深度解析 go2_rl_gym:从 IsaacGym 仿真到真实 Go2/Vbot 四足机器人的 MoE-CTS 强化学习框架
项目地址:https://github.com/Robot-Nav/vbot_rl_gym
论文参考:https://arxiv.org/html/2602.00678v4;https://arxiv.org/html/2405.10830v2
1. 项目概述
本项目是基于 NVIDIA IsaacGym 的四足机器人(Unitree Go2)强化学习训练框架,支持多种训练算法(PPO、CTS、MoE-CTS 等),实现了从仿真训练到实机部署的完整闭环。
核心能力:
- 在 IsaacGym GPU 并行仿真环境中训练足式机器人运动策略(8192 个并行环境)
- 支持多种地形(波浪、斜坡、楼梯、障碍物等)的课程学习与域随机化
- 实现高效的 Sim-to-Real 迁移,在雪地、沙地、30cm 障碍物上表现鲁棒
- 提供从模型导出、MuJoCo 验证到真实 Go2 机器人部署的完整工具链
2. 项目结构
go2_rl_gym/
├── legged_gym/ # 仿真环境与训练入口
│ ├── envs/
│ │ ├── base/ # 基类
│ │ │ ├── base_config.py # 配置基类(递归初始化成员类)
│ │ │ ├── base_task.py # RL任务基类(IsaacGym环境管理)
│ │ │ ├── legged_robot.py # 足式机器人核心环境
│ │ │ └── legged_robot_config.py # 足式机器人配置体系
│ │ └── go2/ # Go2机器人专用
│ │ ├── go2_env.py # Go2环境(重写观测/奖励)
│ │ ├── go2_config.py # 主配置
│ │ ├── go2_config_vanilla.py
│ │ ├── go2_config_fast_flat_move.py
│ │ └── go2_config_vanilla_with_dynamic_cmd.py
│ ├── scripts/
│ │ ├── train.py # 训练入口
│ │ └── play.py # 推理入口
│ └── utils/
│ ├── helpers.py # 参数解析/配置工具
│ ├── terrain.py # 地形生成器
│ ├── math.py # 数学工具
│ ├── isaacgym_utils.py
│ ├── task_registry.py # 任务注册器
│ ├── exporter.py # JIT模型导出
│ └── logger.py
├── rsl_rl/ # 强化学习算法库
│ └── rsl_rl/
│ ├── algorithms/ # 算法实现
│ │ ├── ppo.py
│ │ ├── cts.py
│ │ ├── moe_cts.py
│ │ ├── moe_ng_cts.py
│ │ ├── mcp_cts.py
│ │ ├── ac_moe_cts.py
│ │ └── dual_moe_cts.py
│ ├── modules/ # 神经网络模块
│ │ ├── actor_critic.py
│ │ ├── actor_critic_cts.py
│ │ ├── actor_critic_moe_cts.py
│ │ ├── actor_critic_moe_ng_cts.py
│ │ ├── actor_critic_mcp_cts.py
│ │ ├── actor_critic_ac_moe_cts.py
│ │ ├── actor_critic_dual_moe_cts.py
│ │ ├── actor_critic_recurrent.py
│ │ └── utils.py # MLP/MoE/L2Norm/SimNorm
│ ├── runners/ # 训练循环
│ │ ├── on_policy_runner.py
│ │ └── on_policy_runner_cts.py
│ ├── storage/ # 经验回放
│ │ ├── rollout_storage.py
│ │ └── rollout_storage_cts.py
