
一句话总结:
本研究利用随机森林等五种机器学习算法,基于公开数据集成功预测天然纤维增强聚合物复合材料的拉伸强度,最优模型R2达到0.92,显著降低实验成本,加速新材料设计。
一、研究背景:为什么需要机器学习来预测材料性能?
天然纤维增强聚合物(NFRP)复合材料因其轻质、环保、低成本等优点,越来越多地应用于汽车、航空、建筑等领域。
然而,拉伸强度作为衡量材料结构完整性的关键指标,传统上依赖于大量实验测试,耗时、昂贵、资源密集。
问题在于:新配方的拉伸强度往往缺乏实验数据,而现有机器学习模型存在特征使用不全、数据不公开、可解释性差等问题。
因此,研究者希望建立一个可复现、高精度、可解释的机器学习框架,用数据驱动的方式预测复合材料拉伸强度。
二、实验方法:数据 + 模型 + 评估
数据来源与预处理
-
数据来自Kaggle公开数据集,共1168条样本。
-
包含8个输入特征:密度、环氧基含量、弹性模量、固化剂用量、树脂消耗量、面密度、基体-填料比,以及目标变量拉伸强度。
预处理流程包括:
-
删除不完整和重复数据
-
Z-score法剔除异常值(阈值 ±3)
-
相关性分析,剔除弱相关特征(|r| < 0.1)
-
标准化数值特征
-
最终保留1124条数据,80%训练 / 20%测试
使用的机器学习模型
-
多项式回归
-
Bagging回归
-
随机森林(Random Forest)
-
XGBoost
-
梯度提升(Gradient Boosting)
评估方法
-
五折交叉验证
-
评估指标:R2、MAE、MSE、RMSE
三、图文解析:原文重要图表分析
图1:机器学习数据流程图(原文 Page 3)
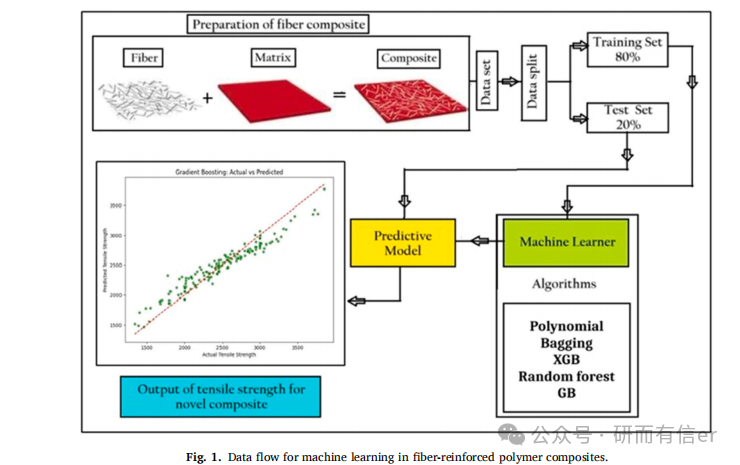
原图位置:Fig. 1, Page 3
这张图展示了从数据准备到模型预测的完整流程:
数据采集 → 预处理(清洗、去异常、特征选择) → 训练集(80%)/测试集(20%) → 多种ML模型训练 → 拉伸强度预测 → 性能评估
