从自然语言到SQL:大模型时代结构化数据查询的技术革命与落地实践
在数据驱动的今天,数据库已经成为企业的核心资产,但传统SQL查询的技术门槛,让绝大多数非技术人员无法直接挖掘数据价值。自然语言转SQL(NL2SQL)技术的出现,正在打破这一壁垒------它让任何人都能通过"说人话"的方式查询数据库,真正实现"数据民主化"。
本文将系统拆解NL2SQL的核心原理、技术演进、工业落地策略与实战技巧,带你全面了解这一连接自然语言与结构化数据的关键技术。
1 什么是NL2SQL?核心定义与不可替代的价值
1.1 任务定义
NL2SQL(Natural Language to SQL)是将自然语言问题转化为符合SQL语法规范、可在关系数据库上执行的查询语句的技术。其核心是语义精准映射+语法严谨生成:既要准确理解人类自然语言的业务意图,又要输出零语法错误、逻辑正确的SQL代码。
1.2 三大核心价值
- 降低数据使用门槛:非技术人员(产品、运营、财务)无需学习SQL,通过自然语言即可直接查询数据库,将数据查询效率提升10倍以上。
- 作为多模态对齐的技术基石:NL2SQL解决的"文本→结构化目标"映射问题,是所有NL2X任务的通用范式,其技术逻辑可直接迁移至文本转图像、文本转视频、文本转3D等跨模态场景。
- 工业级落地刚需:是大厂Coder模型的核心组件,也是企业级BI、智能客服、数据中台等产品的标配能力。
1.3 NL2SQL vs NL2Code:为什么大厂要做专门的Coder模型?
NL2SQL是NL2Code(自然语言转代码)中最具代表性的子集,但两者在技术要求上存在本质差异,这也是大厂除了通用大模型外,还要投入资源研发专门Coder模型的原因:
| 维度 | 通用大模型 | 专用Coder模型 |
|---|---|---|
| 精度要求 | 允许一定程度的"胡说八道",综合能力优先 | 零语法错误要求,一个标点错误就会导致程序崩溃 |
| 成本效率 | 参数量巨大,推理成本高、延迟高 | 小参数量优化,保证性能的同时实现低成本、低延迟 |
| 能力边界 | 擅长通用语言理解与创作 | 支持全代码库上下文理解,能避免生成安全漏洞代码 |
1.4 NL2SQL:多模态对齐的"纯Grounding"训练
Grounding(锚定)是指将语言实体映射到现实世界或数字世界中具体对象的过程。NL2SQL被称为"更纯粹的Grounding",因为它在最苛刻的条件下实现精确锚定:
| 维度 | NL2SQL | NL2IMG(文本转图像) | 为什么NL2SQL更"纯" |
|---|---|---|---|
| 锚点明确性 | 表名/列名有唯一ID,离散可枚举 | 图像区域模糊,边界不确定 | SQL的锚点是绝对精确的 |
| 真值确定性 | SQL执行结果只有0/1两种,执行即验证 | FID、CLIP-Score是连续值,存在主观性 | 无争议的评估标准 |
| 约束强度 | SQL语法零容错,一个标点错误全盘皆错 | 图像可以"差不多",存在艺术发挥空间 | 对对齐精度要求最高 |
| 数据规模 | Spider数据集包含10k+复杂查询样本 | COCO仅5k简单描述样本 | 复杂Grounding样本更丰富 |
所有NL2X任务的核心本质都是Grounding:
- NL2SQL:"北京" →
city = '北京' - NL2IMG:"黑色的车" → 图像中的边界框坐标
- NL2Video:"第3秒的猫" → 第90帧 + 物体ID
