ResNet-18 通过引入残差连接(Skip Connection) ,有效解决了深层卷积神经网络(CNN)中常见的梯度消失 与网络退化问题。
论文 https://arxiv.org/pdf/1512.03385v1
对于传统的深度学习网络,我们普遍认为网络深度越深(参数越多)非线性的表达能力越强,该网络所能学习到的东西就越多。 凭借这一基本规则,经典的CNN网络从LetNet-5(5层)和AlexNet(8层)发展到VGGNet(16-19),再到后来GoogleNet(22层)。 但是后来发现传统的CNN网络结构随着层数加深到一定程度之后,越深的网络反而效果更差,过深的网络竟然使分类的准确率下降了,如图所示 56层网络的错误率 高于 20层的错误率 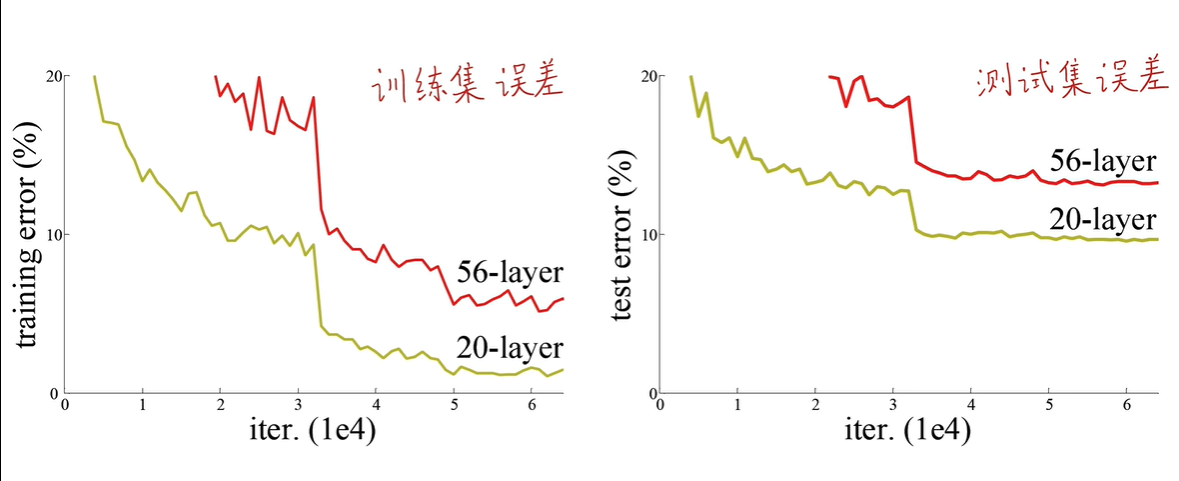
网络退化
网络退化(Network Degradation)是指随着神经网络深度的增加,模型的性能并未如预期那样持续提升,反而可能出现饱和乃至下降的现象。这种现象并非由过拟合引起,因为在更深的网络中,即使在训练数据上的表现也开始变差,导致训练误差和测试误差之间的差距可能增大。
残差结构
传统深层网络直接学习映射 (H(x)),层数加深时梯度消失、性能下降。 ResNet 改为学习残差 : H(x)=F(x)+x 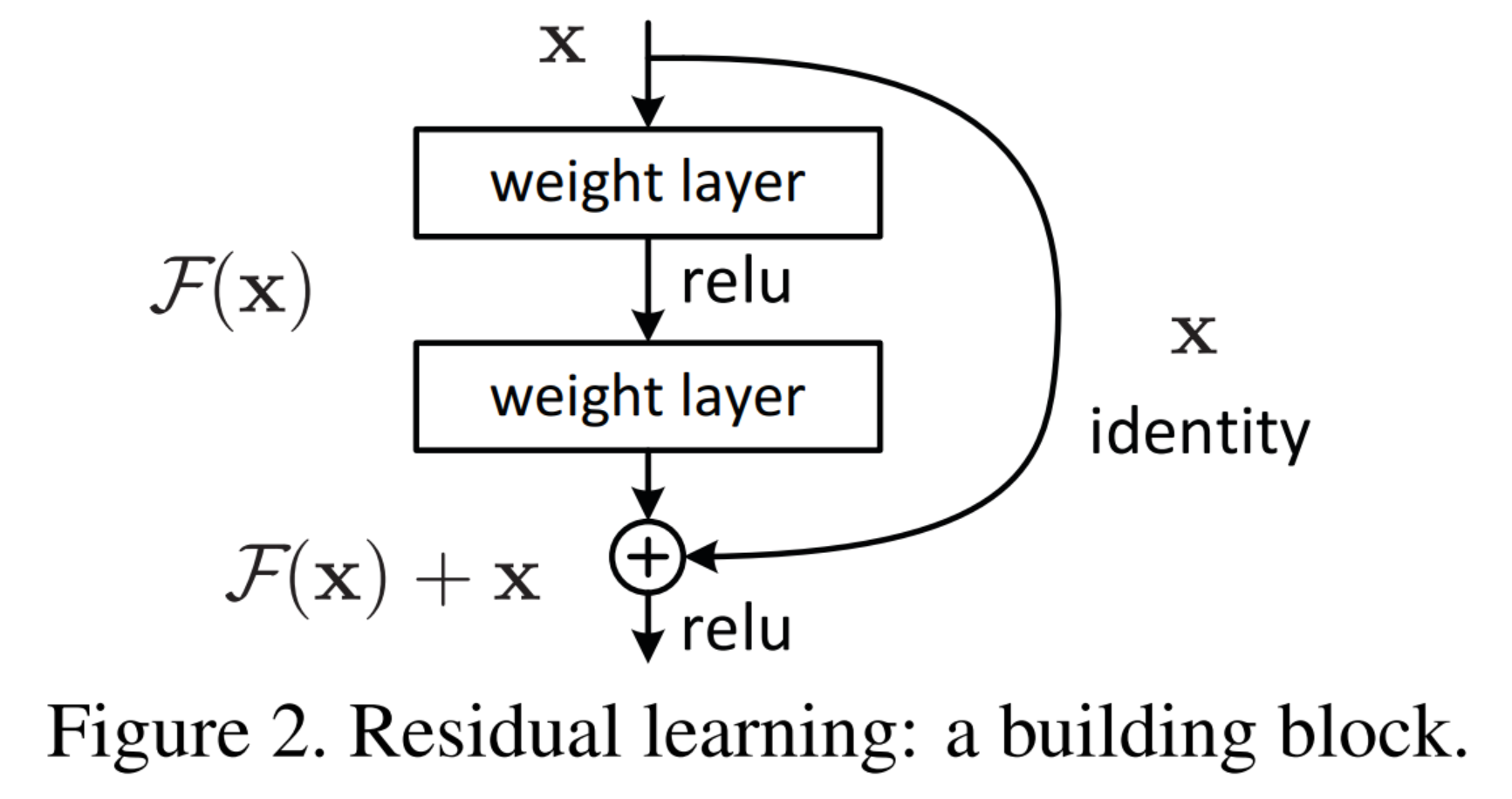
-
x:输入特征(跳跃连接,直接传到输出)
-
F(x):残差函数(2层3×3卷积+BN+ReLU)
-
优势:
-
梯度可沿跳跃连接直达浅层,缓解梯度消失
-
网络易拟合恒等映射(F(x)\to0)),深层训练更稳
-
关键特性
-
轻量高效 :约11M参数 、1.8G FLOPs,推理快,适合移动端/嵌入式。
-
模块化设计:4个Stage,每阶段2个Block,易扩展(如ResNet-34/50)。
-
强表征能力:通道从64→512,空间逐级下采样,兼顾细粒度与全局特征。
-
训练稳定:残差连接让深层梯度有效回传,收敛快、泛化性好。
典型应用
-
图像分类:ImageNet、CIFAR-10/100、自定义数据集
-
迁移学习:特征提取、微调小样本任务
-
检测/分割骨干:Faster R-CNN、YOLO、Mask R-CNN、U-Net
-
轻量化部署:手机、边缘设备、实时系统
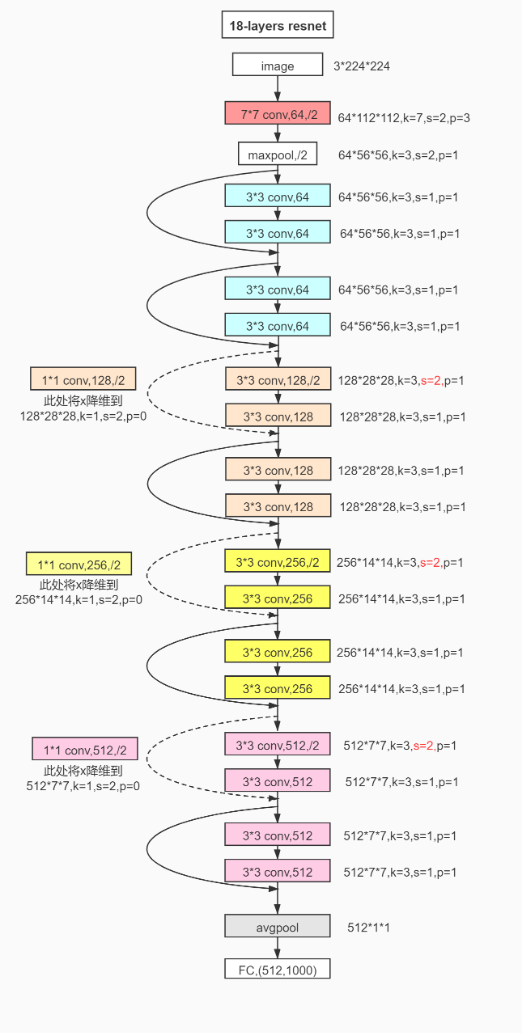
ResNet-18 结构总览
(输入 3×224×224) 共18个可训练层 (17卷积+1全连接),分5阶段: 
| 阶段 | 操作 | 输出尺寸 | 通道数 | 层数 |
|---|---|---|---|---|
| 输入 | RGB图像 | 224×224 | 3 | - |
| Stage1 | 7×7卷积(64, stride=2)+BN+ReLU+MaxPool(3×3, stride=2) | 56×56 | 64 | 1 |
| Stage2 | 2×BasicBlock(3×3卷积×2) | 56×56 | 64 | 4 |
| Stage3 | 2×BasicBlock(第一个stride=2下采样) | 28×28 | 128 | 4 |
| Stage4 | 2×BasicBlock(第一个stride=2下采样) | 14×14 | 256 | 4 |
| Stage5 | 2×BasicBlock(第一个stride=2下采样) | 7×7 | 512 | 4 |