│ └── env/
│ └── vec_env.py
├── deploy/ # 部署
│ ├── deploy_mujoco/ # MuJoCo仿真部署
│ │ ├── deploy_go2.py
│ │ ├── utils.py
│ │ └── configs/go2.yaml
│ └── deploy_real/ # 真实机器人部署
│ ├── deploy_real_go2.py
│ ├── config_go2.py
│ ├── common/ # 通信/遥控工具
│ └── configs/go2.yaml
├── resources/ # 机器人模型资源
│ └── robots/go2/ # Go2 URDF/MJCF/网格
├── vbot/ # 赛道环境模型
└── tools/ # 日志压缩/合并工具关键目录说明:
legged_gym/envs/go2/:Go2 机器人的环境实现与多套配置(fast_flat_move 用于高速平地训练,vanilla 用于消融实验)rsl_rl/algorithms/:实现了从 PPO 到 MoE-CTS 等 7 种算法变体,方便对比研究deploy/:分为 MuJoCo 仿真预部署和真实机器人部署,确保迁移前的充分验证
3. 深入解析:从 PPO 到 MoE-CTS 的算法演进
如果说 Isaac Gym 提供了强大的"物理引擎",那么强化学习算法就是赋予机器人"智能"的灵魂。本项目实现了从标准的 PPO 到更高级的 CTS,再到 MoE-CTS 的完整算法演进路径。
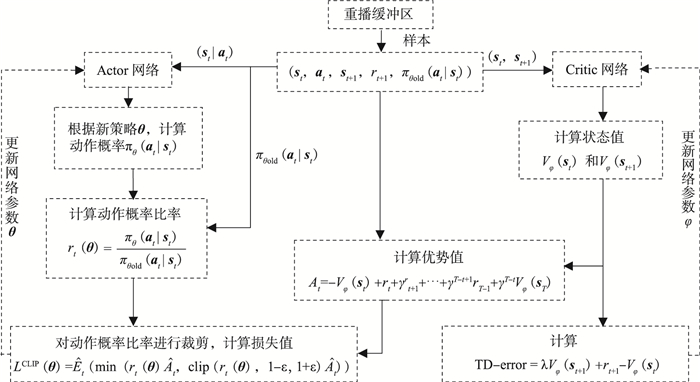
3.1 基线算法:PPO
PPO 是目前连续控制任务中最主流的策略优化算法之一。其核心思想是通过"裁剪"来限制策略更新的幅度,从而保证训练的稳定性。核心公式为:
-
裁剪代理目标 :
L = -min(r·A, clip(r, 1-ε, 1+ε)·A)其中
r = π_new(a|s) / π_old(a|s),优势A采用 GAE 估计,裁剪参数ε = 0.2。 -
GAE(Generalized Advantage Estimation) :
δ_t = r_t + γ·V(s_{t+1}) - V(s_t)A_t = Σ_{l=0}^{∞} (γλ)^l · δ_{t+l},折扣因子γ = 0.99,GAE 参数λ = 0.95。
本项目在此基础上还引入了 KL 散度自适应学习率机制:当策略更新后的 KL 散度超过目标值(0.01)的两倍时自动降低学习率,低于目标值的一半时则提高学习率,从而在训练全程维持最优的更新步长。
- 网络结构 :
- Actor:
obs → [512, 256, 128] → action_mean,加可学习标准差构成高斯分布 - Critic:
obs → [512, 256, 128] → 1
- Actor:
PPO算法框图:
3.2 并行师生强化学习:CTS
PPO 虽然在仿真中表现出色,但在部署到真实机器人时面临一个根本性的问题:输入差异 。仿真训练时,我们可以获取线速度、地形高度等"特权信息",但在真实机器人上,我们通常只能依赖本体感知。为了解决这一困境,项目实现了 Concurrent Teacher-Student 范式。如下图:
CTS学习框架:
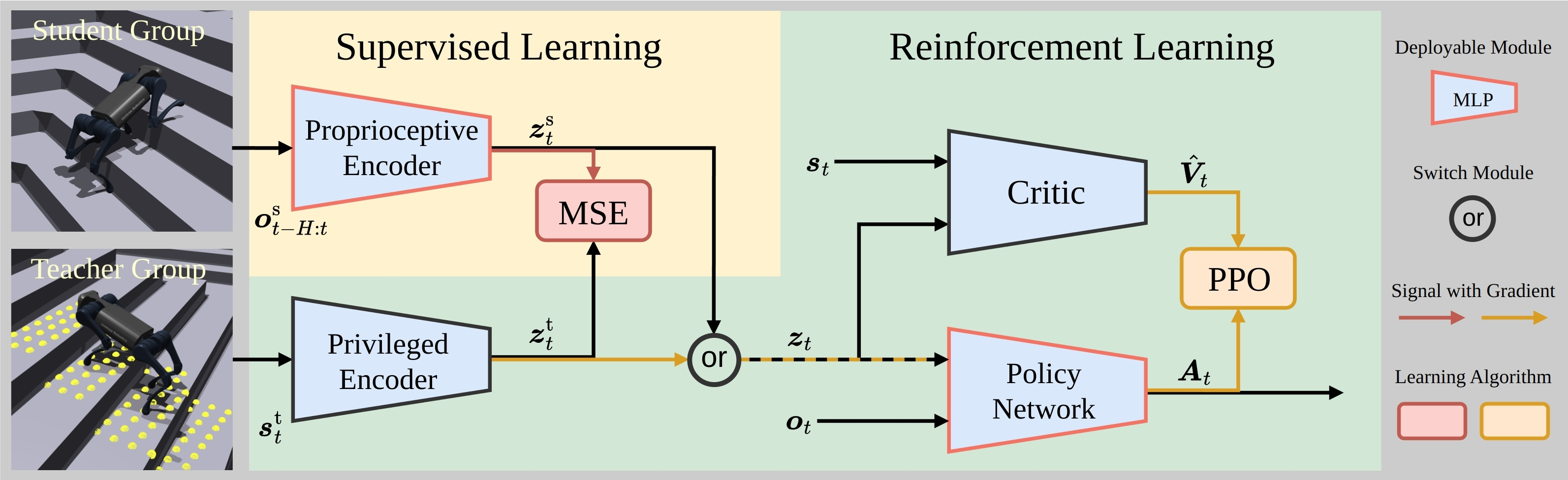
在传统知识蒸馏(三阶段训练)中,需要先训练一个 Teacher 策略,固定 Teacher 权重后用监督学习训练 Student,Student 只能被动"模仿"。CTS 的创新之处在于 并行机制:在同一个 RL 循环中,Teacher 和 Student 同时进行梯度更新,使 Student 不再是单纯的模仿者,而是通过 RL 损失主动探索------如果 Student 通过自身编码的潜在表示能获得更高回报,它自然向 Teacher 的潜在空间靠拢,从而实现更高效的知识迁移。其核心架构如下:
Teacher分支: privileged_obs → Teacher_Encoder → latent_t ─┐
├→ [latent, obs] → Actor → action
