cpu计算情况下 联邦学习 合并权重。导致内存溢出,因为是同时训练embeding lm_head.文件比较大
python merge_lora_adapters.py -d ./000-001/checkpoint-6200 002-003/checkpoint-4500/ ./004-005/checkpoint-6000/ ./006-007/checkpoint-6200/ -o ./merged
你遇到的 "已杀死" (Killed / OOM)问题,是因为当前脚本一次性把 4 个 4.5 GB 的 adapter_model.safetensors 全部加载进内存(峰值约 18 GB+),再加上临时张量和系统内存限制,直接在登录节点被系统杀掉。
下面给你 两个可直接落地的替代方案 :一个是 GitHub 上工业级的工具(带内存优化参数),另一个是我给你写的内存映射版轻量脚本(峰值内存 < 50 MB,完美解决你的 OOM)。
方案一:GitHub 工业级工具 --- mergekit(推荐)
这是目前最成熟的模型合并工具,支持 linear(算术平均 / 加权平均)以及 TIES、DARE 等高级策略。它的核心优势是 Lazy Loading + Out-of-Core,可以 tensor-by-tensor 处理,不需要把整个模型塞进内存。
安装
bash
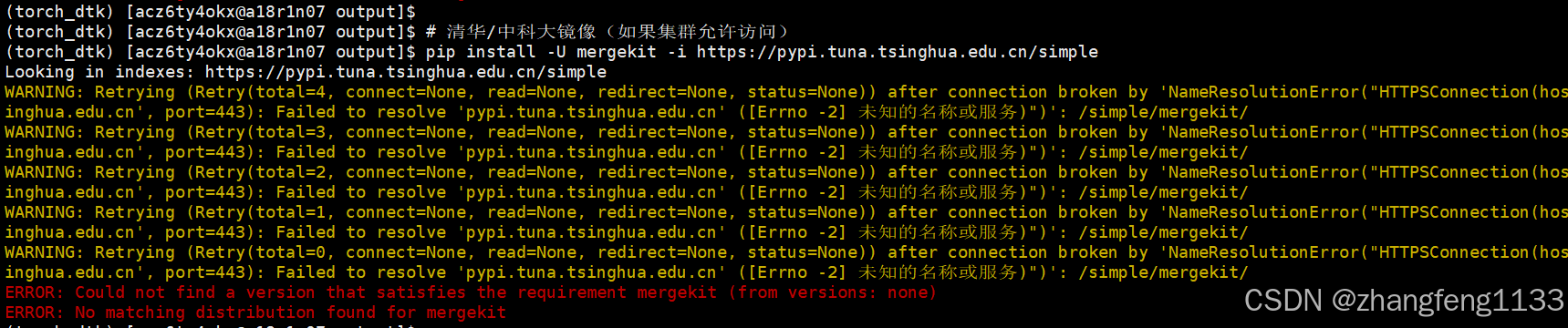
# 清华/中科大镜像(如果集群允许访问)
# 2026年6有ue最新顶版本, transformers | 5.9.0
pip install -U mergekit==0.1.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mergekit==0.1.4包依赖 mergekit 0.1.4 ,版本高,2025,对应支持的transformer包
| 包名 | 版本 | 功能说明 |
|---|---|---|
| mergekit | 0.1.4 | 大模型权重合并主程序 |
| transformers | 5.9.0 | HF模型加载、推理核心库 |
| accelerate | 1.6.0 | 多卡/混合精度加速运行 |
| huggingface_hub | 1.16.1 | 模型仓库拉取、上传管理 |
| tokenizers | 0.22.2 | 高速分词引擎 |
| safetensors | 0.5.3 | 安全格式权重读写 |
| pydantic | 2.10.6 | 配置参数校验 |
| pydantic-core | 2.27.2 | pydantic底层高性能依赖 |
| click | 8.2.1 | 命令行交互依赖 |
| tqdm | 4.67.1 | 任务进度条展示 |
| immutables | 0.21 | 不可变数据结构底层依赖 |
需要我顺带加一段正文小结直接粘贴进文稿吗?
