大数据 项目 综合实战 答辩 要求讲解
项目答辩以 ++++小组形似++++ 进行:每组最多3人,特殊情况可以独自建队。
答辩的顺序:1.各答辩小组经过讨论后自行决定顺序;2.无法决定顺序的组使用课堂点名程序进行排序。由于排序会对位于后面的小组给与时间与技术上的优势,所以每节课答辩完成后,后续小组会在总分上减去3分,以保证答辩的公平性。 例如: 第一场答辩有三个小组, 该三个小组的总分为100分。 第二场答辩有2个小组,该小组的总分从97分开始计算,以此类推。
如果第一场答辩有五个小组进行,但只完成了三个小组的答辩,剩下的小组默认转为第二轮答辩组,成绩按第二轮的成绩进行评估,以此类推。
如果在答辩的过程中如出现程序运行错误,抛出异常等BUG无法正确执行,可在操作过程中解决了bug等问题(可以通过技术手段如AI等)。如未能解决异常,该小组则需下台调整程序,并扣除相应的分值,待其余小组答辩完成后方可继续答辩。
答辩分为 三 部分 ( 100分 ) :
第一 部分 : 项目概述(40分)
对大数据广告监测项目的整个流程进行讲述。
- 项目背景与目标
- 一句话说明:这是一个大数据广告监测项目,核心目标是从多源数据中采集、清洗、分析广告行为数据,最终用可视化呈现广告效果,为业务决策提供数据支撑。
- 补充:为什么要做这个项目?(比如解决广告投放效果不透明、数据分散难分析、人工统计效率低等问题)
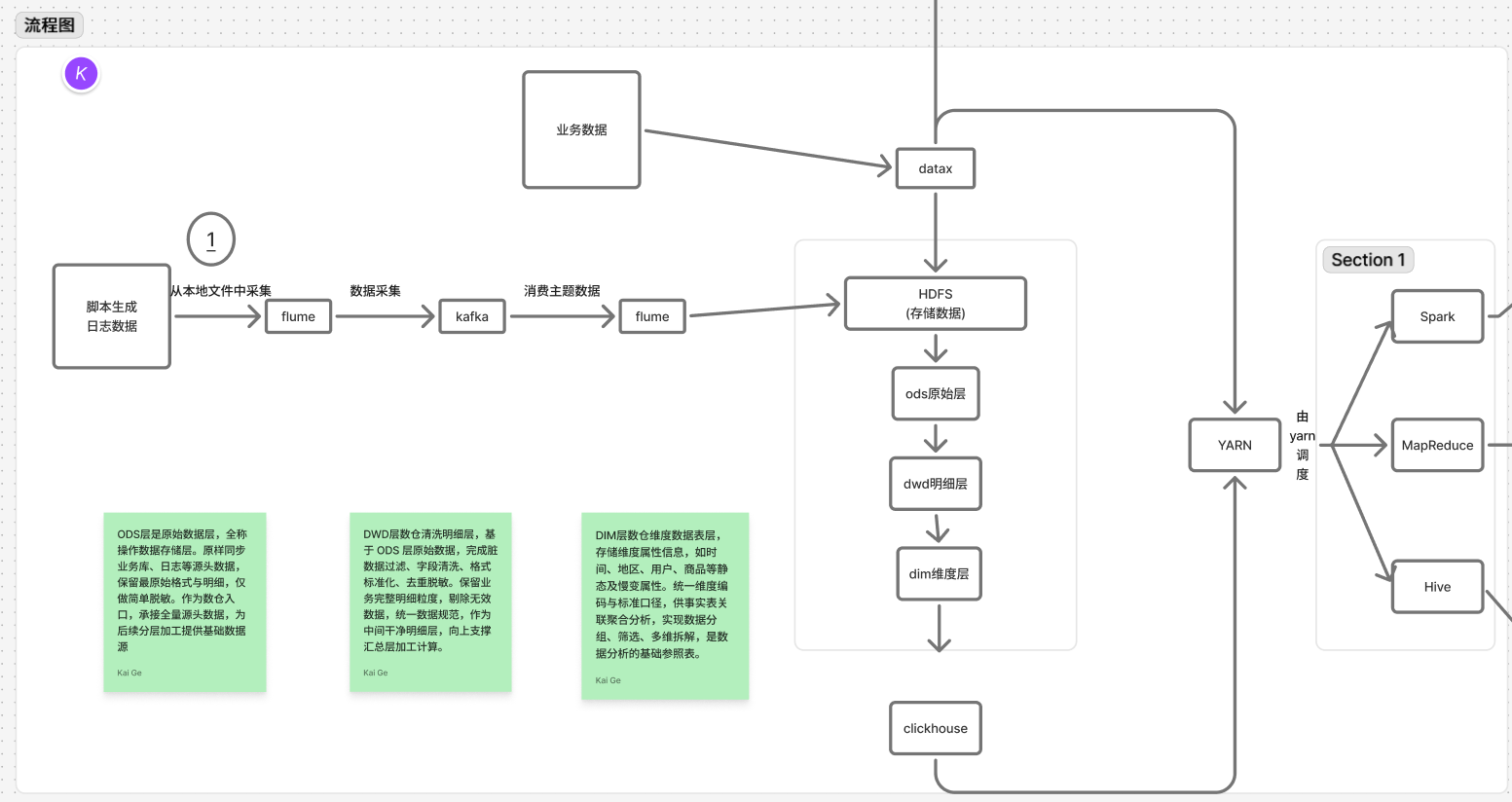
- **整体技术架构(结合你给的流程图)**照着你的流程图讲清楚数据流转的完整链路:
- 数据来源:用户行为日志数据 + 业务数据
- 采集链路:
- 日志数据:Flume → Kafka → Flume → HDFS/Hive(ODS 层)
- 业务数据:DataX → HDFS/Hive(ODS 层)
- 存储与计算:Hadoop(HDFS 存数据、YARN 调度、MapReduce/Spark 计算)
- 数仓分层:ODS(原始数据)→ DWD(明细清洗)→ DIM(维度层)
- 数据落地:Spark 处理后迁移到 ClickHouse
- 数据应用:可视化大屏 / 报表
大数据广告监测项目 第一部分全覆盖基础技术问答
(全是课堂答辩常考基础题,超好背,全覆盖无遗漏)
一、Hadoop 相关问答
- 问:Hadoop 是什么答:开源分布式大数据基础框架,是我们整个项目的底层环境支撑。
- 问:Hadoop 三大核心组件答:HDFS、YARN、MapReduce。
- 问:HDFS 主要作用答:分布式文件系统,用来统一存储项目所有日志数据和业务数据。
- 问:HDFS 优点答:存储量大、安全性高、支持集群扩展、适合存放海量大数据文件。
- 问:YARN 的作用答:集群资源调度管理器,负责分配内存、CPU 资源,调度运行各类大数据任务。
- 问:MapReduce 作用答:传统离线分布式计算引擎,用来做简单批量数据统计计算。
- 问:Hadoop 适合处理什么数据答:海量离线大批量数据,不适合实时高频小数据。
- 问:HDFS 默认存储格式是什么答:普通文本、日志文件、压缩文件都可以存放。
二、Flume 日志采集问答
- 问:Flume 是什么答:轻量级分布式日志采集工具,专门采集服务器本地日志。
