本文主要介绍使用深度学习进行电缆的异常检测,在少样本、免训练的情况下,实现对电缆等目标的异常检测并进行标记。
本文所使用的方法是PatchCore算法(支持wide resnet50和resnet50系列主干特征提取网络)。该算法是于2021年左右在CVPR提出的,至今仍是工业图像异常检测任务中最常用的基准方法之一。
该方法仅需"记住"正常样本的特征,就能检测和定位异常方法,适合于异常样本少、形态多样等问题。
但该方法也有缺陷。即物体背景干扰影响比较大,如果背景出现较大变动,那么检测结果会很受影响。
想来看一下检测效果图:
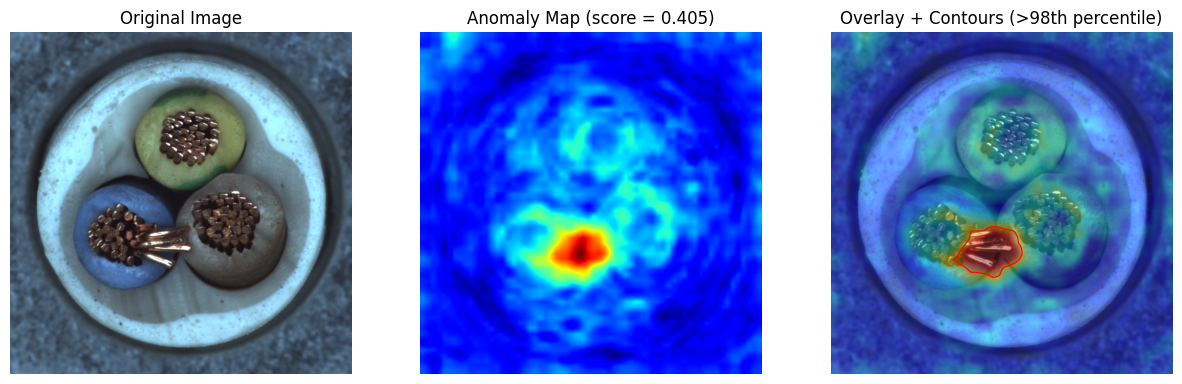
1. 核心思想
PatchCore 的核心洞察有两点:
-
使用预训练的深度神经网络(如 WideResNet) 作为特征提取器。这种网络在 ImageNet 上训练过,能提取到非常通用的图像特征。
-
采用"记忆库 + 最近邻搜索" :将训练集中所有正常图像切割成许多小"块"(patch),提取每个 patch 的特征,构成一个巨大的特征库**(memory bank)** 。测试时,对测试图像的每个 patch 特征,去特征库里找距离最近的正常特征,如果距离太远,则判定为异常。
本质上,它把异常检测转化成了:测试样本的局部特征是否存在于正常样本的特征分布流形中。
2. 主要步骤
步骤 1:特征提取(训练阶段)
这里说的训练并不是真正的训练,并不会经过反向传播。
-
输入:一批无缺陷的正常图像。
-
使用预训练的 CNN(如 WideResNet-50,本文也支持resnet50),取中间多层的特征图(例如第 2、3 层的输出)。
-
对每张图像的特征图,按空间位置提取 局部邻域聚合特征(通常用 3×3 的 patch 聚合),得到多个 patch 级特征向量。
-
将所有正常图像的所有 patch 特征向量收集起来,构成初始记忆库。
步骤 2:核心集下采样(Core-set subsampling)
-
原始记忆库可能非常大(例如 100 张 512×512 图像 → 几十万个 patch 特征),存储和检索效率低。
-
PatchCore 使用 贪婪下采样算法(近似最大覆盖问题)从原始记忆库中挑选出一个小而具有代表性的子集(例如原大小的 1%)。
-
这一步保证了内存可控,同时几乎不损失检测性能。
步骤 3:异常检测(测试阶段)
-
对测试图像同样提取 patch 级特征。
-
对每个 patch 特征,在记忆库(核心集)中寻找它的最近邻欧氏距离。
-
取所有 patch 中最小的那个距离(或者最大?注意:常用的是"最大最近邻距离"作为图像级异常分数------实际做法是:每个 patch 获得一个最近邻距离,异常分数取这些距离的最大值,代表最异常的那个局部区域),得到图像级异常分数。
-
同时,将每个 patch 的距离上采样到原图大小,即可生成像素级的异常定位热图。
3. 主要优点
-
无需训练:没有反向传播、没有 epoch、不需要调参(除了特征提取器和下采样比例)。只要运行一次前向提取特征。
-
高召回率:由于保留了所有正常 patch 的分布,并且用最近邻匹配,很少漏掉异常("Total Recall"目标)。
-
性能极强:在 MVTec AD 等主流工业异常检测数据集上,PatchCore 长期保持顶尖水平(AUC 常超过 98%)。
-
可解释性好:可以明确指出测试图像的哪块区域最不像正常样本。
-
适应性强:对物体纹理、结构、刚性物体、非刚性物体都有效。
4. 缺点与局限
-
内存占用仍较大:虽然用了 core-set 下采样,但上百张高分辨率图像仍可能产生几十万 × 高维特征 → 数 GB 内存。对边缘设备不友好。
-
推理速度较慢:每个测试 patch 都需要在记忆库中做一次最近邻搜索(虽然可以用 FAISS 等加速),对于高分辨率图像(如 4K)或实时性要求高的场景有压力。
-
对视角、光照变化敏感:因为是依靠精确的像素级特征匹配,若正常样本中包含大幅度几何变化或光照变化,会导致误报。通常需要对训练集做一定的数据增强。
-
只能检测与训练分布不同的情况 :无法识别正常但罕见的新模式(但这是所有基于分布的方法的通病)。
核心代码解读
模型搭建
支持WideResnet50、ResNet50作为特征提取的主干网络,采用ImageNet数据集上所训练的预权重。
代码核心部分为self.feature_exractor。这里上将网络的除去最后两层作为主干网络进行特征提取。
self.outputs用于存储layer(这里设置的layer 2和layer 3)的特征,用于后面patch特征的拼接。
bash
def _load_backbone(self, name, pre_trained):
if name == 'wide_resnet50_2':
model = models.wide_resnet50_2(weights='DEFAULT' if pre_trained else None)
elif name == 'resnet50':
model = models.resnet50(weights='DEFAULT' if pre_trained else None)