Student分支: obs_history → Student_Encoder → latent_s ─────┘
↑ 蒸馏对齐(MSE)- Teacher 网络:接收包含线速度、地形高度、足底力等的"特权观测"(约 263 维),将其编码为一个低维的"隐状态"(latent)。(PS:"特权信息"是训练时,直接从物理仿真引擎内部获取的一系列精准状态值,包括地形的精确高度图、摩擦力、恢复系数以及机器人的精准惯性参数)
- Student 网络:仅接收纯本体感知的历史观测序列(约 45 维),同样尝试编码出一个相似的隐状态。
- Actor 网络:将最终隐状态与本体观测拼接,输出动作。
- Critic 网络:专门评估状态的价值,为策略更新提供基线。
关键机制:
- 环境划分:约 75% 的环境执行 Teacher 分支,25% 的环境执行 Student 分支。
- 双优化器 :
optimizer1更新 Teacher 编码器 + Critic + Actor(PPO 策略梯度)optimizer2更新 Student 编码器(MSE 蒸馏损失)
- 两阶段更新 :
- PPO 策略梯度更新(融合 Teacher 和 Student 的 surrogate loss)
- 蒸馏更新:
L_distill = MSE(latent_t, latent_s)
- Student 推理时 detach:Student 的 latent 在送入 Actor 前 detach,防止梯度回传干扰蒸馏过程
- Critic 使用 Teacher latent:保证价值估计的准确性
这种设计使得 Student 能够从有限的观测中,自动"想象"出足够丰富的环境信息,进而在实机部署时仅依赖本体感知就能表现出鲁棒的运动能力。
💡 延伸解惑:为何仅凭本体感知就能走复杂地形?
3.2 节展示了 CTS 如何通过并行师生框架实现从特权信息到本体感知的知识迁移,但一个更根本的问题仍然悬而未决:仅凭本体感知,监督学习真的能让四足机器人在复杂地形上稳健运动吗?为什么可以?
(1) "闭眼"走天下:本体感知的"感受→推断"能力
这一问题的肯定答案,已在实际部署中得到了充分验证。搭载本框架的 Unitree Go2 机器人,仅依赖 IMU 和关节编码器的本体感知信息,就能够在雪地、沙地、楼梯、坡道和高达 30 cm 的障碍物等多种复杂地形上稳健运动,高速测试中更达到了 4 m/s 的奔跑速度,并涌现出与高速度稳定性相关的前所未见的窄步态模式。CTS 论文的定量仿真比较也表明,该方法可将不平地形上的平均速度跟踪误差最多降低 20%,在解决盲走任务方面具有显著优势。
这一结果的背后,是以下两个层面的机制共同作用:
- 本体感知的信息含量:机器人所谓的"本体感知"通常包含一个基础组合------IMU 提供身体的三轴加速度和角速度,感知自身姿态和运动;关节编码器精确记录每个关节的当前角度、速度和力矩。通过对这些信息的时序变化进行分析,算法可以推断出地形的起伏、地面的摩擦系数等关键动态特征。
- 从"感受"到"学习":CTS 通过并行师生框架,让学生网络不仅被动模仿教师的动作输出,更在 RL 目标的引导下主动探索------如果学生通过自身编码的潜在表示能获得更高回报,它自然向教师的潜在空间靠拢。这种"RL 目标 + 监督对齐"的双重驱动,使得学生即便只有有限的本体感知输入,也能高效地"想象"出足够丰富的环境状态。
(2) "信息不对称"并非阻碍,而是设计的起点
监督学习本身面临一个核心挑战------信息不对称 。教师网络在训练时拥有完整地形、接触力等"上帝视角"的特权信息,而学生网络只能依靠有限的本体感知数据。这种信息差距会导致 表征错位(Representation Misalignment) ,即学生学到的特征表示与教师不匹配,从而影响泛化能力。
为解决这一难题,学术界与工业界探索了多种策略:
| 方法/概念 | 核心思想 |
|---|---|
| 并行训练 | CTS 的核心创新------让师生网络在同一强化学习框架下同时训练和进化,而非传统两阶段式的被动蒸馏。 |
| 表征对齐 | 通过 MSE 蒸馏损失刻意拉近学生隐状态与教师隐状态,弥合"感知"差距。CTS 采用 L2 归一化将隐状态映射到单位超球面,进一步提升对齐稳定性。 |