大量研究证明,NL2SQL的Grounding预训练可以显著提升多模态模型的性能:NeurIPS 2024的GrounDiT论文表明,结构化Grounding预训练可将文本转图像准确率提升15%。
2 NL2SQL的核心技术基石:Schema对齐与语义消歧
NL2SQL最核心的挑战不是生成SQL语法,而是Schema Linking(模式链接)------将自然语言中的业务术语,精准映射到数据库中的表名和列名。这一步的准确率直接决定了最终SQL的正确性。
2.1 Schema的完整组成
Schema是数据库的元数据描述,是NL2SQL系统的"地图",包含以下要素:
- 基础核心要素:表名及业务含义、列名及数据类型、主键(唯一标识记录)、外键(关联不同表)
- 关键补充要素:列的约束(是否允许为空、枚举值)、业务属性(表的分类、列的统计特征)、索引信息(影响SQL性能优化)
2.2 Schema Linking的四步实现
Schema Linking本质上就是Grounding在数据库领域的具体实现,分为四个标准步骤:
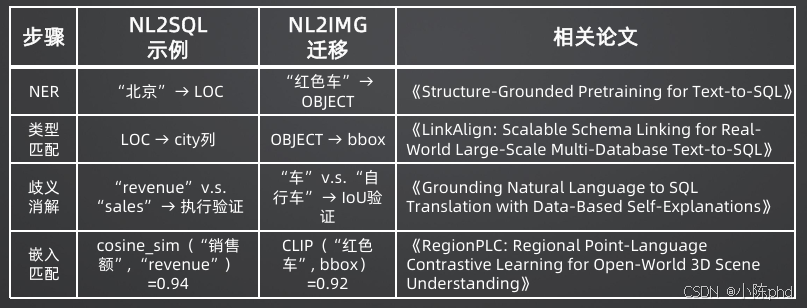
步骤1:命名实体识别(NER)
从自然语言问题中提取关键实体,并标注其类型。
示例 :
问题:"北京Q3销售额最高的3个产品"
提取实体:
{"text":"北京", "type":"LOC"}(地点){"text":"Q3", "type":"TIME"}(时间){"text":"销售额", "type":"METRIC"}(指标)
步骤2:类型匹配
根据实体类型,筛选出数据库中可能匹配的列。
示例 :
类型映射表:
LOC→ "city", "region", "province"TIME→ "quarter", "date", "year"METRIC→ "revenue", "sales", "amount"
"北京"(LOC类型)的候选列:city、region
步骤3:语义消歧
当存在多个候选列时,通过多种策略消除歧义:
- 执行验证:生成测试SQL执行,能成功返回结果的即为正确列
- 上下文关联 :结合前文语境判断,如前文提到"总收入",则优先匹配
revenue而非sales - 业务规则 :根据企业业务规范,如"销售额"在本系统中对应
sales字段
步骤4:嵌入空间匹配
将自然语言术语和数据库列名转换为向量,通过余弦相似度计算匹配度,这是目前最常用的方法。
示例:
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('bge-m3')
query_emb = model.encode("销售额")
col_embs = model.encode(["revenue", "sales", "profit"])
# 计算余弦相似度
scores = np.dot(query_emb, col_embs.T) / (np.linalg.norm(query_emb) * np.linalg.norm(col_embs, axis=1))
# 输出:[0.94, 0.87, 0.62]
# 最优匹配:revenue2.3 中间表示(IR):提升可控性的关键
NL2SQL有两种主流技术路线:端到端直接生成SQL,和先生成中间表示(IR)再转SQL。IR在"低资源、强约束、高可解释"的工业场景中具有不可替代的价值。
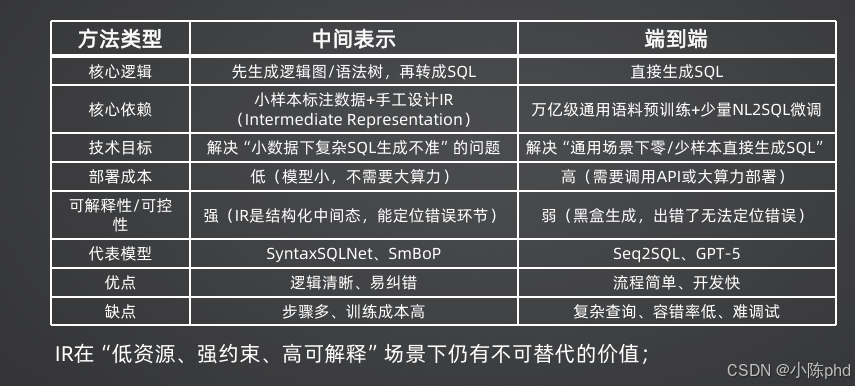
什么是IR?