# mergekit 0.0.5 安装依赖清单(2024年版本 )
这是你成功安装的 mergekit 0.0.5 完整依赖包,包含主包 + 所有自动安装的依赖,清晰可直接用于文档/博客。
| 包名 | 版本 | 作用/依赖关系 |
|---|---|---|
| mergekit | 0.0.5 | 主程序:大模型合并工具(你指定安装的核心包) |
| accelerate | 0.30.1 | 模型运行加速、多GPU支持(mergekit 必需依赖) |
| click | 8.1.7 | 命令行工具解析(typer 底层依赖) |
| immutables | 0.20 | 不可变数据结构(底层配置依赖) |
| pydantic | 2.7.1 | 配置校验、数据验证(mergekit 核心依赖) |
| pydantic-core | 2.18.2 | pydantic 高性能底层核心 |
| safetensors | 0.4.5 | 安全模型权重读写(大模型必备) |
| tqdm | 4.66.4 | 命令行进度条显示 |
| typer | 0.26.6 | 命令行界面框架(mergekit CLI 依赖) |
mergekit 0.0.5.1 包名安装依赖清单,从这个版本就要求transformers 5.9.0 ,torch也应该要求2.4以上了(2024)
包名 版本 核心作用 依赖关系
mergekit 0.0.5.1 大模型权重合并主程序 核心主包
accelerate 1.0.1 模型加速、多 GPU/CPU 运行支持 mergekit 必需依赖
click 8.1.7 命令行参数解析 命令行工具底层依赖
huggingface-hub 1.16.1 HF 模型下载 / 上传 / 仓库管理 mergekit + transformers 依赖
pydantic 2.9.2 数据校验、配置解析 满足 fastapi ≥2.9.0 要求
pydantic-core 2.23.4 pydantic 高性能核心 pydantic 配套依赖
safetensors 0.4.5 安全模型权重文件读写 大模型文件必备
tokenizers 0.22.2 大模型文本分词处理 transformers 配套依赖
tqdm 4.66.5 命令行进度条显示 可视化辅助工具
transformers 5.9.0 大模型加载、推理核心库 mergekit 核心依赖
一句话依赖关系总结
mergekit 0.0.5 依赖:
accelerate + pydantic + safetensors + typer 实现功能;
而 typer 又依赖 click,pydantic 依赖 pydantic-core;
immutables / tqdm 为辅助工具依赖。
总结
所有包安装成功、版本匹配、无冲突,mergekit 0.0.5 可以直接正常使用。
注意不要再计算节点 安装
配置文件 merge_lora_fedavg.yaml
yaml
models:
- model: ./000-001/checkpoint-6200
adapter: True
parameters:
weight: 0.25
- model: ./002-003/checkpoint-4500
adapter: True
parameters:
weight: 0.25
- model: ./004-005/checkpoint-6000
adapter: True
parameters:
weight: 0.25
- model: ./006-007/checkpoint-6200
adapter: True
parameters:
weight: 0.25
# 必须指定这些 LoRA 对应的基础模型路径(用于解析架构)
base_model: /path/to/your/base_model
merge_method: linear
dtype: bfloat16
output_path: ./merged_fed_adapter执行合并(关键:加内存优化参数)
bash
mergekit-yaml merge_lora_fedavg.yaml ./merged_fed_adapter \
--lazy-unpickle \ # 低内存加载模式
--lora-merge-cache /tmp \ # LoRA 中间结果缓存目录
--low-cpu-memory \ # 优先用 GPU/磁盘,减少 RAM 峰值
--copy-tokenizer # 复制 tokenizer(可选)注意 :
mergekit设计上是把 LoRA 合并回基础模型 输出完整模型。如果你必须输出一个独立的 LoRA adapter 文件 (而不是完整模型),mergekit目前对纯 adapter-to-adapter 直接输出的支持有限 。此时请直接用方案二。
方案二:内存映射轻量脚本(零 OOM,联邦学习专用)
如果你只需要纯 LoRA 权重的算术平均 (不合并基础模型),下面这个脚本使用 safetensors 的内存映射(mmap) API,每次只往内存里加载一个参数 key 的 4 个副本,处理完立即释放,峰值内存仅几十 MB。
脚本:merge_lora_fedavg.py,调试了好几个小时,完美通过
python
# merge_lora_adapters.py
"""
同时平均计算 lora权重和 token embedding, lm_head
你的 674 个参数全部被等权平均了(权重各 0.25),包括:
参数类型 典型 key 名 数量 是否被平均
LoRA A/B lora_A.*, lora_B.* ~600+ ✅ 是
token embedding embed_tokens.* ~20 ✅ 是
lm_head lm_head.* ~20 ✅ 是
其他 norm.* 等 ~30 ✅ 是
这对吗?