| 分类头 | 全局平均池化+全连接(1000) | 1×1 | 512→1000 | 1 |
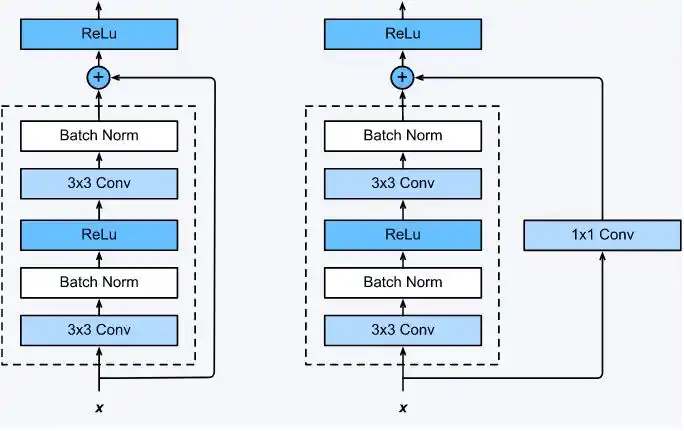
BasicBlock(基础残差块)
-
左图:Conv(3×3)→BN→ReLU→Conv(3×3)→BN
-
右图跳跃连接:维度匹配时用恒等映射 ;不匹配时用1×1卷积 调整通道/步长
代码示例
ResNet18
@Author: CSDN@王_teacher bilibili@王_teacher
@Date: 2024/5/26
@Description: RestNet18 纯手写
"""
import torch
import torch.nn as nn
from torchvision.models import resnet18
# 纯平铺版 ResNet18,没有任何子模块、没有任何函数调用
class ResNet18(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
# ==================== Stem 层 ====================
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# ==================== Layer 1 (64, 无下采样) ====================
# Block 1
self.layer1_conv1 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer1_bn1 = nn.BatchNorm2d(64)
self.layer1_conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer1_bn2 = nn.BatchNorm2d(64)
# Block 2
self.layer1_conv3 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer1_bn3 = nn.BatchNorm2d(64)
self.layer1_conv4 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer1_bn4 = nn.BatchNorm2d(64)
# ==================== Layer 2 (128, 下采样) ====================
# Downsample
self.downsample2 = nn.Sequential(
nn.Conv2d(64, 128, 1, 2, bias=False),
nn.BatchNorm2d(128)
)
# Block 1
self.layer2_conv1 = nn.Conv2d(64, 128, 3, 2, 1, bias=False)
self.layer2_bn1 = nn.BatchNorm2d(128)
self.layer2_conv2 = nn.Conv2d(128, 128, 3, 1, 1, bias=False)
self.layer2_bn2 = nn.BatchNorm2d(128)
# Block 2
self.layer2_conv3 = nn.Conv2d(128, 128, 3, 1, 1, bias=False)
self.layer2_bn3 = nn.BatchNorm2d(128)