IR是一种人工设计的结构化中间语言,固定了所有可能的操作和字段,避免模型生成无效内容。
示例:
json
{
"目标操作": "求和",
"涉及表名": "sales",
"涉及列名": "revenue",
"过滤条件": [
{"列名": "city", "运算符": "=", "值": "北京"},
{"列名": "quarter", "运算符": "=", "值": "Q3"}
]
}转换为SQL:
sql
SELECT SUM(revenue) FROM sales WHERE city='北京' AND quarter='Q3';两种技术路线对比
| 维度 | 端到端生成 | 中间表示(IR) |
|---|---|---|
| 核心逻辑 | 直接生成SQL字符串 | 先生成结构化IR,再转SQL |
| 数据依赖 | 万亿级通用语料+少量微调 | 小样本标注数据+手工设计IR |
| 部署成本 | 高(需要大算力) | 低(小模型即可) |
| 可解释性 | 弱(黑盒,出错无法定位) | 强(可逐字段检查错误) |
| 可控性 | 弱(可能生成危险SQL) | 强(所有操作都在白名单内) |
| 代表模型 | GPT-4o、DeepSeek-Coder | SyntaxSQLNet、SmBoP |
3 NL2SQL技术演进:从规则到大模型的四代变革
NL2SQL技术经历了四十年的发展,从最初的手工规则,演进到如今的大模型时代,每一次技术变革都带来了准确率和泛化能力的质的飞跃。
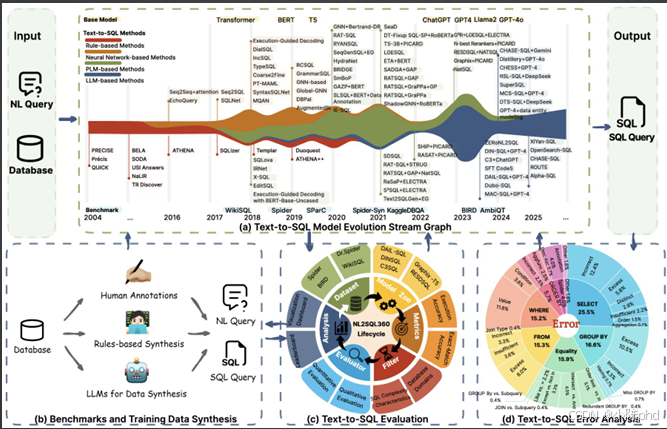
3.1 第一阶段:基于规则的模型(1970s-2010s)
- 核心原理:手工编写语法和语义规则,将自然语言中的关键词与数据库表列进行匹配
- 优点:简单可控,在固定场景下准确率高
- 缺点:泛化能力极差,无法处理复杂查询,维护成本极高
- 适用场景:极其简单的单表查询,固定Schema的内部系统
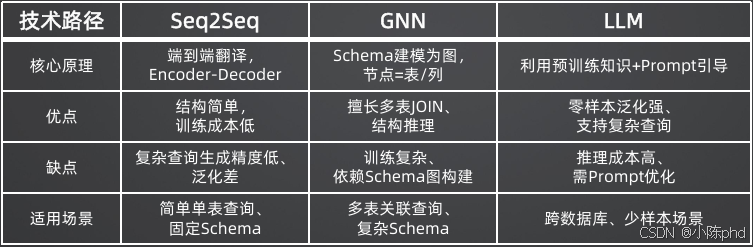
3.2 第二阶段:基于神经网络的模型(2010s中后期)