- 问:Flume 三大核心组件答:Source 数据源、Channel 通道缓冲、Sink 数据输出。
- 问:Source 负责做什么答:读取本地日志文件,抓取产生的日志信息。
- 问:Channel 负责做什么答:临时缓存数据,防止数据过快丢失。
- 问:Sink 负责做什么答:把采集好的数据输出到指定位置。
- 问:本项目 Flume 最终把日志传到哪里答:先传入 Kafka 消息队列,再消费存入 HDFS。
- 问:Flume 可以同时采集多种日志吗答:可以,支持多路径、多类型日志同时采集。
- 问:Flume 采集日志优势答:部署简单、稳定可靠、占用资源小、适配大数据生态。
三、Kafka 消息队列问答
- 问:Kafka 是什么答:分布式流式消息中间件,俗称消息队列。
- 问:项目中使用 Kafka 目的答:流量削峰、数据缓冲、解耦上下游程序,防止日志爆发压垮集群。
- 问:Kafka 里主题是什么答:Topic,用来分类存放不同类型数据流。
- 问:Kafka 生产者作用答:往队列里推送数据。
- 问:Kafka 消费者作用答:从队列里拉取数据进行处理。
- 问:Kafka 依靠什么组件管理集群答:依靠 Zookeeper 完成集群协调管理。
- 问:Kafka 数据可以保存多久答:可自行配置持久化时间,支持数据回溯重读。
- 问:为什么不直接 Flume 传 HDFS,非要加 Kafka答:日志流量不稳定,高峰时段容易丢数据,加队列更稳定。
四、Zookeeper 协调组件问答
- 问:Zookeeper 作用答:分布式协调服务,统一管理集群状态。
- 问:项目中哪些组件依赖它答:Kafka、Hadoop 集群都依赖 Zookeeper。
- 问:主要实现什么功能答:集群节点选举、配置管理、服务注册、状态同步。
- 问:没有 Zookeeper 会怎么样答:集群服务无法正常协调,容易出现服务异常宕机。
五、DataX 数据同步问答
- 问:DataX 是什么答:阿里开源离线异构数据同步工具。
- 问:本项目用它同步什么数据答:同步广告业务数据,比如 MySQL 业务表数据。
- 问:DataX 两大核心模块答:Reader 数据读取、Writer 数据写入。
- 问:Reader 负责什么答:读取源头业务数据库中的数据。
- 问:Writer 负责什么答:把读取到的数据写入 HDFS 或者 Hive 表。
- 问:DataX 适合实时同步吗答:不适合,只适合离线大批量数据同步。
- 问:DataX 优势答:配置简单、支持几乎所有主流数据库、同步效率高。
六、Hive 数据仓库问答
- 问:Hive 是什么答:基于 Hadoop 构建的数据仓库工具。
- 问:Hive 作用答:把 HDFS 上零散文件映射成数据表,使用 SQL 语句分析大数据。
- 问:Hive 真实数据存在哪里答:真实数据存 HDFS,表结构元数据存在 Hive 自身数据库。
- 问:为什么要用 Hive 做数仓答:上手简单,类 SQL 语法,适合做离线数据分层治理。
- 问:项目数仓三层分别是什么答:ODS 原始层、DWD 明细清洗层、DIM 维度层。
- 问:ODS 层存放什么答:未经任何处理的原始数据,原样留存。
- 问:DWD 层做什么操作答:过滤脏数据、去重、字段规整、剔除无效数据。
