深入解析云计算三大关键技术综合实践检验
摘要
云计算作为21世纪信息技术的核心驱动力,其底层关键技术深刻影响着大数据处理、分布式系统及互联网服务的架构设计。本文全面剖析了Google公司提出的三大云计算基石------GFS(Google File System) 、MapReduce 和 Bigtable。文章从分布式存储、分布式计算、分布式数据库三个维度,详细阐述了各技术的设计思想、体系架构、核心机制及容错策略,并结合经典案例(WordCount、倒排索引、全局排序)与私有云平台(OpenStack)的实验配置,为读者呈现理论与实践相结合的完整知识体系。本文适合云计算入门者、系统架构师及高校相关专业学生阅读参考。
关键词:云计算;GFS;MapReduce;Bigtable;分布式系统;分而治之;私有云
第一章 引言:云计算的起源与三篇论文
1.1 数据爆炸与应用需求
全球最大搜索引擎、Google Maps、Google Earth、Gmail、YouTube 等应用的成功,标志着互联网服务进入数据驱动时代。这些应用的共性在于:
•数据量巨大:搜索引擎需要索引数千亿网页,地图服务需要存储全球高分辨率影像。
•数据类型丰富:包括结构化数据(如用户信息)、半结构化数据(如日志)、非结构化数据(如视频、图片)。
•实时性要求高:面向全球用户提供毫秒级响应。
传统的关系数据库和单机文件系统无法满足上述需求,表现为: - 存储容量受限(单机磁盘有限) - I/O 吞吐量瓶颈(磁盘读写速度) - 容错能力差(单点故障导致服务中断)
1.2 云计算概念的提出与三篇奠基论文
2006年,Google 首次提出"云计算"概念。在此之前,Google 已在内部实践中总结出三大核心技术,并发表了三篇具有里程碑意义的论文:
|------------------------------------------------------------|------|-----------|----------------|
| 论文名称 | 发表年份 | 核心技术 | 解决的问题 |
| The Google File System | 2003 | GFS | 海量数据的分布式存储 |
| MapReduce: Simplified Data Processing on Large Clusters | 2004 | MapReduce | 海量数据的分布式计算 |
| Bigtable: A Distributed Storage System for Structured Data | 2006 | Bigtable | 结构化数据的分布式存储与查询 |
这三篇论文被业界称为"云计算三驾马车"或"三剑客",奠定了现代大数据平台(如 Hadoop、HBase、Spark)的理论基础。
1.3 三剑客之间的关系
三者并非孤立,而是相互依赖、协同工作:
•GFS 位于最底层,提供可靠的、高吞吐的分布式文件存储。
•Bigtable 构建在 GFS 之上,为结构化数据提供 NoSQL 数据库服务。
•MapReduce 既可以直接读取 GFS 中的数据进行计算,也可以对 Bigtable 中的数据进行批量分析。
形象地说:GFS 是"仓库",Bigtable 是"货架管理系统",MapReduce 是"搬运工和加工车间"。
第二章 分布式存储技术:GFS 深度剖析
2.1 从单机文件系统到集群文件系统
2.1.1 单机文件系统如何保存文件?
单机文件系统(如 ext4、NTFS)将文件存储在本地磁盘上,通过目录树(inode 结构)管理。其局限性在于: - 单个磁盘容量有限(通常 ≤ 几 TB) - 单个文件大小受文件系统限制(例如 ext4 最大文件 16TB,但实际 I/O 性能急剧下降) - 无法应对并发访问(多个客户端同时读写会锁竞争)
2.1.2 如何保存大文件?
一种简单方法是使用 RAID(磁盘阵列),将多块磁盘组合成一个逻辑卷。RAID 0 提升容量和速度,但无容错;RAID 1 镜像提供容错,但容量减半;RAID 5/6 兼顾容量与容错。然而,RAID 仍然局限于单台服务器,无法解决跨机器的数据共享和容错问题。
2.1.3 如何保存超大文件?------集群/分布式文件系统
当文件大小达到 PB 级别时,必须使用分布式文件系统。它将文件分割成多个数据块(chunk/block),分散存储在多台独立的服务器上。GFS 正是 Google 为满足这一需求而设计的。
2.2 GFS 的设计目标与假设
GFS 的设计基于以下观察: 1. 组件失效是常态 :集群由成千上万台廉价服务器组成,每天都有硬盘损坏、网络中断、机器宕机。 2. 文件体积巨大 :多数文件在 100MB 到数 GB 之间,小文件也存在但非优化重点。 3. 读操作模式 :有两种读操作------大规模流式读(顺序读取整个文件)和小规模随机读(在任意位置读取少量数据)。 4. 写操作模式 :主要是追加写入(append),而非覆盖写入。文件一旦写入很少修改。 5. 高并发追加:多个客户端可同时向同一文件追加数据,需保证原子性。
2.3 GFS 体系架构
GFS 采用 Master/Slave(主从) 架构,包含三个核心组件:
•Master(主服务器):整个系统的"大脑",管理所有元数据(文件命名空间、文件到 chunk 的映射、chunk 副本位置)。
•Chunk Server(数据块服务器):实际存储数据。每个 chunk 大小为 64MB(可配置),默认保存三个副本(replica)。
•Client(客户端):应用程序接口,与 Master 交互获取元数据,与 Chunk Server 直接交互传输数据。
2.3.1 物理部署视图
在实际部署中: - 一个集群有一个 Master(外加一个 shadow Master 用于热备)。 - 有数百到数千台 Chunk Server。 - 每台 Chunk Server 运行在普通 Linux 机器上,挂载多个磁盘。 - Client 是应用程序进程,例如索引构建程序或网页爬虫。
2.4 控制流与数据流分离
GFS 的一个关键设计是控制流与数据流分离,极大提升了系统吞吐量。
2.4.1 读文件流程(文字详解)
1.Client 向 Master 发送读请求:包含文件名和读取偏移量。
2.Master 根据文件名和偏移量计算出对应的 chunk 索引,并查找元数据,返回该 chunk 所在的所有 Chunk Server 的 IP 地址(通常返回最近的副本)。
3.Client 缓存该信息(文件名 + chunk 索引 → Chunk Server 列表),避免重复查询 Master。
4.Client 直接与其中一个 Chunk Server(例如最近的)建立 TCP 连接,发送读取请求。
5.Chunk Server 读取本地磁盘上的 chunk 数据(64KB 块或更大),返回给 Client。
6.若读取整个大文件,Client 会重复上述过程,依次获取各个 chunk。
重要特性: - Client 与 Master 之间只有控制流(元数据交换),数据流不经过 Master,因此 Master 不会成为数据瓶颈。 - Client 可以同时与多个 Chunk Server 通信,并行读取不同 chunk,实现高 I/O 并行度。
2.4.2 写文件与追加操作
GFS 支持两种写入方式:普通写入(覆盖已有数据)和记录追加(record append)。由于覆盖写入容易造成不一致,GFS 更推荐使用记录追加。
记录追加的原子性保证: - 多个 Client 同时向同一个文件追加记录时,GFS 保证每个追加操作至少成功一次(at-least-once),且追加的数据在文件中的偏移量是连续的,但不同 Client 的追加记录可能交错。 - 如果某次追加失败,Client 会重试,可能导致重复记录,由应用程序去重。
写入步骤(简化): 1. Client 询问 Master 当前文件最后一个 chunk 的主副本(primary replica)位置。 2. Client 将数据推送到所有副本(数据流流水线传输)。 3. Client 发送写命令给主副本,主副本为数据分配连续偏移量,并将写操作转发给所有从副本。 4. 所有副本完成后,主副本向 Client 返回成功。
2.5 Master 的元数据管理
Master 的内存中保存三类元数据:
1.命名空间:文件系统的目录树结构,类似 Unix 文件系统,但每个文件或目录都是可加锁的。
2.文件到 chunk 的映射:每个文件由多个 chunk 组成,Master 记录每个 chunk 的句柄(handle)。
3.chunk 副本位置:每个 chunk 的三个副本分别位于哪些 Chunk Server。
前两种信息会持久化到磁盘(通过操作日志和检查点),第三种信息不需要持久化------Master 在启动时询问所有 Chunk Server 各自拥有哪些 chunk,或者通过心跳信息动态更新。
容错措施: - Master 的操作日志会定期生成检查点(checkpoint),并同步到远程备份机器。 - 若 Master 宕机,可快速从最近的检查点和操作日志恢复。同时 shadow Master 可接管服务(只读模式,写操作需重新选举)。
2.6 Chunk Server 的容错与数据一致性
2.6.1 副本机制
每个 chunk 默认三个副本,可配置(如对关键数据用更多副本)。
写入必须三个副本都成功才算成功。
若某个 Chunk Server 宕机或磁盘损坏,Master 检测到该 chunk 的副本数低于设定值(如从3降为2),会启动副本复制:选择另一个健康的 Chunk Server,从剩余正常副本中复制数据。
2.6.2 校验和(checksum)
每个 64KB 的 block 都有一个 32 位校验和。
读取时,Chunk Server 会校验 block 的校验和,若发现数据损坏(静默数据错误),则向 Client 返回错误,并通知 Master 该副本已损坏,Master 会从其他副本恢复。
后台定期扫描校验和,主动发现磁盘坏道。
2.6.3 心跳检测与失效发现
Master 定期向每个 Chunk Server 发送心跳(heartbeat)消息。
若某个 Chunk Server 在指定时间内(如10秒)未响应,Master 将其标记为失效(dead)。
失效服务器上的所有 chunk 副本视为丢失,Master 启动副本复制流程。
2.6.4 应对访问热点(hot spot)
当某个文件成为热点(例如一个流行视频被千万用户下载),其 chunk 的副本可能负载过高。
解决方案:增加该 chunk 的副本数(临时调整到5或10个),并在低负载时段恢复。
此外,Client 的缓存机制可减少对 Master 的访问,但无法完全避免 Chunk Server 的热点。GFS 后续版本引入了动态负载均衡。
2.7 GFS 的优势与局限
|------|----------------------|
| 优势 | 描述 |
| 高吞吐量 | 控制流与数据流分离,并行 I/O |
| 高容错性 | 副本、校验和、心跳检测、自动恢复 |
| 低成本 | 可使用普通 x86 服务器,无需专用硬件 |
| 弹性伸缩 | 动态添加或移除 Chunk Server |
| 追加优化 | 适合日志、数据采集场景 |
|-------------|----------------------------------------|
| 局限 | 描述 |
| 不适合小文件 | 大量小文件会导致 Master 内存压力大 |
| 弱一致性 | 并发追加可能导致记录重复或交错 |
| Master 单点瓶颈 | 虽然可通过 shadow Master 缓解,但写操作依赖单一 Master |
2.8 课堂小练习精解
(1)以下关于 Google 文件系统 GFS 不正确的说法是哪个?
A. GFS 是一个开源的系统 ❌(GFS 是 Google 内部专有系统,不是开源。开源实现为 HDFS。)
B. GFS 处于 Google 云计算架构所有核心技术的底层 ✅
C. GFS 是分布式存储技术 ✅
D. GFS 可以根据应用需求提供大尺寸文件存储功能 ✅
答案:A
(2)以下关于 GFS 系统的特点哪个描述是错误的?
