一、你为什么需要工作流串联
先用一张图说清楚问题:
你现在的流程(手动): 打开ChatGPT → 复制粘贴 → 打开搜索引擎 → 查资料 → 切回编辑器 → 写初稿 → 打开图片工具 → 配图 → 打开发布平台 → 排版 → 发布 理想流程(工作流): 输入主题 → [扣子工作流自动跑] → 输出完整文章+配图
前者每一步都是「打开→切换→复制→粘贴」,一天写一篇就累得够呛。后者只需输入一个主题,流水线自动跑完,你只做最后的审核发布。
这就是扣子工作流的核心价值:把多个 AI 节点串成一条生产线。
市面上大部分教程只讲单个节点怎么用------代码节点能干啥、大模型节点怎么配。但真正值钱的是多节点串联的能力,也就是本文的重点。
二、环境准备
| 项目 | 说明 |
|---|---|
| 扣子平台 | coze.cn 注册账号 |
| 工作流入口 | 扣子工作台 → 工作流 → 新建工作流 |
| 外部工具 | 本文用到「必应搜索」插件 + 「头条搜索」插件 |
前置知识:建议先了解工作流基本概念(开始节点、结束节点、连线)。如果是零基础,先看扣子官方文档 5 分钟即可。
三、核心实战:搭建一条「选题→成文」流水线
3.1 整体架构
我们要搭的工作流包含 6 个节点:
[开始] → [代码:生成搜索词] → [插件:必应搜索] ↓ [结束] ← [大模型:润色成文] ← [代码:清洗结果]
第一步:新建工作流
在扣子工作台点击「新建工作流」,命名为「AI 内容生成流水线」。
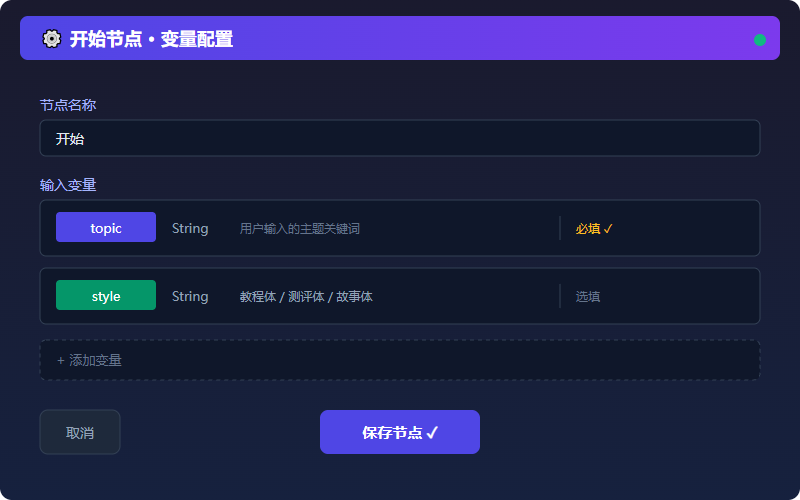
第二步:添加开始节点变量
在开始节点中定义两个输入变量:
| 变量名 | 类型 | 说明 |
|---|---|---|
| topic | String | 用户输入的主题,如"扣子工作流入门" |
| style | String | 文章风格,如"教程体""测评体""故事体" |
3.2 代码节点①:生成搜索关键词
扣子的代码节点支持 JavaScript/Python,这里用 JS 写一个搜索词生成器:
// 代码节点:根据 topic 生成 3 个搜索关键词
function main({ topic, style }) {
const prefixes = [
`${topic} 入门教程`,
`${topic} 实战案例`,
`${topic} 常见问题`,
];
const styleMap = {
"教程体": " step by step",
"测评体": " 对比评测",
"故事体": " 经验分享",
};
const suffix = styleMap[style] || "";
const queries = prefixes.map(p => p + suffix);
return {
query1: queries[0],
query2: queries[1],
query3: queries[2],
};
}新手坑点:代码节点的 main 函数必须接收一个对象参数,返回一个对象。直接 return 字符串会报错。
3.3 插件节点:调用必应搜索
扣子内置了「必应搜索」插件,直接拖进来即可。这里配置循环调用------让三个搜索词依次执行搜索。
关键操作:配置循环变量
- 在左侧拖入「必应搜索」插件
- 点击节点右上角「···」→「设置为循环节点」