- 问:DIM 维度层存放什么答:时间、地区、用户、广告渠道等基础维度信息。
- 问:数据分层有什么好处答:条理清晰、方便排查错误、便于后期数据统计计算。
- 问:Hive 执行引擎默认是什么答:默认 MapReduce,项目中我们常用 Spark 引擎。
七、Spark 计算框架问答
- 问:Spark 是什么答:快速通用分布式大数据计算框架。
- 问:Spark 对比 MapReduce 最大优势答:基于内存计算,运算速度快很多。
- 问:本项目 Spark 用来做什么答:做数据统计分析、指标计算、最后批量迁移数据到 ClickHouse。
- 问:Spark 可以处理离线和实时数据吗答:都可以,适用场景更广。
- 问:SparkSQL 作用答:使用 SQL 语句快速查询处理结构化数据。
八、ClickHouse 数据库问答
- 问:ClickHouse 是什么答:高性能列式存储 OLAP 分析型数据库。
- 问:OLAP 是什么意思答:面向数据分析、海量数据聚合查询。
- 问:为什么最终数据存入 ClickHouse答:查询速度极快,毫秒级响应,专门适配数据可视化大屏。
- 问:ClickHouse 适合日常增删改业务吗答:不适合,不擅长事务操作,只适合统计分析。
- 问:它和普通 MySQL 区别答:MySQL 适合日常业务读写,ClickHouse 适合大数据快速统计展示。
九、DolphinScheduler 调度平台问答
- 问:DolphinScheduler 是什么答:分布式工作流任务调度平台。
- 问:项目中主要用途答:编排采集、清洗、计算、入库整套流程,实现自动定时执行。
- 问:DAG 工作流是什么答:按照先后依赖顺序自动执行一连串数据任务。
- 问:调度平台带来什么便利答:不用手动一步步执行任务,解放人力,定时自动跑批。
- 问:任务失败可以重新执行吗答:支持失败重试、断点续跑,运维更方便。
十、项目数据流通用基础题
- 问:项目两大类数据分别是什么答:用户行为日志数据、广告业务数据。
- 问:日志数据包含哪些内容答:用户点击、曝光、浏览时长、访问设备、访问时间等。
- 问:业务数据包含哪些内容答:广告 ID、投放渠道、投放金额、投放地区、转化订单等。
- 问:什么是脏数据答:空值、重复数据、异常数据、格式错误、无效垃圾数据。
- 问:数据清洗主要剔除哪些内容答:空字段、重复条目、乱码数据、超出正常范围异常数据。
- 问:整套项目完整流程简单叙述答:脚本生成模拟数据→分类采集→存入 HDFS→Hive 数仓分层清洗→Spark 计算指标→调度自动执行→数据迁入 ClickHouse→前端可视化展示。
- 问:本项目禁止使用哪款可视化工具答:禁止使用 FineBI。
- 问:我们前端常用什么技术做可视化答:Vue+ECharts、HTML+JS 原生开发。
- 问:项目过程中允许使用 AI 辅助吗答:允许辅助写脚本、代码、配置文件,但所有技术原理和流程我们都熟练掌握,能够独立讲解。
- 问:答辩现场程序出现 BUG 怎么处理答:优先现场调试解决,无法解决先离场调整,等待其余小组答辩完毕再次上场完成。
- 问:小组一般如何分工答:一人负责项目概述与技术讲解,一人负责数据采集处理调度,一人负责可视化开发展示。
