前言:2026 年,普通人学 AI 的最好时代
2026 年,人工智能已从 "高精尖实验室" 走向全民化、低门槛化 。大模型开源、轻量化工具普及、Python 生态成熟,让零基础、无高数基础、无昂贵显卡 的普通人,也能在 1-2 个月内,从零学会 Python 并搭建可落地的 AI 完整项目(如本地大模型聊天机器人、智能数据分析师、图像识别工具、个人知识库 RAG 系统)。
本教程基于2026 年 4 月最新技术栈 (Python 3.11/3.12、PyTorch 2.2、Ollama 本地大模型、Streamlit 可视化、LangChain RAG 框架),全程无废话、全实操、代码可直接复制运行 ,从环境搭建→Python 基础→AI 核心库→机器学习实战→深度学习入门→本地大模型部署→RAG 项目开发→Web 端部署,一步到位打通 AI 全链路,总字数超 3 万字,适合零基础小白、转行 AI 从业者、大学生、职场技能提升者直接照做。
教程核心优势(2026 专属)
- 零基础友好 :跳过高数推导、算法底层,先会用、再补原理,高中数学足够;
- 低成本 :全程免费工具 + 普通 CPU 电脑即可,无需显卡、无需付费 API、无需云服务器;
- 最新技术 :聚焦 2026 顶流方向 ------本地大模型(Ollama)、RAG 检索增强生成、AI 智能体(Agent),拒绝老旧案例;
- 完整项目落地 :从 0 到 1 搭建4 个工业级 AI 项目,可直接作为毕设 / 作品集 / 职场工具;
- 全链路覆盖 :环境→语法→数据处理→模型训练→大模型调用→Web 部署,一站式学完 AI 开发全流程。
学习路径总览(4 周,每天 2-3 小时)
- 第 1 周:Python 零基础极速入门(AI 刚需语法,够用即可)
- 第 2 周:AI 核心三大库(NumPy+Pandas+Matplotlib,数据处理与可视化)
- 第 3 周:机器学习实战 + 深度学习入门(Scikit-learn 经典算法 + PyTorch 神经网络)
- 第 4 周:2026 顶流 AI 项目开发(本地大模型 + RAG 知识库 + Streamlit Web 部署)
第一部分:环境搭建(10 分钟,Windows/Mac 通用,2026 最新兼容版本)
1.1 Python 安装(3.11/3.12 版本,最稳定,兼容所有 AI 库)
Windows 系统
- 访问 Python 官网:https://www.python.org/downloads/windows/
- 下载Windows Installer (64-bit)(3.11.9 或 3.12.4 版本,避免最新测试版)
- 安装时必须勾选 Add Python to PATH(关键!否则后续无法调用),选择 "Install Now" 默认安装即可;
- 验证安装:按下
Win+R→输入cmd→回车,输入命令:
bash
运行
python --version显示Python 3.11.9即成功。
Mac 系统
- 访问 Python 官网:https://www.python.org/downloads/macos/
- 下载对应系统版本的安装包(3.11/3.12);
- 安装时勾选 "Add Python to PATH",完成后打开终端,输入:
bash
运行
python3 --version显示对应版本即成功(Mac 默认 python3,Windows 默认 python)。
1.2 开发工具选择(2 选 1,免费,新手友好)
工具 1:VS Code(推荐,全功能编辑器,适合长期开发)
- 官网下载:https://code.visualstudio.com/
- 安装后打开,左侧扩展栏搜索安装:
- Python(微软官方,语法提示 + 运行)
- Code Runner(一键运行代码,无需输命令)
- Chinese (Simplified)(中文界面,可选)
工具 2:Jupyter Notebook(交互式,适合新手边写边试)
安装命令(cmd / 终端输入):
bash
运行
pip install notebook启动:输入jupyter notebook,浏览器自动打开,新建.ipynb文件即可编写代码。
1.3 AI 核心库一键安装(2026 最新兼容版本,避免版本冲突)
打开 cmd / 终端,复制以下命令直接运行,一次性安装所有 AI 必备库:
bash
运行
# 升级pip到最新版
pip install --upgrade pip
# 安装数据处理+可视化库
pip install numpy==1.26.4 pandas==2.2.1 matplotlib==3.8.4 seaborn==0.13.2
# 安装机器学习库
pip install scikit-learn==1.4.2
# 安装深度学习框架(PyTorch,2026业界主流,CPU版本)
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1
# 安装大模型+RAG必备库
pip install ollama==0.1.7 transformers==4.38.2 langchain==0.1.13 sentence-transformers==2.5.1 chromadb==0.4.24
# 安装Web部署工具(Streamlit,30行代码做AI网页)
pip install streamlit==1.32.2说明:所有版本均为 2026 年 4 月最新稳定版,直接复制运行即可,无需手动调整版本。
1.4 虚拟环境(可选,推荐,避免库版本冲突)
新手可跳过,后期项目多了再用:
bash
运行
# 创建虚拟环境(命名为ai-env)
python -m venv ai-env
# 激活虚拟环境(Windows)
ai-env\Scripts\activate
# 激活虚拟环境(Mac/Linux)
source ai-env/bin/activate
# 激活后再执行上面的库安装命令,所有库仅在当前环境生效第二部分:Python 零基础极速入门(第 1 周,AI 刚需语法,够用即可)
2.1 为什么学 Python?(AI 第一语言,2026 无可替代)
- 语法极简:接近自然语言,比英语还简单,零基础 3 天能写代码;
- AI 生态碾压:90%+AI 项目用 Python,所有大模型、AI 库均优先支持 Python;
- 跨平台:Windows/Mac/Linux 通用,代码无需修改即可运行;
- 就业刚需:2026 年 AI 岗位招聘,Python 为必备技能,薪资普遍 15K+。
2.2 第一个 Python 程序(Hello AI!)