| 数据增强与混合训练 | 通过随机化动力学参数、混合短期专家和长期学生数据的训练方式,增强学生网络应对未知情况的鲁棒性。本框架的域随机化模块(摩擦系数 0.0, 2.0、电机强度 0.8, 1.2 等)正是这一思想的体现。 |
(3) 量化保障:RoboGauge 评估套件
即使有了 CTS 这样强大的架构,如何在没有实机测试的情况下可靠地评估 Sim-to-Real 迁移性能,仍然是一个关键挑战。为此,相关论文提出了 RoboGauge 评估套件。
RoboGauge 并非传统的仿真评估,而是多角度的 Sim-to-Sim 压力测试 。它通过将训练好的策略放置在从未见过的地形 (7 种地形 × 10 个难度级别)上,同时叠加多种域随机化参数(4 种域随机化 × 3 个优化目标),形成一个多维度评分体系,最终输出一个综合的 Transferability Score。该分数在论文中被证实与真实世界部署的成功率呈高度正相关,从而为策略选择提供了可靠的量化依据,显著减少了在真实机器人上进行昂贵且具破坏性的物理实验的需求。
3.3 引入混合专家:MoE-CTS
尽管 CTS 极大地缩小了仿真与现实的差异,但其单一的编码器结构在应对多样化的地形时,可能会发生 "特征纠缠" ------不同地形特征在同一个隐空间中互相干扰,导致策略需要同时适应相互冲突的需求。为此,项目将 CTS 中的 Student 编码器升级为 Mixture-of-Experts。
MoE-CTS框架图:
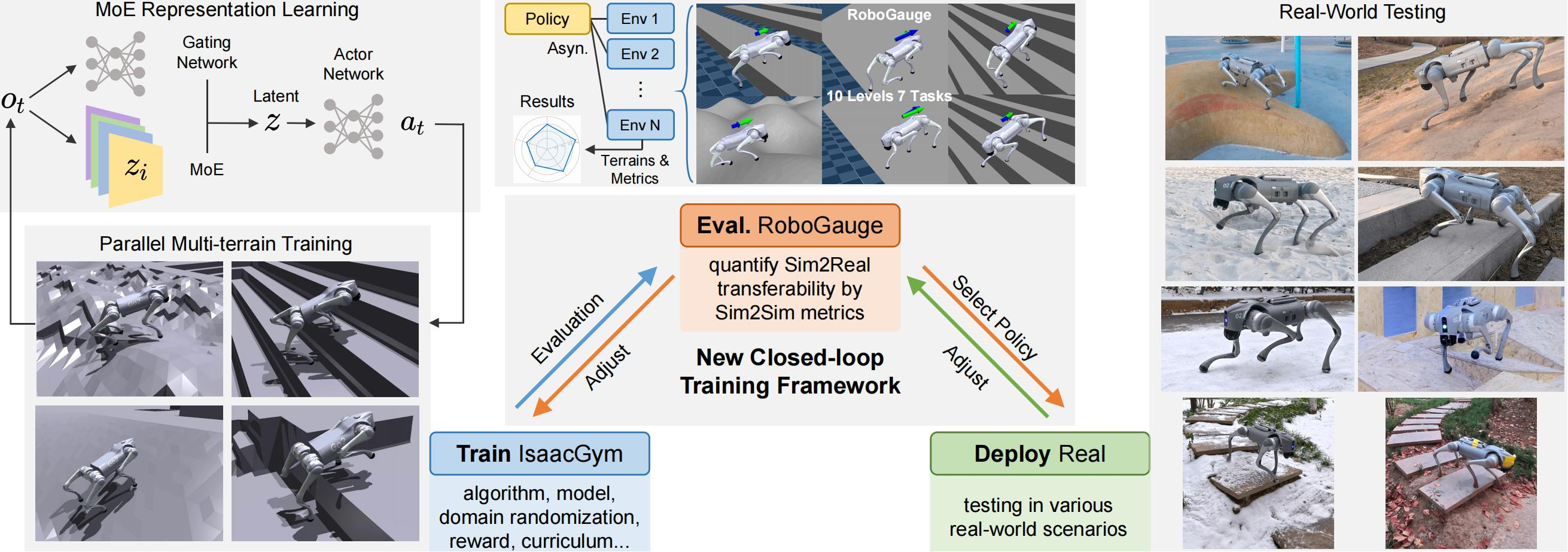
MoE 的核心思想是"术业有专攻":与其使用一个庞大的网络去学习所有地形和运动模式,不如将任务分解成若干子任务,每个"专家"网络专注于处理特定的场景,由一个轻量级的"门控网络"根据当前输入决定激活哪些专家。
MoE 架构:
输入 → Gating_Network → weights (N个专家的权重)
输入 → Experts → expert_outs (N个专家的输出)
output = Σ(weights_i × expert_outs_i)本项目中 MoE 的实现细节体现了对足式机器人的深度定制:专家特征并非凭空产生,而是先通过一个 共享的 MLP Backbone 提取通用运动特征,再经由每个专家独立的 1×1 卷积 进行差异化处理。这是考虑到四足运动的不同模式(如爬行、慢走、小跑)对输入特征的"重用方式"不同而非"特征本身"不同,用 1×1 卷积进行通道级线性变换即可实现这种重用模式的调整,比独立 MLP 更轻量、更高效。
负载均衡损失:
python
mean_usage = mean(gating_weights, dim=batch) # 每个专家的平均使用率
target_usage = 1/N
L_balance = MSE(mean_usage, target_usage)为了防止在训练 MoE 的过程中所有专家趋同(即"模式坍缩"),引入该损失函数,通过促进专家使用的平衡来保证专家多样性。通常系数设为 0.01。
Student 总损失 :
L_student = L_distill + λ_balance × L_balance
3.4 算法继承链:PPO → CTS → MoE-CTS
MoE-CTS 并非全新算法,而是完全基于 PPO 的多层改进。其继承关系与核心差异可用下表清晰概括:
| 算法 | 网络架构 | 优化器 | 环境分配 | 额外损失 |
|---|---|---|---|---|
| PPO | 单一 Actor-Critic | 单优化器 | 全部相同 | 无 |
| CTS | Teacher + Student 双编码器 | 双优化器(RL + 蒸馏) | 75% Teacher / 25% Student | MSE(latent_t, latent_s) |
| MoE-CTS | Teacher + MoE-Student 编码器 | 双优化器(RL + 蒸馏) | 75% Teacher / 25% Student | MSE(latent_t, latent_s) + λ·L_balance |
具体分析:
-
PPO → CTS 的增量 :
CTS 在 PPO 的基础上增加了 Teacher-Student 双分支结构、环境划分、双优化器以及蒸馏损失。其策略更新部分(裁剪、GAE、KL 自适应)与 PPO 完全相同。
