
近日,华为公司董事、半导体业务部总裁何庭波,在国际电路系统研讨会ISCAS 2026上,提出了指导半导体产业发展的新原则------"韬(τ)定律",同时发表署名论文《A Time Scaling Theory for Multi-Layer Electronic Systems(多层电子系统的时间缩微理论)》做具体阐述。
这并非一个学院派的学术游戏,而是在后摩尔时代,面对先进制程封锁和物理极限的双重压力下,一条务实的"换道超车"路线。
要理解这条新路,我们需要从最基础的数学和物理开始,逐步深入其技术实现、行业背景以及对全球芯片产业格局的深远影响。
一、τ的数学身世:一个公式,两种变化
τ,这个不起眼的希腊字母,在电路理论中藏着一个秘密:它是时间的化身。
公式τ=R×C\tau = R \times Cτ=R×C,大概是电路分析中最简洁、优雅的关系之一。
RRR是电阻,CCC是电容,它们的乘积τ\tauτ描述了一个信号在电路中"安定下来"所需的时间。τ 越小,信号就跑得越快。
当信号从 0 跳变到 1(电容充电)时:
V(t)=V0(1−e−t/τ) V(t) = V_0 \left(1 - e^{-t/\tau}\right) V(t)=V0(1−e−t/τ)
电流则从一开始的最大值逐渐衰减:
i(t)=I0⋅e−t/τ i(t) = I_0 \cdot e^{-t/\tau} i(t)=I0⋅e−t/τ
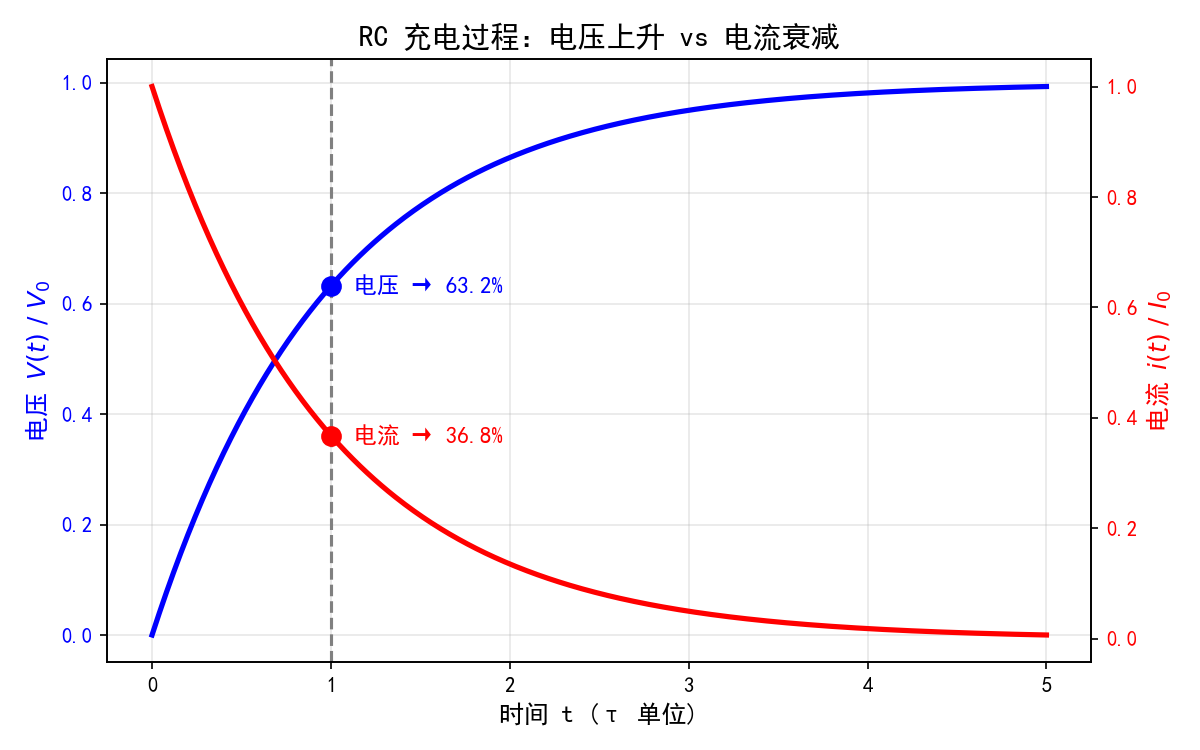 RC充电过程中的电压与电流变化。蓝色曲线为电压V(t)=V0(1−e−t/τ)V(t) = V_0(1 - e^{-t/τ})V(t)=V0(1−e−t/τ),从0上升至终值;红色曲线为电流i(t)=I0⋅e−t/τi(t) = I_0 \cdot e^{-t/τ}i(t)=I0⋅e−t/τ,从初始最大值衰减至0。
RC充电过程中的电压与电流变化。蓝色曲线为电压V(t)=V0(1−e−t/τ)V(t) = V_0(1 - e^{-t/τ})V(t)=V0(1−e−t/τ),从0上升至终值;红色曲线为电流i(t)=I0⋅e−t/τi(t) = I_0 \cdot e^{-t/τ}i(t)=I0⋅e−t/τ,从初始最大值衰减至0。
在t=τt = \taut=τ时,发生两件对称的事:
- 电压充到 63.2%
- 电流降到 36.8%
芯片里一个逻辑门能否"快速翻转",不只看电压,更看电流是否足够驱动负载。τ 越小,电压到达阈值越快、电流衰减越迅速,信号翻转延迟越低------这是 τ 定律最根本的物理依据。
τ 定律的核心主张,就是把芯片性能的度量衡从"空间"换成"时间"。过去我们说"3纳米芯片",那是几何缩微 ;τ 定律说:别比谁画得小,比谁跑得快。芯片的进步不再是"几何缩微",而是 "时间缩微"。
正如何庭波在论文中指出:
"未来十年电子系统的演进应由时间缩微(time scaling)------即在堆栈每一层系统性地缩减单一特征时间常数τ,从皮秒级的晶体管切换到秒级的数据中心工作负载响应------来引导,而非几何缩微。"
1.1 四层分解:从皮秒到微秒的跨度
τ 定律的一个关键洞察是:芯片的延迟不是单一来源,而是层层叠加的结果。华为将系统总延迟分解为四个层级:
τ=f(τtransistor,τcircuit,τchip,τsystem) \tau = f(\tau_{\text{transistor}}, \tau_{\text{circuit}}, \tau_{\text{chip}}, \tau_{\text{system}}) τ=f(τtransistor,τcircuit,τchip,τsystem)
- 晶体管层(τtransistor\tau_{\text{transistor}}τtransistor) :单个晶体管开关的速度,通常以皮秒计。这取决于沟道长度、载流子迁移率等物理参数。
- 电路层(τcircuit\tau_{\text{circuit}}τcircuit) :信号在逻辑门之间的传输延迟,受互连线的电阻和电容(RC)支配,通常在纳秒 级别。这是逻辑折叠技术主要优化的对象。
- 芯片层(τchip\tau_{\text{chip}}τchip) :包括缓存访问、片上网络通信等宏观延迟,通常在纳秒级别。
- 系统层(τsystem\tau_{\text{system}}τsystem) :多芯片之间、甚至机柜之间的数据搬运时间,在传统AI集群中高达数十微秒。
这四层加起来,时间跨度整整十二个数量级。每一层都有自己的 τ,每一层都贡献给总体的系统延迟。τ 定律的本质,就是把"优化"从单一层级(比如死磕晶体管尺寸)扩展到所有层级的协同。
1.2 缩放因子 α:进步速度因场景而异
τ 定律用一个简单的公式描述代际进步:
τn+1=τn/α \tau_{n+1} = \tau_n / \alpha τn+1=τn/α
这里的α\alphaα是每年 τ 缩减的倍数 ,并且因应用场景而异。这不是缺点,而是一种诚实------不同领域对"进步"的定义和约束条件本来就不一样。
| 场景 | α 值 | 含义与原因 |
|---|---|---|
| 移动设备(手机SoC) | ~1.3倍/年 | 受功耗和散热硬约束,性能提升必须同时控制发热,因此进步较慢 |
| 安全关键系统(自动驾驶) | ~1.5倍/年 | 对延迟和可靠性要求极高,但也要保证功能安全,不能激进 |
| AI工作负载(训练集群) | 可达10倍/年 | 通信延迟缩短10倍直接意味着训练时间缩短10倍,经济价值极高,因此投入最大 |
这个 α 缩放因子,本质上是把"进步"从一个静态预言(如摩尔定律的"18个月翻倍")变成了一个动态优化问题:在给定功耗、散热、成本等约束下,寻找 τ 的最优压缩路径。
二、为什么要提出 τ 定律?两个必须面对的背景
任何新原则的提出,背后都有非如此不可的理由。τ 定律的出现,源于两个已经不可逆转的行业现实。
2.1 摩尔定律已死:单纯的"做小"不再管用
 1947年12月23日,第一个晶体管在贝尔实验室诞生。
1947年12月23日,第一个晶体管在贝尔实验室诞生。
60年来,半导体产业靠"把晶体管做得更小"驱动进步。但在7nm节点之后,几何缩微的回报急剧下降:掩模成本超过十亿美元,每晶体管成本不再下降,EUV光刻设备逼近物理极限。简单说,继续缩小尺寸,既不经济,也不现实 。
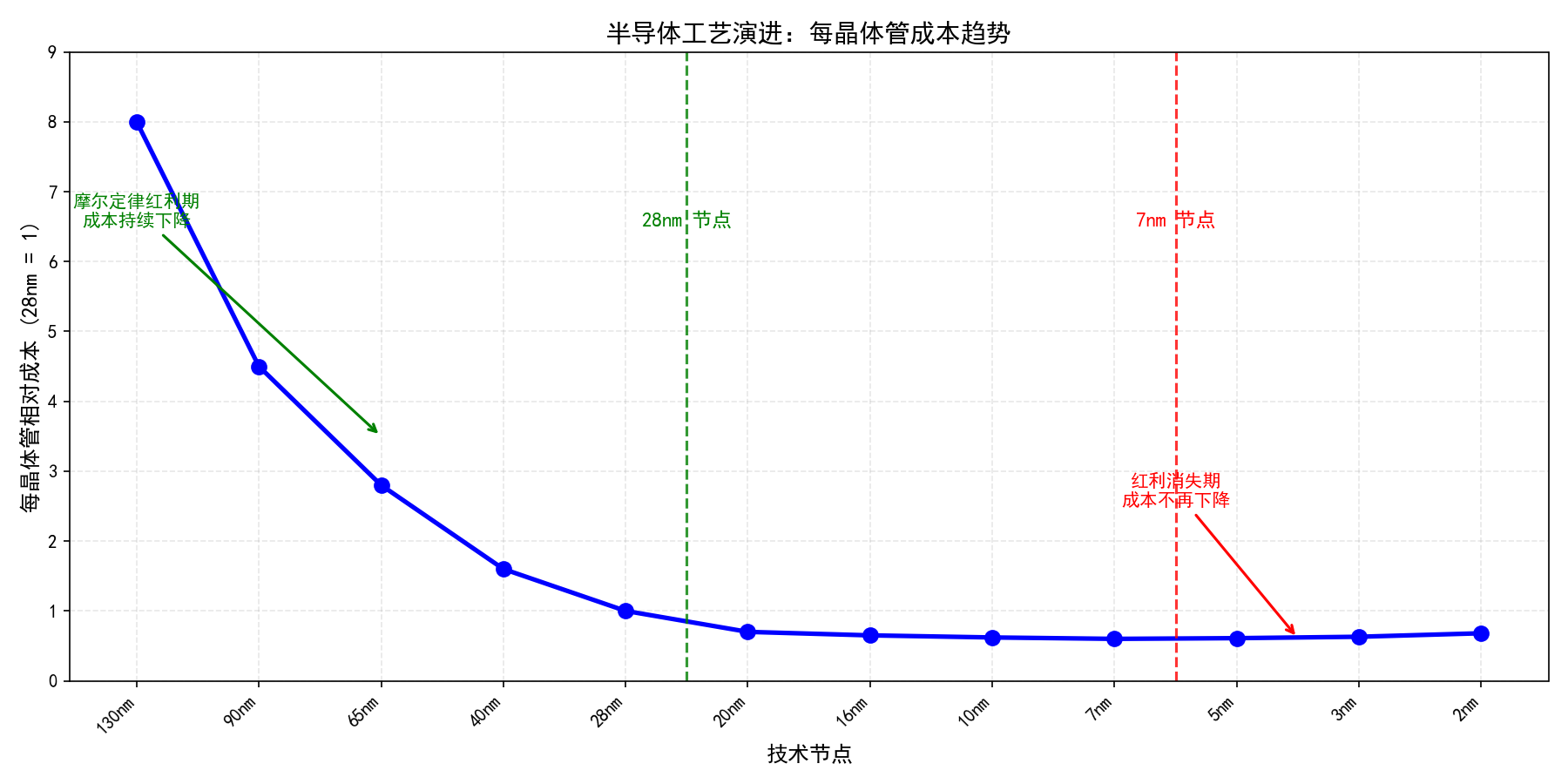 半导体工艺节点演进与每晶体管相对成本趋势
半导体工艺节点演进与每晶体管相对成本趋势
数据来源:综合自 IBS、IRDS 等行业报告(趋势示意,供参考)
如上图所示,在 28nm 节点之前,晶体管的持续微缩带来了显著的经济效益(每晶体管成本持续下降)。然而进入 7nm 及更先进节点后,由于设计复杂度指数级增长、掩模成本超过十亿美元、EUV 光刻设备逼近物理极限,每晶体管成本的下降趋势已基本停滞,甚至在 3nm 及以下节点出现轻微回升。
