1.RAG是什么?
当前对于大部分人来说我们利用LLM都是进行AI搜索来帮助我们进行知识的获取与总结。
对于【AI ⼤模型】来说,它最擅⻓的是语义理解和⽂本总结,最不擅⻓的就是获取实时的信息。因为⼤模型的训练数据是有截⽌⽇期的!
对于【搜索引擎】来说,它最擅⻓的就是获取实时的信息,缺点是信息分散,每次都需要⼈为进⾏总结。
⼤模型与搜索引擎的结合,就是给 AI 配备了⼀个活字典,让 AI 可以随时进⾏查阅
但是 搜索引擎只能获取到公开在⽹络中的数据,⽽⽆法获取到⼀些本地数据,或企业内部的私有数据等 ,此时该 如何?
这是就可以使用到我们的 RAG--检索增强生成(Retrieval-augmented Generation)
当⽤⼾向 LLM 提问时, 系统⾸先在知识库(如公司内部⽂ 档)中进⾏语义搜索,找到最相关的内容,然后将这些内容和问题⼀起交给 LLM 来⽣成答案 。
与 AI 搜索类⽐, 本质是知识库改变了,从搜索引擎线上搜索改为了本地或私有知识库中搜索
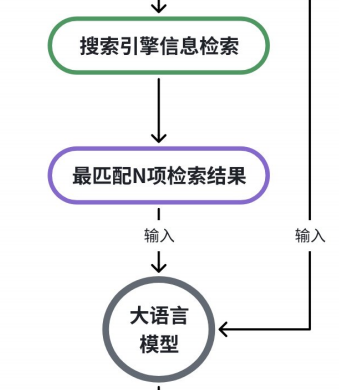
2.RAG流程
RAG 的流程分为【离线数据处理】和【在线检索】两个过程。
说明:RAG系列文章后续会一一介绍LangChain中实现RAG流程中相关组件的知识,本文仅为宏观见面,已完成的文章可通关下面相关链接点击跳转(均为博客文章),没有链接的为还在润色的文章,后续会更新。
RAG 知识库可以是本地⽂档、公司内部⽂档等⼀些私有化数据。但这些私有数据或⽂档实
际上并不能很好地被直接进⾏检索访问。因此需要将这些私有化数据构建成可以被检索的知识库,这就是离线数据处理要⼲的事情。经过离线数据后,知识则会按照某种格式以及排列⽅式存储在知识库中,等待被使⽤。
在线检索则是我们依赖知识库查询,通过⼤模型⽣成结果的过程
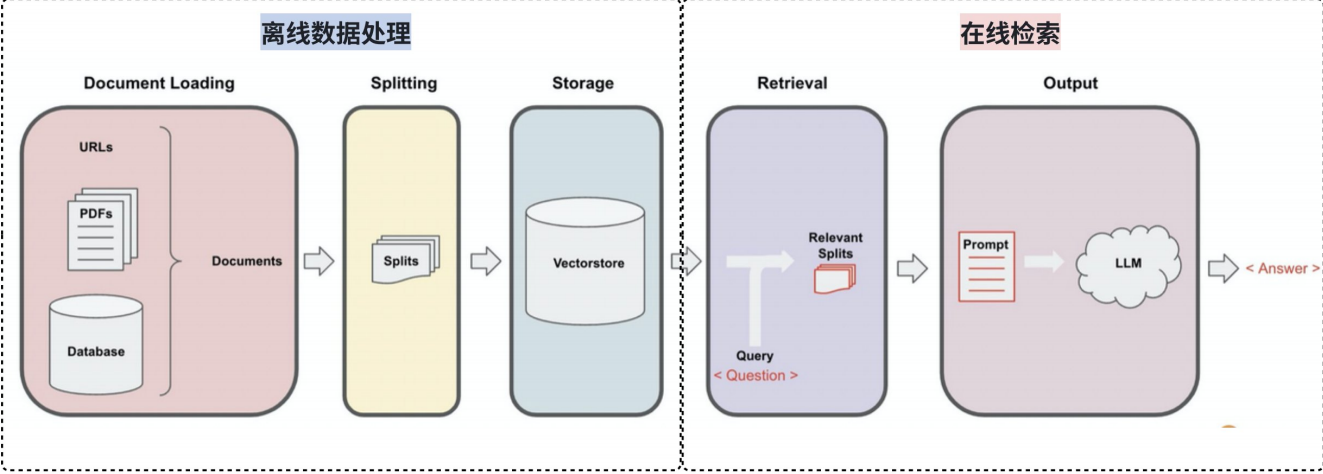
⽂档加载 (Document Loading):加载多种不同来源加载⽂档。LangChain 提供了 100 多种不同的⽂档加载器,包括 PDF 在内的⾮结构化的数据、SQL 在内的结构化的数据,以及 Python、Java 之类的代码等。
•
⽂本分割 (Splitting):⽂本分割器把 Documents 切分为指定⼤⼩的块。
•
存储 (Storage):存储涉及到两个环节,分别是:
(1)将切分好的⽂档块进⾏嵌⼊(Embedding),即将⽂档块转换成向量的形式。
(2)将 Embedding 后的向量数据,存储到向量数据库中。
•
检索 (Retrieval):数据存⼊向量数据库后。当我们需要进⾏数据检索时,会通过某种检索算法找到与输⼊问题相似的⽂档块。
•
输出 (Output):把问题以及检索出来的⽂档块⼀起提交给 LLM,LLM 会通过问题和检索出来的提⽰⼀起来⽣成更加合理的答案。
3.RAG效果案例
用一个租房项目的本地文件为知识库的一个案例演示。
python
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_redis import RedisConfig, RedisVectorStore
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
# 定义聊天模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客⼾端
redis_url = "redis://192.168.100.238:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# 定义 Redis 向量存储
vector_store = RedisVectorStore(embeddings, config=config)