-
CTS → MoE-CTS 的增量 :
MoE-CTS 继承自 CTS,仅将 Student 编码器从普通 MLP 替换为混合专家(MoE)编码器,并额外增加了负载均衡损失以防止专家坍缩。核心 PPO 更新逻辑未作任何改动。
三层改进关系总结:
PPO: Actor(obs) → action, Critic(obs) → value
策略梯度 + 裁剪 + GAE
CTS = PPO + Teacher-Student蒸馏
Teacher: privileged_obs → Encoder → latent_t
Student: obs_history → Encoder → latent_s
Actor: [latent, obs] → action
额外损失: MSE(latent_t, latent_s)
MoE-CTS = CTS + 混合专家Student
Student: obs_history → MoEEncoder → latent_s + gating_weights
额外损失: MSE(latent_t, latent_s) + load_balance_loss结论:MoE-CTS 的策略更新部分就是标准 PPO,只是网络架构从单编码器升级为 Teacher + MoE-Student 双分支,并在 PPO 损失之外叠加了蒸馏损失和负载均衡损失。
3.5 全面评估:RoboGauge
即使有了 MoE-CTS 这样强大的策略,如何在没有实机测试的情况下可靠地评估其 Sim-to-Real 迁移性能,仍然是一个关键挑战。为解决这一问题,相关论文中提出了 RoboGauge 评估套件。
RoboGauge评估架构图:
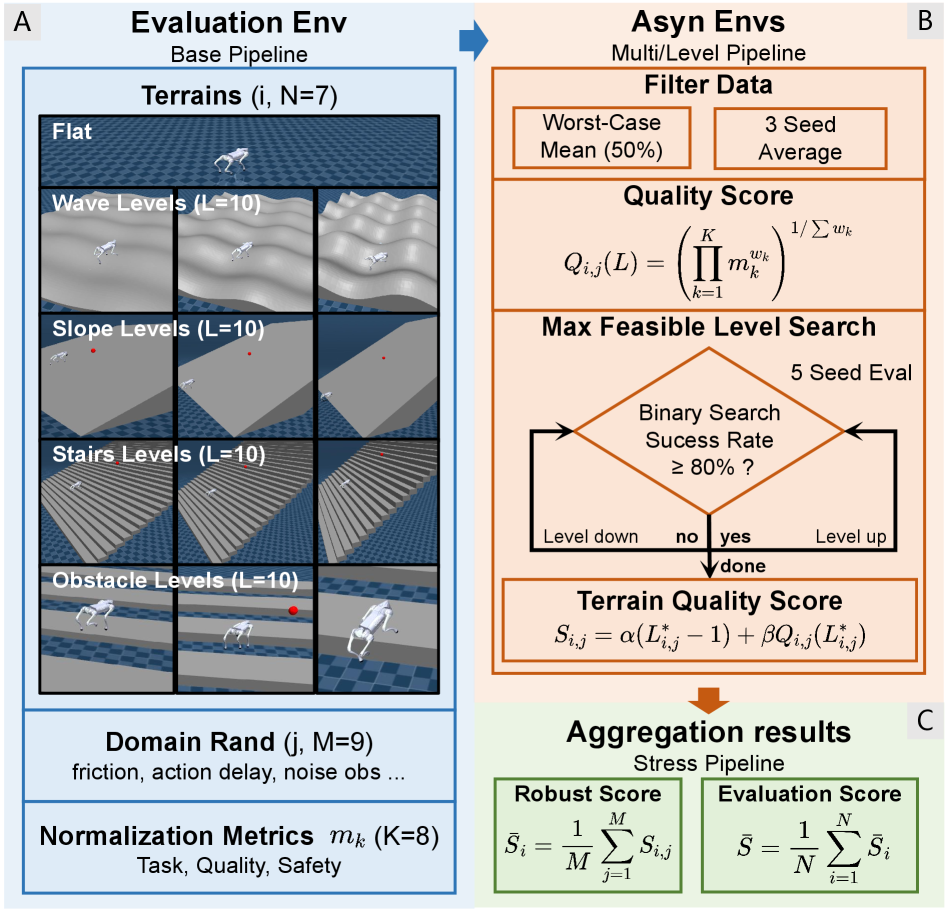
RoboGauge 并非传统的仿真评估,而是多角度的 Sim-to-Sim 压力测试 。它通过将训练好的策略放置在未见过的各种地形 和难度级别上,同时叠加多种域随机化参数,形成一个多维度评分体系,最终输出一个综合的"可迁移性"评估分数。其理念是:如果某个策略在仿真中的极端恶劣条件下(如地形极度粗糙、摩擦力极低、电机强度衰减等)都能表现得游刃有余,那么它迁移到真实世界的成功率将远高于仅仅在标准测试地形中表现优异的策略。这种预筛选机制显著减少了在真实机器人上进行昂贵且具破坏性的物理实验的需求。
RoboGauge 包含五个核心评估维度:
| 维度 | 说明 |
|---|---|
| 地形泛化性 | 在训练中未见过但结构相似的复杂地形上测试,计算平均成功率 |
| 速度跟踪误差 | 在不同命令速度下(尤其是训练范围外的外推速度)的跟踪误差 |
| 域随机化容忍度 | 在多种域随机化组合下测试,计算策略的"生存率"和"性能衰减曲线" |
| 抗干扰能力 | 定时施加脉冲型推力扰动,记录策略从扰动中恢复的时间与成功率 |
| 动作平滑度 | 分析动作序列的高频分量能量,预测真实机器人上的机械磨损和能耗 |
RoboGauge 最终通过加权合成一个 Transferability Score,该分数在论文中被证实与真实世界部署的成功率呈高度正相关,从而为策略选择提供了可靠的量化依据。
3.6 其他 MoE 变体
| 算法 | 特点 |
|---|---|
| MoE-No-Goal CTS | 门控网络不使用命令信息(即 obs_no_goal_mask),让门控仅依赖本体感受 |
| MCP-CTS | 修改门控机制的 CTS 变体,引入跨专家通信 |
| AC-MoE-CTS | Actor 和 Critic 均使用 MoE |
| Dual-MoE-CTS | Student 编码器和 Actor 均采用 MoE 架构 |
4. 环境设计详解
4.1 观测空间
Actor 观测(45 维,实机可用):
| 维度 | 内容 | 缩放 |
|---|---|---|
| 0:3 | 基座角速度 (body frame) | ×0.25 |
| 3:6 | 重力投影方向(IMU 等价) | 无 |
| 6:9 | 速度命令 (vx, vy, wyaw) | ×obs_scales |
| 9:21 | 关节位置偏差 (12 关节) | ×1.0 |