- 问:做这个大数据广告项目核心目的答:统计分析广告投放效果,分析用户流量行为,为广告运营投放提供真实数据支撑。
- 问:海量数据为什么不能用普通单机处理答:单机存储不足、运算速度慢,集群分布式架构才能高效处理。
- 问:数据汇聚统一存放好处是什么答:数据统一标准,方便统一治理、统一计算、统一分析。
- 问:什么叫数据流转答:数据从产生、采集、存储、清洗、计算、入库到展示的全过程流动。
十一、最简单兜底送分题
- 问:你们项目用的是离线大数据还是实时答:整体以离线大数据处理为主。
- 问:大数据处理最先做的一步是什么答:数据采集汇聚。
- 问:数据分析前必须做什么答:数据清洗规整。
- 问:可视化展示的数据从哪里读取答:从 ClickHouse 分析数据库中读取。
- 问:工作流调度最大意义是什么答:实现大数据项目自动化运维。
注意:展示的内容不做固定的技术要求,汇报人一栏中需要写入该小组的成员名称。 会提问关于本项目中涉及到的技术问题 ,可以使用AI实现功能,但必须能讲出实现的过程。
(评分要点:项目概述+技术复杂度+界面美观程度)
第二 部分 : 数据生成==》采集==》分析==》迁移(30分)
通过脚本生成数据,将日志和业务数据分别采集到HDFS上。通过DolphinScheduler完成工作流的调度,最后通过spark将数据迁移到ClickHouse 为后续的可视化提供数据支撑 。注意:这部分内容需要在操作的时候,根据自己的理解进行讲解,讲解内容可以拓展,可创新。
(评分要点:操作讲解+系统操作熟练度)
1.启动集群
cd /opt/bin/
(1)启动hadoop
./hdp.sh start
(2) 启动zookeeper
./zk.sh start
3 启动kafka
./kfk.sh start
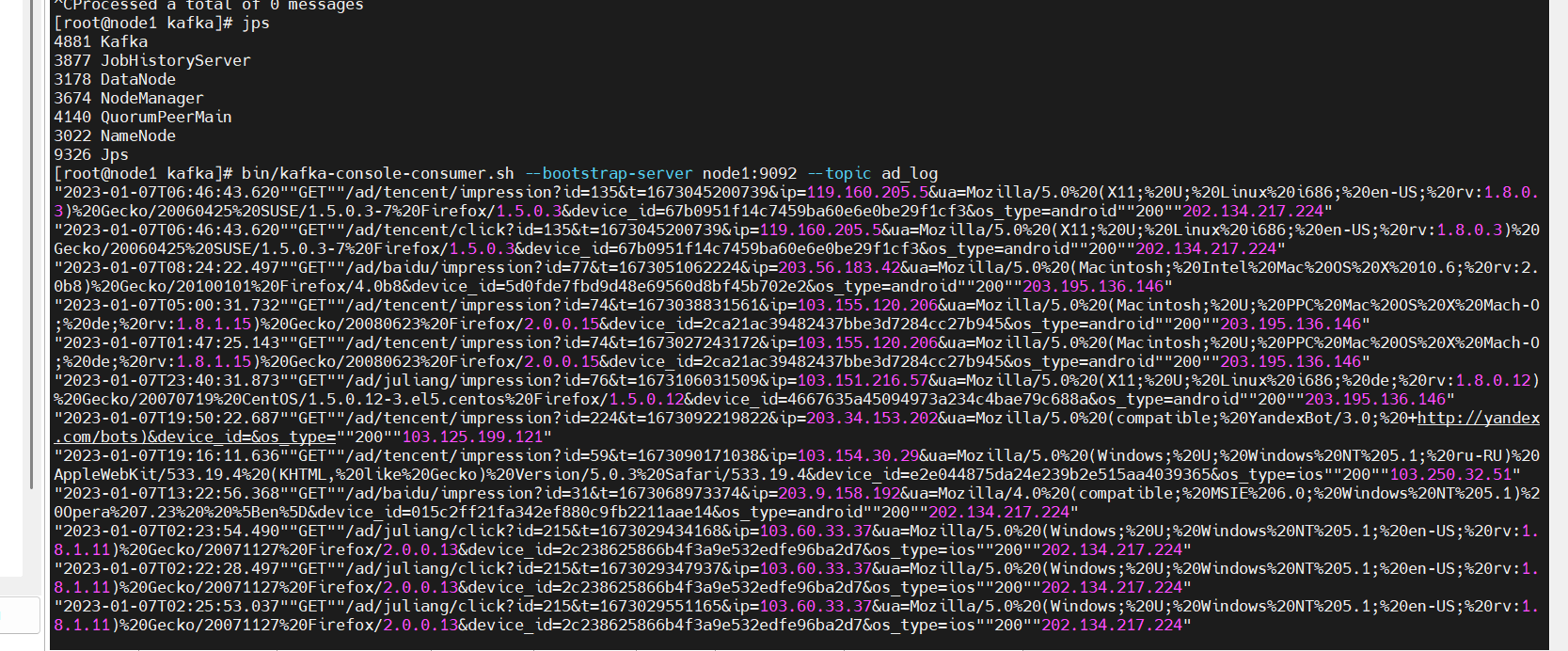
2.采集数据
node1:
bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic ad_log
node2:
bin/flume-ng agent --conf conf/ --conf-file job/ad_file_to_kafka.conf --name a1 -Dflume.root.logger=INFO,console
配置 a1 任务,监控/opt/module/ad_mock/log/所有日志,靠 json 记录读取位置,经 Kafka 通道发到集群 node1/2/3 的 ad_log 主题
#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/ad_mock/log/.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers =node1:9092,node2:9092,node3:9092
a1.channels.c1.kafka.topic = ad_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c1
node3:
bin/flume-ng agent -n a1 -c conf/ -f job/ad_kafka_to_hdfs.conf -Dflume.root.logger=info,console