else:
raise ValueError(f"Unsupported backbone: {name}")
if self.weights:
ckpt = torch.load(self.weights, map_location='cpu')
model.load_state_dict(ckpt, strict=False)
self.feature_extractor = torch.nn.Sequential(*list(model.children())[:-2]).to(self.device) # 主干特征提取网络
self.outputs = {}
for layer_name in self.layers: # 可将layers中的输出保存在outputs中
layer = dict(model.named_children())[layer_name] # 获得layer_name层
# register_forward_hook接受module、input、output
layer.register_forward_hook(lambda m, i, o, name=layer_name: self.outputs.update({name: o}))
return model特征提取
进行特征提取并获取self.outputs(存储的是layer2 和layer 3的输出特征)。
将这两个输出特征特征进行resize为target_h和target_w的大小,再将特征进行拼接得到cat_feat。
最终patch_feat就是前面所说的"块特征"。
bash
def _extract_features(self, img_tensor):
self.outputs.clear() # 清空
_ = self.feature_extractor(img_tensor.to(self.device)) # 特征提取
features = [] # 用于存储输出特征
for layer in self.layers:
f = self.outputs[layer] # 获取输出特征
features.append(f)
target_h, target_w = 64, 64
resized = []
for f in features:
f_resized = F.interpolate(f, size=(target_h, target_w), mode='bilinear', align_corners=False)
resized.append(f_resized)
cat_feat = torch.cat(resized, dim=1) # 特征拼接
B, C, H, W = cat_feat.shape
patch_feat = cat_feat.permute(0, 2, 3, 1).reshape(B, H*W, C)
return patch_feat训练
这里的训练并不是真正的训练,而是获取"记忆特征库"的过程,不需要反向传播,获取正常样本的特征分布即可。且为了减少内存,可将获取的特征先缓存在电脑中。
该过程是将训练集(正常样本)按batch size进行划分。然后提取正常样本的patch feat,再经过平铺,将这些特征保存为pkl缓存文件。
而得到的"memory bank"特征记忆库,上在上面所有特征上,随机选择max_patches_total个特征。
python
def fit(self, normal_images_dir, batch_size=8, img_size=256, max_patches_total=20000, cache_name=None, transform=None):
"""
normal_images_dir:正常数据集样本路径
cache_name: 缓存文件名(基于图像目录路径生成唯一标识),不提供则自动生成
"""
self.img_size = img_size
if cache_name is None:
# 根据目录名和参数生成唯一缓存 key
cache_key = f"{normal_images_dir.replace('/', '_')}_{img_size}_{self.coreset_ratio}_{max_patches_total}.pkl"
else:
cache_key = cache_name
cache_path = os.path.join(self.cache_dir, cache_key)
# 尝试从缓存加载 flat_patches
if os.path.exists(cache_path):
print(f"从缓存加载特征: {cache_path}")
with open(cache_path, 'rb') as f:
flat_patches = pickle.load(f)
# 确保是 torch tensor
if not isinstance(flat_patches, torch.Tensor):
flat_patches = torch.from_numpy(flat_patches).float()
else: # 缓存不存在时
print("提取图像特征...")