2.2 Dennard 缩放失效:芯片不再"更快且不更热"
1974年,现代DRAM内存的发明人、被誉为"DRAM之父"的罗伯特·登纳德 (Robert H. Dennard)在IBM工作期间提出:当晶体管缩小时,电压和电流也应等比缩小,从而功耗密度保持恒定 。这被称为"登纳德缩放定律 "(Dennard Scaling),与摩尔定律 共同构成了半导体产业近五十年的"黄金契约"。
 罗伯特·登纳德(Robert H. Dennard,1932---2024)
罗伯特·登纳德(Robert H. Dennard,1932---2024)
具体来说,登纳德缩放 的核心规则是:晶体管尺寸缩小为原来的1/k1/k1/k,则面积变为1/k21/k^21/k2,电容变为1/k1/k1/k,电压和电流也按1/k1/k1/k比例缩小。结果是:单个晶体管的功耗变为原来的1/k21/k^21/k2,而芯片上的晶体管数量变为原来的k2k^2k2倍------二者恰好抵消,芯片总功耗保持不变。这就是为什么在2005年之前,CPU频率可以从几十MHz一路飙升至3GHz以上,而散热器只需要一个小小的铝挤散热片。
但约2005年前后,Dennard缩放率先失效 。原因在于:电压无法无限降低。晶体管有一个阈值电压的物理下限------大约0.7V。低于这个电压,晶体管无法彻底关断,漏电电流会指数级激增。电压卡在了约1V左右,无法继续按比例缩小,但晶体管还在继续变小。结果就是:芯片上的晶体管数量仍在翻倍,但单个晶体管的功耗不再等比例下降。芯片的总功耗密度开始随集成度提升而飙升。
这就是"暗硅"(Dark Silicon)时代的开始。所谓"暗硅",是指一颗芯片上虽然集成了数百亿个晶体管,但在任意时刻,绝大部分晶体管必须被关闭("变暗"),否则芯片会瞬间过热。今天的高性能CPU和GPU,实际活跃的晶体管面积通常不到芯片总面积的10%------剩下的90%都是"暗的"。
何庭波在论文中指出:
"几何时代事实上已经结束。通过缩微实现加速的时代,正在让位于通过多层电子系统的 τ 优化实现加速的时代。"
τ 定律正是在 Dennard 失效、摩尔定律放缓的背景下,提出的新缩微原则。 它不再执着于"更小的晶体管",而是转向"更快的信号"。如果说登纳德缩放 是通过"降低电压 "来控制功耗,那么τ定律 则是通过"压缩时间"来绕过电压下限------我不再要求晶体管在同样时间内完成更多计算,而是让每次计算本身变快,然后让不工作的部分彻底休眠。
三、τ 定律怎么实现?两项核心技术
有了理论基础,τ 定律需要实实在在的工程抓手。何庭波在论文中披露了两项已经量产或即将量产的核心技术。
3.1 逻辑折叠:在芯片内部"向高度要性能"
传统方式的困境:所有逻辑门平铺在二维平面。从A点到B点的信号,必须在平面上绕行,路径长,寄生电阻和电容(RC)大,延迟τ大。这就像城市里的公交车必须沿着街道走,不能抄近道。
逻辑折叠的做法 :把关键逻辑路径上的门,分布到两层(甚至更多层)垂直堆叠的有源层上,通过超细间距混合键合 连接。从电路设计师的角度看,两层有源层表现为一个单一的连续布局基底,单元可以跨晶圆边界分布,如同那是一个额外的金属层。信号布线大幅缩短,寄生RC急剧降低,时钟偏斜收紧。
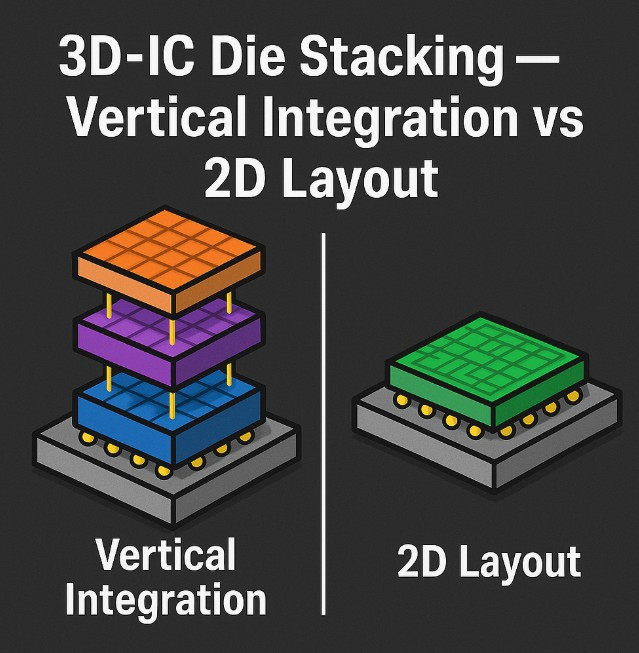 3D-IC 与 2D 平面封装架构对比示意图