A. GFS 采用中心服务器模式 ✅(Master 是中心)
B. 不缓存数据 ✅(Client 和 Chunk Server 都不缓存,因为数据太大,且流式读取不需要缓存)
C. GFS 采用完全分布式的模式 ❌(实际上有中心 Master,不是完全无中心)
D. 系统在用户态下实现 ✅(Google 在用户态实现 GFS,方便开发和调试)
答案:C
(3)关于 GFS 系统架构描述正确的是?(多选)
A. 数据块服务器(Chunk Server)负责具体的存储工作 ✅
B. 客户端可以同时访问多个数据块服务器,从而使得整个系统的 I/O 高度并行 ✅
C. 客户端与主服务器之间只有控制流,而无数据流 ✅
D. 每个 GFS 系统至少有一个主服务器(Master) ✅
答案:A、B、C、D(全部正确)
第三章 分布式计算技术:MapReduce 深度剖析
3.1 问题背景:如何在短时间内处理海量任务?
以搜索引擎为例:用户输入一个查询词,系统需要在数亿网页中找出包含该词的页面,并按相关性排序。如果单个机器扫描所有网页,需要数天甚至数月。必须使用多台机器并行处理。
Jeffrey Dean 和 Sanjay Ghemawat 在 2004 年设计了 MapReduce 模型,将复杂的并行处理抽象为两个简单的函数:Map 和 Reduce。该模型封装了以下复杂性: - 任务划分与调度 - 数据本地化(data locality) - 节点间通信 - 容错与重试 - 负载均衡
3.2 MapReduce 的通俗理解
•Map(映射,拆解):将一个大问题分解成多个小问题,每个小问题独立处理,产生中间结果。
•Reduce(归约,聚合):将相同键的中间结果合并,得到最终结果。
生活类比: - 要统计全校学生成绩的最高分。Map:每个班级的班长统计自己班级的最高分。Reduce:年级主任汇总各班的最高分,得出全校最高分。
3.3 MapReduce 编程模型形式化定义
Map : (K1, V1) → list(K2, V2)
Reduce : (K2, list(V2)) → list(K3, V3)
•Map 函数:输入一个键值对(如文件名和文件内容),输出零个或多个中间键值对。
•Reduce 函数:接收一个键以及与该键关联的所有值的列表,将这些值合并成一个或一组最终值。
3.4 MapReduce 的工作流程(经典六步骤)
下图描述了一个 MapReduce 作业的完整执行流程(文字版):
1.输入分割(Split):MapReduce 库将输入文件划分为 M 个数据分片(split),通常每个分片 16MB 到 64MB。用户可指定分片大小。
2.启动程序:用户程序启动后,会复制代码到集群所有机器,并启动一个特殊的 Master 节点和多个 Worker 节点。
3.Map 任务分配与执行:
--Master 将 M 个 Map 任务分配给空闲的 Worker。
--每个 Map Worker 读取对应的数据分片,解析出键值对,并调用用户定义的 Map 函数。
--Map 函数输出的中间键值对缓存在内存中。
4.中间结果分区与落盘:
--周期性地,内存中的中间结果被写入本地磁盘,并通过分区函数(如 hash(key) mod R)分成 R 个区域。
--分区信息(文件位置)被报告给 Master。
5.Reduce 任务分配与数据拉取:
--Master 将 R 个 Reduce 任务分配给空闲的 Worker。
--每个 Reduce Worker 通过 RPC 从所有 Map Worker 的本地磁盘读取属于自己的分区数据(即所有 Map Worker 产生的第 i 个分区都发给第 i 个 Reduce Worker)。
--Reduce Worker 对读取的数据按键进行排序(如果需要,可进行外部排序)。
6.Reduce 执行与输出:
--Reduce Worker 遍历排序后的中间数据,将每个键及其对应的值列表传给用户定义的 Reduce 函数。
--Reduce 函数的输出追加到该 Reduce 分区的最终输出文件中(通常放在 GFS 中)。
3.5 数据本地化(Data Locality)
MapReduce 的重要优化是尽量将 Map 任务调度到存储有相应数据分片的机器上(即 Chunk Server)。
如果无法本地化(例如所有本地 Worker 繁忙),则选择一个邻近的机器(同一机架)以减少网络传输。
3.6 经典案例:WordCount(词频统计)
问题:给定一个大型文本文件集合,统计每个单词出现的总次数。
Map 阶段(伪代码):
map(String filename, String file_content):
for each word w in file_content:
emit(w, 1)
Reduce 阶段:
reduce(String word, Iterator<Integer> counts):
int sum = 0
for each c in counts:
sum += c
emit(word, sum)
执行过程: - 输入分片:每台机器处理一个文件分片。 - Map 输出:例如 ("hello",1), ("world",1), ("hello",1)。 - Shuffle 阶段:Master 将所有键为 "hello" 的中间值(1,1,...)发送到同一个 Reduce Worker。 - Reduce 输出:("hello", 153), ("world", 89)。
3.7 小案例:倒排索引(Inverted Index)
问题:为搜索引擎构建倒排索引,即每个单词对应包含它的文档 ID 列表。
Map 函数:
map(document_id, document_content):
for each word w in document_content:
emit(w, document_id)
Reduce 函数:
reduce(word, list<document_id> ids):
remove duplicates from ids
sort(ids)
emit(word, ids)
应用:用户搜索某个单词时,系统可直接从索引中取出文档列表。
3.8 小案例:全局排序(TeraSort)
问题:对海量字符串进行全局排序(字典序)。
关键步骤:
1.采样:首先对数据进行抽样,确定 R 个分区边界(称为 split points)。例如,从输入中随机抽取 10000 个字符串,排序后取第 1/R, 2/R, ... 位置的字符串作为边界。
2.Map 阶段:每个 Map Worker 读取一个数据分片,对于每个字符串,判断它落在哪个分区(基于边界),然后输出 (partition_id, string)。
3.分区与 Shuffle:所有具有相同 partition_id 的键值对被发送到同一个 Reduce Worker。
4.Reduce 阶段:每个 Reduce Worker 收到一个分区内的所有字符串,在内存中排序(或外部排序),然后直接输出到 GFS 文件。最终所有 Reduce 的输出文件按分区顺序拼接即为全局有序。
注意:为了支持跨分区全局有序,通常使用一个额外的 MapReduce 作业或自定义输出提交器。
3.9 MapReduce 容错机制
3.9.1 Worker 失效
Master 定期对每个 Worker 发送 ping 心跳。
若一段时间无应答,Master 标记该 Worker 为失效。
对于失效 Worker 上已完成的 Map 任务(其输出在本地磁盘),由于数据不可访问,这些 Map 任务需要重新调度到其他 Worker 上执行。
对于失效 Worker 上已完成的 Reduce 任务,因其输出已写入 GFS,无需重新执行。
对于正在执行的任务,直接重新调度。
3.9.2 Master 失效
Master 会定期保存其状态(检查点),包括任务分配情况、中间文件位置等。
如果 Master 失效,可以启动一个新的 Master 进程,从最近的检查点恢复。
•由于只有一个 Master,如果 Master 彻底宕机且无备份,则整个作业失败,用户需重新启动。在生产环境中,通常会运行一个备份 Master(standby)。
3.9.3 任务粒度与备份任务
•MapReduce 将作业分解为大量细粒度任务(M 和 R 通常远大于 Worker 数量),这样即使某些任务失败,也只需重新执行少量任务。
•为了应对掉队者(straggler,即执行特别慢的机器),Master 会启动备份任务:当作业接近完成时,将剩余的几个未完成任务再次调度到空闲 Worker 上,谁先完成就采用谁的结果。这大幅减少了作业执行时间的 tail latency。
3.10 MapReduce 的局限与演进
|---------|--------------------------------------|
| 局限 | 说明 |
| 不适合迭代计算 | 每次迭代都需要重新从磁盘读取数据,效率低(Spark 用 RDD 解决) |
| 编程模型单一 | 只支持 Map 和 Reduce,复杂计算需要多次作业串联 |
| 高延迟 | 作业启动、调度、shuffle 开销大,不适合实时计算 |
Google 后续推出了 Flume、MillWheel、Dataflow 等模型,开源社区则发展出 Spark、Flink。
第四章 分布式数据库技术:Bigtable 深度剖析
4.1 背景:为什么需要 Bigtable?