打开 VS Code,新建文件test.py,输入代码:
python
运行
# 打印输出:Hello AI!
print("Hello AI!我是零基础小白,2026年开始学Python+AI!")
# 运行:右键→Run Code,或终端输入python test.py
# 输出结果:Hello AI!我是零基础小白,2026年开始学Python+AI!核心知识点 :print()是 Python 内置函数,用于控制台输出内容,引号内为字符串,直接原样输出。
2.3 变量与数据类型(AI 数据处理基础)
变量:存储数据的 "容器",无需声明类型(Python 自动识别)。
2.3.1 常用数据类型
python
运行
# 1. 整数(int):整数数字
a=10
print(a, type(a)) # 输出:10 <class 'int'>
# 2. 浮点数(float):小数
b=3.14
print(b, type(b)) # 输出:3.14 <class 'float'>
# 3. 字符串(str):文本,单引号/双引号包裹
name = "AI小白"
print(name, type(name)) # 输出:AI小白 <class 'str'>
# 4. 布尔值(bool):真/假,True/False
is_ai_easy=True
print(is_ai_easy, type(is_ai_easy)) # 输出:True <class 'bool'>2.3.2 变量命名规则(必须遵守,否则报错)
- 只能由字母、数字、下划线组成;
- 不能以数字开头;
- 区分大小写(
name和Name是两个不同变量); - 不能用 Python 关键字(如
if、for、print)。
2.4 输入输出(实现人机交互,AI 对话基础)
2.4.1 输入函数input():获取用户输入
python
运行
# 获取用户输入的名字
name=input("请输入你的名字:")
# 拼接输出
print(f"你好,{name}!欢迎来到Python+AI的世界!")运行结果:
plaintext
请输入你的名字:张三
你好,张三!欢迎来到Python+AI的世界!f-string 格式化 :f"内容{变量}",快速拼接字符串与变量,2026 最常用。
2.5 条件语句(if-else,AI 逻辑判断基础)
语法:
python
运行
if 条件:
条件成立执行的代码
else:
条件不成立执行的代码示例(判断成绩是否及格):
python
运行
# 获取用户输入的成绩(input返回字符串,需转int)
score=int(input("请输入你的成绩:"))
# 条件判断
if score >= 60:
print("恭喜,成绩及格!")
else:
print("很遗憾,成绩不及格,继续加油!")运行结果:
plaintext
请输入你的成绩:85
恭喜,成绩及格!多条件判断(if-elif-else)
python
运行
score=int(input("请输入你的成绩:"))
if score >= 90:
print("优秀")
elif score >= 80:
print("良好")
elif score >= 60:
print("及格")
else:
print("不及格")2.6 循环语句(for/while,AI 批量处理数据核心)
2.6.1 for 循环(遍历序列,批量处理数据)
语法:
python
运行
for 变量 in 序列:
循环执行的代码示例 1:遍历数字 1-10
python
运行
# range(1,11):生成1到10的数字(左闭右开,不包含11)
for i in range(1, 11):
print(f"当前数字:{i}")示例 2:遍历列表(AI 数据存储常用)
python
运行
# 列表:存储多个数据,用[]包裹
fruits = ["苹果", "香蕉", "橙子", "葡萄"]
for fruit in fruits:
print(f"水果:{fruit}")2.6.2 while 循环(条件满足时重复执行)
语法:
python
运行
while 条件:
循环执行的代码示例:循环打印 1-5
python
运行
i=1
while i <= 5:
print(f"当前数字:{i}")
i += 1 # 每次循环i加1,避免死循环2.7 列表与字典(AI 数据存储核心,必学)
2.7.1 列表(list):有序、可修改的序列,存储多个数据
python
运行
# 1. 创建列表
data = [10, 20, 30, "AI", True]
# 2. 访问元素(索引从0开始)
print(data[0]) # 输出:10(第一个元素)
print(data[-1]) # 输出:True(最后一个元素)
# 3. 修改元素
data[1] = 200
print(data) # 输出:[10, 200, 30, 'AI', True]
# 4. 常用方法
data.append(40) # 末尾添加元素
data.remove("AI") # 删除指定元素
print(len(data)) # 输出列表长度2.7.2 字典(dict):键值对存储,无序、可修改,AI 数据标注常用
python
运行
# 1. 创建字典(键:值,键唯一)
student = {"name": "张三", "age": 20, "score": 85, "is_ai_student": True}
# 2. 访问值(通过键)
print(student["name"]) # 输出:张三
print(student.get("age")) # 输出:20(推荐,键不存在不报错)
# 3. 修改/添加键值对
student["score"] = 90 # 修改
student["gender"] = "男" # 添加
print(student)
# 4. 常用方法
print(student.keys()) # 所有键
print(student.values()) # 所有值
print(student.items()) # 所有键值对2.8 函数(def,AI 代码复用核心,避免重复写代码)
语法:
python
运行
def 函数名(参数):
函数体(执行代码)
return 返回值(可选)示例 1:无参数函数(打印 AI 问候语)
python
运行
# 定义函数
def ai_greeting():
print("你好!我是AI助手,很高兴为你服务!")
