文章目录
- [MongoDB 从入门到精通:文档数据库的灵活之道](#MongoDB 从入门到精通:文档数据库的灵活之道)
-
- [一、引言:为什么选择 MongoDB?](#一、引言:为什么选择 MongoDB?)
- 二、核心概念:文档、集合与数据库
-
- [2.1 文档(Document)](#2.1 文档(Document))
- [2.2 集合(Collection)](#2.2 集合(Collection))
- [2.3 数据库(Database)](#2.3 数据库(Database))
- [三、CRUD 操作:从基础到进阶](#三、CRUD 操作:从基础到进阶)
-
- [3.1 插入文档](#3.1 插入文档)
- [3.2 查询文档](#3.2 查询文档)
- [3.3 更新文档](#3.3 更新文档)
- [3.4 删除文档](#3.4 删除文档)
- 四、索引:查询性能的基石
-
- [4.1 索引类型](#4.1 索引类型)
- [4.2 创建索引](#4.2 创建索引)
- [4.3 索引使用策略](#4.3 索引使用策略)
- 五、聚合管道:数据处理的艺术
-
- [5.1 常用阶段](#5.1 常用阶段)
- [5.2 实战示例](#5.2 实战示例)
- [5.3 lookup 实现关联查询](#5.3 lookup 实现关联查询)
- 六、复制集:高可用与数据安全
-
- [6.1 复制集架构](#6.1 复制集架构)
- [6.2 故障转移机制](#6.2 故障转移机制)
- [6.3 读写关注](#6.3 读写关注)
- 七、分片集群:水平扩展之道
-
- [7.1 分片组件](#7.1 分片组件)
- [7.2 分片键选择](#7.2 分片键选择)
- [7.3 分片策略](#7.3 分片策略)
- 八、性能优化最佳实践
-
- [8.1 查询优化](#8.1 查询优化)
- [8.2 写入优化](#8.2 写入优化)
- [8.3 内存与存储](#8.3 内存与存储)
- 九、实战案例:构建一个博客系统
-
- [9.1 数据模型设计](#9.1 数据模型设计)
- [9.2 常用查询](#9.2 常用查询)
- 十、总结与展望
MongoDB 从入门到精通:文档数据库的灵活之道
一、引言:为什么选择 MongoDB?
在关系型数据库统治了半个世纪之后,互联网的爆发式增长带来了新的数据挑战:海量用户、高并发读写、快速迭代的业务模型、半结构化或非结构化的数据。传统的关系型数据库(如 MySQL、PostgreSQL)虽然强大,但在面对这些场景时,往往显得僵化且难以扩展。
MongoDB 作为 NoSQL 数据库的佼佼者,以其文档模型为核心,重新定义了数据存储的灵活性。它不再要求你预先定义严格的表结构,而是允许你将数据存储为 JSON 风格的文档(BSON),字段可以动态变化,数组和嵌套对象成为一等公民。这种设计天然适配现代应用开发,尤其是 Node.js、Python、Java 等语言中的对象模型。
本文将带你从零开始,深入 MongoDB 的核心概念、查询技巧、索引优化、聚合管道、复制集与分片集群,最终达到生产级实战水平。
二、核心概念:文档、集合与数据库
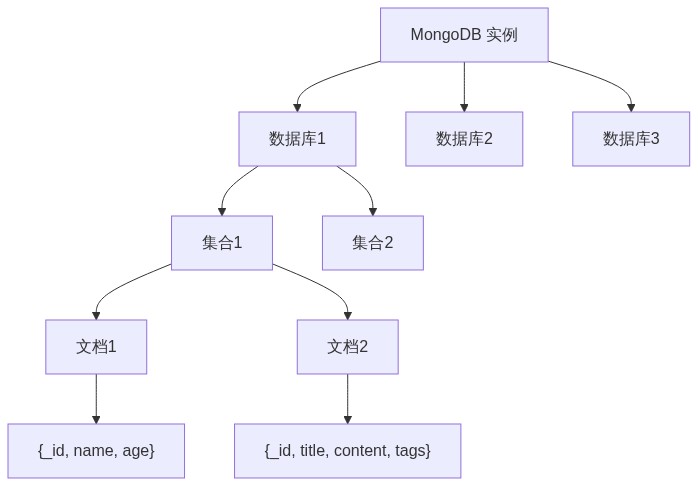
2.1 文档(Document)
MongoDB 中的文档是一个键值对的有序集合,使用 BSON(Binary JSON)格式存储。BSON 扩展了 JSON,支持更多数据类型,如 Date、Binary、ObjectId 等。