# ⽣成检索器
retriever = vector_store.as_retriever()
# 定义提⽰词模板
prompt = ChatPromptTemplate.from_messages(
[
(
"human",
"""你是负责回答问题的助⼿。使⽤以下检索到的上下⽂⽚段来回答问题。如果你不知
道答案,就说你不知道。最多只⽤三句话,回答要简明扼要。
Question: {question}
Context: {context}
Answer:""",
),
]
)
# 将⽂档转换为字符串
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 定义链
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}| prompt| model| StrOutputParser()
)
# 循环输⼊问题
while True:
# 获取⽤⼾输⼊
question = input("\n请输⼊您的问题(输⼊'退出'或'quit'结束程序): ").strip()
# 检查是否退出
if question.lower() in ["退出", "quit"]:
print("程序已结束,再⻅!")
break
# 检查输⼊是否为空
if not question:
print("问题不能为空,请重新输⼊。")
continue
# 执⾏链,流式输出
print("回答: ", end="", flush=True)
chunks = []
for chunk in rag_chain.stream(question):
chunks.append(chunk)
print(chunk, end="", flush=True)
print() # 换⾏请输⼊您的问题(输⼊ ' 退出 ' 或 'quit' 结束程序) : 介绍⼀下这个项⽬
回答 : 这个项⽬是⼀个基于脚⼿架的微服务在线租房系统,旨在模仿⻉壳、安居客等流⾏应⽤,具备真 实的交互体验和架构设计。通过结合理论和实践,我在这个项⽬中加深了对 Java 编程语⾔的理解。这 个项⽬的灵感来源于我在⼤学时和同学合租的经历。
请输⼊您的问题(输⼊ ' 退出 ' 或 'quit' 结束程序) : 项⽬设计难点有哪些?
回答 : 项⽬设计的难点主要包括⾮技术⽅⾯的需求把控和技术⽅⾯的明确项⽬范围与⽬标。缺乏产品经理的介⼊使得设计过程中需⾃⾏绘制原型图并拆分功能,这增加了设计的复杂性。同时,测试和质量保证也是项⽬中的重要挑战,需要合理安排时间以确保项⽬质量。
请输⼊您的问题(输⼊ ' 退出 ' 或 'quit' 结束程序) : 介绍数据存储的相关设计
回答 : 数据存储的设计中,使⽤ MySQL 作为关系数据库管理系统,并结合 MyBatis 简化 SQL 操作。为了更好地应对⾼并发场景,设计了Redis 缓存⽅案来优化内存利⽤和减轻数据库压⼒。引⼊ OSS 对象存储是为了实现⽆限扩展性,相对于本地存储和MySQL ,它具备更⾼的性能和成本效益。
请输⼊您的问题(输⼊ ' 退出 ' 或 'quit' 结束程序) : 详细介绍 Redis 与 Mysql 数据⼀致性⽅案
回答 : Redis 与 MySQL 的数据⼀致性⽅案通常采⽤ " 双写⼀致性 " 模式,通过 Cache-Aside ⽅法实现。在这⼀⽅案中,应⽤程序在读取数据时先查询Redis 缓存,如果不存在再查询 MySQL 数据库,并将结果缓存到Redis 中;在更新数据时,需同时更新 MySQL 和 Redis ,以确保两者状态⼀致。此⽅法也包括设置 合理的缓存过期时间和使⽤布隆过滤器,以解决缓存穿透等问题。
请输⼊您的问题(输⼊ ' 退出 ' 或 'quit' 结束程序) :......