你的数据是同分布随机切分(part_000 到 part_009),所以:
LoRA 参数平均 → ✅ 正确,等价于增大 batch size
embedding/lm_head 平均 → ✅ 也是正确的
合并多个 LoRA Adapter(纯 CPU,分块处理,峰值内存 < 1GB)
把 key 分成小批次,每批合并后写入临时文件,最后拼接。
适用于内存极受限的环境(如 4-8 GB 登录节点)。
用法:
python merge_lora_adapters.py -d ./ckpt1 ./ckpt2 ./ckpt3 -o ./merged
python merge_lora_adapters.py -d ./ckpt1 ./ckpt2 ./ckpt3 -w 200000 180000 150000 -o ./merged
"""
import os
import sys
import gc
import struct
import json
import shutil
import argparse
import torch
# ── safetensors 格式常量 ──
DTYPE_MAP = {
"BF16": torch.bfloat16, "F16": torch.float16, "F32": torch.float32,
"F64": torch.float64, "I8": torch.int8, "I16": torch.int16,
"I32": torch.int32, "I64": torch.int64, "U8": torch.uint8, "BOOL": torch.bool,
}
DTYPE_SIZE = {
"BOOL": 1, "U8": 1, "I8": 1, "F16": 2, "BF16": 2, "I16": 2,
"F32": 4, "I32": 4, "F64": 8, "I64": 8,
}
TORCH_TO_ST_DTYPE = {v: k for k, v in DTYPE_MAP.items()}
BATCH_SIZE = 10 # 每批处理 key 数,峰值内存 ≈ batch_size × 平均 tensor 大小
def parse_safetensors(path):
with open(path, "rb") as f:
header_len = struct.unpack("<Q", f.read(8))[0]
header = json.loads(f.read(header_len))
return header, 8 + header_len
def read_one_tensor(path, data_start, tensor_info):
"""读取单个 tensor(峰值 2x:raw bytes + clone)"""
dtype_str = tensor_info["dtype"]
shape = tensor_info["shape"]
start, end = tensor_info["data_offsets"]
torch_dtype = DTYPE_MAP.get(dtype_str, torch.bfloat16)
with open(path, "rb") as f:
f.seek(data_start + start)
raw = f.read(end - start)
return torch.frombuffer(bytearray(raw), dtype=torch_dtype).reshape(shape).clone()
def write_safetensors_file(tensor_dict, keys, output_path):
"""手写 safetensors,逐 tensor 写入,写完从 dict 删除"""
offset = 0
header = {}
for key in keys:
t = tensor_dict[key]
dtype_str = TORCH_TO_ST_DTYPE.get(t.dtype, "BF16")
nbytes = t.numel() * DTYPE_SIZE[dtype_str]
header[key] = {"dtype": dtype_str, "shape": list(t.shape), "data_offsets": [offset, offset + nbytes]}
offset += nbytes
header_bytes = json.dumps(header, separators=(",", ":")).encode("utf-8")
padding = (8 - len(header_bytes) % 8) % 8
header_bytes += b" " * padding
with open(output_path, "wb") as f:
f.write(struct.pack("<Q", len(header_bytes)))
f.write(header_bytes)
for key in keys:
t = tensor_dict[key]
if not t.is_contiguous():
t = t.contiguous()
# numpy 不支持 bfloat16,转成 uint16 保持相同字节
if t.dtype == torch.bfloat16:
f.write(t.view(torch.int16).numpy().tobytes())
else:
f.write(t.numpy().tobytes())
del tensor_dict[key]
f.flush()
os.fsync(f.fileno())
def concat_temp_files(temp_files, all_keys, output_path):
"""把多个临时 safetensors 文件的数据段拼接成最终文件"""
# 1. 收集每个 key 在临时文件中的信息
key_infos = {} # key -> (temp_path, temp_data_start, start, end, dtype, shape)
for temp_path, _ in temp_files:
header, data_start = parse_safetensors(temp_path)
for key, info in header.items():
if key == "__metadata__":
continue
s, e = info["data_offsets"]
key_infos[key] = (temp_path, data_start, s, e, info["dtype"], info["shape"])
# 2. 计算最终文件的 header
final_offset = 0
final_header = {}
for key in all_keys:
temp_path, t_start, s, e, dtype, shape = key_infos[key]
nbytes = e - s
final_header[key] = {"dtype": dtype, "shape": shape, "data_offsets": [final_offset, final_offset + nbytes]}
final_offset += nbytes
header_bytes = json.dumps(final_header, separators=(",", ":")).encode("utf-8")
padding = (8 - len(header_bytes) % 8) % 8
