Linux-EXT系列文件系统
1、路径解析
在上一章节的内容中我们可以看到,想要打开目录中的目录,必须先加载目录中目录的内容,也就是先加载目录文件的数据,那张映射表存放着inode与文件名之间的关系。
例如我现在要访问:/home/benjiang/Bite/lesson26/test 这个路径下的test目录下的code.c这个文件,那么我势必需要从根目录 "/"开始进行解析,一层一层加载目录的inode和文件名之间的关系,才能最终找到code.c这个文件,这个过程叫做路径解析。
1、从根目录进行路径解析
具体解析过程:系统会先拿到根目录/的inode,读取根目录的数据块,从映射表中找到home对应的inode编号,接着拿着home路径的inode编号,去读取home目录的数据块,从映射表中找到对应benjiang的inode编号...如此层层递进,类似于递归,最终找到code.c的inode。
2、相对路径进行路径解析
但是现在我没有一层一层递进进入目录中,而是输入了相对路径,怎么办呢?
bash
(base) benjiang@BENJIANGLIU:~/Bite/lesson25$ pwd
/home/benjiang/Bite/lesson25
(base) benjiang@BENJIANGLIU:~/Bite/lesson25$ cd ../lesson26
# 此处使用相对路径从lesson25进入了lesson26目录
(base) benjiang@BENJIANGLIU:~/Bite/lesson26$ pwd
/home/benjiang/Bite/lesson26如果路径不以 / 开头(例如 ./test/code.c),系统则会从当前进程的当前工作目录(Current Working Directory, CWD)的 inode 开始解析,假如在shell中输入进行目录路径解析,从shell的内容可以看到。
bash
base) benjiang@BENJIANGLIU:~$ ps -axj | head -1 && ps -axj | grep shell
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
29141 29228 29228 29228 pts/11 29813 Ss 1000 0:00 /bin/bash --init-file /home/benjiang/.vscode-server/bin/8761a5560cfd65fdd19ce7e2bd18dab5c0a4d84e/out/vs/workbench/contrib/terminal/common/scripts/shellIntegration-bash.sh
29228 29814 29813 29228 pts/11 29813 S+ 1000 0:00 grep --color=auto shell
# 发现shell的进程编号是 29228
(base) benjiang@BENJIANGLIU:~$ ls /proc/29228 -l
total 0
lrwxrwxrwx 1 benjiang benjiang 0 Jun 2 22:12 cwd -> /home/benjiang # 这既是shell的工作路径
-r-------- 1 benjiang benjiang 0 Jun 2 22:12 environ
lrwxrwxrwx 1 benjiang benjiang 0 Jun 2 22:15 exe -> /usr/bin/bash
dr-x------ 2 benjiang benjiang 4 Jun 2 22:12 fd
(base) benjiang@BENJIANGLIU:~$ pwd # 查看当前工作路径确实是 /home/benjiang
/home/benjiang所以我们得到结论,相对路径的路径解析是通过当前进程的cwd提供的路径。
3、小总结
从这里可以看出几个问题:
1、为什么需要 / 根目录?
很显然,如果没有根目录,在OS进行路径解析的时候,就不知道从哪里开始了。
就算是相对路径解析时进程提供的cwd,也是从根目录开始的。
2、linux中为什么都会有家目录home ?在这个目录下可以新建目录?
其实本质就是在磁盘文件系统中,新建目录文件 。而你新建的所有文件,都是在你或者系统指定的目录下新建的,这就是天然的路径。而linux文件系统本质上就是一颗多叉树!这个多叉树的根节点就是 根目录 !
4、路径缓存
因为在linux系统中不存在所谓的"目录",目录的本质是一个文件,只保存文件原属性(indoe)和文件内容(数据块)。
这个文件的数据块内容是一张映射表,里面存放着目录内文件名和inode的映射关系。
而我们在访问目录中的文件时,原则上都是从根目录进行解析的,但是这样太慢,因为每次都需要进行磁盘IO,查看数据存放的位置,如果我们把之前打开过的文件或者目录的路径都缓存起来,下次读取的时候,直接读取缓存中的内容,是不是会变快了?