GFS 提供了分布式文件系统,但无结构化数据组织能力。
关系数据库(如 MySQL)在数据量达 PB 级时扩展性差,且 schema 变更昂贵。
Google 的应用(如网页索引、个性化搜索、Google Earth)需要存储海量的半结构化或结构化数据,并且需要高吞吐、低延迟的随机读写。
Bigtable 应运而生,它是一个稀疏的、分布式的、持久化的、多维排序的 Map,以 (row, column, timestamp) 为键,值是一个字符串。
4.2 Bigtable 的数据模型
4.2.1 逻辑视图
Bigtable 的存储逻辑可表示为:
(row:string, column:string, time:int64) → string
行(Row):行键是一个任意字符串(最大64KB)。数据按照行键的字典序排序。同一行中的所有列组成一个原子单元(支持行级别事务)。
列族(Column Family):列由"列族:限定词"组成,例如 content:html 或 anchor:cnn.com。列族是访问控制的基本单元,必须预先定义;限定词可动态添加。
时间戳(Timestamp):64位整数,通常表示微秒级的时间。每个单元格可存储多个时间戳版本,默认保留最近3个版本。
4.2.2 物理存储
逻辑上的表格在物理上被存储为一系列 SSTable(Sorted String Table)。每个 SSTable 是 (row, column, timestamp) 到 value 的排序映射,并以块(block)为单位压缩存储。
转换示例: - 逻辑:(Steve, body:height, 2011) = "6'2",(Steve, body:height, 1987) = "5'7"。 - 物理:Steve:body:height:2011 → 6'2",Steve:body:height:1987 → 5'7"。
4.3 Bigtable 体系架构
Bigtable 建立在 GFS 之上,由以下组件构成:
1.Client Library:应用程序链接的库,提供 API。
2.Master Server:
--管理 Tablet 分配(将 Tablet 分配给 Tablet Server)。
--监控 Tablet Server 的存活状态。
--处理 schema 变更(创建表、列族)。
--负载均衡。
3.Tablet Server:
--管理一组 Tablet(一个 Tablet 是表的一个连续行范围)。
--处理对该 Tablet 的读写请求。
--将数据写入 GFS 中的 SSTable 和日志。
4.GFS:存储所有 SSTable 和日志(commit log)。
4.4 Tablet 拆分与负载均衡
初始时,一个表只有一个 Tablet。
当 Tablet 大小超过阈值(如 100MB 或 200MB),Master 将其拆分为两个新的 Tablet,并分配给 Tablet Server。
每个 Tablet 由单个 Tablet Server 服务,但可以动态迁移以均衡负载。
4.5 写入流程与加速
Q2:如何加速写数据? A2:在内存中写入。
每个 Tablet 包含: - memTable :内存中的缓存,新写入的数据先插入 memTable(有序数据结构,如跳表)。 - SSTable 列表:已经持久化到 GFS 的 SSTable 文件。
写入步骤: 1. 将操作写入 commit log(在 GFS 中),以保证持久性。 2. 将数据插入 memTable。 3. 当 memTable 大小达到阈值(如 64MB),将其冻结,创建一个新的 memTable,并将冻结的 memTable 转换为 SSTable 写入 GFS。 4. 后台可以合并多个小的 SSTable 为更大的 SSTable(compaction),减少读取时的文件数量。
4.6 读取流程与加速
Q4:如何加速读数据? A4:建立索引。
每个 SSTable 在内部组织为: - 多个 64KB 的数据块(block)。 - 一个块索引(block index),记录每个块的最大 key 及其在文件中的偏移量。 - 可选地,一个 Bloom Filter。
读取步骤: 1. 检查 memTable(最新数据)。 2. 如果未找到,依次检查每个 SSTable(从新到旧)。对于每个 SSTable: - 首先加载块索引到内存(或已存在)。 - 二分查找确定 key 可能存在的块。 - 从 GFS 读取该块(可能用缓存)。 3. 返回找到的值。
Q5:如何进一步加速读? A5:Bloom Filter。
Bloom Filter 是一个空间高效的随机数据结构,用于判断一个元素是否在集合中。
优点:100% 召回率(不会漏判),节省内存(每个 SSTable 只需约 1 字节 per key)。
缺点:存在假阳性(可能会误判 key 存在于 SSTable 中,导致一次无效的磁盘读取,但不会影响正确性)。
在读取时,先查询 Bloom Filter:如果 Bloom Filter 说 key 不在该 SSTable 中,则直接跳过该 SSTable,避免磁盘 I/O。
4.7 容错与恢复
Tablet Server 失效:Master 通过心跳检测到失效后,将该 Server 上的所有 Tablet 重新分配给其他 Server。新 Server 从 GFS 读取该 Tablet 的 SSTable 和 commit log(包括未合并到 SSTable 的 memTable 数据),重放日志重建 memTable。
Master 失效:使用分布式锁服务(如 Chubby)选举新的 Master。新 Master 从 GFS 中读取元数据,扫描 Tablet Server 的负载情况,恢复服务。
4.8 Bigtable vs 传统关系数据库
|------|-----------------|-------------------|
| 特性 | Bigtable | 传统 RDBMS(如 MySQL) |
| 数据模型 | 稀疏多维 Map,列族 | 严格 schema,表格行/列 |