3D-IC 与 2D 平面封装架构对比示意图
效果是惊人的 。根据何庭波披露的麒麟2026芯片量产数据(在固定制程节点上):
| 指标 | 提升幅度 |
|---|---|
| 晶体管密度 | 单代提升55% (从155→238 MTr/mm²) |
| SoC能效 | 性能核功耗效率提升41% |
| 最大时钟频率 | 提升近13% ,CPU核心频率回到3.1GHz |
| SRAM工作频率 | 提升40%以上 |
| 时钟网络 | 缓冲器减少50% ,偏斜降低25% ,布线缩短30% |
何庭波说:"这一提升幅度此前需要三年的几何缩微才能实现。" 这不是通过新的光刻步骤,而是通过逻辑在三维空间分布的拓扑重组。
3.2 统一总线 + 光学I/O:在系统层面"让集群像一颗芯片"
如果逻辑折叠解决的是芯片内部的皮秒/纳秒级延迟,那么AI集群的问题在系统层:数据搬运的能耗和成本已经超过了计算本身。大型AI集群中,超过80%的能耗用于数据传输,超过70%的成本投入在存储设备上。
问题出在哪里? 传统AI集群使用多层协议栈------PCIe连接主机、NVLink连接机箱内部、以太网连接机箱之间。每一层协议转换、序列化、握手都会增加延迟。端到端远程访问延迟高达数十微秒。
华为的解法:统一总线(Unified Bus) 。它以单一内存语义协议取代多层堆栈,在机箱内部和机箱之间实现对等互连。硬件原生支持远程内存访问,无需软件栈的消息传递和转换。效果是:端到端远程访问延迟从数十微秒降至约100纳秒------约500倍的τ缩减。
但光有协议还不够 。在每颗芯片多Tb/s的带宽需求下,传统铜缆SerDes(串行/解串器)的传输距离和功耗都到了极限。华为为此开发了Hi-ONE近封装光学引擎:每模块提供8Tb/s带宽,将电气SerDes的传输距离从约100厘米压缩至5厘米,然后转为光信号,传输距离从不到1米扩展至100米。
这两个技术合起来,让τ定律的优化范围从芯片内部(皮秒/纳秒级)一直延伸到数据中心级别(微秒级),真正实现了"端到端的τ压缩"。
四、τ 定律的优势与限制
任何技术路线都有它的长处和边界。τ 定律也不例外。
4.1 三大优势
优势一:摆脱制程封锁
τ 定律最令人振奋的承诺是:使7nm芯片性能对标3nm,成本仅为其一半以下。这意味着即使拿不到最先进的EUV光刻机,用成熟工艺(如DUV多重曝光)也能造出同等性能的芯片。这对受限于制程工艺的国家和产业来说,是一条真实的"换道超车"路径。
优势二:破解AI的资源错配困局
当AI集群超过80%的能耗和70%的成本被数据搬运消耗时,继续提升计算能力已经意义不大。τ 定律的逻辑折叠和统一总线,直击这个痛点------把能耗从"搬运"释放回"计算",把成本从存储转移到真正的算力单元。
优势三:统一行业坐标系
这是τ定律最具战略意义的一点。在此之前,工艺专家谈纳米,电路设计师谈RC延迟,架构师谈带宽,系统工程师谈功耗------各说各话,协同优化极为困难。τ坐标系让所有人用同一套语言、同一个目标函数工作:谁对压缩τ的贡献最显著,谁就掌握了产业话语权。
4.2 四大限制
限制一:光速是硬天花板
即使在理想导体中,电磁信号的传播速度也受限于光速c≈3×108 m/sc \approx 3 \times 10^8 \, \text{m/s}c≈3×108m/s。对于长度为LLL的互连线,仅传播延迟就至少有L/cL/cL/c。当τ被压缩到接近这个物理极限时,无论怎么优化R和C,都无法再进一步。
