1.背景
随着大模型能力的提升,AI 助手已经能够回答问题,但大多数助手仍然存在一个明显问题------ 缺乏长期记忆能力。每次对话结束后,用户的偏好、习惯和历史行为都会丢失,导致 AI 难以真正理解用户,更无法提供持续、个性化的服务。
-
在健康管理场景中,这一问题尤为突出。用户的饮食习惯、运动情况、睡眠质量、用药记录等信息具有长期积累和持续变化的特点,仅依靠单次对话很难形成全面认知。
-
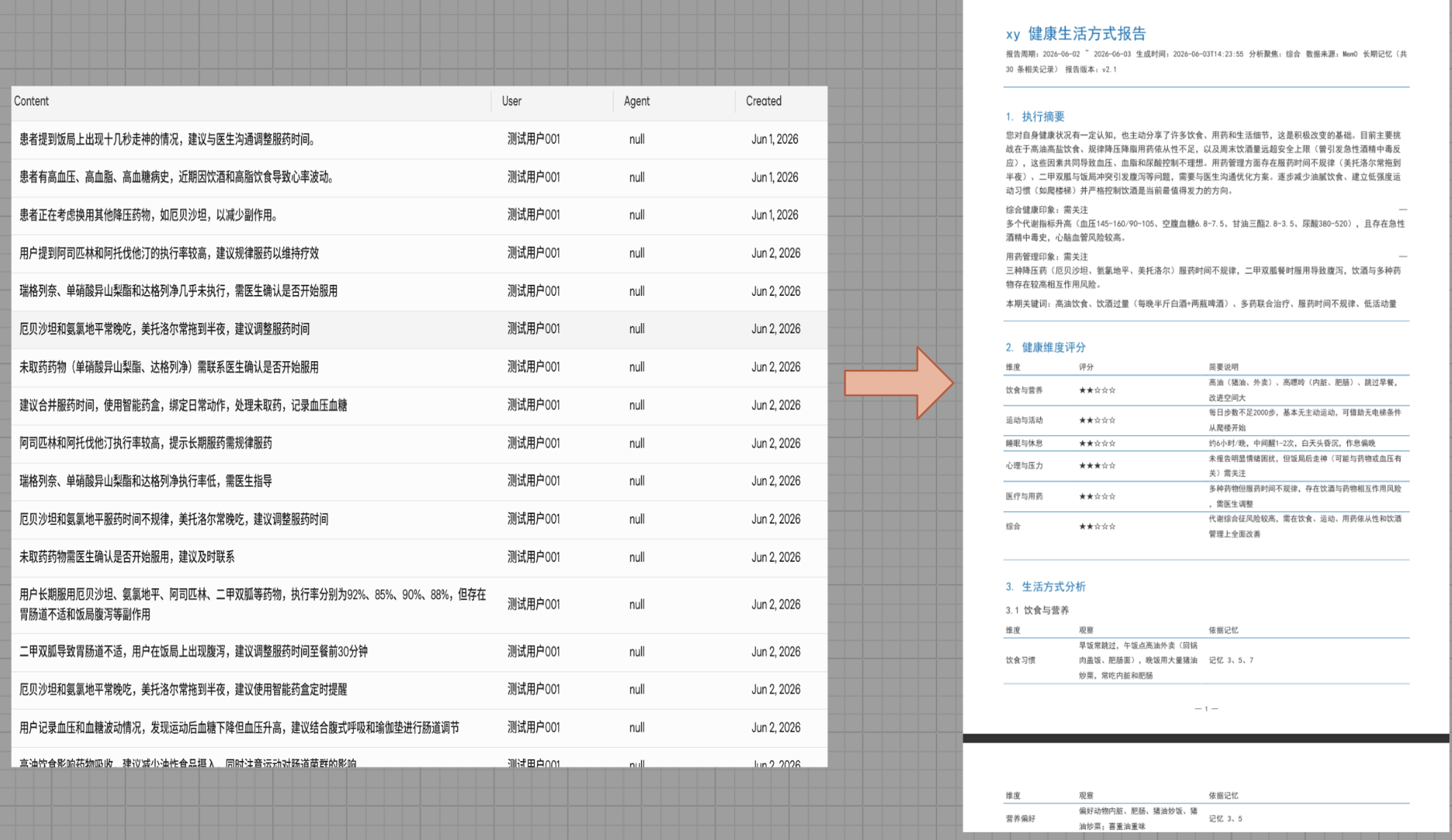
为了解决这一问题,开发了家庭健康助手 xy_healthy_assistant。项目基于 Mem0 + LLM + Health Report Skill 构建,通过 Mem0 持续沉淀用户健康记忆,让 AI 不仅能够回答问题,更能够长期了解用户。系统可以结合历史记忆自动生成个性化健康报告,分析生活方式变化趋势、识别潜在健康风险,并提供针对性的改善建议。
-
相比传统问答式 AI,xy_healthy_assistant 的核心价值在于让 AI 从"回答问题"进化为"理解用户",从而实现更加连续、主动和个性化的健康管理服务。