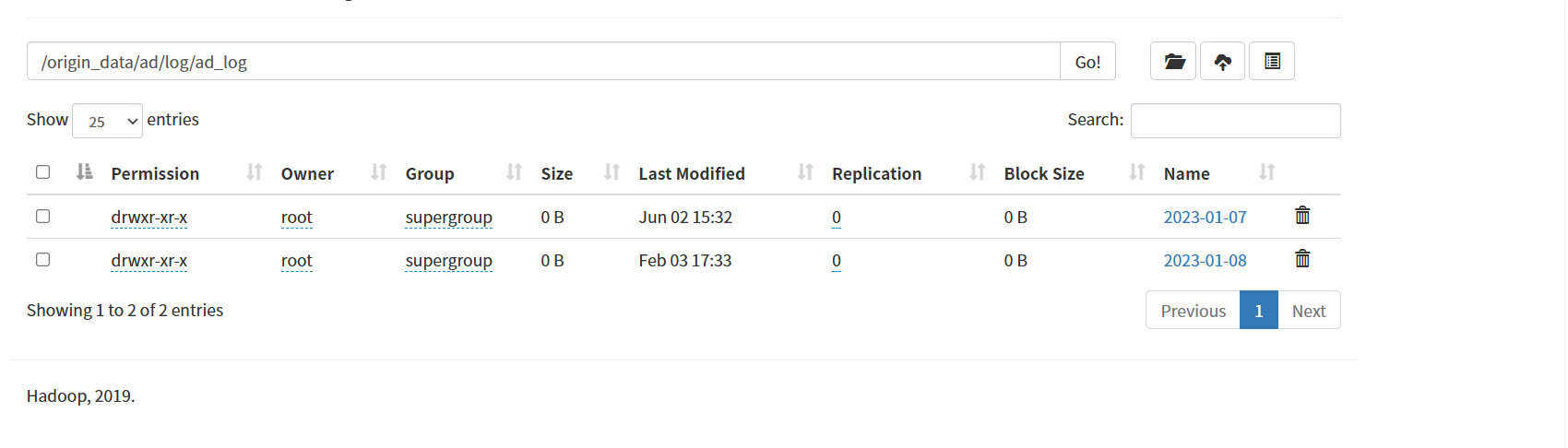
Flume 从 Kafka 的 ad_log 主题读取数据,写入 HDFS 路径:hdfs://node1:8020/origin_data/ad/log/ad_log/
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 1000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
a1.sources.r1.kafka.topics = ad_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.BigData.TimestampInterceptor$Builder
#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node1:8020/origin_data/ad/log/ad_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
如图便成功了
node1
./ad_ods_to_dim.sh all 2023-01-07
systemctl restart clickhouse-server.service
clickhouse-client -m
use ad_report;
drop table if exists dwd_ad_event_inc;
create table if not exists dwd_ad_event_inc
(
event_time Int64 comment '事件时间',
event_type String comment '事件类型',
ad_id String comment '广告id',
ad_name String comment '广告名称',
ad_product_id String comment '广告产品id',
ad_product_name String comment '广告产品名称',
ad_product_price Decimal(16, 2) comment '广告产品价格',
ad_material_id String comment '广告素材id',
ad_material_url String comment '广告素材url',
ad_group_id String comment '广告组id',
platform_id String comment '推广平台id',
platform_name_en String comment '推广平台名称(英文)',
platform_name_zh String comment '推广平台名称(中文)',
client_country String comment '客户端所处国家',
client_area String comment '客户端所处地区',
client_province String comment '客户端所处省份',
client_city String comment '客户端所处城市',