限制二:热力学第二定律
兰道尔原理告诉我们:擦除1比特信息至少耗散kTln2kT \ln 2kTln2的能量。压缩τ的同时压缩功耗,最终会遇到热力学的墙。当晶体管密度和开关频率都趋向无穷时,散热会熔化一切。
限制三:EDA工具的数学复杂性
传统EDA工具是为平面设计开发的,不支持跨层联合优化。将平面电路布局问题扩展到三维,求解空间从O(N2)O(N^2)O(N2)爆炸到O(N3)O(N^3)O(N3),约束条件呈指数增长。这是一个NP-hard问题,近似算法的设计本身就是数学挑战。
限制四:工艺偏差的统计特性
在逻辑折叠的多层结构中,来自不同晶圆的层被键合在一起,它们的阈值电压、迁移率等参数存在统计波动。这要求设计者用随机过程和概率约束来建模,而非传统的确定性问题。
4.3 一个关键定位
需要诚实地说:τ 定律目前更是一个 "方法论" 而非真正的"定律"。它的技术主张需要到**2031年(等效1.4nm目标)**才有完整验证。但它的价值在于:为后摩尔时代提供了一条不依赖极致制程的可持续演进路线。
五、行业背景:STCO 是什么?
在讨论 τ 定律对行业的影响之前,需要先了解一个已有共识的方法论------STCO( System Technology Co-Optimization,系统技术协同优化,也叫系统工艺协同优化)。STCO理念最早由imec(比利时微电子研究中心)于2019年提出并系统阐述,现已成为后摩尔时代半导体行业的核心方法论之一。
STCO 的核心思想是"分而治之":把一颗大芯片拆成存储芯粒、逻辑芯粒、I/O芯粒、供电芯粒,各自用最适合的工艺制造,再通过先进封装(如台积电的CoWoS、英特尔的EMIB)拼装起来。AMD的Chiplet、英伟达的NVLink + 多芯片模组,本质上都是STCO的实践。
但STCO面临一个根本问题:不同芯粒用不同工艺制造,各说各话。工艺专家谈纳米,电路设计师谈RC,架构师谈带宽,系统工程师谈功耗。没有共同的语言,就无法做真正的协同优化。
τ 定律提供的正是这个共同语言 :把一切都换算成时间常数 τ。工艺改进 → 降低τtransistor\tau_{\text{transistor}}τtransistor;逻辑折叠 → 降低τcircuit\tau_{\text{circuit}}τcircuit;统一总线 → 降低τsystem\tau_{\text{system}}τsystem。所有层级的贡献都可以用同一个指标 τ 衡量,所有设计决策都可以问"这能让系统总 τ 降低多少?"
τ 定律与 STCO 的关系可以概括为:STCO 是"怎么做",τ 定律是"优化什么"。具体如下所示:
| 概念 | 核心定义 | 关键词 |
|---|---|---|
| STCO | 将芯片按功能拆解成不同模块,为每个模块匹配最适合的工艺,再拼成完整系统 | 芯粒(Chiplet)、先进封装、异构集成 |
| τ定律 | 以时间常数 τ 作为统一优化目标,在堆栈每一层系统性压缩 τ | 时间缩微、逻辑折叠、统一坐标系 |
何庭波在论文中写道:
"τ 是使端到端堆栈协同优化成为可能的语言------而各层独立优化、时序只是残差的时代已经结束。"
这句话精准地揭示了τ定律对STCO的赋能:它把一种工程哲学,变成了一门可量化、可优化的数学。
六、τ 定律对其他公司的影响
对于行业外人士来说,一个自然的问题是:台积电、Intel、AMD、NVIDIA 难道在 STCO 方面没有作为吗?