| 21:33 | 关节速度 (12 关节) | ×0.05 |
| 33:45 | 上一步动作 (12 关节) | 无 |
Critic 特权观测(263 维,仅仿真用):
| 维度 | 内容 |
|---|---|
| 0:45 | Actor 观测 |
| 45:48 | 基座线速度 (body frame) |
| 48:52 | 足端接触力 (4 脚) |
| 52:64 | 电机力矩 (12 关节) |
| 64:76 | 电机加速度 (12 关节) |
| 76:263 | 地形高度扫描(187 点) |
4.2 动作空间
- 12 维连续动作,对应 12 个关节的位置偏移
target_pos = action × action_scale + default_angles,action_scale = 0.25- PD 控制器:
torque = Kp×(target_pos - q) + Kd×(0 - dq)
4.3 奖励函数
| 奖励项 | 权重 | 说明 |
|---|---|---|
| tracking_lin_vel | +1.0 | 线速度跟踪:`exp(- |
| tracking_ang_vel | +0.5 | 角速度跟踪:`exp(- |
| lin_vel_z | -2.0 | 惩罚 Z 轴速度 |
| ang_vel_xy | -0.05 | 惩罚俯仰/横滚角速度 |
| dof_acc | -2.5e-7 | 惩罚关节加速度 |
| dof_power | -2e-5 | 惩罚关节功率 |
| torques | -1e-4 | 惩罚力矩 |
| correct_base_height | -1.0 | 惩罚基座高度偏离 0.38m |
| action_rate | -0.01 | 惩罚动作变化率 |
| action_smoothness | -0.01 | 惩罚二阶动作差分 |
| collision | -1.0 | 惩罚大腿/小腿碰撞 |
| dof_pos_limits | -2.0 | 惩罚接近关节限位 |
| feet_regulation | -0.05 | CTS 抬腿正则(高速时要求脚高) |
| hip_to_default | -0.05 | 髋关节回归默认角 |
动态 σ 机制:σ 根据命令速度和地形类型动态调整。例如低速平地 σ 小(精确跟踪),高速或复杂地形 σ 大(容忍误差)。这种设计避免了机器人在困难地形上因过度追求速度跟踪而摔倒。
课程学习奖励 :部分奖励权重随训练进度线性变化,如 lin_vel_z 从 -2.0 渐变到 0,correct_base_height 从 -1.0 渐变到 -10.0,使策略先学会运动再精细化姿态。
4.4 域随机化
| 随机化项 | 范围 | 说明 |
|---|---|---|
| 摩擦系数 | 0.0, 2.0 | 64 个摩擦桶随机分配 |
| 基座附加质量 | -1, 1 kg | 模拟负载 |
| 连杆质量倍率 | 0.9, 1.1 | 制造误差 |
| 基座质心偏移 | -0.03, 0.03 m | 质心偏差 |
| 恢复系数 | 0.0, 0.5 | 地面弹性 |
| PD 增益倍率 | 0.9, 1.1 | 执行器特性 |
| 电机零位偏移 | -0.035, 0.035 rad | 编码器误差 |
| 电机强度 | 0.8, 1.2 | 输出衰减 |
| 动作延迟 | 0~20 ms | 通信延迟 |
| 外力推扰 | 周期 4s | 鲁棒性训练 |
4.5 地形课程学习
地形类型(9 种):波浪、平滑坡、粗糙坡、上楼梯、下楼梯、障碍物、梅花桩、间隙、平地。
课程机制:
- 机器人走得远 → 升级到更难地形
- 机器人走得近 → 降级到更简单地形
- 降级判定基于累计命令距离(比基于存活步数更稳定)
命令课程:训练初期命令范围小(±0.5 m/s),逐步扩大到 ±2.0 m/s 甚至 ±4.5 m/s。
5. 训练流程
5.1 训练启动
bash
python legged_gym/scripts/train.py --task go25.2 训练循环
1. 初始化环境和策略网络
2. for iteration in range(max_iterations):
a. Rollout 采集(24 步/环境):