| 扩展性 | 水平扩展,自动分片 | 垂直扩展为主,分片需手动 |
| 事务 | 单行原子性,不支持多行事务 | ACID 事务,支持复杂 join |
| 查询语言 | 不支持 SQL,专有 API | SQL 标准 |
| 索引 | 仅行键主索引,二级索引需额外表 | 多种索引,外键 |
| 适用场景 | 海量数据、高吞吐、写密集 | 复杂查询、事务一致性要求高 |
第五章 私有云平台环境配置实验详解
(本章基于 OpenStack 平台,以 IaaS 2.2 镜像为例,详细解释每个步骤的原理与常见问题。以下所有代码、命令、配置文件内容均完整保留,不做任何修改。)
5.1 实验目的
通过手动配置私有云平台的控制节点(controller)和计算节点(compute),掌握: - Linux 存储设备管理(分区、文件系统) - 网络配置与主机名解析 - 本地 yum 源与 FTP 服务搭建 - 环境变量配置与 OpenStack 安装前提准备
5.2 实验拓扑
Controller:IP 192.168.1.241,主机名 controller。运行控制服务(keystone, glance, nova-api, neutron-server 等)。
Compute:IP 192.168.1.242主机名 compute。运行计算服务(nova-compute, neutron-agent)。
两个节点均连接同一管理网络(ens33 或 ens34),并能够互相通信。
5.3 详细步骤与深度解析
5.3.1 存储设备准备
目的:为 OpenStack 的块存储服务(Cinder)和对象存储服务(Swift)提供专用磁盘。
命令解析:
fdisk /dev/sdb
n:新建分区
p:主分区
1:分区编号
两次回车:使用默认起始和结束扇区(占用整个磁盘)
t:修改分区类型
8e:Linux LVM 类型(因为 Cinder 后端通常使用 LVM)
w:写入分区表并退出
为什么需要 LVM 类型?
OpenStack Cinder 使用 LVM 作为存储后端时,要求磁盘分区类型为 8e,以便 pvcreate 创建物理卷。
文件系统创建:
mkfs.xfs /dev/sdb1
XFS 是 CentOS 7 默认文件系统,适合大文件和大容量。
【完整实验代码块 - 不可改动】
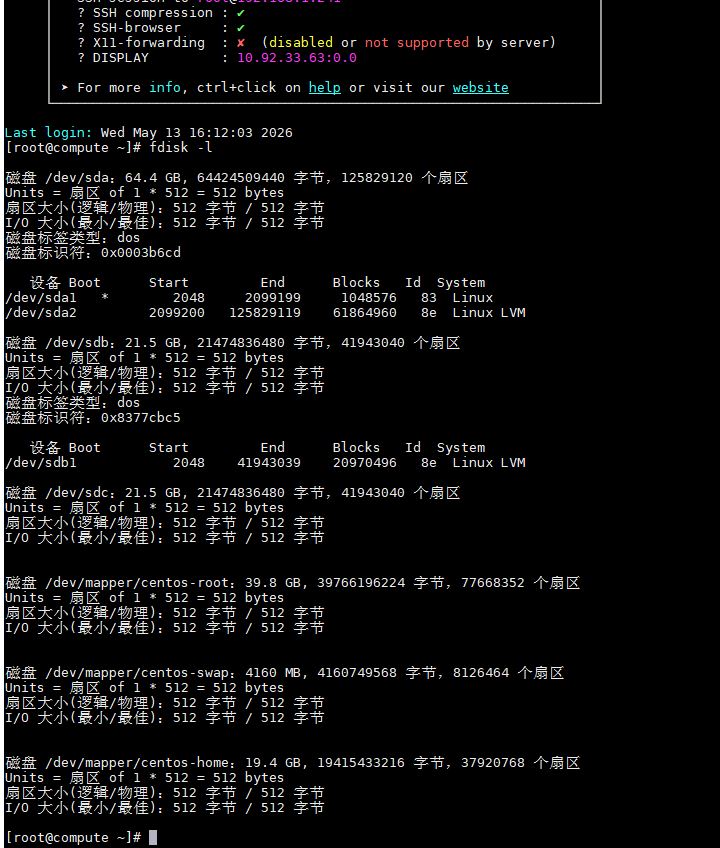
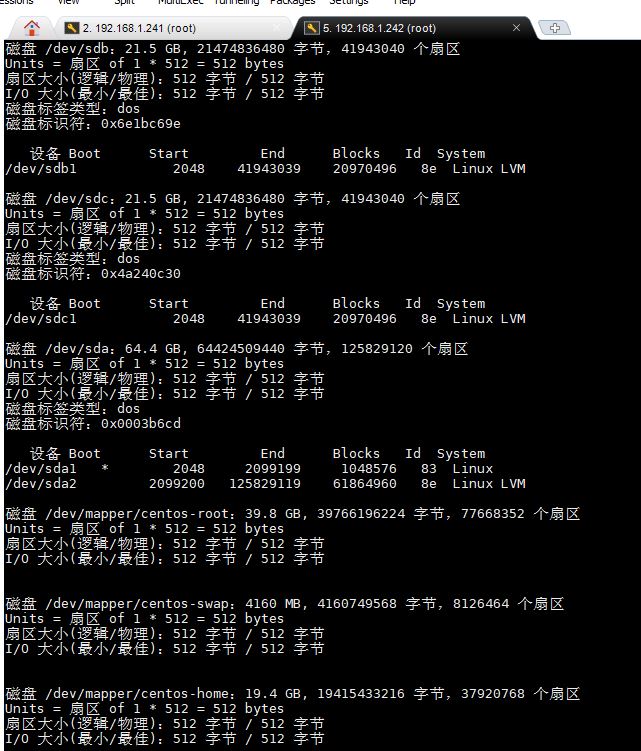
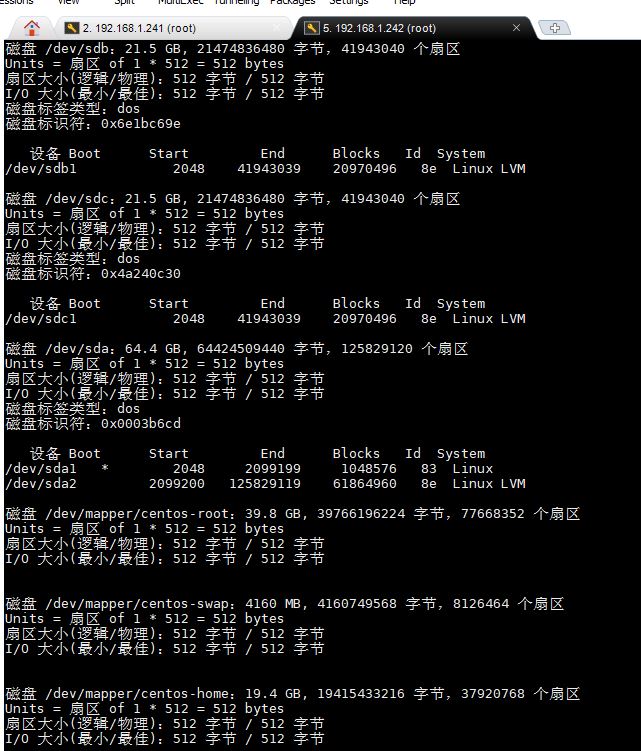
1.在controller中确定已添加两块20G的scsi硬盘, 用命令 fdisk -l , 观察到有/dev/sdb和/dev/sdc字样。截图到7-1.jpg。(若无则 echo "- - -" > /sys/class/scsi_host/host0/scan识别它们)
【实验截图位置:图 5-1】
|-------------------------------------------------|
| 图 5-1 在 Controller 节点使用 fdisk -l 查看新添加的 SCSI 硬盘 |
图 5-1 在 Controller 节点使用 fdisk -l 查看新添加的 SCSI 硬盘
图 5-1 在 Controller
节点使用 fdisk -l 查看新添加的 SCSI 硬盘
截图说明:执行 fdisk -l 命令后,终端应显示 /dev/sdb 和 /dev/sdc 两块 20GB 的 SCSI 硬盘信息。若未显示,需执行 echo "- - -" > /sys/class/scsi_host/host0/scan 重新扫描 SCSI 总线。
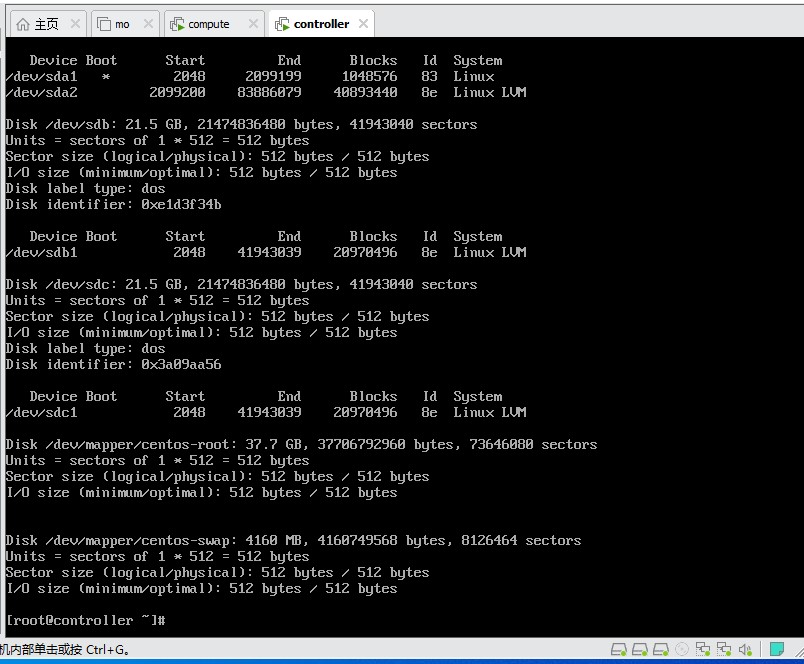
- 执行 fdisk /dev/sdb进行分区, n进行新建, 选p指定分区类型为主分区, 选1指定分区编号为1, 分区起点和终点均回车采用默认值, 选t进行系统类型选择, 输入8e, 最后w保存退出。对/dev/sdc执行同样的操作。再用命令fdisk -l 观察结果, 截图到7-2.jpg。
【实验截图位置:图 5-2】
|-------------------------------------------|
| 图 5-2 使用 fdisk 对 /dev/sdb 和 /dev/sdc 进行分区 |
图 5-2 使用 fdisk 对 /dev/sdb 和 /dev/sdc 进行分区
图 5-2 使用 fdisk 对
/dev/sdb 和 /dev/sdc 进行分区
截图说明:分区完成后,再次执行 fdisk -l 应显示 /dev/sdb1 和 /dev/sdc1 两个新分区,类型为 Linux LVM (8e)。
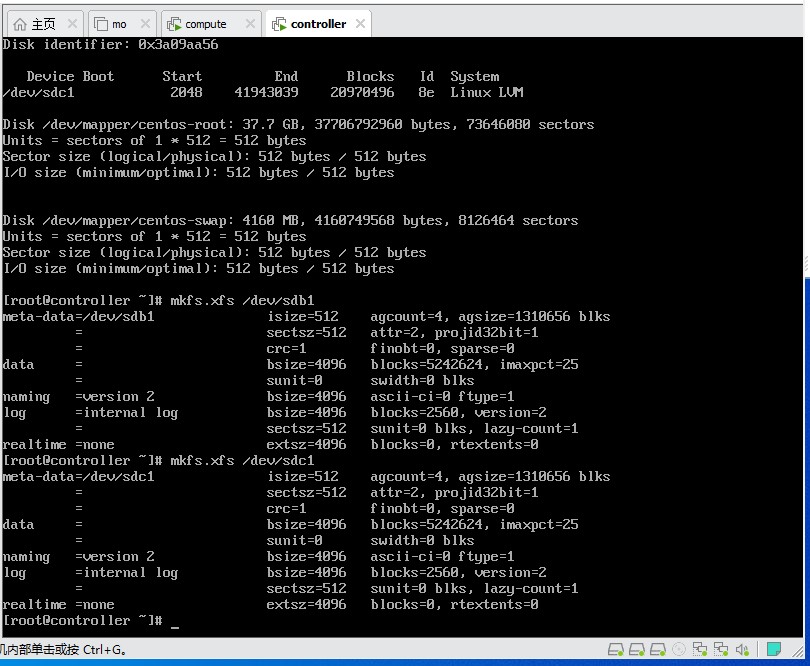
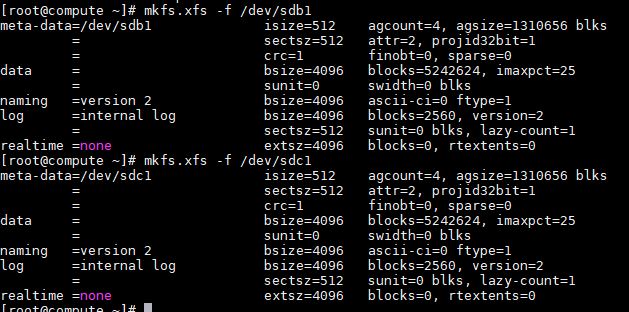
- 对上述两个新分区进行文件系统创建, mkfs.xfs /dev/sdb1, mkfs.xfs /dev/sdc1, 将屏幕截图到7-3.jpg。
【实验截图位置:图 5-3】
|-------------------------------|
| 图 5-3 使用 mkfs.xfs 创建 XFS 文件系统 |
图 5-3 使用 mkfs.xfs 创建 XFS 文件系统
图 5-3 使用 mkfs.xfs 创建 XFS 文件系统
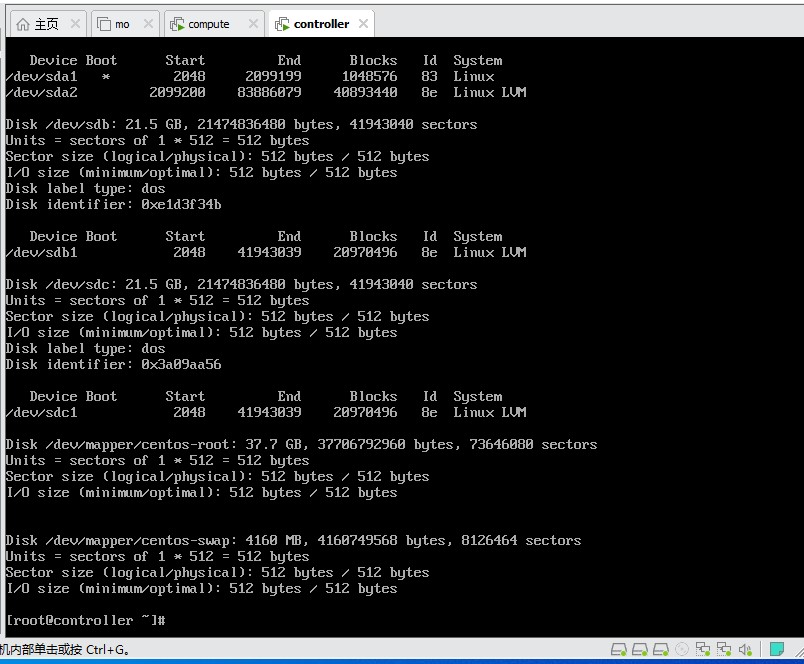
截图说明:执行 mkfs.xfs 命令后,终端应显示文件系统创建的详细信息,包括 inode 数量、块大小等参数。
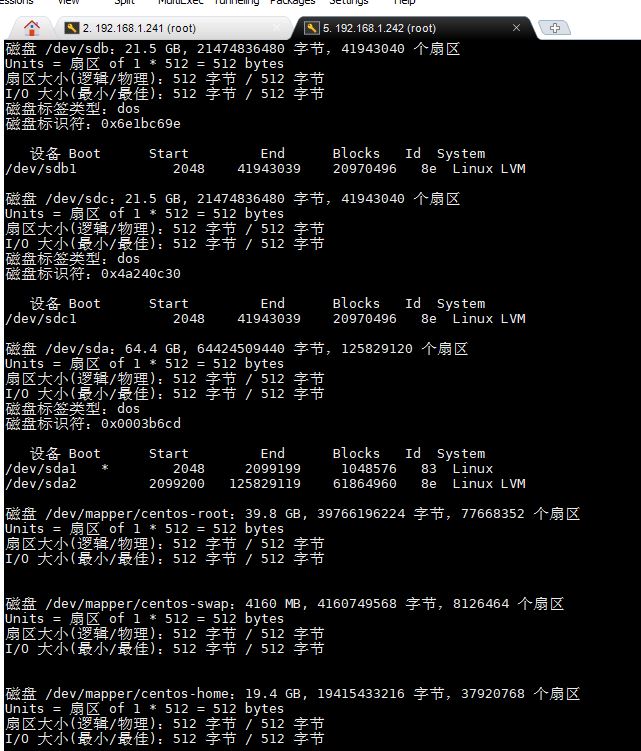
- 在compute中重复1-3,分别截图到7-4.jpg,7-5.jpg和7-6.jpg。
【实验截图位置:图 5-4】
|------------------------------|
| 图 5-4 在 Compute 节点查看 SCSI 硬盘 |
