一、故障发现
1.1 问题现象
五一假期期间,生产环境出现订单消息消费严重积压的情况。通过RocketMQ监控仪表板发现,qnh-order-create-topic主题的消息消费速度异常缓慢,最新消息的业务订单创建时间order_create_time为2026-05-04 23:16:00,而实际MQ消费时间create_time为2026-05-06 10:48:37,消息积压时间长达两天。
1.2 监控数据
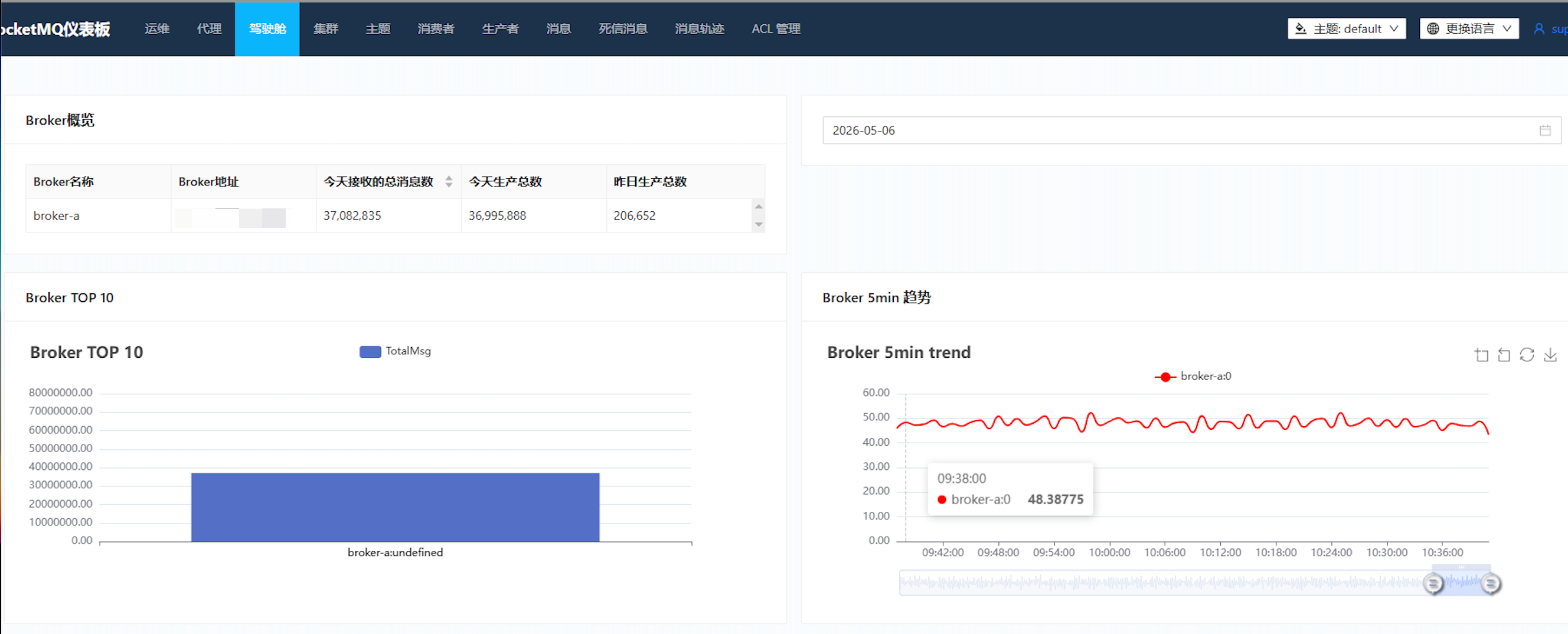
从RocketMQ仪表板可以看到关键数据:
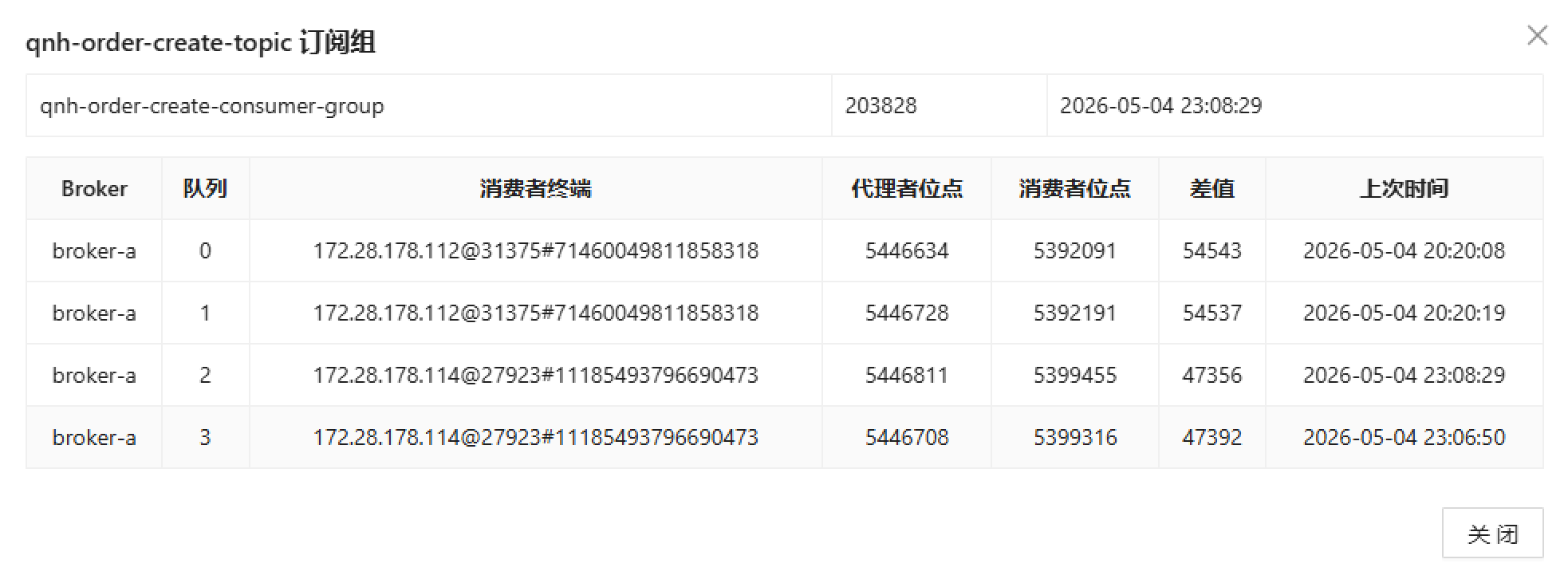
- 消息积压量 :消费者组
qnh-order-create-consumer-group的差值(积压量)达到数万条 - 消费进度:4个队列的消费者位点明显滞后于代理者位点
- qnh-order-create-topic :订单创建Topic 在本地消息表中查询到有积压二十多万条消息消费状态为
待消费状态 - 消费速度:SLS日志搜索区间30秒内仅消费63条消息,远低于业务需求
MQ所有主题监控:
qnh-order-create-topic主题: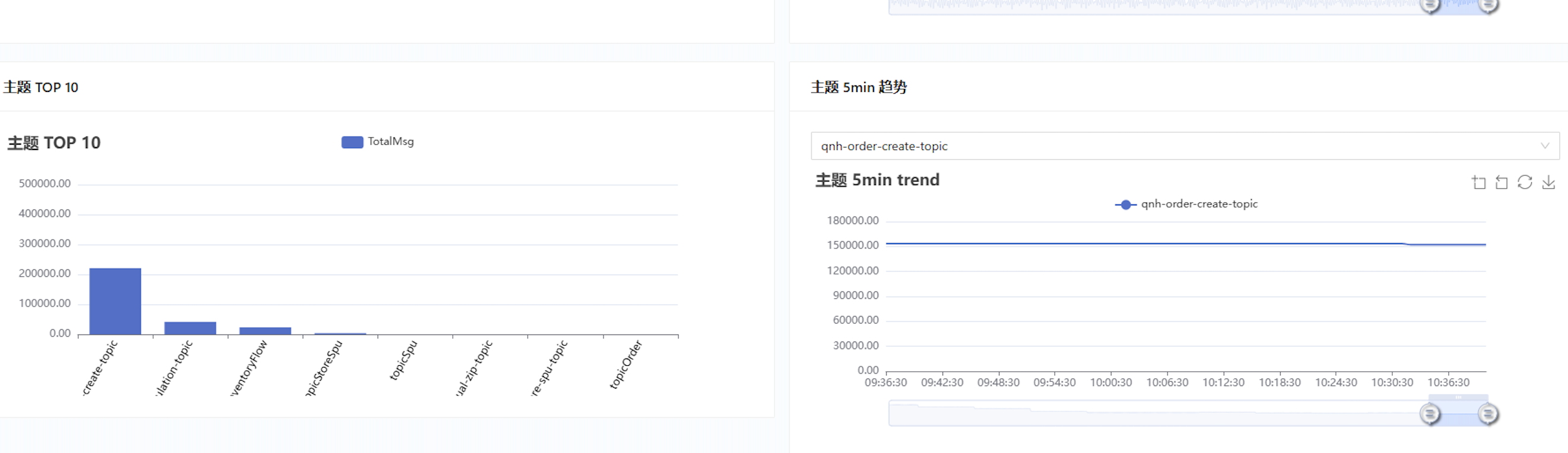
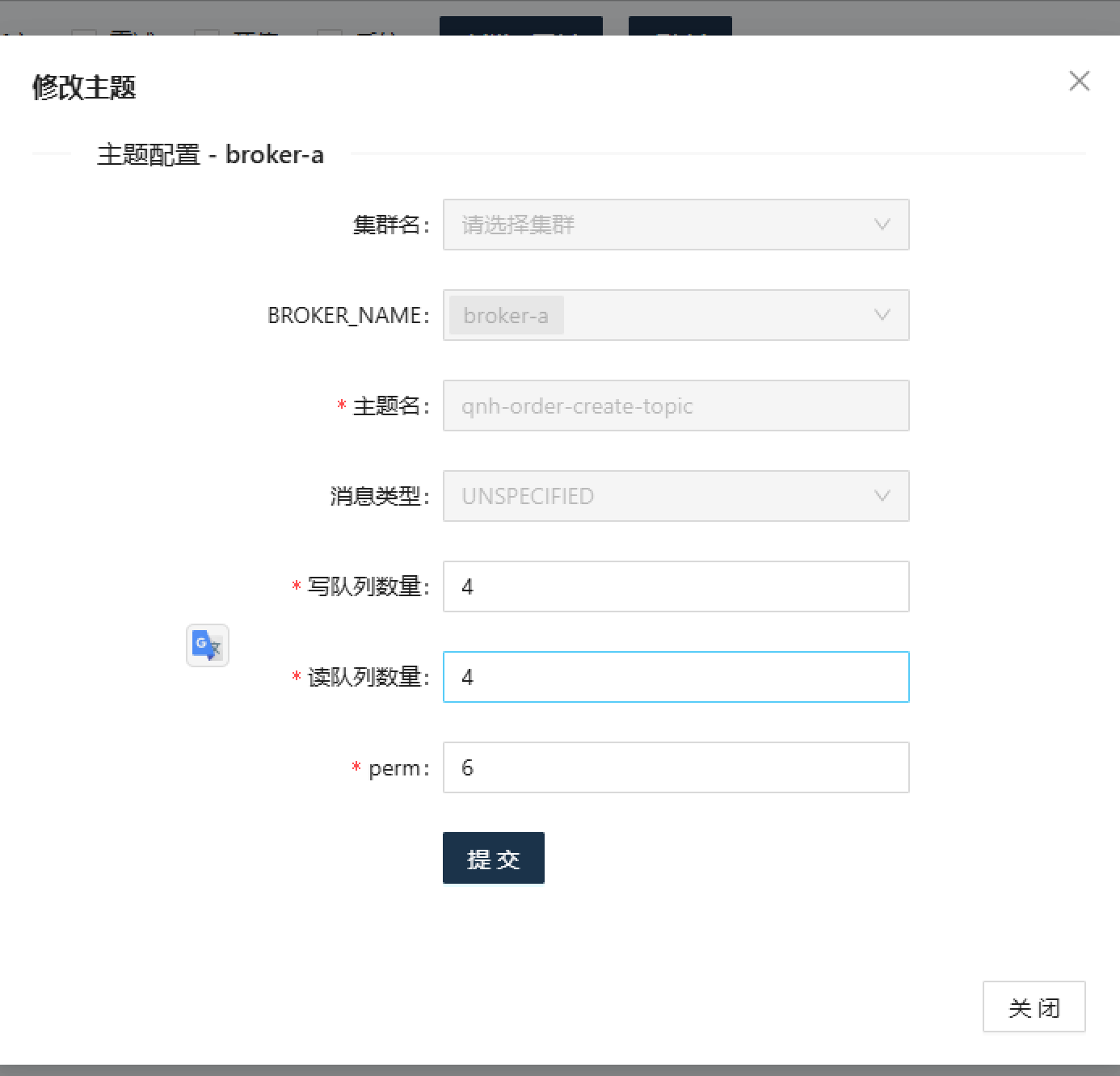
qnh-order-create-topic 主题队列配置:
qnh-order-create-topic 队列状态监控:
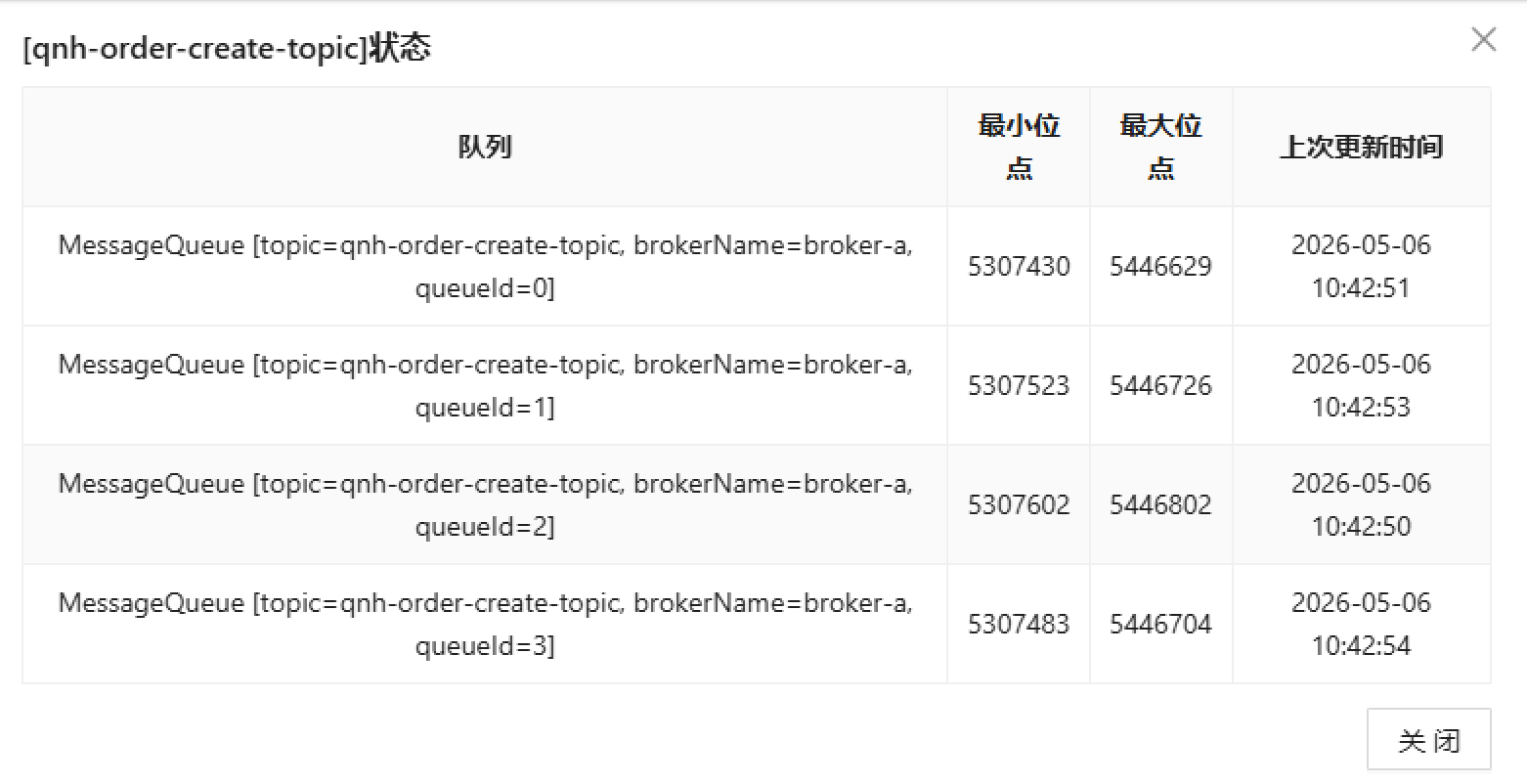
qnh-order-create-topic 消费进度监控:
二、环境架构分析
2.1 部署架构
生产环境部署情况:
- 服务器:两台阿里云8核16G机器(01和02)
- 应用部署 :两台机器均部署了
mtx业务系统,通过nginx负载均衡 - RocketMQ:01机器部署了RocketMQ 4.9的namesrv和broker(单节点)
2.2 环境信息
- RocketMQ版本:4.9
- 监控工具:rocketmq-dashboard
2.3 业务流程
订单消息的完整流转路径:
第三方订单平台(美团/京东/饿了么)→ 牵牛花接口 → mtx业务应用接收消息接口 → 线存入本地消息sync_notify_msg表 → 发送RocketMQ → 消费者 → 订单order_info表核心业务逻辑:消费者从MQ拉取消息后,消息内容只含有订单号和一些基础数据,订单详细信息,需要调用第三方牵牛花接口获取订单详情,然后插入或更新到数据库。
三、根因分析
3.1 架构层面瓶颈
1. Topic队列数不足
监控显示qnh-order-create-topic的读写队列数为4,RocketMQ中同一消费组对Topic的有效并行度上限约等于队列数。2台机器时每台约分到2个队列,严重限制了消费并行度。
2. 消费线程配置过低
MQ集群配置文件rocketmq-cluster.yml中:
consume-thread-min: 1consume-thread-max: 3
整体吞吐与节假日高峰完全不匹配。
大促活动业务方也没通知技术部门,合理流程是大促前需要通知技术部门进行准备的。
3.2 应用层面瓶颈
1. 同步HTTP调用耗时
每条消息处理都需要同步调用美团order/list或refundList接口获取订单详情,这是业务必需操作,但网络IO耗时较长,成为主要瓶颈。
2. N+1查询问题