解读:该流程清晰再现了本研究的可复现框架,是材料信息学中典型的"数据-模型-预测"闭环。
图3:各模型预测值与实际值散点图(原文 Page 4-5)
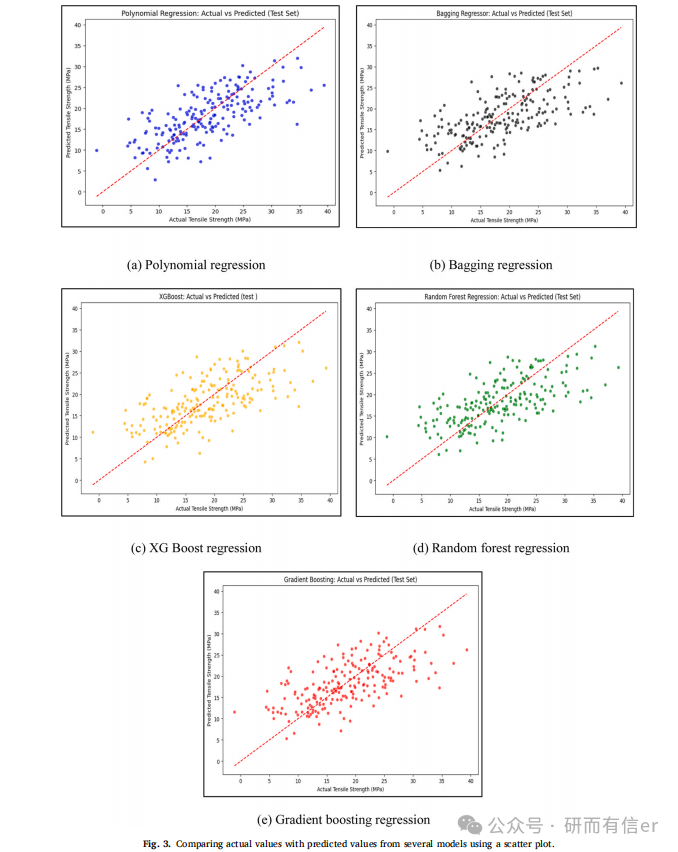
原图位置:Fig. 3(a--e), Page 4-5
原文对比了五种模型的预测效果:
-
图3(a) 多项式回归:预测值紧密围绕理想线,尤其在10--30 MPa区间,R2≈0.85--0.90。
-
图3(b) Bagging:整体趋势正确,但两端误差较大,R2≈0.75-0.80。
-
图3(c) XGBoost:表现良好,中段预测准确,但极端值有偏差,R2≈0.78-0.83。
-
图3(d) 随机森林:正相关明显,但偏离理想线的点较多,R2≈0.75-0.80。
-
图3(e) 梯度提升:整体趋势良好,中段预测稳定,R2≈0.82-0.86。
结论:多项式回归精度最高,但后续特征选择后,随机森林表现更优。
图5:特征选择后各模型预测效果(原文 Page 7-8)
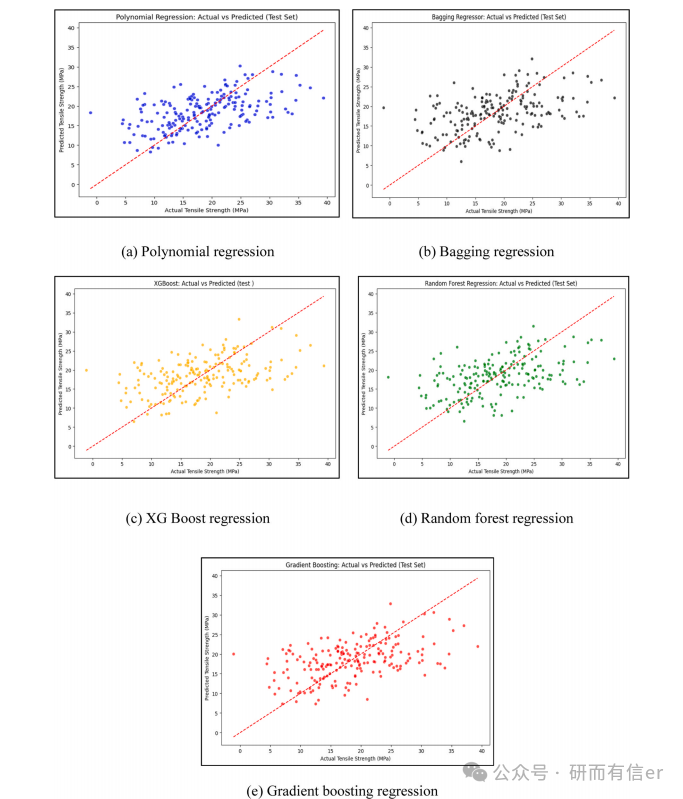
原图位置:Fig. 5(a--e), Page 7-8
在剔除了弱相关特征(密度、面密度、树脂消耗量)后,模型表现显著提升:
-
图5(c) XGBoost:预测点紧密围绕理想线,极端值误差小,R2≈0.88-0.92
-
图5(d) 随机森林:整体趋势正确,但两端预测分散,R2≈0.78-0.82
-
图5(e) 梯度提升:表现稳定,与XGBoost接近,R2≈0.87-0.91
结论:特征选择后,XGBoost和梯度提升成为最优模型,随机森林在极端值上略逊。
图6:特征选择后的相关性矩阵(原文 Page 9)
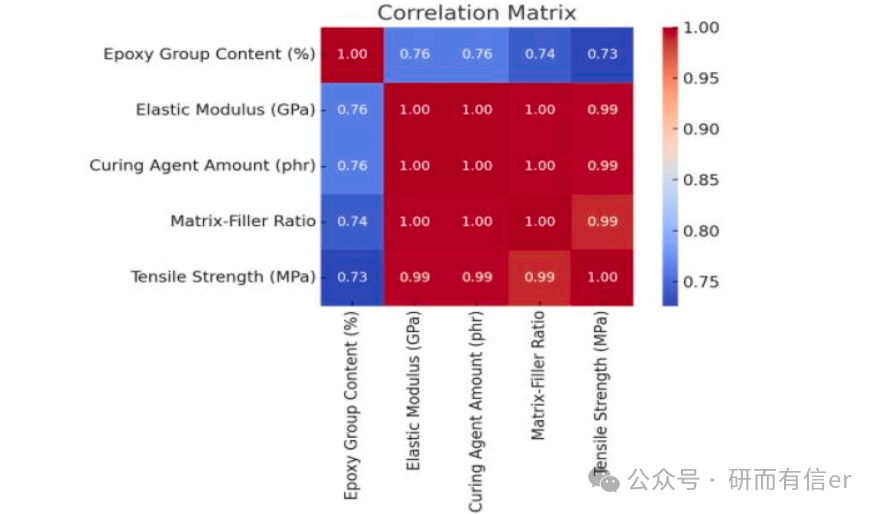
原图位置:Fig. 6, Page 9