图 5-4 在 Compute 节点查看 SCSI 硬盘
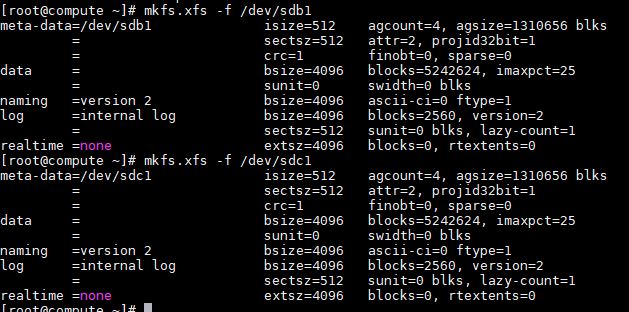
图 5-4 在 Compute 节点使用 fdisk -l 查看新添加的 SCSI 硬盘
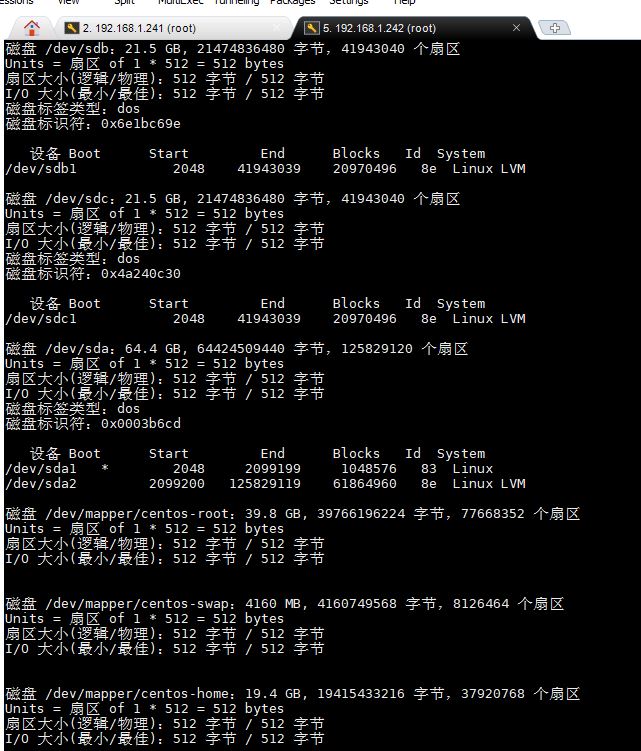
【实验截图位置:图 5-5】
|--------------------------|
| 图 5-5 在 Compute 节点进行磁盘分区 |
图 5-5 在 Compute 节点进行磁盘分区
图 5-5 在 Compute 节点使用 fdisk 对 /dev/sdb 和 /dev/sdc 进行分区
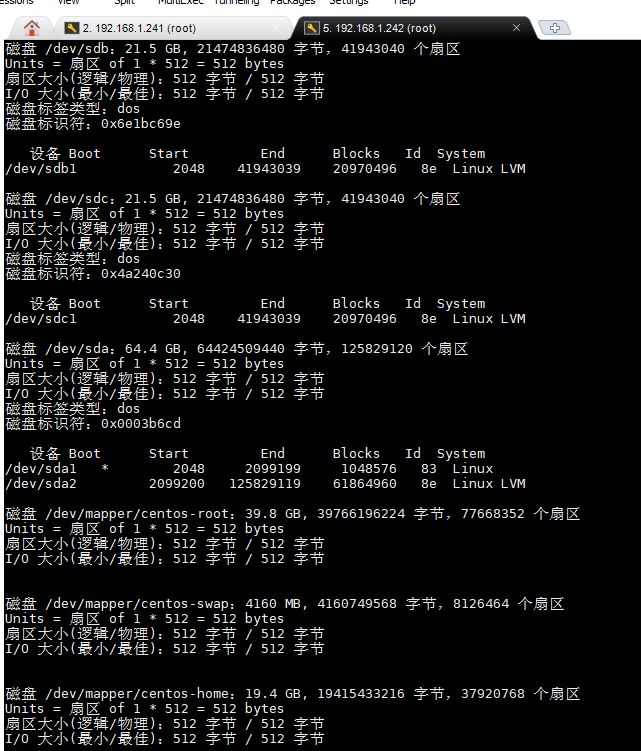
【实验截图位置:图 5-6】
|-------------------------------|
| 图 5-6 在 Compute 节点创建 XFS 文件系统 |
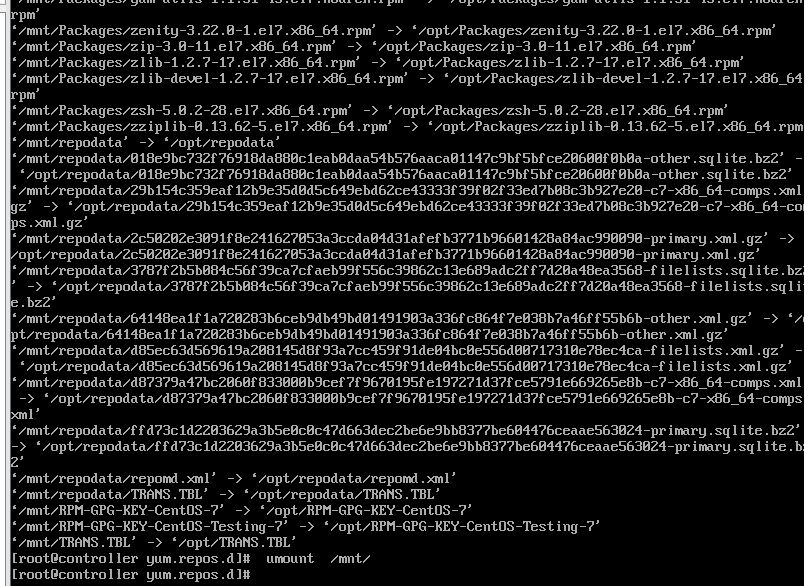
图 5-6 在 Compute 节点创建 XFS 文件系统
图 5-6 在 Compute 节点使用 mkfs.xfs 创建 XFS 文件系统
5.3.2 网卡与主机名配置
网卡配置示例(/etc/sysconfig/network-scripts/ifcfg-ens34):
TYPE=Ethernet
BOOTPROTO=static
DEVICE=ens34
ONBOOT=yes
IPADDR=192.168.1.241
NETMASK=255.255.255.0
GATEWAY= # 第二网卡不设置网关,避免默认路由冲突
主机名解析(/etc/hosts):
192.168.1.241 controller
192.168.1.242 compute
【完整实验代码块 - 不可改动】
1.在controller中修改和添加/etc/sysconfig/network-scripts/ifcfg-ens**(具体是两个网卡,**一般是33和34)文件,主要改动以下参数:ONBOOT=yes,BOOTPROTO=static,第二网卡的gateway要删除。
2.确认主机名为controller,输入命令hostnamectl set-hostname controller。
3.在compute中重复前面第1步。
4.确认当前主机名为compute,输入命令hostnamectl set-hostname compute。
【实验截图位置:图 5-7】
|---------------------------|
| 图 5-7 Controller 节点网卡配置文件 |
图 5-7 Controller 节点网卡配置文件
图 5-7 Controller 节点网卡配置文件内容
5.3.3 YUM 源配置
本地源(controller): - baseurl=file:///opt/centos:直接从本地目录读取 RPM 包,速度快且不依赖网络。 - gpgcheck=0:跳过 GPG 签名检查(实验环境)。
FTP 源(compute): - baseurl=ftp://192.168.1.241/centos:通过 FTP 读取 controller 上的软件包,适合多节点环境。 - 需提前在 controller 上安装并配置 vsftpd,设置 anon_root=/opt 使匿名用户可访问 /opt 目录。
【完整实验代码块 - 不可改动】
1.在controller中,先备份原来的安装源 #mv /etc/yum.repos.d/* /opt/
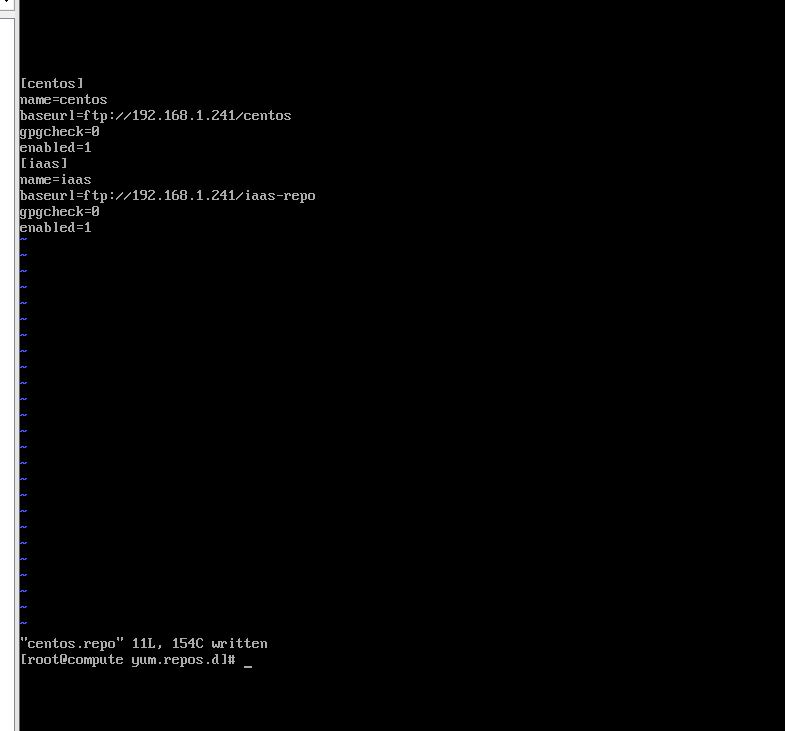
2.创建repo文件,在/etc/yum.repos.d创建centos.repo源 文件,内容如下:
centos name=centos baseurl=file:///opt/centos gpgcheck=0 enabled=1
iaas name=iaas baseurl=file:///opt/iaas-repo gpgcheck=0 enabled=1
显示文件内容并截图到7-7.jpg。
【实验截图位置:图 5-8】
|-------------------------------|
| 图 5-8 Controller 节点 YUM 源配置文件 |
图 5-8 Controller 节点 YUM 源配置文件
图 5-8 Controller 节点 YUM 源配置文件内容
- 在compute中,先备份原来的安装源 #mv /etc/yum.repos.d/* /opt/
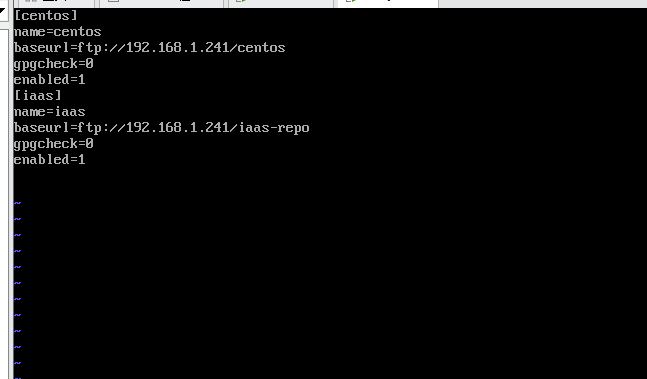
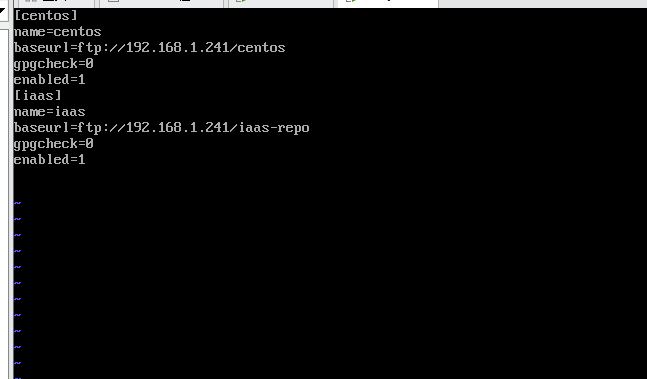
- 创建repo文件,在/etc/yum.repos.d创建centos.repo源文件,内容如下:
centos name=centos baseurl=ftp://192.168.1.241/centos gpgcheck=0 enabled=1
iaas name=iaas baseurl=ftp://192.168.1.241/iaas-repo gpgcheck=0 enabled=1
显示文件内容并截图到7-8.jpg。
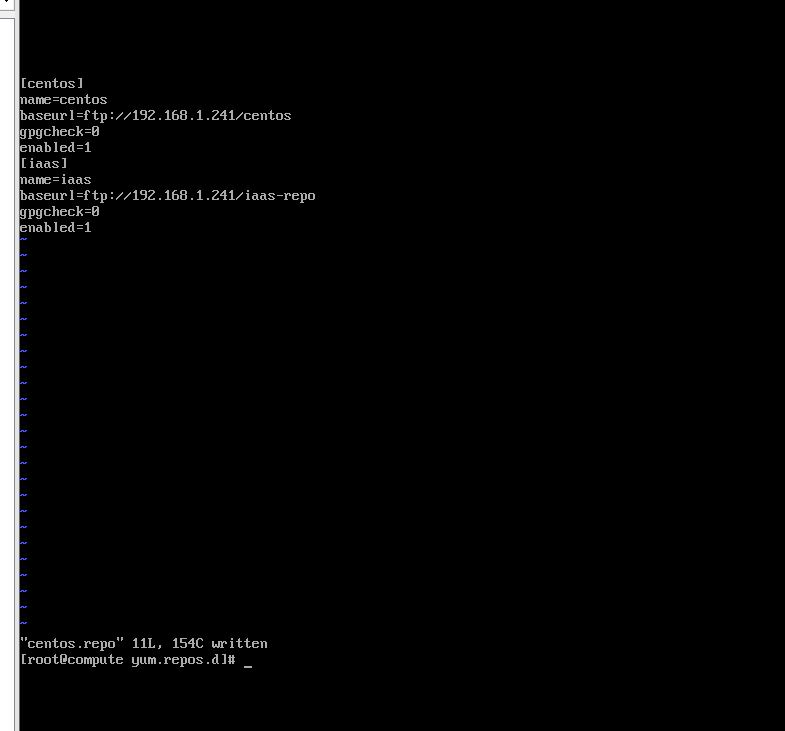
【实验截图位置:图 5-9】
|----------------------------|
| 图 5-9 Compute 节点 YUM 源配置文件 |
图 5-9 Compute 节点 YUM 源配置文件
图 5-9 Compute 节点 YUM 源配置文件内容
5.3.4 复制光盘文件
挂载与复制:
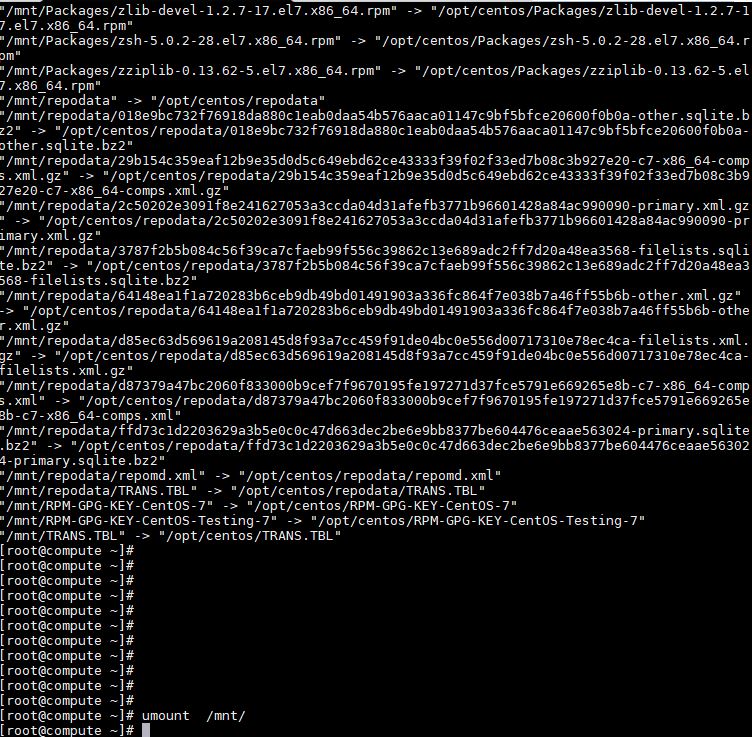
mount /dev/cdrom /mnt/
cp -rvf /mnt/* /opt/centos/
-r:递归复制目录
-v:显示详细过程
-f:强制覆盖
为何需要复制?