在handleInsertScenario方法中,对每个订单都单独调用getWarehouseIdAndName(shop.getId())查询仓库信息,存在严重的N+1查询问题。
3. 过度日志输出
高频INFO日志输出全量body、完整requestBody、加密前参数字符串等,增加了IO开销。
3.3 框架层面问题
RocketMQAutoConfiguration.createConsumer中每条消息循环内都调用findMessageListener,存在不必要的开销。
四、解决方案
4.1 运维层面优化(P0)
1. 扩大Topic队列数重点
将qnh-order-create-topic的读写队列从4调整到16,提高集群并行度。
2. 调整消费线程数
在rocketmq-cluster.yml中修改配置:
yaml
qngOrderSync:
consume-thread-min: 8
consume-thread-max: 163. 资源监控
关注01机器(Broker+业务+Job同机)的堆内存、GC、磁盘IO,必要时错峰/限流Job任务。
4.2 代码层面优化(P1)
1. 解决N+1查询
在handleInsertScenario中:
- 收集所有涉及的
shop.getId() - 批量调用
iCenterWarehouseService获取CenterWarehouseRespDTO - 构建
Map<Long, CenterWarehouseRespDTO>,循环内O(1)赋值
2. 日志降级
- 不再默认打印全量body、完整requestBody
- 改为每条处理一条摘要,仅包含
msgId、orderId、耗时ms - 必要时仅DEBUG保留敏感或大字段
3. 添加队列观测日志
在生产者和消费者中增加queueId日志,便于测试环境核对路由:
生产者代码片段(示例,已脱敏):