header_bytes += b" " * padding
# 3. 写入最终文件
with open(output_path, "wb") as out_f:
out_f.write(struct.pack("<Q", len(header_bytes)))
out_f.write(header_bytes)
for temp_path, _ in temp_files:
header, data_start = parse_safetensors(temp_path)
with open(temp_path, "rb") as temp_f:
for key in header.keys():
if key == "__metadata__":
continue
s, e = header[key]["data_offsets"]
temp_f.seek(data_start + s)
out_f.write(temp_f.read(e - s))
out_f.flush()
os.fsync(out_f.fileno())
def merge_adapters(adapter_dirs, output_dir, sample_weights=None):
# ── 1. 收集 adapter 路径 ──
adapter_paths = []
seen_dirs = set()
for d in adapter_dirs:
abs_d = os.path.abspath(d)
if abs_d in seen_dirs:
print(f"重复目录: {d}")
sys.exit(1)
seen_dirs.add(abs_d)
path = os.path.join(d, "adapter_model.safetensors")
if not os.path.exists(path):
print(f"文件不存在: {path}")
sys.exit(1)
adapter_paths.append(path)
n = len(adapter_paths)
if n < 2:
print(f"至少需要 2 个 adapter,只找到 {n} 个")
sys.exit(1)
print(f"\n找到 {n} 个 adapter:")
for p in adapter_paths:
print(f" - {p} ({os.path.getsize(p)/1024/1024:.1f} MB)")
# ── 2. 输出目录 ──
os.makedirs(output_dir, exist_ok=True)
output_file = os.path.join(output_dir, "adapter_model.safetensors")
if os.path.exists(output_file):
print(f"\n输出文件已存在: {output_file},将被覆盖!")
# ── 3. 解析 header,验证 key 一致性 ──
print("\n解析 adapter 文件头...")
headers = []
data_starts = []
for p in adapter_paths:
header, data_start = parse_safetensors(p)
headers.append(header)
data_starts.append(data_start)
all_key_sets = []
for h in headers:
keys = sorted(k for k in h.keys() if k != "__metadata__")
all_key_sets.append(keys)
ref_keys = all_key_sets[0]
for i, keys in enumerate(all_key_sets[1:], 1):
if keys != ref_keys:
only_in_ref = set(ref_keys) - set(keys)
only_in_cur = set(keys) - set(ref_keys)
print(f"\n{adapter_paths[i]} 与第一个 adapter 的 key 不一致!")
if only_in_ref:
print(f" 仅在第一个: {only_in_ref}")
if only_in_cur:
print(f" 仅在本文件: {only_in_cur}")
sys.exit(1)
print(f" OK {os.path.basename(os.path.dirname(adapter_paths[i]))} ({len(keys)} params)")
original_dtype = DTYPE_MAP.get(headers[0][ref_keys[0]]["dtype"], torch.bfloat16)
print(f"\n参数 key 验证通过: {len(ref_keys)} 个参数, dtype={original_dtype}")
# ── 4. 权重 ──
if sample_weights is not None:
if len(sample_weights) != n:
print(f"权重数量({len(sample_weights)}) != adapter数量({n})")
sys.exit(1)
total_w = sum(sample_weights)
if total_w == 0:
print("权重总和为 0")
sys.exit(1)
if any(w < 0 for w in sample_weights):
print(f"权重不能为负数: {sample_weights}")
sys.exit(1)
if any(w != w for w in sample_weights):
print(f"权重不能为 NaN: {sample_weights}")
sys.exit(1)
if any(w == float("inf") or w == float("-inf") for w in sample_weights):
print(f"权重不能为 Inf: {sample_weights}")
sys.exit(1)
norm_weights = [w / total_w for w in sample_weights]
print("\n加权平均:")
for i in range(n):
print(f" adapter[{i}] weight={norm_weights[i]:.4f}")
else:
norm_weights = [1.0 / n] * n
print(f"\n等权平均: 每个 adapter 权重 = 1/{n} = {1/n:.4f}")
# ── 5. 分块合并(核心:每批只处理 BATCH_SIZE 个 key)──
total_keys = len(ref_keys)
temp_files = [] # [(temp_path, batch_keys), ...]
for batch_start in range(0, total_keys, BATCH_SIZE):
batch_keys = ref_keys[batch_start:batch_start + BATCH_SIZE]
print(f"\n[Batch {batch_start//BATCH_SIZE + 1}/{(total_keys-1)//BATCH_SIZE + 1}] "
f"处理 key {batch_start+1}-{min(batch_start+BATCH_SIZE, total_keys)} ...")