当然!而且linux也是这么做的,会缓存历史路径结构,它在内存中维护了一个被称为 Dcache(Directory Entry Cache,目录项缓存) 的树形结构,这个缓存由一个叫做dentry的结构体进行维护。
dentry结构体代码:
c
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};每一个被访问过的文件或目录组件(如 /home/user/file.txt 中的 home、user、file.txt),都会在内存中生成一个 struct dentry 对象。
层级关系:每个 dentry 都包含指向其父节点的指针(d_parent)和子节点列表(d_subdirs)。通过这些指针,内核在内存中完美地映射了文件系统的层级结构。
2、挂载分区
抛出一个问题,我现在的linux硬盘上一块有128GB,现在硬盘空间不足了,我需要在linux电脑上再连接一个256GB的硬盘,我直接用IDE、PICE、M2的方式连接到电脑,电脑就能够识别到这块硬盘码?直接就可以读取硬盘上的数据吗?
答案:硬盘连接方式(如M.2、PCIe或SATA)只要正常通电,开机后Linux内核是完全可以识别到这块256GB新硬盘的。但仅仅识别到硬件并不等于能直接读取数据 。这是因为Linux系统与Windows不同,它没有自动分配盘符(如D盘、E盘)的机制。这就引出了Linux存储管理中一个极其重要的核心概念------挂载(Mount)。
**在Linux的单一文件系统树结构中,所有的存储设备都必须通过"挂载"操作,才能与系统目录树中的某个具体目录(即"挂载点",如 /mnt/data)建立关联。**打个比方,新硬盘就像是一个装满文件的U盘,而"挂载点"就像是电脑上的USB接口;只有把U盘插进接口(执行挂载命令),你才能顺着这个接口访问里面的内容。
因此,即使这块硬盘里原本就存有数据,且使用的是Linux支持的文件系统(如EXT4、XFS,甚至是Windows常用的NTFS等),你也必须先手动创建一个空目录作为入口,然后通过 mount 命令将硬盘分区挂载到这个目录下,才能真正读取其中的文件。如果希望每次开机都能自动读取,还需要将挂载信息写入 /etc/fstab 配置文件中。简而言之:硬件识别只是第一步,挂载才是赋予数据访问权限的关键钥匙。
1、一个挂载试验
我们在家目录里面从硬盘中创建一个大的磁盘块,当做一个分区,并挂载。
bash
(base) benjiang@BENJIANGLIU:~$ dd if=/dev/zero of=./disk.img bs=1M count=5 # 分割5M大小的磁盘文件
5+0 records in
5+0 records out
5242880 bytes (5.2 MB, 5.0 MiB) copied, 0.00330404 s, 1.6 GB/s
(base) benjiang@BENJIANGLIU:~$ ll
total 164596
drwxr-x--- 19 benjiang benjiang 4096 Jun 3 21:52 ./
drwxr-xr-x 3 root root 4096 Sep 16 2025 ../
-rw-r--r-- 1 benjiang benjiang 5242880 Jun 3 21:52 disk.img # 查看当前分割出来的文件
drwxr-xr-x 18 benjiang benjiang 4096 May 18 10:22 miniconda3/
-rw-r--r-- 1 benjiang benjiang 5 Apr 15 20:37 test.txt
(base) benjiang@BENJIANGLIU:~$ pwd # 当前路径
/home/benjiang
(base) benjiang@BENJIANGLIU:~$ mkfs.ext4 disk.img # 写入ext4文件系统
mke2fs 1.47.0 (5-Feb-2023)
Filesystem too small for a journal
Discarding device blocks: done
Creating filesystem with 1280 4k blocks and 1280 inodes
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
(base) benjiang@BENJIANGLIU:~$ df -h # 查看当前磁盘内容,只有一个ssd,其中挂载了根目录
Filesystem Size Used Avail Use% Mounted on
/dev/sdd 1007G 8.4G 948G 1% /
tmpfs 1.6G 20K 1.6G 1% /run/user/1000
(base) benjiang@BENJIANGLIU:~$ sudo mkdir /mnt/mydisk # 创建挂载路径
[sudo] password for benjiang:
# 将新创建的分区挂载在/mnt/mydisk 目录下
(base) benjiang@BENJIANGLIU:~$ sudo mount -t ext4 ./disk.img /mnt/mydisk/
(base) benjiang@BENJIANGLIU:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdd 1007G 8.4G 948G 1% /
tmpfs 1.6G 20K 1.6G 1% /run/user/1000
# 此处发现已经多了个4.7M的磁盘
/dev/loop0 4.7M 24K 4.4M 1% /mnt/mydisk2、挂载的过程
看过程:
1、首先先创建一个大文件,当做分区使用,此处类似于插入一块刚买来的新的磁盘。
2、然后格式化写入文件系统,此处非常重要!因为格式化的过程本质就是写入文件系统 ,之前已经说了文件系统的写入本质其实是磁盘管理信息的写入 。如果没有写入正确的、linux可识别的文件系统,linux是无法读写硬盘数据的!