- 核心原理:将NL2SQL视为"机器翻译"任务,使用Encoder-Decoder架构(LSTM、GRU)将自然语言"翻译"成SQL
- 优点:减少对人工规则的依赖,支持多表关联和复杂查询
- 缺点:复杂查询生成精度低,泛化能力差,需要大量标注数据
- 代表模型:Seq2SQL
3.3 第三阶段:基于预训练模型的方法(2020前后)
- 核心原理:在BERT、T5等大规模预训练语言模型基础上进行微调,利用模型自带的语言理解先验知识
- 里程碑:Spider数据集发布,成为业界公认的跨领域NL2SQL评测标准
- 关键技术:图神经网络(GNN)的引入,解决了多表关联的结构推理问题
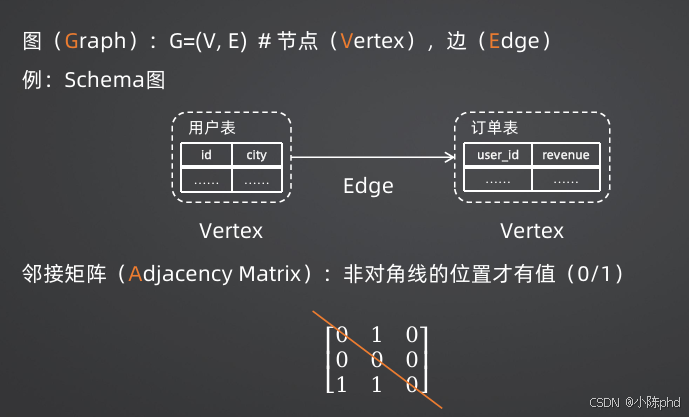
GNN在NL2SQL中的应用
GNN(图神经网络)擅长处理图结构数据,而数据库Schema天然就是一个图:节点是表和列,边是外键关联。
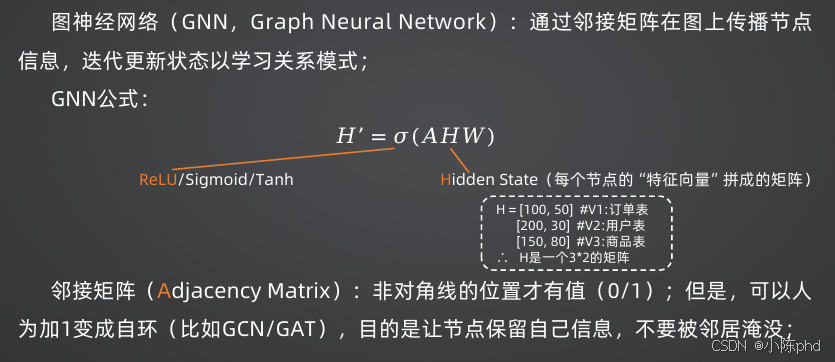
- GCN(图卷积网络):通过邻接矩阵聚合节点及其邻居的信息,实现图上的"局部平均"
- GAT(图注意力网络) :引入注意力机制,自动学习不同邻居节点的权重,比GCN更灵活
代表模型:
- RAT-SQL:使用GNN编码数据库Schema为关系感知图,捕捉表/列间的连接关系
- SADGA:双图聚合网络,同时处理Schema结构和自然语言查询的依赖关系
3.4 第四阶段:基于大语言模型的方法(2022-至今)
- 核心原理:利用超大规模语言模型的通用推理能力,通过提示工程在零样本或少样本下生成SQL
- 优点:零样本泛化能力强,支持极其复杂的查询,技术栈简单
- 缺点:推理成本高,存在幻觉问题,需要精心设计Prompt
- 关键技术:思维链(CoT)、自修正(Self-Refine)、RAG增强
LLM实现NL2SQL的三大关键细节
- Prompt设计:在Prompt中注入数据库Schema、SQL语法提示和少量示例(Few-shot)
- 思维链推理:让模型分步思考:先确定查询表→再确定查询列→然后确定过滤条件→最后确定排序和限制
- 后处理优化 :使用
sqlparse解析SQL语法,使用FuzzyWuzzy修正字段拼写错误