相关性矩阵显示:
-
弹性模量(0.99)、固化剂用量(0.99)、基体-填料比(0.99)与拉伸强度高度正相关。
-
环氧基含量(0.73)也呈较强正相关。
解读:这些特征是决定拉伸强度的核心因素,验证了模型选择的合理性。
四、核心结果对比表
| 模型 | R2R2 | MAE | RMSE |
|---|---|---|---|
| 随机森林(原始特征) | 0.92 | 1.64 | 5.57 |
| 随机森林(特征选择后) | 0.92 | 4.47 | 2.04 |
| XGBoost(特征选择后) | 0.873 | 3.83 | 4.78 |
| 梯度提升(特征选择后) | 0.888 | 3.73 | 4.67 |
| Bagging(特征选择后) | 0.83 | 2.33 | 2.93 |
| 多项式回归(特征选择后) | 0.32 | 4.75 | 5.95 |
随机森林在 R2R2和 RMSE 上均表现最佳,是最适合该任务的模型。
五、研究局限与未来方向
局限:
-
数据集规模有限(1124条),可能影响泛化能力。
-
未考虑环境因素(湿度、温度)。
-
缺乏微观结构特征(如纤维-基体界面)。
未来方向:
-
引入深度学习(CNN、RNN)处理更复杂特征。
-
集成实时制造数据,构建自适应预测系统。
-
拓展到多性能预测(弯曲、冲击、硬度)。
-
加入可持续性指标(碳足迹、可降解性)。
六、总结
本研究成功构建了一个基于随机森林的NFRP复合材料拉伸强度预测模型,R2 最高达到0.92,显著优于传统回归方法。
通过特征选择、五折交叉验证和公开数据集,该框架具备高可解释性和可复现性,为材料科学中的机器学习应用提供了坚实范本。
注:更多关于机器学习预测复合材料拉伸强度的前沿知识小编之前有推荐,可以详查置顶文章:机器学习pinn辅助力学多尺度建模/岩土固结大模型生成/水泥基复合材料应用技术前沿
如果您觉得文章不错,欢迎点赞、关注、收藏及转发~