3、创建一个或者使用已经存在的文件夹,当做新磁盘挂载的锚点,并挂载磁盘,例如我写了/mnt/mydisk,那么以后访问这个5M大小的空间就是通过/mnt/mydisk这个路径去访问的!
3、挂载结论
分区写入文件系统后,是无法直接使用的,需要与指定的目录进行关联,这个关联的过程就是挂载
所以我就可以通过访问目标文件的前缀来判断我在哪一个分区里面!
3、软硬链接
1、硬连接
在linux系统中,我们找到磁盘中文件的并不是文件名,而是inode,其实在linux中可以让多个文件指向一个inode。
例子:
bash
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ touch abc
# 创建一个文件
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ ln abc def
# 给这个文件创建一个硬链接
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ ls -li
total 0
18337 -rw-r--r-- 2 benjiang benjiang 0 Jun 3 22:14 abc
18337 -rw-r--r-- 2 benjiang benjiang 0 Jun 3 22:14 def
# 我们发现这两个文件的inode值是一样的!
# 而且硬链接数为2在上面的代码中我们可以看到:
ln是创建硬链接的命令
c
ln -s [源文件或目录] [链接名]硬链接可以理解为同一个文件的"多个平等入口"。它通过指向同一个 inode 节点来实现链接。
创建命令:ln 源文件 链接名(默认不加 -s 即为硬链接)
核心特点:
同步变化:硬链接与源文件完全等同,修改任意一个,另一个都会同步改变。
防误删机制:删除源文件或硬链接中的任意一个,文件实体并不会被真正删除,只有当所有的硬链接都被删除(链接数归零)时,文件才会被物理删除。
不跨文件系统:硬链接只能在同一个文件系统(分区)内创建。
不支持目录:不允许对目录创建硬链接(防止文件系统出现死循环)。
共享 Inode:硬链接与源文件共享同一个 inode 编号。
bash
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ pwd
/home/benjiang/Bite/lesson30
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ echo "测试硬链接" >> abc
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ cat def
测试硬链接
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ rm -rf abc
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ cat def
测试硬链接从上面这段代码中可以看到,我们想源文件内写入的数据,在硬连接的文件中也可以读取!而且我们删除了源文件后,发现硬连接的文件仍然可以读取的源文件中的内容,为什么?看图
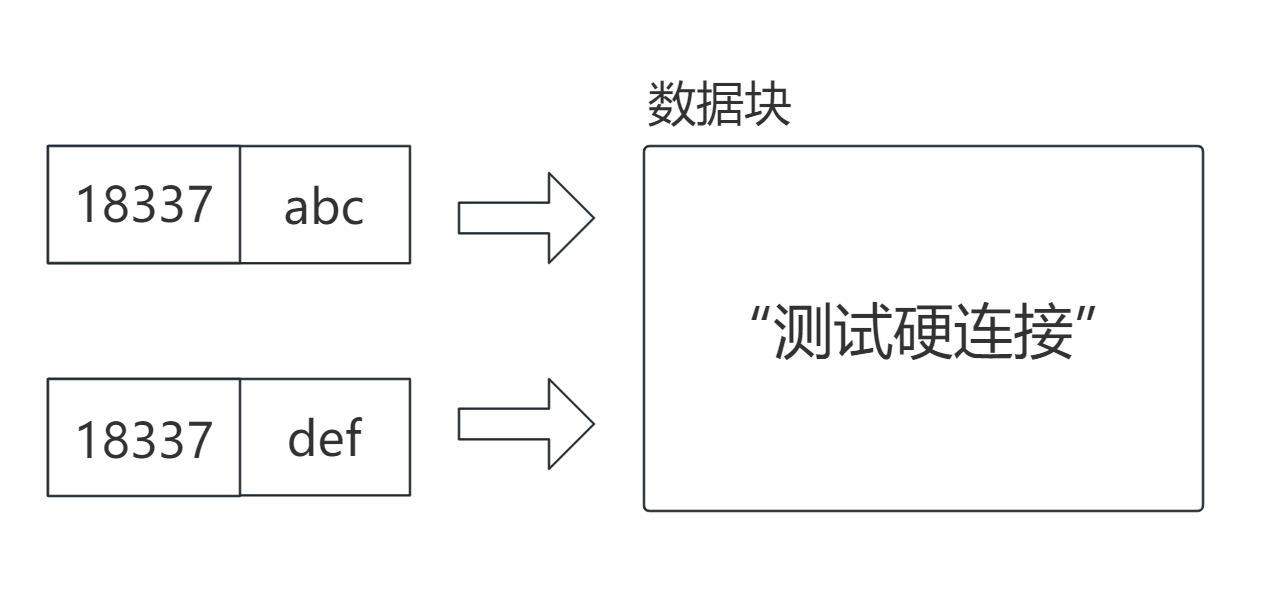
在文件系统中,/home/benjiang/Bite/lesson30 这个目录文件的映射表中,无论是abc还是def,这两个文件名的inode值其实是指向的同一块data block中区域。所以就算你删除了所谓的"源文件",硬连接的文件一样可以指向数据源!
引用计数(Link Count):注意看 ls -li 输出中权限位后面的那个数字 2。这个数字叫做"链接数"。当创建 def 时,这个计数从 1 变成了 2。只有当这个计数归零时,操作系统才会真正释放数据块的占用。
在删除文件的时候,我们干了2件事:第一将目录中的对应关系删除,第二将硬链接数-1,如果硬连接数为0,则将对应的磁盘空间释放。
硬连接的意义:一个轻量化的备份,不用cp源文件就可以做到删除源文件而备份不丢失。
为什么新建目录的硬连接数2???
bash
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ mkdir new
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ ll
total 16
drwxr-xr-x 3 benjiang benjiang 4096 Jun 3 22:40 ./ # 指向本级目录lesson30
drwxr-xr-x 24 benjiang benjiang 4096 Jun 3 22:14 ../ # 指向上级目录Bite