4 工业级落地的核心策略:解决泛化与精度难题
NL2SQL在实验室环境下已经取得了很高的准确率,但在真实工业场景中,仍然面临两大核心挑战:噪声过滤 和跨域泛化。
4.1 工业界的"5S"落地框架
为了解决上述挑战,工业界总结出了一套成熟的"5S"技术框架:
- Schema Linking(模式链接):通过RAG+DDL注入,强制将表名和列名塞进Prompt,避免模型幻觉
- SQL Candidate Generation(SQL候选生成):生成多条可能的SQL语句,增加命中正确结果的概率
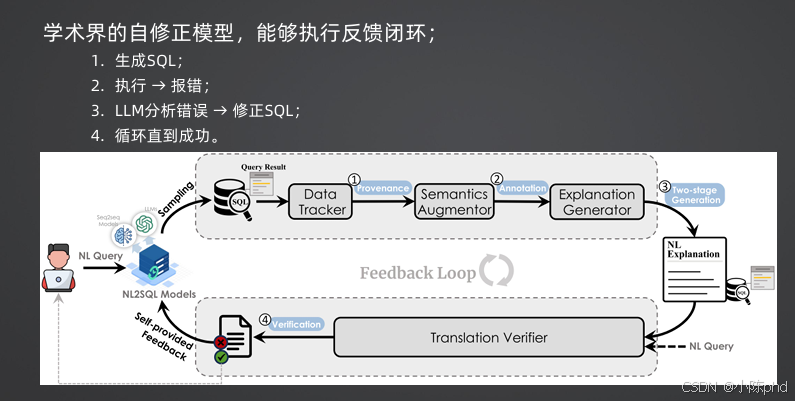
- SQL Error Correction(SQL错误修正):利用自修正机制,根据执行错误信息迭代修正SQL
- Selection of Candidates(候选选择):对生成的多条SQL进行重排序,选出最优解
- Service Verification and Execution(服务验证及执行):最终执行SQL并返回结果,加入权限控制和审计日志
4.2 三大主流开源工具对比
目前工业界已经有多个成熟的NL2SQL开源工具,覆盖不同的部署需求:
| 工具 | 架构 | 特点 | 适用场景 |
|---|---|---|---|
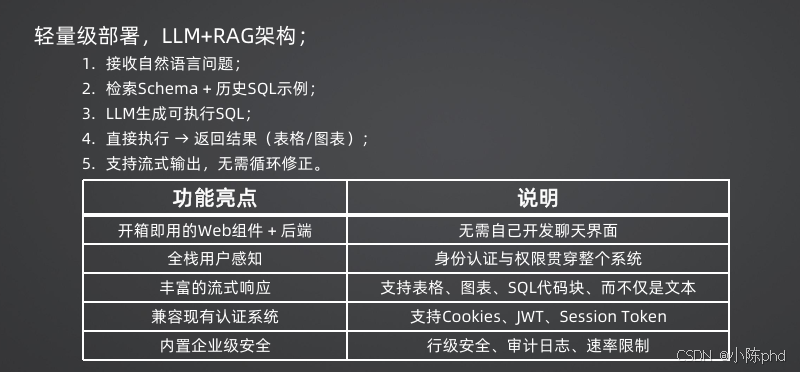
| Vanna | LLM+RAG | 轻量级,开箱即用,自带Web界面和图表生成 | 中小企业快速部署,内部数据分析 |
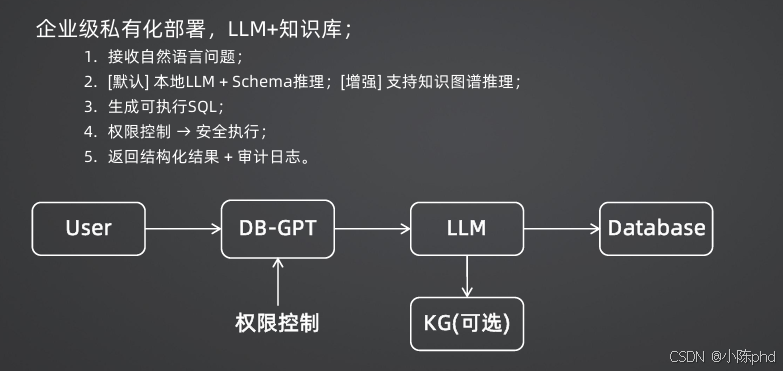
| DB-GPT | 本地LLM+知识库 | 企业级私有化部署,支持知识图谱推理和行级安全 | 金融、政务等对数据安全要求高的场景 |
| CycleSQL | 自修正闭环 | 学术界的自修正模型,支持执行反馈循环 | 复杂查询场景,高准确率要求 |
5 实战指南:从数据集到性能优化
5.1 常用数据集与评估指标
主流数据集
- WikiSQL:最简单的单表查询数据集,适合入门
- Spider:业界公认难度最大的跨领域多表查询数据集