json
{
"_id": ObjectId("507f1f77bcf86cd799439011"),
"name": "张三",
"age": 28,
"email": "zhangsan@example.com",
"address": {
"city": "北京",
"street": "长安街"
},
"tags": ["developer", "mongodb"]
}关键特性:
_id是文档的唯一标识,默认自动生成。- 字段可以动态增减,无需提前定义 schema。
- 支持嵌套文档和数组,天然表达复杂关系。
2.2 集合(Collection)
集合类似于关系型数据库中的表,但它是 schema-less 的。同一个集合中的文档可以拥有完全不同的字段结构。当然,实际项目中我们通常保持一定的结构一致性,以便于查询和索引。
2.3 数据库(Database)
数据库是集合的容器。一个 MongoDB 实例可以包含多个数据库,每个数据库拥有独立的权限和存储空间。
三、CRUD 操作:从基础到进阶
3.1 插入文档
javascript
// 插入单个文档
db.users.insertOne({
name: "李四",
age: 30,
email: "lisi@example.com"
})
// 插入多个文档
db.users.insertMany([
{ name: "王五", age: 25 },
{ name: "赵六", age: 35, city: "上海" }
])3.2 查询文档
查询是 MongoDB 最强大的部分之一。支持条件查询、投影、排序、分页、正则、范围查询等。
javascript
// 基本查询
db.users.find({ age: { $gte: 25 } })
// 多条件查询(AND)
db.users.find({ age: { $gte: 25 }, city: "北京" })
// OR 查询
db.users.find({ $or: [{ age: 30 }, { city: "上海" }] })
// 嵌套字段查询
db.users.find({ "address.city": "北京" })
// 数组查询
db.users.find({ tags: "mongodb" }) // 包含该元素
db.users.find({ tags: { $all: ["mongodb", "node"] } }) // 同时包含多个
db.users.find({ tags: { $size: 3 } }) // 数组长度为33.3 更新文档
javascript
// 更新单个文档
db.users.updateOne(
{ name: "张三" },
{ $set: { age: 29 } }
)
// 更新多个文档
db.users.updateMany(
{ age: { $lt: 20 } },
{ $inc: { age: 1 } }
)
// 替换整个文档
db.users.replaceOne(
{ name: "张三" },
{ name: "张三", age: 30, email: "new@example.com" }
)3.4 删除文档
javascript
db.users.deleteOne({ name: "张三" })
db.users.deleteMany({ age: { $lt: 18 } })四、索引:查询性能的基石