因为后续使用 createrepo 创建本地元数据时,需要文件在本地。同时,compute 节点可通过 FTP 访问,无需每个节点都挂载光盘。
【完整实验代码块 - 不可改动】
四、复制centos7和iaas2.2光盘中的文件到/opt
1.在controller中,将光驱中光盘指为定centos7并确认已连接。
2.挂载光盘到/mnt文件夹并复制文件 root@controller \~# mount /dev/cdrom /mnt/ root@controller \~# mkdir /opt/centos root@controller \~# cp -rvf /mnt/* /opt/centos/ root@controller \~# umount /mnt/ 将复制完成结果截图到7-9.jpg
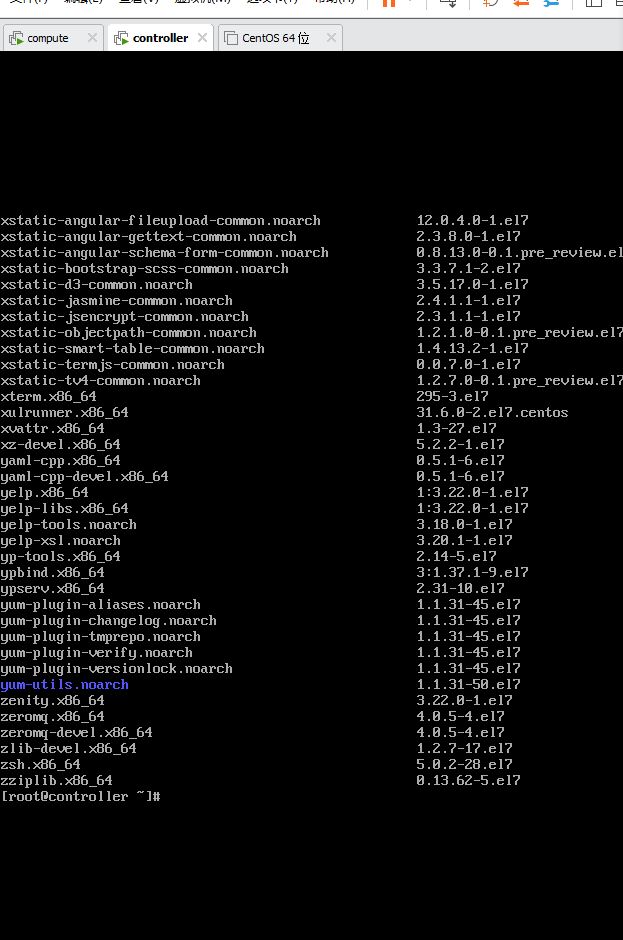
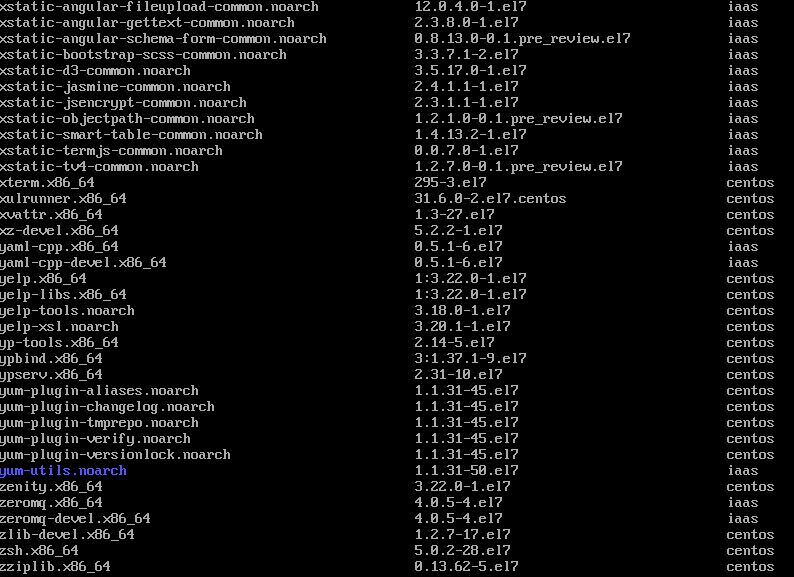
【实验截图位置:图 5-10】
|--------------------------------------|
| 图 5-10 复制 CentOS 7 光盘文件到 /opt/centos |
图 5-10 复制 CentOS 7 光盘文件到 /opt/centos
图 5-10 复制 CentOS 7 光盘文件到 /opt/centos 目录
- 将光驱中光盘指为定iaas2.2确认已连接。
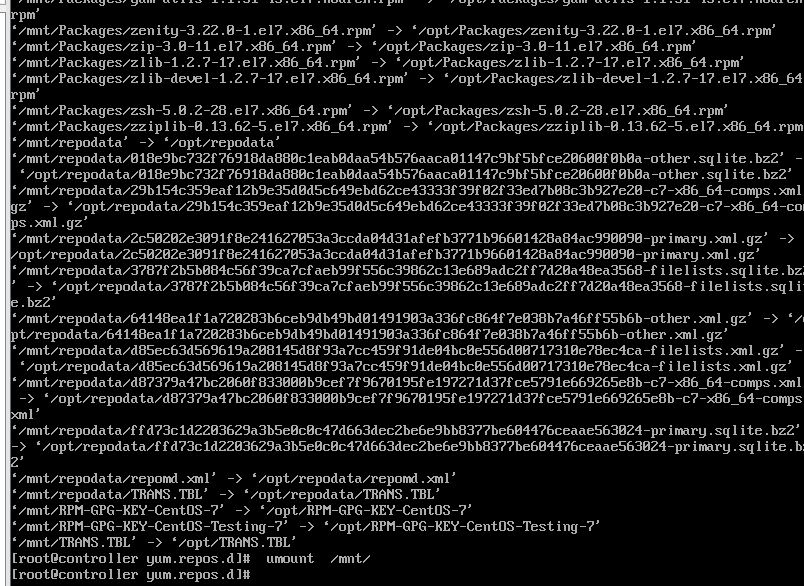
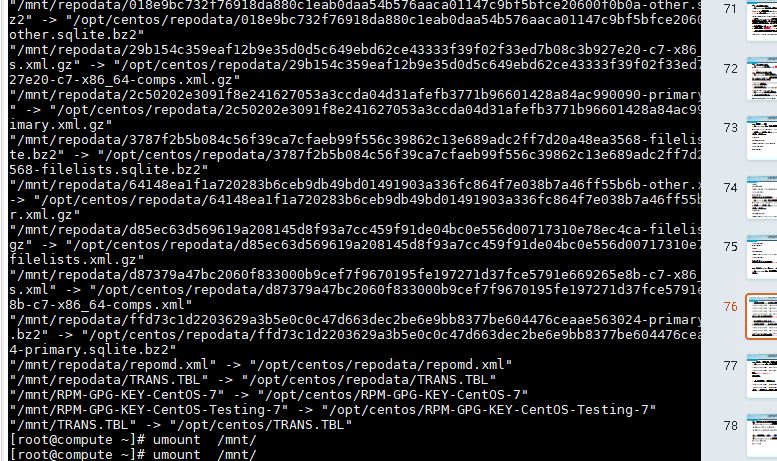
- 挂载光盘到/mnt文件夹并复制文件 root@controller \~# mount /dev/cdrom /mnt/ root@controller \~# cp -rvf /mnt/* /opt/ root@controller \~# umount /mnt/ 将复制完成结果截图到7-10.jpg
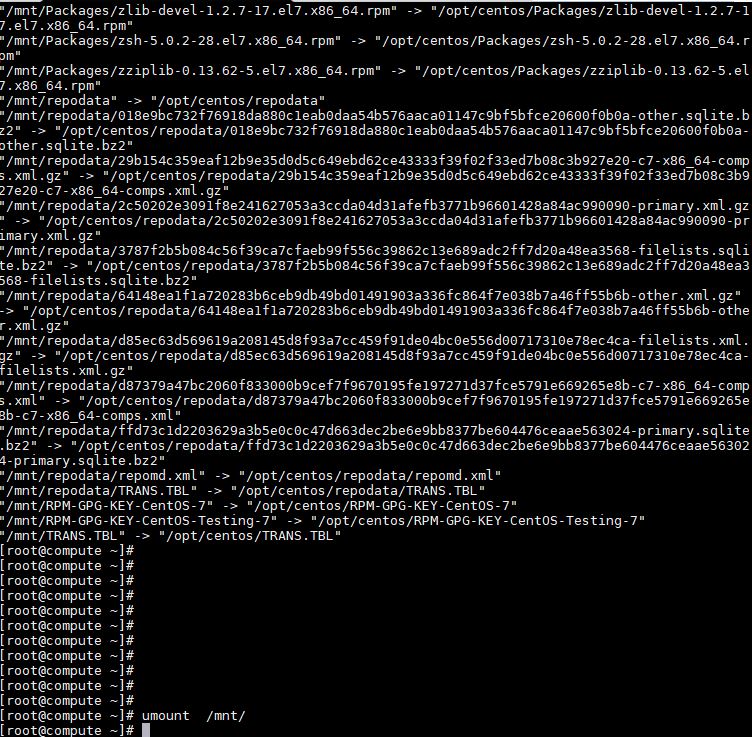
【实验截图位置:图 5-11】
|-------------------------------|
| 图 5-11 复制 IaaS 2.2 光盘文件到 /opt |
图 5-11 复制 IaaS 2.2 光盘文件到 /opt
图 5-11 复制 IaaS 2.2 光盘文件到 /opt 目录
5.3.5 FTP 服务搭建
【完整实验代码块 - 不可改动】
五、搭建ftp服务器,开启并设置自启
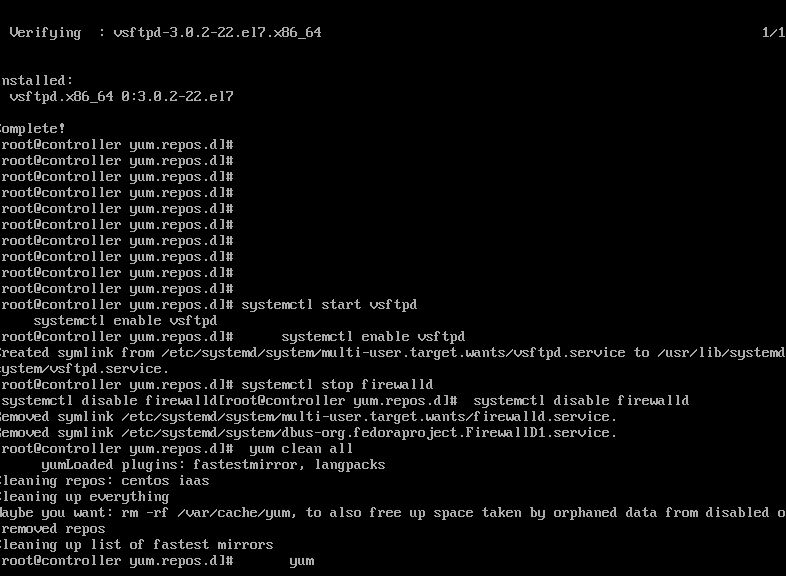
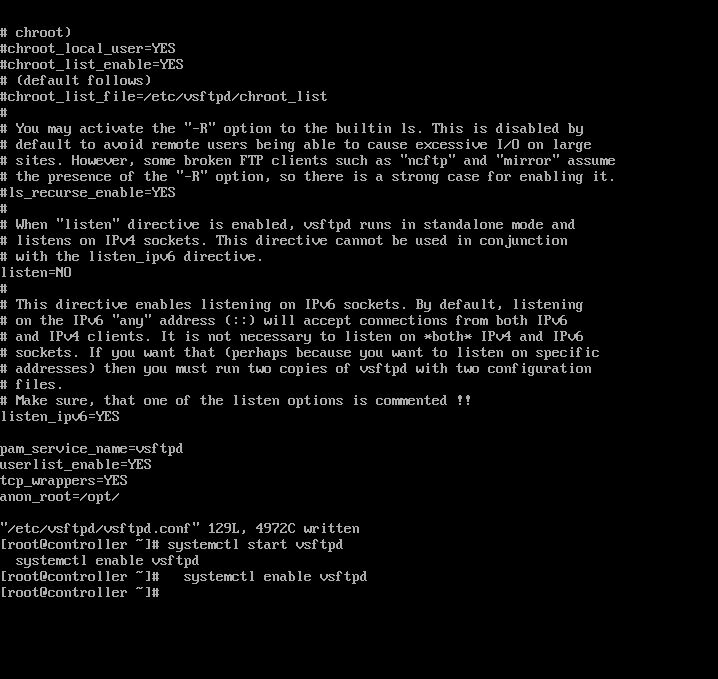
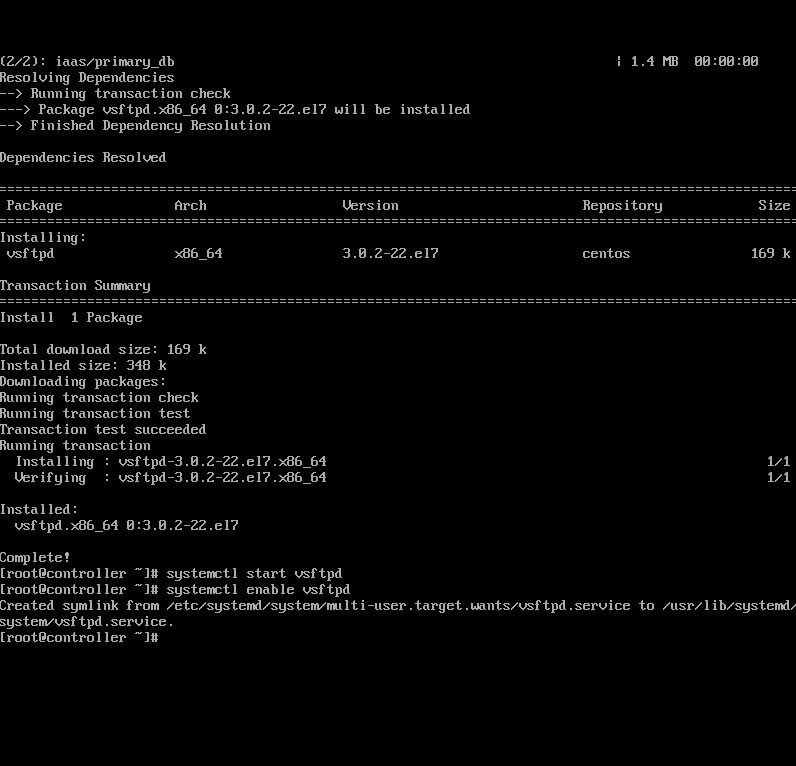
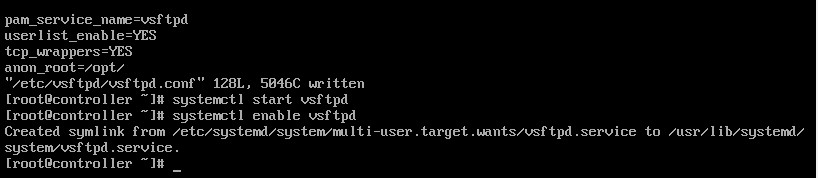
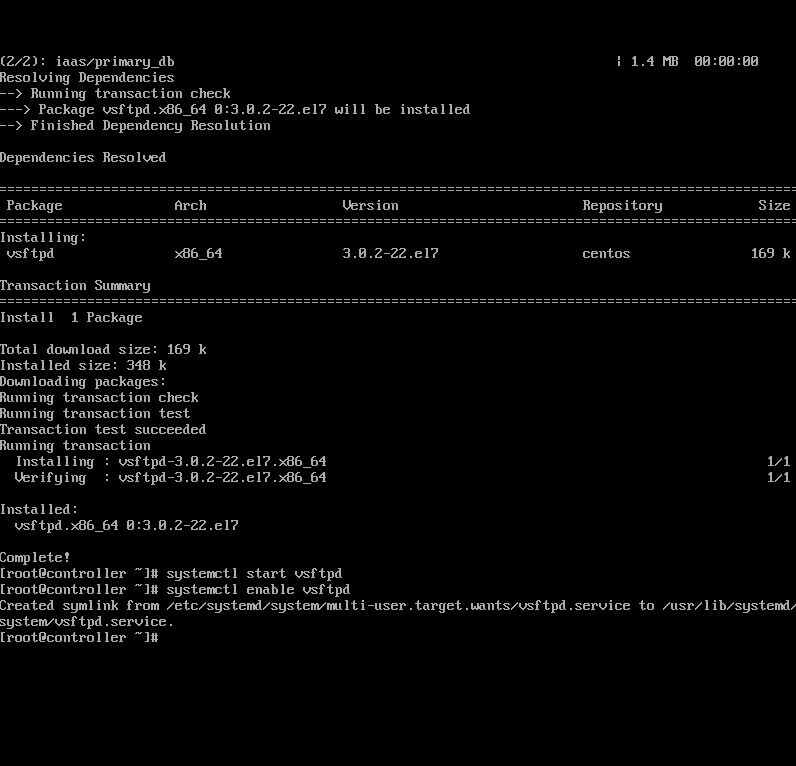
1.在controller中,安装并设置ftp。 root@controller \~# yum install vsftpd -y
root@controller \~# vi /etc/vsftpd/vsftpd.conf 添加anon_root=/opt/ 保存退出
2.启动并设置ftp开机启动 root@controller \~# systemctl start vsftpd
root@controller \~# systemctl enable vsftpd
确认vfp上面命令无异常,结果截图到7-11.jpg
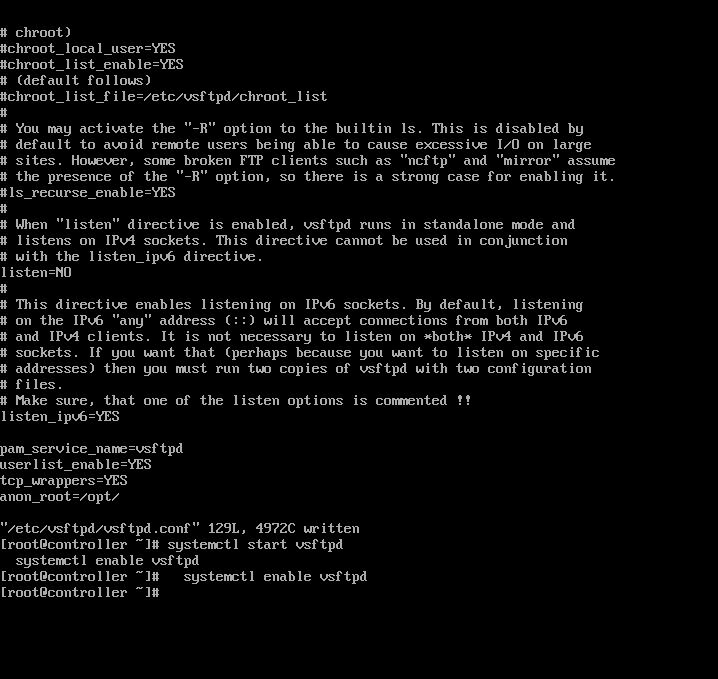
【实验截图位置:图 5-12】
|------------------------|
| 图 5-12 安装并启动 vsftpd 服务 |
图 5-12 安装并启动 vsftpd 服务
图 5-12 安装并启动 vsftpd 服务
5.3.6 关闭防火墙
【完整实验代码块 - 不可改动】