- 循环变量选代码节点输出的 query1, query2, query3
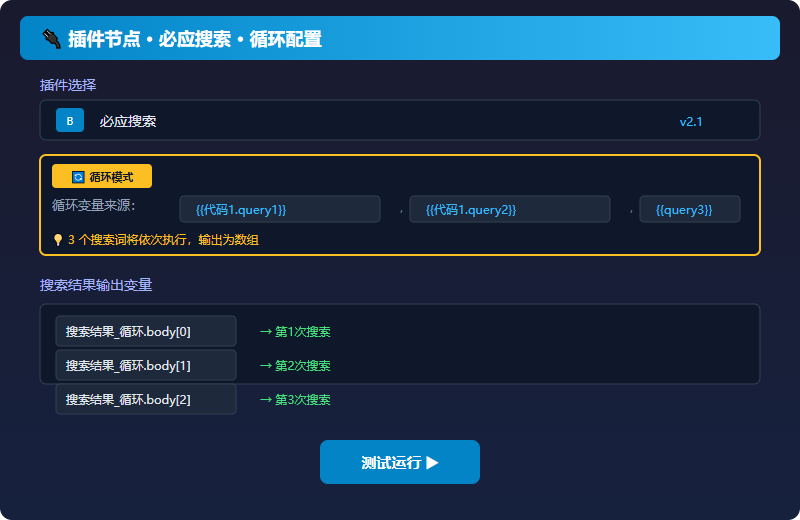
循环节点的输出是一个数组,后续节点需要通过索引取值。这是很多人踩的第一个坑------直接引用变量会发现取不到值。
正确写法:
{{搜索结果_循环.body[0]}} // 取第一次搜索的结果
{{搜索结果_循环.body[1]}} // 取第二次搜索的结果3.4 代码节点②:清洗搜索结果
搜索返回的 JSON 里大量无用字段,需要用代码节点做一次清洗:
function main({ searchResults, topic }) {
// searchResults 是必应搜索返回的 JSON 字符串
const parsed = typeof searchResults === 'string'
? JSON.parse(searchResults)
: searchResults;
const cleanResults = [];
// 遍历搜索结果(可能是数组或嵌套对象)
const items = parsed.webPages?.value || parsed.value || [];
for (const item of items.slice(0, 10)) {
cleanResults.push({
title: item.name || item.title || "",
url: item.url || "",
snippet: (item.snippet || item.summary || "").slice(0, 200),
});
}
// 格式化成大模型易读的文本
const formatted = cleanResults
.map((r, i) => `[${i + 1}] ${r.title}\n ${r.snippet}\n 链接: ${r.url}`)
.join('\n\n');
return {
cleanText: formatted,
resultCount: cleanResults.length
};
}踩坑记录:不同插件的输出结构不一样。必应搜索返回 webPages.value,头条搜索返回 data.list。写清洗代码前先用「调试运行」看原始 JSON 结构。
3.5 大模型节点:润色成文
把清洗后的资料喂给大模型,让它生成完整文章。
Prompt 配置:
你是一个技术内容编辑。请根据以下搜索资料,写一篇关于「{{开始.topic}}」的技术文章。
要求:
1. 风格为「{{开始.style}}」
2. 文章长度 1500-2000 字
3. 分 3-4 个小节,每节有小标题
4. 语言通俗易懂,避免学术腔
5. 文末加一个「实用建议」小节
搜索资料如下:
{{代码2.cleanText}}
请直接输出 Markdown 格式的文章正文。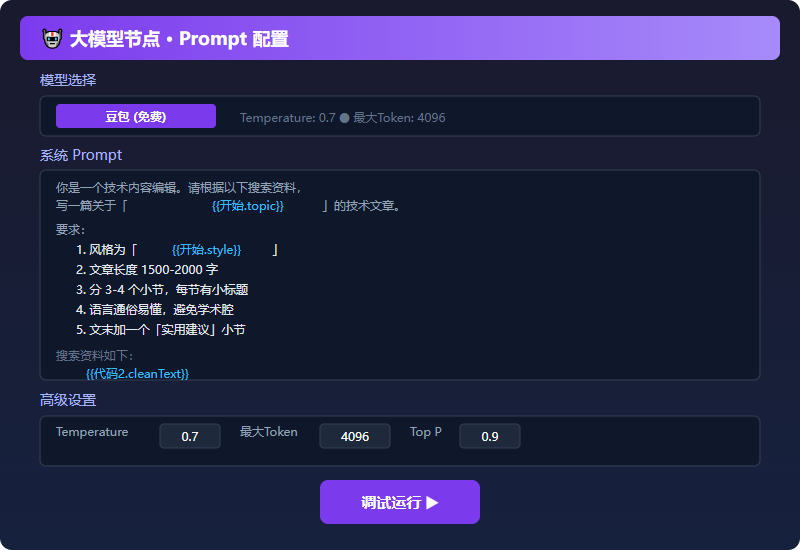
模型参数建议:
| 参数 | 推荐值 | 说明 |
|---|---|---|
| 模型 | 豆包/通义千问(免费) | 扣子免费额度足够日常使用 |
| Temperature | 0.7 | 保持一定创造性 |
| 最大Tokens | 4096 | 确保长文不截断 |