# 调用函数
ai_greeting() # 输出:你好!我是AI助手,很高兴为你服务!示例 2:带参数函数(计算两数之和)
python
运行
# 定义函数(a和b为参数)
def add(a, b):
result=a+b
return result # 返回结果
# 调用函数(传入参数10和20)
sum_result=add(10, 20)
print(f"10+20={sum_result}") # 输出:10+20=30示例 3:AI 实用函数(判断是否为正数)
python
运行
def is_positive(num):
if num > 0:
return True
else:
return False
print(is_positive(5)) # True
print(is_positive(-3)) # False2.9 模块导入(import,调用 AI 库核心)
Python 核心优势:无需手写复杂功能,直接导入现成模块 / 库。语法:
python
运行
# 导入整个模块
import 模块名
# 导入模块并别名(简化调用,常用)
import 模块名 as 别名
# 从模块导入指定功能
from 模块名 import 功能名示例(导入数学模块,计算平方根):
python
运行
# 导入数学模块
import math
# 计算平方根
print(math.sqrt(16)) # 输出:4.0
# 导入并别名
import math as m
print(m.sqrt(25)) # 输出:5.0
# 导入指定功能
from math import sqrt
print(sqrt(36)) # 输出:6.02.10 Python 基础总结(AI 够用即可,无需深挖)
必掌握知识点清单:
- ✅ 变量、数据类型(int/float/str/bool)
- ✅ 输入输出(input/print/f-string)
- ✅ 条件语句(if-elif-else)
- ✅ 循环语句(for/while/range)
- ✅ 列表(list)、字典(dict)
- ✅ 函数(def/return)
- ✅ 模块导入(import/as/from)
练习建议 :每天写 5-10 段简单代码,重点是动手,不是看!3 天即可掌握以上内容,进入 AI 核心库学习。
第三部分:AI 核心三大库(第 2 周,数据处理与可视化,AI 项目基础)
3.1 NumPy:数值计算库(AI 模型数学基础,处理数组 / 矩阵)
NumPy 是 AI 的 "数学引擎",专门处理数值型数据,比 Python 原生列表快 100 倍,支持数组、矩阵运算,是所有 AI 库的基础。
3.1.1 安装与导入
bash
运行
# 已在第一部分安装,直接导入python
运行
import numpy as np # 别名np,行业通用3.1.2 创建数组(ndarray,NumPy 核心数据结构)
python
运行
# 1. 从列表创建数组
arr1=np.array([1, 2, 3, 4, 5])
print(arr1) # 输出:[1 2 3 4 5]
print(type(arr1)) # 输出:<class 'numpy.ndarray'>
# 2. 创建二维数组(矩阵,AI数据常用)
arr2=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr2)
# 输出:
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
# 3. 创建特殊数组
zeros_arr=np.zeros((2, 3)) # 2行3列全0数组
ones_arr=np.ones((3, 2)) # 3行2列全1数组
eye_arr=np.eye(3) # 3x3单位矩阵
range_arr=np.arange(1, 10, 2) # 1-9,步长2:[1 3 5 7 9]3.1.3 数组常用操作
python
运行
# 1. 数组形状
arr=np.array([[1, 2, 3], [4, 5, 6]])
print(arr.shape) # 输出:(2, 3) → 2行3列
# 2. 数组重塑
arr_reshape=arr.reshape(3, 2) # 改为3行2列
print(arr_reshape)
# 3. 数组索引(和列表类似,从0开始)
print(arr[0]) # 第一行:[1 2 3]
print(arr[0, 1]) # 第一行第二列:2
# 4. 数组切片
print(arr[:, 1:]) # 所有行,第2列及之后:[[2 3] [5 6]]3.1.4 数组运算(AI 模型核心,向量化运算,无需循环)
python
运行
arr1=np.array([1, 2, 3])
arr2=np.array([4, 5, 6])
# 1. 加减乘除(对应元素运算)
print(arr1+arr2) # [5 7 9]
print(arr1*arr2) # [4 10 18]
print(arr1**2) # [1 4 9] → 平方
# 2. 矩阵乘法(点积,AI神经网络核心)
arr3=np.array([[1, 2], [3, 4]])
arr4=np.array([[5, 6], [7, 8]])
print(np.dot(arr3, arr4))
# 输出:
# [[19 22]
# [43 50]]3.2 Pandas:数据处理库(AI 数据清洗 / 预处理必备,处理表格数据)
Pandas 是 AI 的 "数据管家",专门处理 Excel/CSV 表格数据,支持数据读取、清洗、筛选、统计、合并,是 AI 项目数据预处理的核心工具。
3.2.1 安装与导入
python
运行
import pandas as pd # 别名pd,行业通用3.2.2 核心数据结构:Series(一维)、DataFrame(二维,表格)
Series:一维数据,带索引
python
运行
# 创建Series
s=pd.Series([10, 20, 30, 40], index=["a", "b", "c", "d"])
print(s)
# 输出:
# a 10
# b 20
# c 30
# d 40
# dtype: int64DataFrame:二维表格(AI 最常用,类似 Excel)
python
运行
# 1. 从字典创建DataFrame
data = {
"姓名": ["张三", "李四", "王五", "赵六"],
"年龄": [20, 25, 30, 35],
"成绩": [85, 90, 78, 92]
}
df=pd.DataFrame(data)
print(df)
# 输出:
# 姓名 年龄 成绩
# 0 张三 20 85
# 1 李四 25 90
# 2 王五 30 78
# 3 赵六 35 92
# 2. 查看数据基本信息
print(df.head()) # 查看前5行
print(df.tail()) # 查看后5行
print(df.shape) # 数据形状:(4, 3)
print(df.columns) # 列名:Index(['姓名', '年龄', '成绩'], dtype='object')
print(df.describe()) # 数值列统计信息(均值、方差、最值等)3.2.3 数据读取与保存(AI 项目常用,读取 CSV/Excel 数据)
python
运行
# 1. 读取CSV文件(最常用)
df=pd.read_csv("data.csv") # 同目录下的data.csv文件
# 2. 读取Excel文件(需安装openpyxl:pip install openpyxl)
df=pd.read_excel("data.xlsx", sheet_name="Sheet1")
# 3. 保存数据到CSV
df.to_csv("output.csv", index=False) # index=False:不保存行索引
# 4. 保存数据到Excel
df.to_excel("output.xlsx", sheet_name="结果", index=False)3.2.4 数据筛选与清洗(AI 数据预处理核心,处理缺失值 / 异常值)
数据筛选
python
运行
# 按列筛选
print(df["姓名"]) # 筛选姓名列