client_ip String comment '客户端ip地址',
client_device_id String comment '客户端设备id',
client_os_type String comment '客户端操作系统类型',
client_os_version String comment '客户端操作系统版本',
client_browser_type String comment '客户端浏览器类型',
client_browser_version String comment '客户端浏览器版本',
client_user_agent String comment '客户端UA',
is_invalid_traffic UInt8 comment '是否是异常流量'
) ENGINE = MergeTree()
ORDER BY (event_time, ad_name, event_type, client_province, client_city, client_os_type,
client_browser_type, is_invalid_traffic);
cd /opt/module/spark/
spark-submit --class com.BigData.ad.spark.HiveToClickhouse --master yarn BigData2403_hive_spark_clickhouse-1.0-SNAPSHOT-jar-with-dependencies\(1\).jar --hive_db ad --hive_table dwd_ad_event_inc --hive_partition 2023-01-07 --ck_url jdbc:clickhouse:node1//:8123/ad_report --ck_table dwd_ad_event_inc --batch_size 1000第三部分:数据可视化(30分)
注意 :该操作不限定技术要求(除fineBI),例如:HTML+CSS+JavaScripts、VUE+ECharts等技术,从数据库中读取数据,进行可视化展示。部分功能可以使用AI完成,但必须能讲出实现的过程。
(评分要点:技术讲解+技术复杂度+UI界面美观程度)
问题一: 当前项目中使用了哪些大数据组件,这些组件有什么特点。
负责第二部分和第三部分的学生需要回答项目相关问题:
1.Hadoop 为开源分布式大数据基础架构,核心由HDFS、MapReduce、YARN组成。HDFS 实现分布式海量文件存储,MapReduce 负责离线分布式计算,YARN 承担集群资源调度与任务管理。具备高可靠、易扩展、低成本特性,是大数据生态底层核心支撑框架。
2.Flume 是分布式日志采集框架,以 Agent 为运行单元,由 Source、Channel、Sink 三大组件构成。可采集多源流式数据,依靠事务机制保障数据精准投递,通过通道缓冲实现流量削峰。支持多级聚合部署,高可靠易拓展,常对接 Kafka、HDFS,作为大数据实时数据接入核心组件