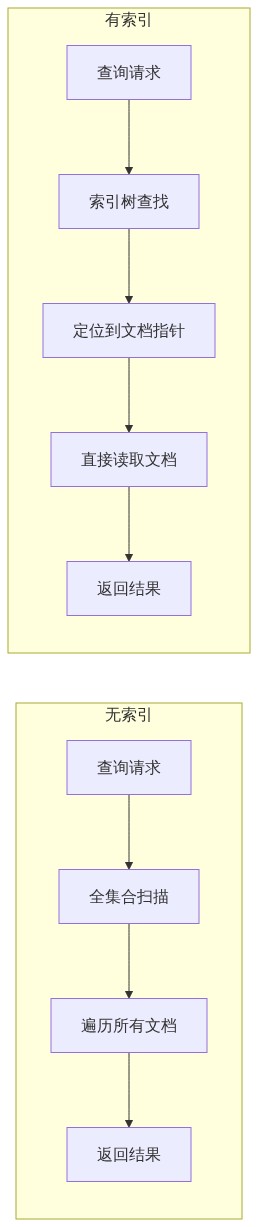
没有索引的 MongoDB 查询会进行全集合扫描(collection scan),这在数据量大时是灾难性的。索引是提升查询性能最有效的手段。
4.1 索引类型
- 单字段索引:最基本的索引。
- 复合索引:针对多个字段的联合查询。
- 多键索引:针对数组字段的索引。
- 文本索引:支持全文搜索。
- 地理空间索引:支持地理位置查询。
- 哈希索引:用于分片键的哈希分布。
4.2 创建索引
javascript
// 单字段索引(1 升序,-1 降序)
db.users.createIndex({ email: 1 })
// 复合索引
db.users.createIndex({ city: 1, age: -1 })
// 唯一索引
db.users.createIndex({ email: 1 }, { unique: true })
// 后台创建索引(不阻塞读写)
db.users.createIndex({ name: 1 }, { background: true })4.3 索引使用策略
- 覆盖查询:查询的所有字段都在索引中,无需回表读取文档。
- 索引选择性:索引字段的区分度越高,效果越好。
- 复合索引的字段顺序:将等值查询字段放在前面,范围查询字段放在后面。
- 避免过多索引:每个索引都会增加写入开销和存储空间。
五、聚合管道:数据处理的艺术
聚合管道(Aggregation Pipeline)是 MongoDB 最强大的数据处理工具。它将数据通过一系列阶段(stage)进行转换,每个阶段对输入文档执行特定操作,输出结果传递给下一阶段。
5.1 常用阶段
$match:过滤文档,类似 find 的条件。$group:分组聚合,支持 sum、avg、max、min 等。$sort:排序。$project:投影,可以添加、删除、重命名字段。$lookup:左外连接,类似 SQL 的 JOIN。$unwind:将数组字段拆分为多条文档。$bucket:分桶聚合。
5.2 实战示例
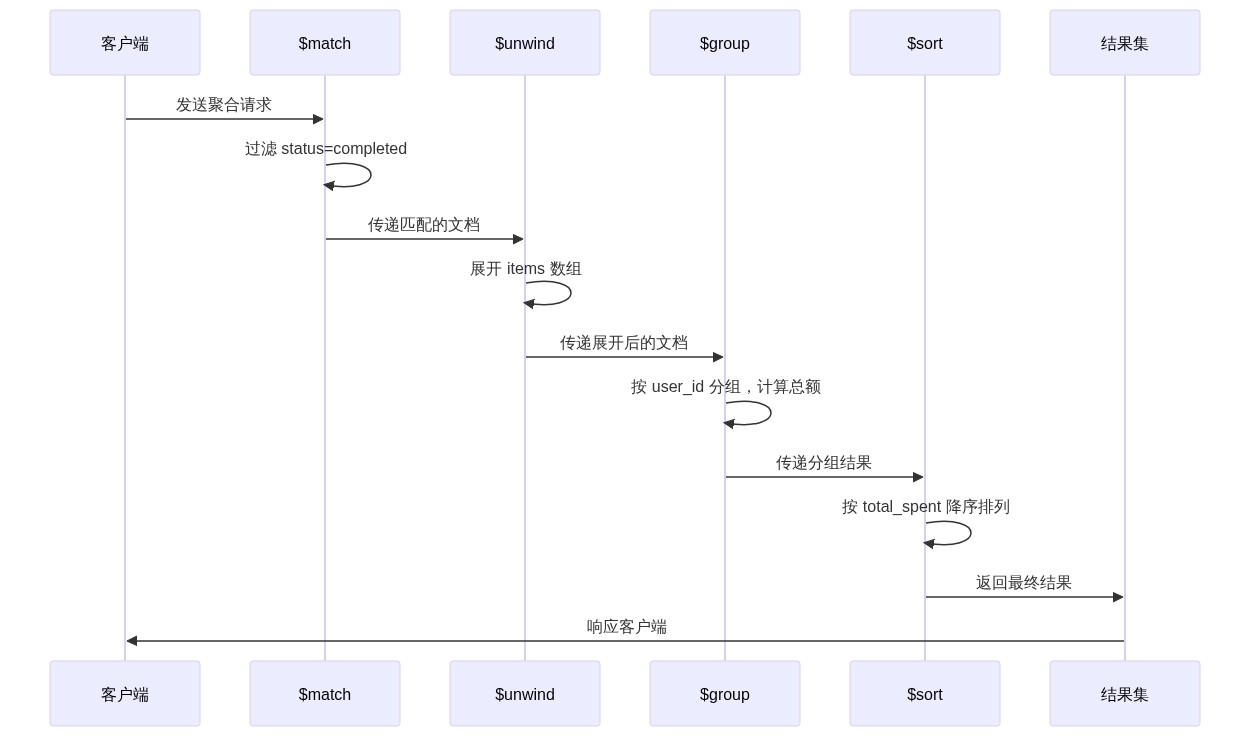
假设有一个订单集合 orders,结构如下:
json
{
"_id": ObjectId,
"user_id": "u001",
"items": [
{ "product": "手机", "price": 5000, "quantity": 1 },
{ "product": "耳机", "price": 200, "quantity": 2 }
],
"status": "completed",
"created_at": ISODate("2024-01-15")
}需求:统计每个用户的总消费金额,并按金额降序排列。
javascript
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $unwind: "$items" },
{ $group: {
_id: "$user_id",
total_spent: { $sum: { $multiply: ["$items.price", "$items.quantity"] } },
order_count: { $sum: 1 }
}},
{ $sort: { total_spent: -1 } },
{ $limit: 10 }
])5.3 $lookup 实现关联查询
javascript