3.6 结束节点:组装最终输出
在结束节点中,将各环节的输出整理成一个结构化结果:
输出变量:
- title: "关于「{{开始.topic}}」的技术文章"
- article: {{大模型_output.output}}
- sources: {{代码2.resultCount}} 条参考资料
- keywords: {{代码1.query1}}, {{代码1.query2}}, {{代码1.query3}}点击「测试运行」,输入 topic=扣子工作流,style=教程体,看整条链路能否一次跑通。
四、进阶技巧:条件分支 + 变量引用
4.1 根据搜索结果数量做分支
如果搜索返回 0 条结果,没必要继续跑大模型。加一个条件分支:
[代码2:清洗结果] → [条件判断]
├→ resultCount >= 3 → [大模型:润色]
└→ resultCount < 3 → [代码:生成兜底内容]条件判断节点配置:
- 条件 1:{{代码2.resultCount}} >= 3
- 条件 2:{{代码2.resultCount}} < 3
分支 2 的兜底代码节点:
function main({ topic, style }) {
return {
fallback: `关于「${topic}」,目前搜索信息不足。以下是基于现有知识的概述:\n\n` +
`(此处可接大模型做知识库问答)`
};
}4.2 变量引用的层级问题
扣子工作流中,循环节点内部的变量引用和非循环节点不一样:
| 场景 | 引用方式 |
|---|---|
| 普通节点输出 | {{节点名.变量名}} |
| 循环节点输出(当前轮) | {{循环节点.变量名}} |
| 循环节点输出(全部) | {{循环节点_循环.变量名}} |
关键规则:在循环内部引用变量,用不带 _循环 后缀的形式。在循环外部引用,必须带 _循环 后缀。
这是 80% 的新手会踩的坑------变量明明定义了但死活取不到值,通常就是后缀问题。
五、复盘:3 个容易忽略的问题
① 节点输出变量名不一致
每个节点的输出变量名由「节点名称」决定,改名后引用路径也会变。建议先定好节点名再连线,别中途改名。
② 大模型节点超时
默认超时 120 秒,但如果 Prompt 太长 + 搜索结果很多,可能超时。对策:清洗环节把搜索结果控制在 10 条以内,每条的 snippet 限制 200 字。
③ 免费额度不够用
扣子免费版每天有一定调用次数。如果你的工作流要高频使用,可以接自己的 API Key(在模型配置里切换为「自定义模型」),成本很低------豆包 API 千次调用不到 1 块钱。
六、总结
- 核心思路 :扣子工作流不是单个节点的叠加,而是一条完整自动化流水线的设计
- 关键技能:代码节点做数据清洗 → 插件节点做外部调用 → 大模型节点做最终输出
- 踩坑重点:循环变量引用、输出结构解析、节点超时配置
如果你想把这条流水线做得更复杂------比如接入图片生成(文生图节点)、自动发布到 WordPress(HTTP 请求节点)、多个大模型对比输出------这些高级玩法需要更多节点串联技巧,本质上都是本文这套思路的延伸。
关于作者 :专注 AI 工作流自动化,更多扣子工作流模板和进阶教程可搜索「米核AI易山」或访问 miheaii.com 获取。
本文部分内容由 AI 辅助完成。