下面是根据mem0中的对话记忆生成的健康报告:
2.mem0与RAG
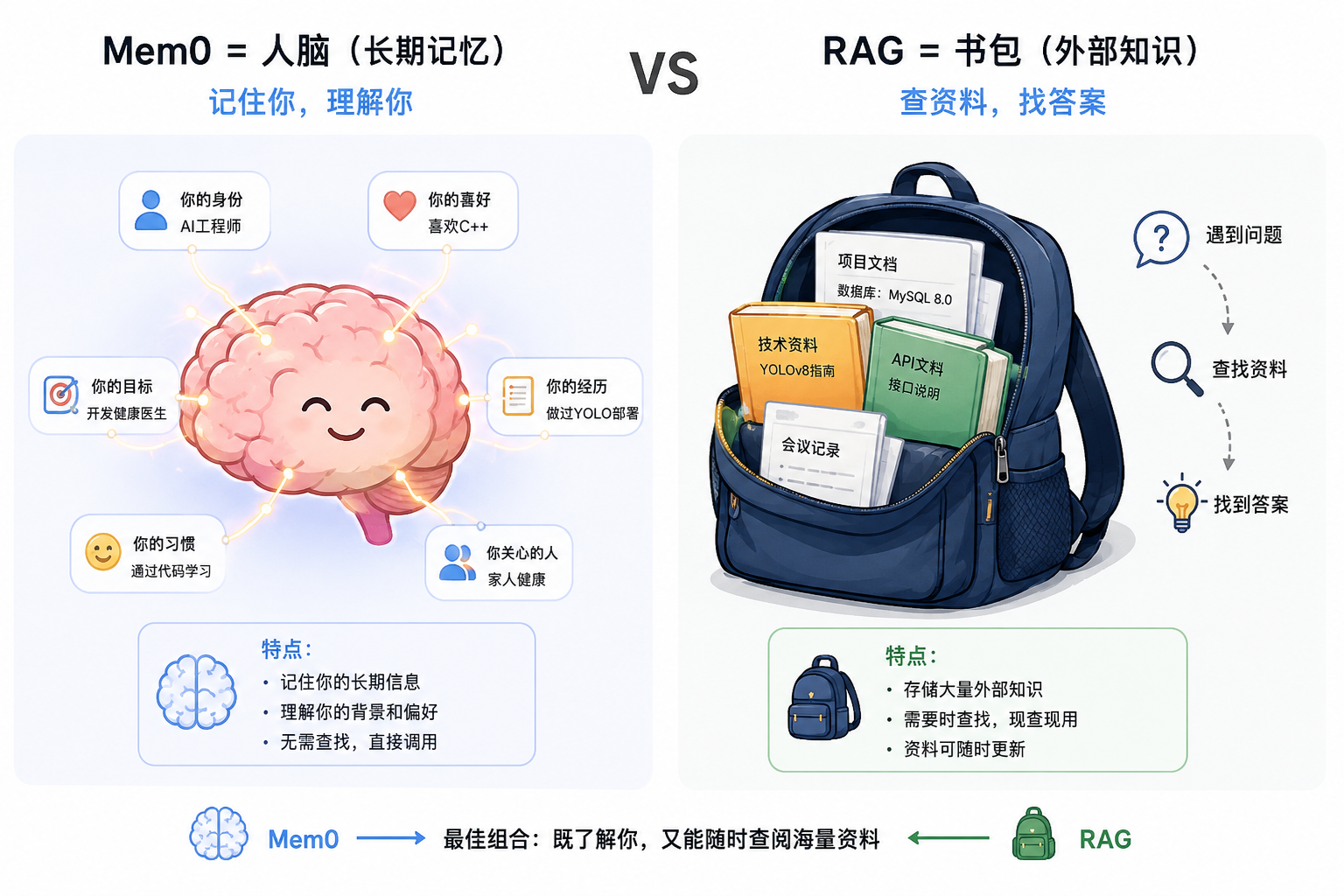
(1).功能定位
- 功能定位
- Mem0:长期记忆系统
- 类似于人脑的长期记忆。
- 记住与用户相关的历史信息和偏好。
- 支持个性化生成,例如根据用户日常运动、饮食和用药记录生成健康报告。
- 具有连续性和上下文关联能力。
- RAG:外部知识检索
- 类似于背包里的知识库或图书馆。
- 用户提出问题时,从外部资料中检索相关内容,再结合 LLM 生成答案。
- 适合处理通用知识和大型文档查询,但对用户个性化信息理解有限。
- Mem0:长期记忆系统
(2).数据来源与使用方式
| 特性 | Mem0 | RAG |
|---|---|---|
| 数据来源 | 用户长期输入、交互记录、健康日志 | 文档库、知识库、外部数据库 |
| 信息特性 | 高度个性化、带上下文 | 通用性、结构化或半结构化 |
| 检索方式 | 向量记忆 + 相关度匹配 | 文本匹配 + 向量搜索 |