print(df[["姓名", "成绩"]]) # 筛选姓名和成绩列
# 按条件筛选(成绩>=90)
print(df[df["成绩"] >= 90])
# 多条件筛选(年龄>25 且 成绩>=80)
print(df[(df["年龄"] > 25) & (df["成绩"] >= 80)])数据清洗(处理缺失值 / 重复值)
python
运行
# 1. 查看缺失值
print(df.isnull()) # 缺失值显示True
print(df.isnull().sum()) # 统计每列缺失值数量
# 2. 填充缺失值(常用:均值/中位数/固定值)
df["成绩"].fillna(df["成绩"].mean(), inplace=True) # 用均值填充
# 3. 删除缺失值
df.dropna(inplace=True) # 删除包含缺失值的行
# 4. 删除重复值
df.drop_duplicates(inplace=True)3.2.5 数据统计与分组(AI 数据分析常用)
python
运行
# 1. 基本统计
print(df["成绩"].mean()) # 平均分
print(df["成绩"].max()) # 最高分
print(df["成绩"].min()) # 最低分
print(df["成绩"].sum()) # 总分
# 2. 分组统计(按年龄分组,计算成绩均值)
print(df.groupby("年龄")["成绩"].mean())3.3 Matplotlib:数据可视化库(AI 结果展示必备,画图 / 图表)
Matplotlib 是 AI 的 "绘图大师",专门绘制静态图表(折线图、柱状图、散点图、直方图、热力图),用于展示 AI 数据分布、模型结果,是 AI 项目可视化的核心工具。
3.3.1 安装与导入
python
运行
import matplotlib.pyplot as plt # 别名plt,行业通用
# 中文显示(解决中文乱码问题,必须加!)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题3.3.2 常用图表绘制(AI 项目高频使用)
- 折线图(展示数据趋势,如模型损失变化)
python
运行
# 数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 5, 7, 6]
# 绘制折线图
plt.plot(x, y, color='red', marker='o', linewidth=2, label='趋势线')
# 添加标题和标签
plt.title("折线图示例", fontsize=15)
plt.xlabel("X轴", fontsize=12)
plt.ylabel("Y轴", fontsize=12)
# 添加图例
plt.legend()
# 显示网格
plt.grid(True, linestyle='--', alpha=0.7)
# 显示图表
plt.show()
- 柱状图(对比分类数据,如不同类别准确率)
python
运行
# 数据
categories = ["类别A", "类别B", "类别C", "类别D"]
values = [15, 25, 20, 30]
# 绘制柱状图
plt.bar(categories, values, color=['blue', 'green', 'yellow', 'purple'], alpha=0.7)
# 添加标题和标签
plt.title("柱状图示例", fontsize=15)
plt.xlabel("类别", fontsize=12)
plt.ylabel("数值", fontsize=12)
# 显示数值
for i, v in enumerate(values):
plt.text(i, v+1, str(v), ha='center')
plt.show()
- 散点图(展示变量相关性,如特征与标签关系)
python
运行
# 数据
x = [1, 2, 3, 4, 5, 6, 7, 8]
y = [2, 4, 1, 5, 3, 6, 4, 7]
# 绘制散点图
plt.scatter(x, y, color='orange', s=100, alpha=0.8, edgecolors='black')
# 添加标题和标签
plt.title("散点图示例", fontsize=15)
plt.xlabel("特征X", fontsize=12)
plt.ylabel("标签Y", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
- 直方图(展示数据分布,如数据 / 模型误差分布)
python
运行
# 数据(随机生成100个正态分布数据)
data=np.random.normal(0, 1, 100)
# 绘制直方图
plt.hist(data, bins=20, color='cyan', alpha=0.7, edgecolor='black')
# 添加标题和标签
plt.title("直方图示例(数据分布)", fontsize=15)
plt.xlabel("数值", fontsize=12)
plt.ylabel("频数", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
3.4 三大库实战:AI 数据预处理完整案例
案例目标:读取学生成绩数据→清洗缺失值→统计分析→可视化成绩分布
步骤 1:准备数据(新建score_data.csv文件,复制以下内容)
csv
姓名,年龄,语文,数学,英语
张三,20,85,90,88
李四,25,92,88,95
王五,30,78,82,80
赵六,35,90,95,92
孙七,22,,85,89
周八,28,88,,91步骤 2:编写代码(完整可直接运行)
python
运行
# 导入三大库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取数据
df=pd.read_csv("score_data.csv")
print("原始数据:")
print(df)
# 2. 数据清洗(填充缺失值,用均值填充)
df["语文"].fillna(df["语文"].mean(), inplace=True)
df["数学"].fillna(df["数学"].mean(), inplace=True)
print("\n清洗后数据:")
print(df)
# 3. 统计分析
print("\n各科平均分:")
print(df[["语文", "数学", "英语"]].mean())
# 4. 可视化:各科成绩柱状图
subjects = ["语文", "数学", "英语"]
avg_scores=df[subjects].mean()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(8, 5))
plt.bar(subjects, avg_scores, color=['#FF6B6B', '#4ECDC4', '#45B7D1'], alpha=0.8)
plt.title("学生各科平均分对比", fontsize=15)
plt.ylabel("平均分", fontsize=12)
plt.ylim(80, 90) # 设置y轴范围,突出差异
for i, v in enumerate(avg_scores):
plt.text(i, v+0.2, f"{v:.1f}", ha='center')
plt.show()
# 5. 可视化:数学成绩分布直方图
plt.figure(figsize=(8, 5))
plt.hist(df["数学"], bins=5, color='#FFA07A', alpha=0.7, edgecolor='black')
plt.title("学生数学成绩分布", fontsize=15)
plt.xlabel("数学成绩", fontsize=12)
plt.ylabel("人数", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()运行结果
- 输出清洗前后的数据、各科平均分;