java
// 实际Topic和Broker名称已脱敏
String topic = "your-order-topic";
String brokerName = "broker-a";
Integer queueId = null;
if (sendResult.getMessageQueue() != null) {
queueId = sendResult.getMessageQueue().getQueueId();
brokerName = sendResult.getMessageQueue().getBrokerName();
}
log.info("发送MQ结果成功,queueId={}, broker={}", queueId, brokerName);消费者代码片段(示例,已脱敏):
java
// 实际Topic名称已脱敏
String targetTopic = "your-order-topic";
if (targetTopic.equals(config.getTopic())) {
log.info("消费消息 topic={}, queueId={}, broker={}, msgId={}",
config.getTopic(), message.getQueueId(), "broker-x", // Broker名称已脱敏
message.getMsgId());
}4.3 可选优化(P2)
1. 调整pullBatchSize
在RocketMQAutoConfiguration创建DefaultMQPushConsumer处设置更大的pull批次,但当前consume-message-batch-max-size: 1,主要瓶颈仍在HTTP调用,预期收益有限。
2. Listener缓存
缓存MessageListenerConcurrent的listener引用,减少循环内的查找开销。
五、顺序语义分析与处理
5.1 现状分析
当前实现既不保证同一订单进同一队列,也不保证队列内严格FIFO业务顺序:
- 发送端 :延迟发送走
DefaultMQProducer.send(Message),由客户端默认队列选择策略(轮询)挑队列 - 消费端 :
CONCURRENTLY并发消费+多线程,两条消息即使在同一队列也可能被不同线程并行处理
5.2 乱序处理策略
采用策略A:业务侧顺序无关:
消费代码processOrdersUnderLock中:
getOrderByIds后无记录则走handleInsertScenario(新增)- 有记录则走
handleUpdateScenario(更新)
即使出现"更新先于创建"的情况:
先消费的更新消息,库中尚无订单 → 走新增路径后续创建消息到达时,库中已存在订单 → 走更新路径
通过"库内是否存在订单"这一事实自动纠正消费顺序,不必依赖MQ全局顺序。
但为了后续消息能落在同一个队列,我们这里还是写了一个消息顺序到同一个队列的方法。
java
/**
* 与顺序发送一致的哈希选队列策略:idx = |hash(shardingKey)| % mqs.size()。
* <p>
* 在<strong>当前 Topic 路由稳定</strong>(队列数、Broker 拓扑一段时间内不变)时,同一 shardingKey 会稳定落到同一队列。
* 若将读写队列从例如 4 扩到 16,取模底数变化,同一订单号映射到的 queueId 可能变化,属预期现象;
* 扩展完成后在新队列数下会重新稳定,不要求跨「扩缩容前后」保持同一 queueId。
*/