| 生成策略 | 基于用户历史信息生成个性化建议 | 基于检索到的外部信息生成答案 |
(3).数据来源与使用方式
- Mem0 场景
- 生成个性化健康报告(如 PDF 示例中用户血压、用药和饮酒习惯分析)。
- 提醒用户按时服药或调整运动计划。
- 支持长期跟踪和行为改善建议。
- RAG 场景
- 查询健康常识、药物说明书、疾病指南。
- 生成通用问答或文档摘要。
- 不依赖用户个人历史信息。
3.Mem0 的核心检索原理------三重检索机制
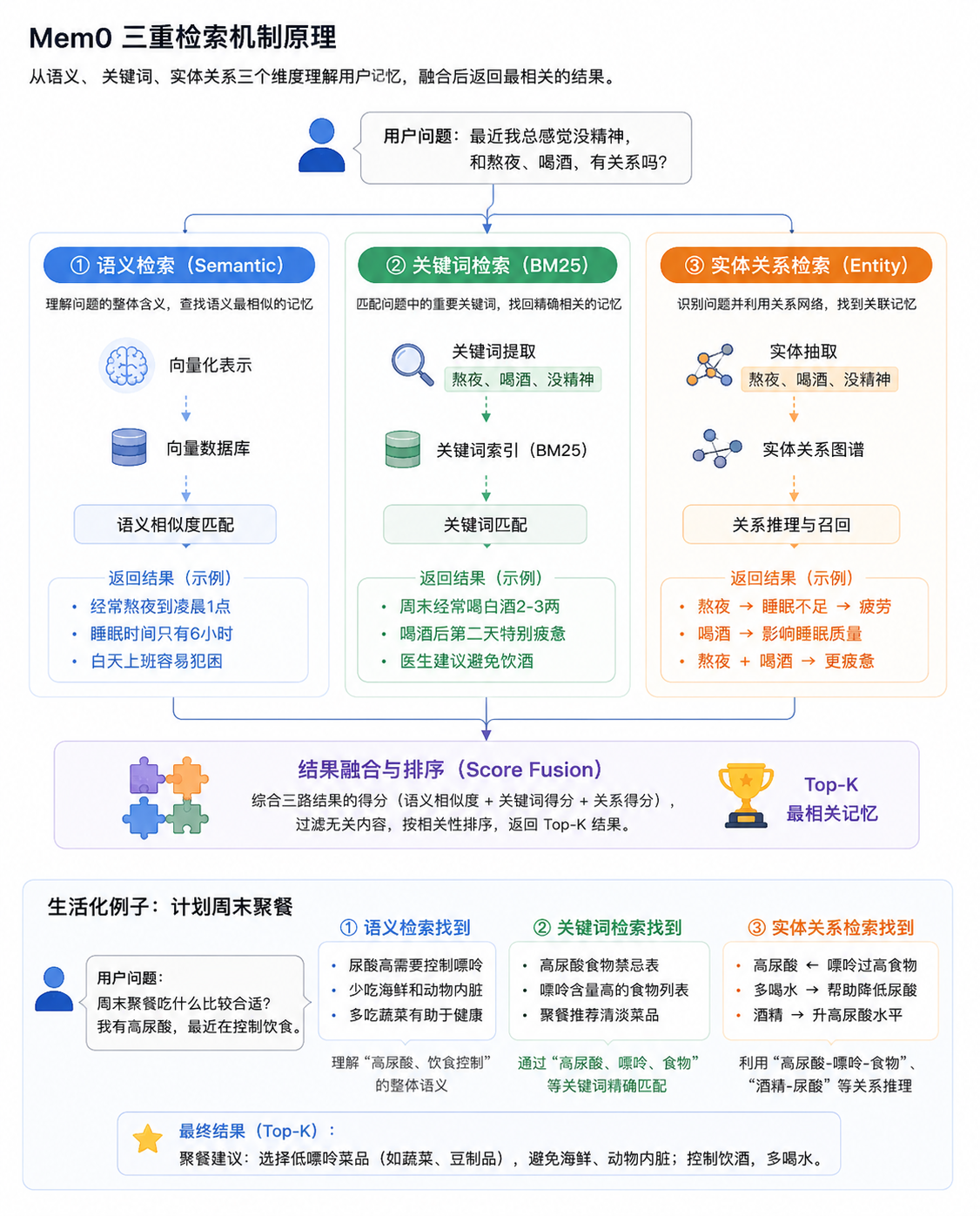
在传统大模型应用中,用户每次发起新的对话时,模型只能依赖当前上下文窗口进行推理。随着对话结束,用户的历史信息、行为习惯以及健康数据都会逐渐丢失。为了让 AI 真正具备长期记忆能力 ,xy_healthy_assistant 引入了 Mem0 作为长期记忆层。与传统向量检索不同,Mem0 并非简单地执行相似度搜索,而是采用Semantic Retrieval(语义检索)+ BM25 Retrieval(关键词检索)+ Entity Retrieval(实体关系检索) 的三重检索机制,通过多维度召回提升记忆检索的准确性。
3.1 语义检索(Semantic Retrieval)
语义检索是 Mem0 的基础层,它负责理解自然语言的意思,而不仅仅是匹配文字。
原理:
- 将用户问题或对话内容转换为向量表示。
- 在记忆库中寻找向量最接近的历史记忆。
- 即使文字不完全一致,也能找到语义相关的记忆。
生活化例子:
小明问:"我最近总是没精神,身体状态不好。"
系统会检索到:
- 日均步数不足2000步
- 睡眠时间6小时
- 周末经常熬夜
尽管小明没有明确提到"睡眠",系统仍然能匹配相关记忆。
优势:
- 能理解自然语言的多样表达
- 对模糊描述或同义表达有效
- 保证检索到与问题意思相关的内容
3.2 关键词检索(BM25 Retrieval)
关键词检索用于补充语义检索在专业名词或精确事实上的不足。
原理:
- 对用户输入进行词形还原(将"跑步"与"running"统一到基本形式"run")。
- 使用 BM25 算法匹配记忆库中含有相同关键词的记忆。
- 对专业词、药品名、数值指标尤为有效。
生活化例子:
小明问:"我服用非布司他需要注意什么?"