image_paths = [os.path.join(normal_images_dir, f) for f in os.listdir(normal_images_dir)
if f.lower().endswith(('.png','.jpg','.jpeg'))]
all_patches = []
self.backbone.eval()
with torch.no_grad():
for i in tqdm(range(0, len(image_paths), batch_size), desc="Extracting features"):
batch_paths = image_paths[i:i+batch_size] # 获得前batch size张图路径
batch_imgs = []
for p in batch_paths:
img = Image.open(p).convert('RGB')
img_t = transform(img).unsqueeze(0)
batch_imgs.append(img_t) # batch 图像
batch_tensor = torch.cat(batch_imgs, dim=0).to(self.device) # 拼接为batch维度
patch_feat = self._extract_features(batch_tensor) # (B, N, D) 提取特征
all_patches.append(patch_feat.cpu()) # 存储特征
all_patches = torch.cat(all_patches, dim=0) # (total_imgs, N, D) 特征拼接,batch维度上
flat_patches = all_patches.reshape(-1, all_patches.shape[-1]) # (total_patches, D) # 平铺
# 保存缓存(保存的是所有图像的特征,最终保存的缓存文件内存比较大)
with open(cache_path, 'wb') as f:
# 存储为缓存(正常样本的特征向量)
pickle.dump(flat_patches.numpy() if torch.is_tensor(flat_patches) else flat_patches, f)
print(f"特征已缓存到 {cache_path}")
# 限制 patch 数量
if max_patches_total is not None and len(flat_patches) > max_patches_total:
print(f"随机下采样 patch 数量: {len(flat_patches)} -> {max_patches_total}")
idx = np.random.choice(len(flat_patches), max_patches_total, replace=False) # 随机选择max_patches_total个特征
flat_patches = flat_patches[idx]
# 核心集采样
flat_patches = flat_patches / (flat_patches.norm(dim=1, keepdim=True) + 1e-8)
self.memory_bank = self._coreset_sampling(flat_patches, ratio=self.coreset_ratio) # 采样后的特征
self.feature_dim = self.memory_bank.shape[-1] # 获取特征维度大小采样
这里可推荐随机采样,速度更快,但精度会比贪婪采样低一些。
python
def _coreset_sampling(self, features, ratio):
# 此处的features是已经经过随机下采样后的
n_samples = max(1, int(len(features) * ratio))
if self.sampling_method == 'random':
indices = np.random.choice(len(features), n_samples, replace=False) # 随机选择n个特征样本索引
return features[indices].clone() # 随机选择n个特征样本
elif self.sampling_method == 'greedy':
# 如果数据很大,贪婪采样极慢,这里做简单限制
if len(features) > 30000:
print("警告:贪婪采样数据量过大,自动切换为随机采样")
indices = np.random.choice(len(features), n_samples, replace=False)
return features[indices].clone()
return self._greedy_sampling(features, n_samples)
elif self.sampling_method == 'kmeans':
from sklearn.cluster import MiniBatchKMeans
features_np = features.numpy()
kmeans = MiniBatchKMeans(n_clusters=n_samples, batch_size=1000, random_state=42)
kmeans.fit(features_np)
return torch.from_numpy(kmeans.cluster_centers_).float()
else:
raise ValueError(f"Unknown sampling method: {self.sampling_method}")