恰恰相反------它们才是 STCO 的先行者和主要推动者。τ 定律的本质,是对这些分散的行业实践进行了一次"理论收编"和"坐标系统一"。
6.1 各公司的既有作为
台积电:STCO 的"基础设施提供商"
台积电在STCO领域布局最深、商业化最成熟。CoWoS (Chip-on-Wafer-on-Substrate)是台积电主流的 2.5D 先进封装技术,也是当前 STCO 方法论最核心的基础设施之一。
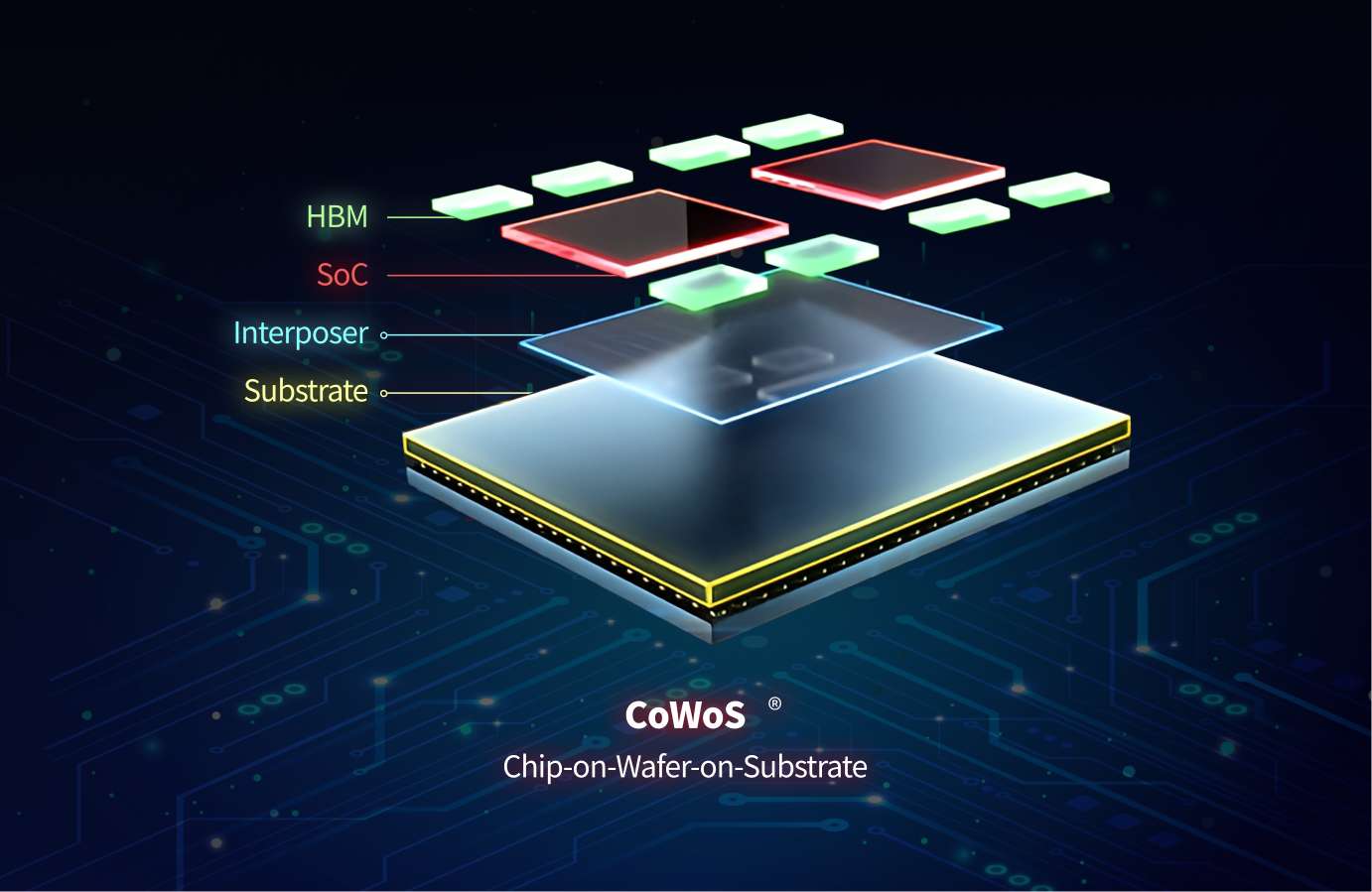 台积电 CoWoS 先进封装结构示意图
台积电 CoWoS 先进封装结构示意图
图中展示了 CoWoS 的典型堆叠结构(从下往上):
- Substrate(基板):最底层,提供机械支撑和外部电气连接;
- Interposer(硅中介层):位于基板之上,内部刻有高密度互连线,通过硅通孔(TSV)连接上下层;
- SoC(系统级芯片)和HBM(高带宽内存):并排放置在硅中介层之上,通过微凸块与中介层相连。
这种结构的关键优势在于:硅中介层将 SoC 与 HBM 之间的信号传输距离从毫米级缩短到微米级,大幅降低了寄生电阻和电容(RC),从而系统性压缩系统层的时间常数 τ------这正是 τ 定律在系统层优化中所依赖的技术路径。
目前 CoWoS 已发展出三个主要版本:CoWoS-S(整块硅中介层)、CoWoS-R(有机中介层)、CoWoS-L(局部硅桥)。其中 CoWoS-S 是英伟达、AMD 等 HPC 和 AI 芯片的首选方案。
英特尔:STCO 的"系统级践行者"
英特尔是"系统工艺协同优化"这一术语最积极的推广者之一。其技术路线完整覆盖2.5D到3D:EMIB(通过基板内微型硅桥连接)、Foveros(芯片垂直堆叠)、Foveros Direct(铜-铜直接键合,间距进入9μm以下)。2026年6月发布的至强6+,采用Foveros Direct 3D + EMIB,由29个组件构成------这是STCO在CPU领域的顶级实践。
AMD:STCO 的"量产先锋"
AMD的Chiplet策略是STCO最成功的商业化案例。2019年的Zen 2开始将处理器拆分为多颗小芯片分别制造;2023年的MI300X通过SoIC 3D封装,单颗集成1530亿个晶体管;3D V-Cache将SRAM直接堆叠在CPU之上,是3D堆叠的经典量产案例。2026年,AMD已锁定了台积电约11%的CoWoS产能用于MI400系列。
英伟达:STCO 的"系统层定义者"