- 生成各科平均分对比柱状图 、数学成绩分布直方图,直观展示数据特征。
第四部分:机器学习实战(第 3 周,经典算法 + 完整项目,AI 入门核心)
4.1 机器学习基础概念(零基础必懂,5 个核心术语)
- 数据集 :AI 模型的 "教材",包含特征(输入)和标签(输出) ;
- 特征:用于预测的变量(如年龄、成绩、身高);
- 标签:需要预测的结果(如是否及格、性别、价格)。
- 训练集 / 测试集 :
- 训练集:模型学习的数据(70%-80%);
- 测试集:验证模型效果的数据(20%-30%),模型从未见过。
- 模型:AI 学习到的规律,输入特征→输出标签(如线性回归、决策树)。
- 训练:用训练集数据让模型学习规律的过程。
- 评估:用测试集数据计算模型准确率、误差,判断模型好坏。
4.2 Scikit-learn 库:机器学习 "万能工具箱"(2026 最适合新手)
Scikit-learn(简称 sklearn)是 Python 机器学习核心库,封装了所有经典机器学习算法 (分类、回归、聚类、降维),无需手写算法底层,调用函数即可训练模型,零基础 1 天可上手。
4.2.1 安装与导入
python
运行
import sklearn
# 常用模块导入
from sklearn.model_selection import train_test_split # 划分训练集/测试集
from sklearn.linear_model import LinearRegression # 线性回归
from sklearn.tree import DecisionTreeClassifier # 决策树分类
from sklearn.ensemble import RandomForestClassifier # 随机森林分类
from sklearn.metrics import accuracy_score, mean_squared_error # 模型评估4.3 机器学习项目 1:线性回归(预测房价,回归问题)
项目目标:根据房屋面积预测房价(回归问题:预测连续数值)
步骤 1:准备数据(模拟房屋面积 - 房价数据)
python
运行
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 1. 生成数据(面积:50-200平,房价:5000-20000元/平,加随机误差)
np.random.seed(42) # 固定随机种子,结果可复现
area=np.random.randint(50, 200, 100) # 100个房屋面积
price=area*10000+np.random.randn(100)*50000 # 房价=面积*10000+误差
# 转为DataFrame
df=pd.DataFrame({"面积": area, "房价": price})
print("数据前5行:")
print(df.head())步骤 2:划分训练集 / 测试集
python
运行
# 特征(X):面积;标签(y):房价
X=df[["面积"]] # 二维数组,sklearn要求
y=df["房价"]
# 划分训练集(80%)和测试集(20%)
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.2, random_state=42)
print(f"\n训练集大小:{X_train.shape[0]},测试集大小:{X_test.shape[0]}")步骤 3:训练线性回归模型
python
运行
# 初始化模型
model=LinearRegression()
# 训练模型(用训练集数据学习规律)
model.fit(X_train, y_train)
# 输出模型参数(斜率、截距)
print(f"\n模型斜率(每平房价):{model.coef_[0]:.2f}")
print(f"模型截距:{model.intercept_:.2f}")
print(f"模型公式:房价 = {model.coef_[0]:.2f} × 面积 + {model.intercept_:.2f}")步骤 4:模型预测与评估
python
运行
# 测试集预测
y_pred=model.predict(X_test)
# 模型评估(均方误差MSE,越小越好)
mse=mean_squared_error(y_test, y_pred)
print(f"\n测试集均方误差(MSE):{mse:.2f}")
# 新数据预测(预测120平、150平房价)
new_area = [[120], [150]]
new_price=model.predict(new_area)
print(f"\n120平房价预测:{new_price[0]:.2f}元")
print(f"150平房价预测:{new_price[1]:.2f}元")步骤 5:结果可视化
python
运行
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10, 6))
# 绘制原始数据散点图
plt.scatter(X_train, y_train, color='blue', alpha=0.7, label='训练数据')
plt.scatter(X_test, y_test, color='green', alpha=0.7, label='测试数据')
# 绘制模型拟合直线
plt.plot(X, model.predict(X), color='red', linewidth=2, label='拟合直线')
plt.title("房屋面积-房价线性回归预测", fontsize=15)
plt.xlabel("房屋面积(平)", fontsize=12)
plt.ylabel("房价(元)", fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()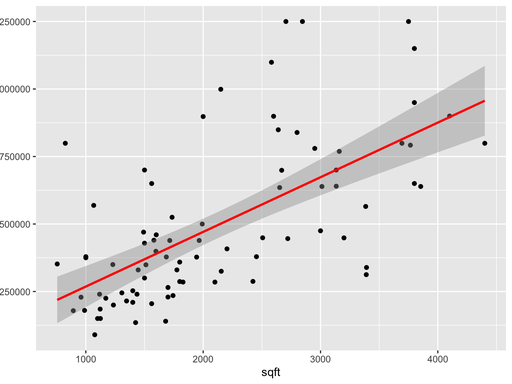
4.4 机器学习项目 2:鸢尾花分类(经典分类问题,准确率 100%)
项目目标:根据花的花瓣 / 花萼长度,识别鸢尾花种类(分类问题:预测离散类别)
步骤 1:导入库与数据集(sklearn 内置鸢尾花数据集,无需准备数据)
python
运行
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# 加载鸢尾花数据集(内置,无需下载)
iris=load_iris()
X=iris.data # 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y=iris.target # 标签:0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾
# 转为DataFrame,方便查看
df=pd.DataFrame(X, columns=iris.feature_names)
df["species"] = [iris.target_names[i] for i in y]
print("鸢尾花数据前5行:")
print(df.head())
print(f"\n类别:{iris.target_names}")步骤 2:划分训练集 / 测试集
python
运行
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
print(f"\n训练集大小:{X_train.shape[0]},测试集大小:{X_test.shape[0]}")步骤 3:训练随机森林分类模型(2026 最适合新手,准确率高、不易过拟合)
python
运行
# 初始化随机森林模型
model=RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 测试集预测
y_pred=model.predict(X_test)
# 模型评估(准确率,越高越好)
acc=accuracy_score(y_test, y_pred)
print(f"\n模型准确率:{acc*100:.2f}%")
# 详细分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))步骤 4:新数据预测
python