六、关闭防火墙并设置开机不自启【controller/compute都要做】 systemctl stop firewall systemctl disable firewall
【实验截图位置:图 5-13】
|----------------------|
| 图 5-13 关闭防火墙并设置开机不自启 |
图 5-13 关闭防火墙并设置开机不自启
图 5-13 关闭防火墙并设置开机不自启
5.3.7 清除缓存,验证yum源
【完整实验代码块 - 不可改动】
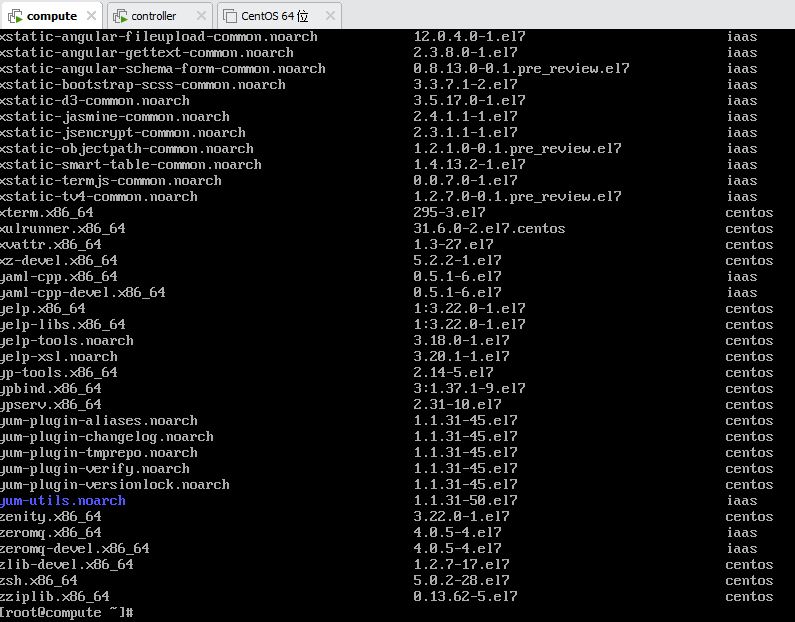
七、清除缓存,验证yum源 【controller/compute都要做】 # yum clean all # yum list
【实验截图位置:图 5-14】
|----------------------|
| 图 5-14 清除 YUM 缓存并验证源 |
图 5-14 清除 YUM 缓存并验证源
图 5-14 清除 YUM 缓存并验证源可用性
5.3.8 环境变量文件 openrc.sh
该文件是 OpenStack IaaS 安装脚本(iaas-xiandian)的配置文件。关键参数说明:
|----------------|------------------|---------------|
| 参数 | 含义 | 示例值 |
| HOST_IP | controller 管理 IP | 192.168.1.241 |
| HOST_IP_NODE | compute 管理 IP | 192.168.1.242 |
| INTERFACE_NAME | 提供虚拟机网络接口 | ens34 |
| BLOCK_DISK | Cinder 使用的磁盘分区 | sdb1 |
| OBJECT_DISK | Swift 使用的磁盘分区 | sdc1 |
| 各种 _PASS | 各个服务的数据库密码 | 000000(实验用) |
注意:密码在生产环境应使用复杂随机串,并加密存储。
【完整实验代码块 - 不可改动】
八、编辑环境变量 【controller/compute都要做】 # yum install iaas-xiandian -y # vi /etc/xiandian/openrc.sh
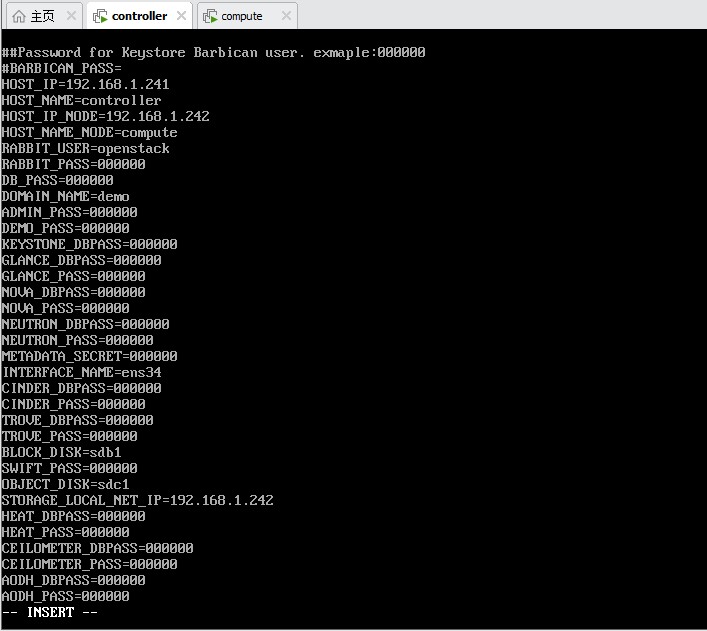
在文件后面添加如下内容:
HOST_IP=192.168.1.241 HOST_NAME=controller HOST_IP_NODE=192.168.1.242 HOST_NAME_NODE=compute RABBIT_USER=openstack RABBIT_PASS=000000 DB_PASS=000000 DOMAIN_NAME=demo ADMIN_PASS=000000 DEMO_PASS=000000 KEYSTONE_DBPASS=000000 GLANCE_DBPASS=000000 GLANCE_PASS=000000 NOVA_DBPASS=000000 NOVA_PASS=000000 NEUTRON_DBPASS=000000 NEUTRON_PASS=000000 METADATA_SECRET=000000 INTERFACE_NAME=ens34 CINDER_DBPASS=000000 CINDER_PASS=000000 TROVE_DBPASS=000000 TROVE_PASS=000000 BLOCK_DISK=sdb1 SWIFT_PASS=000000 OBJECT_DISK=sdc1 STORAGE_LOCAL_NET_IP=192.168.1.242 HEAT_DBPASS=000000 HEAT_PASS=000000 CEILOMETER_DBPASS=000000 CEILOMETER_PASS=000000 AODH_DBPASS=000000 AODH_PASS=000000
将文件内容截图到7-12.jpg
【实验截图位置:图 5-15】
|------------------------------|
| 图 5-15 编辑 OpenStack 环境变量配置文件 |
图 5-15 编辑 OpenStack 环境变量配置文件