- CSpider:中文NL2SQL数据集
- BIRD-SQL:涵盖区块链、医疗、教育等37个专业领域的大规模数据集
评估指标
- 精确匹配率(EM):生成的SQL与标注SQL完全一致的比例,结果可能被低估(因为存在语义等价但写法不同的SQL)
- 执行正确率(EA):SQL执行结果正确的比例,结果可能被高估(因为可能存在逻辑错误但结果碰巧正确的情况)
最佳实践:组合使用EM和EA两个指标。当EM远低于EA时,说明模型已经学到了正确的逻辑,只是SQL写法不标准;当两者都很低时,说明模型的基础语义理解能力不足。
5.2 SQL查询优化8大技巧
NL2SQL生成的SQL往往不是最优的,在生产环境中需要进行优化:
- 为经常查询的列创建B-tree索引
- 避免使用
SELECT *,只选择需要的列 - 使用
LIMIT限制返回行数,避免全表扫描 - 优先使用
INNER JOIN,避免不必要的OUTER JOIN - 嵌套子查询过多时,改用
JOIN替代 - 避免在WHERE子句中使用函数,会导致索引失效
- 用
EXISTS代替IN,EXISTS只检查存在性,性能更高 - 用
UNION ALL代替UNION,UNION会进行去重操作,速度慢
6 结语与未来展望
NL2SQL技术正在从实验室走向大规模工业落地,它不仅改变了人们与数据交互的方式,更为多模态人工智能的发展提供了重要的技术基石。未来,NL2SQL技术将向以下方向发展:
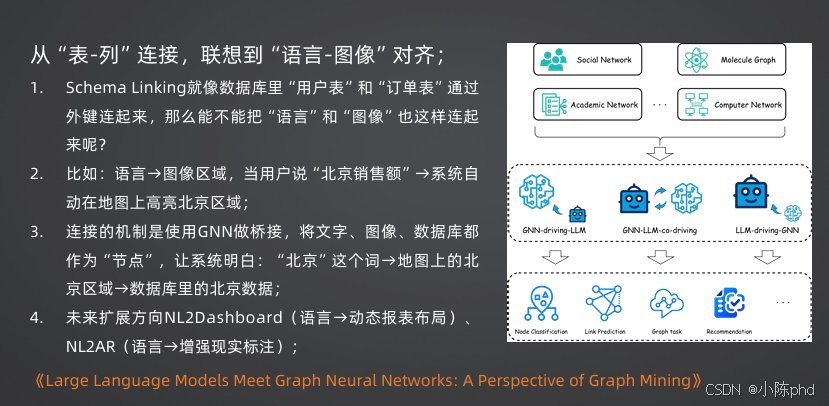
- 多模态扩展:从NL2SQL演进到NL2Dashboard(自然语言生成动态报表)、NL2AR(自然语言生成增强现实标注)
- GNN与LLM深度融合:结合GNN的结构推理能力和LLM的语言理解能力,进一步提升复杂多表查询的准确率
- 自主智能体:NL2SQL智能体将能够自主理解业务需求、探索数据库结构、生成并优化SQL,甚至自动发现数据中的异常和洞察
在数据成为核心生产要素的今天,NL2SQL技术正在让数据真正流动起来,释放出巨大的商业价值。无论是中小企业的数据分析,还是大型企业的数字化转型,NL2SQL都将成为不可或缺的核心能力。