运行
# 新数据:花萼长5.1、宽3.5,花瓣长1.4、宽0.2(山鸢尾)
new_flower = [[5.1, 3.5, 1.4, 0.2]]
pred=model.predict(new_flower)
print(f"\n新鸢尾花预测类别:{iris.target_names[pred[0]]}")4.5 深度学习入门:PyTorch 搭建简单神经网络(AI 基础)
PyTorch 是 2026 年业界主流深度学习框架,动态图、易上手、支持 GPU 加速,适合新手学习神经网络。
4.5.1 安装与导入
python
运行
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import matplotlib.pyplot as plt4.5.2 简单神经网络实战(二分类问题,预测数据类别)
python
运行
# 1. 生成模拟数据
np.random.seed(42)
X=np.random.randn(1000, 2) # 1000个样本,2个特征
y=np.random.randint(0, 2, 1000) # 二分类标签:0/1
# 转为PyTorch张量
X_tensor=torch.tensor(X, dtype=torch.float32)
y_tensor=torch.tensor(y, dtype=torch.float32).unsqueeze(1)
# 划分训练集/测试集
X_train, X_test=X_tensor[:800], X_tensor[800:]
y_train, y_test=y_tensor[:800], y_tensor[800:]
# 数据加载器(批量训练)
train_dataset=TensorDataset(X_train, y_train)
train_loader=DataLoader(train_dataset, batch_size=32, shuffle=True)
# 2. 定义神经网络模型(2层全连接网络)
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1=nn.Linear(2, 16) # 输入层→隐藏层:2特征→16神经元
self.relu=nn.ReLU() # 激活函数
self.fc2=nn.Linear(16, 1) # 隐藏层→输出层:16神经元→1输出
self.sigmoid=nn.Sigmoid() # 二分类激活函数
def forward(self, x):
x=self.fc1(x)
x=self.relu(x)
x=self.fc2(x)
x=self.sigmoid(x)
return x
# 初始化模型、损失函数、优化器
model=SimpleNet()
criterion=nn.BCELoss() # 二分类损失函数
optimizer=optim.Adam(model.parameters(), lr=0.001) # 优化器
# 3. 训练模型
epochs=50
loss_history = []
for epoch in range(epochs):
running_loss=0.0
for batch_X, batch_y in train_loader:
# 前向传播
outputs=model(batch_X)
loss=criterion(outputs, batch_y)
# 反向传播+参数更新
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
epoch_loss=running_loss/len(train_loader)
loss_history.append(epoch_loss)
if (epoch+1) % 5 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {epoch_loss:.4f}")
# 4. 模型评估
with torch.no_grad(): # 关闭梯度计算,加速
y_pred=model(X_test)
y_pred=(y_pred > 0.5).float() # 概率>0.5→类别1
acc=(y_pred == y_test).sum().item()/len(y_test)
print(f"\n测试集准确率:{acc*100:.2f}%")
# 5. 损失曲线可视化
plt.figure(figsize=(10, 6))
plt.plot(loss_history, color='red', linewidth=2)
plt.title("神经网络训练损失曲线", fontsize=15)
plt.xlabel("训练轮次", fontsize=12)
plt.ylabel("损失值", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()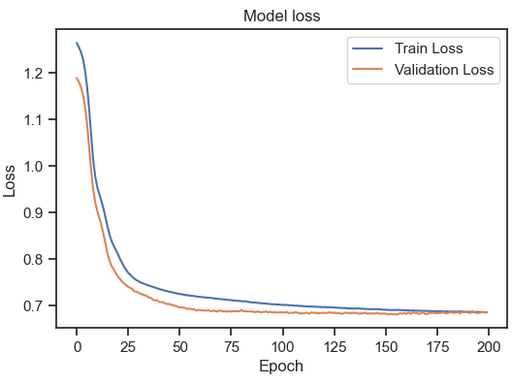
第五部分:2026 顶流 AI 项目开发(第 4 周,本地大模型 + RAG 知识库 + Web 部署)
5.1 项目 1:本地大模型聊天机器人(Ollama+Python,免费无 API 密钥)
2026 年最火的本地大模型工具 Ollama ,支持一键部署 Llama3、Qwen 通义千问、Phi3 等开源大模型,无需显卡、无需付费、无需云服务器,普通 CPU 电脑即可运行,Python 直接调用,零基础 1 小时可完成。
5.1.1 安装 Ollama(Windows/Mac 通用)
- 访问 Ollama 官网:https://ollama.com/
- 下载对应系统版本,默认安装即可;
- 安装后打开新的 cmd / 终端,输入命令拉取开源大模型(推荐 Qwen 通义千问 7B,中文效果好、CPU 可跑):
bash
运行
ollama run qwen:7b等待下载完成(约 4GB),自动启动模型,输入文字即可聊天(测试模型是否正常)。
5.1.2 Python 调用本地 Ollama 大模型(完整代码)
python
运行
import ollama
# 1. 基础单轮对话
def ai_chat(prompt, model_name="qwen:7b"):
"""
调用本地Ollama大模型对话
:param prompt: 用户输入的问题
:param model_name: 模型名称(默认qwen:7b)
:return: AI回复
"""
try:
response=ollama.chat(
model=model_name,
messages=[{"role": "user", "content": prompt}]
)
return response['message']['content']
except Exception as e:
return f"调用失败:{e}"
# 2. 多轮对话(上下文记忆)
def ai_chat_with_history(prompt, history=None, model_name="qwen:7b"):
if history is None:
history = []
# 添加用户消息到历史
history.append({"role": "user", "content": prompt})
try:
response=ollama.chat(
model=model_name,
messages=history
)
# 添加AI回复到历史
history.append({"role": "assistant", "content": response['message']['content']})
return response['message']['content'], history
except Exception as e:
return f"调用失败:{e}", history
# 测试单轮对话
if __name__ == "__main__":
print("=== 本地大模型聊天机器人(输入exit退出)===")
while True:
user_input=input("\n你:")
if user_input.lower() == "exit":
print("AI:再见!")