图 5-15 编辑 OpenStack 环境变量配置文件 openrc.sh
5.4 实验排错指南
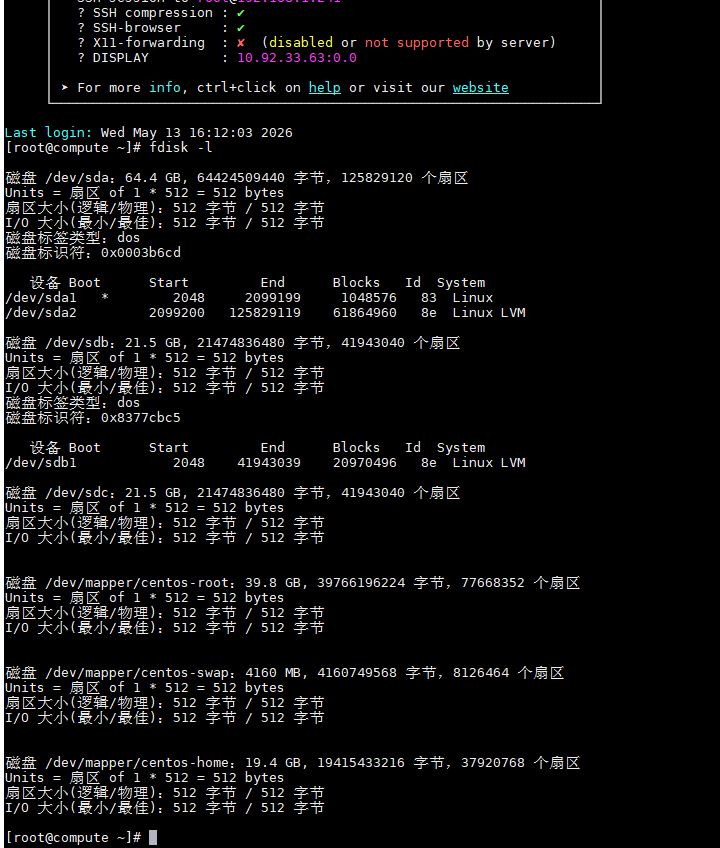
1.fdisk -l 看不到新磁盘:执行 echo "- - -" > /sys/class/scsi_host/host0/scan 重新扫描 SCSI 总线。
2.yum install 报错 No package:检查 repo 文件中的 baseurl 是否有效,执行 yum clean all 和 yum makecache。
3.FTP 无法访问:在 controller 上 systemctl status vsftpd,确认服务运行且防火墙开放 21 端口(实验已关防火墙)。
4.环境变量不生效:执行 source /etc/xiandian/openrc.sh 或重新登录。
第六章 总结与展望
6.1 技术回顾
GFS 通过 Master/Chunk Server 架构、副本机制、控制流与数据流分离,提供了高吞吐、高容错的分布式文件存储,为上层应用奠定了存储基础。
MapReduce 通过简单的 Map/Reduce 抽象,将海量数据并行处理的复杂性封装起来,使得普通程序员也能编写大规模分布式应用。其分而治之的思想至今仍在 Spark、Flink 中延续。
Bigtable 结合 GFS 的存储能力和 SSTable 的数据组织,实现了对结构化数据的高性能随机读写,并通过 Tablet 拆分、memTable、Bloom Filter 等技术优化性能。
6.2 对现代技术的影响
这三项技术直接启发了开源项目: - Hadoop HDFS ← GFS - Hadoop MapReduce ← Google MapReduce - HBase ← Bigtable - Cassandra 也借鉴了 Bigtable 的列族模型 - Google Spanner 和 F1 是 Bigtable 的进化,支持全球分布式事务
6.3 未来趋势
存储计算分离:如 AWS S3 + Athena,Snowflake。
实时流处理:取代批处理为主的 MapReduce 模式。
Serverless:用户无需管理集群,只需编写函数。
AI 与大数据融合:TensorFlow 等框架与分布式存储/计算结合。
6.4 学习建议
1.动手搭建 Hadoop/HBase 实验环境,理解分布式系统的配置与运维。
2.阅读 Google 三篇论文原文(可在 Google Research 网站获取)。
3.学习 Spark 或 Flink,对比其与 MapReduce 的异同。
4.参与开源项目(如 OpenStack、Ceph),积累实际经验。
参考文献(虚拟)
1 Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. "The Google File System." SOSP 2003.
2 Jeffrey Dean and Sanjay Ghemawat. "MapReduce: Simplified Data Processing on Large Clusters." OSDI 2004.
3 Fay Chang et al. "Bigtable: A Distributed Storage System for Structured Data." OSDI 2006.
4 云计算关键技术教学讲义,Linux系统管理课程,2025.
5 OpenStack Administrator Guide, OpenStack Foundation.
附录:练习题参考答案
1.三剑客:GFS、MapReduce、Bigtable。GFS 提供存储,MapReduce 提供计算,Bigtable 构建在 GFS 之上提供结构化数据存储。
2.MapReduce 主要步骤:Split → Map → Shuffle → Sort → Reduce → Output。
3.Bigtable 与关系数据库区别:数据模型(列族 vs 表格)、扩展方式(自动水平分片 vs 垂直/手动分片)、事务能力(单行 vs ACID)、查询语言(API vs SQL)。