private static final MessageQueueSelector ORDER_HASH_SELECTOR = (mqs, m, arg) -> {
String key = String.valueOf(arg);
int idx = Math.abs(key.hashCode()) % mqs.size();
return mqs.get(idx);
};延迟消息+根据订单ID取模队列数 发送消息
java
/**
* 延迟 + 顺序哈希选队列:同时设置 {@link Message#setDelayTimeLevel(int)} 与 {@link DefaultMQProducer#send(Message, MessageQueueSelector, Object)},
* 适用于 RocketMQ 4.9 需「延迟级别 + 按业务键固定队列」的场景。
*
* @param moduleName 模块名(对应 yml 中的 producer 所属模块)
* @param topic Topic
* @param tag Tag
* @param messageBody 消息体
* @param messageKey 消息 Key(检索用,可与 shardingKey 不同)
* @param levelEnum 延迟级别枚举
* @param shardingKey 选队列键(如同一牵牛花 order_id),相同键落到同一队列
*/
public SendResult sendDelayOrderMessage(String moduleName, String topic, String tag, String messageBody, String messageKey,
RocketMQDelayLevelEnum levelEnum, String shardingKey) {
try {
DefaultMQProducer producer = autoConfiguration.getProducer(moduleName);
if (producer == null) {
throw new IllegalStateException("RocketMQProducer not found for module=" + moduleName);
}
Message msg = new Message(topic, tag, messageBody.getBytes(StandardCharsets.UTF_8));
if (messageKey != null) {
msg.setKeys(messageKey);
}
msg.setDelayTimeLevel(levelEnum.getLevel());
MqTraceIdSupport.copyMdcToUserProperties(msg);
return producer.send(msg, ORDER_HASH_SELECTOR, shardingKey);
} catch (Exception e) {
log.error("RocketMQ发送延迟顺序消息失败, topic={}, tag={}, shardKey={}, level={}", topic, tag, shardingKey,
levelEnum != null ? levelEnum.getLevel() : null, e);
throw new RuntimeException(e);
}
}5.3 扩容注意事项
- 队列数宜只增不减:扩容后短暂rebalance属正常。
- 历史消息位置固定:扩容前已写入Broker的积压消息永久绑定在原QueueId,不会"搬家"。