-rw-r--r-- 1 benjiang benjiang 16 Jun 3 22:20 def
drwxr-xr-x 2 benjiang benjiang 4096 Jun 3 22:40 new/ # 新建目录的连接数是2因为 ... 的存在,当我们cd进new这个目录的时候,ls发现目录中存在 . 和 ... 这两个文件。
这2个文件的本质就是,本级目录和上级目录的硬连接!
2、软连接
硬连接是通过inode引用另外一个文件,软链接是是通过名字引用另外一个文件,单实际上,新的文件和被引用的文件的inode不同!应用常见上可以理解为一个快捷方式。
bash
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ ls -li
total 12
18337 -rw-r--r-- 2 benjiang benjiang 16 Jun 3 22:20 abc
18337 -rw-r--r-- 2 benjiang benjiang 16 Jun 3 22:20 def
1763 drwxr-xr-x 2 benjiang benjiang 4096 Jun 3 22:40 new
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ ln -s abc abc.s
# 建立一个软连接
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ ls -li
total 12
18337 -rw-r--r-- 2 benjiang benjiang 16 Jun 3 22:20 abc
1860 lrwxrwxrwx 1 benjiang benjiang 3 Jun 3 22:47 abc.s -> abc
# 软连接 abc.s 指向了 abc
18337 -rw-r--r-- 2 benjiang benjiang 16 Jun 3 22:20 def
1763 drwxr-xr-x 2 benjiang benjiang 4096 Jun 3 22:40 new
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ cat abc.s
测试硬链接
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ readlink abc.s # 读取软链接的内部存储的数据
abc我们readlink 发现abs.s这个软连接内部存储的是abc,这个它连接的文件名。
继续
bash
(base) benjiang@BENJIANGLIU:~/Bite/lesson30$ cd new/
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ ll
total 8
drwxr-xr-x 2 benjiang benjiang 4096 Jun 3 23:16 ./
drwxr-xr-x 3 benjiang benjiang 4096 Jun 3 23:16 ../
lrwxrwxrwx 1 benjiang benjiang 3 Jun 3 22:47 abc.s -> abc
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ cat abc.s
cat: abc.s: No such file or directory
# 发现因为使用的相对路径,abc.s在移动到new目录后无法继续使用了
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ ln -s ../abc newabc.s
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ ll
total 8
drwxr-xr-x 2 benjiang benjiang 4096 Jun 3 23:22 ./
drwxr-xr-x 3 benjiang benjiang 4096 Jun 3 23:16 ../
lrwxrwxrwx 1 benjiang benjiang 3 Jun 3 22:47 abc.s -> abc
lrwxrwxrwx 1 benjiang benjiang 6 Jun 3 23:22 newabc.s -> ../abc
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ readlink newabc.s
../abc # 确定默认使用的是相对路径上面2个例子能够看出软连接是一个独立的文件,他有自己的inode和data block,而他的data block中存储的是它指向文件的相对路径!
