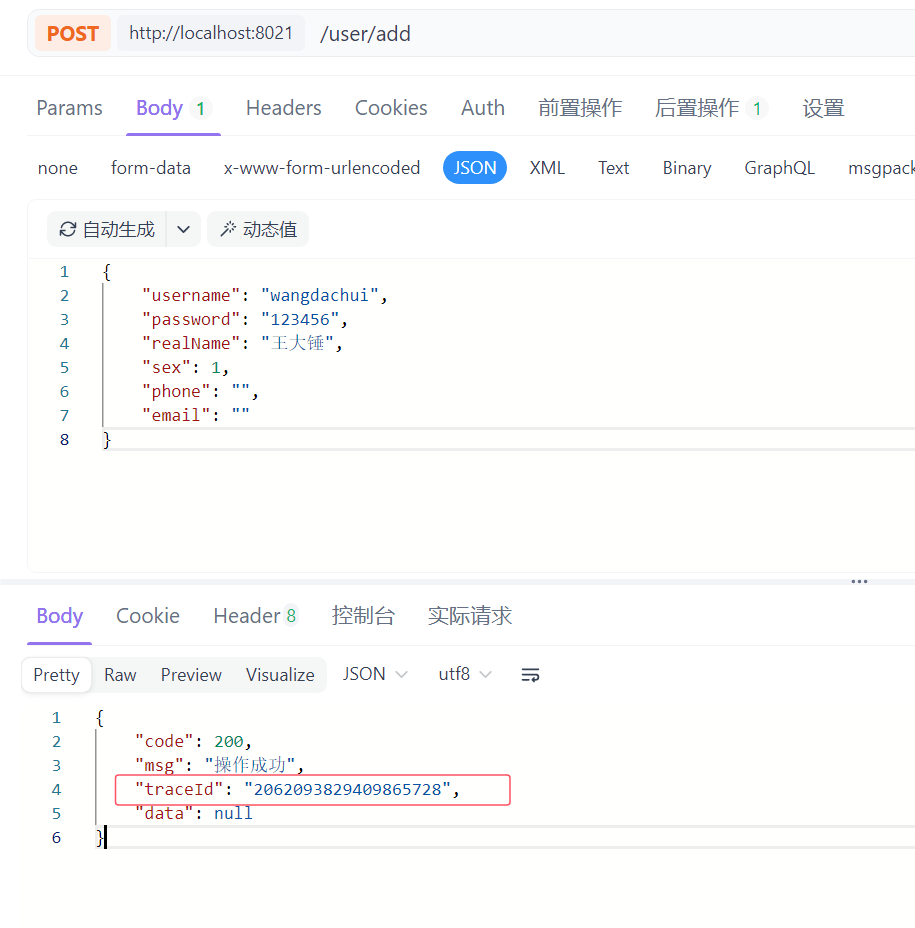
发现无论是正常响应的请求还是异常请求,返回结果中都给出了traceId 。开发人员只需要拿着这个id就可以精准地搜索到相关的日志
5.1、正常响应请求
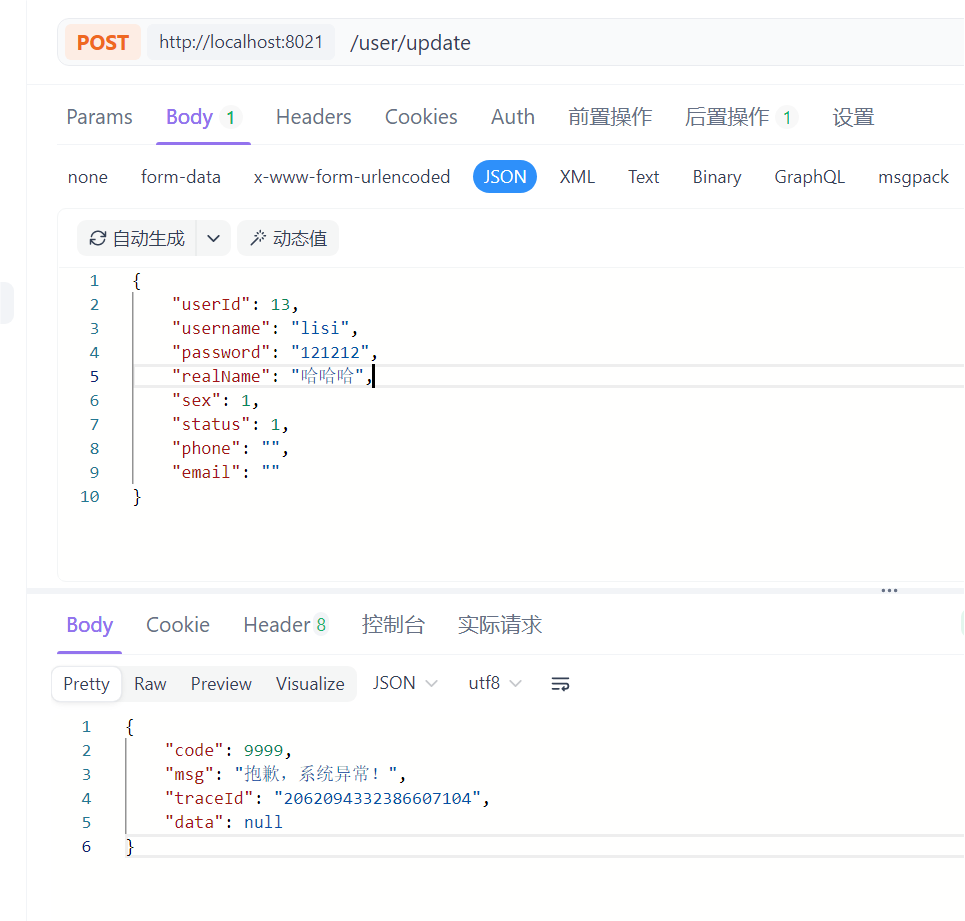
5.2、异常响应请求
5.3、plume日志查看
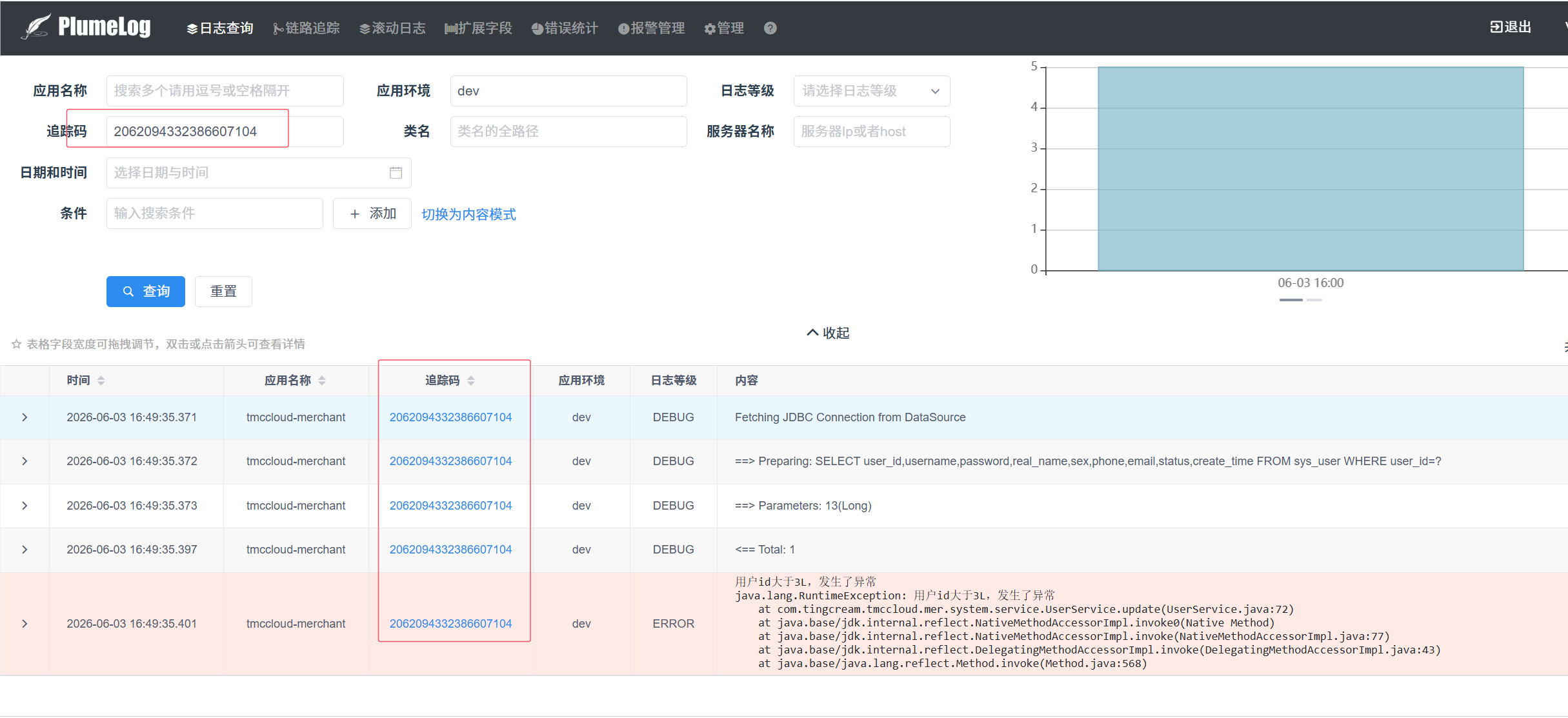
可根据应用名称、环境、追踪码等条件查询, 当然我们直接输入追踪码查询才是最方便直接的!
六、扩展: 雪花算法中workerId怎么取
请注意 我们项目中生成traceId 使用的是雪花算法,雪花算法中最重要的概念是workerId、datacenterId。那么我们该怎么得到服务的workerId呢?
首先指出直接在nacos配置死服务的workerId是不对的, 这样做服务的所有实例都是相同的workerId了,不具有区分性。最好的做法是根据服务所在的物理网络环境生成workerId ,我们也可根据服务所在机器的ip、主机名 或docker容器id及容器名称等 得到workerId。
以下是笔者生成workerId的简单实现 (根据机器ip)
java
import java.net.InetAddress;