db.orders.aggregate([
{ $lookup: {
from: "users",
localField: "user_id",
foreignField: "_id",
as: "user_info"
}},
{ $unwind: "$user_info" },
{ $project: {
user_name: "$user_info.name",
total_amount: { $sum: "$items.price" }
}}
])
六、复制集:高可用与数据安全
6.1 复制集架构
复制集(Replica Set)是一组维护相同数据集的 MongoDB 实例。它提供自动故障转移和数据冗余。
- Primary:主节点,处理所有写操作。
- Secondary:从节点,同步主节点的数据,可处理读请求(需配置)。
- Arbiter:仲裁节点,不存储数据,仅参与选举投票。
6.2 故障转移机制
当 Primary 宕机时,复制集自动触发选举,从 Secondary 中选出一个新的 Primary。整个过程对应用透明,只需配置正确的连接字符串。
javascript
// 连接复制集
const uri = "mongodb://host1:27017,host2:27017,host3:27017/mydb?replicaSet=rs0"6.3 读写关注
- 写关注(write concern) :控制写操作被确认的节点数量。
w: 1:主节点确认即可。w: majority:大多数节点确认。w: 0:不等待确认(性能最高,但有数据丢失风险)。
- 读偏好(read preference) :控制读请求发往哪个节点。
primary:只读主节点(默认)。primaryPreferred:优先主节点,不可用时读从节点。secondary:只读从节点。nearest:读取网络延迟最低的节点。
七、分片集群:水平扩展之道
当单台服务器无法承载数据量和吞吐量时,分片(Sharding)是 MongoDB 的终极解决方案。
7.1 分片组件
- 分片(Shard):每个分片是一个复制集,存储数据子集。
- 配置服务器(Config Server):存储集群的元数据和配置信息。
- 查询路由器(mongos):接收客户端请求,将请求路由到正确的分片。
7.2 分片键选择
分片键是决定数据分布的关键。好的分片键应该满足:
- 高基数:分片键的值分布广泛,避免数据倾斜。
- 写分布均匀:写入操作能均匀分散到各个分片。
- 查询模式匹配:大多数查询包含分片键,实现定向查询(targeted query),避免广播查询(broadcast query)。
javascript
// 启用分片
sh.enableSharding("mydb")
// 对集合进行分片
sh.shardCollection("mydb.orders", { user_id: "hashed" })7.3 分片策略
- 范围分片:基于分片键的值范围进行分片。适合范围查询,但可能导致数据倾斜。
- 哈希分片:对分片键计算哈希值,数据分布更均匀。适合写入密集型场景。
八、性能优化最佳实践
8.1 查询优化
- 使用 explain() 分析查询计划:查看是否使用了索引,扫描了多少文档。
- 避免正则表达式前导通配符 :
/^pattern/可以使用索引,/pattern/不能。 - 限制返回字段:使用投影减少网络传输。
- 使用批量操作:减少网络往返次数。
8.2 写入优化
- 批量插入 :使用