系统会检索到记忆:
- "服用非布司他控制尿酸"
- "非布司他需遵医嘱服用"
即使这些句子语义距离可能不大,关键词检索确保了精确命中。
优势:
- 精确召回关键事实
- 对专有名词、药品、检查项目效果显著
- 弥补语义检索可能遗漏的低频但重要信息
3.3 实体关系检索(Entity Retrieval)
实体关系检索是 Mem0 最独特的一层,它关注记忆之间的关联,而不仅仅是单条匹配。
原理:
- 系统识别用户输入中的实体,例如药物、疾病、习惯。
- 构建实体网络,将相关实体之间的关系加权。
- 检索时对与查询实体相关的记忆进行加分,提升关联性。
生活化例子:
小明问:"为什么我的血压一直控制不好?"
系统检索到的实体关系:
- 高血压
- 服用厄贝沙坦和氨氯地平
- 周末饮酒
通过实体网络发现饮酒可能抵消降压药效果,从而生成针对性的回答。
优势:
- 找出潜在因果关系,而不仅仅是相关事实
- 支持多实体、多维度问题
- 更接近人类联想记忆方式
3.4 三重检索的协同作用
三层检索不是孤立的,而是通过 混合评分融合(Score Fusion) 协同工作:
- 语义检索决定记忆是否相关
- BM25 提升精确关键词召回能力
- 实体关系检索强化关联性和推理能力
生活化总结:
可以把它想象成:
- 语义检索:理解问题的大意
- 关键词检索:抓住核心事实
- 实体关系检索:理解事实之间的联系
三者结合,Mem0 能从海量历史对话中精准召回用户相关的健康记忆,形成可供 LLM 生成个性化报告的高质量上下文。
3.5 在健康报告中的应用
在生成健康报告时,系统会针对多维度主题(饮食、运动、睡眠、用药、检查指标)分别执行三重检索,然后融合排序,最终生成:
- 个性化饮食建议
- 运动计划提醒
- 用药与检查注意事项
- 生活方式改进建议
通过这种方式,Mem0 不仅记住用户说过的事情,还理解哪些事情重要、哪些事情相关,从而实现真正"记得住、找得准、说得对"的智能健康助手。
4.Health Report Skill 与人物画像
Mem0 如何通过三重检索机制,从海量记忆中找回与用户最相关的信息。然而,仅靠记忆检索还无法直接生成个性化健康报告。为了让健康报告更加精准和个性化,xy_healthy_assistant 引入了 人物画像(User Persona) 与 Health Report Skill 的结合使用。 人物画像的核心作用是对用户的长期健康特征、行为习惯和健康风险进行结构化整理,为生成健康报告提供清晰的输入。
4.1 人物画像的概念
人物画像可以理解为:
当前用户的综合健康特征和行为偏好集合
它不仅包括用户的生理特征和疾病史,还包括生活习惯、用药信息、运动习惯、饮食偏好等。通过人物画像,系统能够将零散的记忆整合成一个整体视图,使 Health Report Skill 可以在此基础上进行专业分析和报告生成。
举例:
- 年龄:55岁
- BMI:28.5
- 高血压病史:4年
- 用药情况:长期服用降压药
- 生活习惯:周末饮酒,早餐不规律
- 运动习惯:日均步数不足2000步
- 睡眠习惯:平均睡眠时间不足6小时
这些信息构成了完整的人物画像,用于指导健康报告的生成。
4.2 人物画像的构建流程
在 xy_healthy_assistant 中,人物画像主要由三类信息组成:
- 基础画像
- 年龄、性别
- 身高、体重、BMI
- 疾病史、慢性病状况
- 长期用药信息
这部分信息变化较慢,是健康分析的基础。
- 行为画像
- 饮食习惯(高脂、高盐等)
- 饮酒情况
- 运动频率和强度
- 睡眠时间和质量
行为画像变化频繁,是健康风险评估的重要依据。
- 风险画像
- 血压波动异常
- 心血管疾病风险
- 高尿酸风险
- 运动不足导致的肥胖风险
风险画像用于指导 Health Report Skill 生成个性化健康建议。
4.3 Health Report Skill 的作用
人物画像构建完成后,Health Report Skill 会消费这些结构化信息,并进行健康分析与报告生成。其主要功能包括:
-
健康现状分析
根据基础画像与行为画像,判断用户当前健康指标和生活习惯的合理性。
-
风险识别
结合风险画像,发现潜在健康隐患,例如用药与生活习惯的冲突。
-
个性化建议生成
提供可执行的健康管理建议,例如控制饮酒、增加运动、改善睡眠。
-
报告输出
生成结构化、易读的健康报告,包括:
- 健康概况
- 风险分析
- 行为评估
- 改善建议
- 下周行动计划
4.4 Mem0 与人物画像的协同
整个流程中,三者的关系可以总结为:
text
用户长期健康记忆
↓
Mem0三重检索
↓
人物画像构建
↓
Health Report Skill分析
↓
个性化健康报告生成5.部署与配置概述
本项目推荐运行于配备 NVIDIA GPU 的 Linux 环境,核心组件通过 Docker 容器化部署以确保稳定性。
- 硬件要求:建议至少 8GB 内存及支持 CUDA 的显卡(本地推理);若仅使用云端 API,常规 Linux 服务器即可。
- 记忆引擎:使用 Docker 部署 Mem0 服务,通过挂载宿主机绝对路径确保数据持久化。
- 模型配置:项目支持通过 config.yaml 灵活切换推理模式:
- Ollama:适合本地轻量测试。
- vLLM:适合高并发、生产环境,提供兼容 OpenAI 的 API 接口。
- API:直接对接主流云端大模型,无需配置本地算力。
5. 架构的横向扩展与更多应用场景
当前的 LLM + Mem0 + Skill 架构具有极高的解耦性。只需替换检索策略(Queries)、输出模板与绑定的执行接口,即可快速将本系统扩展至其他垂直领域:
- 研发辅助 Copilot
- 记忆沉淀:记录你的偏好技术栈(如只用 FastAPI、习惯用 uv 管理环境)、代码格式规范以及历史踩坑记录。
- Skill 联动:在审查代码或生成脚手架时,自动拉取历史规约进行 Code Review,输出完全符合你个人风格的工程代码。
- 个人知识库 (第二大脑)
- 记忆沉淀:在日常对话中,自动提取并存储你的碎片化灵感、阅读偏好及核心关注的行业赛道。
- Skill 联动:对接 Notion 或 Obsidian API,将平时零散的聊天记录,按周自动整理归类,生成结构化的知识网络或深度阅读简报。
- 日程与效率管家
- 记忆沉淀:记住你的通勤时间、差旅偏好、会议习惯以及当前高优推进的核心项目。
- Skill 联动:打通日历、天气与邮件系统,在每天早晨主动为你生成一份排版精美的"晨间智能简报",并在关键日程前自动触发提醒。
6.项目视频展示
视频链接: 录制中