英伟达的核心贡献在于系统层的τ压缩,这与τ定律中的"系统层"维度高度重合。NVLink(第五代达1.8TB/s双向带宽)、NVSwitch(实现单节点16个GPU全互联)、GB200 NVL72(将72颗GPU连成单一逻辑单元)------这些技术本质上都是在压缩系统层的时间常数τ。英伟达在2026年预定了台积电约60%-65%的CoWoS产能,其对先进封装的依赖是战略性的。
6.2 τ 定律对它们的影响
影响一:被"统一坐标系",从"散装努力"到"可比较指标"
τ 定律最重要的贡献,不是发明了新东西,而是为已有实践提供了统一的衡量尺度。此前,台积电的CoWoS-L将互连间距推进到6μm------这在τ语言中意味着什么?英特尔的Foveros Direct将信号传输距离缩短了x%------这对应多少τ压缩?英伟达的NVLink将系统延迟从微秒级压到纳秒级------这对应系统层τ的多少倍缩减?τ定律回答的正是这个问题:把所有分散的努力换算成同一个指标------时间常数τ的压缩倍数。
影响二:竞争焦点的转移
τ 定律明确宣告:竞争不再是"谁把线画得更细",而是"谁把数据搬得更快"。
| 公司 | 原有的竞争坐标 | τ 定律后的竞争坐标 |
|---|---|---|
| 台积电 | 制程节点(3nm→2nm) | 封装集成度对τ的贡献(CoWoS-L、SoIC) |
| 英特尔 | 制程+封装分两条线 | 系统级全栈τ优化(18A + Foveros + EMIB协同) |
| AMD | Chiplet的设计灵活性 | 3D堆叠对τ的压缩能力 |
| 英伟达 | GPU算力 + CUDA生态 | 系统互连的端到端τ(NVLink域的统一性) |
中信证券在2026年5月的报告中明确指出,τ定律的本质是"系统技术协同优化(STCO)方法论的演进版",它让竞争从"单一维度"转向"多层级系统优化"。
影响三:黄仁勋的回应与分歧
2026年6月,英伟达CEO黄仁勋在台北电脑展前回应τ定律时表示:这对华为是重大突破,但对台积电不构成真正威胁,因为类似技术行业已探索多年。
这一回应的本质分歧在于:黄仁勋认为Logic Folding ≈ 先进封装(die级堆叠),这是台积电、英特尔已在做的;而华为认为Logic Folding深入到**"逻辑单元级别"的细粒度三维重构**,而不是简单的芯片堆叠。观察者网的分析指出:"华为的方向并非孤立存在,而是整个行业过去十多年共同推进的一条大趋势。区别在于,华为在工艺受限条件下,把'细粒度3D化'推进得更激进。"
影响四:话语权的重新分配
τ 定律最深远的影响可能不在技术层面,而在产业话语权层面。在摩尔定律时代,"谁能造出最先进制程"决定了行业话语权。