import java.net.NetworkInterface;
import java.util.Enumeration;
public class WorkerIdUtil {
/**
* 根据IP地址生成workerId
* 策略:取IPv4地址的最后两段,计算哈希后映射到0-31范围
*/
public static long getWorkerIdByIp() {
try {
String ip = getLocalIpAddress();
// 例如:192.168.31.1 -> 取最后两段 "31.1"
String[] ipParts = ip.split("\\.");
if (ipParts.length >= 4) {
String lastTwo = ipParts[2] + "." + ipParts[3];
// 计算哈希并映射到0-31范围
return Math.abs(lastTwo.hashCode()) % 32;
}
// 备用方案:使用完整IP的哈希
return Math.abs(ip.hashCode()) % 32;
} catch (Exception e) {
// 降级方案:返回默认值
return 1L;
}
}
/**
* 获取本机IPv4地址(优先取eth0网卡)
*/
private static String getLocalIpAddress() throws Exception {
Enumeration<NetworkInterface> interfaces = NetworkInterface.getNetworkInterfaces();
while (interfaces.hasMoreElements()) {
NetworkInterface ni = interfaces.nextElement();
// 跳过回环地址和未启用的网卡
if (ni.isLoopback() || !ni.isUp()) {
continue;
}
Enumeration<InetAddress> addresses = ni.getInetAddresses();
while (addresses.hasMoreElements()) {
InetAddress addr = addresses.nextElement();
if (!addr.isLoopbackAddress() && addr.isSiteLocalAddress()) {
return addr.getHostAddress();
}
}
}
// 降级:获取本地主机地址
return InetAddress.getLocalHost().getHostAddress();
}
}