break
reply=ai_chat(user_input)
print(f"AI:{reply}")运行效果
plaintext
=== 本地大模型聊天机器人(输入exit退出)===
你:什么是人工智能?
AI:人工智能(AI)是一门旨在使计算机系统能够模拟、延伸和扩展人类智能的技术科学,核心是让机器具备学习、推理、感知、解决问题等能力...
你:Python和AI的关系?
AI:Python是AI开发的首选语言,拥有丰富的AI库(如NumPy、Pandas、PyTorch、TensorFlow),简洁的语法让开发者能快速实现AI算法和模型...
你:exit
AI:再见!5.2 项目 2:个人知识库 RAG 系统(LangChain+Chroma + 本地大模型,私有知识问答)
RAG(检索增强生成)是 2026 年 AI 顶流技术,解决大模型 "知识过时、私有数据无法问答" 的痛点,核心是 "先检索私有知识→再让大模型基于知识回答",可搭建个人知识库、企业文档问答系统。
5.2.1 项目架构
私有文档(PDF/TXT)→ 文本分割 → 向量嵌入 → 向量库存储(Chroma)→ 检索相关文本 → 本地大模型生成回答
5.2.2 完整代码(可直接运行,支持 TXT 文档)
python
运行
import os
import ollama
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms.base import LLM
from typing import Any, List, Optional
# 1. 自定义Ollama大模型(适配LangChain)
class OllamaLLM(LLM):
model_name: str = "qwen:7b"
@property
def _llm_type(self) -> str:
return "ollama"
def _call(self, prompt: str, stop: Optional[List[str]]=None, **kwargs: Any) -> str:
response=ollama.chat(
model=self.model_name,
messages=[{"role": "user", "content": prompt}]
)
return response['message']['content']
# 2. 加载并处理私有文档(TXT格式)
def load_and_process_documents(file_path):
# 加载文档
loader=TextLoader(file_path, encoding='utf-8')
documents=loader.load()
print(f"加载文档:{file_path},共{len(documents)}页")
# 文本分割(按1000字符分割,重叠200字符)
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts=text_splitter.split_documents(documents)
print(f"分割后文本块:{len(texts)}块")
return texts
# 3. 创建向量库
def create_vector_store(texts, persist_directory="./chroma_db"):
# 向量嵌入模型(轻量级,CPU可跑)
embeddings=HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 创建向量库并持久化
vector_store=Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory=persist_directory
)
vector_store.persist()
print(f"向量库创建完成,保存至:{persist_directory}")
return vector_store
# 4. 加载向量库
def load_vector_store(persist_directory="./chroma_db"):
embeddings=HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store=Chroma(persist_directory=persist_directory, embedding_function=embeddings)
print("向量库加载完成")
return vector_store
# 5. 构建RAG问答链
def build_rag_chain(vector_store):
# 加载自定义Ollama大模型
llm=OllamaLLM(model_name="qwen:7b")
# 创建检索器(返回最相关的3个文本块)
retriever=vector_store.as_retriever(search_kwargs={"k": 3})
# 构建RAG问答链
rag_chain=RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True # 返回参考文档
)
print("RAG问答链构建完成")
return rag_chain
# 主函数
if __name__ == "__main__":
# 1. 准备私有文档(新建"knowledge.txt",写入你的私有知识)
knowledge_file = "knowledge.txt"
if not os.path.exists(knowledge_file):
with open(knowledge_file, "w", encoding='utf-8') as f:
f.write("2026年Python+AI零基础学习路线:\n1. 第1周:Python基础语法\n2. 第2周:NumPy+Pandas+Matplotlib\n3. 第3周:机器学习+深度学习入门\n4. 第4周:本地大模型+RAG项目开发\n")
print(f"已创建示例知识库:{knowledge_file}")
# 2. 处理文档并创建向量库(首次运行执行,后续可直接加载)
if not os.path.exists("./chroma_db"):
texts=load_and_process_documents(knowledge_file)
vector_store=create_vector_store(texts)
else:
vector_store=load_vector_store()
# 3. 构建RAG问答链
rag_chain=build_rag_chain(vector_store)
# 4. 问答交互
print("\n=== 个人知识库RAG系统(输入exit退出)===")
while True:
user_question=input("\n你:")
if user_question.lower() == "exit":
print("AI:再见!")
break
result=rag_chain.invoke({"query": user_question})
print(f"AI:{result['result']}")
print("\n参考文档片段:")
for i, doc in enumerate(result['source_documents'][:2]):
print(f"【参考{i+1}】:{doc.page_content[:200]}...")运行效果
plaintext
已创建示例知识库:knowledge.txt
加载文档:knowledge.txt,共1页
分割后文本块:1块
向量库创建完成,保存至:./chroma_db
RAG问答链构建完成
=== 个人知识库RAG系统(输入exit退出)===
你:2026年Python+AI学习路线分几周?