3.Kafka 是分布式流式消息中间件,基于发布订阅模式。集群含 Broker、生产者、消费者,依托 Zookeeper 协调管理。数据按主题分区存储,多副本机制保障高可用,支持持久化与消息回溯。具备高吞吐、低延迟特性,实现系统解耦、流量削峰,广泛用于实时数据流转与日志汇聚。。
4.DataX 为阿里开源异构数据源同步工具,采用插件化架构,由 Reader、Channel、Writer 组成。支持主流关系型与大数据数据源,通过内存通道完成数据流转,内置流控、重试机制。可高效实现全量及增量数据迁移,是数仓建设中 ETL 数据集成的常用离线同步工具。
5.Zookeeper 是分布式协调服务,基于 ZAB 协议实现数据一致性。集群划分为 Leader、Follower、Observer 节点,Leader 统筹事务请求。依托树形 Znode 存储元数据,提供集群选举、配置同步、服务注册发现、分布式锁能力,保障大数据集群高可用与状态统一。
-
Hive 是构建于 Hadoop 之上的数据仓库组件,可将结构化数据映射为数据表,通过类 SQL 语句实现数据分析。底层默认调度 MR 引擎,也可适配 Spark执行任务。屏蔽底层分布式计算细节,适配海量离线数据处理,多用于数据仓库分层构建与批量统计分析。
-
Spark 是快速通用分布式计算框架,基于内存运算,速度远超 MapReduce。核心含 SparkCore、SparkSQL、Streaming 等组件,支持批处理与实时流处理,兼容多种数据源,生态完善,资源调度灵活,是大数据离线与实时计算主流引擎。
-
ClickHouse 是列式存储 OLAP 数据库,主打毫秒级实时分析。核心靠列式存储 + 向量化执行 + 高压缩提速,支持 SQL 与分布式架构。擅长 PB 级数据多维聚合、用户行为 / 日志分析、实时大屏,不适合事务与高频点查。
-
DolphinScheduler 分布式高可用工作流调度平台,采用 Master-Worker 架构,依托注册中心实现集群协调。以 DAG 模式编排任务,支持多类型大数据作业调度,具备失败重试、断点续跑、动态负载均衡及多渠道告警能力,适配数仓 ETL 流程编排与全链路定时任务运维。。
问题二:什么是数据仓库?本项中数据仓库分为哪几层,这些层的特点是什么?
数据仓库是面向主题、集成、非易失、随时间变化的结构化数据聚合环境,专为企业离线决策分析构建。
其通过 ETL 流程完成多源异构数据统一汇聚、清洗转换与标准化治理,依托 Hadoop 分布式存储架构承载海量离线数据,借助 Hive 等组件实现分层建模与批量计算。摒弃事务处理逻辑,侧重历史数据归档留存与多维聚合分析,统一数据统计口径,为商业智能、指标体系建设、数据挖掘及经营战略研判提供规范化数据支撑。
ODS层是原始数据层,全称操作数据存储层。原样同步业务库、日志等源头数据,保留最原始格式与明细,仅做简单脱敏。作为数仓入口,承接全量源头数据,为后续分层加工提供基础数据源。
DIM层数仓维度数据表层,存储维度属性信息,如时间、地区、用户、商品等静态及慢变属性。统一维度编码与标准口径,供事实表关联聚合分析,实现数据分组、筛选、多维拆解,是数据分析的基础参照表。
DWD层数仓清洗明细层,基于 ODS 层原始数据,完成脏数据过滤、字段清洗、格式标准化、去重脱敏。保留业务完整明细粒度,剔除无效数据,统一数据规范,作为中间干净明细层,向上支撑汇总层加工计算。