insertMany替代循环insertOne。 - 调整写关注:在可接受的数据安全范围内,降低写关注级别。
- 使用无序写入 :
ordered: false允许部分失败,提高吞吐量。
8.3 内存与存储
- 监控工作集(Working Set):确保热数据能放入内存。
- 使用 WiredTiger 存储引擎:默认引擎,支持压缩和文档级锁。
- 定期运行 compact:回收磁盘空间,但会阻塞操作。
九、实战案例:构建一个博客系统
9.1 数据模型设计
javascript
// 文章集合
db.posts.insertOne({
title: "MongoDB 入门",
content: "这是一篇关于 MongoDB 的文章...",
author_id: ObjectId("..."),
tags: ["mongodb", "database"],
comments: [
{ user: "user1", content: "好文章!", created_at: ISODate() },
{ user: "user2", content: "学习了", created_at: ISODate() }
],
created_at: ISODate(),
updated_at: ISODate()
})
// 用户集合
db.users.insertOne({
name: "张三",
email: "zhangsan@example.com",
bio: "全栈工程师",
followers_count: 100
})9.2 常用查询
javascript
// 按标签查询文章,按时间排序
db.posts.find({ tags: "mongodb" })
.sort({ created_at: -1 })
.limit(20)
// 聚合:统计每个标签的文章数量
db.posts.aggregate([
{ $unwind: "$tags" },
{ $group: { _id: "$tags", count: { $sum: 1 } } },
{ $sort: { count: -1 } }
])
// 聚合:查询文章及其作者信息
db.posts.aggregate([
{ $lookup: {
from: "users",
localField: "author_id",
foreignField: "_id",
as: "author"
}},
{ $unwind: "$author" },
{ $project: {
title: 1,
content: { $substr: ["$content", 0, 200] },
author_name: "$author.name",
created_at: 1
}}
])十、总结与展望
MongoDB 以其灵活的文档模型、强大的查询语言、原生的高可用和水平扩展能力,成为现代应用开发中不可或缺的数据存储方案。从简单的 CRUD 到复杂的聚合分析,从单机部署到大规模分片集群,MongoDB 提供了一条平滑的成长路径。
但也要清醒认识到,MongoDB 并非万能。对于强事务一致性要求极高的金融系统、复杂的多表关联查询场景,传统关系型数据库可能更合适。最佳实践是:根据业务场景选择最合适的工具,而不是盲目追求技术潮流。
随着 MongoDB 7.0 的发布,其事务支持、查询性能、安全特性进一步增强。未来,MongoDB 在实时分析、移动后端、物联网等领域的应用将更加广泛。掌握 MongoDB,就是掌握了一把应对现代数据挑战的利器。