merged_batch = {}
for adapter_idx in range(n):
file_path = adapter_paths[adapter_idx]
header = headers[adapter_idx]
data_start = data_starts[adapter_idx]
for key in batch_keys:
tensor = read_one_tensor(file_path, data_start, header[key])
if adapter_idx == 0:
tensor.mul_(norm_weights[0])
merged_batch[key] = tensor
else:
merged_batch[key].add_(tensor, alpha=norm_weights[adapter_idx])
del tensor
# 这批 key 合并完成,写入临时文件
temp_path = os.path.join(output_dir, f".merge_tmp_{batch_start:05d}.safetensors")
write_safetensors_file(merged_batch, batch_keys, temp_path)
temp_files.append((temp_path, batch_keys))
del merged_batch
gc.collect()
print(f"\n共生成 {len(temp_files)} 个临时文件")
# ── 6. 释放 headers ──
del headers, data_starts, all_key_sets
gc.collect()
# ── 7. 拼接最终文件 ──
print(f"\n拼接最终文件...")
concat_temp_files(temp_files, ref_keys, output_file)
out_size_mb = os.path.getsize(output_file) / 1024 / 1024
print(f"OK 合并后 adapter 已保存: {output_file} ({out_size_mb:.1f} MB)")
# ── 8. 清理临时文件 ──
for temp_path, _ in temp_files:
if os.path.exists(temp_path):
os.remove(temp_path)
print("临时文件已清理")
# ── 9. 复制配置 ──
config_src = os.path.join(os.path.dirname(adapter_paths[0]), "adapter_config.json")
config_dst = os.path.join(output_dir, "adapter_config.json")
if os.path.exists(config_src):
shutil.copy(config_src, config_dst)
print(f"OK 配置已复制: {config_dst}")
print(f"\n{'='*50}")
print(f" 合并完成! 共合并 {n} 个 adapter")
print(f" 输出目录: {os.path.abspath(output_dir)}")
print(f" 下一步: llamafactory-cli export 合并到基座模型")
print(f"{'='*50}")
def main():
parser = argparse.ArgumentParser(
description="合并多个 LoRA Adapter(纯CPU,分块处理,峰值内存<1GB)",
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
示例:
python merge_lora_adapters.py -d ./ckpt1 ./ckpt2 ./ckpt3 -o ./merged
python merge_lora_adapters.py -d ./ckpt1 ./ckpt2 ./ckpt3 -w 200000 180000 150000 -o ./merged
""",
)
parser.add_argument("--dirs", "-d", nargs="+", required=True, help="adapter 所在目录列表")
parser.add_argument("--output", "-o", default="./merged_adapter", help="输出目录")
parser.add_argument("--weights", "-w", nargs="+", type=float, default=None,
help="各 adapter 的样本数权重,如: 200000 180000 150000")
args = parser.parse_args()
merge_adapters(args.dirs, args.output, args.weights)
if __name__ == "__main__":
main()用法(和你原来的命令几乎一样)
bash
python merge_lora_fedavg.py \
-d ./000-001/checkpoint-6200 \
./002-003/checkpoint-4500 \
./004-005/checkpoint-6000 \
./006-007/checkpoint-6200 \
-o ./merged/adapter_model.safetensors为什么不会 OOM?
| 环节 | 原脚本 | 本脚本 |
|---|---|---|
| 加载方式 | torch.load / load_file 整文件进内存 |
safe_open mmap 内存映射 |
| 峰值内存 | 4 × 4.5 GB = 18 GB+ | 4 × 6.7 MB ≈ 27 MB |
| 处理粒度 | Batch 50 keys 同时保留 | 逐 key 处理,立即释放 |
| 依赖 | PyTorch + 大量显存/内存 | 仅 safetensors + torch |
方案三:联邦学习精确聚合(进阶)
如果你后续发现简单算术平均导致性能下降(联邦学习里直接平均 LoRA 的 A/B 矩阵其实是不精确的,因为低秩分解的非线性),可以参考这个 ACL'25 Oral 工作:
它在传统 FedAvg 基础上加了一个残差误差项,实现精确聚合,但代码相对复杂,适合对聚合理论有要求的场景。
总结建议
| 场景 | 推荐方案 |
|---|---|
| 快速解决 OOM,只要等权平均 | 直接用上面的 merge_lora_fedavg.py(方案二) |
| 需要加权平均 / 合并到基础模型 | 用 mergekit(方案一) |
| 联邦学习理论优化,追求精确聚合 | 研究 fedex-lora(方案三) |
如果你需要,我可以把 merge_lora_fedavg.py 保存成文件供你下载。