那么我们如何避免在移动软连接文件后导致的相对路径失效问题呢?使用绝对路径
bash
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ pwd
/home/benjiang/Bite/lesson30/new
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ ln -s /home/benjiang/Bite/lesson30/abc ./abs.s
# 使用绝对路径创建软连接
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ ll
total 8
drwxr-xr-x 2 benjiang benjiang 4096 Jun 3 23:26 ./
drwxr-xr-x 3 benjiang benjiang 4096 Jun 3 23:16 ../
lrwxrwxrwx 1 benjiang benjiang 3 Jun 3 22:47 abc.s -> abc # 已经因为移动文件导致相对路径失效的软连接
lrwxrwxrwx 1 benjiang benjiang 32 Jun 3 23:26 abs.s -> /home/benjiang/Bite/lesson30/abc # 使用绝对路径的软连接
lrwxrwxrwx 1 benjiang benjiang 6 Jun 3 23:22 newabc.s -> ../abc
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ mkdir new # 创建新目录
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ mv abs.s ./new # 将软连接移动到new目录
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new$ cd new
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new/new$ ll
total 8
drwxr-xr-x 2 benjiang benjiang 4096 Jun 3 23:27 ./
drwxr-xr-x 3 benjiang benjiang 4096 Jun 3 23:27 ../
lrwxrwxrwx 1 benjiang benjiang 32 Jun 3 23:26 abs.s -> /home/benjiang/Bite/lesson30/abc
(base) benjiang@BENJIANGLIU:~/Bite/lesson30/new/new$ cat abs.s
测试硬链接
# 发现就算移动了软链接的,但是因为使用了绝对路径,软连接依然有效3、软硬连接对比
| 特性 | 软连接(Symbolic Link) | 硬链接(Hard Link) |
|---|---|---|
| 底层本质 | 是一个独立的特殊文件,拥有自己独立的 inode,其内容仅存储目标文件的路径字符串(类似于 Windows 快捷方式)。 | 是原始文件的"别名",与原始文件共享同一个 inode 和数据块,在系统看来它们就是同一个文件。 |
| 跨文件系统 | 支持。可以跨越不同的磁盘分区或文件系统创建链接。 | 不支持。只能在同一个文件系统(同一分区)内创建。 |
| 链接对象 | 支持目录。可以对普通文件或目录创建软连接。 | 不支持目录。只能对普通文件创建硬链接(Linux 为防止目录树循环引用,默认禁止对目录创建硬链接)。 |
| 删除原文件后 | 链接失效。如果目标文件被删除或移动,软连接会变成"断链"(悬空链接),无法访问。 | 不受影响。只要还有一个硬链接存在,文件数据就不会被真正删除,依然可以正常访问。 |
| 权限与属性 | 软连接自身权限通常显示为 lrwxrwxrwx,但实际访问权限由它指向的目标文件决定。 |
与原始文件完全共享权限、所有者、大小和修改时间,修改任何一个,另一个都会同步变化。 |
| 创建命令 | ln -s <目标路径> <链接名> |
ln <目标文件> <链接名> |