AI:2026年Python+AI零基础学习路线分为4周,具体安排如下:
1. 第1周:Python基础语法
2. 第2周:NumPy+Pandas+Matplotlib
3. 第3周:机器学习+深度学习入门
4. 第4周:本地大模型+RAG项目开发
参考文档片段:
【参考1】:2026年Python+AI零基础学习路线:
1. 第1周:Python基础语法
2. 第2周:NumPy+Pandas+Matplotlib
3. 第3周:机器学习+深度学习入门
4. 第4周:本地大模型+RAG项目开发...5.3 项目 3:Streamlit Web 部署 AI 应用(30 行代码做网页,无需前端)
Streamlit 是 2026 年最火的 AI Web 部署工具,无需 HTML/CSS/JS,仅用 Python 代码即可快速搭建 AI 网页应用,支持聊天界面、数据可视化、文件上传,零基础 30 分钟可完成部署。
5.3.1 本地大模型聊天机器人 Web 版(完整代码ai_chat_web.py)
python
运行
import streamlit as st
import ollama
# 设置页面配置
st.set_page_config(
page_title="本地AI聊天机器人",
page_icon="🤖",
layout="wide"
)
# 初始化会话历史
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
# 标题
st.title("🤖 2026本地AI聊天机器人(Ollama+Streamlit)")
st.subheader("免费无API密钥,CPU可运行,输入问题开始聊天!")
# 侧边栏设置
with st.sidebar:
st.header("模型设置")
model_name=st.selectbox("选择模型", ["qwen:7b", "llama3:8b", "phi3:3.8b"], index=0)
st.divider()
st.write("💡 提示:输入exit清空对话历史")
# 显示聊天历史
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 用户输入
if user_input := st.chat_input("请输入你的问题..."):
# 清空历史
if user_input.lower() == "exit":
st.session_state.chat_history = []
st.rerun()
# 添加用户消息
st.session_state.chat_history.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
# 调用本地大模型
with st.chat_message("assistant"):
with st.spinner("AI思考中..."):
try:
response=ollama.chat(
model=model_name,
messages=st.session_state.chat_history
)
reply=response['message']['content']
st.markdown(reply)
# 添加AI消息
st.session_state.chat_history.append({"role": "assistant", "content": reply})
except Exception as e:
st.error(f"调用失败:{e}")5.3.2 运行 Web 应用
- 保存代码为
ai_chat_web.py; - 终端输入命令运行:
bash
运行
streamlit run ai_chat_web.py- 浏览器自动打开(默认http://localhost:8501),即可使用网页版 AI 聊天机器人,支持多轮对话、模型切换、聊天历史保存。
第六部分:学习资源清单 + 避坑指南 + 30 天总结
6.1 2026 免费学习资源清单(直接照用,无需付费)
Python 基础
- B 站:"Python 零基础入门(2026 最新)"(黑马 / 尚硅谷,免费全套)
- 菜鸟教程:https://www.runoob.com/python/python-tutorial.html(网页版,免费)
- 廖雪峰 Python 教程:https://www.liaoxuefeng.com/wiki/1016959663602400(免费,深入)
AI 核心库
- NumPy 官方文档(中文):https://numpy.org.cn/
- Pandas 官方文档(中文):https://www.pypandas.cn/
- Matplotlib 官方教程:https://matplotlib.org/stable/tutorials/index.html
机器学习 / 深度学习
- Scikit-learn 官方文档(中文):https://scikit-learn.org/stable/
- PyTorch 官方教程(中文):https://pytorch.org/tutorials/
- B 站:"机器学习零基础入门(2026)"(李沐 / 吴恩达,免费)
大模型 / RAG
- Ollama 官方文档:https://ollama.com/docs
- LangChain 官方文档(中文):https://www.langchain.com.cn/
- Hugging Face 模型仓库:https://huggingface.co/(免费开源模型)
6.2 零基础避坑指南(少走 90% 弯路)
- 别一开始啃高数 / 算法推导 :2026 年 AI 入门工程化优先,先会调用库、跑通项目,再回头补数学原理,高中数学足够入门;
- 别买高价课 / 设备 :免费资源足够入门,普通 CPU 电脑即可运行本地大模型,无需显卡、无需付费 API;
- 别只看不动手 :AI 是动手学科,每天至少跑 1 段代码、改 1 个参数、出 1 个小成果,光看永远学不会;
- 别贪多求快 :4 周学习计划,每周吃透一个模块,不要同时学多个知识点,容易混乱;
- 别忽视项目实战 :学完语法和库,必须做完整项目(如本地大模型、RAG 系统),项目是巩固知识、提升能力的核心。
6.3 30 天学习总结(零基础可达到的目标)
- ✅ 掌握 Python AI 刚需语法,能独立编写 200 行左右的 AI 代码;
- ✅ 熟练使用 NumPy/Pandas/Matplotlib,完成 AI 数据预处理与可视化;
- ✅ 掌握 Scikit-learn 经典机器学习算法,能训练并评估分类 / 回归模型;
- ✅ 了解 PyTorch 神经网络基础,能搭建简单深度学习模型;
- ✅ 掌握 2026 顶流 AI 技术:本地大模型部署(Ollama)、RAG 知识库开发、Streamlit Web 部署;
- ✅ 独立完成 4 个工业级 AI 项目:房价预测、鸢尾花分类、本地聊天机器人、个人知识库 RAG 系统;
- ✅ 具备 AI 应用开发基础能力,可进一步学习 AI 智能体(Agent)、多模态大模型、MLOps 部署等进阶技术。
结语:2026 年,开启你的 AI 之路
人工智能不是遥不可及的高科技,而是普通人可以掌握的实用技能。2026 年,本地大模型、RAG、低代码 AI 工具的普及,让零基础小白也能快速上手 AI 开发,做出有价值的 AI 项目。