- 根据观测采样动作
- 执行仿真步进
- 存储转移 (obs, action, reward, done)
b. 计算 GAE 回报
c. PPO/CTS 更新:
- 多轮(mini-batch)梯度更新
- CTS 额外蒸馏 Student 编码器
d. 日志记录 + 定期保存模型5.3 关键训练参数
| 参数 | 值 | 说明 |
|---|---|---|
| num_envs | 8192 | 并行环境数 |
| num_steps_per_env | 24 | 每次迭代的仿真步数 |
| max_iterations | 150000 | 最大训练迭代数 |
| learning_rate | 1e-3 | 初始学习率 |
| num_mini_batches | 4 | 小批量数 |
| num_learning_epochs | 5 | 每次迭代的更新轮数 |
| clip_param | 0.2 | PPO 裁剪参数 |
| gamma | 0.99 | 折扣因子 |
| lam | 0.95 | GAE 参数 |
| desired_kl | 0.01 | 目标 KL 散度 |
| teacher_env_ratio | 0.75 | CTS 中 Teacher 环境占比 |
6. 部署流程
6.1 模型导出
训练完成后,策略通过 export_policy_as_jit 导出为 TorchScript 格式。该格式移除了梯度和优化器状态,仅保留前向计算图,可在 C++ 环境中高效加载。
bash
python legged_gym/utils/exporter.py --load_run <模型路径> --export_name go2_policy.pt6.2 MuJoCo 仿真验证
bash
python deploy/deploy_mujoco/deploy_go2.py- 加载 JIT 模型和 MuJoCo XML 场景
- 键盘/手柄控制速度命令
- 实时推理 + PD 控制(50Hz)
- 支持视频录制和 MoE 门控权重可视化(便于分析专家激活模式)
6.3 实机部署
bash
python deploy/deploy_real/deploy_real_go2.py enp3s0- 通过 Unitree SDK2 与 Go2 通信(DDS 协议)
- 遥控器控制速度命令
- 状态机:零力矩 → 移动到默认姿态 → 默认姿态保持 → RL 控制运行
- 紧急停止通过遥控器覆盖
实机观测构建与仿真一致:角速度 + 重力方向 + 命令 + 关节偏差 + 关节速度 + 上一步动作。
7. 配置体系
项目采用嵌套类继承的配置体系:
BaseConfig # 递归初始化成员类
└── LeggedRobotCfg # 足式机器人基础配置
├── GO2Cfg # Go2 主配置
├── GO2CfgVanilla # 关闭课程学习特性
├── GO2CfgFastFlat # 平地+高速训练
└── GO2CfgVanillaDynamic # 带动态命令的 Vanilla
LeggedRobotCfgPPO # PPO 训练配置
LeggedRobotCfgCTS # CTS 训练配置
LeggedRobotCfgMoECTS # MoE-CTS 训练配置
...(其他算法变体)配置差异对比:
| 配置 | 地形 | 回合时长 | 命令重采样 | heading_command | dynamic_sigma | command_curriculum |
|---|---|---|---|---|---|---|
| 主配置 | trimesh | 25s | 5s | 否 | 开启 | 开启 |
| Vanilla | trimesh | 20s | 10s | 是 | 关闭 | 关闭 |
| FastFlat | plane | 25s | 5s | 否 | 开启 | 开启(至4.5m/s) |
| VanillaDynamic | trimesh | 25s | 5s | 否 | 关闭 | 关闭 |
注:
heading_command为 True 时,命令的 yaw 角速度会被转换为航向角误差,适用于定向跟踪任务。
8. 关键设计决策
8.1 为什么用 CTS 而不是纯 PPO?