- 新消息路由策略 :扩容后新发送的消息路由取决于生产者的队列选择策略。若使用默认轮询策略,消息会均匀分配到所有队列(包括新增的);若使用基于Key的哈希策略,则消息仍只路由到哈希值对应的队列子集,可能无法立即利用所有新队列。需要评估生产者配置以确保扩容效果。
- 顺序无关性:由于采用业务幂等设计,新旧消息混合消费不会影响最终一致性。
六、验证指标
6.1 监控指标
- Dashboard:各队列Diff(lag)是否持续下降;两台客户端Last Time是否接近
- 应用日志:单条处理总耗时及HTTP/DB分段耗时
- 数据库:批量插入与批量仓库查询是否减少慢查询
6.2 改造效果
改造前后对比:
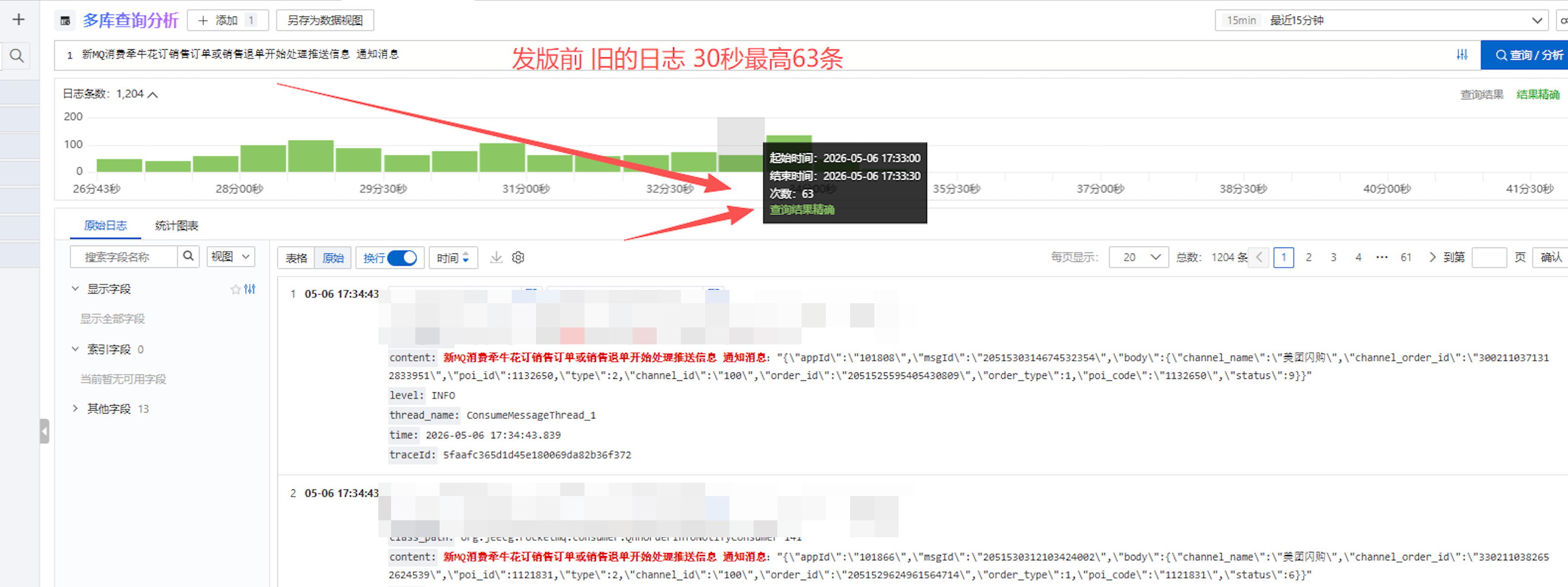
-
改造前 :30秒内消费63条消息
-
改造后 :30秒内消费482条消息
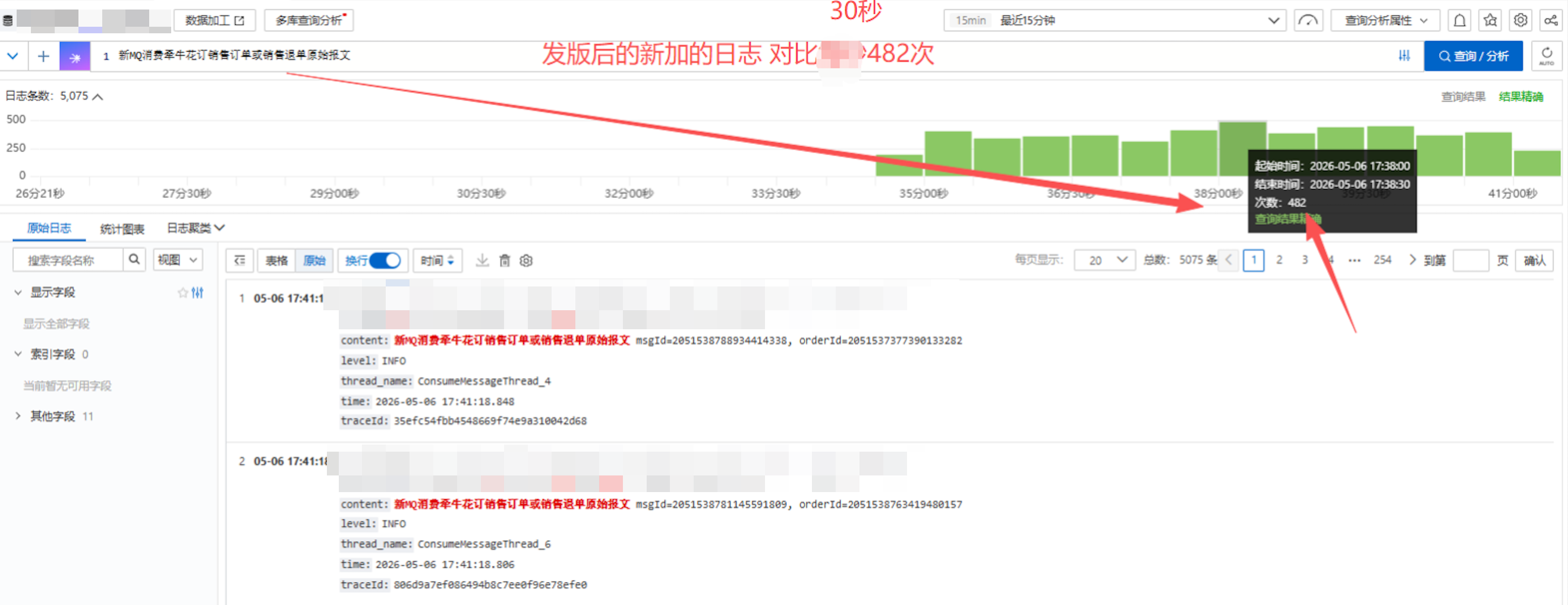
消费速度提升约7.6倍,有效解决了消息积压问题。
七、总结与经验
7.1 关键收获
- 队列数是并行度的天花板:RocketMQ中消费并行度上限约等于队列数,需根据业务峰值合理配置
- 消费线程数需要调优:默认配置往往无法满足高并发场景,需根据服务器资源动态调整。
- N+1查询是大敌:批量查询+Map缓存是解决N+1问题的标准模式。
- 日志需分级控制:生产环境应避免输出大量调试信息,改为摘要日志。
- 业务幂等比MQ顺序更可靠:通过数据库状态判断比依赖MQ顺序更健壮。
7.2 后续规划
- 持续监控消费速度和积压情况。
- 根据业务增长评估是否需要进一步扩容。
- 考虑引入APM工具进行全链路性能监控。
- 评估是否需要实现Hash发送+顺序消费(当前阶段不实施)。