self.layer2_conv4 = nn.Conv2d(128, 128, 3, 1, 1, bias=False)
self.layer2_bn4 = nn.BatchNorm2d(128)
# ==================== Layer3 (256, 下采样) ====================
self.downsample3 = nn.Sequential(
nn.Conv2d(128, 256, 1, 2, bias=False),
nn.BatchNorm2d(256)
)
self.layer3_conv1 = nn.Conv2d(128, 256, 3, 2, 1, bias=False)
self.layer3_bn1 = nn.BatchNorm2d(256)
self.layer3_conv2 = nn.Conv2d(256, 256, 3, 1, 1, bias=False)
self.layer3_bn2 = nn.BatchNorm2d(256)
self.layer3_conv3 = nn.Conv2d(256, 256, 3, 1, 1, bias=False)
self.layer3_bn3 = nn.BatchNorm2d(256)
self.layer3_conv4 = nn.Conv2d(256, 256, 3, 1, 1, bias=False)
self.layer3_bn4 = nn.BatchNorm2d(256)
# ==================== Layer4 (512, 下采样) ====================
self.downsample4 = nn.Sequential(
nn.Conv2d(256, 512, 1, 2, bias=False),
nn.BatchNorm2d(512)
)
self.layer4_conv1 = nn.Conv2d(256, 512, 3, 2, 1, bias=False)
self.layer4_bn1 = nn.BatchNorm2d(512)
self.layer4_conv2 = nn.Conv2d(512, 512, 3, 1, 1, bias=False)
self.layer4_bn2 = nn.BatchNorm2d(512)
self.layer4_conv3 = nn.Conv2d(512, 512, 3, 1, 1, bias=False)
self.layer4_bn3 = nn.BatchNorm2d(512)
self.layer4_conv4 = nn.Conv2d(512, 512, 3, 1, 1, bias=False)
self.layer4_bn4 = nn.BatchNorm2d(512)
# ==================== 头部 ====================
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
# Stem
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# ==================== Layer 1 ====================
identity = x
x = self.layer1_conv1(x)
x = self.layer1_bn1(x)
x = self.relu(x)
x = self.layer1_conv2(x)
x = self.layer1_bn2(x)
x += identity