- PPO 的 Actor 只能访问有限观测,无法利用特权信息(地形高度、摩擦等)
- CTS 通过 Teacher 编码特权信息为潜在表示,Student 从历史观测中恢复该表示
- 推理时只需 Student 分支,实现 Sim-to-Real 迁移
8.2 为什么 Student 用历史观测而不是当前观测?
- 实机特权信息不可获取,但历史观测序列中隐含了环境信息(如地形变化趋势、摩擦导致的滑移)
- 通过 5 步历史观测(
history_length=5),Student 可以推断地形、摩擦等隐含状态 - 这是一种隐式状态估计方法,比显式添加状态估计器更简洁
8.3 为什么用 MoE?
- 不同地形/运动模式需要不同的运动策略(例如爬坡与平地小跑的关节协调模式不同)
- MoE 的门控机制可以自动为不同场景选择不同专家,实现模式解耦
- 负载均衡损失防止专家坍缩,保证专家多样性
8.4 为什么观测中不包含线速度?
- 实机线速度估计通常不准确(依赖腿部运动学积分或外部定位)
- CTS 的 Student 可以通过历史观测隐式推断速度(例如通过关节速度和机身姿态变化)
- PPO 模式下,线速度仅作为特权观测传给 Critic
8.5 动态 σ 的设计意图
- 低速时使用小 σ(精确跟踪),高速时使用大 σ(容忍更大误差)
- 复杂地形使用大 σ(安全优先),简单地形使用小 σ(性能优先)
- 避免机器人在高速/复杂地形下因过度追求精确跟踪而摔倒
9. 数据流图
训练数据流:
┌──────────────────────────────────────────────────────────┐
│ IsaacGym 并行仿真 (8192 envs) │
│ ┌─────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 观测构建 │───→│ 策略推理 │───→│ PD控制 │──→ 仿真步进 │
│ │(obs+priv)│ │(Actor) │ │(torques) │ │
│ └─────────┘ └──────────┘ └──────────┘ │
│ │ ↑ │
│ │ ┌────┴────┐ │
│ │ │Encoder │ │
│ │ │T: priv │ │
│ │ │S: hist │ │
│ │ └─────────┘ │
│ ↓ │
│ RolloutStorage (obs, action, reward, done, history) │
└──────────────────────────────────────────────────────────┘
│
↓
┌──────────────────────────────────────────────────────────┐
│ 策略更新 │
│ 1. GAE 回报计算 │
│ 2. PPO 裁剪目标更新 (optimizer1: Actor+Critic+TeacherEnc)│
│ 3. Student 蒸馏更新 (optimizer2: StudentEnc ← TeacherEnc)│
└──────────────────────────────────────────────────────────┘
部署数据流:
┌──────────────────────────────────────────────────────────┐
│ MuJoCo/实机 │
│ obs_history → StudentEncoder → latent │
│ [latent, obs] → Actor → action_mean │
│ target_pos = action × scale + default_angles │
│ torque = Kp×(target - q) + Kd×(0 - dq) │
└──────────────────────────────────────────────────────────┘10. 性能指标
训练通常在 150k 迭代后收敛,关键指标:
- 线速度跟踪精度:命令速度与实际速度的比值(通常 >0.9 为优)
- 存活率:机器人不摔倒的回合比例(>95% 为优)
- 地形等级:课程学习中达到的最高地形难度(例如能够稳定通过楼梯和 30cm 障碍物)
- MoE 专家利用率:各专家的激活频率分布(理想情况下应接近均匀)
- RoboGauge 综合得分:论文中提出的可迁移性评分,与实物部署成功率呈正相关
11. 扩展指南
添加新机器人
- 在
resources/robots/下放置 URDF 模型 - 创建新的环境类继承
LeggedRobot,重写compute_observations和奖励函数 - 创建配置类继承
LeggedRobotCfg,设置机器人参数(如关节数量、PD 增益等) - 在
envs/__init__.py中注册任务
添加新算法
- 在
rsl_rl/algorithms/下实现算法类(继承OnPolicyAlgorithm) - 在
rsl_rl/modules/下实现对应的网络结构 - 在
rsl_rl/runners/下实现训练循环(继承OnPolicyRunner) - 在配置体系中添加对应的配置类(如
LeggedRobotCfgNewAlgo)
添加新地形
- 在
legged_gym/utils/terrain.py的make_terrain中添加地形类型 - 更新
terrain_proportions和terrain_max_command_ranges - 调整
dynamic_sigma的max_sigma列表,为新地形配置合适的容忍度
12. 总结
go2_rl_gym 项目将前沿的 MoE-CTS 算法、高效的 GPU 并行仿真、丰富的域随机化与课程学习、完整的部署工具链融为一体,为四足机器人运动控制提供了一个从仿真到现实的强大研究平台。通过模块化的设计,开发者可以轻松替换算法、修改奖励、添加地形或适配新机器人。其在真实 Go2 上实现的 4 m/s 高速奔跑和 30 cm 越障能力,证明了该框架在 Sim-to-Real 迁移方面的卓越效果。