而在τ定律的"时间缩微"坐标系下,封装厂、内存厂、互连协议定义者、系统架构师的τ贡献都变得可量化。这意味着:不再只有"先进制程玩家"站在食物链顶端。
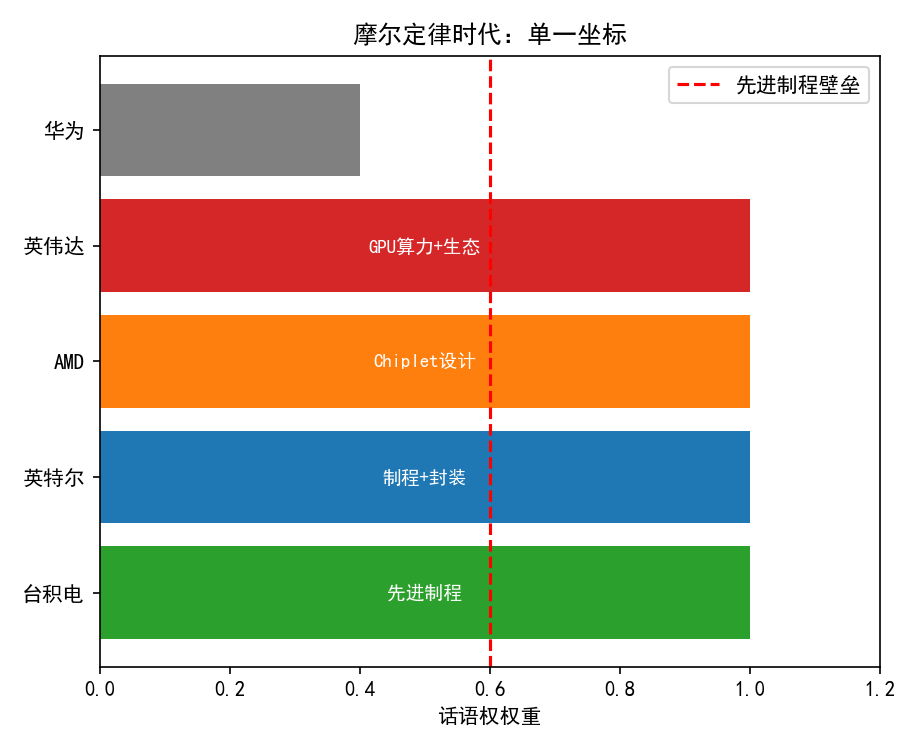
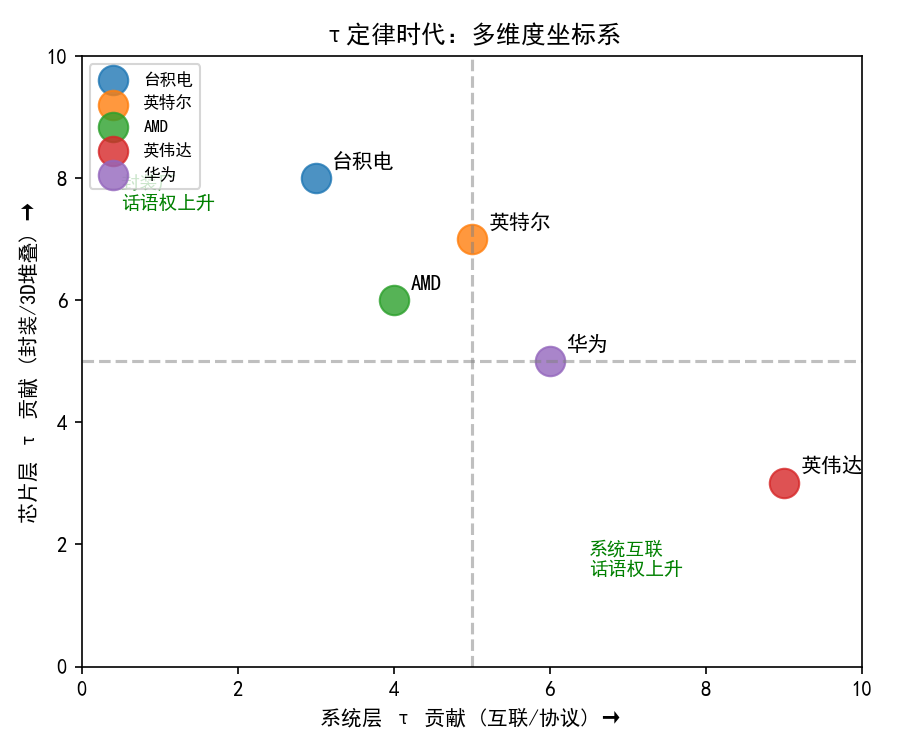
6.3 总结
| 公司 | τ 定律带来的影响 |
|---|---|
| 台积电 | 其封装技术的τ贡献被显式度量;需应对"不依赖先进制程"叙事的冲击 |
| 英特尔 | 其"系统级思维"与τ定律高度契合,获得路线图背书 |
| AMD | 其SoIC实践成为τ定律在芯片层的典型例证 |
| 英伟达 | 其互联架构被纳入τ坐标系;需回应"华为换道超车"的竞争叙事 |
| 华为 | 理论收编者与坐标系建立者;在受限条件下把"细粒度3D化"推进得更激进 |
一句话:τ 定律不是对既有行业的颠覆,而是对既有行业实践的"理论收编"和"坐标系统一"。各家公司的分散努力,被华为用"时间常数τ"这一把尺子重新度量------这让竞争变得可比较、可衡量,也重新分配了产业话语权。
七、结语:定律不靠命名,靠验证
华为将这条定律命名为"韬",取 τ 的谐音。但一个定律能否真正成为定律,不取决于命名,而取决于验证。它的技术主张需要到2031年(等效1.4nm目标)才有完整验证。
τ 定律更深层的意义在于:它是第一次由中国企业提出的半导体产业原则。在过去半个多世纪,行业标准一直由西方企业和机构定义------摩尔定律(英特尔)、登纳德定律(IBM)、STCO(imec)。τ 定律的提出,标志着中国企业在全球半导体行业从"规则遵循者"向"规则定义者"的转变。
正如华为轮值董事长徐直军所说:"韬定律不可能只靠一家公司完成。希望整个产业界参与进来。"这既是邀请,也是判断。
至少,τ 定律已经迈出了关键一步:它让产业界的注意力,从"谁能把线画得更细"转向了"谁能把数据搬得更快"。而这,正是华为的目标------在制程受限的困境下,重塑后摩尔时代的游戏规则。
参考文献
1 何庭波. A Time Scaling Theory for Multi-Layer Electronic Systems. 2026.
2 芯东西. 刚刚,华为何庭波发表署名芯片论文,全文来了. 2026-05-25.
3 上海证券报. "韬(τ)定律"有何影响?行业独家解读. 2026-05-25.
4 中信证券. 电子行业专题报告:τ定律与半导体产业新范式. 2026-05.
5 观察者网. 黄仁勋回应华为"τ定律":行业已探索多年. 2026-06.