x = self.relu(x)
identity = x
x = self.layer1_conv3(x)
x = self.layer1_bn3(x)
x = self.relu(x)
x = self.layer1_conv4(x)
x = self.layer1_bn4(x)
x += identity
x = self.relu(x)
# ==================== Layer 2 ====================
identity = self.downsample2(x)
x = self.layer2_conv1(x)
x = self.layer2_bn1(x)
x = self.relu(x)
x = self.layer2_conv2(x)
x = self.layer2_bn2(x)
x += identity
x = self.relu(x)
identity = x
x = self.layer2_conv3(x)
x = self.layer2_bn3(x)
x = self.relu(x)
x = self.layer2_conv4(x)
x = self.layer2_bn4(x)
x += identity
x = self.relu(x)
# ==================== Layer3 ====================
identity = self.downsample3(x)
x = self.layer3_conv1(x)
x = self.layer3_bn1(x)
x = self.relu(x)
x = self.layer3_conv2(x)
x = self.layer3_bn2(x)
x += identity
x = self.relu(x)
identity = x
x = self.layer3_conv3(x)
x = self.layer3_bn3(x)
x = self.relu(x)
x = self.layer3_conv4(x)
x = self.layer3_bn4(x)
x += identity
x = self.relu(x)
# ==================== Layer4 ====================
identity = self.downsample4(x)
x = self.layer4_conv1(x)
x = self.layer4_bn1(x)
x = self.relu(x)
x = self.layer4_conv2(x)
x = self.layer4_bn2(x)
x += identity
x = self.relu(x)
identity = x
x = self.layer4_conv3(x)
x = self.layer4_bn3(x)
x = self.relu(x)
x = self.layer4_conv4(x)
x = self.layer4_bn4(x)
x += identity
x = self.relu(x)
# 分类头
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
if __name__ == '__main__':
torch.manual_seed(0)
# 模型
model = ResNet18()
x = torch.randn(1,3,224,224)
model.eval()
py = model.forward(x)
print(py.shape)